ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
心理科学进展 ›› 2023, Vol. 31 ›› Issue (11): 2092-2105.doi: 10.3724/SP.J.1042.2023.02092 cstr: 32111.14.2023.02092
卜晓鸥, 王耀, 杜亚雯, 王沛( )
)
收稿日期:2022-11-08
出版日期:2023-11-15
发布日期:2023-08-28
通讯作者:
王沛, E-mail: wangpei1970@163.com基金资助:
BU Xiaoou, WANG Yao, DU Yawen, WANG Pei()
Received:2022-11-08
Online:2023-11-15
Published:2023-08-28
摘要:
发展性阅读障碍严重影响儿童的学业成就、心理健康和社会适应能力。近年来, 机器学习因其强大的数据处理和挖掘能力逐渐被应用到阅读障碍儿童的早期筛查中, 在标准化心理教育测试、眼动追踪、游戏测试、脑成像等多个领域积累了较为丰富的成果, 获得了更加精准高效、灵活可靠的分类结果。然而, 机器学习在对象选取、数据采集、转化潜力和安全隐私等方面仍存在局限性。未来研究需要重点关注学龄前阅读障碍儿童的早期筛查系统的科学性, 同时积极构建多模态数据库、在多种算法中寻找最佳算法以获取最优参数, 最终实现临床实践中的广泛使用。
中图分类号:
卜晓鸥, 王耀, 杜亚雯, 王沛. (2023). 机器学习在发展性阅读障碍儿童早期筛查中的应用. 心理科学进展 , 31(11), 2092-2105.
BU Xiaoou, WANG Yao, DU Yawen, WANG Pei. (2023). Application of machine learning in early screening of children with dyslexia. Advances in Psychological Science, 31(11), 2092-2105.
| 序号 | 国家 | 作者 | 被试 | 主要数据指标 | 算法/方法 | 评价指标(%) Accuracy/Specificity/ Precision/F1 | ||
|---|---|---|---|---|---|---|---|---|
| 样本量 | 年龄 | 性别(男%) | ||||||
| 1 | 沙特阿拉伯 | Ahmad et al. ( | 3644 (392DD+non) | 7~17岁 | 50.8 | 语音能力, 认知能力 | SVM, ANN | Accuracy = 95 |
| 2 | 沙特阿拉伯 | AlGhamdi ( | 3644 (392DD+non) | 7~17岁 | 50.8 | 语音能力, 认知能力 | KNN, BT | Accuracy = 99.9 |
| 3 | 希腊 | Asvestopoulou et al. ( | 32DD, 37TD | 8.5~12.5岁 | / | 眼动特征 | LSVM | Accuracy = 84.21 |
| 4 | 印度 | Bhargavi & Prabha ( | 97DD, 88non | 9~10岁 | / | 眼动特征 | Hybrid SVM-PSO, LR, RF, KNN | 96.6/95/95/96.6 |
| 5 | 荷兰 | Chen et al. ( | 495FR, 498TD | 17~35个月 | 54.6 | 词汇发展(N-CDI量表) | SVM | 68/70/67/-/- |
| 6 | 中国 | Cui et al. ( | 28DD, 33TD | av11.6岁;av11.8岁 | 52.5 | MRI (白质形态学特征) | LSVM | 83.61/75/90.91/-/- |
| 7 | 巴西 | Da Silva et al. ( | 16DYS, 16TYP | 8~12岁 | 62.5 | fMRI (大脑激活差异) | 2D CNN, 3D CNN, SVM | Accuracy = 94.83 |
| 8 | 西班牙 | Formoso et al. ( | 16DG, 32CG | 88~100个月 | 50 | EEG (脑功能网络) | NB | 90/93/86/-/-, AUC = 0.95 |
| 9 | 法国 | Hmimdi et al. ( | 46DA, 41non | av15.52岁; av14.78岁 | 56.3 | 眼动特征 | LR, SVM | 81.25/85/82.5/-/- |
| 10 | 土耳其 | Iler et al. (2022) | 20DD, 13HC | 8~11岁 | 48.5 | EOG (垂直/水平眼电信号) | 1D-CNN | 98.70/97.52/99.90/-/98.69 |
| 11 | 土耳其 | Latifoglu et al. ( | 20DD, 10HC | 8~12岁 | 50 | EOG (眼电信号频谱图) | 2D-CNN | 99/100/98.2/-/98.9 |
| 12 | 中国香港 | Lee et al. ( | 454DD, 561TD | 7~12岁 | / | 汉字字符, 个人特征 | NB, SVM, KNN, DT, ANN, LR | Accuracy = 78 |
| 13 | 波兰 | Plonski et al. ( | 130DG, 106CG | 8.5~13.7岁 | 53.0 | MRI (灰质形态学特征) | LR | Accuracy = 65, AUC = 0.66 |
| 14 | 印度 | Prabha & Bhargavi ( | 97DD, 88non | 9~10岁 | / | 眼动特征 | SVM-PSO, L SVM | 95/100/89/-/- |
| 15 | 澳大利亚 | Radford et al. ( | 43DD, 50non | 7~14岁 | / | 单词音频信号 | LSTM, LR, SVM, KNN, RF, DT | Accuracy = 80 |
| 16 | 德国 | Rauschenberger et al. ( | 116DG, 197CG | 7~12岁 | 51.1 | 听觉特征, 视觉特征 | RF, ET, GB | 74/-/78/75 |
| 17 | 马来西亚 | Rello et al. ( | 3644 (392DD+non) | 7~17岁 | 50.8 | 语音能力, 认知能力 | RF | Accuracy = 89.2 |
| 18 | 以色列 | Shamir et al. ( | 81RD, 44TR | 6~14岁 | 40 | 语音能力, 认知能力 | SVM | -/75/75/-/- |
| 19 | 德国 | Skeide et al. ( | 141 (37DD+non) | 3~12岁 | 59.6 | MRI (白/灰质形态学特征), 基因 | SVM | Accuracy = 75.53 |
| 20 | 伊朗 | Tolami et al. ( | 29DD, 25non | 8~11岁 | / | 语言特征 | NB, MLP, KNN, SVM, LR, DT | 93.33/-/-/94.44/93.21 |
| 21 | 塞尔维亚 | Vajs et al. ( | 15DD, 15non | 7~13岁 | 36.7 | 眼动特征 | LR, SVM, KNN, RF | Accuracy = 94, AUC = 0.98 |
| 22 | 中国 | Wang & Bi ( | 187DD, 212TD | 7~13岁 | 64.2 | 与阅读相关的认知能力, 个人特征 | GA-BPNN | Accuracy = 94.1, AUC = 0.95 |
| 23 | 美国 | Yu et al. ( | 227SAC | 8~14岁 | / | 虚拟迷宫数据, 个人特征, 阅读水平 | RUSBoosted Trees | Accuracy = 70 |
| 24 | 西班牙 | Zahia et al. ( | 19DXR, 3 8non (TD+ MVR) | 9~12岁 | 58.2 | fMRI (大脑激活区域) | 3D CNN | 72.3/71.43/60/67 |
| 25 | 马来西亚 | Zainuddin et al. ( | 10PDS, 10CDS, 10CG | 7~12岁 | / | EEG (beta/theta频带信息) | KNN, ELM | Accuracy = 89 |
表1 机器学习在发展性阅读障碍儿童早期筛查中的应用
| 序号 | 国家 | 作者 | 被试 | 主要数据指标 | 算法/方法 | 评价指标(%) Accuracy/Specificity/ Precision/F1 | ||
|---|---|---|---|---|---|---|---|---|
| 样本量 | 年龄 | 性别(男%) | ||||||
| 1 | 沙特阿拉伯 | Ahmad et al. ( | 3644 (392DD+non) | 7~17岁 | 50.8 | 语音能力, 认知能力 | SVM, ANN | Accuracy = 95 |
| 2 | 沙特阿拉伯 | AlGhamdi ( | 3644 (392DD+non) | 7~17岁 | 50.8 | 语音能力, 认知能力 | KNN, BT | Accuracy = 99.9 |
| 3 | 希腊 | Asvestopoulou et al. ( | 32DD, 37TD | 8.5~12.5岁 | / | 眼动特征 | LSVM | Accuracy = 84.21 |
| 4 | 印度 | Bhargavi & Prabha ( | 97DD, 88non | 9~10岁 | / | 眼动特征 | Hybrid SVM-PSO, LR, RF, KNN | 96.6/95/95/96.6 |
| 5 | 荷兰 | Chen et al. ( | 495FR, 498TD | 17~35个月 | 54.6 | 词汇发展(N-CDI量表) | SVM | 68/70/67/-/- |
| 6 | 中国 | Cui et al. ( | 28DD, 33TD | av11.6岁;av11.8岁 | 52.5 | MRI (白质形态学特征) | LSVM | 83.61/75/90.91/-/- |
| 7 | 巴西 | Da Silva et al. ( | 16DYS, 16TYP | 8~12岁 | 62.5 | fMRI (大脑激活差异) | 2D CNN, 3D CNN, SVM | Accuracy = 94.83 |
| 8 | 西班牙 | Formoso et al. ( | 16DG, 32CG | 88~100个月 | 50 | EEG (脑功能网络) | NB | 90/93/86/-/-, AUC = 0.95 |
| 9 | 法国 | Hmimdi et al. ( | 46DA, 41non | av15.52岁; av14.78岁 | 56.3 | 眼动特征 | LR, SVM | 81.25/85/82.5/-/- |
| 10 | 土耳其 | Iler et al. (2022) | 20DD, 13HC | 8~11岁 | 48.5 | EOG (垂直/水平眼电信号) | 1D-CNN | 98.70/97.52/99.90/-/98.69 |
| 11 | 土耳其 | Latifoglu et al. ( | 20DD, 10HC | 8~12岁 | 50 | EOG (眼电信号频谱图) | 2D-CNN | 99/100/98.2/-/98.9 |
| 12 | 中国香港 | Lee et al. ( | 454DD, 561TD | 7~12岁 | / | 汉字字符, 个人特征 | NB, SVM, KNN, DT, ANN, LR | Accuracy = 78 |
| 13 | 波兰 | Plonski et al. ( | 130DG, 106CG | 8.5~13.7岁 | 53.0 | MRI (灰质形态学特征) | LR | Accuracy = 65, AUC = 0.66 |
| 14 | 印度 | Prabha & Bhargavi ( | 97DD, 88non | 9~10岁 | / | 眼动特征 | SVM-PSO, L SVM | 95/100/89/-/- |
| 15 | 澳大利亚 | Radford et al. ( | 43DD, 50non | 7~14岁 | / | 单词音频信号 | LSTM, LR, SVM, KNN, RF, DT | Accuracy = 80 |
| 16 | 德国 | Rauschenberger et al. ( | 116DG, 197CG | 7~12岁 | 51.1 | 听觉特征, 视觉特征 | RF, ET, GB | 74/-/78/75 |
| 17 | 马来西亚 | Rello et al. ( | 3644 (392DD+non) | 7~17岁 | 50.8 | 语音能力, 认知能力 | RF | Accuracy = 89.2 |
| 18 | 以色列 | Shamir et al. ( | 81RD, 44TR | 6~14岁 | 40 | 语音能力, 认知能力 | SVM | -/75/75/-/- |
| 19 | 德国 | Skeide et al. ( | 141 (37DD+non) | 3~12岁 | 59.6 | MRI (白/灰质形态学特征), 基因 | SVM | Accuracy = 75.53 |
| 20 | 伊朗 | Tolami et al. ( | 29DD, 25non | 8~11岁 | / | 语言特征 | NB, MLP, KNN, SVM, LR, DT | 93.33/-/-/94.44/93.21 |
| 21 | 塞尔维亚 | Vajs et al. ( | 15DD, 15non | 7~13岁 | 36.7 | 眼动特征 | LR, SVM, KNN, RF | Accuracy = 94, AUC = 0.98 |
| 22 | 中国 | Wang & Bi ( | 187DD, 212TD | 7~13岁 | 64.2 | 与阅读相关的认知能力, 个人特征 | GA-BPNN | Accuracy = 94.1, AUC = 0.95 |
| 23 | 美国 | Yu et al. ( | 227SAC | 8~14岁 | / | 虚拟迷宫数据, 个人特征, 阅读水平 | RUSBoosted Trees | Accuracy = 70 |
| 24 | 西班牙 | Zahia et al. ( | 19DXR, 3 8non (TD+ MVR) | 9~12岁 | 58.2 | fMRI (大脑激活区域) | 3D CNN | 72.3/71.43/60/67 |
| 25 | 马来西亚 | Zainuddin et al. ( | 10PDS, 10CDS, 10CG | 7~12岁 | / | EEG (beta/theta频带信息) | KNN, ELM | Accuracy = 89 |
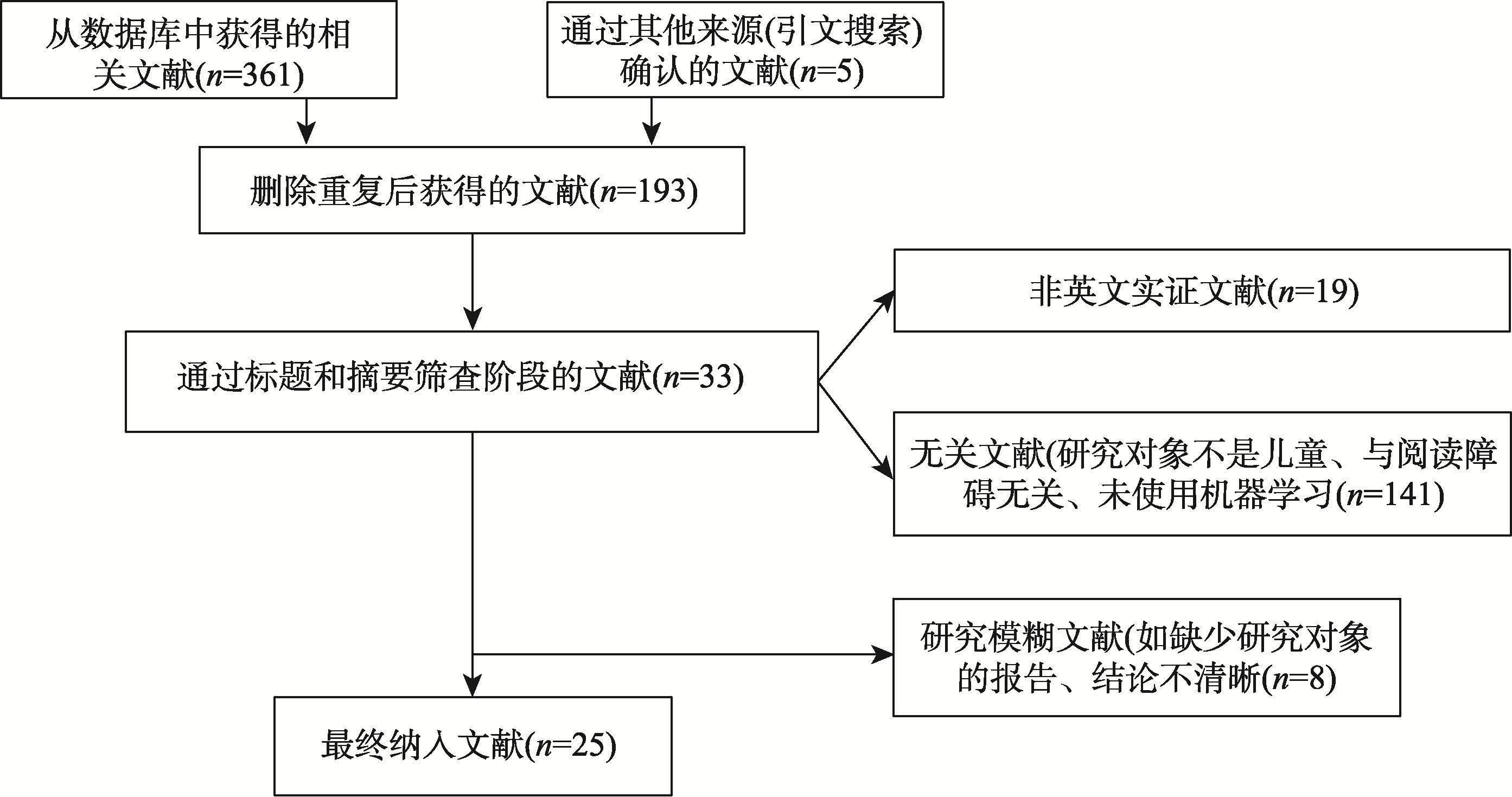
图1 文献筛选流程图

图2 文献检索完成后的文献年度分布
| 一级维度 | 具体特征 |
|---|---|
| 标准化心理教育测试 | 语音加工: 正字法意识, 语素意识, 音节意识, 字母意识, 快速自动命名, 语音意识, 语音感知, 语音流畅性, 语言表达与理解, 语法错误, 语法复杂性, 语法可读性, 词汇多样性; 阅读能力: 阅读速度, 阅读时间, 阅读流畅性, 阅读准确性, 阅读理解性; 认知能力: 工作记忆, 视觉/听觉工作记忆, 视觉/听觉辨别和分类, 视觉注意, 加工速度; 字符特征: 字符结构, 书写正确率, 词汇地位, 部首, 正字法, 笔画, 语音, 首音, 韵律, 声调; 个人特征: 年级, 年龄, 性别, 智力; 其他特征: 沟通发展量表(N-CDI)数据, 虚拟迷宫学习数据; |
| 眼动追踪 | 常见的眼动特征: 注视时间/次数/频率/中位数长度/交叉变异性/分形维数, 眼跳时间/次数/中位数长度/变异性/距离, 眨眼次数/频率, 回视, 落点位置, 双眼位置; 其他眼动特征: 主动阅读时间, 阅读速度/时间/错误率, 垂直/水平EOG信号, EOG信号的频谱图; |
| 网络/手机游戏 | 语音能力: 语言技能, 语言练习; 认知能力: 工作记忆, 执行功能, 感知过程; 听觉特征: 持续时间, 平均点击时间, 间隔时间, 命中率; 视觉特征: 点击次数, 点击时间 |
| 脑成像技术 | MRI: 白质的体积/各向异性分数/平均弥散率/轴向扩散系数/径向扩散系数, 灰质的体积/厚度/面积/折叠指数/平均曲率; fMRI: 阅读任务下的大脑激活区域, 大脑激活差异; EEG: 脑功能网络、beta/theta频带信息 |
| 其他 | 阅读障碍的候选基因 |
表2 机器学习在发展性阅读障碍儿童早期筛查中的特征类型
| 一级维度 | 具体特征 |
|---|---|
| 标准化心理教育测试 | 语音加工: 正字法意识, 语素意识, 音节意识, 字母意识, 快速自动命名, 语音意识, 语音感知, 语音流畅性, 语言表达与理解, 语法错误, 语法复杂性, 语法可读性, 词汇多样性; 阅读能力: 阅读速度, 阅读时间, 阅读流畅性, 阅读准确性, 阅读理解性; 认知能力: 工作记忆, 视觉/听觉工作记忆, 视觉/听觉辨别和分类, 视觉注意, 加工速度; 字符特征: 字符结构, 书写正确率, 词汇地位, 部首, 正字法, 笔画, 语音, 首音, 韵律, 声调; 个人特征: 年级, 年龄, 性别, 智力; 其他特征: 沟通发展量表(N-CDI)数据, 虚拟迷宫学习数据; |
| 眼动追踪 | 常见的眼动特征: 注视时间/次数/频率/中位数长度/交叉变异性/分形维数, 眼跳时间/次数/中位数长度/变异性/距离, 眨眼次数/频率, 回视, 落点位置, 双眼位置; 其他眼动特征: 主动阅读时间, 阅读速度/时间/错误率, 垂直/水平EOG信号, EOG信号的频谱图; |
| 网络/手机游戏 | 语音能力: 语言技能, 语言练习; 认知能力: 工作记忆, 执行功能, 感知过程; 听觉特征: 持续时间, 平均点击时间, 间隔时间, 命中率; 视觉特征: 点击次数, 点击时间 |
| 脑成像技术 | MRI: 白质的体积/各向异性分数/平均弥散率/轴向扩散系数/径向扩散系数, 灰质的体积/厚度/面积/折叠指数/平均曲率; fMRI: 阅读任务下的大脑激活区域, 大脑激活差异; EEG: 脑功能网络、beta/theta频带信息 |
| 其他 | 阅读障碍的候选基因 |
| 一级维度 | 最具预测性的特征 |
|---|---|
| 标准化心理教育测试 | 阅读准确性, 笔画, 词汇地位, 字符结构, 词汇量, 年级; |
| 眼动追踪 | 异向眼动, 注视交叉变异性, 注视次数/持续时间, 眼跳次数/持续时间/长度, 短前向移动个数, 多重注视词个数, 水平EOG信号; |
| 网络/手机游戏 | 视觉/听觉点击总次数, 视觉/听觉第一次点击时间; |
| 脑成像技术 | MRI: NRSN1相关的“视觉单词形成区”的灰质体积, 假定阅读系统内/边缘系统/运动系统的白质区域, 左半球外侧裂周区有额外褶皱的非典型曲率模式; fMRI: 左侧枕叶, 顶下小叶, 右侧前额叶; EEG: beta频带信息, db2小波, db4小波 |
表3 机器学习在发展性阅读障碍儿童早期筛查中最具预测性的特征
| 一级维度 | 最具预测性的特征 |
|---|---|
| 标准化心理教育测试 | 阅读准确性, 笔画, 词汇地位, 字符结构, 词汇量, 年级; |
| 眼动追踪 | 异向眼动, 注视交叉变异性, 注视次数/持续时间, 眼跳次数/持续时间/长度, 短前向移动个数, 多重注视词个数, 水平EOG信号; |
| 网络/手机游戏 | 视觉/听觉点击总次数, 视觉/听觉第一次点击时间; |
| 脑成像技术 | MRI: NRSN1相关的“视觉单词形成区”的灰质体积, 假定阅读系统内/边缘系统/运动系统的白质区域, 左半球外侧裂周区有额外褶皱的非典型曲率模式; fMRI: 左侧枕叶, 顶下小叶, 右侧前额叶; EEG: beta频带信息, db2小波, db4小波 |
| *为纳入系统分析的文献 | |
| [1] | 苏萌萌, 张玉平, 史冰洁, 舒华. (2012). 发展性阅读障碍的遗传关联分析. 心理科学进展, 20(8), 1259-1267. |
| [2] |
Aaron, P. G., Joshi, M., & Williams, K. A. (1999). Not all reading disabilities are alike. Journal of Learning Disabilities, 32(2), 120-137. https://doi.org/10.1177/002221949903200203
URL pmid: 15499713 |
| [3] |
Abd Rahman, R., Omar, K., Noah, S. A. M., Danuri, M. S. N. M., & Al-Garadi, M. A. (2020). Application of machine learning methods in mental health detection: A systematic review. IEEE Access, 8, 183952-183964. https://doi.org/10.1109/ACCESS.2020.3029154
doi: 10.1109/Access.6287639 URL |
| [4] |
Ahire, N., Awale, R. N., Patnaik, S., & Wagh, A. (2022). A comprehensive review of machine learning approaches for dyslexia diagnosis. Multimedia Tools and Applications, 82, 13557-13577. https://doi.org/10.1007/s11042-022-13939-0
doi: 10.1007/s11042-022-13939-0 URL |
| [5] | * Ahmad, N., Rehman, M. B., El Hassan, H. M., Ahmad, I., & Rashid, M. (2022). An efficient machine learning-based feature optimization model for the detection of dyslexia. Computational Intelligence and Neuroscience, 2022, 8491753. https://doi.org/10.1155/2022/8491753 |
| [6] | * AlGhamdi, A. S. (2022). Novel ensemble model recommendation approach for the detection of dyslexia. Children-Basel, 9, 1337. https://doi.org/10.3390/children9091337 |
| [7] | * Asvestopoulou, T., Manousaki, V., Psistakis, A., Smyrnakis, I., Andreadakis, V., Aslanides, I. M., & Papadopouli, M. (2019). DysLexML: Screening tool for dyslexia using machine learning. arXiv. https://doi.org/10.48550/arXiv.1903.06274 |
| [8] | Atkar, G., & Jayaraju, P. (2021). Speech synthesis using generative adversarial network for improving readability of Hindi words to recuperate from dyslexia. Neural Computing & Applications, 33(15), 9353-9362. https://doi.org/10.1007/s00521-021-05695-3 |
| [9] |
Ballester, P. L., da Silva, L. T., Marcon, M., Esper, N. B., Frey, B. N., Buchweitz, A., & Meneguzzi, F. (2021). Predicting brain age at slice level: Convolutional neural networks and consequences for interpretability. Frontiers in Psychiatry, 12, 598518. https://doi.org/10.3389/fpsyt.2021.598518
doi: 10.3389/fpsyt.2021.598518 URL |
| [10] |
* Bhargavi, R., & Prabha, A. J. (2020). Predictive model for dyslexia from fixations and saccadic eye movement events. Computer Methods and Programs in Biomedicine, 195(5), 105538. https://doi.org/10.1016/j.cmpb.2020.105538
doi: 10.1016/j.cmpb.2020.105538 URL |
| [11] |
Borleffs, E., Glatz, T. K., Daulay, D. A., Richardson, U., Zwarts, F., & Maassen, B. A. M. (2018). GraphoGame SI: The development of a technology-enhanced literacy learning tool for standard Indonesian. European Journal of Psychology of Education, 33(4), 595-613. https://doi.org/10.1007/s10212-017-0354-9
doi: 10.1007/s10212-017-0354-9 URL |
| [12] | Burns, M. K., VanDerHeyden, A. M., Duesenberg-Marshall, M. D., Romero, M. E., Stevens, M. A., Izumi, J. T., & McCollom, E. M. (2022). Decision accuracy of commonly used dyslexia screeners among students who are potentially at-risk for reading difficulties. Learning Disability Quarterly. Advance online publication. https://doi.org/10.1177/07319487221096684 |
| [13] |
Catts, H. W., McIlraith, A., Bridges, M. S., & Nielsen, D. C. (2017). Viewing a phonological deficit within a multifactorial model of dyslexia. Reading and Writing, 30(3), 613-629. https://doi.org/10.1007/s11145-016-9692-2
doi: 10.1007/s11145-016-9692-2 URL |
| [14] |
Catts, H. W., & Petscher, Y. (2022). A cumulative risk and resilience model of dyslexia. Journal of Learning Disabilities, 55(3), 171-184. https://doi.org/10.1177/00222194211037062
doi: 10.1177/00222194211037062 URL |
| [15] |
* Chen, A., Wijnen, F., Koster, C., & Schnack, H. (2017). Individualized early prediction of familial risk of dyslexia: A study of infant vocabulary development. Frontiers in Psychology, 8, 156. https://doi.org/10.3389/fpsyg.2017.00156
doi: 10.3389/fpsyg.2017.00156 URL pmid: 28270778 |
| [16] |
Chimeno, Y. G., Zapirain, B. G., Prieto, I. S., & Fernandez- Ruanova, B. (2014). Automatic classification of dyslexic children by applying machine learning to fMRI images. Bio-Medical Materials and Engineering, 24(6), 2995-3002. https://doi.org/10.3233/BME-141120
doi: 10.3233/BME-141120 URL |
| [17] |
* Cui, Z. X., Xia, Z. C., Su, M. M., Shu, H., & Gong, G. L. (2016). Disrupted white matter connectivity underlying developmental dyslexia: A machine learning approach. Human Brain Mapping, 37(4), 1443-1458. https://doi.org/10.1002/hbm.23112
doi: 10.1002/hbm.23112 URL pmid: 26787263 |
| [18] | * Da Silva, L. T., Esper, N. B., Ruiz, D. D., Meneguzzi, F., & Buchweitz, A. (2021). Visual explanation for identification of the brain bases for developmental dyslexia on fMRI data. Frontiers in Computational Neuroscience, 15, 584659. https://doi.org/10.3389/fncom.2021.594659 |
| [19] |
Farah, R., Ionta, S., & Horowitz-Kraus, T. (2021). Neuro- behavioral correlates of executive dysfunctions in dyslexia over development from childhood to adulthood. Frontiers in Psychology, 12, 708863. https://doi.org/10.3389/fpsyg.2021.708863
doi: 10.3389/fpsyg.2021.708863 URL |
| [20] | Fletcher, J. M., Lyon, G. R., Fuchs, L. S., & Barnes, M. A. (2019). Learning disabilities: From identification to intervention (2nd ed). The Guilford Press. |
| [21] |
* Formoso, M. A., Ortiz, A., Martinez-Murcia, F. J., Gallego, N., & Luque, J. L. (2021). Detecting phase-synchrony connectivity anomalies in EEG signals. Application to dyslexia diagnosis. Sensors, 21(21), 7061. https://doi.org/10.3390/s21217061
doi: 10.3390/s21217061 URL |
| [22] |
Fox, S. E., Levitt, P., & Nelson, C. A. (2010). How the timing and quality of early experiences influence the development of brain architecture. Child Development, 81(1), 28-40. https://doi.org/10.1111/j.1467-8624.2009. 01380.x
doi: 10.1111/j.1467-8624.2009.01380.x URL pmid: 20331653 |
| [23] |
Gabel, L. A., Voss, K., Johnson, E., Lindstrom, E. R., Truong, D. T., Murray, E. M., … Gruen, J. R. (2021). Identifying dyslexia: Link between maze learning and dyslexia susceptibility gene, DCDC2, in young children. Developmental Neuroscience, 43(2), 116-133. https://doi.org/10.1159/000516667
doi: 10.1159/000516667 URL |
| [24] |
Galaburda, A. M., LoTurco, J., Ramus, F., Fitch, R. H., & Rosen, G. D. (2006). From genes to behavior in developmental dyslexia. Nature Neuroscience, 9(10), 1213-1217. https://doi.org/10.1038/nn1772
URL pmid: 17001339 |
| [25] | Gilvary, C., Elkhader, J., Madhukar, N., Henchcliffe, C., Goncalves, M. D., & Elemento, O. (2020). A machine learning and network framework to discover new indications for small molecules. PLoS Computational Biology, 16(8), e1008098. https://doi.org/10.1371/journal.pcbi.1008098 |
| [26] |
Hale, J., Alfonso, V., Berninger, V., Bracken, B., Christo, C., Clark, E., …Yalof, J. (2010). Critical issues in response- to-intervention, comprehensive evaluation, and specific learning disabilities identification and intervention: An expert white paper consensus. Learning Disability Quarterly, 33(3), 223-236. https://doi.org/10.1177/073194871003300310
doi: 10.1177/073194871003300310 URL |
| [27] |
* Hmimdi, A., Ward, L. M., Palpanas, T., & Kapoula, Z. (2021). Predicting dyslexia and reading speed in adolescents from eye movements in reading and non-reading tasks: A machine learning approach. Brain Sciences, 11(10), 1337. https://doi.org/10.3390/brainsci11101337
doi: 10.3390/brainsci11101337 URL |
| [28] |
Hosseini, S. M. H., Black, J. M., Soriano, T., Bugescu, N., Martinez, R., Raman, M. M., … Hoeft, F. (2013). Topological properties of large-scale structural brain networks in children with familial risk for reading difficulties. NeuroImage, 71, 260-274. https://doi.org/10.1016/j.neuroimage.2013.01.013
doi: 10.1016/j.neuroimage.2013.01.013 URL pmid: 23333415 |
| [29] | * Ileri, R., Latifoglu, F., & Demirci, E. (2022). A novel approach for detection of dyslexia using convolutional neural network with EOG signals. Medical & Biological Engineering & Computing, 60(11), 3041-3055. https://doi.org/10.1007/s11517-022-02656-3 |
| [30] |
Kaisar, S. (2020). Developmental dyslexia detection using machine learning techniques: A survey. ICT Express, 6(3), 181-184. https://doi.org/10.1016/j.icte.2020.05.006
doi: 10.1016/j.icte.2020.05.006 URL |
| [31] | Khan, R. U., Lee, J., & Yin, B. O. (2018). Machine learning and dyslexia: Diagnostic and classification system (DCS) for kids with learning disabilities. Journal of Engineering Technology, 7(3), 97-100. |
| [32] | Kraft, I., Cafiero, R., Schaadt, G., Brauer, J., Neef, N. E., Mueller, B., … Skeide, M. A. (2015). Cortical differences in preliterate children at familiar risk of dyslexia are similar to those observed in dyslexic readers. Brain, 138(9), e378. https://doi.org/10.1093/brain/awv036 |
| [33] |
Larco, A., Carrillo, J., Chicaiza, N., Yanez, C., & Luján- Mora, S. (2021). Moving beyond limitations: Designing the Helpdys App for children with dyslexia in rural areas. Sustainability, 13, 7801. https://doi.org/10.3390/su13137081
doi: 10.3390/su13147801 URL |
| [34] |
* Latifoglu, F., Ileri, R., & Demirci, E. (2021). Assessment of dyslexic children with EOG signals: Determining retrieving words/re-reading and skipping lines using convolutional neural networks. Chaos Solitons & Fractals, 145, 110721. https://doi.org/10.1016/j.chaos.2021.110721
doi: 10.1016/j.chaos.2021.110721 URL |
| [35] | * Lee, S. M. K., Liu, H. W., & Tong, S. X. (2022). Identifying chinese children with dyslexia using machine learning with character dictation. Scientific Studies of Reading. https://doi.org/10.1080/10888438.2022.2088373. |
| [36] |
Livingston, E. M., Siegel, L. S., & Ribary, U. (2018). Developmental dyslexia: Emotional impact and consequences. Australian Journal of Learning Difficulties, 23(2), 107-135. https://doi.org/10.1080/19404158.2018.1479975
doi: 10.1080/19404158.2018.1479975 URL |
| [37] |
Lucchiari, C., Folgieri, R., & Pravettoni, G. (2014). Fuzzy cognitive maps: A tool to improve diagnostic decisions. Diagnosis (Berl), 1(4), 289-293. https://doi.org/10.1515/dx-2014-0026
doi: 10.1515/dx-2014-0026 URL pmid: 29540009 |
| [38] |
Lyu, J., & Zhang, J. (2019). BP neural network prediction model for suicide attempt among Chinese rural residents. Journal of Affective Disorders, 246, 465-473. https://doi.org/10.1016/j.jad.2018.12.111
doi: S0165-0327(18)32153-0 URL pmid: 30599370 |
| [39] |
Lyytinen, P., Eklund, K., & Lyytinen, H. (2005). Language development and literacy skills in late-talking toddlers with and without familial risk for dyslexia. Annals of Dyslexia, 55(2), 166-192. https://doi.org/10.1007/s11881-005-0010-y
URL pmid: 17849192 |
| [40] |
McGrath, L. M., Peterson, R. L., & Pennington, B. F. (2020). The multiple deficit model: Progress, problems, and prospects. Scientific Studies of Reading, 24(1), 7-13. https://doi.org/10.1080/10888438.2019.1706180
doi: 10.1080/10888438.2019.1706180 URL pmid: 32440085 |
| [41] |
Miciak, J., & Fletcher, J. M. (2020). The critical role of instructional response for identifying dyslexia and other learning disabilities. Journal of Learning Disabilities, 53(5), 343-353. https://doi.org/10.1177/0022219420906801
doi: 10.1177/0022219420906801 URL pmid: 32075514 |
| [42] |
Miciak, J., Stuebing, K. K., Vaughn, S., Roberts, G., Barth, A. E., & Fletcher, J. M. (2014). Cognitive attributes of adequate and inadequate responders to reading intervention in middle school. School Psychology Review, 43(4), 407-427. https://doi.org/10.17105/SPR-13-0052.1
doi: 10.17105/SPR-13-0052.1 URL pmid: 28579668 |
| [43] |
Morris, R. D., Stuebing, K. K., Fletcher, J. M., Shaywitz, S. E., Lyon, G. R., Shankweiler, D. P., … Shaywitz, B. A. (1998). Subtypes of reading disability: Variability around a phonological core. Journal of Educational Psychology, 90(3), 347-373. https://doi.org/10.1037/0022-0663.90.3.347
doi: 10.1037/0022-0663.90.3.347 URL |
| [44] |
Ojanen, E., Ronimus, M., Ahonen, T., Chansa-Kabali, T., February, P., Jere-Folotiya, J., … Lyytinen, H. (2015). GraphoGame — A catalyst for multi-level promotion of literacy in diverse contexts. Frontiers in Psychology, 6, 671. https://doi.org/10.3389/fpsyg.2015.00671
doi: 10.3389/fpsyg.2015.00671 URL pmid: 26113825 |
| [45] |
Oliaee, A., Mohebbi, M., Shirani, S., & Rostami, R. (2022). Extraction of discriminative features from EEG signals of dyslexic children; before and after the treatment. Cognitive Neurodynamics, 16(6), 1249-1259. https://doi.org/10.1007/s11571-022-09794-2.
doi: 10.1007/s11571-022-09794-2 URL pmid: 36408072 |
| [46] |
Ortiz, A., Martinez-Murcia, F. J., Luque, J. L., Gimenez, A., Morales-Ortega, R., & Ortega, J. (2020). Dyslexia diagnosis by EEG temporal and spectral descriptors: An anomaly detection approach. International Journal of Neural Systems, 30(7). 2050029. https://doi.org/10.1142/S012906572050029X
doi: 10.1142/S012906572050029X URL |
| [47] |
* Plonski, P., Gradkowski, W., Altarelli, I., Monzalvo, K., van Ermingen-Marbach, M., Grande, M., … Jednorog, K. (2017). Multi-parameter machine learning approach to the neuroanatomical basis of developmental dyslexia. Human Brain Mapping, 38(2), 900-908. https://doi.org/10.1002/hbm.23426
doi: 10.1002/hbm.23426 URL pmid: 27712002 |
| [48] |
* Prabha, A. J., & Bhargavi, R. (2019). Prediction of dyslexia from eye movements using machine learning. IETE Journal of Research, 68(2), 814-823. https://doi.org/10.1080/03772063.2019.1622461
doi: 10.1080/03772063.2019.1622461 URL |
| [49] |
Raatikainen, P., Hautala, J., Loberg, O., Kärkkäinen, T., Leppänen, P., & Nieminen, P. (2021). Detection of developmental dyslexia with machine learning using eye movement data. Array, 12, 100087. https://doi.org/10.1016/j.array.2021.100087
doi: 10.1016/j.array.2021.100087 URL |
| [50] | * Radford, J., Richard, G., Richard, H., & Serrurier, M. (2021, February). Detecting dyslexia from audio records: An AI approach. Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies-HEALTHINF (pp. 58-66), Electr Network. https://doi.org/10.5220/0010196000580066 |
| [51] |
* Rauschenberger, M., Baeza-Yates, R., & Rello, L. (2022). A universal screening tool for dyslexia by a web-game and machine learning. Frontiers in Computer Science, 3, 628634. https://doi.org/10.3389/fcomp.2021.628634
doi: 10.3389/fcomp.2021.628634 URL |
| [52] | * Rello, L., Baeza-Yates, R., Ali, A., Bigham, J. P., & Serra, M. (2020). Predicting risk of dyslexia with an online gamified test. PLoS ONE, 15(12), e0241687. https://doi.org/10.1371/journal.pone.0241687 |
| [53] |
Richlan, F., Kronbichler, M., & Wimmer, H. (2013). Structural abnormalities in the dyslexic brain: A meta- analysis of voxel-based morphometry studies. Human Brain Mapping, 34(11), 3055-3065. https://doi.org/10.1002/hbm.22127
doi: 10.1002/hbm.22127 URL pmid: 22711189 |
| [54] | Russell, S. J., & Norvig, P. (2010). Artificial intelligence: A modern approach. Hoboken, NJ: Prentice Hall. |
| [55] | Sanfilippo, J., Ness, M., Petscher, Y., Rappaport, L., Zuckerman, B., & Gaab, N. (2020). Reintroducing dyslexia: Early identification and implications for pediatric practice. Pediatrics, 146(1), e20193046. https://doi.org/10.1542/peds.2019-3046 |
| [56] |
* Shamir, N., Zivan, M., & Horowitz‐Kraus, T. (2019). Six‐minute screening test can provide valid information about the skills that underlie childhood reading and cognitive abilities. Acta Paediatrica, 108(7), 1278-1284. https://doi.org/10.1111/apa.14680
doi: 10.1111/apa.14680 URL |
| [57] |
Sihvonen, A. J., Virtala, P., Thiede, A., Laasonen, M., & Kujala, T. (2021). Structural white matter connectometry of reading and dyslexia. NeuroImage, 241, 118411. https://doi.org/10.1016/j.neuroimage.2021.118411
doi: 10.1016/j.neuroimage.2021.118411 URL |
| [58] |
* Skeide, M. A., Kraft, I., Mueller, B., Schaadt, G., Neef, N. E., Brauer, J., … Friederici, A. D. (2016). NRSN1 associated grey matter volume of the visual word form area reveals dyslexia before school. Brain, 139, 2792-2803. https://doi.org/10.1093/brain/aww153
URL pmid: 27343255 |
| [59] |
Tamboer, P., Vorst, H. C. M., Ghebreab, S., & Scholte, H. S. (2016). Machine learning and dyslexia: Classification of individual structural neuro-imaging scans of students with and without dyslexia. Neuroimage-Clinical, 11, 508-514. https://doi.org/10.1016/j.nicl.2016.03.014
doi: S2213-1582(16)30055-9 URL pmid: 27114899 |
| [60] |
Thiede, A., Glerean, E., Kujala, T., & Parkkonen, L. (2020). Atypical MEG inter-subject correlation during listening to continuous natural speech in dyslexia. NeuroImage, 216, 116799. https://doi.org/10.1016/j.neuroimage.2020.116799
doi: 10.1016/j.neuroimage.2020.116799 URL |
| [61] | * Tolami, F. A., Khorasani, M., Kahani, M., Yazdi, S. A. A., & Ghalenoei, M. A. (2021, October). An intelligent linguistic error detection approach to automated diagnosis of Dyslexia disorder in Persian speaking children. 11th International Conference on Computer Engineering and Knowledge (ICCKE) (pp. 393-398), Mashad, Iran. https://doi.org/10.1109/ICCKE54056.2021.9721446 |
| [62] | Usman, O. L., & Muniyandi, R. C. (2020). CryptoDL: Predicting dyslexia biomarkers from encrypted neuroimaging dataset using energy-efficient residue number system and deep convolutional neural network. Symmetry-Basel, 12(5), 836. https://doi.org/10.3390/sym12050836 |
| [63] |
Usman, O. L., Muniyandi, R. C., Omar, K., & Mohamad, M. (2021). Advance machine learning methods for dyslexia biomarker detection: A review of implementation details and challenges. IEEE Access, 9, 36879-36897. https://doi.org/10.1109/ACCESS.2021.3062709
doi: 10.1109/Access.6287639 URL |
| [64] |
* Vajs, I., Kovic, V., Papic, T., Savic, A. M., & Jankovic, M. M. (2022). Spatiotemporal eye-tracking feature set for improved recognition of dyslexic reading patterns in children. Sensors, 22(13), 4900. https://doi.org/10.3390/s22134900
doi: 10.3390/s22134900 URL |
| [65] |
Vandermosten, M., Boets, B., Wouters, J., & Ghesquiere, P. (2012). A qualitative and quantitative review of diffusion tensor imaging studies in reading and dyslexia. Neuroscience and Biobehavioral Reviews, 36(6), 1532-1552. https://doi.org/10.1016/j.neubiorev.2012.04.002
doi: 10.1016/j.neubiorev.2012.04.002 URL pmid: 22516793 |
| [66] |
Vogler, G. P., Defries, J. C., & Decker, S. N. (1985). Family history as an indictor of risk for reading disability. Journal of Learning Disabilities, 17(10), 616-618. https://doi.org/10.1177/002221948401701009
doi: 10.1177/002221948401701009 URL |
| [67] |
Walda, S., Hasselman, F., & Bosman, A. (2022). Identifying determinants of dyslexia: An ultimate attempt using machine learning. Frontiers in Psychology, 13, 869352. https://doi.org/10.3389/fpsyg.2022.869352
doi: 10.3389/fpsyg.2022.869352 URL |
| [68] |
* Wang, R., & Bi, H. Y. (2022). A predictive model for chinese children with developmental dyslexia - Based on a genetic algorithm optimized back-propagation neural network. Expert Systems with Applications, 187, 115949. https://doi.org/10.1016/j.eswa.2021.115949
doi: 10.1016/j.eswa.2021.115949 URL |
| [69] |
Wanzek, J., & Vaughn, S. (2007). Research-based implications from extensive early reading interventions. School Psychology Review, 36(4), 541-561. https://doi.org/10.1080/02796015.2007.12087917
doi: 10.1080/02796015.2007.12087917 URL |
| [70] |
Yang, X., Zhang, J., Lv, Y., Wang, F., Ding, G., Zhang, M., … Song, Y. (2021). Failure of resting-state frontal- occipital connectivity in linking visual perception with reading fluency in Chinese children with developmental dyslexia. NeuroImage, 233, 117911. https://doi.org/10.1016/j.neuroimage.2021.117911
doi: 10.1016/j.neuroimage.2021.117911 URL |
| [71] | * Yu, Y. C., Shyntassov, K., Zewge, A., & Gabel, L. (2022, March). Classification predictive modeling of dyslexia. 56th Annual Conference on Information Sciences and Systems (pp. 177-181), Electr Network. https://doi.org/10.1109/CISS53076.2022.9751182 |
| [72] |
* Zahia, S., Garcia-Zapirain, B., Saralegui, I., & Fernandez- Ruanova, B. (2020). Dyslexia detection using 3D convolutional neural networks and functional magnetic resonance imaging. Computer Methods and Programs in Biomedicine, 197, 105726. https://doi.org/10.1016/j.cmpb.2020.105726
doi: 10.1016/j.cmpb.2020.105726 URL |
| [73] | * Zainuddin, A. Z. A., Mansor, W., Lee, K. Y., & Mahmoodin, Z. (2019, July). Comparison of extreme learning machine and K-nearest neighbour performance in classifying EEG signal of normal, poor and capable dyslexic children. Annual International Conference of the IEEE Engineering in Medicine and Biology Society (pp. 4513-4516), Berlin, Germany. https://doi.org/10.1109/EMBC.2019.8857569 |
| [1] | 高白雪, 谢云龙, 罗俊龙, 贺雯. 机器学习在提高非自杀性自伤预测力中的应用:一项系统综述[J]. 心理科学进展, 2025, 33(3): 506-519. |
| [2] | 刘豫, 毕丹丹, 赵凯宾, 史怡明, Hanna Y. Adamseged, 晋争. 儿童挑食行为的认知机制[J]. 心理科学进展, 2025, 33(2): 305-321. |
| [3] | 周嘉雯, 王明怡. 新冠疫情下的儿童青少年健康危险行为:基于家庭风险的视角[J]. 心理科学进展, 2024, 32(8): 1328-1341. |
| [4] | 何婷, 胡惠南, 乔璐, 杨靓靓, 李明英, 蔺秀云. 父母应对社会化如何影响儿童青少年适应:基于长时与实时时间轴的视角[J]. 心理科学进展, 2024, 32(8): 1342-1353. |
| [5] | 蒋莹, 胡佳, 冯靓瑜, 任启丹. 贫困经历下稀缺心态对儿童执行功能的影响及其机制[J]. 心理科学进展, 2024, 32(5): 728-737. |
| [6] | 文思雁, 于旭晨, 金磊, 宫俊如, 张晓函, 孙敬林, 张杉, 吕厚超. 儿童青少年家庭功能障碍与心理健康关系的三水平元分析[J]. 心理科学进展, 2024, 32(5): 771-789. |
| [7] | 郑远霞, 刘国雄, 辛聪, 程黎. 以貌取人:儿童基于面孔的信任判断[J]. 心理科学进展, 2024, 32(2): 300-317. |
| [8] | 高旭亮, 李宁. 机器学习方法在测验安全领域的应用[J]. 心理科学进展, 2024, 32(11): 1814-1828. |
| [9] | 崔楠, 王久菊, 赵婧. 注意缺陷多动障碍−发展性阅读障碍共患儿童的干预效果及其内在机理[J]. 心理科学进展, 2023, 31(4): 622-630. |
| [10] | 张李斌, 张其文, 王晨旭, 张云运. 社会网络视角下儿童青少年同伴关系网络与欺凌相关行为的共同变化关系[J]. 心理科学进展, 2023, 31(3): 416-427. |
| [11] | 陈新文, 李鸿杰, 丁玉珑. 探究事件相关脑电/脑磁信号中的神经表征模式:基于分类解码和表征相似性分析的方法[J]. 心理科学进展, 2023, 31(2): 173-195. |
| [12] | 李运端, 马小凤, 胡钰. 发展性阅读障碍儿童潜在的早期识别标志——节奏异常及其特点[J]. 心理科学进展, 2023, 31(12): 2306-2318. |
| [13] | 邓士昌, 林子涵, 陆昱谦, 李象千. 智能时代的新玩伴:儿童与机器人的互动特征及其对儿童发展的影响[J]. 心理科学进展, 2023, 31(12): 2319-2336. |
| [14] | 李凯茜, 梁丹丹. 发展性阅读障碍风险儿童的大脑异常及阅读障碍的早期神经标记[J]. 心理科学进展, 2023, 31(10): 1912-1923. |
| [15] | 江丹莹, 杨运梅, 李晶. 群体情境下儿童的分配公平性[J]. 心理科学进展, 2022, 30(9): 2004-2019. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||