ISSN 0439-755X
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
心理学报 ›› 2022, Vol. 54 ›› Issue (11): 1416-1423.doi: 10.3724/SP.J.1041.2022.01416 cstr: 32110.14.2022.01416
• 研究报告 • 上一篇
詹沛达1,2( )
)
收稿日期:2021-06-10
发布日期:2022-09-08
出版日期:2022-11-25
基金资助:
ZHAN Peida1,2()
Received:2021-06-10
Online:2022-09-08
Published:2022-11-25
摘要:
多模态数据为实现对认知结构的精准诊断及其他认知特征(如, 认知风格)的全面反馈提供了可能性。为实现对题目作答精度、作答时间(RT)和视觉注视点数(FC)的联合分析, 本文基于联合-交叉负载建模法提出3个多模态认知诊断模型。实证研究及模拟研究结果表明: (1)联合分析比分离分析更适用于多模态数据; (2)新模型可直接利用RT和FC中信息提高潜在能力或潜在属性的估计准确性; (3)新模型的参数估计返真性较好; (4)忽略交叉负载所导致的负面结果比冗余考虑交叉负载所导致的更严重。
中图分类号:
詹沛达. (2022). 引入眼动注视点的联合-交叉负载多模态认知诊断建模. 心理学报, 54(11), 1416-1423.
ZHAN Peida. (2022). Joint-cross-loading multimodal cognitive diagnostic modeling incorporating visual fixation counts. Acta Psychologica Sinica, 54(11), 1416-1423.
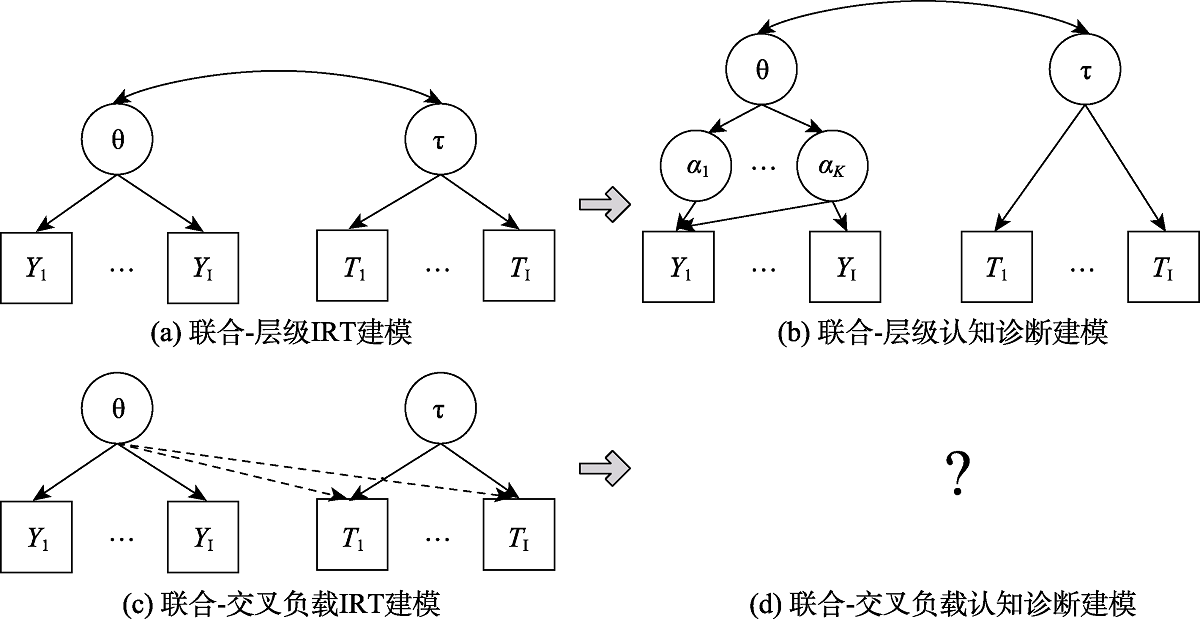
图1 多模态联合建模示意图(以作答精度和作答时间数据为例)
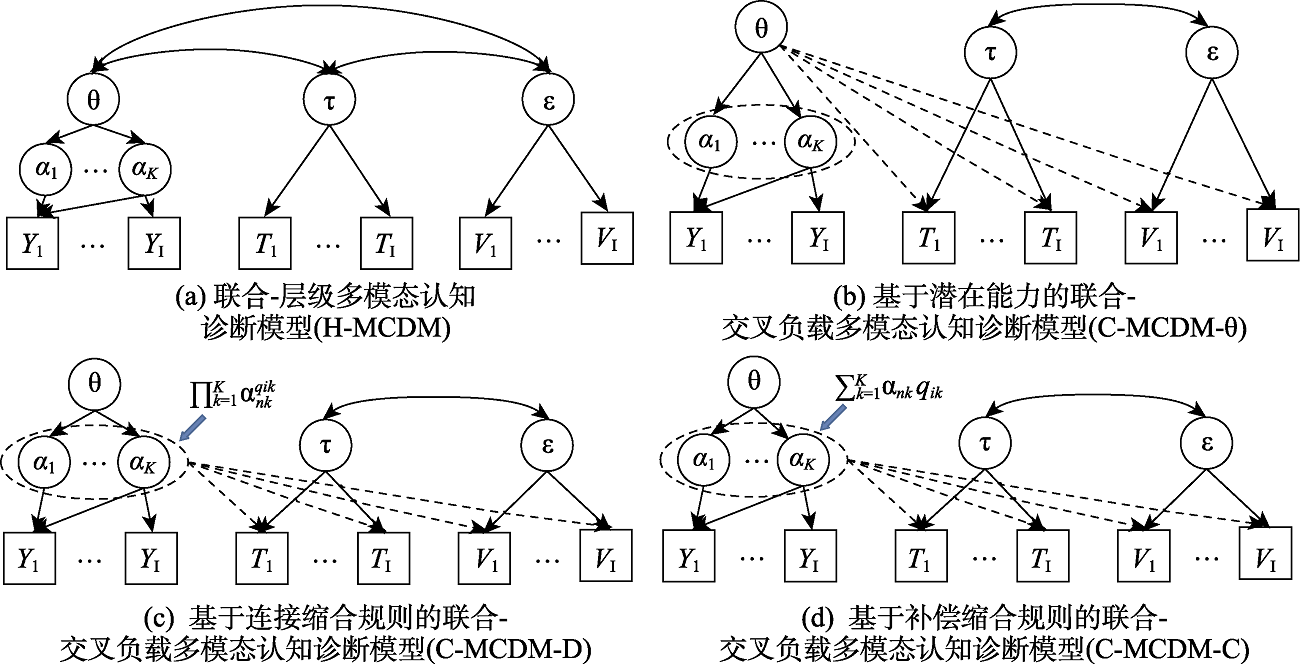
图2 联合-层级和联合-交叉负载多模态认知诊断建模示意图 注: θ为潜在能力; τ为潜在加工速度; ε为潜在视觉参与度; α为潜在属性; Y为题目作答精度; T为题目作答时间; V为注视点数; I为题目数量; K为属性数量.
| φi | λi | |
|---|---|---|
| > 0 | < 0 | |
| > 0 | 关键信息多, 认知负荷要求低: 若f(θn, αn, qi) ↑, 则RT↓, FC↑; 若f(θn, αn, qi) ↓, 则RT↑, FC↓; | 关键信息少, 认知负荷要求低: 若f(θn, αn, qi) ↑, 则RT↓, FC↓; 若f(θn, αn, qi) ↓, 则RT↑, FC↑; |
| < 0 | 关键信息多, 认知负荷要求高: 若f(θn, αn, qi) ↑, 则RT↑, FC↑; 若f(θn, αn, qi) ↓, 则RT↓, FC↓; | 关键信息少, 认知负荷要求高: 若f(θn, αn, qi) ↑, 则RT↑, FC↓; 若f(θn, αn, qi) ↓, 则RT↓, FC↑; |
表1 C-MCDM中φi和λi参数的正负取值可能反映的题目信息
| φi | λi | |
|---|---|---|
| > 0 | < 0 | |
| > 0 | 关键信息多, 认知负荷要求低: 若f(θn, αn, qi) ↑, 则RT↓, FC↑; 若f(θn, αn, qi) ↓, 则RT↑, FC↓; | 关键信息少, 认知负荷要求低: 若f(θn, αn, qi) ↑, 则RT↓, FC↓; 若f(θn, αn, qi) ↓, 则RT↑, FC↑; |
| < 0 | 关键信息多, 认知负荷要求高: 若f(θn, αn, qi) ↑, 则RT↑, FC↑; 若f(θn, αn, qi) ↓, 则RT↓, FC↓; | 关键信息少, 认知负荷要求高: 若f(θn, αn, qi) ↑, 则RT↑, FC↓; 若f(θn, αn, qi) ↓, 则RT↓, FC↑; |
| θ | τ | ε | 认知特征推断 | 可能的原因或行为表现 |
|---|---|---|---|---|
| + | + | + | 认知流畅+聚焦者 | 有能力全面提取题目中的关键信息 |
| + | + | - | 认知流畅+非聚焦者 | 有能力排除干扰, 提取题目中少有的关键信息 |
| + | - | + | 沉思型+聚焦者 | 基于已提取的关键信息, 对可能问题解决方法深思熟虑 |
| + | - | - | 沉思型+非聚焦者 | 有能力排除干扰, 基于少量的关键信息进行深思熟虑 |
| - | + | + | 冲动型+聚焦者 | 快速提取一些信息, 快速验证问题解决方法 |
| - | + | - | 冲动型+非聚焦者 | 未充分提取信息, 倾向于快速猜测 |
| - | - | + | 认知不流畅+聚焦者 | 有作答动机但认知能力较低 |
| - | - | - | 认知不流畅+非聚焦者 | 缺乏作答动机 |
表2 8种认知特征综合类别及可能的原因或行为表现(Zhan et al., 2022)
| θ | τ | ε | 认知特征推断 | 可能的原因或行为表现 |
|---|---|---|---|---|
| + | + | + | 认知流畅+聚焦者 | 有能力全面提取题目中的关键信息 |
| + | + | - | 认知流畅+非聚焦者 | 有能力排除干扰, 提取题目中少有的关键信息 |
| + | - | + | 沉思型+聚焦者 | 基于已提取的关键信息, 对可能问题解决方法深思熟虑 |
| + | - | - | 沉思型+非聚焦者 | 有能力排除干扰, 基于少量的关键信息进行深思熟虑 |
| - | + | + | 冲动型+聚焦者 | 快速提取一些信息, 快速验证问题解决方法 |
| - | + | - | 冲动型+非聚焦者 | 未充分提取信息, 倾向于快速猜测 |
| - | - | + | 认知不流畅+聚焦者 | 有作答动机但认知能力较低 |
| - | - | - | 认知不流畅+非聚焦者 | 缺乏作答动机 |

图3 实证数据Q矩阵; 白色表示“0”, 灰色表示“1”
| Model | -2LL | DIC | ppp_RA | ppp_RT | ppp_FC |
|---|---|---|---|---|---|
| S-MCDM | 11104.13 | 11890.70 | 0.42 | 0.52 | 0.78 |
| H-MCDM | 11040.62 | 11804.00 | 0.42 | 0.51 | 0.57 |
| C-MCDM-θ | 10275.27 | 11542.78 | 0.43 | 0.51 | 0.68 |
| C-MCDM-D | 10127.21 | 10549.14 | 0.40 | 0.52 | 0.64 |
| C-MCDM-C | 10009.65 | 10434.95 | 0.36 | 0.51 | 0.67 |
表3 实证数据中模型-数据拟合指标
| Model | -2LL | DIC | ppp_RA | ppp_RT | ppp_FC |
|---|---|---|---|---|---|
| S-MCDM | 11104.13 | 11890.70 | 0.42 | 0.52 | 0.78 |
| H-MCDM | 11040.62 | 11804.00 | 0.42 | 0.51 | 0.57 |
| C-MCDM-θ | 10275.27 | 11542.78 | 0.43 | 0.51 | 0.68 |
| C-MCDM-D | 10127.21 | 10549.14 | 0.40 | 0.52 | 0.64 |
| C-MCDM-C | 10009.65 | 10434.95 | 0.36 | 0.51 | 0.67 |
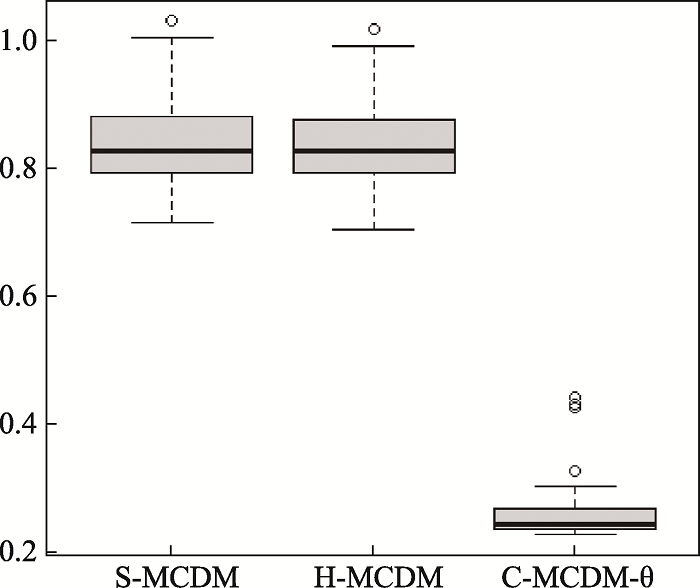
图4 实证数据中潜在能力参数估计后验标准差(标准误)
| 题目 | 考查 属性 | 作答精度 | 作答时间 | 注视点数 | φ | λ | |||
|---|---|---|---|---|---|---|---|---|---|
| g | s | ξ | ω | m | d | ||||
| 1 | (1010) | 0.71 (0.23) | 0.06 (0.04) | 2.89 (0.04) | 3.78 (0.340) | 4.23 (0.04) | 0.08 (0.011) | 0.25 (0.05) | -0.22 (0.04) |
| 2 | (1100) | 0.60 (0.22) | 0.05 (0.04) | 3.43 (0.05) | 2.56 (0.20) | 4.85 (0.04) | 0.03 (0.002) | -0.07 (0.06) | 0.13 (0.04) |
| 3 | (1100) | 0.33 (0.13) | 0.38 (0.11) | 2.60 (0.06) | 2.65 (0.25) | 3.87 (0.05) | 0.07 (0.010) | 0.43 (0.07) | -0.40 (0.05) |
| 4 | (0100) | 0.31 (0.21) | 0.18 (0.08) | 3.34 (0.05) | 2.56 (0.20) | 4.68 (0.04) | 0.03 (0.003) | -0.11 (0.06) | 0.15 (0.04) |
| 5 | (0010) | 0.49 (0.20) | 0.25 (0.07) | 3.13 (0.07) | 1.83 (0.14) | 4.50 (0.05) | 0.03 (0.002) | 0.21 (0.08) | -0.18 (0.06) |
| 6 | (0100) | 0.09 (0.04) | 0.86 (0.07) | 3.08 (0.08) | 3.14 (0.42) | 4.42 (0.07) | 0.05 (0.012) | -0.65 (0.08) | 0.61 (0.07) |
| 7 | (0001) | 0.43 (0.19) | 0.22 (0.11) | 3.74 (0.06) | 1.98 (0.16) | 5.06 (0.05) | 0.02 (0.001) | -0.22 (0.07) | 0.19 (0.06) |
| 8 | (1001) | 0.15 (0.08) | 0.61 (0.16) | 3.92 (0.06) | 2.88 (0.29) | 5.18 (0.06) | 0.02 (0.002) | -0.43 (0.07) | 0.41 (0.06) |
| 9 | (0001) | 0.44 (0.13) | 0.36 (0.10) | 3.41 (0.10) | 1.22 (0.10) | 4.82 (0.07) | 0.01 (0.001) | -0.07 (0.12) | 0.17 (0.08) |
| 10 | (1001) | 0.11 (0.06) | 0.73 (0.15) | 3.80 (0.12) | 1.13 (0.10) | 5.18 (0.09) | 0.01 (0.001) | 0.31 (0.14) | -0.29 (0.10) |
表4 实证数据中C-MCDM-θ模型的题目参数估计值
| 题目 | 考查 属性 | 作答精度 | 作答时间 | 注视点数 | φ | λ | |||
|---|---|---|---|---|---|---|---|---|---|
| g | s | ξ | ω | m | d | ||||
| 1 | (1010) | 0.71 (0.23) | 0.06 (0.04) | 2.89 (0.04) | 3.78 (0.340) | 4.23 (0.04) | 0.08 (0.011) | 0.25 (0.05) | -0.22 (0.04) |
| 2 | (1100) | 0.60 (0.22) | 0.05 (0.04) | 3.43 (0.05) | 2.56 (0.20) | 4.85 (0.04) | 0.03 (0.002) | -0.07 (0.06) | 0.13 (0.04) |
| 3 | (1100) | 0.33 (0.13) | 0.38 (0.11) | 2.60 (0.06) | 2.65 (0.25) | 3.87 (0.05) | 0.07 (0.010) | 0.43 (0.07) | -0.40 (0.05) |
| 4 | (0100) | 0.31 (0.21) | 0.18 (0.08) | 3.34 (0.05) | 2.56 (0.20) | 4.68 (0.04) | 0.03 (0.003) | -0.11 (0.06) | 0.15 (0.04) |
| 5 | (0010) | 0.49 (0.20) | 0.25 (0.07) | 3.13 (0.07) | 1.83 (0.14) | 4.50 (0.05) | 0.03 (0.002) | 0.21 (0.08) | -0.18 (0.06) |
| 6 | (0100) | 0.09 (0.04) | 0.86 (0.07) | 3.08 (0.08) | 3.14 (0.42) | 4.42 (0.07) | 0.05 (0.012) | -0.65 (0.08) | 0.61 (0.07) |
| 7 | (0001) | 0.43 (0.19) | 0.22 (0.11) | 3.74 (0.06) | 1.98 (0.16) | 5.06 (0.05) | 0.02 (0.001) | -0.22 (0.07) | 0.19 (0.06) |
| 8 | (1001) | 0.15 (0.08) | 0.61 (0.16) | 3.92 (0.06) | 2.88 (0.29) | 5.18 (0.06) | 0.02 (0.002) | -0.43 (0.07) | 0.41 (0.06) |
| 9 | (0001) | 0.44 (0.13) | 0.36 (0.10) | 3.41 (0.10) | 1.22 (0.10) | 4.82 (0.07) | 0.01 (0.001) | -0.07 (0.12) | 0.17 (0.08) |
| 10 | (1001) | 0.11 (0.06) | 0.73 (0.15) | 3.80 (0.12) | 1.13 (0.10) | 5.18 (0.09) | 0.01 (0.001) | 0.31 (0.14) | -0.29 (0.10) |
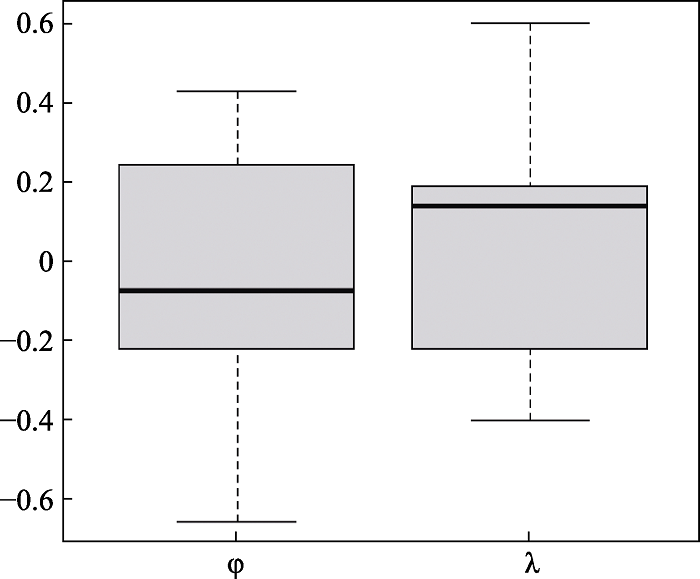
图5 实证数据中C-MCDM-θ模型的φi和λi估计值分布
| 被试 | α1 | α2 | α3 | α4 | θ | τ | ε | 认知特征推断 |
|---|---|---|---|---|---|---|---|---|
| 5 | 1 | 1 | 1 | 1 | 0.12 (0.25) | -0.17 (0.11) | 0.20 (0.09) | 沉思型+聚焦者 |
| 9 | 1 | 1 | 1 | 1 | 0.31 (0.23) | 0.05 (0.11) | 0.06 (0.08) | 认知流畅+聚焦者 |
| 34 | 1 | 0 | 1 | 0 | -0.19 (0.26) | 0.20 (0.11) | -0.06 (0.08) | 冲动型+非聚焦者 |
| 65 | 1 | 1 | 1 | 1 | 0.25 (0.24) | 0.20 (0.11) | -0.22 (0.09) | 认知流畅+非聚焦者 |
| 67 | 1 | 0 | 1 | 0 | -1.52 (0.27) | -0.18 (0.11) | 0.10 (0.09) | 认知不流畅+聚焦者 |
| 76 | 1 | 1 | 1 | 0 | 0.56 (0.25) | -0.01 (0.11) | -0.12 (0.09) | 沉思型+非聚焦者 |
表5 实证数据中个体认知结构诊断及其他认知特征推断样例
| 被试 | α1 | α2 | α3 | α4 | θ | τ | ε | 认知特征推断 |
|---|---|---|---|---|---|---|---|---|
| 5 | 1 | 1 | 1 | 1 | 0.12 (0.25) | -0.17 (0.11) | 0.20 (0.09) | 沉思型+聚焦者 |
| 9 | 1 | 1 | 1 | 1 | 0.31 (0.23) | 0.05 (0.11) | 0.06 (0.08) | 认知流畅+聚焦者 |
| 34 | 1 | 0 | 1 | 0 | -0.19 (0.26) | 0.20 (0.11) | -0.06 (0.08) | 冲动型+非聚焦者 |
| 65 | 1 | 1 | 1 | 1 | 0.25 (0.24) | 0.20 (0.11) | -0.22 (0.09) | 认知流畅+非聚焦者 |
| 67 | 1 | 0 | 1 | 0 | -1.52 (0.27) | -0.18 (0.11) | 0.10 (0.09) | 认知不流畅+聚焦者 |
| 76 | 1 | 1 | 1 | 0 | 0.56 (0.25) | -0.01 (0.11) | -0.12 (0.09) | 沉思型+非聚焦者 |

图6 模拟研究Q矩阵(K × I). 空白为“0”, 灰色为“1”, *表示I = 15测验条件下用题
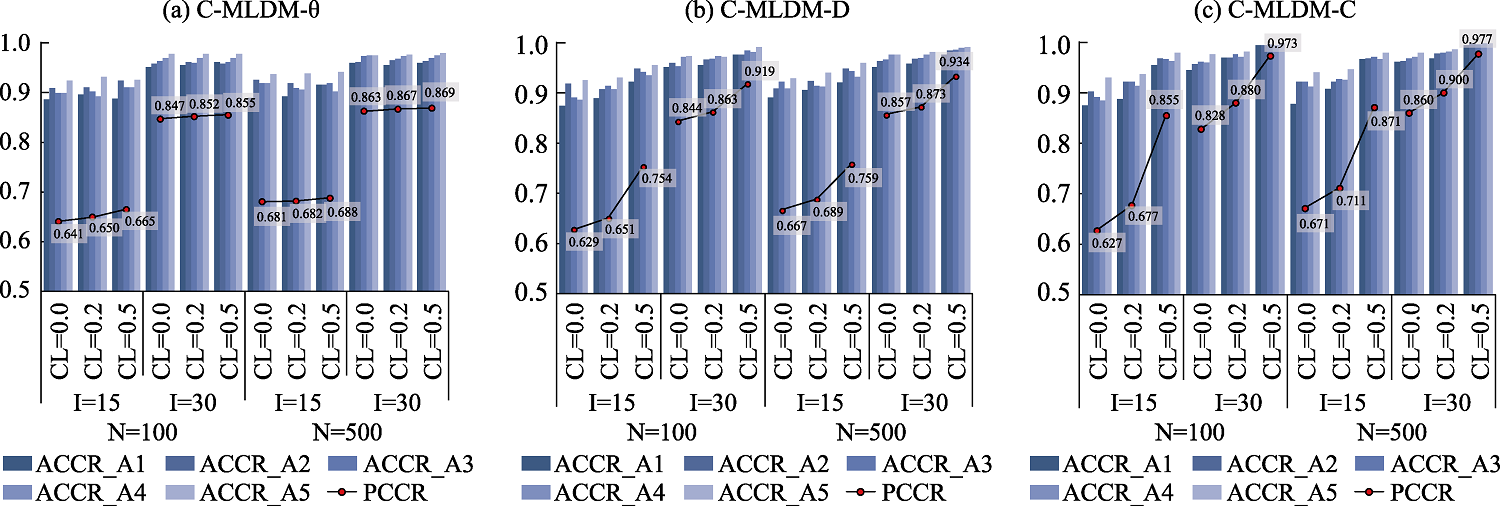
图7 模拟研究1中3个C-MCDM的属性(模式)判准率. 注: N = 样本量; I = 测验长度; CL = 交叉载荷; ACCR = 属性判准率; PCCR = 属性模式判准率.
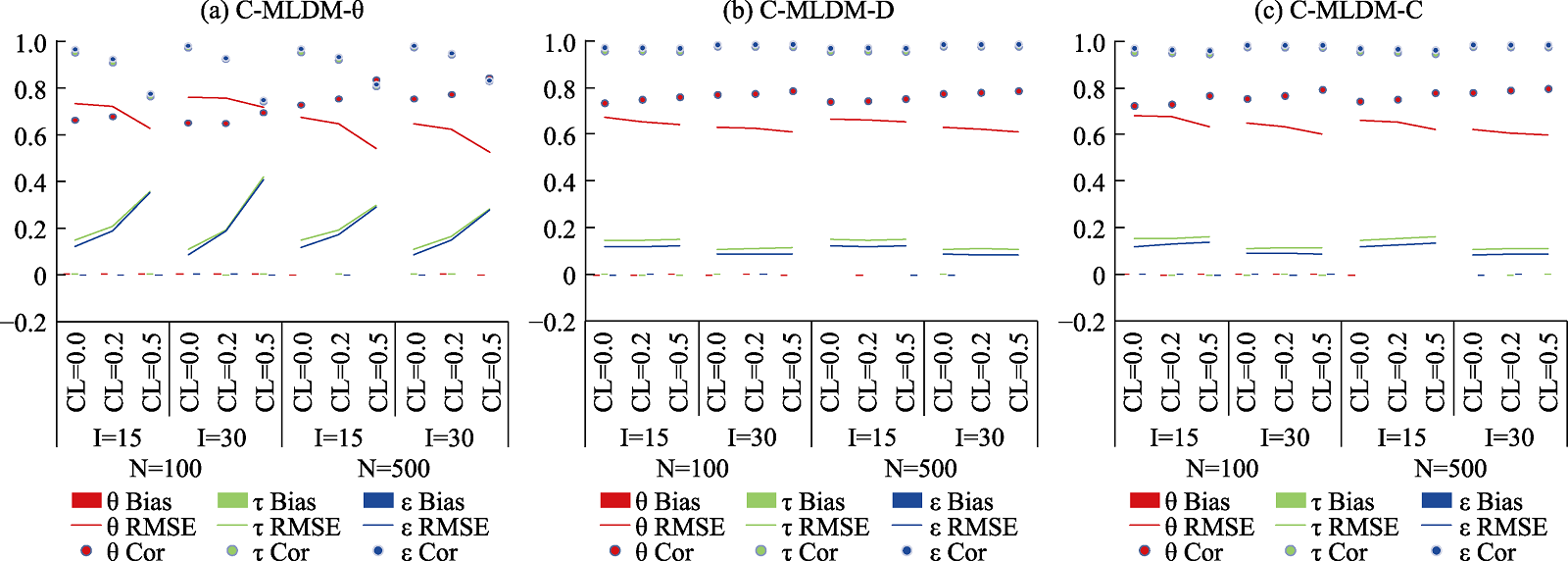
图8 模拟研究1中3个C-MCDM的潜在能力、潜在加工速度和潜在视觉参与度的参数估计返真性. 注: N = 样本量; I = 测验长度; CL = 交叉载荷; θ = 高阶潜在能力; τ = 潜在加工速度; ε = 潜在视觉参与度; Bias = 偏差; RMSE = 均方根误差; Cor = 估计值与真值的相关系数.
| 数据生成模型 | 数据分析模型 | DIC |
|---|---|---|
| C-MCDM-θ | H-MCDM | 186481.5 |
| C-MCDM-θ | 181029.5 | |
| C-MCDM-D | H-MCDM | 183774.8 |
| C-MCDM-D | 181720.3 | |
| C-MCDM-C | H-MCDM | 189775.6 |
| C-MCDM-C | 183881.5 | |
| H-MCDM | H-MCDM | 180286.2 |
| C-MCDM-θ | 180395.0 | |
| C-MCDM-D | 180347.8 | |
| C-MCDM-C | 180351.9 |
表6 模拟研究2中模型-数据拟合情况
| 数据生成模型 | 数据分析模型 | DIC |
|---|---|---|
| C-MCDM-θ | H-MCDM | 186481.5 |
| C-MCDM-θ | 181029.5 | |
| C-MCDM-D | H-MCDM | 183774.8 |
| C-MCDM-D | 181720.3 | |
| C-MCDM-C | H-MCDM | 189775.6 |
| C-MCDM-C | 183881.5 | |
| H-MCDM | H-MCDM | 180286.2 |
| C-MCDM-θ | 180395.0 | |
| C-MCDM-D | 180347.8 | |
| C-MCDM-C | 180351.9 |
| 数据生成模型 | 数据分析模型 | ACCR | PCCR | ||||
|---|---|---|---|---|---|---|---|
| A1 | A2 | A3 | A4 | A5 | |||
| C-MCDM-θ | H-MCDM | 0.957 | 0.966 | 0.967 | 0.975 | 0.977 | 0.862 |
| C-MCDM-θ | 0.961 | 0.969 | 0.969 | 0.977 | 0.979 | 0.874 | |
| C-MCDM-D | H-MCDM | 0.953 | 0.966 | 0.966 | 0.971 | 0.982 | 0.860 |
| C-MCDM-D | 0.960 | 0.970 | 0.984 | 0.980 | 0.987 | 0.894 | |
| C-MCDM-C | H-MCDM | 0.955 | 0.961 | 0.969 | 0.970 | 0.980 | 0.858 |
| C-MCDM-C | 0.991 | 0.990 | 0.988 | 0.990 | 0.995 | 0.958 | |
| H-MCDM | H-MCDM | 0.960 | 0.958 | 0.967 | 0.977 | 0.977 | 0.863 |
| C-MCDM-θ | 0.960 | 0.957 | 0.967 | 0.977 | 0.977 | 0.863 | |
| C-MCDM-D | 0.957 | 0.958 | 0.967 | 0.977 | 0.976 | 0.861 | |
| C-MCDM-C | 0.957 | 0.957 | 0.966 | 0.976 | 0.976 | 0.859 | |
表7 模拟研究2中潜在属性(模式)判准率.
| 数据生成模型 | 数据分析模型 | ACCR | PCCR | ||||
|---|---|---|---|---|---|---|---|
| A1 | A2 | A3 | A4 | A5 | |||
| C-MCDM-θ | H-MCDM | 0.957 | 0.966 | 0.967 | 0.975 | 0.977 | 0.862 |
| C-MCDM-θ | 0.961 | 0.969 | 0.969 | 0.977 | 0.979 | 0.874 | |
| C-MCDM-D | H-MCDM | 0.953 | 0.966 | 0.966 | 0.971 | 0.982 | 0.860 |
| C-MCDM-D | 0.960 | 0.970 | 0.984 | 0.980 | 0.987 | 0.894 | |
| C-MCDM-C | H-MCDM | 0.955 | 0.961 | 0.969 | 0.970 | 0.980 | 0.858 |
| C-MCDM-C | 0.991 | 0.990 | 0.988 | 0.990 | 0.995 | 0.958 | |
| H-MCDM | H-MCDM | 0.960 | 0.958 | 0.967 | 0.977 | 0.977 | 0.863 |
| C-MCDM-θ | 0.960 | 0.957 | 0.967 | 0.977 | 0.977 | 0.863 | |
| C-MCDM-D | 0.957 | 0.958 | 0.967 | 0.977 | 0.976 | 0.861 | |
| C-MCDM-C | 0.957 | 0.957 | 0.966 | 0.976 | 0.976 | 0.859 | |
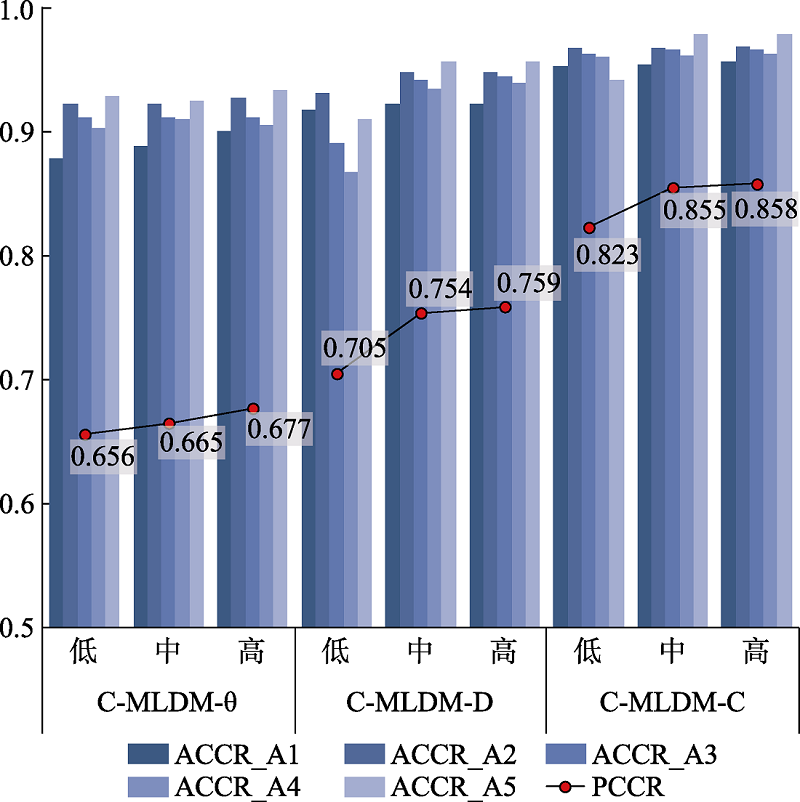
图S1 三模型在不同信息量先验分布下的属性(模式)判准率.

图S2 三模型在不同信息量先验分布下的潜在能力、潜在加工速度和潜在视觉参与度的返真性 注: N = 样本量; I = 测验长度; CL = 交叉载荷; θ = 高阶潜在能力; τ = 潜在加工速度; ε = 潜在视觉参与度; Bias = 偏差; RMSE = 均方根误差; Cor = 估计值与真值的相关系数.
| 模型 | 先验分布信息量 | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | ||
| C-MCDM-θ | 低 | 0.016 | 0.051 | 0.875 | 0.055 | 0.086 | 0.952 | -0.063 | 0.088 | 0.993 | -0.332 | 0.355 | 0.878 | -0.067 | 0.095 | 0.992 | 0.001 | 0.004 | 0.985 | -0.042 | 0.112 | 0.049 | 0.134 |
| 中 | 0.014 | 0.050 | 0.875 | 0.056 | 0.086 | 0.952 | 0.002 | 0.062 | 0.993 | -0.015 | 0.121 | 0.869 | 0.000 | 0.067 | 0.992 | 0.000 | 0.004 | 0.985 | 0.152 | 0.182 | -0.148 | 0.188 | |
| 高 | -0.010 | 0.046 | 0.882 | -0.022 | 0.078 | 0.954 | -0.002 | 0.061 | 0.993 | 0.003 | 0.100 | 0.890 | -0.003 | 0.065 | 0.992 | 0.000 | 0.003 | 0.985 | -0.023 | 0.100 | 0.026 | 0.108 | |
| C-MCDM-D | 低 | 0.021 | 0.049 | 0.914 | 0.084 | 0.127 | 0.930 | -0.113 | 0.257 | 0.913 | -0.233 | 0.258 | 0.822 | -0.123 | 0.227 | 0.912 | 0.000 | 0.003 | 0.982 | -0.066 | 0.218 | 0.085 | 0.195 |
| 中 | 0.014 | 0.045 | 0.923 | 0.033 | 0.069 | 0.959 | 0.005 | 0.086 | 0.986 | -0.013 | 0.124 | 0.825 | 0.009 | 0.073 | 0.989 | 0.000 | 0.003 | 0.982 | 0.029 | 0.152 | -0.023 | 0.132 | |
| 高 | -0.007 | 0.041 | 0.930 | -0.028 | 0.080 | 0.956 | -0.004 | 0.085 | 0.986 | 0.013 | 0.116 | 0.826 | 0.003 | 0.072 | 0.989 | 0.000 | 0.003 | 0.982 | -0.012 | 0.150 | 0.006 | 0.129 | |
| C-MCDM-C | 低 | 0.009 | 0.041 | 0.928 | 0.042 | 0.080 | 0.941 | -0.036 | 0.122 | 0.977 | -0.334 | 0.356 | 0.869 | -0.066 | 0.166 | 0.952 | 0.001 | 0.003 | 0.987 | 0.001 | 0.096 | 0.018 | 0.128 |
| 中 | 0.009 | 0.040 | 0.929 | 0.035 | 0.073 | 0.947 | 0.009 | 0.106 | 0.981 | -0.021 | 0.121 | 0.864 | -0.001 | 0.100 | 0.981 | 0.000 | 0.003 | 0.987 | 0.014 | 0.096 | -0.012 | 0.092 | |
| 高 | -0.009 | 0.040 | 0.931 | -0.024 | 0.073 | 0.949 | -0.003 | 0.103 | 0.981 | 0.004 | 0.103 | 0.874 | -0.011 | 0.098 | 0.981 | 0.000 | 0.003 | 0.987 | -0.006 | 0.095 | 0.004 | 0.091 | |
表S1 三模型在不同信息量先验分布下的题目参数返真性
| 模型 | 先验分布信息量 | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | ||
| C-MCDM-θ | 低 | 0.016 | 0.051 | 0.875 | 0.055 | 0.086 | 0.952 | -0.063 | 0.088 | 0.993 | -0.332 | 0.355 | 0.878 | -0.067 | 0.095 | 0.992 | 0.001 | 0.004 | 0.985 | -0.042 | 0.112 | 0.049 | 0.134 |
| 中 | 0.014 | 0.050 | 0.875 | 0.056 | 0.086 | 0.952 | 0.002 | 0.062 | 0.993 | -0.015 | 0.121 | 0.869 | 0.000 | 0.067 | 0.992 | 0.000 | 0.004 | 0.985 | 0.152 | 0.182 | -0.148 | 0.188 | |
| 高 | -0.010 | 0.046 | 0.882 | -0.022 | 0.078 | 0.954 | -0.002 | 0.061 | 0.993 | 0.003 | 0.100 | 0.890 | -0.003 | 0.065 | 0.992 | 0.000 | 0.003 | 0.985 | -0.023 | 0.100 | 0.026 | 0.108 | |
| C-MCDM-D | 低 | 0.021 | 0.049 | 0.914 | 0.084 | 0.127 | 0.930 | -0.113 | 0.257 | 0.913 | -0.233 | 0.258 | 0.822 | -0.123 | 0.227 | 0.912 | 0.000 | 0.003 | 0.982 | -0.066 | 0.218 | 0.085 | 0.195 |
| 中 | 0.014 | 0.045 | 0.923 | 0.033 | 0.069 | 0.959 | 0.005 | 0.086 | 0.986 | -0.013 | 0.124 | 0.825 | 0.009 | 0.073 | 0.989 | 0.000 | 0.003 | 0.982 | 0.029 | 0.152 | -0.023 | 0.132 | |
| 高 | -0.007 | 0.041 | 0.930 | -0.028 | 0.080 | 0.956 | -0.004 | 0.085 | 0.986 | 0.013 | 0.116 | 0.826 | 0.003 | 0.072 | 0.989 | 0.000 | 0.003 | 0.982 | -0.012 | 0.150 | 0.006 | 0.129 | |
| C-MCDM-C | 低 | 0.009 | 0.041 | 0.928 | 0.042 | 0.080 | 0.941 | -0.036 | 0.122 | 0.977 | -0.334 | 0.356 | 0.869 | -0.066 | 0.166 | 0.952 | 0.001 | 0.003 | 0.987 | 0.001 | 0.096 | 0.018 | 0.128 |
| 中 | 0.009 | 0.040 | 0.929 | 0.035 | 0.073 | 0.947 | 0.009 | 0.106 | 0.981 | -0.021 | 0.121 | 0.864 | -0.001 | 0.100 | 0.981 | 0.000 | 0.003 | 0.987 | 0.014 | 0.096 | -0.012 | 0.092 | |
| 高 | -0.009 | 0.040 | 0.931 | -0.024 | 0.073 | 0.949 | -0.003 | 0.103 | 0.981 | 0.004 | 0.103 | 0.874 | -0.011 | 0.098 | 0.981 | 0.000 | 0.003 | 0.987 | -0.006 | 0.095 | 0.004 | 0.091 | |
| N | I | CL | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | |||
| 100 | 15 | 0.0 | 0.013 | 0.054 | 0.852 | 0.047 | 0.080 | 0.950 | -0.001 | 0.066 | 0.992 | -0.010 | 0.118 | 0.868 | 0.001 | 0.058 | 0.993 | 0.000 | 0.004 | 0.987 | 0.003 | 0.104 | 0.012 | 0.106 |
| 0.2 | 0.016 | 0.050 | 0.894 | 0.046 | 0.084 | 0.937 | 0.002 | 0.064 | 0.992 | -0.015 | 0.127 | 0.857 | -0.006 | 0.065 | 0.992 | 0.001 | 0.004 | 0.984 | 0.032 | 0.111 | -0.036 | 0.112 | ||
| 0.5 | 0.014 | 0.050 | 0.875 | 0.056 | 0.086 | 0.952 | 0.002 | 0.062 | 0.993 | -0.015 | 0.121 | 0.869 | 0.000 | 0.067 | 0.992 | 0.000 | 0.004 | 0.985 | 0.152 | 0.182 | -0.148 | 0.188 | ||
| 30 | 0.0 | 0.008 | 0.043 | 0.927 | 0.031 | 0.065 | 0.960 | 0.000 | 0.064 | 0.992 | -0.008 | 0.116 | 0.878 | -0.004 | 0.062 | 0.993 | 0.000 | 0.004 | 0.984 | -0.013 | 0.130 | 0.003 | 0.126 | |
| 0.2 | 0.007 | 0.041 | 0.934 | 0.034 | 0.069 | 0.958 | -0.002 | 0.064 | 0.992 | -0.015 | 0.114 | 0.878 | -0.006 | 0.057 | 0.994 | 0.000 | 0.004 | 0.986 | 0.080 | 0.151 | -0.095 | 0.151 | ||
| 0.5 | 0.009 | 0.040 | 0.941 | 0.032 | 0.068 | 0.956 | 0.000 | 0.066 | 0.992 | -0.008 | 0.112 | 0.872 | 0.000 | 0.058 | 0.994 | 0.000 | 0.003 | 0.987 | 0.270 | 0.299 | -0.249 | 0.283 | ||
| 500 | 15 | 0.0 | 0.004 | 0.024 | 0.968 | 0.010 | 0.033 | 0.989 | 0.002 | 0.027 | 0.999 | 0.000 | 0.052 | 0.973 | 0.001 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | 0.004 | 0.043 | 0.004 | 0.043 |
| 0.2 | 0.002 | 0.025 | 0.970 | 0.008 | 0.031 | 0.989 | 0.001 | 0.029 | 0.998 | -0.002 | 0.053 | 0.969 | -0.001 | 0.026 | 0.999 | 0.000 | 0.002 | 0.997 | 0.010 | 0.046 | -0.010 | 0.044 | ||
| 0.5 | 0.003 | 0.025 | 0.965 | 0.013 | 0.035 | 0.988 | -0.002 | 0.029 | 0.998 | 0.000 | 0.052 | 0.970 | -0.001 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | 0.035 | 0.055 | -0.030 | 0.052 | ||
| 30 | 0.0 | 0.002 | 0.020 | 0.984 | 0.007 | 0.028 | 0.991 | 0.003 | 0.029 | 0.998 | -0.002 | 0.053 | 0.971 | 0.000 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | 0.000 | 0.042 | -0.004 | 0.038 | |
| 0.2 | 0.002 | 0.019 | 0.985 | 0.007 | 0.029 | 0.991 | 0.000 | 0.028 | 0.999 | 0.000 | 0.051 | 0.972 | -0.002 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | -0.001 | 0.042 | -0.004 | 0.045 | ||
| 0.5 | 0.003 | 0.019 | 0.986 | 0.006 | 0.027 | 0.991 | 0.000 | 0.029 | 0.998 | -0.004 | 0.054 | 0.970 | 0.001 | 0.028 | 0.999 | 0.000 | 0.002 | 0.997 | 0.040 | 0.057 | -0.037 | 0.054 | ||
表S2 模拟研究1中C-MCDM-θ模型的题目参数返真性
| N | I | CL | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | |||
| 100 | 15 | 0.0 | 0.013 | 0.054 | 0.852 | 0.047 | 0.080 | 0.950 | -0.001 | 0.066 | 0.992 | -0.010 | 0.118 | 0.868 | 0.001 | 0.058 | 0.993 | 0.000 | 0.004 | 0.987 | 0.003 | 0.104 | 0.012 | 0.106 |
| 0.2 | 0.016 | 0.050 | 0.894 | 0.046 | 0.084 | 0.937 | 0.002 | 0.064 | 0.992 | -0.015 | 0.127 | 0.857 | -0.006 | 0.065 | 0.992 | 0.001 | 0.004 | 0.984 | 0.032 | 0.111 | -0.036 | 0.112 | ||
| 0.5 | 0.014 | 0.050 | 0.875 | 0.056 | 0.086 | 0.952 | 0.002 | 0.062 | 0.993 | -0.015 | 0.121 | 0.869 | 0.000 | 0.067 | 0.992 | 0.000 | 0.004 | 0.985 | 0.152 | 0.182 | -0.148 | 0.188 | ||
| 30 | 0.0 | 0.008 | 0.043 | 0.927 | 0.031 | 0.065 | 0.960 | 0.000 | 0.064 | 0.992 | -0.008 | 0.116 | 0.878 | -0.004 | 0.062 | 0.993 | 0.000 | 0.004 | 0.984 | -0.013 | 0.130 | 0.003 | 0.126 | |
| 0.2 | 0.007 | 0.041 | 0.934 | 0.034 | 0.069 | 0.958 | -0.002 | 0.064 | 0.992 | -0.015 | 0.114 | 0.878 | -0.006 | 0.057 | 0.994 | 0.000 | 0.004 | 0.986 | 0.080 | 0.151 | -0.095 | 0.151 | ||
| 0.5 | 0.009 | 0.040 | 0.941 | 0.032 | 0.068 | 0.956 | 0.000 | 0.066 | 0.992 | -0.008 | 0.112 | 0.872 | 0.000 | 0.058 | 0.994 | 0.000 | 0.003 | 0.987 | 0.270 | 0.299 | -0.249 | 0.283 | ||
| 500 | 15 | 0.0 | 0.004 | 0.024 | 0.968 | 0.010 | 0.033 | 0.989 | 0.002 | 0.027 | 0.999 | 0.000 | 0.052 | 0.973 | 0.001 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | 0.004 | 0.043 | 0.004 | 0.043 |
| 0.2 | 0.002 | 0.025 | 0.970 | 0.008 | 0.031 | 0.989 | 0.001 | 0.029 | 0.998 | -0.002 | 0.053 | 0.969 | -0.001 | 0.026 | 0.999 | 0.000 | 0.002 | 0.997 | 0.010 | 0.046 | -0.010 | 0.044 | ||
| 0.5 | 0.003 | 0.025 | 0.965 | 0.013 | 0.035 | 0.988 | -0.002 | 0.029 | 0.998 | 0.000 | 0.052 | 0.970 | -0.001 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | 0.035 | 0.055 | -0.030 | 0.052 | ||
| 30 | 0.0 | 0.002 | 0.020 | 0.984 | 0.007 | 0.028 | 0.991 | 0.003 | 0.029 | 0.998 | -0.002 | 0.053 | 0.971 | 0.000 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | 0.000 | 0.042 | -0.004 | 0.038 | |
| 0.2 | 0.002 | 0.019 | 0.985 | 0.007 | 0.029 | 0.991 | 0.000 | 0.028 | 0.999 | 0.000 | 0.051 | 0.972 | -0.002 | 0.027 | 0.999 | 0.000 | 0.002 | 0.997 | -0.001 | 0.042 | -0.004 | 0.045 | ||
| 0.5 | 0.003 | 0.019 | 0.986 | 0.006 | 0.027 | 0.991 | 0.000 | 0.029 | 0.998 | -0.004 | 0.054 | 0.970 | 0.001 | 0.028 | 0.999 | 0.000 | 0.002 | 0.997 | 0.040 | 0.057 | -0.037 | 0.054 | ||
| N | I | CL | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | |||
| 100 | 15 | 0.0 | 0.016 | 0.051 | 0.894 | 0.037 | 0.077 | 0.948 | 0.001 | 0.084 | 0.985 | -0.021 | 0.122 | 0.854 | 0.000 | 0.078 | 0.988 | 0.000 | 0.004 | 0.986 | 0.012 | 0.151 | -0.002 | 0.148 |
| 0.2 | 0.019 | 0.051 | 0.883 | 0.040 | 0.077 | 0.940 | 0.001 | 0.083 | 0.987 | -0.014 | 0.118 | 0.870 | -0.001 | 0.083 | 0.986 | 0.000 | 0.004 | 0.984 | 0.025 | 0.149 | -0.018 | 0.150 | ||
| 0.5 | 0.014 | 0.045 | 0.923 | 0.033 | 0.069 | 0.959 | 0.005 | 0.086 | 0.986 | -0.013 | 0.124 | 0.825 | 0.009 | 0.073 | 0.989 | 0.000 | 0.003 | 0.982 | 0.029 | 0.152 | -0.023 | 0.132 | ||
| 30 | 0.0 | 0.013 | 0.044 | 0.925 | 0.031 | 0.068 | 0.954 | -0.001 | 0.080 | 0.987 | -0.020 | 0.114 | 0.871 | 0.000 | 0.075 | 0.988 | 0.000 | 0.004 | 0.987 | -0.007 | 0.140 | -0.001 | 0.135 | |
| 0.2 | 0.013 | 0.043 | 0.931 | 0.029 | 0.065 | 0.963 | 0.002 | 0.081 | 0.988 | -0.020 | 0.113 | 0.873 | 0.002 | 0.076 | 0.989 | 0.000 | 0.003 | 0.987 | 0.012 | 0.139 | -0.011 | 0.124 | ||
| 0.5 | 0.010 | 0.039 | 0.939 | 0.028 | 0.067 | 0.954 | 0.009 | 0.081 | 0.987 | -0.026 | 0.120 | 0.865 | 0.007 | 0.073 | 0.990 | 0.000 | 0.003 | 0.987 | 0.039 | 0.146 | -0.035 | 0.136 | ||
| 500 | 15 | 0.0 | 0.005 | 0.026 | 0.969 | 0.008 | 0.032 | 0.989 | 0.000 | 0.036 | 0.997 | -0.001 | 0.054 | 0.972 | -0.001 | 0.037 | 0.997 | 0.000 | 0.002 | 0.996 | -0.004 | 0.072 | 0.004 | 0.066 |
| 0.2 | 0.005 | 0.023 | 0.972 | 0.007 | 0.030 | 0.989 | 0.002 | 0.039 | 0.997 | -0.006 | 0.055 | 0.965 | 0.003 | 0.034 | 0.998 | 0.000 | 0.002 | 0.997 | 0.002 | 0.073 | -0.004 | 0.063 | ||
| 0.5 | 0.003 | 0.021 | 0.979 | 0.009 | 0.029 | 0.992 | 0.001 | 0.037 | 0.997 | -0.006 | 0.055 | 0.971 | 0.002 | 0.037 | 0.997 | 0.000 | 0.002 | 0.997 | 0.008 | 0.066 | -0.011 | 0.065 | ||
| 30 | 0.0 | 0.003 | 0.019 | 0.984 | 0.007 | 0.030 | 0.989 | 0.001 | 0.038 | 0.997 | -0.002 | 0.053 | 0.970 | 0.003 | 0.034 | 0.998 | 0.000 | 0.002 | 0.997 | 0.001 | 0.065 | -0.003 | 0.065 | |
| 0.2 | 0.002 | 0.019 | 0.984 | 0.007 | 0.028 | 0.992 | 0.003 | 0.037 | 0.997 | -0.002 | 0.054 | 0.970 | 0.002 | 0.035 | 0.998 | 0.000 | 0.002 | 0.997 | 0.007 | 0.064 | -0.007 | 0.060 | ||
| 0.5 | 0.001 | 0.018 | 0.987 | 0.006 | 0.027 | 0.991 | 0.001 | 0.037 | 0.997 | -0.002 | 0.053 | 0.972 | 0.002 | 0.035 | 0.998 | 0.000 | 0.001 | 0.997 | 0.006 | 0.064 | -0.007 | 0.058 | ||
表S3 模拟研究1中C-MCDM-D模型的题目参数返真性
| N | I | CL | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | |||
| 100 | 15 | 0.0 | 0.016 | 0.051 | 0.894 | 0.037 | 0.077 | 0.948 | 0.001 | 0.084 | 0.985 | -0.021 | 0.122 | 0.854 | 0.000 | 0.078 | 0.988 | 0.000 | 0.004 | 0.986 | 0.012 | 0.151 | -0.002 | 0.148 |
| 0.2 | 0.019 | 0.051 | 0.883 | 0.040 | 0.077 | 0.940 | 0.001 | 0.083 | 0.987 | -0.014 | 0.118 | 0.870 | -0.001 | 0.083 | 0.986 | 0.000 | 0.004 | 0.984 | 0.025 | 0.149 | -0.018 | 0.150 | ||
| 0.5 | 0.014 | 0.045 | 0.923 | 0.033 | 0.069 | 0.959 | 0.005 | 0.086 | 0.986 | -0.013 | 0.124 | 0.825 | 0.009 | 0.073 | 0.989 | 0.000 | 0.003 | 0.982 | 0.029 | 0.152 | -0.023 | 0.132 | ||
| 30 | 0.0 | 0.013 | 0.044 | 0.925 | 0.031 | 0.068 | 0.954 | -0.001 | 0.080 | 0.987 | -0.020 | 0.114 | 0.871 | 0.000 | 0.075 | 0.988 | 0.000 | 0.004 | 0.987 | -0.007 | 0.140 | -0.001 | 0.135 | |
| 0.2 | 0.013 | 0.043 | 0.931 | 0.029 | 0.065 | 0.963 | 0.002 | 0.081 | 0.988 | -0.020 | 0.113 | 0.873 | 0.002 | 0.076 | 0.989 | 0.000 | 0.003 | 0.987 | 0.012 | 0.139 | -0.011 | 0.124 | ||
| 0.5 | 0.010 | 0.039 | 0.939 | 0.028 | 0.067 | 0.954 | 0.009 | 0.081 | 0.987 | -0.026 | 0.120 | 0.865 | 0.007 | 0.073 | 0.990 | 0.000 | 0.003 | 0.987 | 0.039 | 0.146 | -0.035 | 0.136 | ||
| 500 | 15 | 0.0 | 0.005 | 0.026 | 0.969 | 0.008 | 0.032 | 0.989 | 0.000 | 0.036 | 0.997 | -0.001 | 0.054 | 0.972 | -0.001 | 0.037 | 0.997 | 0.000 | 0.002 | 0.996 | -0.004 | 0.072 | 0.004 | 0.066 |
| 0.2 | 0.005 | 0.023 | 0.972 | 0.007 | 0.030 | 0.989 | 0.002 | 0.039 | 0.997 | -0.006 | 0.055 | 0.965 | 0.003 | 0.034 | 0.998 | 0.000 | 0.002 | 0.997 | 0.002 | 0.073 | -0.004 | 0.063 | ||
| 0.5 | 0.003 | 0.021 | 0.979 | 0.009 | 0.029 | 0.992 | 0.001 | 0.037 | 0.997 | -0.006 | 0.055 | 0.971 | 0.002 | 0.037 | 0.997 | 0.000 | 0.002 | 0.997 | 0.008 | 0.066 | -0.011 | 0.065 | ||
| 30 | 0.0 | 0.003 | 0.019 | 0.984 | 0.007 | 0.030 | 0.989 | 0.001 | 0.038 | 0.997 | -0.002 | 0.053 | 0.970 | 0.003 | 0.034 | 0.998 | 0.000 | 0.002 | 0.997 | 0.001 | 0.065 | -0.003 | 0.065 | |
| 0.2 | 0.002 | 0.019 | 0.984 | 0.007 | 0.028 | 0.992 | 0.003 | 0.037 | 0.997 | -0.002 | 0.054 | 0.970 | 0.002 | 0.035 | 0.998 | 0.000 | 0.002 | 0.997 | 0.007 | 0.064 | -0.007 | 0.060 | ||
| 0.5 | 0.001 | 0.018 | 0.987 | 0.006 | 0.027 | 0.991 | 0.001 | 0.037 | 0.997 | -0.002 | 0.053 | 0.972 | 0.002 | 0.035 | 0.998 | 0.000 | 0.001 | 0.997 | 0.006 | 0.064 | -0.007 | 0.058 | ||
| N | I | CL | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | |||
| 100 | 15 | 0.0 | 0.015 | 0.049 | 0.894 | 0.054 | 0.089 | 0.948 | 0.003 | 0.119 | 0.974 | -0.008 | 0.119 | 0.858 | 0.010 | 0.109 | 0.977 | 0.000 | 0.004 | 0.987 | 0.005 | 0.112 | -0.007 | 0.106 |
| 0.2 | 0.014 | 0.046 | 0.916 | 0.045 | 0.079 | 0.951 | 0.001 | 0.119 | 0.974 | -0.029 | 0.120 | 0.837 | -0.007 | 0.113 | 0.976 | 0.000 | 0.003 | 0.987 | 0.009 | 0.108 | -0.008 | 0.112 | ||
| 0.5 | 0.009 | 0.040 | 0.929 | 0.035 | 0.073 | 0.947 | 0.009 | 0.106 | 0.981 | -0.021 | 0.121 | 0.864 | -0.001 | 0.100 | 0.981 | 0.000 | 0.003 | 0.987 | 0.014 | 0.096 | -0.012 | 0.188 | ||
| 30 | 0.0 | 0.009 | 0.043 | 0.921 | 0.034 | 0.069 | 0.952 | -0.007 | 0.108 | 0.977 | -0.018 | 0.112 | 0.880 | -0.010 | 0.101 | 0.980 | 0.000 | 0.004 | 0.987 | -0.006 | 0.096 | 0.006 | 0.126 | |
| 0.2 | 0.013 | 0.040 | 0.944 | 0.029 | 0.069 | 0.953 | 0.010 | 0.107 | 0.977 | -0.018 | 0.115 | 0.868 | 0.000 | 0.101 | 0.980 | 0.000 | 0.003 | 0.986 | 0.009 | 0.093 | 0.000 | 0.151 | ||
| 0.5 | 0.012 | 0.041 | 0.935 | 0.029 | 0.065 | 0.958 | 0.017 | 0.104 | 0.980 | -0.019 | 0.117 | 0.873 | 0.010 | 0.094 | 0.983 | 0.000 | 0.002 | 0.987 | 0.021 | 0.094 | -0.018 | 0.283 | ||
| 500 | 15 | 0.0 | 0.005 | 0.025 | 0.970 | 0.010 | 0.029 | 0.991 | -0.002 | 0.051 | 0.995 | -0.001 | 0.055 | 0.966 | -0.005 | 0.051 | 0.995 | 0.000 | 0.002 | 0.997 | -0.001 | 0.050 | 0.002 | 0.043 |
| 0.2 | 0.001 | 0.022 | 0.973 | 0.007 | 0.029 | 0.991 | 0.000 | 0.048 | 0.996 | -0.003 | 0.053 | 0.970 | 0.004 | 0.047 | 0.996 | 0.000 | 0.001 | 0.997 | -0.003 | 0.046 | -0.007 | 0.044 | ||
| 0.5 | 0.003 | 0.020 | 0.983 | 0.009 | 0.030 | 0.991 | 0.008 | 0.049 | 0.996 | -0.009 | 0.056 | 0.971 | 0.003 | 0.043 | 0.996 | 0.000 | 0.001 | 0.997 | 0.010 | 0.044 | -0.003 | 0.052 | ||
| 30 | 0.0 | 0.002 | 0.019 | 0.983 | 0.006 | 0.028 | 0.991 | -0.001 | 0.047 | 0.996 | -0.003 | 0.052 | 0.972 | 0.000 | 0.039 | 0.997 | 0.000 | 0.002 | 0.997 | 0.002 | 0.043 | 0.000 | 0.038 | |
| 0.2 | 0.002 | 0.018 | 0.987 | 0.006 | 0.027 | 0.991 | 0.004 | 0.047 | 0.996 | -0.005 | 0.054 | 0.971 | -0.001 | 0.043 | 0.996 | 0.000 | 0.001 | 0.997 | 0.006 | 0.041 | -0.001 | 0.045 | ||
| 0.5 | 0.002 | 0.018 | 0.988 | 0.006 | 0.027 | 0.991 | 0.001 | 0.048 | 0.996 | -0.006 | 0.055 | 0.969 | 0.006 | 0.044 | 0.996 | 0.000 | 0.001 | 0.998 | 0.001 | 0.042 | -0.006 | 0.054 | ||
表S4 模拟研究1中C-MCDM-C模型的题目参数返真性
| N | I | CL | g | s | ζ | ω | m | d | φ | λ | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Bias | RMSE | |||
| 100 | 15 | 0.0 | 0.015 | 0.049 | 0.894 | 0.054 | 0.089 | 0.948 | 0.003 | 0.119 | 0.974 | -0.008 | 0.119 | 0.858 | 0.010 | 0.109 | 0.977 | 0.000 | 0.004 | 0.987 | 0.005 | 0.112 | -0.007 | 0.106 |
| 0.2 | 0.014 | 0.046 | 0.916 | 0.045 | 0.079 | 0.951 | 0.001 | 0.119 | 0.974 | -0.029 | 0.120 | 0.837 | -0.007 | 0.113 | 0.976 | 0.000 | 0.003 | 0.987 | 0.009 | 0.108 | -0.008 | 0.112 | ||
| 0.5 | 0.009 | 0.040 | 0.929 | 0.035 | 0.073 | 0.947 | 0.009 | 0.106 | 0.981 | -0.021 | 0.121 | 0.864 | -0.001 | 0.100 | 0.981 | 0.000 | 0.003 | 0.987 | 0.014 | 0.096 | -0.012 | 0.188 | ||
| 30 | 0.0 | 0.009 | 0.043 | 0.921 | 0.034 | 0.069 | 0.952 | -0.007 | 0.108 | 0.977 | -0.018 | 0.112 | 0.880 | -0.010 | 0.101 | 0.980 | 0.000 | 0.004 | 0.987 | -0.006 | 0.096 | 0.006 | 0.126 | |
| 0.2 | 0.013 | 0.040 | 0.944 | 0.029 | 0.069 | 0.953 | 0.010 | 0.107 | 0.977 | -0.018 | 0.115 | 0.868 | 0.000 | 0.101 | 0.980 | 0.000 | 0.003 | 0.986 | 0.009 | 0.093 | 0.000 | 0.151 | ||
| 0.5 | 0.012 | 0.041 | 0.935 | 0.029 | 0.065 | 0.958 | 0.017 | 0.104 | 0.980 | -0.019 | 0.117 | 0.873 | 0.010 | 0.094 | 0.983 | 0.000 | 0.002 | 0.987 | 0.021 | 0.094 | -0.018 | 0.283 | ||
| 500 | 15 | 0.0 | 0.005 | 0.025 | 0.970 | 0.010 | 0.029 | 0.991 | -0.002 | 0.051 | 0.995 | -0.001 | 0.055 | 0.966 | -0.005 | 0.051 | 0.995 | 0.000 | 0.002 | 0.997 | -0.001 | 0.050 | 0.002 | 0.043 |
| 0.2 | 0.001 | 0.022 | 0.973 | 0.007 | 0.029 | 0.991 | 0.000 | 0.048 | 0.996 | -0.003 | 0.053 | 0.970 | 0.004 | 0.047 | 0.996 | 0.000 | 0.001 | 0.997 | -0.003 | 0.046 | -0.007 | 0.044 | ||
| 0.5 | 0.003 | 0.020 | 0.983 | 0.009 | 0.030 | 0.991 | 0.008 | 0.049 | 0.996 | -0.009 | 0.056 | 0.971 | 0.003 | 0.043 | 0.996 | 0.000 | 0.001 | 0.997 | 0.010 | 0.044 | -0.003 | 0.052 | ||
| 30 | 0.0 | 0.002 | 0.019 | 0.983 | 0.006 | 0.028 | 0.991 | -0.001 | 0.047 | 0.996 | -0.003 | 0.052 | 0.972 | 0.000 | 0.039 | 0.997 | 0.000 | 0.002 | 0.997 | 0.002 | 0.043 | 0.000 | 0.038 | |
| 0.2 | 0.002 | 0.018 | 0.987 | 0.006 | 0.027 | 0.991 | 0.004 | 0.047 | 0.996 | -0.005 | 0.054 | 0.971 | -0.001 | 0.043 | 0.996 | 0.000 | 0.001 | 0.997 | 0.006 | 0.041 | -0.001 | 0.045 | ||
| 0.5 | 0.002 | 0.018 | 0.988 | 0.006 | 0.027 | 0.991 | 0.001 | 0.048 | 0.996 | -0.006 | 0.055 | 0.969 | 0.006 | 0.044 | 0.996 | 0.000 | 0.001 | 0.998 | 0.001 | 0.042 | -0.006 | 0.054 | ||
| 数据生成模型 | 数据分析模型 | θ | τ | ε | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | ||
| C-MCDM-θ | H-MCDM | 0.001 | 0.600 | 0.796 | -0.001 | 0.137 | 0.961 | 0.001 | 0.217 | 0.912 |
| C-MCDM-θ | 0.001 | 0.239 | 0.972 | -0.001 | 0.109 | 0.976 | 0.001 | 0.098 | 0.980 | |
| C-MCDM-D | H-MCDM | 0.001 | 0.625 | 0.775 | 0.000 | 0.110 | 0.975 | 0.000 | 0.104 | 0.978 |
| C-MCDM-D | 0.000 | 0.614 | 0.784 | 0.001 | 0.108 | 0.976 | -0.002 | 0.083 | 0.986 | |
| C-MCDM-C | H-MCDM | 0.000 | 0.625 | 0.775 | -0.001 | 0.134 | 0.963 | 0.000 | 0.113 | 0.974 |
| C-MCDM-C | 0.000 | 0.601 | 0.795 | 0.001 | 0.108 | 0.976 | -0.001 | 0.087 | 0.984 | |
| H-MCDM | H-MCDM | 0.000 | 0.571 | 0.817 | 0.000 | 0.108 | 0.976 | 0.000 | 0.082 | 0.986 |
| C-MCDM-θ | -0.001 | 0.589 | 0.805 | 0.001 | 0.214 | 0.907 | 0.000 | 0.204 | 0.916 | |
| C-MCDM-D | 0.000 | 0.622 | 0.778 | 0.001 | 0.109 | 0.976 | -0.001 | 0.082 | 0.986 | |
| C-MCDM-C | 0.000 | 0.622 | 0.779 | 0.000 | 0.110 | 0.975 | 0.000 | 0.083 | 0.986 | |
表S5 模拟研究2中潜在能力、潜在加工速度和潜在视觉参与度的参数估计返真性.
| 数据生成模型 | 数据分析模型 | θ | τ | ε | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | ||
| C-MCDM-θ | H-MCDM | 0.001 | 0.600 | 0.796 | -0.001 | 0.137 | 0.961 | 0.001 | 0.217 | 0.912 |
| C-MCDM-θ | 0.001 | 0.239 | 0.972 | -0.001 | 0.109 | 0.976 | 0.001 | 0.098 | 0.980 | |
| C-MCDM-D | H-MCDM | 0.001 | 0.625 | 0.775 | 0.000 | 0.110 | 0.975 | 0.000 | 0.104 | 0.978 |
| C-MCDM-D | 0.000 | 0.614 | 0.784 | 0.001 | 0.108 | 0.976 | -0.002 | 0.083 | 0.986 | |
| C-MCDM-C | H-MCDM | 0.000 | 0.625 | 0.775 | -0.001 | 0.134 | 0.963 | 0.000 | 0.113 | 0.974 |
| C-MCDM-C | 0.000 | 0.601 | 0.795 | 0.001 | 0.108 | 0.976 | -0.001 | 0.087 | 0.984 | |
| H-MCDM | H-MCDM | 0.000 | 0.571 | 0.817 | 0.000 | 0.108 | 0.976 | 0.000 | 0.082 | 0.986 |
| C-MCDM-θ | -0.001 | 0.589 | 0.805 | 0.001 | 0.214 | 0.907 | 0.000 | 0.204 | 0.916 | |
| C-MCDM-D | 0.000 | 0.622 | 0.778 | 0.001 | 0.109 | 0.976 | -0.001 | 0.082 | 0.986 | |
| C-MCDM-C | 0.000 | 0.622 | 0.779 | 0.000 | 0.110 | 0.975 | 0.000 | 0.083 | 0.986 | |
| 数据生成 模型 | 数据分析 模型 | g | s | ζ | m | ω | d | fai | lamda | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | ||
| C-MLDM-θ | H-MLDM | 0.003 | 0.019 | 0.986 | 0.004 | 0.027 | 0.992 | 0.000 | 0.028 | 0.998 | 0.032 | 0.047 | 0.995 | -0.145 | 0.170 | 0.683 | -0.004 | 0.007 | 0.952 | ||||||
| C-MLDM-θ | 0.003 | 0.019 | 0.986 | 0.004 | 0.027 | 0.992 | 0.000 | 0.028 | 0.998 | -0.001 | 0.026 | 0.999 | -0.007 | 0.053 | 0.970 | 0.000 | 0.002 | 0.997 | 0.003 | 0.035 | 0.996 | 0.002 | 0.032 | 0.995 | |
| C-MLDM-D | H-MLDM | 0.002 | 0.019 | 0.984 | 0.006 | 0.027 | 0.991 | 0.020 | 0.072 | 0.988 | 0.056 | 0.108 | 0.968 | -0.028 | 0.065 | 0.958 | -0.002 | 0.004 | 0.981 | ||||||
| C-MLDM-D | 0.002 | 0.019 | 0.984 | 0.005 | 0.027 | 0.991 | 0.002 | 0.036 | 0.997 | 0.001 | 0.036 | 0.997 | -0.004 | 0.054 | 0.971 | 0.000 | 0.002 | 0.997 | 0.003 | 0.062 | 0.969 | 0.004 | 0.062 | 0.982 | |
| C-MLDM-C | H-MLDM | 0.003 | 0.020 | 0.984 | 0.005 | 0.028 | 0.991 | 0.139 | 0.292 | 0.821 | 0.138 | 0.281 | 0.789 | -0.120 | 0.148 | 0.763 | -0.003 | 0.006 | 0.967 | ||||||
| C-MLDM-C | 0.003 | 0.019 | 0.985 | 0.004 | 0.027 | 0.992 | 0.004 | 0.048 | 0.996 | 0.003 | 0.045 | 0.996 | -0.001 | 0.054 | 0.970 | 0.000 | 0.002 | 0.997 | 0.003 | 0.041 | 0.994 | -0.003 | 0.039 | 0.992 | |
| H-MLDM | H-MLDM | 0.003 | 0.021 | 0.983 | 0.007 | 0.028 | 0.991 | 0.000 | 0.028 | 0.998 | -0.002 | 0.028 | 0.999 | -0.002 | 0.052 | 0.972 | 0.000 | 0.002 | 0.998 | ||||||
| C-MLDM-θ | 0.003 | 0.021 | 0.983 | 0.007 | 0.028 | 0.991 | 0.000 | 0.028 | 0.998 | -0.002 | 0.028 | 0.999 | -0.001 | 0.052 | 0.972 | 0.000 | 0.002 | 0.997 | |||||||
| C-MLDM-D | 0.003 | 0.021 | 0.982 | 0.007 | 0.028 | 0.991 | -0.006 | 0.037 | 0.997 | -0.005 | 0.037 | 0.997 | -0.002 | 0.052 | 0.972 | 0.000 | 0.002 | 0.998 | |||||||
| C-MLDM-C | 0.003 | 0.021 | 0.982 | 0.007 | 0.028 | 0.991 | -0.018 | 0.051 | 0.996 | -0.012 | 0.048 | 0.996 | -0.002 | 0.052 | 0.972 | 0.000 | 0.002 | 0.998 | |||||||
表S6 模拟研究2中题目参数返真性
| 数据生成 模型 | 数据分析 模型 | g | s | ζ | m | ω | d | fai | lamda | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | Bias | RMSE | Cor | ||
| C-MLDM-θ | H-MLDM | 0.003 | 0.019 | 0.986 | 0.004 | 0.027 | 0.992 | 0.000 | 0.028 | 0.998 | 0.032 | 0.047 | 0.995 | -0.145 | 0.170 | 0.683 | -0.004 | 0.007 | 0.952 | ||||||
| C-MLDM-θ | 0.003 | 0.019 | 0.986 | 0.004 | 0.027 | 0.992 | 0.000 | 0.028 | 0.998 | -0.001 | 0.026 | 0.999 | -0.007 | 0.053 | 0.970 | 0.000 | 0.002 | 0.997 | 0.003 | 0.035 | 0.996 | 0.002 | 0.032 | 0.995 | |
| C-MLDM-D | H-MLDM | 0.002 | 0.019 | 0.984 | 0.006 | 0.027 | 0.991 | 0.020 | 0.072 | 0.988 | 0.056 | 0.108 | 0.968 | -0.028 | 0.065 | 0.958 | -0.002 | 0.004 | 0.981 | ||||||
| C-MLDM-D | 0.002 | 0.019 | 0.984 | 0.005 | 0.027 | 0.991 | 0.002 | 0.036 | 0.997 | 0.001 | 0.036 | 0.997 | -0.004 | 0.054 | 0.971 | 0.000 | 0.002 | 0.997 | 0.003 | 0.062 | 0.969 | 0.004 | 0.062 | 0.982 | |
| C-MLDM-C | H-MLDM | 0.003 | 0.020 | 0.984 | 0.005 | 0.028 | 0.991 | 0.139 | 0.292 | 0.821 | 0.138 | 0.281 | 0.789 | -0.120 | 0.148 | 0.763 | -0.003 | 0.006 | 0.967 | ||||||
| C-MLDM-C | 0.003 | 0.019 | 0.985 | 0.004 | 0.027 | 0.992 | 0.004 | 0.048 | 0.996 | 0.003 | 0.045 | 0.996 | -0.001 | 0.054 | 0.970 | 0.000 | 0.002 | 0.997 | 0.003 | 0.041 | 0.994 | -0.003 | 0.039 | 0.992 | |
| H-MLDM | H-MLDM | 0.003 | 0.021 | 0.983 | 0.007 | 0.028 | 0.991 | 0.000 | 0.028 | 0.998 | -0.002 | 0.028 | 0.999 | -0.002 | 0.052 | 0.972 | 0.000 | 0.002 | 0.998 | ||||||
| C-MLDM-θ | 0.003 | 0.021 | 0.983 | 0.007 | 0.028 | 0.991 | 0.000 | 0.028 | 0.998 | -0.002 | 0.028 | 0.999 | -0.001 | 0.052 | 0.972 | 0.000 | 0.002 | 0.997 | |||||||
| C-MLDM-D | 0.003 | 0.021 | 0.982 | 0.007 | 0.028 | 0.991 | -0.006 | 0.037 | 0.997 | -0.005 | 0.037 | 0.997 | -0.002 | 0.052 | 0.972 | 0.000 | 0.002 | 0.998 | |||||||
| C-MLDM-C | 0.003 | 0.021 | 0.982 | 0.007 | 0.028 | 0.991 | -0.018 | 0.051 | 0.996 | -0.012 | 0.048 | 0.996 | -0.002 | 0.052 | 0.972 | 0.000 | 0.002 | 0.998 | |||||||
| [1] |
An, L., Wang, Y., & Sun, Y. (2017). Reading words or pictures: Eye movement patterns in adults and children differ by age group and receptive language ability. Frontiers in Psychology, 8, 791. https://doi.org/10.3389/fpsyg.2017.00791
doi: 10.3389/fpsyg.2017.00791 URL pmid: 28588526 |
| [2] |
Bezirhan, U., von Davier, M., & Grabovsky, I. (2021). Modeling item revisit behavior: The hierarchical speed-accuracy-revisits model. Educational and Psychological Measurement, 81(2), 363-387.
doi: 10.1177/0013164420950556 URL |
| [3] | Biancarosa, G., & Shanley, L. (2015). What is fluency? In K. D. Cummings & Y. Petscher (Eds.), The fluency construct: Curriculum-based measurement concepts and applications (pp. 1-18). Springer. |
| [4] |
Bolsinova, M., de Boeck, P., & Tijmstra, J. (2017). Modelling conditional dependence between response time and accuracy. Psychometrika, 82, 112-1148. https://doi.org/10.1007/s11336-016-9537-6
doi: 10.1007/s11336-016-9536-7 URL |
| [5] |
Bolsinova, M., & Tijmstra, J. (2018). Improving precision of ability estimation: Getting more from response times. British Journal of Mathematical and Statistical Psychology, 71(1), 13-38.
doi: 10.1111/bmsp.12104 URL |
| [6] | Bos, W., Lankes, E.-M., Prenzel, M., Schwippert, K., Valtin, R., & Walther, G. (Eds). (2005). IGLU: Vertiefende Analysen zu Leseverständnis, Rahmenbedingungen und Zusatzstudien [IGLU: Supplementary in-depth analyses of reading comprehension, context effects, and additional studies]. Münster: Waxmann. |
| [7] | Brooks, S. P., & Gelman, A. (1998). General methods for monitoring convergence of iterative simulations. Journal of Computational and Graphical Statistics, 7(4), 434-455. https://doi.org/10.2307/1390675 |
| [8] |
de Boeck, P., & Jeon, M. (2019). An overview of models for response times and processes in cognitive tests. Frontiers in Psychology, 10, 102.
doi: 10.3389/fpsyg.2019.00102 pmid: 30787891 |
| [9] |
de la Torre, J. (2011). The generalized DINA model framework. Psychometrika, 76, 179-199.
doi: 10.1007/s11336-011-9207-7 URL |
| [10] |
de la Torre, J., & Douglas, J. A. (2004). Higher-order latent trait models for cognitive diagnosis. Psychometrika, 69(3), 333-353. https://doi.org/10.1007/BF02295640
doi: 10.1007/BF02295640 URL |
| [11] | Gardner, R. W., Holzman, P. S., Klein, G. S., Linton, H. B., & Spence, D. (1959). Cognitive control: A study of individual consistencies in cognitive behavior. Psychological Issues, 1, Monograph 4. |
| [12] | Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2014). Bayesian data analysis. Boca Raton: CRC Press. |
| [13] | Gu, Y., & Xu, G. (2021). Sufficient and necessary conditions for the identifiability of the Q-matrix. Statistica Sinica, 31, 449-472. |
| [14] |
Guo, L. Shang, P., & Xia, L. (2017). Advantages and illustrations of application of response time model in psychological and educational testing. Advances in Psychological Science, 25(4), 701-712.
doi: 10.3724/SP.J.1042.2017.00701 URL |
| [郭磊, 尚鹏丽, 夏凌翔. (2017). 心理与教育测验中反应时模型应用的优势与举例. 心理科学进展, 25(4), 701-712.] | |
| [15] |
Holzman, P. S. (1966). Scanning: A principle of reality contact. Perceptual and Motor Skills, 23, 835-844.
doi: 10.2466/pms.1966.23.3.835 URL |
| [16] |
Jeon, M., de Boeck, P., Luo, J., Li, X., & Lu, Z.-L. (2021). Modeling within-item dependencies in parallel data on test responses and brain activation. Psychometrika, 86(1), 239-271. https://doi.org/10.1007/s11336-020-09741-2
doi: 10.1007/s11336-020-09741-2 URL pmid: 33486707 |
| [17] |
Junker, B. W., & Sijtsma, K. (2001). Cognitive assessment models with few assumptions, and connections with nonparametric item response theory. Applied Psychological Measurement, 25(3), 258-272.
doi: 10.1177/01466210122032064 URL |
| [18] |
Kagan, J. (1965). Reflection-impulsivity and reading ability in primary grade children. Child Development, 36(3), 609-628.
doi: 10.2307/1126908 URL |
| [19] |
Lahat, D., Adali, T., & Jutten, C. (2015). Multimodal data fusion: An overview of methods, challenges, and prospects. Proceedings of the IEEE, 103(9), 1449-1477.
doi: 10.1109/JPROC.2015.2460697 URL |
| [20] | Levy, R., & Mislevy, R. J. (2016). Bayesian psychometric modeling. Boca Raton, FL: CRC Press. |
| [21] |
Li, M., Liu, Y., & Liu, H. (2020). Analysis of the problem- solving strategies in computer-based dynamic assessment: The extension and application of multilevel mixture IRT model. Acta Psychologica Sinica, 52(4), 528-540.
doi: 10.3724/SP.J.1041.2020.00528 URL |
| [李美娟, 刘玥, 刘红云. (2020). 计算机动态测验中问题解决过程策略的分析: 多水平混合IRT模型的拓展与应用. 心理学报, 52(4), 528-540.] | |
| [22] |
Liu, H., Liu, Y., & Li, M. (2018). Analysis of process data of PISA 2012 computer-based problem solving: Application of the modified multilevel mixture IRT model. Frontiers in Psychology, 9, 1372.
doi: 10.3389/fpsyg.2018.01372 pmid: 30123171 |
| [23] |
Liu, Y., Xu, H., Chen, Q., & Zhan, P. (2022). The measurement of problem-solving competence using process data. Advances in Psychological Science, 30(3), 522-525.
doi: 10.3724/SP.J.1042.2022.00522 URL |
| [刘耀辉, 徐慧颖, 陈琦鹏, 詹沛达. (2022). 基于过程数据的问题解决能力测量及数据分析方法. 心理科学进展, 30(3), 522-525.] | |
| [24] |
Ma, W., & de la Torre, J. (2016). A sequential cognitive diagnosis model for polytomous responses. British Journal of Mathematical and Statistical Psychology, 69(3), 253-275.
doi: 10.1111/bmsp.12070 URL |
| [25] |
Ma, W., & Guo, W. (2019). Cognitive diagnosis models for multiple strategies. British Journal of Mathematical and Statistical Psychology, 72(2), 370-392.
doi: 10.1111/bmsp.12155 |
| [26] |
Man, K., & Harring, J. R. (2019). Negative binomial models for visual fixation counts on test items. Educational and Psychological Measurement, 79(4), 617-635. http://doi. org/0.1177/0013164418824148
doi: 10.1177/0013164418824148 pmid: 32655176 |
| [27] |
Man, K., & Harring, J. R. (2020). Assessing preknowledge cheating via innovative measures: A multiple-group analysis of jointly modeling item responses, response times, and visual fixation counts. Educational and Psychological Measurement, 81(3), 441-465. https://doi.org/10.1177/0013164420968630
doi: 10.1177/0013164420968630 URL |
| [28] | Messick, S. (1989). Cognitive style and personality: Scanning and orientation toward affect. ETS Research Report Series, RR-89-16. https://doi.org/10.1002/j.2330-8516.1989.tb00342.x |
| [29] |
Molenaar, D., Tuerlinckx, F., & van der Maas, H. L. (2015). A bivariate generalized linear item response theory modeling Framework to the Analysis of Responses and Response Times. Multivariate Behavioral Research, 50(1), 56-74.
doi: 10.1080/00273171.2014.962684 pmid: 26609743 |
| [30] | Plummer, M. (2015). Jags: Just another Gibbs sampler (version 4.0.0). Retrieved from http://mcmc-jags.sourceforge.net/ |
| [31] | Poole, A., Ball, L. J., & Phillips, P. (2004). In search of salience:A response-time and eye-movement analysis of bookmark recognition. In S. Fincher, P. Markopoulos, D. Moore, & R. Ruddle (Eds.), People and computers xviii: Design for life (pp. 363-378). London, England: Springer. |
| [32] |
Ranger, J. (2013). A note on the hierarchical model for responses and response times in tests of van der Linden (2007). Psychometrika, 78(3), 538-544.
doi: 10.1007/s11336-013-9324-6 pmid: 25106399 |
| [33] |
Ren, H., Xu, N., Lin, Y., Zhang, S., & Yang, T. (2021). Remedial teaching and learning from a cognitive diagnostic model perspective: Taking the data distribution characteristics as an example. Frontiers in Psychology, 12, 628607. https://doi.org/10.3389/fpsyg.2021.628607
doi: 10.3389/fpsyg.2021.628607 URL |
| [34] |
Riding, R. J. (1997). On the nature of cognitive style. Educational Psychology, 17(1-2), 29-49.
doi: 10.1080/0144341970170102 URL |
| [35] | Rimawi, O., Al-Halabiyah, F., & Hussein, O. (2020). The cognitive style (focusing-scanning) among Al-Quds University students. International Journal of Humanities and Cultural Studies, 7(1), 143-154. |
| [36] | Rupp, A. A., Templin, J. L., & Henson, R. (2010). Diagnostic measurement: Theory, methods, and applications. New York: Guilford Press. |
| [37] | Schaeffer, G. A., Reese, C. M., Steffen, M., McKinley, R. L., & Mills, C. N. (1993). Field test of a computer-based GRE general test (ETS Research report No. 93-07). Princeton, NJ: Educational Testing Service. |
| [38] | Tang, F., & Zhan, P. (2021). Does diagnostic feedback promote learning? Evidence from a longitudinal cognitive diagnostic assessment. AERA Open, 7. https://doi.org/10.1177/ 23328584211060804 |
| [39] |
Unkelbach, C. (2006). The learned interpretation of cognitive fluency. Psychological Science, 17(4), 339-345.
pmid: 16623692 |
| [40] |
van der Linden, W. J. (2006). A lognormal model for response times on test items. Journal of Educational and Behavioral Statistics, 31(2), 181-204.
doi: 10.3102/10769986031002181 URL |
| [41] |
van der Linden, W. J. (2007). A hierarchical framework for modeling speed and accuracy on test items. Psychometrika, 72(3), 287-308.
doi: 10.1007/s11336-006-1478-z URL |
| [42] | von Davier, M., & Lee, Y.-S. (2019). Handbook of diagnostic classification models: Models and model extensions, applications, software packages. New York, NY: Springer. |
| [43] | Wang, L., Tang, F., & Zhan, P. (2020). Effect analysis of individualized remedial teaching based on cognitive diagnostic assessment: Taking “linear equation with one unknown” as an example. Journal of Psychological Science, 43(6), 1490-1497. |
| [王立君, 唐芳, 詹沛达. (2020). 基于认知诊断测评的个性化补救教学效果分析: 以“一元一次方程”为例. 心理科学, 43(6), 1490-1497.] | |
| [44] |
Wang, S., & Chen, Y. (2020). Using response times and response accuracy to measure fluency within cognitive diagnosis models. Psychometrika, 85(2), 600-629.
doi: 10.1007/s11336-020-09717-2 URL |
| [45] |
Wang, W. C., & Qiu, X. L. (2019). Multilevel modeling of cognitive diagnostic assessment: The multilevel DINA example. Applied Psychological Measurement, 43(1), 34-50.
doi: 10.1177/0146621618765713 URL |
| [46] |
Wise, S. L., & Kong, X. (2005). Response time effort: A new measure of examinee motivation in computer-based tests. Applied Measurement in Education, 18(2), 163-183
doi: 10.1207/s15324818ame1802_2 URL |
| [47] | Zhan, P. (2018). Bayesian cognitive diagnosis modeling incorporating time information: joint analysis of response times and response accuracy data (Unpublished doctoral dissertation). Beijing Normal University. |
| [詹沛达. (2018). 引入时间信息的贝叶斯认知诊断建模: 对作答时间和作答精度数据的联合分析 (博士学位论文). 北京师范大学.] | |
| [48] | Zhan, P. (2019). Joint modeling for response times and response accuracy in computer-based multidimensional assessments. Journal of Psychological Science, 42(1), 170-178. |
| [詹沛达. (2019). 计算机化多维测验中作答时间和作答精度数据的联合分析. 心理科学, 42(1), 170-178.] | |
| [49] |
Zhan, P. (2020). A Markov estimation strategy for longitudinal learning diagnosis: Providing timely diagnostic feedback. Educational and Psychological Measurement, 80(6), 1145-1167. https://doi.org/10.1177/0013164420912318
doi: 10.1177/0013164420912318 URL pmid: 33116330 |
| [50] |
Zhan, P., Jiao, H., & Liao, D. (2018). Cognitive diagnosis modelling incorporating item response times. British Journal of Mathematical and Statistical Psychology, 71(2), 262-286.
doi: 10.1111/bmsp.12114 URL |
| [51] | Zhan, P., Jiao, H., Man, K, & Wang, L. (2019). Using JAGS for Bayesian cognitive diagnosis modeling: A tutorial. Journal of Educational and Behavioral Statistics, 44(4), 473-503. |
| [52] |
Zhan, P., Liao, M., & Bian, Y. (2018). Joint testlet cognitive diagnosis modeling for paired local item dependence in response times and response accuracy. Frontiers in Psychology, 9, 607.
doi: 10.3389/fpsyg.2018.00607 pmid: 29922192 |
| [53] | Zhan, P., Man, K., Wind, S. A., & Malone, J. (2022). Cognitive diagnosis modeling incorporating response times and fixation counts: Providing comprehensive feedback and accurate diagnosis. Journal of Educational and Behavioral Statistics. https://doi.org/10.3102/10769986221111085 |
| [54] | Zhan, P., & Qiao, X. (2022). Diagnostic Classification analysis of problem-solving competence using process data: An item expansion method. Psychometrika. https://doi.org/10.1007/s11336-022-09855-9 |
| [55] | Zheng, T., Zhou, W., & Guo, L. (in press). Cognitive diagnosis modelling based on response times. Journal of Psychological Science. |
| [郑天鹏, 周文杰, 郭磊. (in press). 基于题目作答时间信息的认知诊断模型. 心理科学.] | |
| [56] | Zoanetti, N. (2010). Interactive computer based assessment tasks: How problem-solving process data can inform instruction. Australasian Journal of Educational Technology, 26(5), 585-606. |
| [1] | 张琪, 王紫乐, 吴美君. 知觉学习中非显著性刺激视觉加工的学习机制[J]. 心理学报, 2024, 56(6): 689-700. |
| [2] | 谭青蓉, 蔡艳, 汪大勋, 罗芬, 涂冬波. CD-CAT中基于SCAD惩罚和EM视角的在线标定方法开发——G-DINA模型[J]. 心理学报, 2024, 56(5): 670-688. |
| [3] | 郭磊, 秦海江. 基于信号检测论的认知诊断评估:构建与应用[J]. 心理学报, 2024, 56(3): 339-351. |
| [4] | 梁菲菲, 刘瑛, 贺斐, 冯琳琳, 王峥, 白学军. 中文阅读伴随词汇学习中的视觉复杂性效应:基于笔画数和词长的证据[J]. 心理学报, 2024, 56(12): 1734-1750. |
| [5] | 杨周, 朱嘉雯, 苏琳, 熊明洁. 对疼痛线索的晚期注视偏向预测慢性疼痛的维持:来自眼动的证据[J]. 心理学报, 2024, 56(1): 44-60. |
| [6] | 田亚淑, 詹沛达, 王立君. 联合作答精度和作答时间的概率态认知诊断模型[J]. 心理学报, 2023, 55(9): 1573-1586. |
| [7] | 游晓锋, 杨建芹, 秦春影, 刘红云. 认知诊断测评中缺失数据的处理:随机森林阈值插补法[J]. 心理学报, 2023, 55(7): 1192-1206. |
| [8] | 龙翼婷, 姜英杰, 崔璨, 岳阳. 奖赏预测误差对项目和联结记忆影响的分离:元记忆的作用[J]. 心理学报, 2023, 55(6): 877-891. |
| [9] | 黄元娜, 江程铭, 刘洪志, 李纾. 风险、跨期和空间决策的决策策略共享:眼动和主观判断的证据[J]. 心理学报, 2023, 55(6): 994-1015. |
| [10] | 刘洪志, 杨钘兰, 李秋月, 魏子晗. 跨期决策中的维度差异偏好:眼动证据[J]. 心理学报, 2023, 55(4): 612-625. |
| [11] | 曹海波, 兰泽波, 高峰, 于海涛, 李鹏, 王敬欣. 词素位置概率在中文阅读中的作用:词汇判断和眼动研究[J]. 心理学报, 2023, 55(2): 159-176. |
| [12] | 刘彦楼, 陈启山, 王一鸣, 姜晓彤. 模型参数点估计的可靠性:以CDM为例[J]. 心理学报, 2023, 55(10): 1712-1728. |
| [13] | 刘彦楼, 吴琼琼. 认知诊断模型Q矩阵修正:完整信息矩阵的作用[J]. 心理学报, 2023, 55(1): 142-158. |
| [14] | 孙小坚, 郭磊. 考虑题目选项信息的非参数认知诊断计算机自适应测验[J]. 心理学报, 2022, 54(9): 1137-1150. |
| [15] | 李佳, 毛秀珍, 韦嘉. 一种简单有效的Q矩阵修正新方法[J]. 心理学报, 2022, 54(8): 996-1008. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||