ISSN 0439-755X
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
心理学报 ›› 2026, Vol. 58 ›› Issue (3): 416-436.doi: 10.3724/SP.J.1041.2026.0416 cstr: 32110.14.2026.0416
周蕾1, 李立统1, 王旭1, 区桦烽1, 胡倩瑜1, 李爱梅2( ), 古晨妍1()
), 古晨妍1()
收稿日期:2025-05-12
发布日期:2025-12-26
出版日期:2026-03-25
通讯作者:
李爱梅, E-mail: tliaim@jnu.edu.cn;基金资助:
ZHOU Lei1, LI Litong1, WANG Xu1, OU Huafeng1, HU Qianyu1, LI Aimei2(), GU Chenyan1()
Received:2025-05-12
Online:2025-12-26
Published:2026-03-25
摘要:
风险决策的理论研究主要依赖行为结果的逆向推理和自我报告数据, 缺乏对决策过程的直接观测, 制约了其内在机制解释及有效行为干预方案开发。人工智能大语言模型(LLMs)的运用为克服以上局限提供了途径。本文通过三项研究系统考察了LLMs在风险决策中的模拟潜力, 基于DeepSeek-R1进行单次和多次博弈并生成决策依据, 并运用GPT-4o对其进行归纳性主题分析(ITA), 构建了LLMs生成决策策略文本的技术路径, 并将其用于决策干预。发现: (1) ChatGPT-3.5/4能复现人类单次(更风险规避)与多次(更风险寻求)博弈的典型选择模式; (2) LLMs能分清单次/多次博弈逻辑, 并正确分别运用规范性和描述性理论生成相应策略, 其策略被认可度高; (3) LLMs基于不同策略生成的干预文本能有效影响人们在医疗、金融、内容创作和电商营销情境中固有的风险决策偏好。研究系统验证LLMs对行为偏好的模拟能力, 对决策的理解力, 并构建了基于生成式AI的决策干预新范式, 为人工智能辅助高风险决策提供了理论和实践基础。
中图分类号:
周蕾, 李立统, 王旭, 区桦烽, 胡倩瑜, 李爱梅, 古晨妍. (2026). 能辨“单次−多次博弈”的大语言模型: 理解与干预风险决策. 心理学报, 58(3), 416-436.
ZHOU Lei, LI Litong, WANG Xu, OU Huafeng, HU Qianyu, LI Aimei, GU Chenyan. (2026). Large language models capable of distinguishing between single and repeated gambles: Understanding and intervening in risky choice. Acta Psychologica Sinica, 58(3), 416-436.
| 赌博游戏任务 | |||
|---|---|---|---|
| 获益结果 | 损失结果 | ||
| 金额(元) | 概率(%) | 金额(元) | 概率(%) |
| +10000 | 10 | −278 | 10 |
| +5000 | 20 | −313 | 20 |
| +3333 | 30 | −357 | 30 |
| +2500 | 40 | −417 | 40 |
| +2000 | 50 | −500 | 50 |
| +1667 | 60 | −625 | 60 |
| +1429 | 70 | −833 | 70 |
| +1250 | 80 | −1250 | 80 |
| +1111 | 90 | −2500 | 90 |
表1 研究1实验任务参数
| 赌博游戏任务 | |||
|---|---|---|---|
| 获益结果 | 损失结果 | ||
| 金额(元) | 概率(%) | 金额(元) | 概率(%) |
| +10000 | 10 | −278 | 10 |
| +5000 | 20 | −313 | 20 |
| +3333 | 30 | −357 | 30 |
| +2500 | 40 | −417 | 40 |
| +2000 | 50 | −500 | 50 |
| +1667 | 60 | −625 | 60 |
| +1429 | 70 | −833 | 70 |
| +1250 | 80 | −1250 | 80 |
| +1111 | 90 | −2500 | 90 |
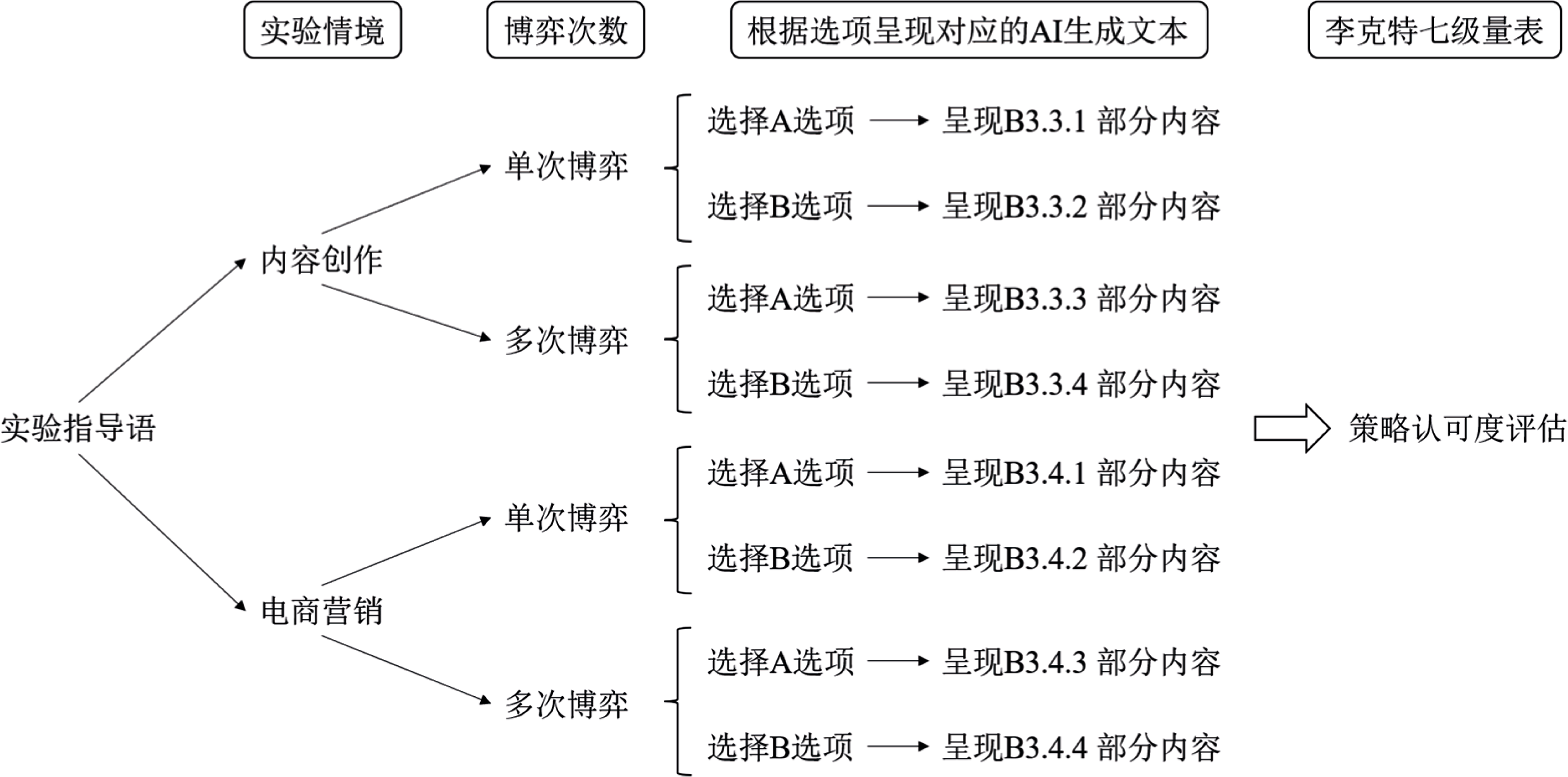
图1 研究1提示词示例
| 自变量 | 回归系数(β) | 标准误(SE) | 95% CI | Wald χ²值 | Exp (β) | p值 |
|---|---|---|---|---|---|---|
| 截距 | 1.867 | 0.098 | [1.679, 2.064] | 362.10 | 6.47 | < 0.001 |
| 博弈次数(多次 = 1, 单次 = 0) | 0.597 | 0.159 | [0.289, 0.911] | 14.17 | 1.82 | < 0.001 |
| 模型类型(GPT-4 = 1, GPT-3.5 = 0) | −0.815 | 0.124 | [−1.061, −0.574] | 43.09 | 0.44 | < 0.001 |
| 博弈次数 ×模型类型 | 0.251 | 0.202 | [−0.149, 0.646] | 1.55 | 1.29 | 0.213 |
表2 研究1回归分析结果
| 自变量 | 回归系数(β) | 标准误(SE) | 95% CI | Wald χ²值 | Exp (β) | p值 |
|---|---|---|---|---|---|---|
| 截距 | 1.867 | 0.098 | [1.679, 2.064] | 362.10 | 6.47 | < 0.001 |
| 博弈次数(多次 = 1, 单次 = 0) | 0.597 | 0.159 | [0.289, 0.911] | 14.17 | 1.82 | < 0.001 |
| 模型类型(GPT-4 = 1, GPT-3.5 = 0) | −0.815 | 0.124 | [−1.061, −0.574] | 43.09 | 0.44 | < 0.001 |
| 博弈次数 ×模型类型 | 0.251 | 0.202 | [−0.149, 0.646] | 1.55 | 1.29 | 0.213 |
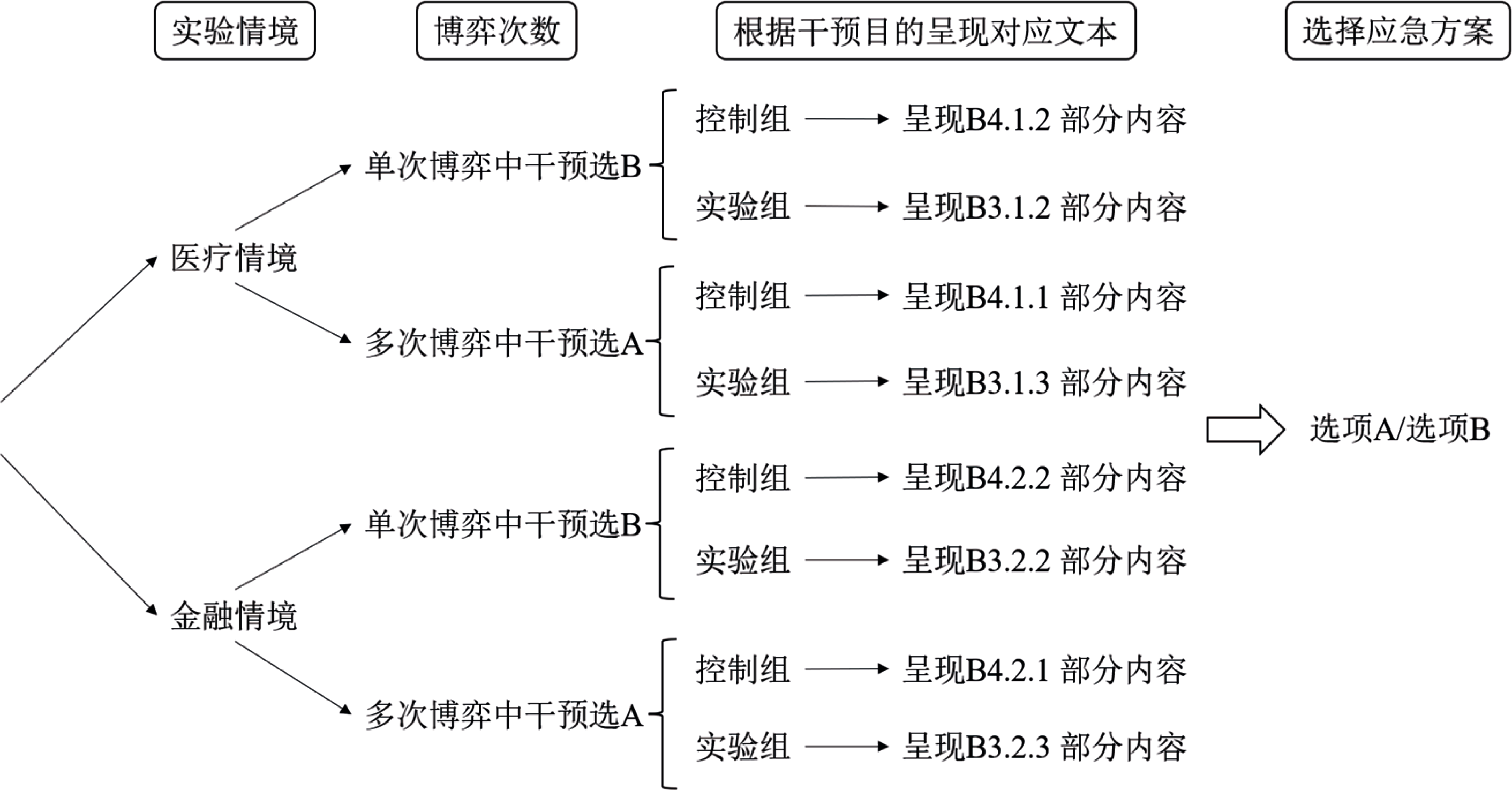
图2 研究1中LLMs和人类在单次和多次博弈中选择参加赌博的比例 注: A. 为GPT(3.5/4)在所有概率条件下选择参加赌博游戏的平均比例; B. 为GPT(3.5/4)概率为50%的条件下选择参加赌博游戏的比例, 以及Redelmeier和Tversky (1992)等人论文中同等概率条件下人类的数据结果。图中每组柱状图自左至右分别代表GPT-3.5、GPT-4与人类组。彩图见电子版, 下同。
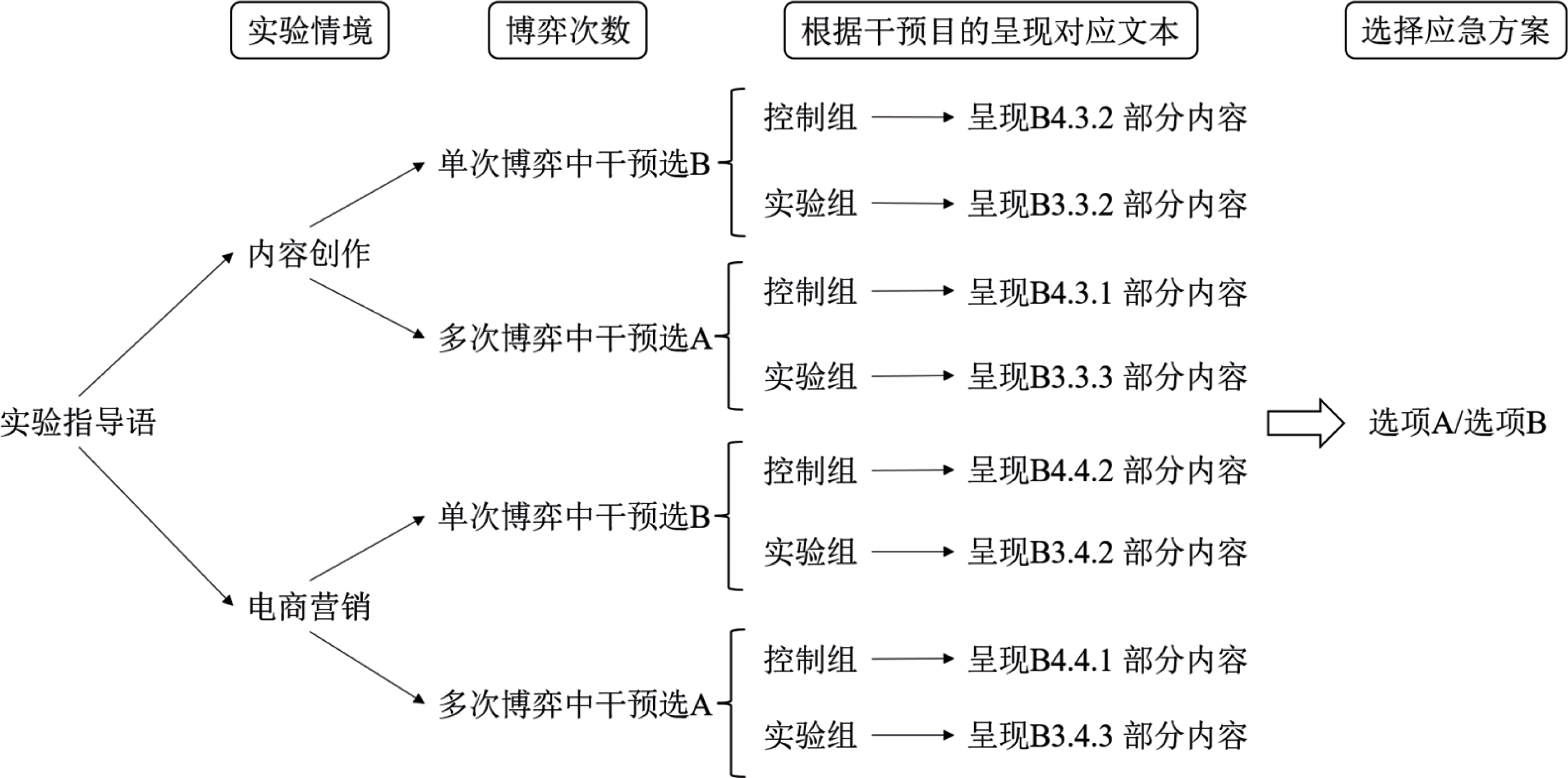
图3 LLMs生成决策策略流程图

图4 研究2归纳性主题分析的提示词示例

图5 研究2实验任务及LLMs生成的决策策略示例
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 博弈次数(多次 = 1, 单次 = 0) | 1.967 | 0.175 | 11.245 | [1.624, 2.309] | < 0.001 |
| 实验情境(金融 = 1, 医疗 = 0) | −1.828 | 0.242 | −7.549 | [−2.303, −1.354] | < 0.001 |
| 博弈次数 × 实验情境 | 0.766 | 0.265 | 2.886 | [0.246, 1.286] | 0.004 |
表3 博弈次数与实验情境及其交互作用对风险决策倾向的累积链接混合模型回归结果
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 博弈次数(多次 = 1, 单次 = 0) | 1.967 | 0.175 | 11.245 | [1.624, 2.309] | < 0.001 |
| 实验情境(金融 = 1, 医疗 = 0) | −1.828 | 0.242 | −7.549 | [−2.303, −1.354] | < 0.001 |
| 博弈次数 × 实验情境 | 0.766 | 0.265 | 2.886 | [0.246, 1.286] | 0.004 |
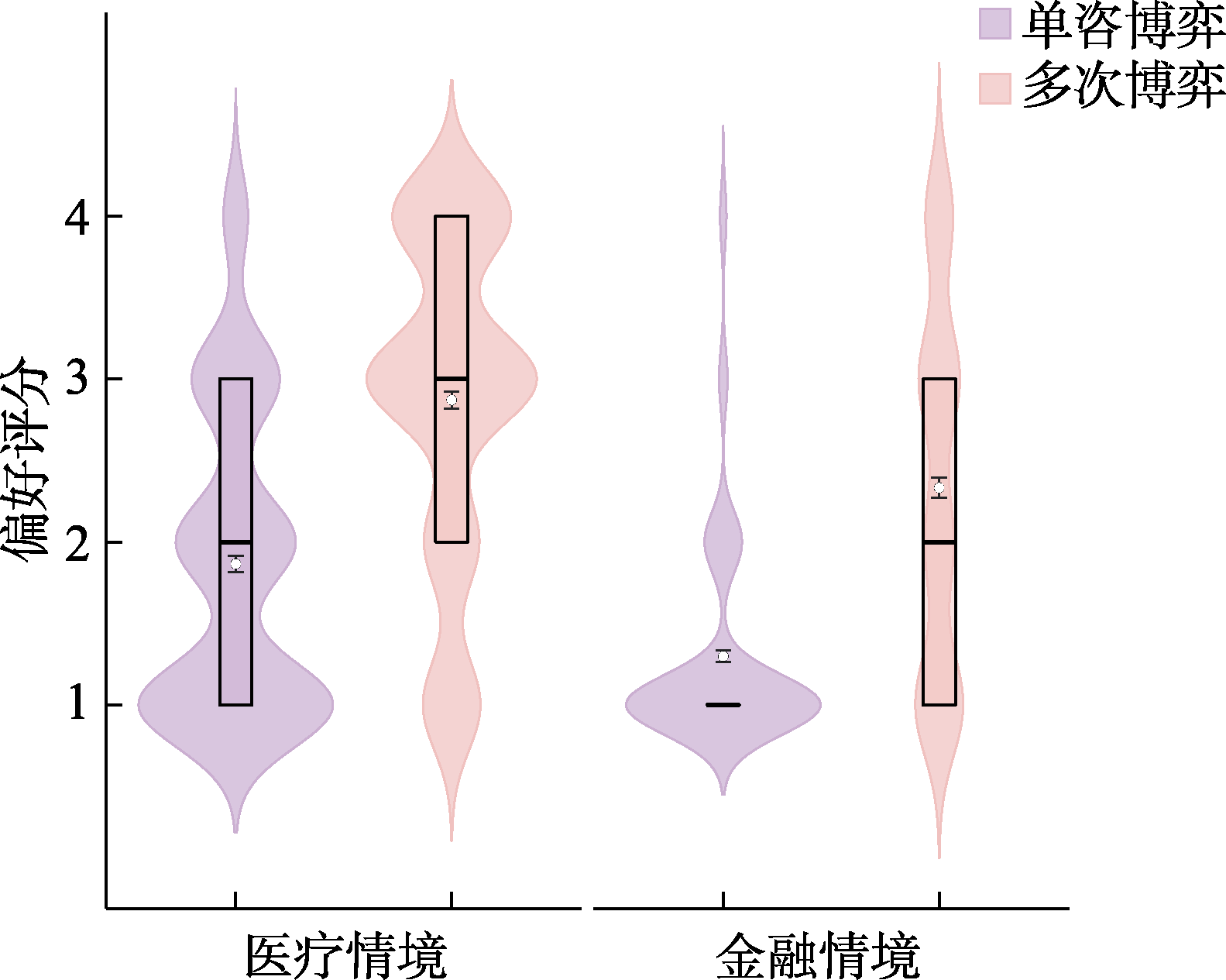
图6 研究2实验1中医疗与金融情境在单次与多次博弈任务中的选择分布 注: 图中纵轴评分采用4点量表, 方案A代表确定选项, 方案B代表风险选项。其中“1”表示“非常可能选择方案A”, “2”表示“可能选择方案A”, “3”表示“可能选择方案B”, “4”表示“非常可能选择方案B”。箱线图的横线自上而下分别为上四分位数、中位数、下四分位数, 横线重合则表示对应统计值相同; 白色圆点为均值M, 误差线为标准误SE。每对分布图由左至右分别为单次博弈和多次博弈条件。
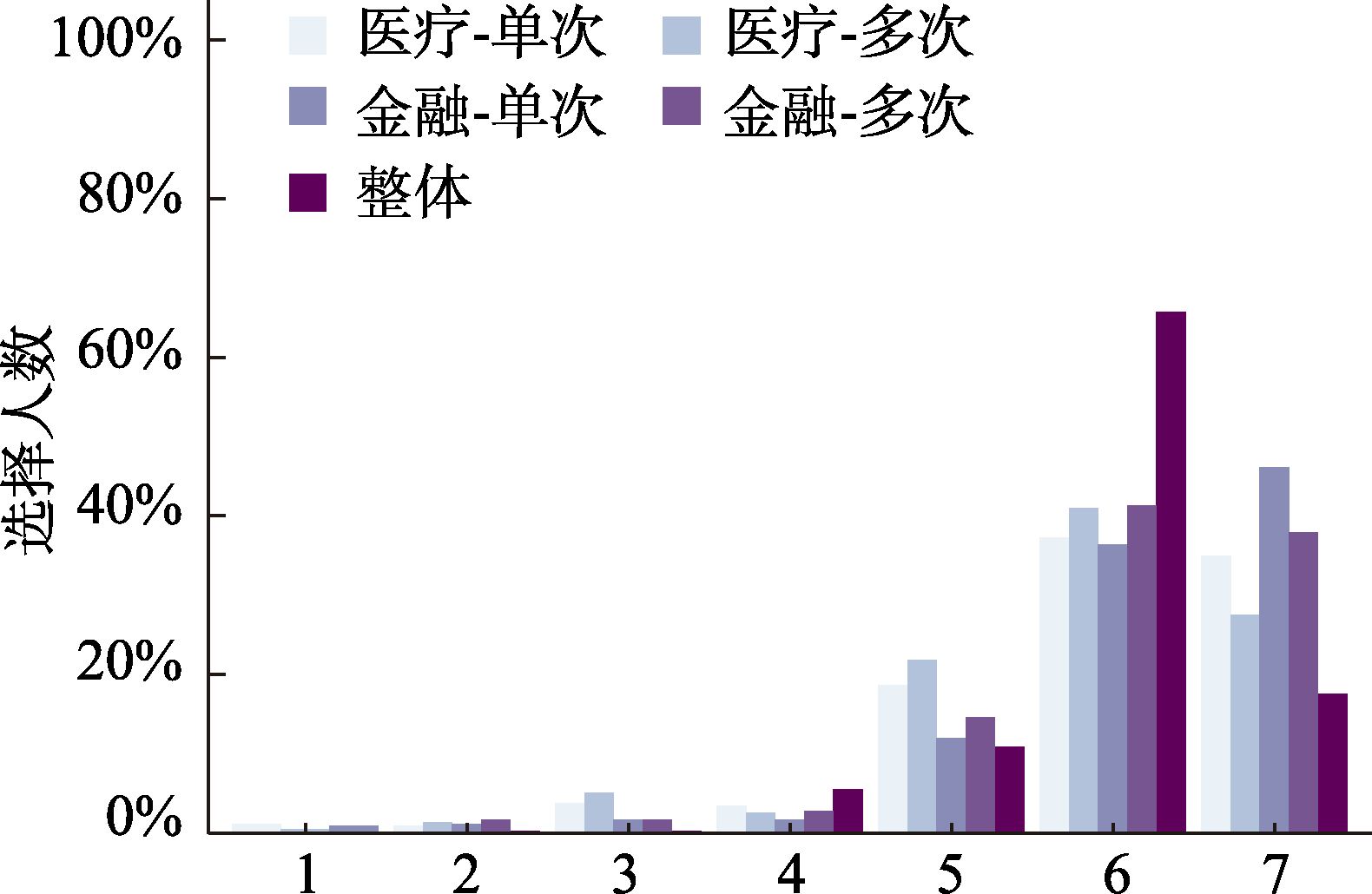
图7 研究2实验1中各组被试对决策策略认可度评分的分布 注: 横坐标表示策略文本与个体在决策过程中思考路径的相似程度, 评分采用7点量表(1 = “完全不相似”, 7 = “完全相似”)。每组柱状图由左至右依次为医疗−单次、医疗−多次、金融−单次、金融−多次及整体(4个情境样本合并后的总体分布)条件下该分数的统计数。
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 博弈次数(多次 = 1, 单次 = 0) | 0.635 | 0.263 | 2.415 | [0.120, 1.151] | 0.016 |
| 实验情境(创作 = 1, 营销 = 0) | 0.619 | 0.273 | 2.272 | [0.085, 1.153] | 0.023 |
| 博弈次数 × 实验情境 | −0.003 | 0.362 | −0.009 | [−0.713, 0.706] | 0.993 |
表4 博弈次数与实验情境及其交互作用对风险决策倾向的累积链接混合模型回归结果
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 博弈次数(多次 = 1, 单次 = 0) | 0.635 | 0.263 | 2.415 | [0.120, 1.151] | 0.016 |
| 实验情境(创作 = 1, 营销 = 0) | 0.619 | 0.273 | 2.272 | [0.085, 1.153] | 0.023 |
| 博弈次数 × 实验情境 | −0.003 | 0.362 | −0.009 | [−0.713, 0.706] | 0.993 |
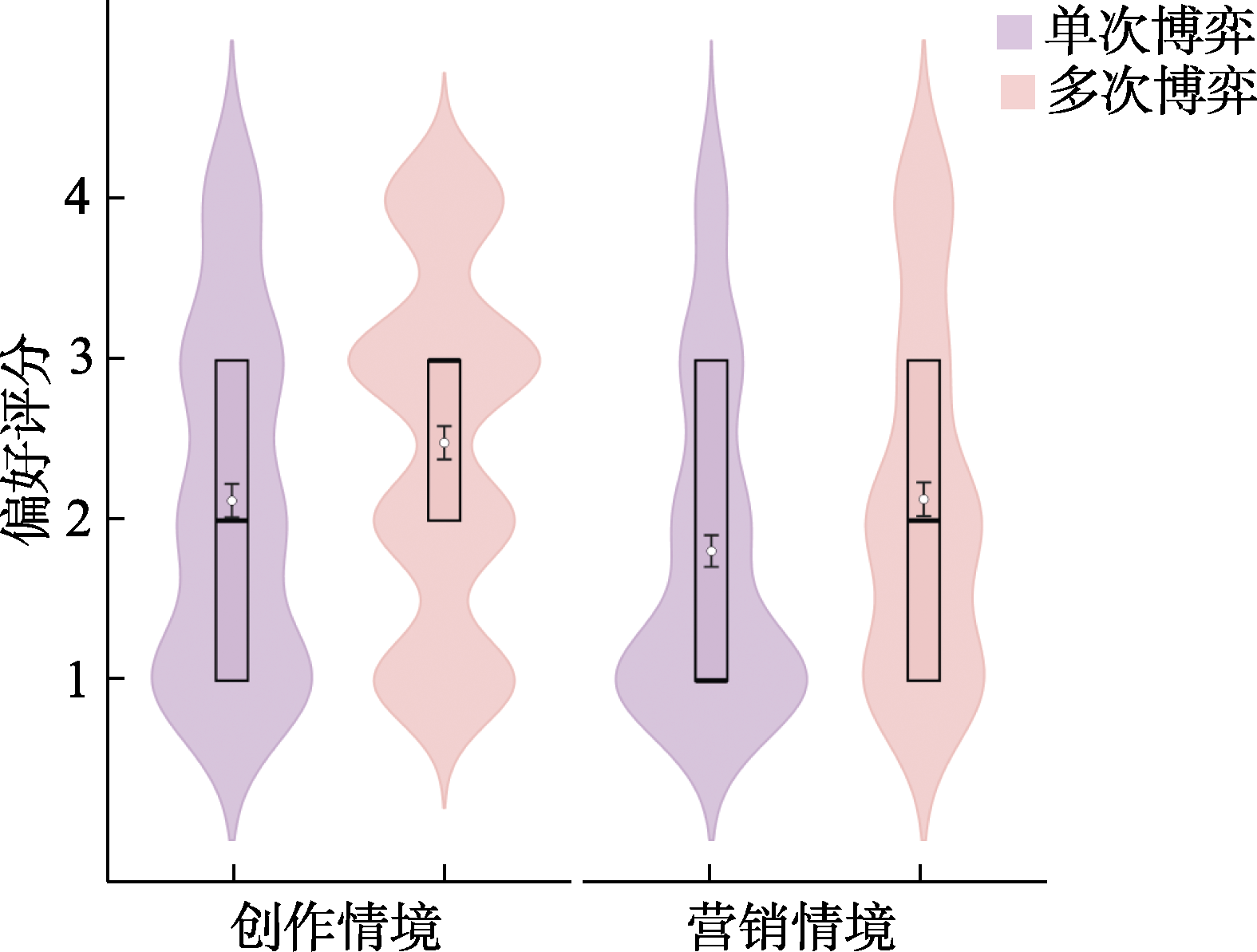
图8 研究2实验2中内容创作与电商营销情境在单次与多次博弈任务中的选择分布 注: 图中纵轴评分采用4点量表, 方案A代表确定选项, 方案B代表风险选项。其中“1”表示“非常可能选择方案A”, “2”表示“可能选择方案A”, “3”表示“可能选择方案B”, “4”表示“非常可能选择方案B”。箱线图的横线自上而下分别为上四分位数、中位数、下四分位数, 横线重合则表示对应统计值相同; 白色圆点为均值M, 误差线为标准误SE。每对分布图由左至右分别为单次博弈和多次博弈条件。
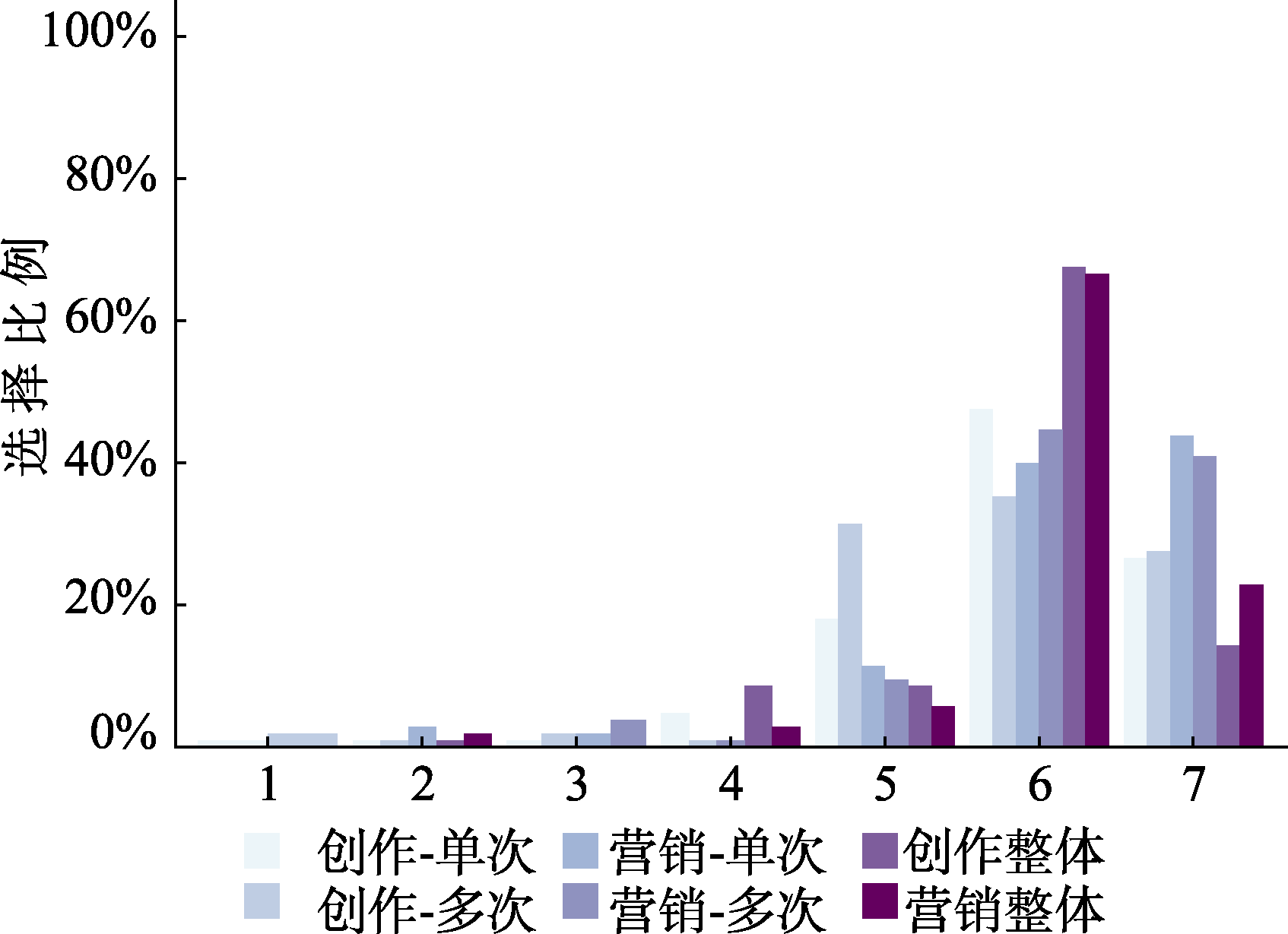
图9 研究2实验2中各组被试对决策策略认可度评分的分布 注: 横坐标表示策略文本与个体在决策过程中思考路径的相似程度, 评分采用7点量表(1 = 完全不相似, 7 = 完全相似)。每组柱状图由左至右依次为创作−单次、创作−多次、营销−单次、营销−多次、创作整体及营销整体(分别表示对应情境下两个博弈条件样本合并后的总体分布)条件下该分数的统计人数。
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 文本类型(干预 = 1, 控制 = 0) | 1.072 | 0.180 | 5.940 | [0.718, 1.426] | < 0.001 |
| 博弈次数(多次 = 1, 单次 = 0) | 1.500 | 0.203 | 7.397 | [1.103, 1.898] | < 0.001 |
| 实验情境(金融 = 1, 医疗 = 0) | −1.518 | 0.232 | −6.530 | [−1.974, −1.062] | < 0.001 |
| 文本类型 × 博弈次数 | −1.840 | 0.284 | −6.480 | [−2.397, −1.284] | < 0.001 |
| 文本类型 × 实验情境 | 0.096 | 0.283 | 0.339 | [−0.458, 0.650] | 0.735 |
| 博弈次数 × 实验情境 | 0.503 | 0.288 | 1.749 | [−0.061, 1.067] | 0.080 |
| 文本类型 × 博弈次数 × 实验情境 | −0.220 | 0.384 | −0.573 | [−0.972, 0.532] | 0.567 |
表5 文本类型、博弈次数与实验情境及其交互作用对风险决策倾向的累积链接混合模型回归结果
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 文本类型(干预 = 1, 控制 = 0) | 1.072 | 0.180 | 5.940 | [0.718, 1.426] | < 0.001 |
| 博弈次数(多次 = 1, 单次 = 0) | 1.500 | 0.203 | 7.397 | [1.103, 1.898] | < 0.001 |
| 实验情境(金融 = 1, 医疗 = 0) | −1.518 | 0.232 | −6.530 | [−1.974, −1.062] | < 0.001 |
| 文本类型 × 博弈次数 | −1.840 | 0.284 | −6.480 | [−2.397, −1.284] | < 0.001 |
| 文本类型 × 实验情境 | 0.096 | 0.283 | 0.339 | [−0.458, 0.650] | 0.735 |
| 博弈次数 × 实验情境 | 0.503 | 0.288 | 1.749 | [−0.061, 1.067] | 0.080 |
| 文本类型 × 博弈次数 × 实验情境 | −0.220 | 0.384 | −0.573 | [−0.972, 0.532] | 0.567 |
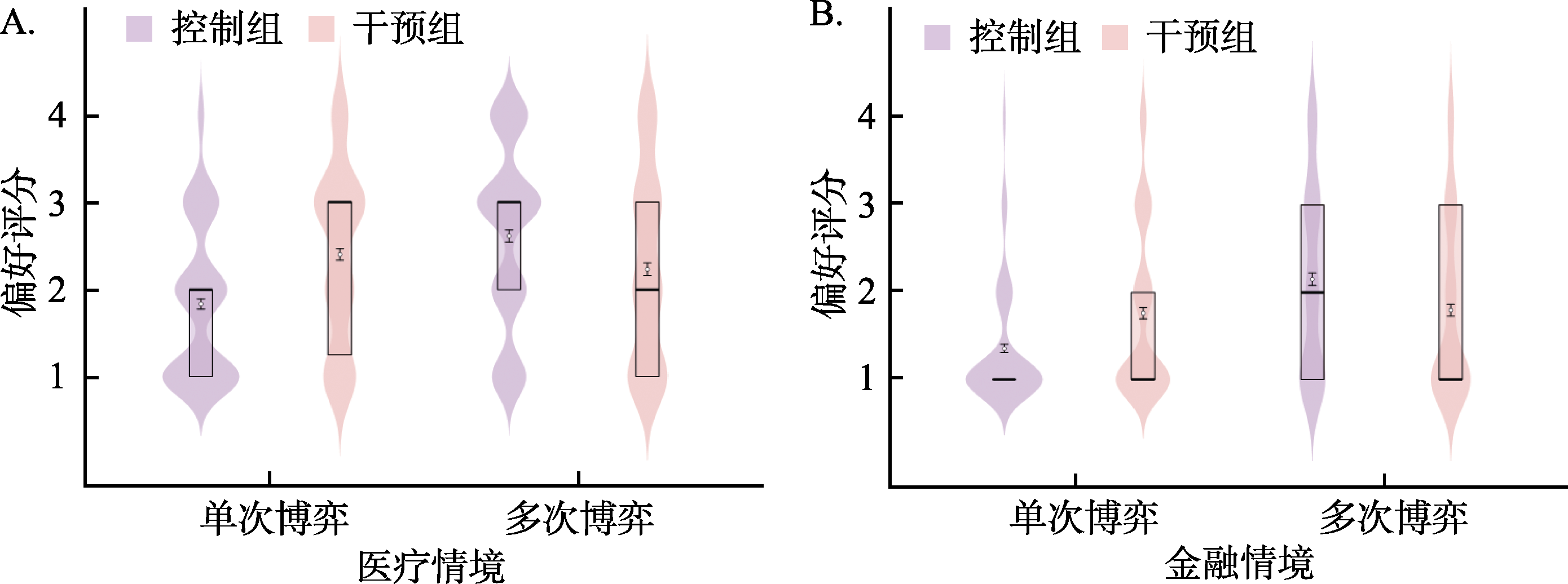
图10 研究3实验1中医疗与金融情境在单次与多次博弈任务中的选择分布 注: 在图A与图B中, 纵轴评分采用4点量表, 方案A代表确定选项, 方案B代表风险选项。其中“1”表示“非常可能选择方案A”, “2”表示“可能选择方案A”, “3”表示“可能选择方案B”, “4”表示“非常可能选择方案B”。箱线图的横线自上而下分别为上四分位数、中位数、下四分位数, 横线重合则表示对应统计值相同; 白色圆点为均值M, 误差线为标准误SE。每对分布图由左至右分别为控制组和干预组。
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 文本类型(干预 = 1, 控制 = 0) | 0.961 | 0.335 | 2.867 | [0.304, 1.619] | 0.004 |
| 博弈次数(多次 = 1, 单次 = 0) | 0.819 | 0.350 | 2.341 | [0.133, 1.505] | 0.019 |
| 实验情境(创作 = 1, 营销 = 0) | 0.917 | 0.335 | 2.735 | [0.260, 1.574] | 0.006 |
| 文本类型 × 博弈次数 | −2.101 | 0.487 | −4.314 | [−3.056, −1.147] | < 0.001 |
| 文本类型 × 实验情境 | −0.266 | 0.464 | −0.572 | [−1.176, 0.645] | 0.567 |
| 博弈次数 × 实验情境 | −0.534 | 0.471 | −1.132 | [−1.457, 0.390] | 0.257 |
| 文本类型 × 博弈次数 × 实验情境 | 0.070 | 0.666 | 0.105 | [−1.235, 1.375] | 0.916 |
表6 文本类型、博弈次数与实验情境及其交互作用对风险决策倾向的累积链接混合模型回归结果
| 变量类型 | 回归系数(β) | 标准差(SE) | z | 95% CI | p值 |
|---|---|---|---|---|---|
| 文本类型(干预 = 1, 控制 = 0) | 0.961 | 0.335 | 2.867 | [0.304, 1.619] | 0.004 |
| 博弈次数(多次 = 1, 单次 = 0) | 0.819 | 0.350 | 2.341 | [0.133, 1.505] | 0.019 |
| 实验情境(创作 = 1, 营销 = 0) | 0.917 | 0.335 | 2.735 | [0.260, 1.574] | 0.006 |
| 文本类型 × 博弈次数 | −2.101 | 0.487 | −4.314 | [−3.056, −1.147] | < 0.001 |
| 文本类型 × 实验情境 | −0.266 | 0.464 | −0.572 | [−1.176, 0.645] | 0.567 |
| 博弈次数 × 实验情境 | −0.534 | 0.471 | −1.132 | [−1.457, 0.390] | 0.257 |
| 文本类型 × 博弈次数 × 实验情境 | 0.070 | 0.666 | 0.105 | [−1.235, 1.375] | 0.916 |
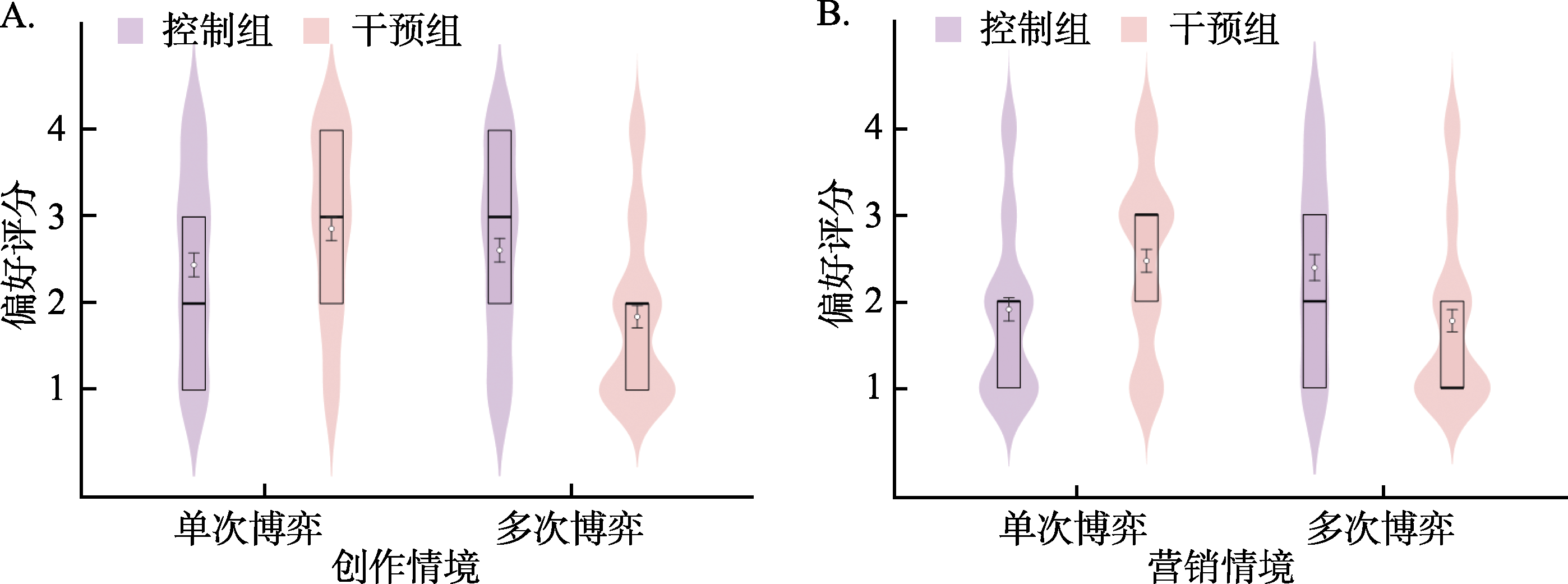
图11 研究3实验2中内容创作与电商营销情境在单次与多次博弈任务中的选择分布 注: 在图A与图B中, 纵轴评分采用4点量表, 方案A代表确定选项, 方案B代表风险选项。其中“1”表示“非常可能选择方案A”, “2”表示“可能选择方案A”, “3”表示“可能选择方案B”, “4”表示“非常可能选择方案B”。箱线图的横线自上而下分别为上四分位数、中位数、下四分位数, 横线重合则表示对应统计值相同; 白色圆点为均值M, 误差线为标准误SE。每对分布图由左至右分别为控制组和干预组。
图S1 研究2实验1问卷流程示意图
图S2 研究2实验2问卷流程示意图
图S3 研究3实验1问卷流程示意图
图S4 研究3实验2问卷流程示意图
| 评测基准(指标) | Claude-3.5-Sonnet-1022 | GPT-4o0513 | DeepSeek-V3 | OpenAIo1- mini | OpenAIo1- 1217 | DeepSeek-R1 | |
|---|---|---|---|---|---|---|---|
| 数学 | AIME2024(Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500(Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| 编程 | LiveCodeBench (Pass@1-COT) | 38.9 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| 开放任务 | AlpacaEval2.0(LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | |
| 中文测试集 | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | |
表S1 DeepSeek-R1与其他主流模型的比较
| 评测基准(指标) | Claude-3.5-Sonnet-1022 | GPT-4o0513 | DeepSeek-V3 | OpenAIo1- mini | OpenAIo1- 1217 | DeepSeek-R1 | |
|---|---|---|---|---|---|---|---|
| 数学 | AIME2024(Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500(Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| 编程 | LiveCodeBench (Pass@1-COT) | 38.9 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| 开放任务 | AlpacaEval2.0(LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | |
| 中文测试集 | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | |
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 6.67/7.32 | 受教育程度 | 大学专科及以下 | 6.67/14.63 |
| 20~22 | 26.67/17.07 | 大学本科 | 80.00/73.17 | ||
| 23~25 | 9.99/4.88 | 硕士及以上 | 13.33/12.20 | ||
| 26及以上 | 56.67/70.73 | 专业类别 | 法学类 | 10.00/2.44 | |
| 性别 | 男 | 36.67/43.90 | 经管类 | 36.67/31.70 | |
| 女 | 63.33/56.10 | 理工类 | 43.33/60.98 | ||
| 工作年限 | 2年及以下 | 20.00/17.65 | 医学类 | 3.33/2.44 | |
| 3~5年 | 15.00/20.59 | 艺术类 | 6.67/2.44 | ||
| 6年及以上 | 65.00/61.76 | 其他 | 0.00/0.00 |
表S2 内容评估中被试的人口学分布
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 6.67/7.32 | 受教育程度 | 大学专科及以下 | 6.67/14.63 |
| 20~22 | 26.67/17.07 | 大学本科 | 80.00/73.17 | ||
| 23~25 | 9.99/4.88 | 硕士及以上 | 13.33/12.20 | ||
| 26及以上 | 56.67/70.73 | 专业类别 | 法学类 | 10.00/2.44 | |
| 性别 | 男 | 36.67/43.90 | 经管类 | 36.67/31.70 | |
| 女 | 63.33/56.10 | 理工类 | 43.33/60.98 | ||
| 工作年限 | 2年及以下 | 20.00/17.65 | 医学类 | 3.33/2.44 | |
| 3~5年 | 15.00/20.59 | 艺术类 | 6.67/2.44 | ||
| 6年及以上 | 65.00/61.76 | 其他 | 0.00/0.00 |
| 变量类别 | t值 | p值 | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| 总体评分 | 39.48/68.91 | < 0.001/< 0.001 | 7.21/10.76 | 5.38/5.49 | 0.26/0.18 |
| 合理性 | 19.81/32.72 | < 0.001/< 0.001 | 3.62/5.20 | 5.40/5.20 | 0.52/0.33 |
| 专业性 | 20.14/32.44 | < 0.001/< 0.001 | 3.68/5.31 | 5.46/5.31 | 0.53/0.36 |
| 逻辑性 | 16.52/43.91 | < 0.001/< 0.001 | 3.02/5.48 | 5.34/5.48 | 0.61/0.29 |
| 可读性 | 16.39/42.64 | < 0.001/< 0.001 | 2.99/5.64 | 5.42/5.64 | 0.64/0.32 |
| 说服力 | 17.64/43.27 | < 0.001/< 0.001 | 3.22/5.81 | 5.30/5.81 | 0.56/0.34 |
表S3 内容评估结果
| 变量类别 | t值 | p值 | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| 总体评分 | 39.48/68.91 | < 0.001/< 0.001 | 7.21/10.76 | 5.38/5.49 | 0.26/0.18 |
| 合理性 | 19.81/32.72 | < 0.001/< 0.001 | 3.62/5.20 | 5.40/5.20 | 0.52/0.33 |
| 专业性 | 20.14/32.44 | < 0.001/< 0.001 | 3.68/5.31 | 5.46/5.31 | 0.53/0.36 |
| 逻辑性 | 16.52/43.91 | < 0.001/< 0.001 | 3.02/5.48 | 5.34/5.48 | 0.61/0.29 |
| 可读性 | 16.39/42.64 | < 0.001/< 0.001 | 2.99/5.64 | 5.42/5.64 | 0.64/0.32 |
| 说服力 | 17.64/43.27 | < 0.001/< 0.001 | 3.22/5.81 | 5.30/5.81 | 0.56/0.34 |
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 9.74 | 受教育程度 | 普高/中专/技校/职高 | 1.15 |
| 20~22 | 57.02 | 大学专科 | 6.59 | ||
| 23~25 | 32.09 | 大学本科 | 75.36 | ||
| 26及以上 | 1.15 | 硕士及以上 | 16.90 | ||
| 性别 | 男 | 49.86 | 专业类别 | 法学类 | 6.31 |
| 女 | 50.14 | 经管类 | 32.66 | ||
| 月收入 | 1000元及以下 | 5.73 | 理工类 | 47.85 | |
| 1001元~1500元 | 35.24 | 医学类 | 6.30 | ||
| 1501元~2000元 | 28.08 | 艺术类 | 5.73 | ||
| 2001元及以上 | 30.95 | 其他 | 1.15 |
表S4 研究2实验1被试的人口学分布
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 9.74 | 受教育程度 | 普高/中专/技校/职高 | 1.15 |
| 20~22 | 57.02 | 大学专科 | 6.59 | ||
| 23~25 | 32.09 | 大学本科 | 75.36 | ||
| 26及以上 | 1.15 | 硕士及以上 | 16.90 | ||
| 性别 | 男 | 49.86 | 专业类别 | 法学类 | 6.31 |
| 女 | 50.14 | 经管类 | 32.66 | ||
| 月收入 | 1000元及以下 | 5.73 | 理工类 | 47.85 | |
| 1001元~1500元 | 35.24 | 医学类 | 6.30 | ||
| 1501元~2000元 | 28.08 | 艺术类 | 5.73 | ||
| 2001元及以上 | 30.95 | 其他 | 1.15 |
| 变量类别 | t(df) | p值 | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| 整体 | t(348) = 63.04 | < 0.001 | 3.37 | 5.97 | 0.73 |
| 医疗-单次 | t(348) = 37.42 | < 0.001 | 2.00 | 5.89 | 1.19 |
| 医疗-多次 | t(348) = 36.00 | < 0.001 | 1.93 | 5.77 | 1.18 |
| 金融-单次 | t(348) = 45.87 | < 0.001 | 2.46 | 6.17 | 1.09 |
| 金融-多次 | t(348) = 46.16 | < 0.001 | 2.47 | 6.05 | 1.03 |
表S5 研究2实验1各组被试对决策策略认可度评分的结果
| 变量类别 | t(df) | p值 | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| 整体 | t(348) = 63.04 | < 0.001 | 3.37 | 5.97 | 0.73 |
| 医疗-单次 | t(348) = 37.42 | < 0.001 | 2.00 | 5.89 | 1.19 |
| 医疗-多次 | t(348) = 36.00 | < 0.001 | 1.93 | 5.77 | 1.18 |
| 金融-单次 | t(348) = 45.87 | < 0.001 | 2.46 | 6.17 | 1.09 |
| 金融-多次 | t(348) = 46.16 | < 0.001 | 2.47 | 6.05 | 1.03 |
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 6.19 | 受教育程度 | 大学专科及以下 | 12.86 |
| 20~22 | 25.71 | 大学本科 | 69.52 | ||
| 23~25 | 18.57 | 硕士及以上 | 17.62 | ||
| 26及以上 | 49.52 | 专业类别 | 法学类 | 5.71 | |
| 性别 | 男 | 43.81 | 经管类 | 38.57 | |
| 女 | 56.19 | 理工类 | 44.29 | ||
| 工作年限 | 2年及以下 | 36.67 | 医学类 | 4.29 | |
| 3~5年 | 20.00 | 艺术类 | 5.71 | ||
| 6年及以上 | 43.33 | 其他 | 1.43 |
表S6 研究2实验2被试的人口学分布
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 6.19 | 受教育程度 | 大学专科及以下 | 12.86 |
| 20~22 | 25.71 | 大学本科 | 69.52 | ||
| 23~25 | 18.57 | 硕士及以上 | 17.62 | ||
| 26及以上 | 49.52 | 专业类别 | 法学类 | 5.71 | |
| 性别 | 男 | 43.81 | 经管类 | 38.57 | |
| 女 | 56.19 | 理工类 | 44.29 | ||
| 工作年限 | 2年及以下 | 36.67 | 医学类 | 4.29 | |
| 3~5年 | 20.00 | 艺术类 | 5.71 | ||
| 6年及以上 | 43.33 | 其他 | 1.43 |
| 变量类别 | t(df) | p值 | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| 整体 | t(209) = 41.78 | < 0.001 | 2.88 | 5.99 | 0.86 |
| 创作-单次 | t(104) = 23.12 | < 0.001 | 2.26 | 5.88 | 1.05 |
| 创作-多次 | t(104) = 19.64 | < 0.001 | 2.00 | 5.75 | 1.17 |
| 营销-单次 | t(104) = 25.14 | < 0.001 | 2.45 | 6.15 | 1.08 |
| 营销-多次 | t(104) = 29.60 | < 0.001 | 2.89 | 6.18 | 0.93 |
表S7 研究2实验2的各组被试对决策策略认可度评分的结果
| 变量类别 | t(df) | p值 | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| 整体 | t(209) = 41.78 | < 0.001 | 2.88 | 5.99 | 0.86 |
| 创作-单次 | t(104) = 23.12 | < 0.001 | 2.26 | 5.88 | 1.05 |
| 创作-多次 | t(104) = 19.64 | < 0.001 | 2.00 | 5.75 | 1.17 |
| 营销-单次 | t(104) = 25.14 | < 0.001 | 2.45 | 6.15 | 1.08 |
| 营销-多次 | t(104) = 29.60 | < 0.001 | 2.89 | 6.18 | 0.93 |
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 10.22 | 受教育程度 | 普高/中专/技校/职高 | 2.17 |
| 20~22 | 54.78 | 大学专科 | 6.09 | ||
| 23~25 | 34.78 | 大学本科 | 72.61 | ||
| 26及以上 | 0.22 | 硕士及以上 | 19.13 | ||
| 性别 | 男 | 44.57 | 专业类别 | 法学类 | 7.61 |
| 女 | 55.47 | 经管类 | 30.22 | ||
| 月收入 | 1000元及以下 | 11.52 | 理工类 | 45.65 | |
| 1001元~1500元 | 28.91 | 医学类 | 7.61 | ||
| 1501元~2000元 | 29.57 | 艺术类 | 6.74 | ||
| 2001元及以上 | 30.00 | 其他 | 2.17 |
表S8 研究3实验1被试的人口学分布
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 10.22 | 受教育程度 | 普高/中专/技校/职高 | 2.17 |
| 20~22 | 54.78 | 大学专科 | 6.09 | ||
| 23~25 | 34.78 | 大学本科 | 72.61 | ||
| 26及以上 | 0.22 | 硕士及以上 | 19.13 | ||
| 性别 | 男 | 44.57 | 专业类别 | 法学类 | 7.61 |
| 女 | 55.47 | 经管类 | 30.22 | ||
| 月收入 | 1000元及以下 | 11.52 | 理工类 | 45.65 | |
| 1001元~1500元 | 28.91 | 医学类 | 7.61 | ||
| 1501元~2000元 | 29.57 | 艺术类 | 6.74 | ||
| 2001元及以上 | 30.00 | 其他 | 2.17 |
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 5.42 | 受教育程度 | 大学专科及以下 | 10.42 |
| 20~22 | 24.58 | 大学本科 | 75.83 | ||
| 23~25 | 16.67 | 硕士及以上 | 13.75 | ||
| 26及以上 | 53.33 | 专业类别 | 法学类 | 6.25 | |
| 性别 | 男 | 44.17 | 经管类 | 38.75 | |
| 女 | 55.83 | 理工类 | 45.42 | ||
| 工作年限 | 2年及以下 | 16.03 | 医学类 | 4.17 | |
| 3~5年 | 20.51 | 艺术类 | 4.58 | ||
| 6年及以上 | 63.46 | 其他 | 0.83 |
表S9 研究3实验2被试的人口学分布
| 变量 | 类别 | 占比(%) | 变量 | 类别 | 占比(%) |
|---|---|---|---|---|---|
| 年龄 | 19及以下 | 5.42 | 受教育程度 | 大学专科及以下 | 10.42 |
| 20~22 | 24.58 | 大学本科 | 75.83 | ||
| 23~25 | 16.67 | 硕士及以上 | 13.75 | ||
| 26及以上 | 53.33 | 专业类别 | 法学类 | 6.25 | |
| 性别 | 男 | 44.17 | 经管类 | 38.75 | |
| 女 | 55.83 | 理工类 | 45.42 | ||
| 工作年限 | 2年及以下 | 16.03 | 医学类 | 4.17 | |
| 3~5年 | 20.51 | 艺术类 | 4.58 | ||
| 6年及以上 | 63.46 | 其他 | 0.83 |
| [1] | Achiam J., Adler S., Agarwal S., Ahmad L., Akkaya I., Aleman F. L.,... McGrew B. (2023). GPT-4 technical report. arXiv preprint. https://doi.org/10.48550/arXiv.2303.08774 |
| [2] | Aher G. V., Arriaga R. I., & Kalai A. T. (2023). Using large language models to simulate multiple humans and replicate human subject studies. In Proceedings of the 40th International Conference on Machine Learning (pp. 337-371). PMLR. https://proceedings.mlr.press/v202/aher23a.html |
| [3] |
Altay S., Hacquin A. S., Chevallier C., & Mercier H. (2023). Information delivered by a chatbot has a positive impact on COVID-19 vaccines attitudes and intentions. Journal of Experimental Psychology: Applied, 29(1), 52-62. https://doi.org/10.1037/xap0000400
doi: 10.1037/xap0000400 URL |
| [4] |
Anderson M. A. B., Cox D. J., & Dallery J. (2023). Effects of economic context and reward amount on delay and probability discounting. Journal of the Experimental Analysis of Behavior, 120(2), 204-213. https://doi.org/10.1002/jeab.868
doi: 10.1002/jeab.868 URL pmid: 37311053 |
| [5] |
Argyle L. P., Busby E. C., Fulda N., Gubler J., Rytting C., & Wingate D. (2023). Out of one, many: Using language models to simulate human samples. Political Analysis, 31(3), 337-351. https://doi.org/10.1017/pan.2023.2
doi: 10.1017/pan.2023.2 URL |
| [6] | Arora C., Sayeed A. I., Licorish S., Wang F., & Treude C. (2024). Optimizing large language model hyperparameters for code generation. arXiv preprint. https://doi.org/10.48550/arXiv.2408.10577 |
| [7] |
Barberis N., & Huang M. (2009). Preferences with frames: A new utility specification that allows for the framing of risks. Journal of Economic Dynamics and Control, 33(8), 1555-1576. https://doi.org/10.1016/j.jedc.2009.01.009
doi: 10.1016/j.jedc.2009.01.009 URL |
| [8] |
Benartzi S., & Thaler R. H. (1999). Risk aversion or myopia? Choices in repeated gambles and retirement investments. Management Science, 45(3), 364-381. https://doi.org/10.1287/mnsc.45.3.364
doi: 10.1287/mnsc.45.3.364 URL |
| [9] |
Binz M., & Schulz E. (2023). Using cognitive psychology to understand GPT-3. Proceedings of the National Academy of Sciences, 120(6), e2218523120. https://doi.org/10.1073/pnas.2218523120
doi: 10.1073/pnas.2218523120 URL |
| [10] |
Brandstätter E., Gigerenzer G., & Hertwig R. (2006). The priority heuristic: Making choices without trade-offs. Psychological Review, 113(2), 409-432. https://doi.org/10.1037/0033-295X.113.2.409
doi: 10.1037/0033-295X.113.2.409 URL pmid: 16637767 |
| [11] | Brislin, R. W. (1986). The wording and translation of research instruments. In W. J. Lonner & J. W. Berry (Eds.), Field methods in cross-cultural research (pp. 137-164). Sage Publications. |
| [12] | Brown T., Mann B., Ryder N., Subbiah M., Kaplan J. D., Dhariwal P., … Amodei D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901. https://doi.org/10.48550/arXiv.2005.14165 |
| [13] | Carvalho T., Negm H., & El-Geneidy A. (2024). A comparison of the results from artificial intelligence-based and human-based transport-related thematic analysis. Findings. https://doi.org/10.32866/001c.94401 |
| [14] |
Chen Y., Liu T. X., Shan Y., & Zhong S. (2023). The emergence of economic rationality of GPT. Proceedings of the National Academy of Sciences, 120(51), e2316205120. https://doi.org/10.1073/pnas.2316205120
doi: 10.1073/pnas.2316205120 URL |
| [15] |
Choi S., Kang H., Kim N., & Kim J. (2025). How does artificial intelligence improve human decision-making? Evidence from the AI-powered Go program. Strategic Management Journal, 46(6), 1523-1554. https://doi.org/10.1002/smj.3694
doi: 10.1002/smj.v46.6 URL |
| [16] | Christensen R. H. B. (2023). ordinal: Regression models for ordinal data (R package version 2023.12-4.1) [Computer software]. https://CRAN.R-project.org/package=ordinal |
| [17] | Coda-Forno J., Witte K., Jagadish A. K., Binz M., Akata Z., & Schulz E. (2023). Inducing anxiety in large language models can induce bias. arXiv preprint. https://doi.org/10.48550/arXiv.2304.11111 |
| [18] | Dai S. C., Xiong A., & Ku L. W. (2023). LLM-in-the-loop: Leveraging large language model for thematic analysis. arXiv preprint. https://doi.org/10.48550/arXiv.2310.15100 |
| [19] |
de Kok T. (2025). ChatGPT for textual analysis? How to use generative LLMs in accounting research. Management Science, 71(9), 7888-7906. https://doi.org/10.1287/mnsc.2023.03253
doi: 10.1287/mnsc.2023.03253 URL |
| [20] |
de Varda A. G., Saponaro C., & Marelli M. (2025). High variability in LLMs’ analogical reasoning. Nature Human Behaviour, 9(7), 1339-1341. https://doi.org/10.1038/s41562-025-02224-3
doi: 10.1038/s41562-025-02224-3 URL |
| [21] | DeepSeek-AI Guo, D. Yang, D. Zhang, H. Song, J. Zhang, R., … Zhang Z. (2025). Deepseek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint. https://doi.org/10.48550/arXiv.2501.12948 |
| [22] |
Deiana G., Dettori M., Arghittu A., Azara A., Gabutti G., & Castiglia P. (2023). Artificial intelligence and public health: Evaluating ChatGPT responses to vaccination myths and misconceptions. Vaccines, 11(7), 1217. https://doi.org/10.3390/vaccines11071217
doi: 10.3390/vaccines11071217 URL |
| [23] |
Deiner M. S., Honcharov V., Li J., Mackey T. K., Porco T. C., & Sarkar U. (2024). Large language models can enable inductive thematic analysis of a social media corpus in a single prompt: Human validation study. JMIR Infodemiology, 4(1), e59641. https://doi.org/10.2196/59641
doi: 10.2196/59641 URL |
| [24] | Demszky D., Yang D., Yeager D. S., Bryan C. J., Clapper M., Chandhok S.,... Pennebaker J. W. (2023). Using large language models in psychology. Nature Reviews Psychology, 2(11), 688-701. https://doi.org/10.1038/s44159-023-00241-5 |
| [25] |
Dillion D., Tandon N., Gu Y., & Gray K. (2023). Can AI language models replace human participants? Trends in Cognitive Sciences, 27(7), 597-600. https://doi.org/10.1016/j.tics.2023.04.008
doi: 10.1016/j.tics.2023.04.008 URL pmid: 37173156 |
| [26] | Ding Y., Zhang L. L., Zhang C., Xu Y., Shang N., Xu J., Yang F., & Yang M. (2024). Longrope: Extending LLM context window beyond 2 million tokens. arXiv preprint. https://doi.org/10.48550/arXiv.2402.13753 |
| [27] |
Faul F., Erdfelder E., Lang A. G., & Buchner A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175-191. https://doi.org/10.3758/BF03193146
doi: 10.3758/bf03193146 URL pmid: 17695343 |
| [28] | Ferguson S. A., Aoyagui P. A., & Kuzminykh A. (2023). Something borrowed: Exploring the influence of AI-generated explanation text on the composition of human explanations. In Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems (pp. 1-7). ACM. https://doi.org/10.1145/3544549.3585727 |
| [29] |
Goli A., & Singh A. (2024). Frontiers: Can large language models capture human preferences? Marketing Science, 43(4), 709-722. https://doi.org/10.1287/mksc.2023.0306
doi: 10.1287/mksc.2023.0306 URL |
| [30] |
Grossmann I., Feinberg M., Parker D. C., Christakis N. A., Tetlock P. E., & Cunningham W. A. (2023). AI and the transformation of social science research. Science, 380(6650), 1108-1109. https://doi.org/10.1126/science.adi1778
doi: 10.1126/science.adi1778 URL pmid: 37319216 |
| [31] |
Gupta R., Nair K., Mishra M., Ibrahim B., & Bhardwaj S. (2024). Adoption and impacts of generative artificial intelligence: Theoretical underpinnings and research agenda. International Journal of Information Management Data Insights, 4(1), 100232. https://doi.org/10.1016/j.jjimei.2024.100232
doi: 10.1016/j.jjimei.2024.100232 URL |
| [32] |
Hagendorff T., Fabi S., & Kosinski M. (2023). Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nature Computational Science, 3(10), 833-838. https://doi.org/10.1038/s43588-023-00527-x
doi: 10.1038/s43588-023-00527-x URL pmid: 38177754 |
| [33] | Hebenstreit K., Praas R., Kiesewetter L. P., & Samwald M. (2024). A comparison of chain-of-thought reasoning strategies across datasets and models. PeerJ Computer Science, 10, e1999. https://doi.org/10.7717/peerj-cs.1999 |
| [34] |
Hertwig R., & Erev I. (2009). The description-experience gap in risky choice. Trends in Cognitive Sciences, 13(12), 517-523. https://doi.org/10.1016/j.tics.2009.09.004
doi: 10.1016/j.tics.2009.09.004 URL pmid: 19836292 |
| [35] |
Jiao L., Li C., Chen Z., Xu H., & Xu Y. (2025). When AI “possesses” personality: Roles of good and evil personalities influence moral judgment in large language models. Acta Psychologica Sinica, 57(6), 929-946. https://doi.org/10.3724/SP.J.1041.2025.0929
doi: 10.3724/SP.J.1041.2025.0929 URL |
|
[焦丽颖, 李昌锦, 陈圳, 许恒彬, 许燕. (2025). 当AI“具有”人格: 善恶人格角色对大语言模型道德判断的影响. 心理学报, 57(6), 929-946.]
doi: 10.3724/SP.J.1041.2025.0929 |
|
| [36] |
Jin H. J., & Han D. H. (2014). Interaction between message framing and consumers’ prior subjective knowledge regarding food safety issues. Food Policy, 44, 95-102. https://doi.org/10.1016/j.foodpol.2013.10.007
doi: 10.1016/j.foodpol.2013.10.007 URL |
| [37] | Jones E., & Steinhardt J. (2022). Capturing failures of large language models via human cognitive biases. Advances in Neural Information Processing Systems, 35, 11785-11799. https://doi.org/10.48550/arxiv.2202.12299 |
| [38] |
Kahneman D., & Tversky A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47(2), 263-292. https://doi.org/10.2307/1914185
doi: 10.2307/1914185 URL |
| [39] | Karinshak E., Hu A., Kong K., Rao V., Wang J., Wang J., & Zeng Y. (2024). LLM-globe: A benchmark evaluating the cultural values embedded in LLM output. arXiv preprint. https://doi.org/10.48550/arXiv.2411.06032 |
| [40] | Karinshak E., Liu S. X., Park J. S., & Hancock J. T. (2023). Working with AI to persuade: Examining a large language model's ability to generate pro-vaccination messages. Proceedings of the ACM on Human-Computer Interaction, 7(CSCW1), 1-29. https://doi.org/10.1145/3579592 |
| [41] | Katz A., Fleming G. C., & Main J. (2024). Thematic analysis with open-source generative AI and machine learning: A new method for inductive qualitative codebook development. arXiv preprint. https://doi.org/10.48550/arXiv.2410.03721 |
| [42] |
Kelton A. S., Pennington R. R., & Tuttle B. M. (2010). The effects of information presentation format on judgment and decision making: A review of the information systems research. Journal of Information Systems, 24(2), 79-105. https://doi.org/10.2308/jis.2010.24.2.79
doi: 10.2308/jis.2010.24.2.79 URL |
| [43] | Khalid M. T., & Witmer A. P. (2025). Prompt engineering for large language model-assisted inductive thematic analysis. arXiv preprint. https://doi.org/10.48550/arXiv.2503.22978 |
| [44] |
Kumar A., & Lim S. S. (2008). How do decision frames influence the stock investment choices of individual investors? Management Science, 54(6), 1052-1064. https://doi.org/10.1287/mnsc.1070.0845
doi: 10.1287/mnsc.1070.0845 URL |
| [45] |
Lehr S. A., Caliskan A., Liyanage S., & Banaji M. R. (2024). ChatGPT as research scientist: Probing GPT’s capabilities as a research librarian, research ethicist, data generator, and data predictor. Proceedings of the National Academy of Sciences, 121(35), e2404328121. https://doi.org/10.1073/pnas.2404328121
doi: 10.1073/pnas.2404328121 URL |
| [46] | Lenth R. V. (2025). Emmeans: Estimated marginal means, aka least-squares means (R package version 1.11.0) [Computer software]. https://doi.org/10.32614/CRAN.package.emmeans |
| [47] |
Li S. (2004). A behavioral choice model when computational ability matters. Applied Intelligence, 20(2), 147-163. https://doi.org/10.1023/B:APIN.0000013337.01711.c7
doi: 10.1023/B:APIN.0000013337.01711.c7 URL |
| [48] |
Lin Z. (2023). Why and how to embrace AI such as ChatGPT in your academic life. Royal Society Open Science, 10(8), 230658. https://doi.org/10.1098/rsos.230658
doi: 10.1098/rsos.230658 URL |
| [49] |
Lin Z. (2024). How to write effective prompts for large language models. Nature Human Behaviour, 8(4), 611-615. https://doi.org/10.1038/s41562-024-01847-2
doi: 10.1038/s41562-024-01847-2 URL pmid: 38438650 |
| [50] |
Lin Z. (2025). Techniques for supercharging academic writing with generative AI. Nature Biomedical Engineering, 9(4), 426-431. https://doi.org/10.1038/s41551-024-01185-8
doi: 10.1038/s41551-024-01185-8 URL |
| [51] |
Liu N., Zhou L., Li A. M., Hui Q. S., Zhou Y. R., & Zhang Y. Y. (2021). Neuroticism and risk-taking: the role of competition with a former winner or loser. Personality and Individual Differences, 179, 110917. https://doi.org/10.1016/j.paid.2021.110917
doi: 10.1016/j.paid.2021.110917 URL |
| [52] |
Liu S. X., Yang J. Z., & Chu H. R. (2019). Now or future? Analyzing the effects of message frame and format in motivating Chinese females to get HPV vaccines for their children. Patient Education and Counseling, 102(1), 61-67. https://doi.org/10.1016/j.pec.2018.09.005
doi: S0738-3991(18)30692-X URL pmid: 30219633 |
| [53] |
Lopes L. L. (1996). When time is of the essence: Averaging, aspiration, and the short run. Organizational Behavior and Human Decision Processes, 65(3), 179-189. https://doi.org/10.1006/obhd.1996.0017
doi: 10.1006/obhd.1996.0017 URL |
| [54] |
Lu J., Chen Y., & Fang Q. (2022). Promoting decision satisfaction: The effect of the decision target and strategy on process satisfaction. Journal of Business Research, 139, 1231-1239. https://doi.org/10.1016/j.jbusres.2021.10.056
doi: 10.1016/j.jbusres.2021.10.056 URL |
| [55] |
Mei Q., Xie Y., Yuan W., & Jackson M. O. (2024). A turing test of whether AI chatbots are behaviorally similar to humans. Proceedings of the National Academy of Sciences, 121(9), e2313925121. https://doi.org/10.1073/pnas.2313925121
doi: 10.1073/pnas.2313925121 URL |
| [56] |
Mischler G., Li Y. A., Bickel S., Mehta A. D., & Mesgarani N. (2024). Contextual feature extraction hierarchies converge in large language models and the brain. Nature Machine Intelligence, 6(10), 1467-1477. https://doi.org/10.1038/s42256-024-00925-4
doi: 10.1038/s42256-024-00925-4 URL |
| [57] |
Morreale A., Stoklasa J., Collan M., & Lo Nigro G. (2018). Uncertain outcome presentations bias decisions: Experimental evidence from Finland and Italy. Annals of Operations Research, 268(1-2), 259-272. https://doi.org/10.1007/s10479-016-2349-3
doi: 10.1007/s10479-016-2349-3 URL |
| [58] | Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716. https://doi.org/10.1126/science.aac4716 |
| [59] |
Park P. S. (2024). Diminished diversity-of-thought in a standard large language model. Behavior Research Methods, 56(6), 5754-5770. https://doi.org/10.3758/s13428-023-02307-x
doi: 10.3758/s13428-023-02307-x URL pmid: 38194165 |
| [60] | Pascal B. (1670).Pensées (W. F. Trotter, Trans.). Retrieved Nov. 22, 2018, from https://sourcebooks.fordham.edu/mod/1660pascal-pensees.asp |
| [61] |
Pavey L., & Churchill S. (2014). Promoting the avoidance of high-calorie snacks: Priming autonomy moderates message framing effects. PLoS One, 9(7), e103892. https://doi.org/10.1371/journal.pone.0103892
doi: 10.1371/journal.pone.0103892 URL |
| [62] | Pawel S., Consonni G., & Held L. (2023). Bayesian approaches to designing replication studies. Psychological Methods. Advance online publication. https://doi.org/10.1037/met0000604 |
| [63] |
Peng L., Guo Y., & Hu D. (2021). Information framing effect on public’s intention to receive the COVID-19 vaccination in China. Vaccines, 9(9), 995. https://doi.org/10.3390/vaccines9090995
doi: 10.3390/vaccines9090995 URL |
| [64] |
Peters E., & Levin I. P. (2008). Dissecting the risky-choice framing effect: Numeracy as an individual-difference factor in weighting risky and riskless options. Judgment and Decision Making, 3(6), 435-448. https://doi.org/10.1017/s1930297500000012
doi: 10.1017/S1930297500000012 URL |
| [65] |
Popovic N. F., Pachur T., & Gaissmaier W. (2019). The gap between medical and monetary choices under risk persists in decisions for others. Journal of Behavioral Decision Making, 32(4), 388-402. https://doi.org/10.1002/bdm.2121
doi: 10.1002/bdm.v32.4 URL |
| [66] |
Prescott M. R., Yeager S., Ham L., Saldana C. D. R., Serrano V., Narez J., … Montoya J. (2024). Comparing the efficacy and efficiency of human and generative AI: Qualitative thematic analyses. JMIR AI, 3(1), e54482. https://doi.org/10.2196/54482
doi: 10.2196/54482 URL |
| [67] | Qin X., Huang M., & Ding J. (2024). AITurk: Using ChatGPT for social science research. PsyArXiv. https://doi.org/10.31234/osf.io/xkd23 |
| [68] |
Redelmeier D. A., & Tversky A. (1992). On the framing of multiple prospects. Psychological Science, 3(3), 191-193. https://doi.org/10.1111/j.1467-9280.1992.tb00025.x
doi: 10.1111/j.1467-9280.1992.tb00025.x URL |
| [69] |
Reeck C., Mullette-Gillman O. A., McLaurin R. E., & Huettel S. A. (2022). Beyond money: Risk preferences across both economic and non-economic contexts predict financial decisions. PLoS One, 17(12), e0279125. https://doi.org/10.1371/journal.pone.0279125
doi: 10.1371/journal.pone.0279125 URL |
| [70] |
Salles A., Evers K., & Farisco M. (2020). Anthropomorphism in AI. AJOB Neuroscience, 11(2), 88-95. https://doi.org/10.1080/21507740.2020.1740350
doi: 10.1080/21507740.2020.1740350 URL pmid: 32228388 |
| [71] | Samuelson P. A. (1963). Risk and uncertainty: A fallacy of large numbers. Scientia, 98, 108-113. |
| [72] |
Scarffe A., Coates A., Brand K., & Michalowski W. (2024). Decision threshold models in medical decision making: A scoping literature review. BMC Medical Informatics and Decision Making, 24(1), 273. https://doi.org/10.1186/s12911-024-02681-2
doi: 10.1186/s12911-024-02681-2 URL |
| [73] |
Shahid N., Rappon T., & Berta W. (2019). Applications of artificial neural networks in health care organizational decision-making: A scoping review. PLoS One, 14(2), e0212356. https://doi.org/10.1371/journal.pone.0212356
doi: 10.1371/journal.pone.0212356 URL |
| [74] |
Simonsohn U. (2015). Small telescopes: Detectability and the evaluation of replication results. Psychological Science, 26(5), 559-569. https://doi.org/10.1177/0956797614567341
doi: 10.1177/0956797614567341 URL pmid: 25800521 |
| [75] |
Strachan J. W. A., Albergo D., Borghini G., Pansardi O., Scaliti E., Gupta S., … Becchio C. (2024). Testing theory of mind in large language models and humans. Nature Human Behaviour, 8(7), 1285-1295. https://doi.org/10.1038/s41562-024-01882-z
doi: 10.1038/s41562-024-01882-z URL pmid: 38769463 |
| [76] |
Sun H. Y., Rao L. L., Zhou K., & Li S. (2014). Formulating an emergency plan based on expectation-maximization is one thing, but applying it to a single case is another. Journal of Risk Research, 17(7), 785-814. https://doi.org/10.1080/13669877.2013.816333
doi: 10.1080/13669877.2013.816333 URL |
| [77] |
Suri G., Slater L. R., Ziaee A., & Nguyen M. (2024). Do large language models show decision heuristics similar to humans? A case study using GPT-3.5. Journal of Experimental Psychology: General, 153(4), 1066-1075. https://doi.org/10.1037/xge0001547
doi: 10.1037/xge0001547 URL |
| [78] | Tabachnick B. G., & Fidell L. S. (2007). Using multivariate statistics (5th ed.). Allyn & Bacon. |
| [79] |
Thapa S., & Adhikari S. (2023). ChatGPT, Bard, and large language models for biomedical research: Opportunities and pitfalls. Annals of Biomedical Engineering, 51(12), 2647-2651. https://doi.org/10.1007/s10439-023-03284-0
doi: 10.1007/s10439-023-03284-0 URL |
| [80] |
Tversky A., & Bar-Hillel M. (1983). Risk: The long and the short. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9(4), 713-717. https://doi.org/10.1037/0278-7393.9.4.713
doi: 10.1037/0278-7393.9.4.713 URL |
| [81] | Von Neumann J., & Morgenstern O. (1947). Theory of games and economic behavior (2nd rev. ed.). Princeton University Press. |
| [82] |
Wang Y., Zhang J., Wang F., Xu W., & Liu W. (2023). Do not think any virtue trivial, and thus neglect it: Serial mediating role of social mindfulness and perspective taking. Acta Psychologica Sinica, 55(4), 626-641. https://doi.org/10.3724/SP.J.1041.2023.00626
doi: 10.3724/SP.J.1041.2023.00626 URL |
|
[王伊萌, 张敬敏, 汪凤炎, 许文涛, 刘维婷. (2023). 勿以善小而不为: 正念与智慧——社会善念与观点采择的链式中介. 心理学报, 55(4), 626-641. https://doi.org/10.3724/SP.J.1041.2023.00626 ]
doi: 10.3724/SP.J.1041.2023.00626 URL |
|
| [83] |
Webb T., Holyoak K. J., & Lu H. (2023). Emergent analogical reasoning in large language models. Nature Human Behaviour, 7(9), 1526-1541. https://doi.org/10.48550/arXiv.2212.09196
doi: 10.1038/s41562-023-01659-w URL pmid: 37524930 |
| [84] |
Weber E. U., Blais A. R., & Betz N. E. (2002). A domain- specific risk-attitude scale: Measuring risk perceptions and risk behaviors. Journal of Behavioral Decision Making, 15(4), 263-290. https://doi.org/10.1002/bdm.414
doi: 10.1002/bdm.v15:4 URL |
| [85] | Wei J., Wang X., Schuurmans D., Bosma M., Ichter B., Xia F.,... Zhou D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837. https://doi.org/10.48550/arxiv.2201.11903 |
| [86] |
Xia D., Li Y., He Y., Zhang T., Wang Y., & Gu J. (2019). Exploring the role of cultural individualism and collectivism on public acceptance of nuclear energy. Energy Policy, 132, 208-215. https://doi.org/10.1016/j.enpol.2019.05.014
doi: 10.1016/j.enpol.2019.05.014 URL |
| [87] |
Xia D., Song M., & Zhu T. (2025). A comparison of the persuasiveness of human and ChatGPT generated pro- vaccine messages for HPV. Frontiers in Public Health, 12, 1515871. https://doi.org/10.3389/fpubh.2024.1515871
doi: 10.3389/fpubh.2024.1515871 URL |
| [88] | Yuan Y., Jiao W., Wang W., Huang J. T., He P., Shi S., & Tu Z. (2023). Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher. arXiv preprint. https://doi.org/10.48550/arXiv.2308.06463 |
| [89] |
Zhang J., Li H. A., & Allenby G. M. (2024). Using text analysis in parallel mediation analysis. Marketing Science, 43(5), 953-970. https://doi.org/10.1287/mksc.2023.0045
doi: 10.1287/mksc.2023.0045 URL |
| [90] |
Zhang Y., Huang F., Mo L., Liu X., & Zhu T. (2025). Suicidal ideation data augmentation and recognition technology based on large language models. Acta Psychologica Sinica, 57(6), 987-1000. https://doi.org/10.3724/SP.J.1041.2025.0987
doi: 10.3724/SP.J.1041.2025.0987 URL |
|
[章彦博, 黄峰, 莫柳铃, 刘晓倩, 朱廷劭. (2025). 基于大语言模型的自杀意念文本数据增强与识别技术. 心理学报, 57(6), 987-1000.]
doi: 10.3724/SP.J.1041.2025.0987 |
|
| [91] | Zhao F., Yu F., & Shang Y. (2024). A new method supporting qualitative data analysis through prompt generation for inductive coding. 2024 IEEE International Conference on Information Reuse and Integration for Data Science (IRI), 164-169. https://doi.org/10.1109/IRI62200.2024.00043 |
| [92] | Zhao W. X., Zhou K., Li J., Tang T., Wang X., Hou Y.,... Wen J. R. (2023). A survey of large language models. arXiv preprint. https://doi.org/10.48550/arXiv.2303.18223 |
| [1] | 刘玥, 何月翎, 刘红云. 密集追踪干预研究设计中的建模及其样本量规划——基于动态结构方程模型[J]. 心理学报, 2026, 58(4): 773-792. |
| [2] | 王健树, 姜啸威, 陈亚楠, 王明辉, 杜峰. 从显性威慑到隐性内化:AI监管和黑暗三联征人格对诚实行为的影响[J]. 心理学报, 2026, 58(3): 381-398. |
| [3] | 戴逸清, 马歆茗, 伍珍. 大语言模型放大共情性别刻板印象:对专业与职业推荐的影响[J]. 心理学报, 2026, 58(3): 399-415. |
| [4] | 朱娜平, 张霞, 周杰, 李燕芳. 群体合作规范违反情境中儿童第三方干预偏好的发展及内在动机[J]. 心理学报, 2026, 58(3): 516-533. |
| [5] | 杨沈龙, 胡小勇, 郭永玉. 经济处境的心理影响及其干预策略与治理启示(专栏总论)[J]. 心理学报, 2026, 58(2): 191-197. |
| [6] | 吴诗玉, 王亦赟. “零样本语言学习”:大语言模型能“像人一样”习得语境中的情感吗?[J]. 心理学报, 2026, 58(2): 308-322. |
| [7] | 王雪珂, 邓芳, 陈立, 冯廷勇. 孤独症儿童负性情绪调节特征及干预:基于多模态评估的正念与认知策略训练[J]. 心理学报, 2026, 58(1): 39-56. |
| [8] | 焦丽颖, 李昌锦, 陈圳, 许恒彬, 许燕. 当AI“具有”人格:善恶人格角色对大语言模型道德判断的影响[J]. 心理学报, 2025, 57(6): 929-946. |
| [9] | 高承海, 党宝宝, 王冰洁, 吴胜涛. 人工智能的语言优势和不足:基于大语言模型与真实学生语文能力的比较[J]. 心理学报, 2025, 57(6): 947-966. |
| [10] | 章彦博, 黄峰, 莫柳铃, 刘晓倩, 朱廷劭. 基于大语言模型的自杀意念文本数据增强与识别技术[J]. 心理学报, 2025, 57(6): 987-1000. |
| [11] | 李春好, 刘荣媛, 刘远豪. 经典和对偶共结果效应对前景集结果区间的依赖性:基于概率权重的视角[J]. 心理学报, 2025, 57(3): 398-414. |
| [12] | 耿晓伟, 刘超, 苏黎, 韩冰雪, 张巧明, 吴明证. 人机合作使人更冒险: 主体责任感的中介作用[J]. 心理学报, 2025, 57(11): 1885-1900. |
| [13] | 由姗姗, 齐玥, 陈俊廷, 骆磊, 张侃. 人与AI对智能家居机器人的安全信任及其影响因素[J]. 心理学报, 2025, 57(11): 1951-1972. |
| [14] | 周子森, 黄琪, 谭泽宏, 刘睿, 曹子亨, 母芳蔓, 樊亚春, 秦绍正. 多模态大语言模型动态社会互动情景下的情感能力测评[J]. 心理学报, 2025, 57(11): 1988-2000. |
| [15] | 黄峰, 丁慧敏, 李思嘉, 韩诺, 狄雅政, 刘晓倩, 赵楠, 李林妍, 朱廷劭. 基于大语言模型的自助式AI心理咨询系统构建及其效果评估[J]. 心理学报, 2025, 57(11): 2022-2042. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||