ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
心理科学进展 ›› 2026, Vol. 34 ›› Issue (3): 404-423.doi: 10.3724/SP.J.1042.2026.0404 cstr: 32111.14.2026.0404
田雪涛1, 周文杰2, 骆方1, 乔志宏1, 丰怡3( )
)
收稿日期:2024-12-23
出版日期:2026-03-15
发布日期:2026-01-07
通讯作者:
丰怡, E-mail: fengyi@cufe.edu.cn作者简介:第一联系人:† 田雪涛和周文杰为本文共同第一作者。
基金资助:
TIAN Xuetao1, ZHOU Wenjie2, LUO Fang1, QIAO Zhihong1, FENG Yi3()
Received:2024-12-23
Online:2026-03-15
Published:2026-01-07
摘要:
生成式大语言模型(Generative Large Language Models, Generative LLMs, 通常简称LLMs)是一种在大规模语料库上预训练的人工智能模型, 为心理测量学领域带来前所未有的机遇和挑战。本文通过整合人工智能与心理学交叉研究发展脉络, 总结LLMs赋能心理测量学的显著优势, 定位LLMs在心理学应用中的重要挑战, 并提出基于LLMs的心理测量研究发展方向。具体地, LLMs能够基于上下文生成连贯的自然语言文本, 具有改变传统测验交互方式的潜力; LLMs突破对超长文本和多模态数据的处理能力, 其强大的内容理解能力能够全面获取和分析被试的心理信息; LLMs有助于实现实时分析和个性化反馈, 促进从结果评价向过程评价的转变。尽管LLMs的实际应用面临着稳定性、创造性和拓展性等挑战, 但在情境判断测验生成、合作式问题解决能力评估、心理健康智慧诊疗和试题质量分析等领域展现出广阔的应用前景和研究价值。
中图分类号:
田雪涛, 周文杰, 骆方, 乔志宏, 丰怡. (2026). 生成式大语言模型赋能心理测量学:优势、挑战与应用. 心理科学进展 , 34(3), 404-423.
TIAN Xuetao, ZHOU Wenjie, LUO Fang, QIAO Zhihong, FENG Yi. (2026). Empowering psychometrics with generative large language models: Advantages, challenges, and applications. Advances in Psychological Science, 34(3), 404-423.
| 概念 | 英文 | 含义 |
|---|---|---|
| 生成式大语言模型 | Generative Large Language Models | 一种在海量文本数据(大规模语料库)上进行“预训练”的人工智能模型。其核心能力是理解上下文, 并生成连贯、自然的语言文本。 |
| 预训练 | Pre-Training | 在开发LLM的初始阶段, 使用巨量的、无特定任务标签的文本数据对其进行训练。这个过程旨在让模型学习语言的通用规律、事实知识和语义关系。 |
| 微调 | Fine-Tuning | 在“预训练”之后, 使用一个规模更小、与特定任务相关的“有标注”数据集来进一步训练模型, 使其更好地适应和完成这个特定任务。 |
| Transformer架构 | Transformer Architecture | 一种深度学习模型架构, 是生成式大语言模型的技术基石。其核心是“注意力机制”, 允许模型在处理文本时, 能够权衡不同单词的重要性, 从而实现对长距离依赖和复杂上下文的深度理解。 |
| 多模态 | Multimodal | 模型能够同时处理和理解多种不同类型的数据(模态), 例如文本、图像、音频和视频等。多模态LLMs能将这些不同来源的信息进行深度融合。 |
| 上下文学习 | In-Context Learning | 用户只需在输入(Prompt)中给出少量任务示例或清晰的指令, 模型就能“当场学会”并解决新的、类似的任务, 而无需对模型本身进行任何永久性的改变。 |
| 思维链 | Chain of Thought | 一种引导LLMs进行更复杂推理的技术。通过在指令中要求模型“一步一步地思考”或“展示推理过程”, 可以显著提高其在逻辑、数学和复杂推理任务上的准确性。 |
| 语义向量空间 | Embedding Space | 通过特定的编码器, 将非结构化数据(如文字、图像、声音)映射(转换)到高维数学空间中。在这个空间里, 来自不同模态但语义相关的概念也能得到近似的数值向量表征, 例如, 文字“苹果”和一张苹果的图片在该空间中的位置会非常接近。 |
表1 LLMs相关术语及其含义
| 概念 | 英文 | 含义 |
|---|---|---|
| 生成式大语言模型 | Generative Large Language Models | 一种在海量文本数据(大规模语料库)上进行“预训练”的人工智能模型。其核心能力是理解上下文, 并生成连贯、自然的语言文本。 |
| 预训练 | Pre-Training | 在开发LLM的初始阶段, 使用巨量的、无特定任务标签的文本数据对其进行训练。这个过程旨在让模型学习语言的通用规律、事实知识和语义关系。 |
| 微调 | Fine-Tuning | 在“预训练”之后, 使用一个规模更小、与特定任务相关的“有标注”数据集来进一步训练模型, 使其更好地适应和完成这个特定任务。 |
| Transformer架构 | Transformer Architecture | 一种深度学习模型架构, 是生成式大语言模型的技术基石。其核心是“注意力机制”, 允许模型在处理文本时, 能够权衡不同单词的重要性, 从而实现对长距离依赖和复杂上下文的深度理解。 |
| 多模态 | Multimodal | 模型能够同时处理和理解多种不同类型的数据(模态), 例如文本、图像、音频和视频等。多模态LLMs能将这些不同来源的信息进行深度融合。 |
| 上下文学习 | In-Context Learning | 用户只需在输入(Prompt)中给出少量任务示例或清晰的指令, 模型就能“当场学会”并解决新的、类似的任务, 而无需对模型本身进行任何永久性的改变。 |
| 思维链 | Chain of Thought | 一种引导LLMs进行更复杂推理的技术。通过在指令中要求模型“一步一步地思考”或“展示推理过程”, 可以显著提高其在逻辑、数学和复杂推理任务上的准确性。 |
| 语义向量空间 | Embedding Space | 通过特定的编码器, 将非结构化数据(如文字、图像、声音)映射(转换)到高维数学空间中。在这个空间里, 来自不同模态但语义相关的概念也能得到近似的数值向量表征, 例如, 文字“苹果”和一张苹果的图片在该空间中的位置会非常接近。 |
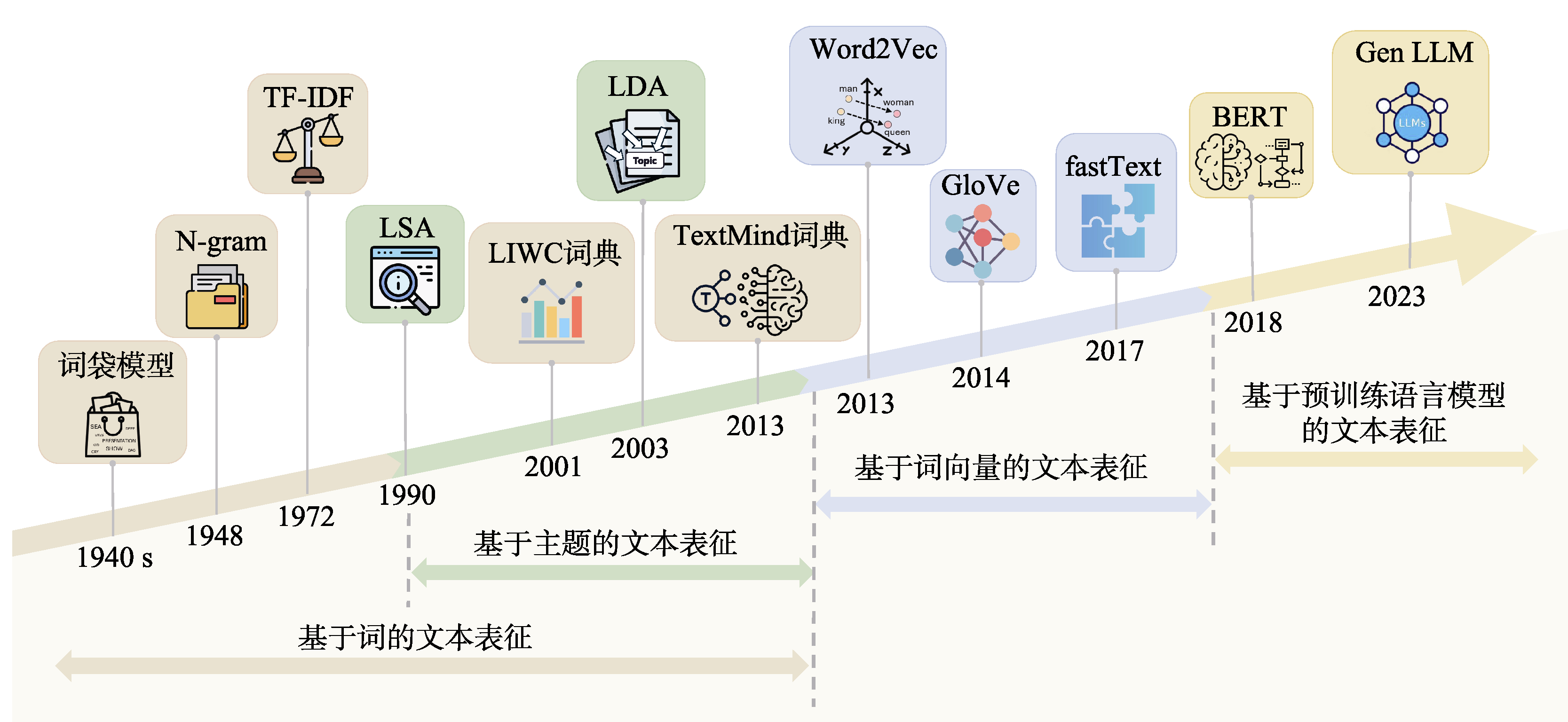
图1 文本表征的技术演进
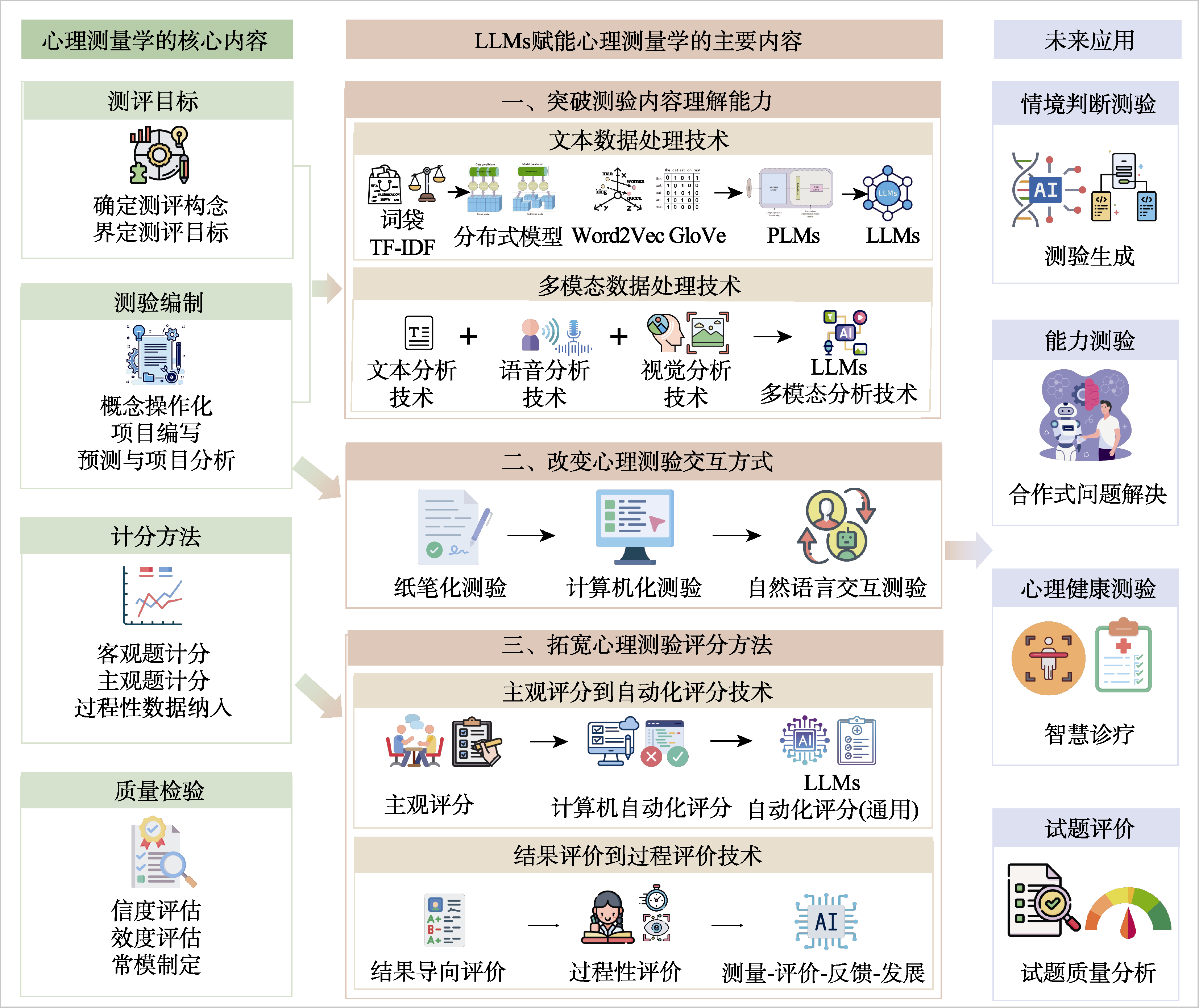
图2 LLMs赋能心理测量学的主要内容框架
| [1] | 方晓义, 袁晓娇, 胡伟, 邓林园, 蔺秀云. (2018). 中国大学生心理健康筛查量表的编制. 心理与行为研究, 16(1), 111-118. |
| [2] |
姜力铭, 田雪涛, 任萍, 骆方. (2022). 人工智能辅助下的心理健康新型测评. 心理科学进展, 30(1), 157-167.
doi: 10.3724/SP.J.1042.2022.00157 |
| [3] |
焦丽颖, 李昌锦, 陈圳, 许恒彬, 许燕. (2025). 当AI“具有”人格: 善恶人格角色对大语言模型道德判断的影响. 心理学报, 57(6), 929-949.
doi: 10.3724/SP.J.1041.2025.0929 |
| [4] | 柯罗马, 李增逸, 廖江群, 童松, 彭凯平. (2025). 大语言模型模拟区域心理结构的有效性:人格与幸福感的实证检验. 心理科学, 48(4), 907-919. |
| [5] | 骆方, 田雪涛, 屠焯然, 姜力铭. (2021). 教育评价新趋向:智能化测评研究综述. 现代远程教育研究, 33(5), 42-52. |
| [6] |
孙鑫, 黎坚, 符植煜. (2018). 利用游戏log-file预测学生推理能力和数学成绩——机器学习的应用. 心理学报, 50(7), 761-770.
doi: 10.3724/SP.J.1041.2018.00761 |
| [7] | 张厚粲, 骆方. (2020). 中国心理和教育测量发展. 教育测量与评估双语期刊, 1(1), Article 8. |
| [8] | 赵守盈, 石艳梅, 朱丹. (2013). 项目反应理论在大规模选拔性考试试题质量评价中的应用. 教育学报, 9(1), 71-77. |
| [9] |
Acheampong, F. A., Nunoo-Mensah, H., & Chen, W. (2021). Transformer models for text-based emotion detection: A review of BERT-based approaches. Artificial Intelligence Review, 54(8), 5789-5829.
doi: 10.1007/s10462-021-09958-2 |
| [10] | Ahn, J., Verma, R., Lou, R., Liu, D., Zhang, R., & Yin, W. (2024). Large language models for mathematical reasoning: Progresses and challenges. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics:Student Research Workshop (pp. 225-237). Association for Computational Linguistics. |
| [11] |
Alomran, M., & Chai, D. (2018). Automated scoring system for multiple choice test with quick feedback. International Journal of Information and Education Technology, 8(8), 538-545. https://doi.org/10.18178/ijiet.2018.8.8.1096
doi: 10.18178/ijiet.2018.8.8.1096 URL |
| [12] |
Antypas, D., Preece, A., & Camacho-Collados, J. (2023). Negativity spreads faster: A large-scale multilingual twitter analysis on the role of sentiment in political communication. Online Social Networks and Media, 33, 100242.
doi: 10.1016/j.osnem.2023.100242 URL |
| [13] |
Asudani, D. S., Nagwani, N. K., & Singh, P. (2023). Impact of word embedding models on text analytics in deep learning environment: A review. Artificial Intelligence Review, 56(9), 10345-10425. https://doi.org/10.1007/s10462-023-10419-1
doi: 10.1007/s10462-023-10419-1 URL |
| [14] |
Bai, H., Voelkel, J. G., Muldowney, S., Eichstaedt, J. C., & Willer, R. (2025). LLM-generated messages can persuade humans on policy issues. Nature Communications, 16(1), 6037. https://doi.org/10.1038/s41467-025-61345-5
doi: 10.1038/s41467-025-61345-5 URL |
| [15] | Bellemare-Pepin, A., Lespinasse, F., Thölke, P., Harel, Y., Mathewson, K., Olson, J. A., Bengio, J., & Jerbi, K. (2024). Divergent creativity in humans and large language models. arXiv preprint arXiv:2405.13012 |
| [16] | Bergner, Y., Droschler, S., Kortemeyer, G., Rayyan, S., Seaton, D., & Pritchard, D. E. (2012). Model-based collaborative filtering analysis of student response data: Machine-learning item response theory. In Proceedings of the 5th International Conference on Educational Data Mining. International Educational Data Mining Society. |
| [17] | Berry, R. (2008). Traditional assessment: Paper-and-pencil tests. In R. Berry (Ed.), Assessment for learning (pp. 61-80). Hong Kong University Press. |
| [18] | Bi, G., Chen, Z., Liu, Z., Wang, H., Xiao, X., Xie, Y., … Huang, M. (2025). MAGI: Multi-agent guided interview for psychiatric assessment. arXiv preprint arXiv: 2504.18260. |
| [19] |
Biswas, G., Jeong, H., Kinnebrew, J. S., Sulcer, B., & Roscoe, R. (2010). Measuring self-regulated learning skills through social interactions in a teachable agent environment. Research and Practice in Technology Enhanced Learning, 5(2), 123-152. https://doi.org/10.1142/S1793206810000839
doi: 10.58459/rptel.2010.5123-152 URL |
| [20] |
Boake, C. (2002). From the Binet-Simon to the Wechsler- Bellevue: Tracing the history of intelligence testing. Journal of Clinical and Experimental Neuropsychology, 24(3), 383-405. https://doi.org/10.1076/jcen.24.3.383.981
doi: 10.1076/jcen.24.3.383.981 URL |
| [21] |
Brady, W. J., McLoughlin, K., Doan, T. N., & Crockett, M. J. (2021). How social learning amplifies moral outrage expression in online social networks. Science Advances, 7(33), eabe5641. https://doi.org/10.1126/sciadv.abe5641
doi: 10.1126/sciadv.abe5641 URL |
| [22] | Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901. https://papers.nips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html |
| [23] | Buongiorno, S., Klinkert, L. J., Chawla, T., Zhuang, Z., & Clark, C. (2024). PANGeA: Procedural artificial narrative using generative AI for turn-based video games. arXiv preprint arXiv: 2404.19721. |
| [24] |
Chan, K. W., Ali, F., Park, J., Sham, B. K. S., Tan, E. Y. T., Chong, F. W. C., Qian, K., & Sze, G. K.(2025). Automatic item generation in various STEM subjects using large language model prompting. Computers and Education: Artificial Intelligence, 8, 100344. https://doi.org/10.1016/j.caeai.2024.100344
doi: 10.1016/j.caeai.2024.100344 URL |
| [25] | Chang, H.-F., & Li, T. (2024). A framework for collaborating a large language model tool in brainstorming for triggering creative thoughts. arXiv preprint arXiv: 2410.11877 |
| [26] | Chen, G. H., Chen, S., Liu, Z., Jiang, F., & Wang, B. (2024). Humans or LLMs as the judge? A study on judgement biases. arXiv preprint arXiv: 2402.10669 |
| [27] | Chen, L., Zaharia, M., & Zou, J. (2023). How is ChatGPT’s behavior changing over time? arXiv preprint arXiv: 2307.09009 |
| [28] |
Chen, Y. (2020). A continuous-time dynamic choice measurement model for problem-solving process data. Psychometrika, 85(4), 1052-1075. https://doi.org/10.1007/s11336-020-09734-1
doi: 10.1007/s11336-020-09734-1 URL pmid: 33346883 |
| [29] |
Chen, Y., Li, X., Liu, J., & Ying, Z. (2019). Statistical analysis of complex problem-solving process data: An event history analysis approach. Frontiers in Psychology, 10, 486.
doi: 10.3389/fpsyg.2019.00486 pmid: 30936843 |
| [30] | Chen, Z., & Zhou, Y. (2019). Research on automatic essay scoring of composition based on CNN and OR. In 2019 2nd International Conference on Artificial Intelligence and Big Data (ICAIBD) (pp.13-18). Chengdu, China. https://doi.org/10.1109/ICAIBD.2019.8837007 |
| [31] | Chiu, Y. Y., Sharma, A., Lin, I. W., & Althoff, T. (2024). A computational framework for behavioral assessment of LLM therapists. arXiv. http://arxiv.org/abs/2401.00820 |
| [32] |
Cho, S.-J., Brown-Schmidt, S., Boeck, P. D., & Shen, J. (2020). Modeling intensive polytomous time-series eye-tracking data: A dynamic tree-based item response model. Psychometrika, 85(1), 154-184. https://doi.org/10.1007/s11336-020-09694-6
doi: 10.1007/s11336-020-09694-6 URL |
| [33] |
Circi, R., Hicks, J., & Sikali, E. (2023). Automatic item generation: Foundations and machine learning-based approaches for assessments. Frontiers in Education, 8, 858273. https://doi.org/10.3389/feduc.2023.858273
doi: 10.3389/feduc.2023.858273 URL |
| [34] | Dai, S., Li, K., Luo, Z., Zhao, P., Hong, B., Zhu, A., & Liu, J. (2024). AI-based NLP section discusses the application and effect of bag-of-words models and TF-IDF in NLP tasks. Journal of Artificial Intelligence General Science, 5(1), 13-21. https://doi.org/10.60087/jaigs.v5i1.149 |
| [35] | Dai, S., Xu, C., Xu, S., Pang, L., Dong, Z., & Xu, J. (2024). Bias and unfairness in information retrieval systems: New challenges in the LLM era. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (pp.6437-6447). https://doi.org/10.1145/3637528.3671458 |
| [36] | Dao, T., Fu, D., Ermon, S., Rudra, A., & Ré, C. (2022). Flash attention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35, 16344-16359. |
| [37] |
Debnath, B., O’Brien, M., Yamaguchi, M., & Behera, A. (2022). A review of computer vision-based approaches for physical rehabilitation and assessment. Multimedia Systems, 28(1), 209-239. https://doi.org/10.1007/s00530-021-00815-4
doi: 10.1007/s00530-021-00815-4 URL |
| [38] | Deerwester, S. C., Dumais, S. T., Landauer, T. K., Furnas, G. W., & Harshman, R. A. (1990). Indexing by latent semantic analysis. Journal of the American Society for Information Science and Technology, 41, 391-407. |
| [39] |
Demszky, D., Liu, J., Hill, H. C., Jurafsky, D., & Piech, C. (2024). Can automated feedback improve teachers’ uptake of student ideas? Evidence from a randomized controlled trial in a large-scale online course. Educational Evaluation and Policy Analysis, 46(3), 483-505. https://doi.org/10.3102/01623737231169270
doi: 10.3102/01623737231169270 URL |
| [40] | Demszky, D., Yang, D., Yeager, D. S., Bryan, C. J., Clapper, M., Chandhok, S., … Johnson, M. (2023). Using large language models in psychology. Nature Reviews Psychology, 2(11), 688-701. https://doi.org/10.1038/s44159-023-00241-5 |
| [41] | DeRosier, M. E., & Thomas, J. M. (2019). Hall of heroes: A digital game for social skills training with young adolescents. International Journal of Computer Games Technology. https://doi.org/10.1155/2019/6981698 |
| [42] |
Devine, R. T., Kovatchev, V., Grumley Traynor, I., Smith, P., & Lee, M. (2023). Machine learning and deep learning systems for automated measurement of “advanced” theory of mind: Reliability and validity in children and adolescents. Psychological Assessment, 35(2), 165-177. https://doi.org/10.1037/pas0001186
doi: 10.1037/pas0001186 URL pmid: 36689387 |
| [43] |
Dipietro, L., Sabatini, A. M., & Dario, P. (2008). A survey of glove-based systems and their applications. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 38(4), 461-482.
doi: 10.1109/TSMCC.2008.923862 URL |
| [44] | Dong, T., Liu, F., Wang, X., Jiang, Y., Zhang, X., & Sun, X. (2024). EmoAda:A multimodal emotion interaction and psychological adaptation system. In S. Rudinac, A. Hanjalic, C. Liem, M. Worring, B. Þ. Jónsson, B. Liu, & Y. Yamakata (Eds.), Multimedia modeling (pp. 301-307). Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-53302-0_25 |
| [45] | Du, H., Liu, S., Zheng, L., Cao, Y., Nakamura, A., & Chen, L. (2025). Privacy in fine-tuning large language models: Attacks, defenses, and future directions. In X. Wu, M. Spiliopoulou, C. Wang, V. Kumar, L. Cao, Y. Wu, Y. Yao, & Z. Wu (Eds.), Advances in knowledge discovery and data mining (pp. 326-344). Springer Nature. https://doi.org/10.1007/978-981-96-8183-9_25 |
| [46] |
Eichstaedt, J. C., Smith, R. J., Merchant, R. M., Ungar, L. H., Crutchley, P., Preoţiuc-Pietro, D., Asch, D. A., & Schwartz, H. A. (2018). Facebook language predicts depression in medical records. Proceedings of the National Academy of Sciences, 115(44), 11203-11208. https://doi.org/10.1073/pnas.1802331115
doi: 10.1073/pnas.1802331115 URL |
| [47] |
Ersozlu, Z., Taheri, S., & Koch, I. (2024). A review of machine learning methods used for educational data. Education and Information Technologies, 29, 22125-22145. https://doi.org/10.1007/s10639-024-12704-0
doi: 10.1007/s10639-024-12704-0 URL |
| [48] | Fernandez, N., Ghosh, A., Liu, N., Wang, Z., Choffin, B., Baraniuk, R., & Lan, A. (2022). Automated scoring for reading comprehension via in-context BERT tuning. In M. M. Rodrigo, N. Matsuda, A. I. Cristea, & V. Dimitrova (Eds.), Artificial intelligence in education (Vol. 13355, pp. 691-697). Springer International Publishing. https://doi.org/10.1007/978-3-031-11644-5_69 |
| [49] |
Foltz, P. W., Chandler, C., Diaz-Asper, C., Cohen, A. S., Rodriguez, Z., Holmlund, T. B., & Elvevåg, B. (2023). Reflections on the nature of measurement in language- based automated assessments of patients’ mental state and cognitive function. Schizophrenia Research, 259, 127-139. https://doi.org/10.1016/j.schres.2022.07.011
doi: 10.1016/j.schres.2022.07.011 URL |
| [50] | Gabbay, H., & Cohen, A. (2024). Combining LLM-generated and test-based feedback in a MOOC for programming. In Proceedings of the Eleventh ACM Conference on Learning @Scale (pp.177-187). https://doi.org/10.1145/3657604.3662040 |
| [51] | Goretzko, D., & Bühner, M. (2022). Note: Machine learning modeling and optimization techniques in psychological assessment. Psychological Test and Assessment Modeling, 64(1), 3-21. |
| [52] |
Gotz, F. M., Maertens, R., Loomba, S., & van der Linden, S. (2023). Let the algorithm speak: How to use neural networks for automatic item generation in psychological scale development. Psychological Methods, 29(3), 494-518. https://doi.org/10.1037/met0000540
doi: 10.1037/met0000540 URL pmid: 36795435 |
| [53] |
Guzik, E. E., Byrge, C., & Gilde, C. (2023). The originality of machines: AI takes the Torrance test. Journal of Creativity, 33(3), 100065. https://doi.org/10.1016/j.yjoc.2023.100065
doi: 10.1016/j.yjoc.2023.100065 URL |
| [54] |
Haizel, P., Vernanda, G., Wawolangi, K. A., & Hanafiah, N. (2021). Personality assessment video game based on the five-factor model. Procedia Computer Science, 179, 566-573. https://doi.org/10.1016/j.procs.2021.01.041
doi: 10.1016/j.procs.2021.01.041 URL |
| [55] | He, J., Pan, K., Dong, X., Song, Z., Liu, Y., Sun, Q., … Zhang, J. (2024). Never lost in the middle: Mastering long-context question answering with position-agnostic decompositional training. arXiv preprint arXiv: 2311. 09198 |
| [56] |
He, Q., Borgonovi, F., & Paccagnella, M. (2021). Leveraging process data to assess adults’ problem-solving skills: Using sequence mining to identify behavioral patterns across digital tasks. Computers & Education, 166, 104170.
doi: 10.1016/j.compedu.2021.104170 URL |
| [57] | Hewitt, L., Ashokkumar, A., Ghezae, I., & Willer, R. (2024). Predicting results of social science experiments using large language models. https://www.ethicalpsychology.com/2024/11/predicting-results-of-social-science.html |
| [58] |
Hoffmann, S., Lasarov, W., & Dwivedi, Y. K. (2024). AI-empowered scale development: Testing the potential of ChatGPT. Technological Forecasting and Social Change, 205, 123488. https://doi.org/10.1016/j.techfore.2024.123488
doi: 10.1016/j.techfore.2024.123488 URL |
| [59] |
Hommel, B. E., Wollang, F.-J. M., Kotova, V., Zacher, H., & Schmukle, S. C. (2022). Transformer-based deep neural language modeling for construct-specific automatic item generation. Psychometrika, 87(2), 749-772. https://doi.org/10.1007/s11336-021-09823-9
doi: 10.1007/s11336-021-09823-9 URL |
| [60] | Hu, A. (2024). Developing an AI-based psychometric system for assessing learning difficulties and adaptive system to overcome: A qualitative and conceptual framework. arXiv preprint arXiv: 2403.06284 |
| [61] | Huang, J., & Chang, K. C.-C.(2023). Towards reasoning in large language models: A survey. arXiv preprint arXiv: 2212.10403 |
| [62] | Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., … Liu, T. (2025). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43(2), 1-55. https://doi.org/10.1145/3703155 |
| [63] | Huang, Y., Sun, L., Wang, H., Wu, S., Zhang, Q., Li, Y., … Zhao, Y. (2024). Trust LLM: Trustworthiness in large language models. arXiv preprint arXiv: 2401.05561 |
| [64] |
Huawei, S., & Aryadoust, V. (2023). A systematic review of automated writing evaluation systems. Education and Information Technologies, 28(1), 771-795. https://doi.org/10.1007/s10639-022-11200-7
doi: 10.1007/s10639-022-11200-7 URL |
| [65] |
Hubert, K. F., Awa, K. N., & Zabelina, D. L. (2024). The current state of artificial intelligence generative language models is more creative than humans on divergent thinking tasks. Scientific Reports, 14(1), 3440. https://doi.org/10.1038/s41598-024-53303-w
doi: 10.1038/s41598-024-53303-w URL |
| [66] | Jandaghi, P., Sheng, X., Bai, X., Pujara, J., & Sidahmed, H. (2024). Faithful persona-based conversational dataset generation with large language models. In E. Nouri, A. Rastogi, G. Spithourakis, B. Liu, Y.-N. Chen, Y. Li, A. Albalak, H. Wakaki, & A. Papangelis (Eds.), Proceedings of the 6th Workshop on NLP for Conversational AI (NLP4ConvAI 2024) (pp. 114-139). Association for Computational Linguistics. https://aclanthology.org/2024.nlp4convai-1.8/ |
| [67] |
Janiesch, C., Zschech, P., & Heinrich, K. (2021). Machine learning and deep learning. Electronic Markets, 31(3), 685-695. https://doi.org/10.1007/s12525-021-00475-2
doi: 10.1007/s12525-021-00475-2 URL |
| [68] |
Jatnika, D., Bijaksana, M. A., & Suryani, A. A. (2019). Word2vec model analysis for semantic similarities in English words. Procedia Computer Science, 157, 160-167.
doi: 10.1016/j.procs.2019.08.153 URL |
| [69] | Ji, Z., Yu, T., Xu, Y., Lee, N., Ishii, E., & Fung, P. (2023). Towards mitigating LLM hallucination via self reflection. In H. Bouamor, J. Pino, & K. Bali (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 1827-1843). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-emnlp.123 |
| [70] |
Jose, R., Matero, M., Sherman, G., Curtis, B., Giorgi, S., Schwartz, H. A., & Ungar, L. H. (2022). Using Facebook language to predict and describe excessive alcohol use. Alcoholism: Clinical and Experimental Research, 46(5), 836-847. https://doi.org/10.1111/acer.14807
doi: 10.1111/acer.v46.5 URL |
| [71] |
Ke, L., Tong, S., Cheng, P., & Peng, K. (2025). Exploring the frontiers of LLMs in psychological applications: A comprehensive review. Artificial Intelligence Review, 58(10), 305. https://doi.org/10.1007/s10462-025-11297-5
doi: 10.1007/s10462-025-11297-5 URL |
| [72] | Kharitonova, K., Pérez-Fernández, D., Gutiérrez-Hernando, J., Gutiérrez-Fandiño, A., Callejas, Z., & Griol, D. (2025). Incorporating evidence into mental health Q&A: A novel method to use generative language models for validated clinical content extraction. Behaviour & Information Technology, 44(10), 2333-2350. https://doi.org/10.1080/0144929X.2024.2321959 |
| [73] |
Kim, Y. J., Almond, R. G., & Shute, V. J. (2016). Applying evidence-centered design for the development of game- based assessments in physics playground. International Journal of Testing, 16(2), 142-163. https://doi.org/10.1080/15305058.2015.1108322
doi: 10.1080/15305058.2015.1108322 URL |
| [74] |
Landauer, T. K., Foltz, P. W., & Laham, D. (1998). An introduction to latent semantic analysis. Discourse Processes, 25(2-3), 259-284. https://doi.org/10.1080/01638539809545028
doi: 10.1080/01638539809545028 URL |
| [75] | Laverghetta, Jr., A., & Licato, J(2023). Generating better items for cognitive assessments using large language models. In E. Kochmar et al. (Eds.), Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023) (pp. 414-428). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.bea-1.34 |
| [76] |
Lawrence, H. R., Schneider, R. A., Rubin, S. B., Matarić, M. J., McDuff, D. J., & Bell, M. J. (2024). The opportunities and risks of large language models in mental health. JMIR Mental Health, 11(1), e59479. https://doi.org/10.2196/59479
doi: 10.2196/59479 URL |
| [77] | Lazos, L., Poovendran, R., & Capkun, S. (2005). ROPE: Robust position estimation in wireless sensor networks. IPSN 2005. Fourth International Symposium on Information Processing in Sensor Networks, 2005 (pp. 324-331). https://doi.org/10.1109/IPSN.2005.1440942 |
| [78] |
Lee, D., & Yeo, S. (2022). Developing an AI-based chatbot for practicing responsive teaching in mathematics. Computers & Education, 191, 104646. https://doi.org/10.1016/j.compedu.2022.104646
doi: 10.1016/j.compedu.2022.104646 URL |
| [79] |
Lee, G.-G., Latif, E., Wu, X., Liu, N., & Zhai, X. (2024). Applying large language models and chain-of-thought for automatic scoring. Computers and Education: Artificial Intelligence, 6, 100213.
doi: 10.1016/j.caeai.2024.100213 URL |
| [80] | Li, C.-J., Zhang, J., Tang, Y., & Li, J. (2025). Automatic item generation for personality situational judgment tests with large language models. arXiv preprint arXiv: 2412.12144 |
| [81] |
Li, H., Zhang, R., Lee, Y.-C., Kraut, R. E., & Mohr, D. C. (2023). Systematic review and meta-analysis of AI-based conversational agents for promoting mental health and well-being. NPJ Digital Medicine, 6(1), 1-14. https://doi.org/10.1038/s41746-023-00979-5
doi: 10.1038/s41746-022-00734-2 URL |
| [82] |
Liang, G., On, B.-W., Jeong, D., Kim, H.-C., & Choi, G. S. (2018). Automated essay scoring: A Siamese bidirectional LSTM neural network architecture. Symmetry, 10(12), 682. https://doi.org/10.3390/sym10120682
doi: 10.3390/sym10120682 URL |
| [83] |
Liao, M., & Jiao, H. (2023). Modelling multiple problem‐solving strategies and strategy shift in cognitive diagnosis for growth. British Journal of Mathematical and Statistical Psychology, 76(1), 20-51. https://doi.org/10.1111/bmsp.12280
doi: 10.1111/bmsp.v76.1 URL |
| [84] | Lin, V., Girard, J. M., Sayette, M. A., & Morency, L.-P. (2020). Toward multimodal modeling of emotional expressiveness. Proceedings of the 2020 International Conference on Multimodal Interaction (pp.548-557). https://doi.org/10.1145/3382507.3418887 |
| [85] | Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the middle: How language models use long contexts. arXiv preprint arXiv: 2307.03172. |
| [86] | Liu, O. L., Brew, C., Blackmore, J., Gerard, L., Madhok, J., & Linn, M. C. (2014). Automated scoring of constructed- response science items: Prospects and obstacles. Educational Measurement: Issues and Practice, 33(2), 19-28. https://doi.org/10.1111/emip.12028 |
| [87] |
Liu, Y., Bhandari, S., & Pardos, Z. A. (2025). Leveraging LLM respondents for item evaluation: A psychometric analysis. British Journal of Educational Technology, 56(3), 1028-1052. https://doi.org/10.1111/bjet.13570
doi: 10.1111/bjet.v56.3 URL |
| [88] | Lu, L.-C., Chen, S.-J., Pai, T.-M., Yu, C.-H., Lee, H., & Sun, S.-H. (2024). LLM discussion: Enhancing the creativity of large language models via discussion framework and role-play. arXiv preprint arXiv: 2405.06373 |
| [89] | Lu, X., & Wang, X. (2024). Generative students: Using LLM-simulated student profiles to support question item evaluation. In Proceedings of the Eleventh ACM Conference on Learning @Scale (pp.16-27). https://doi.org/10.1145/3657604.3662031 |
| [90] |
Ludwig, S., Mayer, C., Hansen, C., Eilers, K., & Brandt, S. (2021). Automated essay scoring using transformer models. Psych, 3(4), 897-915. https://doi.org/10.3390/psych3040056
doi: 10.3390/psych3040056 URL |
| [91] | Ma, L., & Zhang, Y. (2015). Using Word2Vec to process big text data. 2015 IEEE International Conference on Big Data (Big Data) (pp. 2895-2897). https://ieeexplore.ieee.org/abstract/document/7364114/ |
| [92] |
Ma, W., & Guo, W. (2019). Cognitive diagnosis models for multiple strategies. British Journal of Mathematical and Statistical Psychology, 72(2), 370-392. https://doi.org/10.1111/bmsp.12155
doi: 10.1111/bmsp.12155 URL |
| [93] | Ma, W., Yang, C., & Kästner, C. (2024). (why) is my prompt getting worse? Rethinking regression testing for evolving LLM APIs. Proceedings of the IEEE/ACM 3rd International Conference on AI Engineering - Software Engineering for AI (pp.166-171). https://doi.org/10.1145/3644815.3644950 |
| [94] | Majumder, N., Poria, S., Gelbukh, A., & Cambria, E. (2017). Deep learning-based document modeling for personality detection from text. IEEE Intelligent Systems, 32(2), 74-79. |
| [95] |
Man, K., Harring, J. R., & Zhan, P. (2022). Bridging models of biometric and psychometric assessment: A three-way joint modeling approach of item responses, response times, and gaze fixation counts. Applied Psychological Measurement, 46(5), 361-381. https://doi.org/10.1177/01466216221089344
doi: 10.1177/01466216221089344 URL pmid: 35812811 |
| [96] | Martínez-Plumed, F., Prudêncio, R. B. C., Martínez-Usó, A., & Hernández-Orallo, J. (2016). Making sense of item response theory in machine learning. In ECAI’16:Proceedings of the Twenty-second European Conference on Artificial Intelligence (pp. 1140-1148). https://doi.org/10.3233/978-1-61499-672-9-1140 |
| [97] |
Matarazzo, J. D. (1992). Psychological testing and assessment in the 21st century. American Psychologist, 47(8), 1007-1018. https://doi.org/10.1037//0003-066X.47.8.1007
URL pmid: 1510328 |
| [98] |
Mavridis, A., & Tsiatsos, T. (2017). Game-based assessment: Investigating the impact on test anxiety and exam performance. Journal of Computer Assisted Learning, 33(2), 137-150. https://doi.org/10.1111/jcal.12170
doi: 10.1111/jcal.v33.2 URL |
| [99] |
McKenna, P. (2019). Multiple choice questions: Answering correctly and knowing the answer. Interactive Technology and Smart Education, 16(1), 59-73.
doi: 10.1108/ITSE-09-2018-0071 URL |
| [100] |
McDaniel, M. A., Hartman, N. S., Whetzel, D. L., & Grubb Iii, W. L. (2007). Situational judgment tests, response instructions, and validity: A meta-analysis. Personnel Psychology, 60(1), 63-91. https://doi.org/10.1111/j.1744-6570.2007.00065.x
doi: 10.1111/peps.2007.60.issue-1 URL |
| [101] | Mehrotra, P., Parab, A., & Gulwani, S. (2024). Enhancing creativity in large language models through associative thinking strategies. arXiv preprint arXiv: 2405.06715 |
| [102] |
Memon, J., Sami, M., Khan, R. A., & Uddin, M. (2020). Handwritten optical character recognition (OCR): A comprehensive systematic literature review (SLR). IEEE Access, 8, 142642-142668. https://doi.org/10.1109/ACCESS.2020.3012542
doi: 10.1109/ACCESS.2020.3012542 URL |
| [103] |
Meyer, J., Jansen, T., Schiller, R., Liebenow, L. W., Steinbach, M., Horbach, A., & Fleckenstein, J. (2024). Using LLMs to bring evidence-based feedback into the classroom: AI-generated feedback increases secondary students’ text revision, motivation, and positive emotions. Computers and Education: Artificial Intelligence, 6, 100199. https://doi.org/10.1016/j.caeai.2023.100199
doi: 10.1016/j.caeai.2023.100199 URL |
| [104] | Obrenovic, Z., & Starcevic, D. (2004). Modeling multimodal human-computer interaction. Computer, 37(9), 65-72. https://doi.org/10.1109/MC.2004.139 |
| [105] | OECD. (2013). PISA 2012 assessment and analytical framework: Mathematics, reading, science, problem solving and financial literacy. Organisation for Economic Co-operation and Development. https://www.oecd-ilibrary.org/education/pisa-2012-assessment-and-analytical-framework_9789264190511-en |
| [106] | OECD. (2017). PISA 2015 assessment and analytical framework: Science, reading, mathematic, financial literacy and collaborative problem solving. Organisation for Economic Co-operation and Development. https://www.oecd-ilibrary.org/education/pisa-2015-assessment-and-analytical-framework_9789264281820-en |
| [107] | Ouédraogo, W. C., Kaboré, K., Tian, H., Song, Y., Koyuncu, A., Klein, J., Lo, D., & Bissyandé, T. F. (2024). Large- scale, independent and comprehensive study of the power of LLMs for test case generation. arXiv preprint arXiv: 2407.00225 |
| [108] |
Palanivinayagam, A., El-Bayeh, C. Z., & Damaševičius, R. (2023). Twenty years of machine-learning-based text classification: A systematic review. Algorithms, 16(5), 236. https://doi.org/10.3390/a16050236
doi: 10.3390/a16050236 URL |
| [109] |
Palumbo, I. M., Perkins, E. R., Yancey, J. R., Brislin, S. J., Patrick, C. J., & Latzman, R. D. (2020). Toward a multimodal measurement model for the neurobehavioral trait of affiliative capacity. Personality Neuroscience, 3, e11. https://doi.org/10.1017/pen.2020.9
doi: 10.1017/pen.2020.9 URL |
| [110] | Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv: 2304.03442 |
| [111] | Pellert, M., Lechner, C. M., Wagner, C., Rammstedt, B., & Strohmaier, M. (2024). AI psychometrics: Assessing the psychological profiles of large language models through psychometric inventories. Perspectives on Psychological Science, 19, 5. https://doi.org/10.1177/17456916231214460 |
| [112] | Pennington, J., Socher, R., & Manning, C. D. (2014). Glove:Global vectors for word representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 1532-1543). https://aclanthology.org/D14-1162.pdf |
| [113] | Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. arXiv. http://arxiv.org/abs/1802.05365 |
| [114] |
Pliakos, K., Joo, S.-H., Park, J. Y., Cornillie, F., Vens, C., & Van den Noortgate, W. (2019). Integrating machine learning into item response theory for addressing the cold start problem in adaptive learning systems. Computers & Education, 137, 91-103.
doi: 10.1016/j.compedu.2019.04.009 URL |
| [115] | Press, O., Smith, N. A., & Lewis, M. (2022). Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv: 2108.12409 |
| [116] | Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generativepre-training. OpenAI Technical Report. |
| [117] | Rahman, M. A., Al Faisal, A., Khanam, T., Amjad, M., & Siddik, M. S. (2019). Personality detection from text using convolutional neural network. 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT) (pp. 1-6). https://ieeexplore.ieee.org/abstract/document/8934548/ |
| [118] |
Ramnarain-Seetohul, V., Bassoo, V., & Rosunally, Y. (2022). Similarity measures in automated essay scoring systems: A ten-year review. Education and Information Technologies, 27(4), 5573-5604. https://doi.org/10.1007/s10639-021-10838-z
doi: 10.1007/s10639-021-10838-z URL |
| [119] | Rao, A., Yerukola, A., Shah, V., Reinecke, K., & Sap, M. (2025). NormAd: A framework for measuring the cultural adaptability of large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1:Long Papers) (pp. 2373-2403). Albuquerque, New Mexico. Association for Computational Linguistics. https://doi.org/10.18653/v1/2025.naacl-long.120 |
| [120] |
Rathje, S., Mirea, D.-M., Sucholutsky, I., Marjieh, R., Robertson, C. E., & Van Bavel, J. J. (2024). GPT is an effective tool for multilingual psychological text analysis. Proceedings of the National Academy of Sciences, 121(34), e2308950121. https://doi.org/10.1073/pnas.2308950121
doi: 10.1073/pnas.2308950121 URL |
| [121] | Rawte, V., Priya, P., Tonmoy, S. M. T. I., Zaman, S. M. M., Sheth, A., & Das, A. (2023). Exploring the relationship between LLM hallucinations and prompt linguistic nuances: Readability, formality, and concreteness. arXiv preprint arXiv: 2309.11064 |
| [122] | Ren, Z., Shen, Q., Diao, X., & Xu, H. (2021). A sentiment- aware deep learning approach for personality detection from text. Information Processing & Management, 58(3), 102532. |
| [123] | Roy, S., Nakshatri, N. S., & Goldwasser, D. (2022). Towards few-shot identification of morality frames using in-context learning. In D. Bamman, D. Hovy, D. Jurgens, K. Keith, B. O’Connor, & S. Volkova (Eds.), Proceedings of the Fifth Workshop on Natural Language Processing and Computational Social Science (NLP+CSS) (pp. 183-196). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.nlpcss-1.20 |
| [124] | Sakai, S., An, J., Kang, M., & Kwak, H. (2025). Somatic in the east, psychological in the west?: Investigating clinically-grounded cross-cultural depression symptom expression in LLMs. arXiv preprint arXiv: 2508.03247 |
| [125] |
Schulte-Mecklenbeck, M., Kühberger, A., & Ranyard, R. (2011). The role of process data in the development and testing of process models of judgment and decision making. Judgment and Decision Making, 6(8), 733-739. https://doi.org/10.1017/S1930297500004162
doi: 10.1017/S1930297500004162 URL |
| [126] |
Shaik, T., Tao, X., Li, Y., Dann, C., McDonald, J., Redmond, P., & Galligan, L. (2022). A review of the trends and challenges in adopting natural language processing methods for education feedback analysis. IEEE Access, 10, 56720-56739. https://doi.org/10.1109/ACCESS.2022.3177752
doi: 10.1109/ACCESS.2022.3177752 URL |
| [127] |
Sharma, A., Lin, I. W., Miner, A. S., Atkins, D. C., & Althoff, T. (2023). Human-AI collaboration enables more empathic conversations in text-based peer-to-peer mental health support. Nature Machine Intelligence, 5(1), 46-57. https://doi.org/10.1038/s42256-022-00593-2
doi: 10.1038/s42256-022-00593-2 URL |
| [128] |
Sharma, K., & Giannakos, M. (2020). Multimodal data capabilities for learning: What can multimodal data tell us about learning? British Journal of Educational Technology, 51(5), 1450-1484. https://doi.org/10.1111/bjet.12993
doi: 10.1111/bjet.v51.5 URL |
| [129] |
Silva, N., Zhang, D., Kulvicius, T., Gail, A., Barreiros, C., Lindstaedt, S., … Marschik, P. B. (2021). The future of general movement assessment: The role of computer vision and machine learning-A scoping review. Research in Developmental Disabilities, 110, 103854. https://doi.org/10.1016/j.ridd.2021.103854
doi: 10.1016/j.ridd.2021.103854 URL |
| [130] |
Sonabend, W. A., Pellegrini, A. M., Chan, S., Brown, H. E., Rosenquist, J. N., Vuijk, P. J., … Cai, T. (2020). Integrating questionnaire measures for transdiagnostic psychiatric phenotyping using word2vec. PLOS One, 15(4), e0230663. https://doi.org/10.1371/journal.pone.0230663
doi: 10.1371/journal.pone.0230663 URL |
| [131] |
Stade, E. C., Stirman, S. W., Ungar, L. H., Boland, C. L., Schwartz, H. A., Yaden, D. B., … Eichstaedt, J. C. (2024). Large language models could change the future of behavioral healthcare: A proposal for responsible development and evaluation. NPJ Mental Health Research, 3(1), 1-12. https://doi.org/10.1038/s44184-024-00056-z
doi: 10.1038/s44184-023-00041-y URL |
| [132] |
Stadler, M., Herborn, K., Mustafić, M., & Greiff, S. (2020). The assessment of collaborative problem solving in PISA 2015: An investigation of the validity of the PISA 2015 CPS tasks. Computers & Education, 157, 103964. https://doi.org/10.1016/j.compedu.2020.103964
doi: 10.1016/j.compedu.2020.103964 URL |
| [133] | Stamper, J., Xiao, R., & Hou, X. (2024). Enhancing LLM-based feedback:Insights from intelligent tutoring systems and the learning sciences. In A. M. Olney, I.-A. Chounta, Z. Liu, O. C. Santos, & I. I. Bittencourt (Eds.), Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium and Blue Sky (Vol. 2150, pp. 32-43). Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-64315-6_3 |
| [134] | Takano, S., & Ichikawa, O. (2022). Automatic scoring of short answers using justification cues estimated by BERT. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2022) (pp. 8-13). https://aclanthology.org/2022.bea-1.2/ |
| [135] | Taubenfeld, A., Dover, Y., Reichart, R., & Goldstein, A. (2024). Systematic biases in LLM simulations of debates. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp.251-267). https://doi.org/10.18653/v1/2024.emnlp-main.16 |
| [136] |
Tong, S., Mao, K., Huang, Z., Zhao, Y., & Peng, K. (2024). Automating psychological hypothesis generation with AI: When large language models meet causal graph. Humanities and Social Sciences Communications, 11(1), 1-14. https://doi.org/10.1057/s41599-024-03407-5
doi: 10.1057/s41599-023-02237-1 URL |
| [137] |
Uymaz, H. A., & Metin, S. K. (2022). Vector based sentiment and emotion analysis from text: A survey. Engineering Applications of Artificial Intelligence, 113, 104922.
doi: 10.1016/j.engappai.2022.104922 URL |
| [138] |
van Velthoven, M. H., Wang, W., Wu, Q., Li, Y., Scherpbier, R. W., Du, X., … Rudan, I. (2018). Comparison of text messaging data collection vs face-to-face interviews for public health surveys: A cluster randomized crossover study of care-seeking for childhood pneumonia and diarrhoea in rural China. Journal of Global HEALTH, 8(1), 010802. https://doi.org/10.7189/jogh.08.010802
doi: 10.7189/jogh.08.010802 URL |
| [139] | Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Neural Information Processing Systems. |
| [140] |
Vosoughi, S., Roy, D., & Aral, S. (2018). The spread of true and false news online. Science, 359(6380), 1146-1151. https://doi.org/10.1126/science.aap9559
doi: 10.1126/science.aap9559 URL pmid: 29590045 |
| [141] | Wang, C., Luo, W., Dong, S., Xuan, X., Li, Z., Ma, L., & Gao, S. (2025). MLLM-tool: A multimodal large language model for tool agent learning. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (pp. 6678-6687). https://doi.org/10.1109/WACV61041.2025.00650 |
| [142] |
Wang, F., Liu, Q., Chen, E., Huang, Z., Yin, Y., Wang, S., & Su, Y. (2023). NeuralCD: A general framework for cognitive diagnosis. IEEE Transactions on Knowledge and Data Engineering, 35(8), 8312-8327. https://doi.org/10.1109/TKDE.2022.3201037
doi: 10.1109/TKDE.2022.3201037 URL |
| [143] | Wang, P., Li, L., Chen, L., Cai, Z., Zhu, D., Lin, B., … Sui, Z. (2023). Large language models are not fair evaluators. arXiv preprint arXiv: 2305.17926 |
| [144] |
Wang, Q. (2022). The use of semantic similarity tools in automated content scoring of fact-based essays written by EFL learners. Education and Information Technologies, 27(9), 13021-13049. https://doi.org/10.1007/s10639-022-11179-1
doi: 10.1007/s10639-022-11179-1 URL |
| [145] | Wang, Y., Chen, W., Han, X., Lin, X., Zhao, H., Liu, Y., … Yang, H. (2024). Exploring the reasoning abilities of multimodal large language models (MLLMs): A comprehensive survey on emerging trends in multimodal reasoning. arXiv preprint arXiv: 2401.06805 |
| [146] | Wei, J., Yao, Y., Ton, J.-F., Guo, H., Estornell, A., & Liu, Y. (2024). Measuring and reducing LLM hallucination without gold-standard answers. arXiv preprint arXiv: 2402.10412 |
| [147] |
Whetzel, D. L., & McDaniel, M. A. (2009). Situational judgment tests: An overview of current research. Human Resource Management Review, 19(3), 188-202. https://doi.org/10.1016/j.hrmr.2009.03.007
doi: 10.1016/j.hrmr.2009.03.007 URL |
| [148] | Wu, Z., Gong, Z., Ai, L., Shi, P., Donbekci, K., & Hirschberg, J. (2024). Beyond silent letters: Amplifying LLMs in emotion recognition with vocal nuances. arXiv preprint arXiv: 2407.21315 |
| [149] | Xiao, M., Xie, Q., Kuang, Z., Liu, Z., Yang, K., Peng, M., Han, W., & Huang, J. (2024). HealMe: Harnessing cognitive reframing in large language models for psychotherapy. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers) (pp. 1707-1725). https://doi.org/10.18653/v1/2024.acl-long.93 |
| [150] | Xu, X., Yao, B., Dong, Y., Gabriel, S., Yu, H., Hendler, J., … Wang, D. (2024). Mental-LLM: Leveraging large language models for mental health prediction via online text data. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 8(1), 1-32. https://doi.org/10.1145/3643540 |
| [151] | Xu, Y., Chen, H., Yu, J., Huang, Q., Wu, Z., Zhang, S., … Gu, R. (2023). SECap: Speech emotion captioning with large language model. arXiv preprint arXiv: 2312.10381 |
| [152] | Yancey, K. P., Laflair, G., Verardi, A., & Burstein, J. (2023). Rating short l2 essays on the CEFR scale with GPT-4. In Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023) (pp. 576-584). Toronto, Canada. Association for Computational Linguistics. https://aclanthology.org/2023.bea-1.49/ |
| [153] | Yang, Q., Wang, Z., Chen, H., Wang, S., Pu, Y., Gao, X., … Huang, G. (2024). LLM agents for psychology: A study on gamified assessments. arXiv preprint arXiv: 2402.12326 |
| [154] | Yang, T., Shi, T., Wan, F., Quan, X., Wang, Q., Wu, B., & Wu, J. (2023). PsyCoT:Psychological questionnaire as powerful chain-of-thought for personality detection. In H. Bouamor, J. Pino, & K. Bali (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2023 (pp.3305-3320). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-emnlp.216 |
| [155] |
Zhang, T., Koutsoumpis, A., Oostrom, J. K., Holtrop, D., Ghassemi, S., & de Vries, R. E. (2024). Can large language models assess personality from asynchronous video interviews? A comprehensive evaluation of validity, reliability, fairness, and rating patterns. IEEE Transactions on Affective Computing, 15(3), 1769-1785. https://ieeexplore.ieee.org/abstract/document/10463124/
doi: 10.1109/TAFFC.2024.3374875 URL |
| [156] |
Zhang, Y., Jin, R., & Zhou, Z.-H. (2010). Understanding bag-of-words model: A statistical framework. International Journal of Machine Learning and Cybernetics, 1(1-4), 43-52. https://doi.org/10.1007/s13042-010-0001-0
doi: 10.1007/s13042-010-0001-0 URL |
| [157] | Zhao, Y., Yan, L., Sun, W., Xing, G., Wang, S., Meng, C., … Yin, D. (2024a). Improving the robustness of large language models via consistency alignment. arXiv preprint arXiv: 2403.14221 |
| [158] | Zhao, Y., Zhang, R., Li, W., Huang, D., Guo, J., Peng, S., … Chen, Y. (2024b). Assessing and understanding creativity in large language models. arXiv preprint arXiv: 2401. 12491 |
| [159] | Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., … Stoica, I. (2023). Judging LLM-as-a-judge with MT-bench and chatbot arena. arXiv preprint arXiv: 2306.05685 |
| [160] |
Zhu, X., Wu, H., & Zhang, L. (2022). Automatic short- answer grading via BERT-based deep neural networks. IEEE Transactions on Learning Technologies, 15(3), 364-375.
doi: 10.1109/TLT.2022.3175537 URL |
| [1] | 宋一晓, 曾铭灼, 苏涛. 机会抑或威胁? 人与AI协作系统对员工工作效能影响的元分析[J]. 心理科学进展, 2026, 34(3): 461-486. |
| [2] | 武靖宇, 金鑫. 算法介导下的情感趋同:生成式人工智能情感传染机制[J]. 心理科学进展, 2026, 34(1): 123-133. |
| [3] | 李研, 陈维, 武瑞娟. AI技术背景下虚拟影响者营销效应及其作用机制[J]. 心理科学进展, 2025, 33(8): 1425-1442. |
| [4] | 宗树伟, 杨付, 龙立荣, 韩翼. 促进还是抑制?生成式人工智能建议采纳对创造力的双刃剑效应[J]. 心理科学进展, 2025, 33(6): 905-915. |
| [5] | 解煜彬, 周荣刚. 新型人机关系下的人机双向信任[J]. 心理科学进展, 2025, 33(6): 916-932. |
| [6] | 谭美丽, 殷向洲, 张光磊, 熊普臻. 工作场所人工智能角色划分:对员工心理与行为的影响及应对策略[J]. 心理科学进展, 2025, 33(6): 933-947. |
| [7] | 项典典, 尹雨乐, 葛梦琦, 王子涵. 自建IP还是合作IP:虚拟影响者代言人选择策略对消费者融入的影响[J]. 心理科学进展, 2025, 33(6): 965-983. |
| [8] | 罗莉娟, 王康, 胡金淼, 徐四华. 当人工智能面对人类情感:服务机器人情感表达对用户体验的影响机制[J]. 心理科学进展, 2025, 33(6): 1006-1026. |
| [9] | 彭晨明, 屈奕帆, 郭晓凌, 陈增祥. 人工智能服务对消费者道德行为的双刃剑效应[J]. 心理科学进展, 2025, 33(2): 236-255. |
| [10] | 杜传晨, 郑远霞, 郭倩倩, 刘国雄. 大语言模型的人工心理理论: 证据、界定与挑战[J]. 心理科学进展, 2025, 33(12): 2027-2042. |
| [11] | 孙芳, 李绍龙, 龙立荣, 雷宣, 曾祥麟, 黄夏虹. 人工智能反馈寻求行为的驱动机制及其影响效应[J]. 心理科学进展, 2025, 33(10): 1647-1662. |
| [12] | 徐敏亚, 陈丽萍, 刘贝妮. 人工智能对知识型员工的影响及作用机制——基于工具性和人本性视角[J]. 心理科学进展, 2025, 33(10): 1663-1683. |
| [13] | 郑宇, 谌怡, 吴月燕. 生成式人工智能队友如何影响团队新产品创意生成?基于团队过程的视角[J]. 心理科学进展, 2025, 33(10): 1684-1697. |
| [14] | 翁智刚, 陈潇潇, 张小妹, 张琚. 面向新型人机关系的社会临场感[J]. 心理科学进展, 2025, 33(1): 146-162. |
| [15] | 吴波, 张傲杰, 曹菲. 专业设计、用户设计还是AI设计?设计源效应的心理机制[J]. 心理科学进展, 2024, 32(6): 995-1009. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||