ISSN 0439-755X
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
心理学报 ›› 2026, Vol. 58 ›› Issue (2): 308-322.doi: 10.3724/SP.J.1041.2026.0308 cstr: 32110.14.2026.0308
吴诗玉( ), 王亦赟
), 王亦赟
收稿日期:2025-01-27
发布日期:2025-12-03
出版日期:2026-02-25
通讯作者:
吴诗玉, E-mail: shiyuw@sjtu.edu.cn
WU Shiyu(), WANG Yiyun
Received:2025-01-27
Online:2025-12-03
Published:2026-02-25
摘要: 本研究旨在检验大语言模型(LLMs)能否在“零样本”条件下通过阅读附带习得单词所出现的语境情感, 并评估情感效价与语境变异性对词汇学习的影响。研究采用跨模型−人类对比, 4种LLMs与3组学习者在统一材料中学习嵌入不同情感(积极/中性/消极)与重复/变化语境的目标词, 并以多项测试衡量情感迁移及词形、词义习得效果。结果显示, LLMs与人类模式一致, 能将语境情感迁移至目标词, 并在语言生成中保持情感一致; 而且也呈现“积极情感优势” “语境变异优势”, 且在定义生成中出现语境情感与语境变异的交互效应。文章提出“双重机制框架”, 认为LLMs在功能层面具备类人的情感语义学习能力, 但其机制基于统计共现与向量优化, 异于人类的具身与社会加工。本研究为情感计算、人机交互伦理与词汇教学提供启示。
中图分类号:
吴诗玉, 王亦赟. (2026). “零样本语言学习”:大语言模型能“像人一样”习得语境中的情感吗?. 心理学报, 58(2), 308-322.
WU Shiyu, WANG Yiyun. (2026). Zero-shot language learning: Can large language models (LLMs) acquire contextual emotion in a human-like manner?. Acta Psychologica Sinica, 58(2), 308-322.
| 模型名称 | 架构及参数 | 开源 情况 | 上下文长 度(token) | 多模态推理能力 |
|---|---|---|---|---|
| 百度:文心一言3.5 | Transformer/未公开 | 闭源 | 8K | 支持文本、图像和视频生成。中等推理能力, 适合中文语境。 |
| OpenAI: ChatGPT 4 | Transformer/> 1.75万亿 | 闭源 | 8K | 强大的图像生成和数学、逻辑等推理能力, 支持图文结合。 |
| Google DeepMind: Gemini 1.5 Pro | Transformer, MoE/未公开 | 闭源 | 2M | 强大视觉理解和生成。复杂问题和知识查询推理能力强。 |
| Meta: LLaMA 3.1-8B | Transformer/约80亿 | 开源 | 128K | 文本生成, 缺乏多模态能力。中小规模任务, 基础推理能力。 |
表1 四种大语言模型简介
| 模型名称 | 架构及参数 | 开源 情况 | 上下文长 度(token) | 多模态推理能力 |
|---|---|---|---|---|
| 百度:文心一言3.5 | Transformer/未公开 | 闭源 | 8K | 支持文本、图像和视频生成。中等推理能力, 适合中文语境。 |
| OpenAI: ChatGPT 4 | Transformer/> 1.75万亿 | 闭源 | 8K | 强大的图像生成和数学、逻辑等推理能力, 支持图文结合。 |
| Google DeepMind: Gemini 1.5 Pro | Transformer, MoE/未公开 | 闭源 | 2M | 强大视觉理解和生成。复杂问题和知识查询推理能力强。 |
| Meta: LLaMA 3.1-8B | Transformer/约80亿 | 开源 | 128K | 文本生成, 缺乏多模态能力。中小规模任务, 基础推理能力。 |
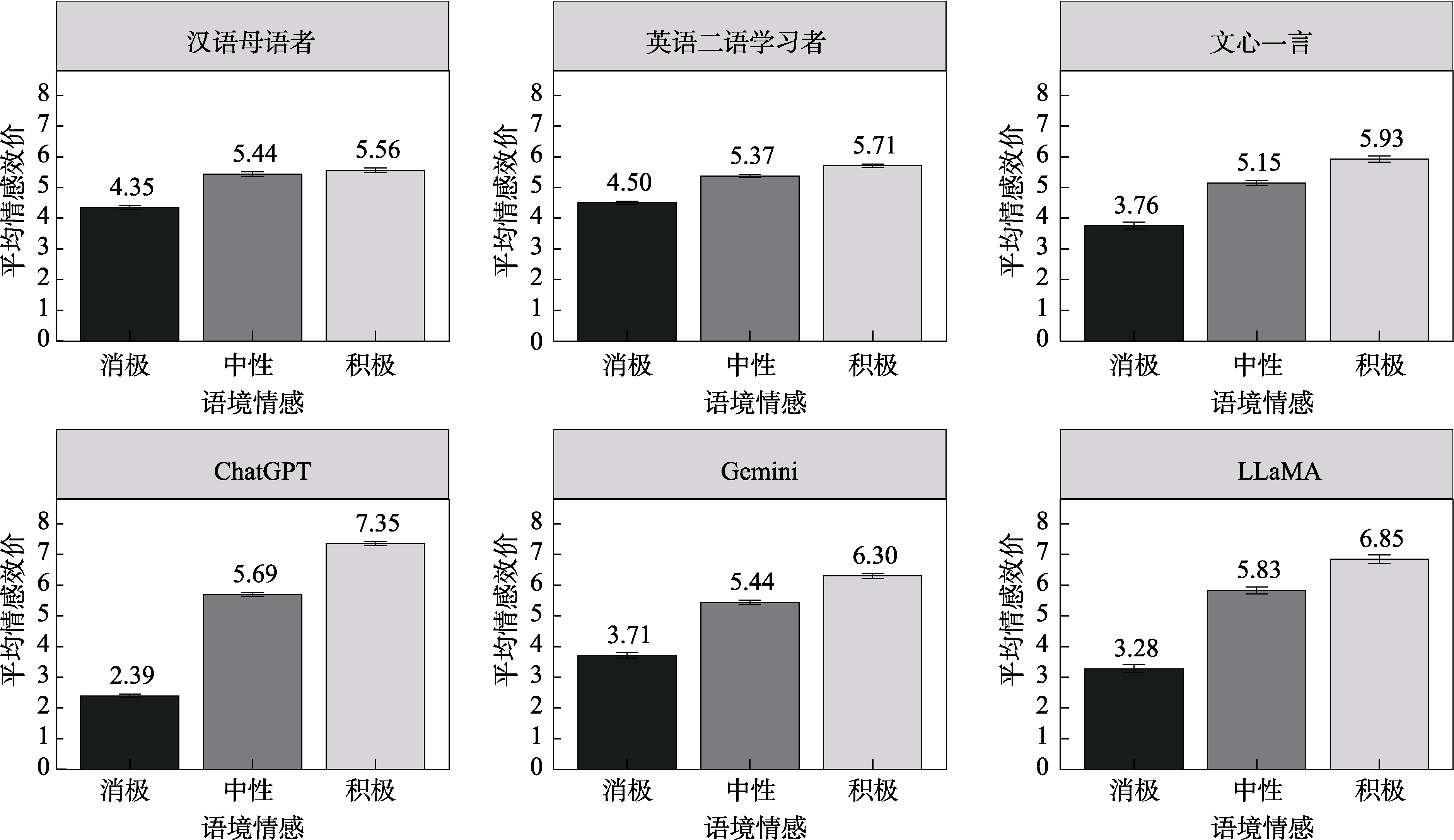
图1 语言学习者和LLMs的情感学习结果
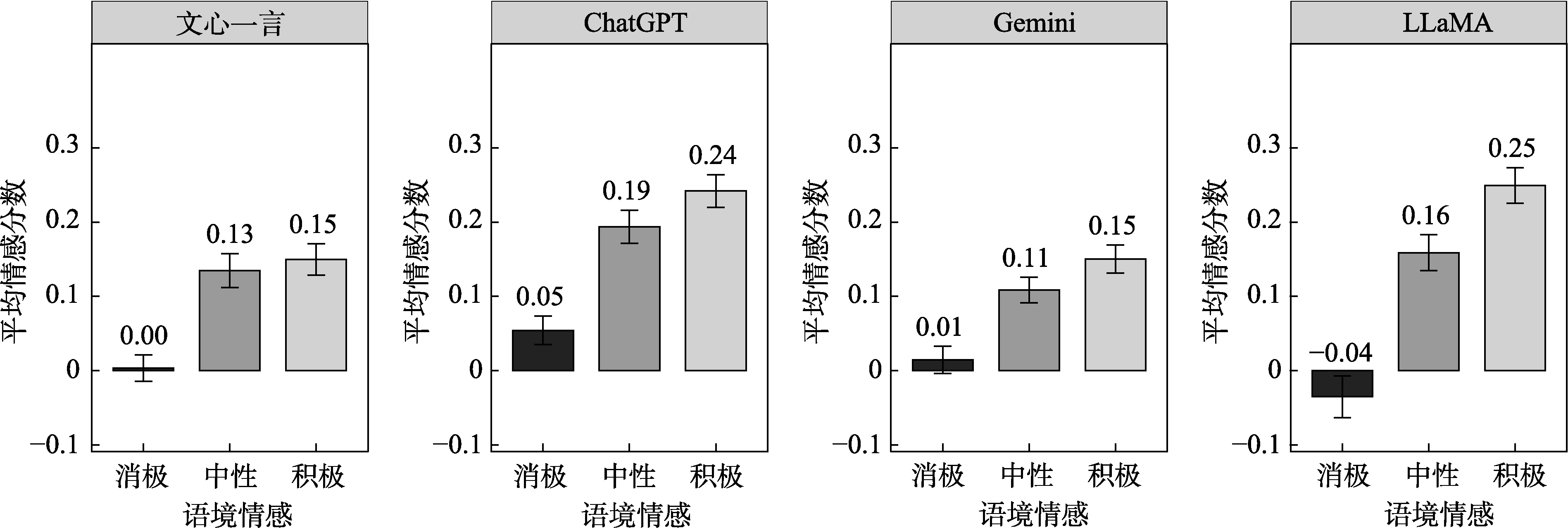
图2 LLMs所产出的句子的情感分析的结果
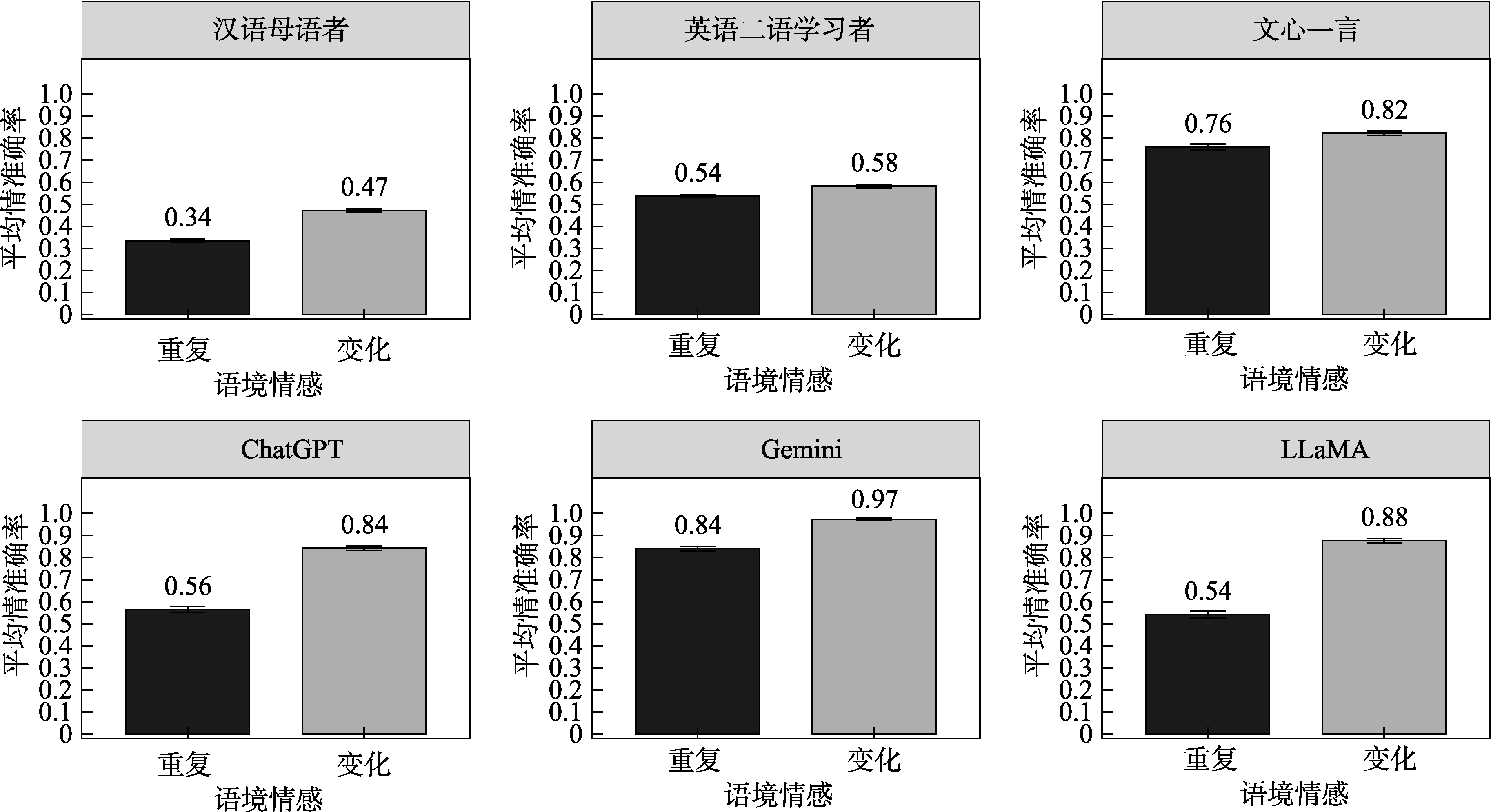
图3 语言学习者和LLMs在重复和变化语境下完成单词定义匹配任务的平均准确率
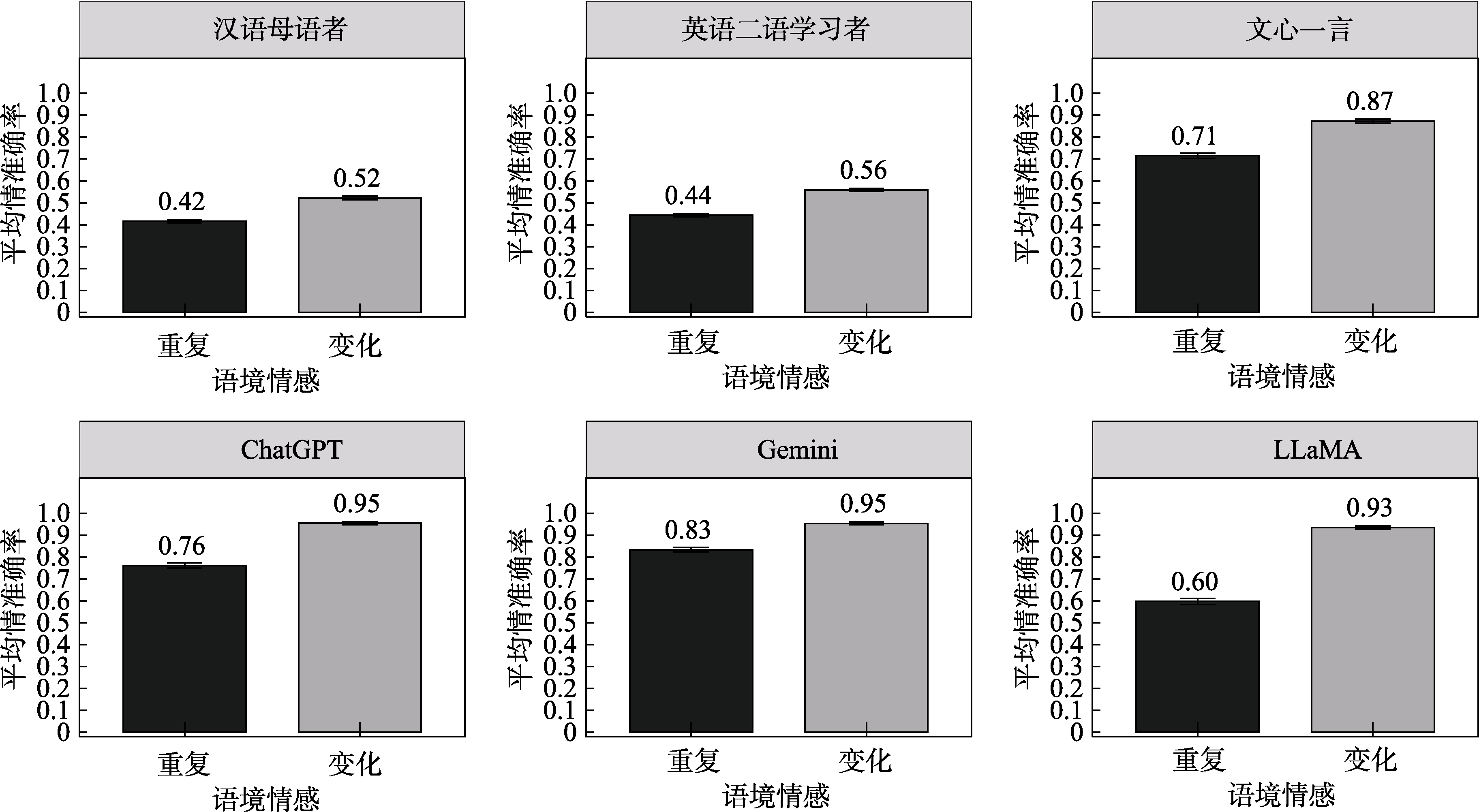
图4 语言学习者和LLMs在重复和变化语境下完成单词定义生成任务的平均准确率
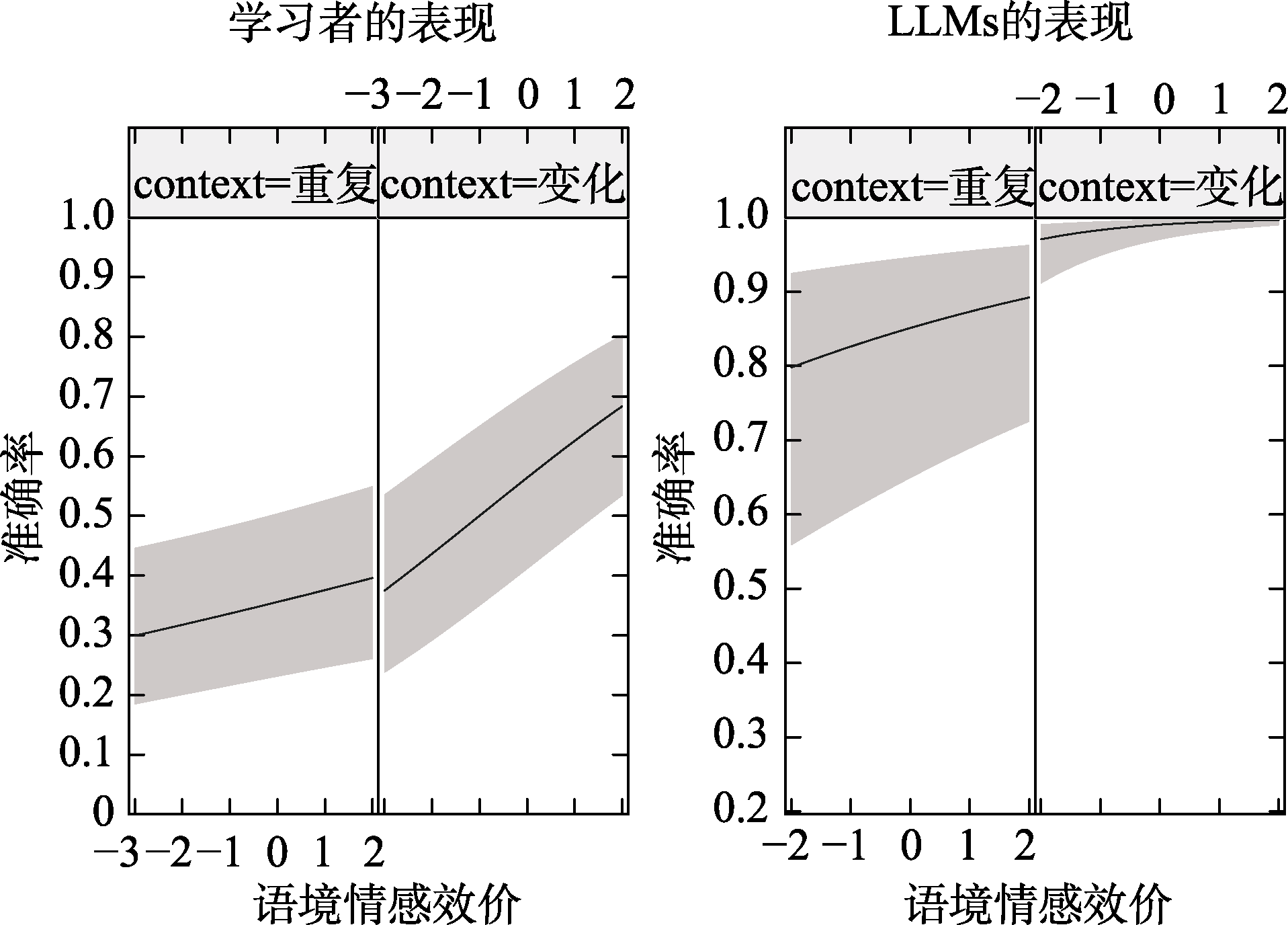
图5 语境情感效价和语境变异性在学习者和LLMs单词定义生成的交互效应
| [1] | Ahmed S. (2004). The cultural politics of emotion. New York: Rouledge. |
| [2] | Ahmed S. (2010). The promise of happiness. London: Duke University Press. |
| [3] |
Andrews B., Vigliocco G., & Vinson D. P. (2009). Integrating experiential and distributional data to learn semantic representations. Psychological Review, 116(3), 463-498.
doi: 10.1037/a0016261 pmid: 19618982 |
| [4] |
Baayen R. H., Davidson D. J., & Bates D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59(4), 390-412.
doi: 10.1016/j.jml.2007.12.005 URL |
| [5] | Balass M. (2011). Learning words in context: An ERP investigation of word experience effects on familiarity and meaning acquisition [Unpublished doctorial dissertation]. University of Pittsburgh. |
| [6] |
Barrett L. F. (2017). The theory of constructed emotion: An active inference account of interoception and categorization. Social Cognitive and Affective Neuroscience, 12(1), 1-23.
doi: 10.1093/scan/nsw154 pmid: 27798257 |
| [7] |
Barsalou L. W. (2008). Grounded cognition. Annual Review of Psychology, 59(1), 617-645.
doi: 10.1146/psych.2008.59.issue-1 URL |
| [8] | Binz M., & Schulz E. (2023). Turning large language models into cognitive models. Computer Science. https://doi.org/10.48550/arXiv.2306.03917 |
| [9] | Bisk Y., Holtzman A., Thomason J., Andreas J., Bengio Y., Chai J., ... Turian J. (2020). Experience grounds language. Computer Science. https://doi.org/10.48550/arXiv.2004.10151 |
| [10] |
Blythe H. I., Liang F., Zang C., Wang J., Yan G., Bai X., & Liversedge S. P. (2012). Inserting spaces into Chinese text helps readers to learn new words: An eye movement study. Journal of Memory and Language, 67(2), 241-254.
doi: 10.1016/j.jml.2012.05.004 URL |
| [11] |
Bolger D. J., Balass M., Landen E., & Perfetti C. A. (2008). Context variation and definitions in learning the meanings of words: An instance-based learning approach. Discourse Processes, 45(2), 122-159.
doi: 10.1080/01638530701792826 URL |
| [12] | Brown T. B., Mann B., Ryder N., Subbiah M., Kaplan J., Dhariwal P., ... Amodei D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901. |
| [13] |
Caliskan A., Bryson J. J., & Narayanan A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334), 183-186.
doi: 10.1126/science.aal4230 pmid: 28408601 |
| [14] | Chomsky N. (1957). Syntactic structures. Berlin: De Gruyter Mouton. |
| [15] | Christensen R. H. B. (2023). ordinal: Regression models for ordinal data. R package version 2023.12-4.1. https://CRAN.R-project.org/package=ordinal |
| [16] | Clark E., Celikyilmaz A., & Smith N. A. (2019, July). Sentence mover’s similarity: Automatic evaluation for multi-sentence texts. Paper presented at the meeting of the Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy. |
| [17] | Damasio A. R. (1994). Descartes’ error: Emotion, reason and the human brain. New York: Grosset/Putnam. |
| [18] |
Driver M. (2022). Emotion-laden texts and words: The influence of emotion on vocabulary learning for heritage and foreign language learners. Studies in Second Language Acquisition, 44(4), 1071-1094.
doi: 10.1017/S0272263121000851 URL |
| [19] | Ellis N. C., & Wulff S. (2015). Usage-based approaches to SLA. In B. VanPatten, & J. Williams (Eds.), Second language acquisition research series: Theories in second language acquisition (pp. 75-94). Routledge. |
| [20] | Eysenck M. W., & Brysbaert M. (2018). Fundamentals of cognition (3rd ed.). Routledge. |
| [21] |
Godfroid A., Ahn J., Choi I., Ballard L., Cui Y., Johnston S., ... Yoon H.-J. (2018). Incidental vocabulary learning in a natural reading context: An eye-tracking study. Bilingualism: Language and Cognition, 21(3), 563-584.
doi: 10.1017/S1366728917000219 URL |
| [22] | Hagendorff T., Dasgupta I., Binz M., Chan S. C. Y., Lampinen A., Wang J. X., ... Schulz E. (2023). Machine psychology. Computer Science. https://doi.org/10.48550/arXiv.2303.13988 |
| [23] |
Hasson U., Ghazanfar A. A., Galantucci B., Garrod S., & Keysers C. (2012). Brain-to-brain coupling: A mechanism for creating and sharing a social world. Trends in Cognitive Sciences, 16(2), 114-121.
doi: 10.1016/j.tics.2011.12.007 pmid: 22221820 |
| [24] | Hatfield E., Rapson R. L., & Le Y. L. (2009). Emotional contagion and empathy. In J. Decety & W. Ickes (Eds.), The social neuroscience of empathy (pp. 19-30). Boston, MA: MIT Press. |
| [25] |
Ho M. H., Kemp B. T., Eisenbarth H., & Rijnders R. J. P. (2023). Designing a neuroclinical assessment of empathy deficits in psychopathy based on the Zipper Model of Empathy. Neuroscience and Biobehavioral Reviews, 151, 105244.
doi: 10.1016/j.neubiorev.2023.105244 URL |
| [26] |
Horst J. S., Parsons K. L., & Bryan N. M. (2011). Get the story straight: Contextual repetition promotes word learning from storybooks. Frontiers in Psychology, 2, 17.
doi: 10.3389/fpsyg.2011.00017 pmid: 21713179 |
| [27] | Hulstijn J. H. (2001). Intentional and incidental second-language vocabulary learning:A reappraisal of elaboration, rehearsal and automaticity. In P. Robinson (Ed.), Cognition and second language instruction (pp. 258-286). Cambridge University Press. |
| [28] |
Jones M. N., Johns B. T., & Recchia G. (2012). The role of semantic diversity in lexical organization. Canadian Journal of Experimental Psychology, 66(2), 115-124.
doi: 10.1037/a0026727 URL |
| [29] | Jones M. N., Dye M., & Johns B. T. (2017). Context as an organizing principle of the lexicon. In B. H. Ross (Ed.), Psychology of learning and motivation (Vol. 67, pp. 239-283). United States: Elsevier Science & Technology. |
| [30] |
Joseph H., & Nation K. (2018). Examining incidental word learning during reading in children: The role of context. Journal of Experimental Child Psychology, 166, 190-211.
doi: S0022-0965(16)30239-9 pmid: 28942127 |
| [31] |
Keuleers E., & Brysbaert M. (2010). Wuggy: A multilingual pseudoword generator. Behavior Research Methods, 42(3), 627-633.
doi: 10.3758/BRM.42.3.627 pmid: 20805584 |
| [32] |
Lana N., & Kuperman V. (2024). Learning concrete and abstract novel words in emotional contexts: Evidence from incidental vocabulary learning. Language Learning and Development, 20(2), 158-173.
doi: 10.1080/15475441.2023.2246438 URL |
| [33] |
Landauer T. K., & Dumais S. T. (1997). A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104(2), 211-240.
doi: 10.1037/0033-295X.104.2.211 URL |
| [34] |
Laufer B., & Aviad-Levitzky T. (2017). What type of vocabulary knowledge predicts reading comprehension: Word meaning recall or word meaning recognition? The Modern Language Journal, 101(4), 729-741.
doi: 10.1111/modl.v101.4 URL |
| [35] |
Lauro J., Schwartz A. I., & Francis W. S. (2020). Bilingual novel word learning in sentence contexts: Effects of semantic and language variation. Journal of Memory and Language, 113, 104123.
doi: 10.1016/j.jml.2020.104123 URL |
| [36] | Li Z. (2024). Semantic prosody acquisition and its influence on the learning of L2 novel word forms and meanings [Unpublished doctorial dissertation]. Shanghai Jiao Tong University. |
| [李赞. (2024). 语义韵习得及其对二语新颖词词形和词义学习的影响 (博士学位论文). 上海交通大学.] | |
| [37] | Louw B. (1993). Irony in the text or insincerity in the writer? The diagnostic potential of semantic prosodies. In M. Baker, G. Francis, & E. Tognini-Bonelli (Eds.), Text and technology: In honour of John Sinclair (pp. 157-176). Amsterdam, The Netherlands: John Benjamins. |
| [38] | Ma Z., & Li Z. (2024). Acquiring semantic prosody in L2 novel word learning: The effect of context variability and gender. Modern Foreign Languages, 47(6), 790-801. |
| [马拯, 李赞. (2024). 二语新颖词语义韵的习得:语境变异性及性别的影响. 现代外语, 47(6), 790-801.] | |
| [39] |
MacIntyre P. D., & Vincze L. (2017). Positive and negative emotions underlie motivation for L2 learning. Studies in Second Language Learning and Teaching, 7(1), 61-88.
doi: 10.14746/ssllt.2017.7.1.4 URL |
| [40] | Nevisi R. B., Hosseinpur R. M., & Darvish F. Z. (2018). The impact of L1/L2-based explicit output task instruction on Iranian EFL learners’ semantic prosody learning. Journal of Language Horizons, 2(2), 51-74. |
| [41] |
Pessoa L. (2008). On the relationship between emotion and cognition. Nature Reviews Neuroscience, 9(2), 148-158.
doi: 10.1038/nrn2317 pmid: 18209732 |
| [42] | Radford A., Wu J., Child R., Luan D., Amodei D., & Sutskever I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9. |
| [43] |
Schmidt R. W. (1990). The role of consciousness in second language learning. Applied Linguistics, 11(2), 129-158.
doi: 10.1093/applin/11.2.129 URL |
| [44] | Sinclair J. (1987). Looking up: An account of the COBUILD Project in lexical computing and the development of the Collins COBUILD English Language Dictionary. London, England: Collins ELT. |
| [45] |
Snefjella B., Lana N., & Kuperman V. (2020). How emotion is learned: Semantic learning of novel words in emotional contexts. Journal of Memory and Language, 115, 104171.
doi: 10.1016/j.jml.2020.104171 URL |
| [46] |
Stewart J., Gyllstad H., Nicklin C., & McLean S. (2024). Establishing meaning recall and meaning recognition vocabulary knowledge as distinct psychometric constructs in relation to reading proficiency. Language Testing, 41(1), 89-108.
doi: 10.1177/02655322231162853 URL |
| [47] |
Tamir M., Schwartz S. H., Cieciuch J., Riediger M., Torres C., Scollon C., ... Vishkin A. (2016). Desired emotions across cultures: A value-based account. Journal of Personality and Social Psychology, 111(1), 67-82.
doi: 10.1037/pspp0000072 pmid: 26524003 |
| [48] |
Tomasello M. (2000). First steps toward a usage-based theory of language acquisition. Cognitive Linguistics, 11(1-2), 61-82.
doi: 10.1515/cogl.2001.012 URL |
| [49] |
Tulving E., & Thomson D. M. (1973). Encoding specificity and retrieval processes in episodic memory. Psychological Review, 80(5), 352-373.
doi: 10.1037/h0020071 URL |
| [50] | Wang W., Zheng V. W., Yu H., & Miao C. (2019). A survey of zero-shot learning: Settings, methods, and applications. ACM Transactions on Intelligent Systems and Technology, 10(2), 1-37. |
| [51] | Wetherell M. (2012). Affect and emotion: A new social science understanding. Los Angeles: SAGE. |
| [52] |
Wu S. Y., & Li Z. (2024). How semantic prosody is acquired in novel word learning: Evidence from the “Double-Jujube Tree” effect. Acta Psychologica Sinica, 56(5), 531-541.
doi: 10.3724/SP.J.1041.2024.00531 |
|
[吴诗玉, 李赞. (2024). 新颖词语义韵的发生机制:“双枣树”效应的证据. 心理学报, 56(5), 531-541.]
doi: 10.3724/SP.J.1041.2024.00531 |
| [1] | 周蕾, 李立统, 王旭, 区桦烽, 胡倩瑜, 李爱梅, 古晨妍. 能辨“单次-多次博弈”的大语言模型: 理解与干预风险决策[J]. 心理学报, 2026, 58(3): 416-436. |
| [2] | 戴逸清, 马歆茗, 伍珍. 大语言模型放大共情性别刻板印象:对专业与职业推荐的影响[J]. 心理学报, 2026, 58(3): 399-415. |
| [3] | 章彦博, 黄峰, 莫柳铃, 刘晓倩, 朱廷劭. 基于大语言模型的自杀意念文本数据增强与识别技术[J]. 心理学报, 2025, 57(6): 987-1000. |
| [4] | 高承海, 党宝宝, 王冰洁, 吴胜涛. 人工智能的语言优势和不足:基于大语言模型与真实学生语文能力的比较[J]. 心理学报, 2025, 57(6): 947-966. |
| [5] | 焦丽颖, 李昌锦, 陈圳, 许恒彬, 许燕. 当AI“具有”人格:善恶人格角色对大语言模型道德判断的影响[J]. 心理学报, 2025, 57(6): 929-946. |
| [6] | 武月婷, 王博, 包寒吴霜, 李若男, 吴怡, 王嘉琪, 程诚, 杨丽. 人类对大语言模型的热情和能力感知[J]. 心理学报, 2025, 57(11): 2043-2059. |
| [7] | 黄峰, 丁慧敏, 李思嘉, 韩诺, 狄雅政, 刘晓倩, 赵楠, 李林妍, 朱廷劭. 基于大语言模型的自助式AI心理咨询系统构建及其效果评估[J]. 心理学报, 2025, 57(11): 2022-2042. |
| [8] | 周子森, 黄琪, 谭泽宏, 刘睿, 曹子亨, 母芳蔓, 樊亚春, 秦绍正. 多模态大语言模型动态社会互动情景下的情感能力测评[J]. 心理学报, 2025, 57(11): 1988-2000. |
| [9] | 由姗姗, 齐玥, 陈俊廷, 骆磊, 张侃. 人与AI对智能家居机器人的安全信任及其影响因素[J]. 心理学报, 2025, 57(11): 1951-1972. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||