ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
心理科学进展 ›› 2025, Vol. 33 ›› Issue (8): 1340-1357.doi: 10.3724/SP.J.1042.2025.1340 cstr: 32111.14.2025.1340
陈静仪1, 宋丽红2( ), 汪文义1
), 汪文义1
收稿日期:2024-09-20
出版日期:2025-08-15
发布日期:2025-05-15
通讯作者:
宋丽红, E-mail: viviansong1981@163.com基金资助:
CHEN Jingyi1, SONG Lihong2(), WANG Wenyi1
Received:2024-09-20
Online:2025-08-15
Published:2025-05-15
摘要:
心理测验、教育测验和医学测验广泛应用于测试者分类, 而内部一致性和α等信度系数并不能直接评价分类信度, 如何评估标准参照测验的分类信度, 成为研究者和实践者关注的重要问题。本研究从分类一致性方法视角, 探究单次施测测验的分类一致性估计模式, 分析各类代表性方法发展脉络及其核心思想, 结合各方法相关软件包与程序, 分析人格测验、学业测验、诊断测验等真实数据。结合理论分析与数据分析, 总结各类方法的优劣与影响因素, 提出选用各类方法的建议, 讨论分类一致性区间估计等问题, 推动分类测验的分类一致性的研究、应用与报告。
中图分类号:
陈静仪, 宋丽红, 汪文义. (2025). 心理与教育测验分类信度:分类一致性评估方法. 心理科学进展 , 33(8), 1340-1357.
CHEN Jingyi, SONG Lihong, WANG Wenyi. (2025). Classification consistency for measuring classification reliability of psychological and educational tests. Advances in Psychological Science, 33(8), 1340-1357.
| 维度 | 分类一致性估计方法 | 划界分数为20 | 划界分数为(10, 30) | ||||
|---|---|---|---|---|---|---|---|
| 500 | 1000 | 2000 | 500 | 1000 | 2000 | ||
| 宜人性 | Rudner方法 | 0.932 | 0.939 | 0.940 | 0.846 | 0.844 | 0.842 |
| Lee等人( | 0.883 | 0.890 | 0.891 | 0.763 | 0.769 | 0.766 | |
| Lee ( | 0.891 | 0.901 | 0.903 | 0.783 | 0.785 | 0.781 | |
| Lathrop和Cheng ( | 0.888 | 0.897 | 0.899 | 0.789 | 0.798 | 0.800 | |
| 责任心 | Rudner方法 | 0.835 | 0.837 | 0.843 | 0.967 | 0.972 | 0.972 |
| Lee等人( | 0.770 | 0.775 | 0.772 | 0.823 | 0.826 | 0.826 | |
| Lee ( | 0.756 | 0.756 | 0.760 | 0.894 | 0.899 | 0.895 | |
| Lathrop和Cheng ( | 0.778 | 0.785 | 0.783 | 0.857 | 0.862 | 0.861 | |
表1 宜人性和责任心两个维度的分类一致性
| 维度 | 分类一致性估计方法 | 划界分数为20 | 划界分数为(10, 30) | ||||
|---|---|---|---|---|---|---|---|
| 500 | 1000 | 2000 | 500 | 1000 | 2000 | ||
| 宜人性 | Rudner方法 | 0.932 | 0.939 | 0.940 | 0.846 | 0.844 | 0.842 |
| Lee等人( | 0.883 | 0.890 | 0.891 | 0.763 | 0.769 | 0.766 | |
| Lee ( | 0.891 | 0.901 | 0.903 | 0.783 | 0.785 | 0.781 | |
| Lathrop和Cheng ( | 0.888 | 0.897 | 0.899 | 0.789 | 0.798 | 0.800 | |
| 责任心 | Rudner方法 | 0.835 | 0.837 | 0.843 | 0.967 | 0.972 | 0.972 |
| Lee等人( | 0.770 | 0.775 | 0.772 | 0.823 | 0.826 | 0.826 | |
| Lee ( | 0.756 | 0.756 | 0.760 | 0.894 | 0.899 | 0.895 | |
| Lathrop和Cheng ( | 0.778 | 0.785 | 0.783 | 0.857 | 0.862 | 0.861 | |
| 分类一致性估计方法 | 划界分数为16 | 划界分数为(10, 20) | ||||
|---|---|---|---|---|---|---|
| 200 | 500 | 765 | 200 | 500 | 765 | |
| Livingston和Lewis ( | 0.749 | 0.757 | 0.759 | 0.601 | 0.628 | 0.623 |
| Rudner方法 | 0.874 | 0.866 | 0.855 | 0.770 | 0.775 | 0.775 |
| Lee ( | 0.918 | 0.908 | 0.888 | 0.791 | 0.788 | 0.785 |
| Lathrop和Cheng ( | 0.860 | 0.858 | 0.847 | 0.742 | 0.752 | 0.757 |
表2 不同分类一致性估计方法在不同划界分数上的分类一致性
| 分类一致性估计方法 | 划界分数为16 | 划界分数为(10, 20) | ||||
|---|---|---|---|---|---|---|
| 200 | 500 | 765 | 200 | 500 | 765 | |
| Livingston和Lewis ( | 0.749 | 0.757 | 0.759 | 0.601 | 0.628 | 0.623 |
| Rudner方法 | 0.874 | 0.866 | 0.855 | 0.770 | 0.775 | 0.775 |
| Lee ( | 0.918 | 0.908 | 0.888 | 0.791 | 0.788 | 0.785 |
| Lathrop和Cheng ( | 0.860 | 0.858 | 0.847 | 0.742 | 0.752 | 0.757 |
| 知识状态估计方法 | 分类一致性估计方法 | 属性1 | 属性2 | 属性3 | 模式 |
|---|---|---|---|---|---|
| MLE | Wang等人( | 0.783 | 0.658 | 0.844 | 0.453 |
| Thompson等人( | 0.746 | 0.664 | 0.799 | 0.428 | |
| MAP | Johnson和Sinharay ( | 0.894 | 0.856 | 0.877 | 0.782 |
| Thompson等人( | 0.860 | 0.832 | 0.845 | 0.754 |
表3 ECPE上认知诊断分类
| 知识状态估计方法 | 分类一致性估计方法 | 属性1 | 属性2 | 属性3 | 模式 |
|---|---|---|---|---|---|
| MLE | Wang等人( | 0.783 | 0.658 | 0.844 | 0.453 |
| Thompson等人( | 0.746 | 0.664 | 0.799 | 0.428 | |
| MAP | Johnson和Sinharay ( | 0.894 | 0.856 | 0.877 | 0.782 |
| Thompson等人( | 0.860 | 0.832 | 0.845 | 0.754 |
| 分类一致性估计方法 | 600 | 800 | 1000 |
|---|---|---|---|
| Lee ( | 0.950 | 0.952 | 0.950 |
| Rudner方法 | 0.953 | 0.949 | 0.949 |
| Gonzalez等人( | 0.927 | 0.937 | 0.951 |
| Gonzalez等人( | 0.925 | 0.934 | 0.949 |
| Gonzalez等人( | 0.942 | 0.951 | 0.950 |
表4 Gonzalez数据集上分类一致性
| 分类一致性估计方法 | 600 | 800 | 1000 |
|---|---|---|---|
| Lee ( | 0.950 | 0.952 | 0.950 |
| Rudner方法 | 0.953 | 0.949 | 0.949 |
| Gonzalez等人( | 0.927 | 0.937 | 0.951 |
| Gonzalez等人( | 0.925 | 0.934 | 0.949 |
| Gonzalez等人( | 0.942 | 0.951 | 0.950 |
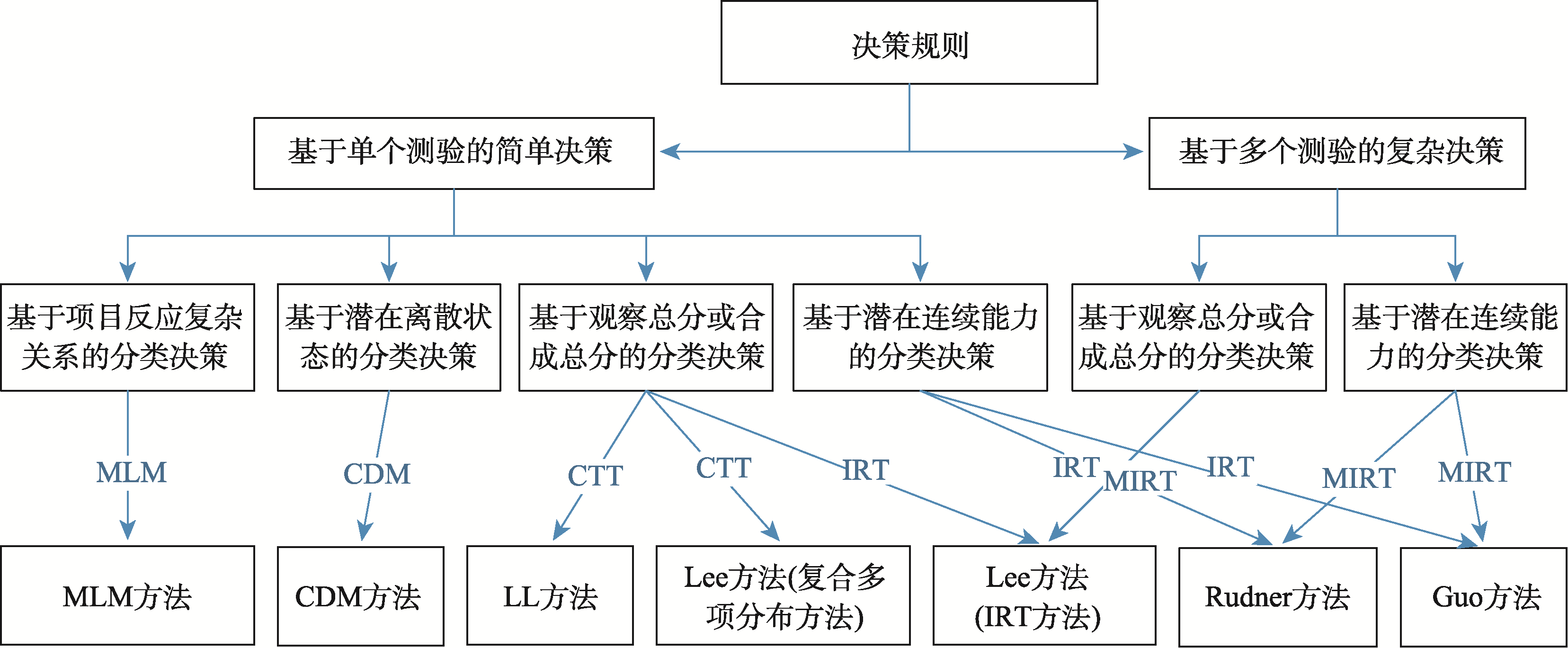
图1 各种方法选择流程图
| 模型 | 代表方法 | 分类标准 | 优点 | 缺点 | 测验应用 | 软件 |
|---|---|---|---|---|---|---|
| CTT | Livingston和Lewis ( | 五类:A[161, 200], B[143, 160], C[103, 142], D[60, 102], E[0, 59] | 适用0~1、多级或混合评分的测验情景。 | 计算较为复杂。 | 英语测验, 小学教师资格测验和AP考试(合成分数)等 | R:betafunction包 程序 BB-CLASS |
| Lee等人( | 四类:15, 30和45 | 多项分布模型和复合多项分布模型可灵活刻画分数分布。 | 样本量较小时会有一定误差。 | 科学成就测试 | 程序 MULT-CLASS | |
| Wolkowit ( | 两类:30 | 简单易于计算, 只需要测验信度和测验分数分布。 | 使用单一误差刻画不同分数误差。 | 执照考试 | 文中未提及 | |
| IRT | Rudner ( | 五类: [375, 489], [490, 529], [530, 579], [580, 619], [620, 650] | 测验信息量具有良好的统计理论基础, 适应测验广。 | 短测验的能力分布可能违背正态性。 | 阅读测试 | R:IRTQ cacIRT包 |
| Guo ( | 三类: 基础[275, 410] 熟练[411, 446] 高级[447, 575] | 放松了能力正态性假设, 具有较好的适用性。 | 相比Guo方法, 计算稍复杂。 | 州考试 | SPSS代码 | |
| Lee ( | 两类:38 四类:15, 30和45 | 适用于基于观察分数分类决策, 具有较好的解释性和易接受性, 对于大规模评估尤为重要。 | 递归方法计算总分或合成分数分布较为复杂。 | 数学测试和科学成就测验 | R:IRTQ包、 cacIRT包。 程序IRT-CLASS | |
| Lathrop和Cheng ( | 两类:分数范围中某个分数 四类:总分分布25%, 50%, 75%的百分位数 | 不依赖于参数模型项目特征曲线特定假设, 适用于能力分布不确定或不满足正态情景。 | 需要使用密度平滑方法, 递归方法较为复杂。 | 数学测试和模拟数据 | R:cacIRT包 | |
| Cheng等人( | 两类:能力量尺上某个能力 | 基于能力标准误差定义分类一致性, 适用于定长(变长)计算机自适应测试下分类一致性估计。 | 复杂分类问题, 该方法仍需要进一步拓展。 | 模拟数据 | 文中未提及 | |
| 汪文义等人( | 总分50%和80%的分位数或能力0和0.75 | 将Guo等方法拓展到MIRT, 适用于复杂决策规则。 | 蒙特卡洛多重积分估计, 计算较为复杂。 | 模拟数据 | Matlab自编程序 | |
| Kim和Lee ( | 五类(如59, 82, 97和118)及两类 | 将Lee方法拓展应用于SS-MIRT和Bi-MIRT, 用于混合题型测验。 | 仅适用于特殊的MIRT模型。 | AP考试(选择题和主观题的混合题型测验) | 程序 MULT-CLASS, BB-CLASS, NM-CLASS | |
| Park等人( | 四类(如总分的25, 50和75百分位数) | 拓展了Lee方法适用于SS-MIRT处理多个测验复杂决策情景。 | 多个决策规则的独立性和相关性仍有待考虑。 | 教师教学国际调查TALIS (测量自我效能和满意度两个维度) | 文章未提及 | |
| IRT | Setzer等人( | 真实数据的划界分数未提及 | 拓展了Rudner方法, 适用于估计多个测验合成能力的分类一致性。 | 计算是否可以简化, 值得进一步研究。 | 注册会计师考试 | R自编程序 |
| CDM | Cui等人( | 极大似然方法 | 考虑了所有可能项目得分模式, 可视为总体统计量。 | 测验长度长时计算量大。 | 分数减法测验 | Mathematica自编程序 |
| Wang等人( | 属性掌握概率0.5 | 简单易行的样本分类一致性估计方法, 拓展了属性水平分类一致性估计。 | 依赖于模型参数, 对样本量有一定要求。 | 模拟数据 | Matlab自编程序 | |
| Johnson和Sinharay ( | 最大后验概率法 | 样本分类一致性估计方法, 并引入了分类一致性的其他度量方法。 | 无法得到个体分类一致性。 | ECPE数据 | R:CDM包 cdm.est.class.accuracy函数 | |
| Thompson等人( | 属性掌握概率0.5 | 可以报告多个水平(如属性掌握数量)的分类一致性。 | 模拟需要更多计算时间和资源。 | 模拟数据 | R:CDM包 cdm.est.class.accuracy函数 | |
| MLM | Gonzalez等人( | 两类:最大化约登指数的划界分数 | 适用于复杂高维数据, 能够自动提取有效特征, 减少人工干预。 | 需要标注数据实现模型的训练和优化。 | 压力测验 人格测验 情绪测验 | R自编程序 |
附表1 分类一致性方法对比
| 模型 | 代表方法 | 分类标准 | 优点 | 缺点 | 测验应用 | 软件 |
|---|---|---|---|---|---|---|
| CTT | Livingston和Lewis ( | 五类:A[161, 200], B[143, 160], C[103, 142], D[60, 102], E[0, 59] | 适用0~1、多级或混合评分的测验情景。 | 计算较为复杂。 | 英语测验, 小学教师资格测验和AP考试(合成分数)等 | R:betafunction包 程序 BB-CLASS |
| Lee等人( | 四类:15, 30和45 | 多项分布模型和复合多项分布模型可灵活刻画分数分布。 | 样本量较小时会有一定误差。 | 科学成就测试 | 程序 MULT-CLASS | |
| Wolkowit ( | 两类:30 | 简单易于计算, 只需要测验信度和测验分数分布。 | 使用单一误差刻画不同分数误差。 | 执照考试 | 文中未提及 | |
| IRT | Rudner ( | 五类: [375, 489], [490, 529], [530, 579], [580, 619], [620, 650] | 测验信息量具有良好的统计理论基础, 适应测验广。 | 短测验的能力分布可能违背正态性。 | 阅读测试 | R:IRTQ cacIRT包 |
| Guo ( | 三类: 基础[275, 410] 熟练[411, 446] 高级[447, 575] | 放松了能力正态性假设, 具有较好的适用性。 | 相比Guo方法, 计算稍复杂。 | 州考试 | SPSS代码 | |
| Lee ( | 两类:38 四类:15, 30和45 | 适用于基于观察分数分类决策, 具有较好的解释性和易接受性, 对于大规模评估尤为重要。 | 递归方法计算总分或合成分数分布较为复杂。 | 数学测试和科学成就测验 | R:IRTQ包、 cacIRT包。 程序IRT-CLASS | |
| Lathrop和Cheng ( | 两类:分数范围中某个分数 四类:总分分布25%, 50%, 75%的百分位数 | 不依赖于参数模型项目特征曲线特定假设, 适用于能力分布不确定或不满足正态情景。 | 需要使用密度平滑方法, 递归方法较为复杂。 | 数学测试和模拟数据 | R:cacIRT包 | |
| Cheng等人( | 两类:能力量尺上某个能力 | 基于能力标准误差定义分类一致性, 适用于定长(变长)计算机自适应测试下分类一致性估计。 | 复杂分类问题, 该方法仍需要进一步拓展。 | 模拟数据 | 文中未提及 | |
| 汪文义等人( | 总分50%和80%的分位数或能力0和0.75 | 将Guo等方法拓展到MIRT, 适用于复杂决策规则。 | 蒙特卡洛多重积分估计, 计算较为复杂。 | 模拟数据 | Matlab自编程序 | |
| Kim和Lee ( | 五类(如59, 82, 97和118)及两类 | 将Lee方法拓展应用于SS-MIRT和Bi-MIRT, 用于混合题型测验。 | 仅适用于特殊的MIRT模型。 | AP考试(选择题和主观题的混合题型测验) | 程序 MULT-CLASS, BB-CLASS, NM-CLASS | |
| Park等人( | 四类(如总分的25, 50和75百分位数) | 拓展了Lee方法适用于SS-MIRT处理多个测验复杂决策情景。 | 多个决策规则的独立性和相关性仍有待考虑。 | 教师教学国际调查TALIS (测量自我效能和满意度两个维度) | 文章未提及 | |
| IRT | Setzer等人( | 真实数据的划界分数未提及 | 拓展了Rudner方法, 适用于估计多个测验合成能力的分类一致性。 | 计算是否可以简化, 值得进一步研究。 | 注册会计师考试 | R自编程序 |
| CDM | Cui等人( | 极大似然方法 | 考虑了所有可能项目得分模式, 可视为总体统计量。 | 测验长度长时计算量大。 | 分数减法测验 | Mathematica自编程序 |
| Wang等人( | 属性掌握概率0.5 | 简单易行的样本分类一致性估计方法, 拓展了属性水平分类一致性估计。 | 依赖于模型参数, 对样本量有一定要求。 | 模拟数据 | Matlab自编程序 | |
| Johnson和Sinharay ( | 最大后验概率法 | 样本分类一致性估计方法, 并引入了分类一致性的其他度量方法。 | 无法得到个体分类一致性。 | ECPE数据 | R:CDM包 cdm.est.class.accuracy函数 | |
| Thompson等人( | 属性掌握概率0.5 | 可以报告多个水平(如属性掌握数量)的分类一致性。 | 模拟需要更多计算时间和资源。 | 模拟数据 | R:CDM包 cdm.est.class.accuracy函数 | |
| MLM | Gonzalez等人( | 两类:最大化约登指数的划界分数 | 适用于复杂高维数据, 能够自动提取有效特征, 减少人工干预。 | 需要标注数据实现模型的训练和优化。 | 压力测验 人格测验 情绪测验 | R自编程序 |
| [1] | 陈平. (2022). 浅谈标准设定中的关键技术: 来自我国大规模测评项目的经验. 中国考试, (8), 48-56. |
| [2] | 陈平, 李珍, 辛涛, 高慧健. (2011). 标准参照测验决策一致性指标研究的总结与展望. 心理发展与教育, 27(2), 210-215. |
| [3] | 陈思佚, 崔红, 周仁来, 贾艳艳. (2012). 正念注意觉知量表(MAAS)的修订及信效度检验. 中国临床心理学杂志, 20(2), 148-151. |
| [4] | 陈希镇. (1996). 标准参照测验中的信度估计公式. 心理学报, 28(4), 436-442. |
| [5] | 丁树良, 罗芬, 涂冬波. (2012). 项目反应理论新进展专题研究. 北京: 北京师范大学出版社. |
| [6] | 郭磊, 张金明, 宋乃庆. (2019). 整合后验信息的多分属性认知诊断信效度指标. 心理科学, 42(2), 446-454. |
| [7] | 廖友国, 张本钰. (2024). 成年中期抑郁情绪的变化轨迹:基于增长混合模型. 心理科学, 47(2), 300-307. |
| [8] | 刘晓梅, 卞冉, 车宏生, 王丽娜, 邵燕萍. (2011). 情境判断测验的效度研究述评. 心理科学进展, 19(5), 740-748. |
| [9] |
任赫, 黄颖诗, 陈平. (2022). 计算机化分类测验终止规则的类别、特点及应用. 心理科学进展, 30(5), 1168-1182.
doi: 10.3724/SP.J.1042.2022.01168 |
| [10] | 宋吉祥, 李付鹏. (2022). 高中学业水平考试等级赋分的分类一致性和准确性研究. 教学与管理, (24), 37-41. |
| [11] | 汪大勋, 涂冬波. (2021). 认知诊断计算机化自适应测量技术在心理障碍诊断与评估中的应用. 江西师范大学学报(自然科学版), 45(2), 111-117. |
| [12] | 汪文义, 方小婷, 叶宝娟. (2018). 认知诊断属性分类一致性信度区间估计三种方法. 心理科学, 41(6), 1492-1499. |
| [13] | 汪文义, 宋丽红, 丁树良. (2016). 复杂决策规则下MIRT的分类准确性和分类一致性. 心理学报, 48(12), 1612-1624. |
| [14] | 王昭, 郭庆科, 岳艳. (2007). 心理测验中个人拟合研究的回顾与展望. 心理科学进展, 15(3), 559-566. |
| [15] | 温忠麟, 叶宝娟. (2011). 测验信度估计: 从α系数到内部一致性信度. 心理学报, 43(7), 821-829. |
| [16] | 张军. (2015). 单维参数型与非参数型项目反应理论项目参数的比较研究. 心理学探新, 35(3), 279-283. |
| [17] | 中共中央, 国务院. (2020). 新时代教育评价改革总体方案. 2024-06-03 取自 https://www.gov.cn/zhengce/2020-10/13/content_5551032.htm. |
| [18] | 周成超, 楚洁, 王婷, 彭倩倩, 何江江, 郑文贵,... 徐凌忠. (2008). 简易心理状况评定量表Kessler10中文版的信度和效度评价. 中国临床心理学杂志, 16(6), 627-629. |
| [19] | Chang, H. H., & Stout, W. (1993). The asymptotic posterior normality of the latent trait in an IRT model. Psychometrika, 58(1), 37-52. |
| [20] |
Cheng, Y., Liu, C., & Behrens, J. (2015). Standard error of ability estimates and the classification accuracy and consistency of binary decisions. Psychometrika, 80(3), 645-664.
doi: 10.1007/s11336-014-9407-z pmid: 25228494 |
| [21] | Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20(1), 37-46. |
| [22] | Cui, Y., Gierl, M. J., & Chang, H. H. (2012). Estimating classification consistency and accuracy for cognitive diagnostic assessment. Journal of Educational Measurement, 49(1), 19-38. |
| [23] | Deng, N., & Hambleton, R. K. (2013). Evaluating CTT- and IRT-based single-administration estimates of classification consistency and accuracy. In R. E. Millsap, L. A. van der Ark, D. M. Bolt, & C. M. Woods (Eds.), Springer proceedings in mathematics & statistics: Vol. 66: New developments in quantitative psychology (pp. 235-250). Springer. |
| [24] | Douglas, J., & Cohen, A. (2001). Nonparametric item response function estimation for assessing parametric model fit. Applied Psychological Measurement, 25(3), 234-243. |
| [25] | Givens, G. H., & Hoeting, J. A. (2013). Computational statistics. John Wiley & Sons. Inc. |
| [26] | Glaser, R. (1963). Instructional technology and the measurement of learing outcomes: Some questions. American Psychologist, 18(8), 519-521. |
| [27] | Goldberg, L. R. (1992). The development of markers for the Big-Five factor structure. Psychological Assessment, 4(1), 26-42. |
| [28] | Gonzalez, O. (2021a). Psychometric and machine learning approaches for diagnostic assessment and tests of individual classification. Psychological Methods, 26(2), 236-254. |
| [29] | Gonzalez, O. (2021b). Psychometric and machine learning approaches to reduce the length of scales. Multivariate Behavioral Research, 56(6), 903-919. |
| [30] |
Gonzalez, O. (2023). Summary intervals for model-based classification accuracy and consistency indices. Educational and Psychological Measurement, 83(2), 240-261.
doi: 10.1177/00131644221092347 pmid: 36866072 |
| [31] | Gonzalez, O., Georgeson, A. R., & Pelham, W. E. (2023). How accurate and consistent are score-based assessment decisions? A procedure using the linear factor model. Assessment, 30(5), 1640-1650. |
| [32] |
Gonzalez, O., Georgeson, A. R., & Pelham, W. E. (2024). Estimating classification consistency of machine learning models for screening measures. Psychological Assessment, 36(6-7), 395-406.
doi: 10.1037/pas0001313 pmid: 38829349 |
| [33] |
Gonzalez, O., Georgeson, A. R., Pelham, W. E., & Fouladi, R. T. (2021). Estimating classification consistency of screening measures and quantifying the impact of measurement bias. Psychological Assessment, 33(7), 596-609.
doi: 10.1037/pas0000938 pmid: 33998821 |
| [34] | Guo, F. (2006). Expected classification accuracy using the latent distribution. Practical Assessment, Research and Evaluation, 11(6), 1-9. |
| [35] | Hambleton, R. K., & Novick, M. R. (1973). Toward an integration of theory and method for criterion-referenced tests. Journal of Educational Measurement, 10(3), 159-170. |
| [36] | Hanson, B. A. (1991). Method of moments estimates for the four-parameter beta compound binomial model and the calculation of classification consistency indexes (Research Rep. No. 91-5). Iowa City, IA: American College Testing. |
| [37] | Hanson, B. A., & Brennan, R. L. (1990). An investigation of classification consistency indexes estimated under alternative strong true score models. Journal of Educational Measurement, 27(4), 345-359. |
| [38] | Huynh, H. (1976). On the reliability of decisions in domain-referenced testing. Journal of Educational Measurement, 13(4), 253-264. |
| [39] | Huynh, H. (1979). Statistical inference for two reliability indices in mastery testing based on the beta-binomial model. Journal of Educational Statistics, 4(3), 231-246. |
| [40] | Jiang, Y., Zhang, J., & Xin, T. (2019). Toward education quality improvement in China: A brief overview of the national assessment of education quality. Journal of Educational and Behavioral Statistics, 44(6), 733-751. |
| [41] | Johnson, M. S., & Sinharay, S. (2018). Measures of agreement to assess attribute-level classification accuracy and consistency for cognitive diagnostic assessments. Journal of Educational Measurement, 55(4), 635-664. |
| [42] | Johnson, M. S., & Sinharay, S. (2020). The reliability of the posterior probability of skill attainment in diagnostic classification models. Journal of Educational and Behavioral Statistics, 45(1), 5-31. |
| [43] |
Kessler, R. C., Barker, P. R., Colpe, L. J., Epstein, J. F., Gfroerer, J. C., Hiripi, E., Howes, M. J., … Zaslavsky, A. M. (2003). Screening for serious mental illness in the general population. Archives of General Psychiatry, 60(2), 184-189.
doi: 10.1001/archpsyc.60.2.184 pmid: 12578436 |
| [44] |
Kim, S. Y., & Lee, W.-C. (2019). Classification consistency and accuracy for mixed-format tests. Applied Measurement in Education, 32(2), 97-115.
doi: 10.1080/08957347.2019.1577246 |
| [45] | Lathrop, Q. N., & Cheng, Y. (2013). Two approaches to estimation of classification accuracy rate under item response theory. Applied Psychological Measurement, 37(3), 226-241. |
| [46] | Lathrop, Q. N., & Cheng, Y. (2014). A nonparametric approach to estimate classification accuracy and consistency. Journal of Educational Measurement, 51(3), 318-334. |
| [47] | Lee, W. (2010). Classification consistency and accuracy for complex assessments using item response theory. Journal of Educational Measurement, 47(1), 1-17. |
| [48] | Lee, W.-C., Brennan, R. L., & Wan, L. (2009). Classification consistency and accuracy for complex assessments under the compound multinomial model. Applied Psychological Measurement, 33(5), 374-390. |
| [49] | Lee, W.-C., Hanson, B. A., & Brennan, R. L. (2002). Estimating consistency and accuracy indices for multiple classifications. Applied Psychological Measurement, 26(4), 412-432. |
| [50] | Livingston, S. A. (1972). Criterion-referenced applications of classical test theory. Journal of Educational Measurement, 9(1), 13-26. |
| [51] | Livingston, S. A., & Lewis, C. (1995). Estimating the consistency and accuracy of classifications based on test scores. Journal of Educational Measurement, 32(2), 179-197. |
| [52] |
Lord, F. M. (1965). A strong true-score theory, with applications. Psychometrika, 30(3), 239-270.
pmid: 5216215 |
| [53] | Lord, F. M., & Wingersky, M. S. (1984). Comparison of IRT true-score and equipercentile observed-score "equatings". Applied Psychological Measurement, 8(4), 453-461. |
| [54] | Maas, L., Brinkhuis, M. J. S., Kester, L., & Meij, L. W. (2022). Cognitive diagnostic assessment in university statistics education: Valid and reliable skill measurement for actionable feedback using learning dashboards. Applied Sciences, 12(10), Article 4809. |
| [55] | Martineau, J. A. (2007). An expansion and practical evaluation of expected classification accuracy. Applied Psychological Measurement, 31(3), 181-194. |
| [56] | Nájera, P., Abad, F. J., Chiu, C.-Y., & Sorrel, M. A. (2023). The restricted DINA model: A comprehensive cognitive diagnostic model for classroom-level assessments. Journal of Educational and Behavioral Statistics, 48(6), 719-749. |
| [57] | Park, S., Kim, K. Y., & Lee, W. (2023). Estimating classification accuracy and consistency indices for multiple measures with the simple structure MIRT model. Journal of Educational Measurement, 60(1), 106-125. |
| [58] | Popham, W. J., & Husek, T. R. (1969). Implications of criterion-referenced measurement. Journal of Educational Measurement, 6(1), 1-9. |
| [59] | Radloff, L. S. (1977). The CES-D scale: A self-report depression scale for research in the general population. Applied Psychological Measurement, 1(3), 385-401. |
| [60] | Ramsay, J. O. (1991). Kernel smoothing approaches to nonparametric item characteristic curve estimation. Psychometrika, 56(4), 611-630. |
| [61] | Ravand, H., & Baghaei, P. (2019). Diagnostic classification models: Recent developments, practical issues, and prospects. International Journal of Testing, 20(1), 24-56. |
| [62] | Roussos, L. A., DiBello, L. V., Stout, W., Hartz, S. M., Henson, R. A., & Templin, J. L. (2007). The Fusion model skills diagnosis system. In: J. P. Leighton, & M. J. Gierl (Eds.), Cognitive diagnostic assessment for education: Theory and applications (pp. 275-318). Cambridge University Press. |
| [63] | Rudner, L. M. (2001). Computing the expected proportions of misclassified examinees. Practical Assessment, Research & Evaluation, 7(14), 1-8. |
| [64] | Rudner, L. M. (2005). Expected classification accuracy. Practical Assessment Research and Evaluation, 10(13), 1-4. |
| [65] | Rupp, A. A., Templin, J. L., & Henson, R. A. (2010). Diagnostic measurement: Theory, methods, and applications. The Guilford Press. |
| [66] | Santor, D. A., Ramsay, J. O., & Zuroff, D. C. (1994). Nonparametric item analyses of the Beck depression inventory: Evaluating gender item bias and response option weights. Psychological Assessment, 6(3), 255-270. |
| [67] | Selzer, M. L. (1971). The Michigan alcoholism screening test: The quest for a new diagnostic instrument. The American Journal of Psychiatry, 127(12), 1653-1658. |
| [68] | Setzer, J. C., Cheng, Y., & Liu, C. (2023). Classification accuracy and consistency of compensatory composite test scores. Journal of Educational Measurement, 60(3), 501-519. |
| [69] | Shrock, S. A., & Coscarelli, W. C. (2007). Criterion- referenced test development: Technical and legal guidelines for corporate training (3rd ed.). John Wiley & Sons, Inc. |
| [70] |
Skaggs, G., Wilkins, J. L. M., & Hein, S. F. (2017). Estimating an observed score distribution from a cognitive diagnostic model. Applied Psychological Measurement, 41(2), 150-154.
doi: 10.1177/0146621616677320 pmid: 29881084 |
| [71] | Subkoviak, M. J. (1976). Estimating reliability from a single administration of a criterion-referenced test. Journal of Educational Measurement, 13(4), 265-276. |
| [72] | Subkoviak, M. J. (1978). Empirical investigation of procedures for estimating reliability for mastery tests. Journal of Educational Measurement, 15(2), 111-116. |
| [73] | Swaminathan, H., Hambleton, R. K., & Algina, J. (1974). Reliability of criterion-referenced tests: A decision- theoretic formulation. Journal of Educational Measurement, 11(4), 263-267. |
| [74] |
Teitelbaum, L. M., & Carey, K. B. (2000). Temporal stability of alcohol screening measures in a psychiatric setting. Psychology of Addictive Behaviors, 14(4), 401-404.
pmid: 11130159 |
| [75] | Templin, J., & Bradshaw, L. (2013). Measuring the reliability of diagnostic classification model examinee estimates. Journal of Classification, 30(2), 251-275. |
| [76] |
Templin, J. L., & Henson, R. A. (2006). Measurement of psychological disorders using cognitive diagnosis models. Psychological Methods, 11(3), 287-305.
pmid: 16953706 |
| [77] | Thissen, D., Pommerich, M., Billeaud, K., & Williams, V. S. L. (1995). Item response theory for scores on tests including polytomous items with ordered responses. Applied Psychological Measurement, 19(1), 39-49. |
| [78] |
Thompson, W. J., Clark, A. K., & Nash, B. (2019). Measuring the reliability of diagnostic mastery classifications at multiple levels of reporting. Applied Measurement in Education, 32(4), 298-309.
doi: 10.1080/08957347.2019.1660345 |
| [79] | Thompson, W. J., Nash, B., Clark, A. K., & Hoover, J. C. (2023). Using simulated retests to estimate the reliability of diagnostic assessment systems. Journal of Educational Measurement, 60(3), 455-475. |
| [80] | von Davier, M., & Lee, Y.-S. (Ed.). (2019). Handbook of diagnostic classification models: Models and model extensions, applications, software packages. Springer International Publishing. |
| [81] | Wang, W., Song, L., Chen, P., & Ding, S. (2019). An item-level expected classification accuracy and its applications in cognitive diagnostic assessment. Journal of Educational Measurement, 56(1), 51-75. |
| [82] | Wang, W., Song, L., Chen, P., Meng, Y., & Ding, S. (2015). Attribute-level and pattern-level classification consistency and accuracy indices for cognitive diagnostic assessment. Journal of Educational Measurement, 52(4), 457-476. |
| [83] | Wang, W., Song, L., & Ding, S. (2017). An extension of Rudner-based consistency and accuracy indices for multidimensional item response theory. In L. A. von der Ark, M. Wiberg, S. A. Culpepper, J. A. Douglas, & W.-C. Wang (Eds.), Springer proceedings in mathematics & statistics: Vol 196: Quantitative psychology . (pp.43-58). Springer New York LLC. |
| [84] | Wang, W., Song, L., Ding, S., & Meng, Y. (2016). Estimating classification accuracy and consistency indices for multidimensional latent ability. In: van der Ark, L., Bolt, D., Wang, W. C., Douglas, J., Wiberg, M. (Eds.), Springer proceedings in mathematics & statistics: Vol 167: Quantitative psychology research (pp.89-103). Springer. |
| [85] | Wolkowitz, A. A. (2021). A computationally simple method for estimating decision consistency. Journal of Educational Measurement, 58(3), 388-412. |
| [86] | Wyse, A. E., & Hao, S. (2012). An evaluation of item response theory classification accuracy and consistency indices. Applied Psychological Measurement, 36(7), 602-624. |
| [87] |
Youngstrom, E. A. (2014). A primer on receiver operating characteristic analysis and diagnostic efficiency statistics for pediatric psychology: We are ready to ROC. Journal of Pediatric Psychology, 39(2), 204-221.
doi: 10.1093/jpepsy/jst062 pmid: 23965298 |
| [88] | Zhang, S., Du, J., Chen, P., Xin, T., & Chen, F. (2017). Using procedure based on item response theory to evaluate classification consistency indices in the practice of large-scale assessment. Frontiers in Psychology, 8, Article 1676. |
| [1] | 刘永进, 杨雪, 杜欣欣, 嵇文麒, 臧寅垠, 官锐园, 宋森, 钱铭怡, 牟文婷. 融合机器学习技术的阈下抑郁神经生理机制及干预[J]. 心理科学进展, 2025, 33(6): 887-904. |
| [2] | 高白雪, 谢云龙, 罗俊龙, 贺雯. 机器学习在提高非自杀性自伤预测力中的应用:一项系统综述[J]. 心理科学进展, 2025, 33(3): 506-519. |
| [3] | 宋丽红, 汪文义, 丁树良. 认知诊断评估中Q矩阵理论及应用[J]. 心理科学进展, 2024, 32(6): 1010-1033. |
| [4] | 高旭亮, 李宁. 机器学习方法在测验安全领域的应用[J]. 心理科学进展, 2024, 32(11): 1814-1828. |
| [5] | 陈新文, 李鸿杰, 丁玉珑. 探究事件相关脑电/脑磁信号中的神经表征模式:基于分类解码和表征相似性分析的方法[J]. 心理科学进展, 2023, 31(2): 173-195. |
| [6] | 卜晓鸥, 王耀, 杜亚雯, 王沛. 机器学习在发展性阅读障碍儿童早期筛查中的应用[J]. 心理科学进展, 2023, 31(11): 2092-2105. |
| [7] | 刘笑晗, 陈明隆, 郭静. 机器学习在儿童创伤后应激障碍识别及转归预测中的应用[J]. 心理科学进展, 2022, 30(4): 851-862. |
| [8] | 侯婷婷, 陈潇, 孔德彭, 邵秀筠, 林丰勋, 李开云. 机器学习在自闭症儿童早期识别和诊断领域的应用[J]. 心理科学进展, 2022, 30(10): 2321-2337. |
| [9] | 苏悦, 刘明明, 赵楠, 刘晓倩, 朱廷劭. 基于社交媒体数据的心理指标识别建模: 机器学习的方法[J]. 心理科学进展, 2021, 29(4): 571-585. |
| [10] | 李佳, 毛秀珍, 张雪琴. 认知诊断Q矩阵估计(修正)方法[J]. 心理科学进展, 2021, 29(12): 2272-2280. |
| [11] | 董健宇, 韦文棋, 吴珂, 妮娜, 王粲霏, 付莹, 彭歆. 机器学习在抑郁症领域的应用[J]. 心理科学进展, 2020, 28(2): 266-274. |
| [12] | 郑泓, 蒲城城, 王毅, 陈楚侨. 基于脑结构像的精神分裂症机器学习分类[J]. 心理科学进展, 2020, 28(2): 252-265. |
| [13] | 唐倩, 毛秀珍, 何明霜, 何洁. 认知诊断计算机化自适应测验的选题策略[J]. 心理科学进展, 2020, 28(12): 2160-2168. |
| [14] | 张雪琴, 毛秀珍, 李佳. 基于CAT的在线标定:设计与方法[J]. 心理科学进展, 2020, 28(11): 1970-1978. |
| [15] | 梁静, 阮倩男, 李贺, 马梦晴, 颜文靖. 认知负荷取向下基于记忆-反应冲突的欺骗检测[J]. 心理科学进展, 2020, 28(10): 1619-1630. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||