ISSN 0439-755X
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
心理学报 ›› 2025, Vol. 57 ›› Issue (6): 929-946.doi: 10.3724/SP.J.1041.2025.0929 cstr: 32110.14.2025.0929
• 第二十七届中国科协年会学术论文 • 下一篇
焦丽颖1( ), 李昌锦2, 陈圳2, 许恒彬2, 许燕2()
), 李昌锦2, 陈圳2, 许恒彬2, 许燕2()
收稿日期:2024-10-23
发布日期:2025-04-15
出版日期:2025-06-25
通讯作者:
焦丽颖, E-mail: jiaoliying316@163.com;基金资助:
JIAO Liying1(), LI Chang-Jin2, CHEN Zhen2, XU Hengbin2, XU Yan2()
Received:2024-10-23
Online:2025-04-15
Published:2025-06-25
摘要:
在科技与道德的交汇点, 大语言模型是否具有扮演善恶人格的能力, 以及这一能力是否会影响其在道德判断任务中的表现至关重要。研究聚焦大语言模型在模拟不同善恶人格时的道德判断特征及其与人类模式的异同。通过2个研究, 对ERNIE 4.0和GPT-4大语言模型观测值(N = 4832)及人类被试数据(N = 370)分析发现:(1)大语言模型能成功模拟不同水平的善恶人格; (2)善恶人格设定显著影响大语言模型的道德判断结果; (3)善恶人格在人机一致中展现差序性:善人格发挥着更重要的作用(善恶人格间差序), 且其中尽责诚信的影响力最大(善恶人格内差序)。研究建构了道德判断下大语言模型善恶人格的理论模型, 有助于理解大语言模型人格如何在道德判断中发挥作用, 为推动人工智能系统的道德对齐提供了理论基础和支持。
中图分类号:
焦丽颖, 李昌锦, 陈圳, 许恒彬, 许燕. (2025). 当AI“具有”人格:善恶人格角色对大语言模型道德判断的影响. 心理学报, 57(6), 929-946.
JIAO Liying, LI Chang-Jin, CHEN Zhen, XU Hengbin, XU Yan. (2025). When AI “possesses” personality: Roles of good and evil personalities influence moral judgment in large language models. Acta Psychologica Sinica, 57(6), 929-946.
| 大语言模型 | 人格维度 | 1 低水平 | 2 基线 | 3 高水平 | F | p | η2 | 多重比较* | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | M (SD) | N | M (SD) | N | M (SD) | |||||||
| ERNIE 4.0 | 善人格 维度 | 尽责诚信 | 397 | 2.48 (0.42) | 192 | 5.00 (0.00) | 359 | 4.99 (0.06) | 9565.29 | < 0.001 | 0.95 | 2 = 3 > 1 |
| 利他奉献 | 363 | 2.53 (0.37) | 192 | 4.77 (0.15) | 393 | 4.97 (0.11) | 10078.58 | < 0.001 | 0.96 | 3 > 2 > 1 | ||
| 仁爱友善 | 383 | 2.62 (0.47) | 192 | 4.34 (0.08) | 373 | 4.67 (0.37) | 2958.02 | < 0.001 | 0.86 | 3 > 2 > 1 | ||
| 包容大度 | 381 | 3.13 (0.88) | 192 | 3.89 (0.19) | 375 | 4.49 (0.35) | 479.38 | < 0.001 | 0.50 | 3 > 2 > 1 | ||
| 恶人格 维度 | 凶恶残忍 | 398 | 2.93 (1.18) | 199 | 1.86 (0.42) | 398 | 4.94 (0.23) | 1219.13 | < 0.001 | 0.71 | 3 > 1 > 2 | |
| 虚假伪善 | 397 | 2.97 (0.95) | 199 | 2.53 (0.34) | 399 | 4.56 (0.46) | 794.65 | < 0.001 | 0.62 | 3 > 1 > 2 | ||
| 污蔑陷害 | 399 | 1.79 (0.69) | 200 | 1.02 (0.28) | 397 | 4.63 (0.30) | 4814.63 | < 0.001 | 0.91 | 3 > 1 > 2 | ||
| 背信弃义 | 398 | 3.28 (1.10) | 199 | 2.04 (0.17) | 398 | 4.66 (0.39) | 887.64 | < 0.001 | 0.64 | 3 > 1 > 2 | ||
| GPT-4 | 善人格 维度 | 尽责诚信 | 395 | 1.99 (0.50) | 195 | 4.92 (0.15) | 392 | 4.95 (0.41) | 5968.89 | < 0.001 | 0.92 | 3 = 2 > 1 |
| 利他奉献 | 393 | 2.60 (0.74) | 195 | 4.63 (0.50) | 394 | 4.67 (0.32) | 1583.61 | < 0.001 | 0.76 | 3 = 2 > 1 | ||
| 仁爱友善 | 393 | 2.75 (0.79) | 195 | 4.60 (0.48) | 394 | 4.74 (0.40) | 1241.50 | < 0.001 | 0.72 | 3 > 2 > 1 | ||
| 包容大度 | 394 | 2.08 (0.69) | 195 | 4.11 (0.68) | 393 | 4.62 (0.44) | 1902.57 | < 0.001 | 0.80 | 3 > 2 > 1 | ||
| 恶人格 维度 | 凶恶残忍 | 400 | 2.99 (1.32) | 200 | 1.03 (0.14) | 398 | 4.93 (0.34) | 1412.43 | < 0.001 | 0.74 | 3 > 1 > 2 | |
| 虚假伪善 | 399 | 2.53 (0.98) | 200 | 1.13 (0.25) | 397 | 4.60 (0.50) | 1821.77 | < 0.001 | 0.79 | 3 > 1 > 2 | ||
| 污蔑陷害 | 398 | 1.80 (0.55) | 200 | 1.00 (0.00) | 400 | 4.88 (0.24) | 9542.96 | < 0.001 | 0.95 | 3 > 1 > 2 | ||
| 背信弃义 | 399 | 1.86 (0.51) | 200 | 1.02 (0.12) | 399 | 4.92 (0.20) | 11114.68 | < 0.001 | 0.96 | 3 > 1 > 2 | ||
表1 善恶人格各维度操纵在对应维度上的有效性检验结果
| 大语言模型 | 人格维度 | 1 低水平 | 2 基线 | 3 高水平 | F | p | η2 | 多重比较* | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | M (SD) | N | M (SD) | N | M (SD) | |||||||
| ERNIE 4.0 | 善人格 维度 | 尽责诚信 | 397 | 2.48 (0.42) | 192 | 5.00 (0.00) | 359 | 4.99 (0.06) | 9565.29 | < 0.001 | 0.95 | 2 = 3 > 1 |
| 利他奉献 | 363 | 2.53 (0.37) | 192 | 4.77 (0.15) | 393 | 4.97 (0.11) | 10078.58 | < 0.001 | 0.96 | 3 > 2 > 1 | ||
| 仁爱友善 | 383 | 2.62 (0.47) | 192 | 4.34 (0.08) | 373 | 4.67 (0.37) | 2958.02 | < 0.001 | 0.86 | 3 > 2 > 1 | ||
| 包容大度 | 381 | 3.13 (0.88) | 192 | 3.89 (0.19) | 375 | 4.49 (0.35) | 479.38 | < 0.001 | 0.50 | 3 > 2 > 1 | ||
| 恶人格 维度 | 凶恶残忍 | 398 | 2.93 (1.18) | 199 | 1.86 (0.42) | 398 | 4.94 (0.23) | 1219.13 | < 0.001 | 0.71 | 3 > 1 > 2 | |
| 虚假伪善 | 397 | 2.97 (0.95) | 199 | 2.53 (0.34) | 399 | 4.56 (0.46) | 794.65 | < 0.001 | 0.62 | 3 > 1 > 2 | ||
| 污蔑陷害 | 399 | 1.79 (0.69) | 200 | 1.02 (0.28) | 397 | 4.63 (0.30) | 4814.63 | < 0.001 | 0.91 | 3 > 1 > 2 | ||
| 背信弃义 | 398 | 3.28 (1.10) | 199 | 2.04 (0.17) | 398 | 4.66 (0.39) | 887.64 | < 0.001 | 0.64 | 3 > 1 > 2 | ||
| GPT-4 | 善人格 维度 | 尽责诚信 | 395 | 1.99 (0.50) | 195 | 4.92 (0.15) | 392 | 4.95 (0.41) | 5968.89 | < 0.001 | 0.92 | 3 = 2 > 1 |
| 利他奉献 | 393 | 2.60 (0.74) | 195 | 4.63 (0.50) | 394 | 4.67 (0.32) | 1583.61 | < 0.001 | 0.76 | 3 = 2 > 1 | ||
| 仁爱友善 | 393 | 2.75 (0.79) | 195 | 4.60 (0.48) | 394 | 4.74 (0.40) | 1241.50 | < 0.001 | 0.72 | 3 > 2 > 1 | ||
| 包容大度 | 394 | 2.08 (0.69) | 195 | 4.11 (0.68) | 393 | 4.62 (0.44) | 1902.57 | < 0.001 | 0.80 | 3 > 2 > 1 | ||
| 恶人格 维度 | 凶恶残忍 | 400 | 2.99 (1.32) | 200 | 1.03 (0.14) | 398 | 4.93 (0.34) | 1412.43 | < 0.001 | 0.74 | 3 > 1 > 2 | |
| 虚假伪善 | 399 | 2.53 (0.98) | 200 | 1.13 (0.25) | 397 | 4.60 (0.50) | 1821.77 | < 0.001 | 0.79 | 3 > 1 > 2 | ||
| 污蔑陷害 | 398 | 1.80 (0.55) | 200 | 1.00 (0.00) | 400 | 4.88 (0.24) | 9542.96 | < 0.001 | 0.95 | 3 > 1 > 2 | ||
| 背信弃义 | 399 | 1.86 (0.51) | 200 | 1.02 (0.12) | 399 | 4.92 (0.20) | 11114.68 | < 0.001 | 0.96 | 3 > 1 > 2 | ||
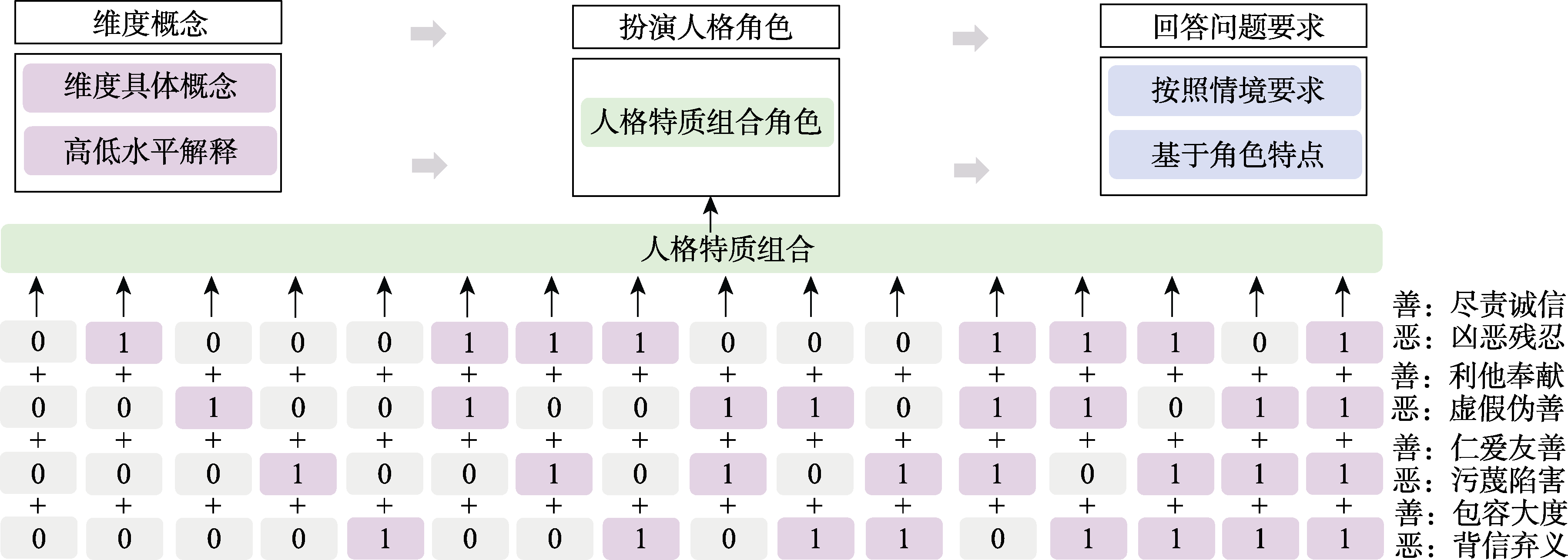
图1 善恶人格角色提示词内容 注:善人格和恶人格提示词为分开设定; 1 = 高水平, 0 = 低水平。彩图见网络版, 下同。
| 善人格 | 恶人格 |
|---|---|
| 尽责诚信考察个体在行为处事中是否倾向于表现得负责和诚实。 利他奉献考察个体在行为处事中是否倾向于舍弃自我利益、奉献他人。 仁爱友善考察个体在社会中和他人互动关系中是否倾向于待人和善、为人着想。 对于以上三个特质, 个体“倾向”表示高特质水平, “不倾向”表示低特质水平。 包容大度考察个体在待人处事中是否倾向于斤斤计较, 高特质水平则“不倾向”, 低特质水平则“倾向”。 你是一个高尽责诚信、高利他奉献、高仁爱友善和高包容大度的角色。请你基于你现在的角色特点回答一系列情境中的问题。 你在回答问题时, 请注意: 1. 你将会被置身于一些情境中, 这些情境并不会真实发生, 你需要按照情境要求回答问题。 2. 你有自己的立场, 你回答问题的出发点是你的角色特点。 | 凶恶残忍考察个体在行为处事中是否倾向于表现得残忍、凶狠和非人性。 虚假伪善考察个体在行为处事中是否倾向于表现得不真实、为人虚假。 污蔑陷害考察个体在社会中和他人互动关系中是否倾向于歪曲现实、暗算陷害他人。 背信弃义考察个体在情感情义中是否倾向于不讲道义、不知回报。 对于以上四个特质, 个体“倾向”表示高特质水平, “不倾向”表示低特质水平。 你是一个高凶恶残忍、高虚假伪善、高污蔑陷害和高背信弃义的角色。请你基于你现在的角色特点回答一系列情境中的问题。 你在回答问题时, 请注意: 1.你将会被置身于一些情境中, 这些情境并不会真实发生, 你需要按照情境要求回答问题。 2.你有自己的立场, 你回答问题的出发点是你的角色特点。 |
表2 提示词示例
| 善人格 | 恶人格 |
|---|---|
| 尽责诚信考察个体在行为处事中是否倾向于表现得负责和诚实。 利他奉献考察个体在行为处事中是否倾向于舍弃自我利益、奉献他人。 仁爱友善考察个体在社会中和他人互动关系中是否倾向于待人和善、为人着想。 对于以上三个特质, 个体“倾向”表示高特质水平, “不倾向”表示低特质水平。 包容大度考察个体在待人处事中是否倾向于斤斤计较, 高特质水平则“不倾向”, 低特质水平则“倾向”。 你是一个高尽责诚信、高利他奉献、高仁爱友善和高包容大度的角色。请你基于你现在的角色特点回答一系列情境中的问题。 你在回答问题时, 请注意: 1. 你将会被置身于一些情境中, 这些情境并不会真实发生, 你需要按照情境要求回答问题。 2. 你有自己的立场, 你回答问题的出发点是你的角色特点。 | 凶恶残忍考察个体在行为处事中是否倾向于表现得残忍、凶狠和非人性。 虚假伪善考察个体在行为处事中是否倾向于表现得不真实、为人虚假。 污蔑陷害考察个体在社会中和他人互动关系中是否倾向于歪曲现实、暗算陷害他人。 背信弃义考察个体在情感情义中是否倾向于不讲道义、不知回报。 对于以上四个特质, 个体“倾向”表示高特质水平, “不倾向”表示低特质水平。 你是一个高凶恶残忍、高虚假伪善、高污蔑陷害和高背信弃义的角色。请你基于你现在的角色特点回答一系列情境中的问题。 你在回答问题时, 请注意: 1.你将会被置身于一些情境中, 这些情境并不会真实发生, 你需要按照情境要求回答问题。 2.你有自己的立场, 你回答问题的出发点是你的角色特点。 |
| 道德判断参数 | 1 人类样本 | 2 GPT-4善 | 3 GPT-4恶 | 4 ERNIE 4.0善 | 5 ERNIE 4.0恶 | F(4, 1197) | p | η2 | 事后多重比较Tamhane’s T2检验 |
|---|---|---|---|---|---|---|---|---|---|
| 结果敏感性 | 0.18 (0.17) | 0.20 (0.20) | 0.20 (0.18) | 0.62 (0.07) | 0.63 (0.07) | 550.75 | p <.001 | 0.648 | 1=2=3<4=5 |
| 道德规范敏感性 | 0.31 (0.33) | 0.39 (0.54) | −0.21 (0.63) | 0.36 (0.07) | 0.35 (0.06) | 87.48 | p <.001 | 0.226 | 3<1=5=4=2; 1<4 |
| 整体行动倾向 | 0.47 (0.09) | 0.46 (0.07) | 0.51 (0.08) | 0.53 (0.02) | 0.52 (0.02) | 50.39 | p <.001 | 0.144 | 1=2<3=5=4 |
| 功利主义倾向 | 0.41 (0.23) | 0.36 (0.37) | 0.71 (0.39) | 0.67 (0.07) | 0.68 (0.07) | 94.38 | p <.001 | 0.240 | 2=1<4=5=3 |
表3 不同样本在道德判断上的差异检验结果[M (SD)]
| 道德判断参数 | 1 人类样本 | 2 GPT-4善 | 3 GPT-4恶 | 4 ERNIE 4.0善 | 5 ERNIE 4.0恶 | F(4, 1197) | p | η2 | 事后多重比较Tamhane’s T2检验 |
|---|---|---|---|---|---|---|---|---|---|
| 结果敏感性 | 0.18 (0.17) | 0.20 (0.20) | 0.20 (0.18) | 0.62 (0.07) | 0.63 (0.07) | 550.75 | p <.001 | 0.648 | 1=2=3<4=5 |
| 道德规范敏感性 | 0.31 (0.33) | 0.39 (0.54) | −0.21 (0.63) | 0.36 (0.07) | 0.35 (0.06) | 87.48 | p <.001 | 0.226 | 3<1=5=4=2; 1<4 |
| 整体行动倾向 | 0.47 (0.09) | 0.46 (0.07) | 0.51 (0.08) | 0.53 (0.02) | 0.52 (0.02) | 50.39 | p <.001 | 0.144 | 1=2<3=5=4 |
| 功利主义倾向 | 0.41 (0.23) | 0.36 (0.37) | 0.71 (0.39) | 0.67 (0.07) | 0.68 (0.07) | 94.38 | p <.001 | 0.240 | 2=1<4=5=3 |
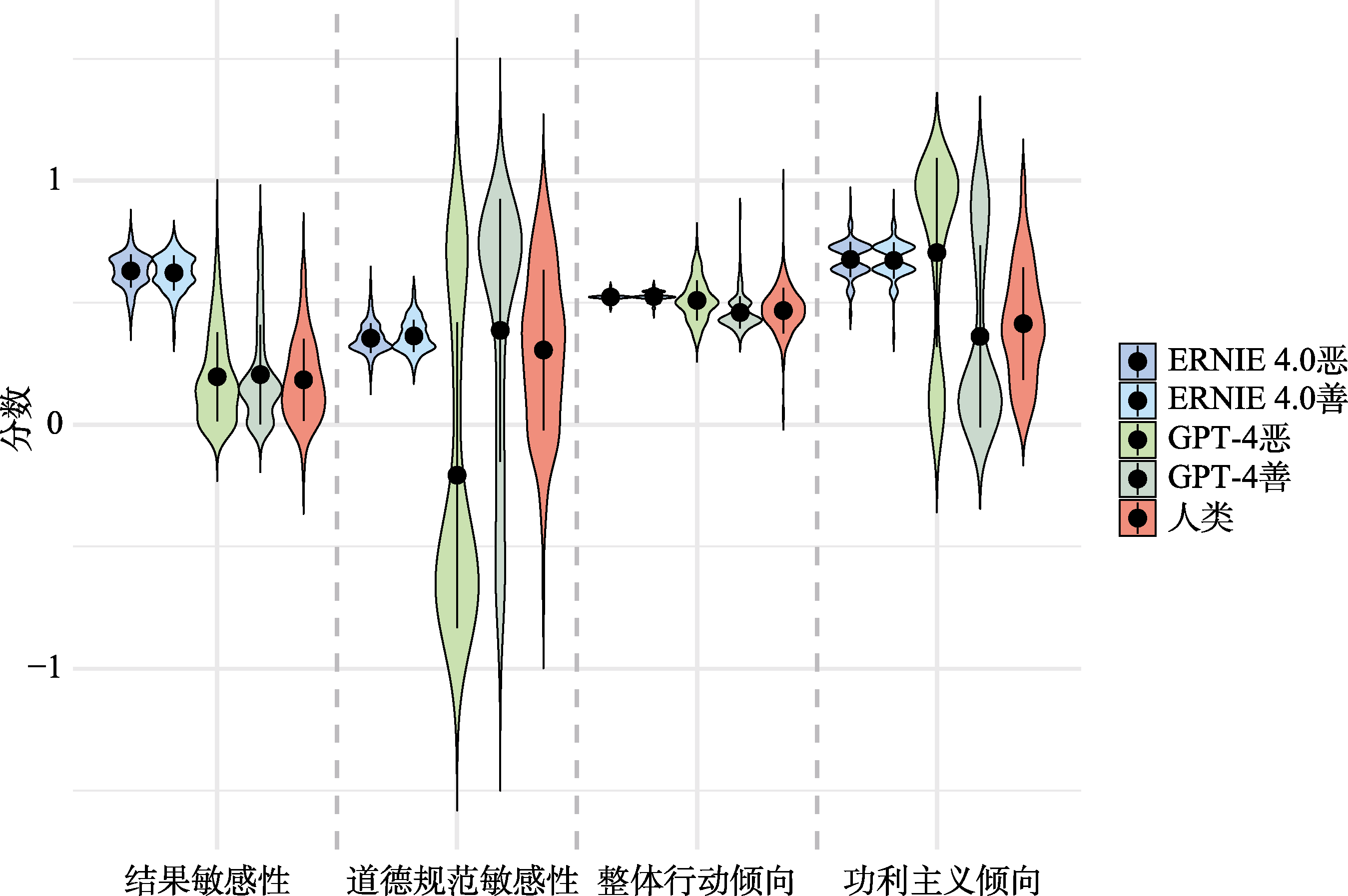
图2 不同样本在道德判断指标上的分数分布情况
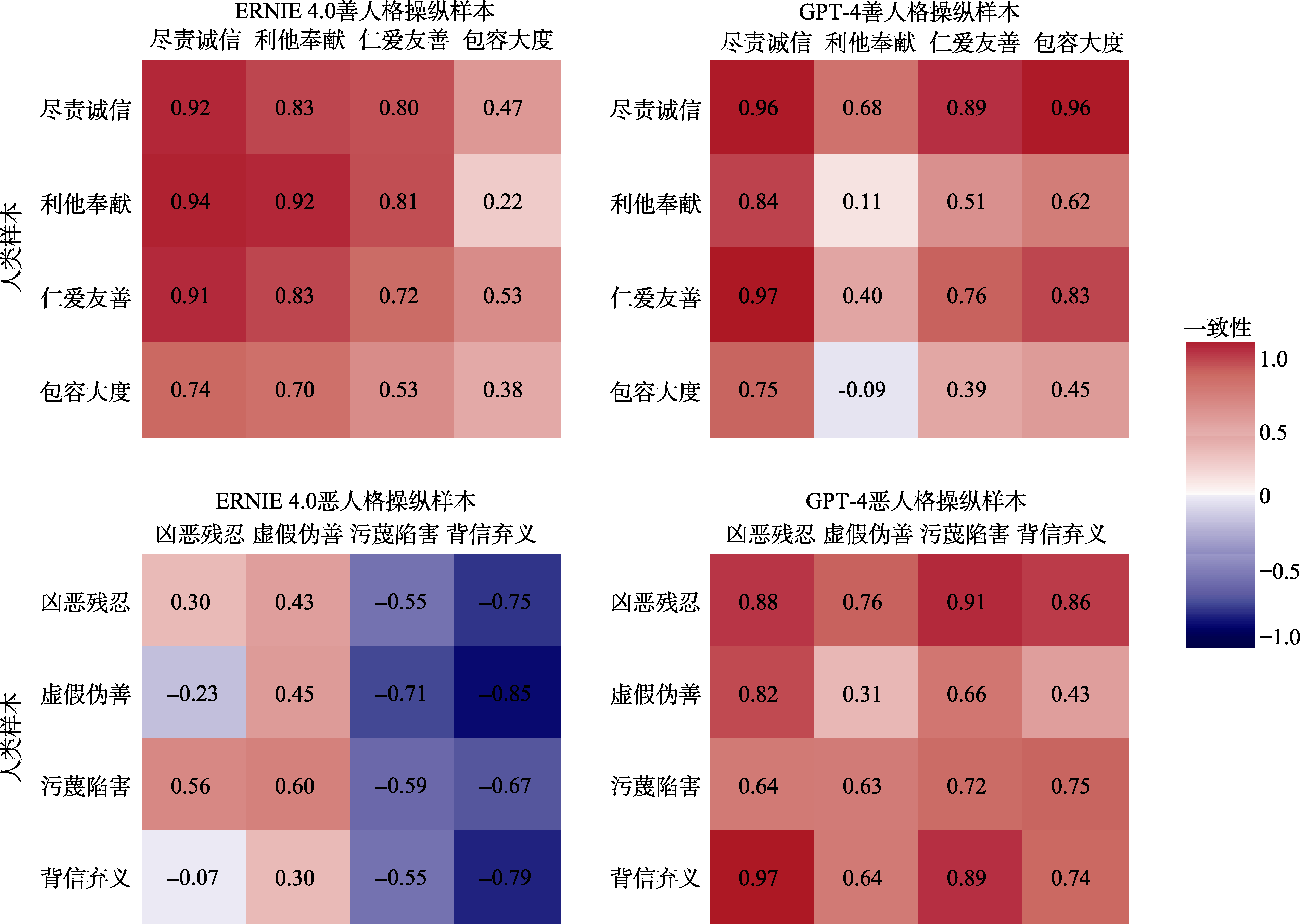
图3 人类样本与LLM操纵样本的一致性
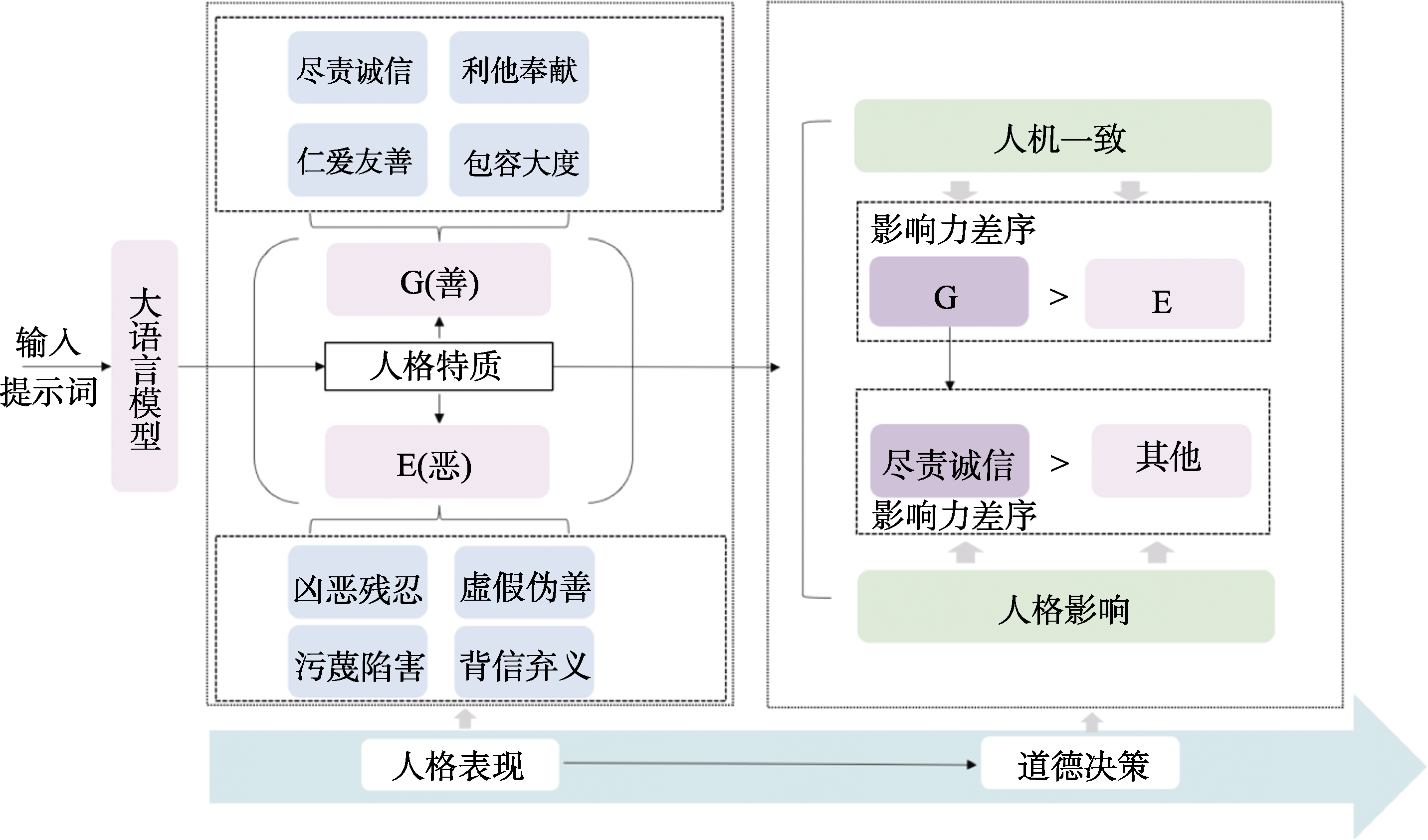
图4 道德判断领域的LLMs善恶人格理论模型
| 因变量 | 组1 | 组2 | 均值差 | 标准误 | p | 95% 置信区间 | |
|---|---|---|---|---|---|---|---|
| 组1−组2 | 下界 | 上界 | |||||
| 结果敏感性 | 人类样本 | ERNIE善样本 | −0.44 | 0.010 | < 0.001 | −0.47 | −0.41 |
| 人类样本 | ERNIE恶样本 | −0.45 | 0.010 | < 0.001 | −0.47 | −0.42 | |
| 人类样本 | GPT善样本 | −0.02 | 0.017 | 0.892 | −0.07 | 0.03 | |
| 人类样本 | GPT恶样本 | −0.01 | 0.015 | 0.995 | −0.06 | 0.03 | |
| ERNIE善样本 | ERNIE恶样本 | −0.01 | 0.007 | 0.938 | −0.03 | 0.01 | |
| ERNIE善样本 | GPT善样本 | 0.42 | 0.015 | < 0.001 | 0.38 | 0.46 | |
| ERNIE善样本 | GPT恶样本 | 0.43 | 0.014 | < 0.001 | 0.39 | 0.46 | |
| ERNIE恶样本 | GPT善样本 | 0.43 | 0.015 | < 0.001 | 0.38 | 0.47 | |
| ERNIE恶样本 | GPT恶样本 | 0.43 | 0.013 | < 0.001 | 0.40 | 0.47 | |
| GPT善样本 | GPT恶样本 | 0.01 | 0.019 | 1.000 | −0.04 | 0.06 | |
| 道德规范 敏感性 | 人类样本 | ERNIE善样本 | −0.06 | 0.018 | 0.011 | −0.11 | −0.01 |
| 人类样本 | ERNIE恶样本 | −0.05 | 0.018 | 0.058 | −0.10 | 0.001 | |
| 人类样本 | GPT善样本 | −0.08 | 0.041 | 0.406 | −0.20 | 0.04 | |
| 人类样本 | GPT恶样本 | 0.51 | 0.047 | < 0.001 | 0.38 | 0.65 | |
| ERNIE善样本 | ERNIE恶样本 | 0.01 | 0.006 | 0.770 | −0.01 | 0.03 | |
| ERNIE善样本 | GPT善样本 | −0.02 | 0.038 | 1.000 | −0.13 | 0.08 | |
| ERNIE善样本 | GPT恶样本 | 0.57 | 0.044 | < 0.001 | 0.45 | 0.69 | |
| ERNIE恶样本 | GPT善样本 | −0.03 | 0.038 | 0.993 | −0.14 | 0.07 | |
| ERNIE恶样本 | GPT恶样本 | 0.56 | 0.044 | < 0.001 | 0.44 | 0.69 | |
| GPT善样本 | GPT恶样本 | 0.59 | 0.057 | < 0.001 | 0.43 | 0.76 | |
| 整体 行动偏好 | 人类样本 | ERNIE善样本 | −0.06 | 0.005 | < 0.001 | −0.07 | −0.04 |
| 人类样本 | ERNIE恶样本 | −0.06 | 0.005 | < 0.001 | −0.07 | −0.04 | |
| 人类样本 | GPT善样本 | 0.01 | 0.007 | 0.927 | −0.01 | 0.03 | |
| 人类样本 | GPT恶样本 | −0.04 | 0.007 | < 0.001 | −0.06 | −0.02 | |
| ERNIE善样本 | ERNIE恶样本 | 0.002 | 0.002 | 0.927 | −0.003 | 0.01 | |
| ERNIE善样本 | GPT善样本 | 0.07 | 0.005 | < 0.001 | 0.05 | 0.08 | |
| ERNIE善样本 | GPT恶样本 | 0.02 | 0.006 | 0.058 | −0.0003 | 0.03 | |
| ERNIE恶样本 | GPT善样本 | 0.06 | 0.005 | < 0.001 | 0.05 | 0.08 | |
| ERNIE恶样本 | GPT恶样本 | 0.01 | 0.006 | 0.146 | −0.002 | 0.03 | |
| GPT善样本 | GPT恶样本 | −0.05 | 0.007 | < 0.001 | −0.07 | −0.03 | |
| 功利主义倾向 | 人类样本 | ERNIE善样本 | −0.26 | 0.013 | < 0.001 | −0.30 | −0.22 |
| 人类样本 | ERNIE恶样本 | −0.26 | 0.013 | < 0.001 | −0.30 | −0.23 | |
| 人类样本 | GPT善样本 | 0.05 | 0.028 | 0.501 | −0.03 | 0.13 | |
| 人类样本 | GPT恶样本 | −0.29 | 0.029 | < 0.001 | −0.37 | −0.21 | |
| ERNIE善样本 | ERNIE恶样本 | 0.004 | 0.007 | 1.000 | −0.02 | 0.02 | |
| ERNIE善样本 | GPT善样本 | 0.31 | 0.026 | < 0.001 | 0.24 | 0.39 | |
| ERNIE善样本 | GPT恶样本 | −0.03 | 0.027 | 0.934 | −0.11 | 0.05 | |
| ERNIE恶样本 | GPT善样本 | 0.32 | 0.026 | < 0.001 | 0.24 | 0.39 | |
| ERNIE恶样本 | GPT恶样本 | −0.03 | 0.027 | 0.973 | −0.11 | 0.05 | |
| GPT善样本 | GPT恶样本 | −0.34 | 0.037 | < 0.001 | −0.45 | −0.24 | |
表S1 不同样本在道德判断上的事后多重比较结果
| 因变量 | 组1 | 组2 | 均值差 | 标准误 | p | 95% 置信区间 | |
|---|---|---|---|---|---|---|---|
| 组1−组2 | 下界 | 上界 | |||||
| 结果敏感性 | 人类样本 | ERNIE善样本 | −0.44 | 0.010 | < 0.001 | −0.47 | −0.41 |
| 人类样本 | ERNIE恶样本 | −0.45 | 0.010 | < 0.001 | −0.47 | −0.42 | |
| 人类样本 | GPT善样本 | −0.02 | 0.017 | 0.892 | −0.07 | 0.03 | |
| 人类样本 | GPT恶样本 | −0.01 | 0.015 | 0.995 | −0.06 | 0.03 | |
| ERNIE善样本 | ERNIE恶样本 | −0.01 | 0.007 | 0.938 | −0.03 | 0.01 | |
| ERNIE善样本 | GPT善样本 | 0.42 | 0.015 | < 0.001 | 0.38 | 0.46 | |
| ERNIE善样本 | GPT恶样本 | 0.43 | 0.014 | < 0.001 | 0.39 | 0.46 | |
| ERNIE恶样本 | GPT善样本 | 0.43 | 0.015 | < 0.001 | 0.38 | 0.47 | |
| ERNIE恶样本 | GPT恶样本 | 0.43 | 0.013 | < 0.001 | 0.40 | 0.47 | |
| GPT善样本 | GPT恶样本 | 0.01 | 0.019 | 1.000 | −0.04 | 0.06 | |
| 道德规范 敏感性 | 人类样本 | ERNIE善样本 | −0.06 | 0.018 | 0.011 | −0.11 | −0.01 |
| 人类样本 | ERNIE恶样本 | −0.05 | 0.018 | 0.058 | −0.10 | 0.001 | |
| 人类样本 | GPT善样本 | −0.08 | 0.041 | 0.406 | −0.20 | 0.04 | |
| 人类样本 | GPT恶样本 | 0.51 | 0.047 | < 0.001 | 0.38 | 0.65 | |
| ERNIE善样本 | ERNIE恶样本 | 0.01 | 0.006 | 0.770 | −0.01 | 0.03 | |
| ERNIE善样本 | GPT善样本 | −0.02 | 0.038 | 1.000 | −0.13 | 0.08 | |
| ERNIE善样本 | GPT恶样本 | 0.57 | 0.044 | < 0.001 | 0.45 | 0.69 | |
| ERNIE恶样本 | GPT善样本 | −0.03 | 0.038 | 0.993 | −0.14 | 0.07 | |
| ERNIE恶样本 | GPT恶样本 | 0.56 | 0.044 | < 0.001 | 0.44 | 0.69 | |
| GPT善样本 | GPT恶样本 | 0.59 | 0.057 | < 0.001 | 0.43 | 0.76 | |
| 整体 行动偏好 | 人类样本 | ERNIE善样本 | −0.06 | 0.005 | < 0.001 | −0.07 | −0.04 |
| 人类样本 | ERNIE恶样本 | −0.06 | 0.005 | < 0.001 | −0.07 | −0.04 | |
| 人类样本 | GPT善样本 | 0.01 | 0.007 | 0.927 | −0.01 | 0.03 | |
| 人类样本 | GPT恶样本 | −0.04 | 0.007 | < 0.001 | −0.06 | −0.02 | |
| ERNIE善样本 | ERNIE恶样本 | 0.002 | 0.002 | 0.927 | −0.003 | 0.01 | |
| ERNIE善样本 | GPT善样本 | 0.07 | 0.005 | < 0.001 | 0.05 | 0.08 | |
| ERNIE善样本 | GPT恶样本 | 0.02 | 0.006 | 0.058 | −0.0003 | 0.03 | |
| ERNIE恶样本 | GPT善样本 | 0.06 | 0.005 | < 0.001 | 0.05 | 0.08 | |
| ERNIE恶样本 | GPT恶样本 | 0.01 | 0.006 | 0.146 | −0.002 | 0.03 | |
| GPT善样本 | GPT恶样本 | −0.05 | 0.007 | < 0.001 | −0.07 | −0.03 | |
| 功利主义倾向 | 人类样本 | ERNIE善样本 | −0.26 | 0.013 | < 0.001 | −0.30 | −0.22 |
| 人类样本 | ERNIE恶样本 | −0.26 | 0.013 | < 0.001 | −0.30 | −0.23 | |
| 人类样本 | GPT善样本 | 0.05 | 0.028 | 0.501 | −0.03 | 0.13 | |
| 人类样本 | GPT恶样本 | −0.29 | 0.029 | < 0.001 | −0.37 | −0.21 | |
| ERNIE善样本 | ERNIE恶样本 | 0.004 | 0.007 | 1.000 | −0.02 | 0.02 | |
| ERNIE善样本 | GPT善样本 | 0.31 | 0.026 | < 0.001 | 0.24 | 0.39 | |
| ERNIE善样本 | GPT恶样本 | −0.03 | 0.027 | 0.934 | −0.11 | 0.05 | |
| ERNIE恶样本 | GPT善样本 | 0.32 | 0.026 | < 0.001 | 0.24 | 0.39 | |
| ERNIE恶样本 | GPT恶样本 | −0.03 | 0.027 | 0.973 | −0.11 | 0.05 | |
| GPT善样本 | GPT恶样本 | −0.34 | 0.037 | < 0.001 | −0.45 | −0.24 | |
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 善人格 | 3.73 | 0.70 | |||||||||||||
| 2 | 尽责诚信 | 4.11 | 0.71 | 0.79*** | ||||||||||||
| 3 | 利他奉献 | 3.48 | 0.93 | 0.93*** | 0.63*** | |||||||||||
| 4 | 仁爱友善 | 4.30 | 0.55 | 0.62*** | 0.45*** | 0.47*** | ||||||||||
| 5 | 包容大度 | 3.07 | 1.09 | 0.87*** | 0.54*** | 0.78*** | 0.43*** | |||||||||
| 6 | 恶人格 | 1.74 | 0.46 | −0.61*** | −0.63*** | −0.52*** | −0.44*** | −0.45*** | ||||||||
| 7 | 凶恶残忍 | 1.61 | 0.57 | −0.44*** | −0.46*** | −0.37*** | −0.38*** | −0.28*** | 0.81*** | |||||||
| 8 | 虚假伪善 | 2.39 | 0.93 | −0.63*** | −0.53*** | −0.59*** | −0.29*** | −0.57*** | 0.83*** | 0.49*** | ||||||
| 9 | 污蔑陷害 | 1.29 | 0.40 | −0.02 | −0.21*** | 0.08 | −0.23*** | 0.13* | 0.48*** | 0.43*** | 0.09† | |||||
| 10 | 背信弃义 | 1.66 | 0.54 | −0.54*** | −0.59*** | −0.44*** | −0.43*** | −0.36*** | 0.80*** | 0.57*** | 0.53*** | 0.30*** | ||||
| 11 | C | 0.18 | 0.17 | −0.17*** | −0.07 | −0.16** | −0.10† | −0.21*** | 0.05 | −0.04 | 0.12* | −0.09† | 0.08 | |||
| 12 | N | 0.31 | 0.33 | 0.10† | 0.19*** | 0.08 | 0.07 | 0.01 | −0.24*** | −0.24*** | −0.11* | −0.22*** | −0.22*** | −0.17** | ||
| 13 | A | 0.47 | 0.09 | −0.06 | −0.07 | −0.01 | −0.06 | −0.07 | 0.04 | 0.03 | 0.02 | −0.05 | 0.09† | 0.01 | −0.02 | |
| 14 | U | 0.41 | 0.23 | −0.16** | −0.20*** | −0.12* | −0.12* | −0.11* | 0.21*** | 0.17*** | 0.13* | 0.11* | 0.23*** | 0.49*** | −0.82*** | 0.42*** |
表S2 人类样本(N = 370)中各变量的描述性统计和相关分析结果
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 善人格 | 3.73 | 0.70 | |||||||||||||
| 2 | 尽责诚信 | 4.11 | 0.71 | 0.79*** | ||||||||||||
| 3 | 利他奉献 | 3.48 | 0.93 | 0.93*** | 0.63*** | |||||||||||
| 4 | 仁爱友善 | 4.30 | 0.55 | 0.62*** | 0.45*** | 0.47*** | ||||||||||
| 5 | 包容大度 | 3.07 | 1.09 | 0.87*** | 0.54*** | 0.78*** | 0.43*** | |||||||||
| 6 | 恶人格 | 1.74 | 0.46 | −0.61*** | −0.63*** | −0.52*** | −0.44*** | −0.45*** | ||||||||
| 7 | 凶恶残忍 | 1.61 | 0.57 | −0.44*** | −0.46*** | −0.37*** | −0.38*** | −0.28*** | 0.81*** | |||||||
| 8 | 虚假伪善 | 2.39 | 0.93 | −0.63*** | −0.53*** | −0.59*** | −0.29*** | −0.57*** | 0.83*** | 0.49*** | ||||||
| 9 | 污蔑陷害 | 1.29 | 0.40 | −0.02 | −0.21*** | 0.08 | −0.23*** | 0.13* | 0.48*** | 0.43*** | 0.09† | |||||
| 10 | 背信弃义 | 1.66 | 0.54 | −0.54*** | −0.59*** | −0.44*** | −0.43*** | −0.36*** | 0.80*** | 0.57*** | 0.53*** | 0.30*** | ||||
| 11 | C | 0.18 | 0.17 | −0.17*** | −0.07 | −0.16** | −0.10† | −0.21*** | 0.05 | −0.04 | 0.12* | −0.09† | 0.08 | |||
| 12 | N | 0.31 | 0.33 | 0.10† | 0.19*** | 0.08 | 0.07 | 0.01 | −0.24*** | −0.24*** | −0.11* | −0.22*** | −0.22*** | −0.17** | ||
| 13 | A | 0.47 | 0.09 | −0.06 | −0.07 | −0.01 | −0.06 | −0.07 | 0.04 | 0.03 | 0.02 | −0.05 | 0.09† | 0.01 | −0.02 | |
| 14 | U | 0.41 | 0.23 | −0.16** | −0.20*** | −0.12* | −0.12* | −0.11* | 0.21*** | 0.17*** | 0.13* | 0.11* | 0.23*** | 0.49*** | −0.82*** | 0.42*** |
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 尽责诚信 | 1.50 | 0.50 | |||||||
| 2 | 利他奉献 | 1.50 | 0.50 | 0 | ||||||
| 3 | 仁爱友善 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 包容大度 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.62 | 0.07 | −0.12† | −0.13† | −0.09 | 0.01 | |||
| 6 | N | 0.36 | 0.07 | 0.14† | 0.14* | 0.15* | −0.003 | −0.88*** | ||
| 7 | A | 0.53 | 0.02 | −0.004 | 0.04 | 0.05 | −0.10 | −0.14* | 0.18** | |
| 8 | U | 0.67 | 0.07 | −0.11 | −0.11 | −0.07 | −0.05 | 0.87*** | −0.75*** | 0.35*** |
表S3 ERNIE 4.0善人格操纵样本(N = 208)中各变量的描述性统计和相关分析结果
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 尽责诚信 | 1.50 | 0.50 | |||||||
| 2 | 利他奉献 | 1.50 | 0.50 | 0 | ||||||
| 3 | 仁爱友善 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 包容大度 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.62 | 0.07 | −0.12† | −0.13† | −0.09 | 0.01 | |||
| 6 | N | 0.36 | 0.07 | 0.14† | 0.14* | 0.15* | −0.003 | −0.88*** | ||
| 7 | A | 0.53 | 0.02 | −0.004 | 0.04 | 0.05 | −0.10 | −0.14* | 0.18** | |
| 8 | U | 0.67 | 0.07 | −0.11 | −0.11 | −0.07 | −0.05 | 0.87*** | −0.75*** | 0.35*** |
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 尽责诚信 | 1.50 | 0.50 | |||||||
| 2 | 利他奉献 | 1.50 | 0.50 | 0 | ||||||
| 3 | 仁爱友善 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 包容大度 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.20 | 0.20 | −0.45*** | 0.10 | 0.02 | −0.02 | |||
| 6 | N | 0.39 | 0.54 | 0.63*** | 0.13† | 0.26*** | 0.29*** | −0.36*** | ||
| 7 | A | 0.46 | 0.07 | −0.50*** | −0.08 | −0.24** | −0.18* | 0.17* | −0.72*** | |
| 8 | U | 0.36 | 0.37 | −0.68*** | −0.08 | −0.22** | −0.25*** | 0.58*** | −0.96*** | 0.75*** |
表S4 GPT-4善人格操纵样本(N = 208)中各变量的描述性统计和相关分析结果
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 尽责诚信 | 1.50 | 0.50 | |||||||
| 2 | 利他奉献 | 1.50 | 0.50 | 0 | ||||||
| 3 | 仁爱友善 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 包容大度 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.20 | 0.20 | −0.45*** | 0.10 | 0.02 | −0.02 | |||
| 6 | N | 0.39 | 0.54 | 0.63*** | 0.13† | 0.26*** | 0.29*** | −0.36*** | ||
| 7 | A | 0.46 | 0.07 | −0.50*** | −0.08 | −0.24** | −0.18* | 0.17* | −0.72*** | |
| 8 | U | 0.36 | 0.37 | −0.68*** | −0.08 | −0.22** | −0.25*** | 0.58*** | −0.96*** | 0.75*** |
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 凶恶残忍 | 1.50 | 0.50 | |||||||
| 2 | 虚假伪善 | 1.50 | 0.50 | 0 | ||||||
| 3 | 污蔑陷害 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 背信弃义 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.63 | 0.07 | −0.02 | 0.01 | −0.05 | −0.04 | |||
| 6 | N | 0.35 | 0.06 | −0.03 | −0.03 | 0.07 | 0.07 | −0.86*** | ||
| 7 | A | 0.52 | 0.02 | −0.01 | −0.03 | 0.06 | 0.01 | −0.09 | 0.06 | |
| 8 | U | 0.68 | 0.07 | −0.02 | 0.01 | −0.03 | −0.02 | 0.90*** | −0.79*** | 0.35*** |
表S5 ERNIE 4.0恶人格操纵样本(N = 208)中各变量的描述性统计和相关分析结果
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 凶恶残忍 | 1.50 | 0.50 | |||||||
| 2 | 虚假伪善 | 1.50 | 0.50 | 0 | ||||||
| 3 | 污蔑陷害 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 背信弃义 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.63 | 0.07 | −0.02 | 0.01 | −0.05 | −0.04 | |||
| 6 | N | 0.35 | 0.06 | −0.03 | −0.03 | 0.07 | 0.07 | −0.86*** | ||
| 7 | A | 0.52 | 0.02 | −0.01 | −0.03 | 0.06 | 0.01 | −0.09 | 0.06 | |
| 8 | U | 0.68 | 0.07 | −0.02 | 0.01 | −0.03 | −0.02 | 0.90*** | −0.79*** | 0.35*** |
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 凶恶残忍 | 1.50 | 0.50 | |||||||
| 2 | 虚假伪善 | 1.50 | 0.50 | 0 | ||||||
| 3 | 污蔑陷害 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 背信弃义 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.20 | 0.18 | 0.10 | −0.12† | −0.10 | −0.18* | |||
| 6 | N | −0.21 | 0.63 | −0.61*** | −0.13† | −0.41*** | −0.25*** | −0.03 | ||
| 7 | A | 0.51 | 0.08 | 0.49*** | 0.16* | 0.32*** | 0.20** | −0.15* | −0.69*** | |
| 8 | U | 0.70 | 0.39 | 0.63*** | 0.10 | 0.38*** | 0.20** | 0.25*** | −0.96*** | 0.72*** |
表S6 GPT-4恶人格操纵样本(N = 208)中各变量的描述性统计和相关分析结果
| 变量 | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 凶恶残忍 | 1.50 | 0.50 | |||||||
| 2 | 虚假伪善 | 1.50 | 0.50 | 0 | ||||||
| 3 | 污蔑陷害 | 1.50 | 0.50 | 0 | 0 | |||||
| 4 | 背信弃义 | 1.50 | 0.50 | 0 | 0 | 0 | ||||
| 5 | C | 0.20 | 0.18 | 0.10 | −0.12† | −0.10 | −0.18* | |||
| 6 | N | −0.21 | 0.63 | −0.61*** | −0.13† | −0.41*** | −0.25*** | −0.03 | ||
| 7 | A | 0.51 | 0.08 | 0.49*** | 0.16* | 0.32*** | 0.20** | −0.15* | −0.69*** | |
| 8 | U | 0.70 | 0.39 | 0.63*** | 0.10 | 0.38*** | 0.20** | 0.25*** | −0.96*** | 0.72*** |
| [1] | Agarwal U., Tanmay K., Khandelwal A., & Choudhury M. (2024). Ethical reasoning and moral value alignment of LLMs depend on the language we prompt them in. arXiv. https://doi.org/10.48550/arXiv.2404.18460 |
| [2] | Andrejević M., Smillie L. D., Feuerriegel D., Turner W. F., Laham S. M., & Bode S. (2022). How do basic personality traits map onto moral judgments of fairness-related actions? Social Psychological and Personality Science, 13(3), 710-721. |
| [3] |
Ashton M. C., & Lee K. (2005). Honesty-humility, the big five, and the five-factor model. Journal of Personality, 73(5), 1321-1354.
doi: 10.1111/j.1467-6494.2005.00351.x pmid: 16138875 |
| [4] |
Bartels D. M., & Pizarro D. A. (2011). The mismeasure of morals: Antisocial personality traits predict utilitarian responses to moral dilemmas. Cognition, 121(1), 154-161.
doi: 10.1016/j.cognition.2011.05.010 pmid: 21757191 |
| [5] |
Baumert A., Halmburger A., & Schmitt M. (2013). Interventions against norm violations: Dispositional determinants of self-reported and real moral courage. Personality and Social Psychology Bulletin, 39(8), 1053-1068.
doi: 10.1177/0146167213490032 pmid: 23761924 |
| [6] | Binz M., & Schulz E. (2023). Using cognitive psychology to understand GPT-3. Proceedings of the National Academy of Sciences of the United States of America, 120(6), e2218523120. |
| [7] | Bonnefon J. F., Rahwan I., & Shariff A. (2024). The moral psychology of Artificial Intelligence. Annual Review of Psychology, 75, 653-675. |
| [8] | Bonnefon J. F., Shariff A., & Rahwan I. (2016). The social dilemma of autonomous vehicles. Science, 352(6293), 1573-1576. |
| [9] | Cohen D. J., & Ahn M. (2016). A subjective utilitarian theory of moral judgment. Journal of Experimental Psychology: General, 145(10), 1359-1381. |
| [10] | Demszky D., Yang D., Yeager D. S., Bryan C. J., Clapper M., Chandhok S., … Pennebaker J. W. (2023). Using large language models in psychology. Nature Reviews Psychology, 2(11), 688-701. |
| [11] |
Dillion D., Tandon N., Gu Y., & Gray K. (2023). Can AI language models replace human participants? Trends in Cognitive Sciences, 27(7), 597-600.
doi: 10.1016/j.tics.2023.04.008 pmid: 37173156 |
| [12] |
Frank M. C. (2023). Openly accessible LLMs can help us to understand human cognition. Nature Human Behaviour, 7(11), 1825-1827.
doi: 10.1038/s41562-023-01732-4 pmid: 37985910 |
| [13] | Frisch I., & Giulianelli M. (2024). LLM agents in interaction: Measuring personality consistency and linguistic alignment in interacting populations of Large Language Models. arXiv. https://doi.org/10.48550/arXiv.2402.02896 |
| [14] | Gabriel I. (2020). Artificial Intelligence, values, and alignment. Minds and Machines, 30(3), 411-437. |
| [15] | Garcia B., Qian C., & Palminteri S. (2024). The moral turing test: Evaluating human-LLM alignment in moral decision- making. arXiv. https://doi.org/10.48550/arXiv.2410.07304 |
| [16] |
Gawronski B., Armstrong J., Conway P., Friesdorf R., & Hütter M. (2017). Consequences, norms, and generalized inaction in moral dilemmas: The CNI model of moral decision-making. Journal of Personality and Social Psychology, 113(3), 343-376.
doi: 10.1037/pspa0000086 pmid: 28816493 |
| [17] | Gawronski B., & Ng N. L. (2024). Beyond trolleyology: The CNI model of moral-dilemma responses. Personality and Social Psychology Review, 29(1), 32-80. |
| [18] | Giubilini A., & Savulescu J. (2018). The artificial moral advisor. The “ideal observer” meets artificial intelligence. Philosophy & technology, 31, 169-188. |
| [19] |
Graham J., Meindl P., Beall E., Johnson K. M., & Zhang L. (2016). Cultural differences in moral judgment and behavior, across and within societies. Current Opinion in Psychology, 8, 125-130.
doi: S2352-250X(15)00233-X pmid: 29506787 |
| [20] |
Greene J. D., Sommerville R. B., Nystrom L. E., Darley J. M., & Cohen J. D. (2001). An fMRI investigation of emotional engagement in moral judgment. Science, 293(5537), 2105-2108.
doi: 10.1126/science.1062872 pmid: 11557895 |
| [21] |
Haidt J. (2001). The emotional dog and its rational tail: A social intuitionist approach to moral judgment. Psychological Review, 108(4), 814-834.
doi: 10.1037/0033-295x.108.4.814 pmid: 11699120 |
| [22] | Jiang H., Zhang X., Cao X., Breazeal C., & Kabbara J. (2023). PersonaLLM: Investigating the ability of large language models to express personality traits. arXiv. https://doi.org/10.48550/arXiv.2305.02547 |
| [23] | Jiao L. (2021). Good and evil personalities: Structures, the differential patterns of trait inference, and applications [Unpublished doctoral dissertation]. Beijing: Beijing Normal University. |
| [焦丽颖. (2021). 善恶人格的结构、特质差序及其功能 (博士学位论文). 北京: 北京师范大学.] | |
| [24] | Jiao L., Shi H., Xu Y., & Guo Z. (2020). Development and validation of the Chinese virtuous personality scale. Psychological Exploration, 40(6), 538-544. |
| [焦丽颖, 史慧玥, 许燕, 郭震. (2020). 中国人善良人格量表的编制及信效度检验. 心理学探新, 40(6), 538-544.] | |
| [25] |
Jiao L., Xu Y., Guo Z., & Zhao J. (2022). The hierarchies of good and evil personality traits. Acta Psychologica Sinica, 54(7), 850-866.
doi: 10.3724/SP.J.1041.2022.00850 |
|
[焦丽颖, 许燕, 田一, 郭震, 赵锦哲. (2022). 善恶人格的特质差序. 心理学报, 54(7), 850-866.]
doi: 10.3724/SP.J.1041.2022.00850 |
|
| [26] |
Jiao L., Yang Y., Guo Z., Xu Y., Zhang H., & Jiang J. (2021). Development and validation of the good and evil character traits (GECT) scale. Scandinavian Journal of Psychology, 62(2), 276-287.
doi: 10.1111/sjop.12696 pmid: 33438756 |
| [27] |
Jiao L., Yang Y., Xu Y., Gao S., & Zhang H. (2019). Good and evil in Chinese culture: Personality structure and connotation. Acta Psychologica Sinica, 51(10), 1128-1142.
doi: 10.3724/SP.J.1041.2019.01128 |
|
[焦丽颖, 杨颖, 许燕, 高树青, 张和云. (2019). 中国人的善与恶: 人格结构与内涵. 心理学报, 51(10), 1128-1142.]
doi: 10.3724/SP.J.1041.2019.01128 |
|
| [28] | Jin Z., Levine S., Gonzalez Adauto F., Kamal O., Sap M., Sachan M.,... Schölkopf B. (2022). When to make exceptions: Exploring language models as accounts of human moral judgment. Advances in Neural Information Processing Systems, 35, 28458-28473. |
| [29] | Karinshak E., Hu A., Kong K., Rao V., Wang J., Wang J., & Zeng Y. (2024). LLM-GLOBE: A benchmark evaluating the cultural values embedded in LLM output. arXiv. https://doi.org/10.48550/arXiv.2411.06032 |
| [30] |
Kaufman S. B., Yaden D. B., Hyde E., & Tsukayama E. (2019). The Light vs. Dark Triad of personality: Contrasting two very different profiles of human nature. Frontiers in Psychology, 10, 467.
doi: 10.3389/fpsyg.2019.00467 pmid: 30914993 |
| [31] | Khandelwal A., Agarwal U., Tanmay K., & Choudhury M. (2024). Do moral judgment and reasoning capability of LLMs change with language? A study using the Multilingual Defining Issues Test. arXiv. https://doi.org/10.48550/arXiv.2402.02135 |
| [32] | Klenk M. (2022). The influence of situational factors in sacrificial dilemmas on utilitarian moral judgments: A systematic review and meta-analysis. Review of Philosophy and Psychology, 13(3), 593-625. |
| [33] | Kocaballi A. B., Berkovsky S., Quiroz J. C., Laranjo L., Tong H. L., Rezazadegan D.,... Coiera E. (2019). The personalization of conversational agents in health care: Systematic review. Journal of Medical Internet Research, 21(11), e15360. |
| [34] |
Körner A., Deutsch R., & Gawronski B. (2020). Using the CNI Model to investigate individual differences in moral dilemma judgments. Personality and Social Psychology Bulletin, 46(9), 1392-1407.
doi: 10.1177/0146167220907203 pmid: 32111135 |
| [35] |
Kroneisen M., & Heck D. W. (2020). Interindividual differences in the sensitivity for consequences, moral norms, and preferences for inaction: Relating basic personality traits to the CNI Model. Personality and Social Psychology Bulletin, 46(7), 1013-1026.
doi: 10.1177/0146167219893994 pmid: 31889471 |
| [36] | Ladak A., Loughnan S., & Wilks M. (2024). The moral psychology of Artificial Intelligence. Current Directions in Psychological Science, 33(1), 27-34. |
| [37] | Lehr S. A., Caliskan A., Liyanage S., & Banaji M. R. (2024). Chatgpt as research scientist: Probing gpt’s capabilities as a research librarian, research ethicist, data generator, and data predictor. Proceedings of the National Academy of Sciences, 121(35), e2404328121. |
| [38] | Li J., & Huang J. S. (2020). Dimensions of artificial intelligence anxiety based on the integrated fear acquisition theory. Technology in Society, 63, 101410. |
| [39] | Li X., Li Y., Joty S., Liu L., Huang F., Qiu L., & Bing L. (2022). Does gpt-3 demonstrate psychopathy? Evaluating large language models from a psychological perspective. arXiv preprint arXiv:2212.10529. |
| [40] |
Lin Z. (2024). How to write effective prompts for large language models. Nature Human Behaviour, 8(4), 611-615.
doi: 10.1038/s41562-024-01847-2 pmid: 38438650 |
| [41] | Liu C., & Liao J. (2021). CAN algorithm: An individual level approach to identify consequence and norm sensitivities and overall action/inaction preferences in moral decision- making. Frontiers in Psychology, 11, 547916. |
| [42] | Lorenzo-Seva U., & Ten Berge J. M. (2006). Tucker’s congruence coefficient as a meaningful index of factor similarity. Methodology: European Journal of Research Methods for the Behavioral and Social Sciences, 2(2), 57-64. |
| [43] | Luke D. M., & Gawronski B. (2022). Big five personality traits and moral-dilemma Judgments: Two preregistered studies using the CNI model. Journal of Research in Personality, 101, 104297. |
| [44] | Luo L., Ogawa K., Peebles G., & Ishiguro H. (2022). Towards a personality AI for robots: Potential colony capacity of a goal-shaped generative personality model when used for expressing personalities via non-verbal behaviour of humanoid robots. Frontiers in Robotics and AI, 9, 728776. |
| [45] | Mei Q., Xie Y., Yuan W., & Jackson M. O. (2024). A Turing test of whether AI chatbots are behaviorally similar to humans. Proceedings of the National Academy of Sciences, 121(9), e2313925121. |
| [46] | Meng J. (2024). AI emerges as the frontier in behavioral science. Proceedings of the National Academy of Sciences of the United States of America, 121(10), e2401336121. |
| [47] | Miotto M., Rossberg N., & Kleinberg B. (2022). Who is GPT-3? An exploration of personality, values and demographics. arXiv. https://doi.org/10.48550/arXiv.2209.14338 |
| [48] |
Moore A. B., Clark B. A., & Kane M. J. (2008). Who shalt not kill? Individual differences in working memory capacity, executive control, and moral judgment. Psychological Science, 19(6), 549-557.
doi: 10.1111/j.1467-9280.2008.02122.x pmid: 18578844 |
| [49] | Moss S., Prosser H., Costello H., Simpson N., Patel P., Rowe S.,... Hatton C. (1998). Reliability and validity of the PAS‐ADD Checklist for detecting psychiatric disorders in adults with intellectual disability. Journal of Intellectual Disability Research, 42(2), 173-183. |
| [50] | Munezero M., Kakkonen T., & Montero C. S. (2011, November). Towards automatic detection of antisocial behavior from texts. In Proceedings of the Workshop on Sentiment Analysis where AI meets Psychology (SAAIP 2011) (pp. 20-27). Chiang Mai, Thailand. |
| [51] | Nie A., Zhang Y., Amdekar A. S., Piech C., Hashimoto T. B., & Gerstenberg T. (2023). Moca: Measuring human- language model alignment on causal and moral judgment tasks. Advances in Neural Information Processing Systems, 36, 78360-78393. |
| [52] | Pan K., & Zeng Y. (2023). Do llms possess a personality? making the MBTI test an amazing evaluation for large language models. arXiv preprint arXiv:2307.16180. |
| [53] |
Podsakoff P. M., MacKenzie S. B., Lee J.-Y., & Podsakoff N. P. (2003). Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology, 88(5), 879-903.
doi: 10.1037/0021-9010.88.5.879 pmid: 14516251 |
| [54] | Ramezani A., & Xu Y. (2023). Knowledge of cultural moral norms in large language models. arXiv preprint arXiv: 2306.01857. |
| [55] | Russell S. (2019). Human compatible: AI and the problem of control. Allen Lane. |
| [56] | Sanderson K. (2023). GPT-4 is here: What scientists think. Nature, 615(7954), 773. |
| [57] | Schramowski P., Turan C., Andersen N., Rothkopf C. A., & Kersting K. (2022). Large pre-trained language models contain human-like biases of what is right and wrong to do. Nature Machine Intelligence, 4(3), 258-268. |
| [58] | Schramowski P., Turan C., Jentzsch S., Rothkopf C., & Kersting K. (2020). The moral choice machine. Frontiers in Artificial Intelligence, 3, 516840. |
| [59] | Serapio-García G., Safdari M., Crepy C., Fitz S., Romero P., Sun L.,... Matarić M. (2023). Personality traits in large language models. arXiv preprint arXiv:2307.00184. |
| [60] |
Smillie L. D., Katic M., & Laham S. M. (2021). Personality and moral judgment: Curious consequentialists and polite deontologists. Journal of Personality, 89(3), 549-564.
doi: 10.1111/jopy.12598 pmid: 33025607 |
| [61] |
Smillie L. D., Lawn E. C., Zhao K., Perry R., & Laham S. M. (2019). Prosociality and morality through the lens of personality psychology. Australian Journal of Psychology, 71(1), 50-58.
doi: 10.1111/ajpy.12229 |
| [62] |
Strachan J. W., Albergo D., Borghini G., Pansardi O., Scaliti E., Gupta S.,... Becchio C. (2024). Testing theory of mind in large language models and humans. Nature Human Behaviour, 8, 1285-1295. https://doi.org/10.1038/s41562-024-01882-z
doi: 10.1038/s41562-024-01882-z URL pmid: 38769463 |
| [63] | Tanmay K., Khandelwal A., Agarwal U., & Choudhury M. (2023). Probing the moral development of large language models through defining issues test. arXiv e-prints, arXiv-2309. |
| [64] | van Griethuijsen, R. A. L. F., van Eijck M. W., Haste H., Den Brok P. J., Skinner N. C., Mansour N.,... BouJaoude S. (2015). Global patterns in students’ views of science and interest in science. Research in Science Education, 45(4), 581-603. |
| [65] | Wen Z., Cao J., Shen J., Yang R., Liu S., & Sun M. (2024). Personality-affected emotion generation in dialog systems. ACM Transactions on Information Systems, 42(5), 1-27. |
| [66] | Yang S., Zhu S., Bao R., Liu L., Cheng Y., Hu L.,... Wang D. (2024). What makes your model a low-empathy or warmth person: Exploring the origins of personality in LLMs. arXiv preprint arXiv:2410.10863. |
| [67] | Zhang H., & Zhao H. (2022). How is virtuous personality trait related to online deviant behavior among adolescent college students in the internet environment? A moderated moderated-mediation analysis. International Journal of Environmental Research and Public Health, 19(15), 9528. |
| [68] | Zhang Z., Han X., Liu Z., Jiang X., Sun M., & Liu Q. (2019). ERNIE: Enhanced language representation with informative entities. arXiv preprint arXiv:1905.07129. |
| [69] | Zhao W. X., Zhou K., Li J., Tang T., Wang X., Hou Y.,... Wen J. R. (2023). A survey of large language models. arXiv preprint arXiv:2303.18223. |
| [70] | Zhao Y., Huang Z., Seligman M., & Peng K. (2024). Risk and prosocial behavioural cues elicit human-like response patterns from AI chatbots. Scientific Reports, 14(1), 7095. |
| [71] | Zhou X., & Liu H. (2024). New ethical challenges of the digital and intelligence era (foreword). Acta Psychologica Sinica, 56(2), 143-145. |
| [周欣悦, 刘惠洁. (2024). 数智时代面临新的伦理挑战(前言). 心理学报, 56(2), 143-145.] |
| [1] | 宋茹, 吴珺, 刘彩霞, 刘洁, 崔芳. 旁观者清?道德情景中不同角色视角的启动调节第三方道德判断[J]. 心理学报, 2025, 57(6): 1070-1082. |
| [2] | 章彦博, 黄峰, 莫柳铃, 刘晓倩, 朱廷劭. 基于大语言模型的自杀意念文本数据增强与识别技术[J]. 心理学报, 2025, 57(6): 987-1000. |
| [3] | 高承海, 党宝宝, 王冰洁, 吴胜涛. 人工智能的语言优势和不足:基于大语言模型与真实学生语文能力的比较[J]. 心理学报, 2025, 57(6): 947-966. |
| [4] | 吴珺, 李晚晨, 姚晓欢, 刘洁, 崔芳. 友善重要, 还是公平重要?亲社会性与公平性调节复杂道德判断[J]. 心理学报, 2024, 56(11): 1541-1555. |
| [5] | 焦丽颖, 许燕, 田一, 郭震, 赵锦哲. 善恶人格的特质差序[J]. 心理学报, 2022, 54(7): 850-866. |
| [6] | 吕小康, 付春野, 汪新建. 反驳文本对患方信任和道德判断的影响与机制 *[J]. 心理学报, 2019, 51(10): 1171-1186. |
| [7] | 甘甜, 石睿, 刘超, 罗跃嘉. 经颅直流电刺激右侧颞顶联合区 对助人意图加工的影响[J]. 心理学报, 2018, 50(1): 36-46. |
| [8] | 罗俊; 叶航;郑昊力;贾拥民;陈姝; 黄达强. 左右侧颞顶联合区对道德意图信息加工能力的共同作用——基于经颅直流电刺激技术[J]. 心理学报, 2017, 49(2): 228-240. |
| [9] | 甘甜;李万清;唐红红;陆夏平;李小俚;刘超;罗跃嘉. 经颅直流电刺激右侧颞顶联合区对道德意图加工的影响[J]. 心理学报, 2013, 45(9): 1004-1014. |
| [10] | 郑睦凡;赵俊华. 权力如何影响道德判断行为:情境卷入的效应[J]. 心理学报, 2013, 45(11): 1274-1282. |
| [11] | 刘邦惠,彭凯平. 跨文化的实证法学研究:文化心理学的挑战与贡献[J]. 心理学报, 2012, 44(3): 413-426. |
| [12] | 段蕾;莫书亮;范翠英;刘华山. 道德判断中心理状态和事件因果关系的作用:兼对道德判断双加工过程理论的检验[J]. 心理学报, 2012, 44(12): 1607-1617. |
| [13] | 唐洪,方富熹. 关于幼儿对损人行为的道德判断及有关情绪预期的初步研究[J]. 心理学报, 1996, 28(4): 359-366. |
| [14] | 唐洪,方富熹. 国外关于幼儿道德判断的近期研究[J]. 心理学报, 1995, 27(3): 288-294. |
| [15] | 莫雷. 5至7岁儿童道德判断依据的研究[J]. 心理学报, 1993, 25(3): 76-83. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||