ISSN 0439-755X
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
心理学报 ›› 2025, Vol. 57 ›› Issue (11): 1988-2000.doi: 10.3724/SP.J.1041.2025.1988 cstr: 32110.14.2025.1988
周子森1, 黄琪1, 谭泽宏2, 刘睿3, 曹子亨4, 母芳蔓5, 樊亚春2( ), 秦绍正1()
), 秦绍正1()
收稿日期:2024-06-23
发布日期:2025-09-24
出版日期:2025-11-25
通讯作者:
樊亚春, E-mail: fanyachun@bnu.edu.cn;基金资助:
ZHOU Zisen1, HUANG Qi1, TAN Zehong2, LIU Rui3, CAO Ziheng4, MU Fangman5, FAN Yachun2(), QIN Shaozheng1()
Received:2024-06-23
Online:2025-09-24
Published:2025-11-25
摘要:
多模态大语言模型(MLLMs)能够处理并整合图像、文本等多模态数据信息, 为理解人类心理与认知行为提供了强有力工具。结合经典的情绪心理学范式, 本研究通过比较两种主流MLLMs与人类被试在动态社会互动情景下情绪识别与情绪推理的表现, 分离出人物对话视觉特征(图像)和对话内容(文本)在识别与推理相关人物情绪中的不同作用。结果表明, 基于人物对话图像和对话内容的MLLMs已经初步展现出和人类被试类似的情绪识别与情绪推理能力。之后进一步比较仅基于人物对话图像、仅基于对话内容以及基于两者结合共三种条件下MLLMs的情绪识别与情绪推理表现, 发现人物对话视觉特征一定程度上制约MLLMs基本情绪识别的表现, 但能够有效促进复合情绪识别, 对情绪推理则未产生显著影响。通过对比两种主流MLLMs及其不同版本(GPT-4-vision/turbo vs. Claude-3-haiku)的表现, 发现相较于单纯扩大训练数据规模, 技术原理框架的创新对提升MLLMs在社会互动中情绪识别与推理能力更为重要。本研究结果对理解社会互动中情绪识别与推理的心理学机制、启发类人的情感计算与智能算法具有重要科学价值和意义。
中图分类号:
周子森, 黄琪, 谭泽宏, 刘睿, 曹子亨, 母芳蔓, 樊亚春, 秦绍正. (2025). 多模态大语言模型动态社会互动情景下的情感能力测评. 心理学报, 57(11), 1988-2000.
ZHOU Zisen, HUANG Qi, TAN Zehong, LIU Rui, CAO Ziheng, MU Fangman, FAN Yachun, QIN Shaozheng. (2025). Emotional capabilities evaluation of multimodal large language model in dynamic social interaction scenarios. Acta Psychologica Sinica, 57(11), 1988-2000.
| 类型 | 电影名 | 双人对话场景 | ||
|---|---|---|---|---|
| 时长 | 轮数 | 说话次数 | ||
| 喜剧 | 国产凌凌漆 | 48秒 | 5 | 10 |
| 甲方乙方 | 59秒 | 3 | 6 | |
| 泰囧 | 1分18秒 | 13 | 27 | |
| 夏洛特烦恼 | 1分12秒 | 3 | 6 | |
| 爱情 | 北京遇上西雅图 | 1分45秒 | 7 | 15 |
| 非诚勿扰 | 1分12秒 | 4 | 9 | |
| 山楂树之恋 | 1分19秒 | 3 | 7 | |
| 失恋33天 | 1分57秒 | 4 | 8 | |
| 悬疑 | 催眠大师 | 1分44秒 | 4 | 10 |
| 风声 | 46秒 | 4 | 9 | |
| 神探 | 30秒 | 4 | 8 | |
| 剧情 | 芳华 | 44秒 | 4 | 9 |
| 让子弹飞 | 1分4秒 | 5 | 10 | |
| 我不是药神 | 38秒 | 3 | 7 | |
| 无间道 | 1分5秒 | 3 | 8 | |
表1 双人对话片段信息表
| 类型 | 电影名 | 双人对话场景 | ||
|---|---|---|---|---|
| 时长 | 轮数 | 说话次数 | ||
| 喜剧 | 国产凌凌漆 | 48秒 | 5 | 10 |
| 甲方乙方 | 59秒 | 3 | 6 | |
| 泰囧 | 1分18秒 | 13 | 27 | |
| 夏洛特烦恼 | 1分12秒 | 3 | 6 | |
| 爱情 | 北京遇上西雅图 | 1分45秒 | 7 | 15 |
| 非诚勿扰 | 1分12秒 | 4 | 9 | |
| 山楂树之恋 | 1分19秒 | 3 | 7 | |
| 失恋33天 | 1分57秒 | 4 | 8 | |
| 悬疑 | 催眠大师 | 1分44秒 | 4 | 10 |
| 风声 | 46秒 | 4 | 9 | |
| 神探 | 30秒 | 4 | 8 | |
| 剧情 | 芳华 | 44秒 | 4 | 9 |
| 让子弹飞 | 1分4秒 | 5 | 10 | |
| 我不是药神 | 38秒 | 3 | 7 | |
| 无间道 | 1分5秒 | 3 | 8 | |
| 类型 | 电影名 | 双人对话场景 | ||
|---|---|---|---|---|
| 地点 | 人物代码 | 人物关系 | ||
| 喜剧 | 国产凌凌漆 | 餐厅 | A:凌凌漆 B:李香琴 | B和A表面合作, 背负刺杀A的任务 |
| 甲方乙方 | 轿车上 | D:钱康 K:尤老板 | K想吃苦, D让K在乡下吃苦两个月 | |
| 泰囧 | 飞机上 | A:徐朗 F:王宝 | A和F是陌生人 | |
| 夏洛特烦恼 | 学校停车棚 | A:夏洛 D:秋雅 | A和D是同学, A在追求D | |
| 爱情 | 北京遇上西雅图 | B的家里 | A:文佳佳 B:Frank/郝志 | B是西雅图月子中心的司机, A是从中国飞过去的待产妈妈 |
| 非诚勿扰 | B打给A的电话 | A:秦奋 B:梁笑笑 | A和B相过一次亲 | |
| 山楂树之恋 | B和M的家里 | B:静秋 M:静秋母亲 | M是B的妈妈 | |
| 失恋33天 | 餐厅门口 | F:陆然 I:黄小仙 | F是I的前男友 | |
| 悬疑 | 催眠大师 | A的心理咨询工作室 | A:徐瑞宁 B:任小妍 | A是B的心理咨询师 |
| 风声 | A和B的临时住处 | A:顾晓梦 B:李宁玉 | A和B都在伪军司令部工作, 被上级怀疑是中共间谍“老鬼” | |
| 神探 | 警车里 | C:高志伟 E:王国柱 | C和E是警察同事 | |
| 剧情 | 芳华 | A的寝室 | A:刘峰 B:何小萍 | A是文工团的男兵, B是文工团的女兵 |
| 让子弹飞 | 县长办公室 | A:张牧之 B:马邦德 | A是县长, B是师爷 | |
| 我不是药神 | 办公室 | A:程勇 J:曹玲 | J是A的前妻 | |
| 无间道 | E的心理咨询工作室 | B:陈永仁 E:李心儿 | E是B的心理咨询师 | |
表2 双人对话场景信息表
| 类型 | 电影名 | 双人对话场景 | ||
|---|---|---|---|---|
| 地点 | 人物代码 | 人物关系 | ||
| 喜剧 | 国产凌凌漆 | 餐厅 | A:凌凌漆 B:李香琴 | B和A表面合作, 背负刺杀A的任务 |
| 甲方乙方 | 轿车上 | D:钱康 K:尤老板 | K想吃苦, D让K在乡下吃苦两个月 | |
| 泰囧 | 飞机上 | A:徐朗 F:王宝 | A和F是陌生人 | |
| 夏洛特烦恼 | 学校停车棚 | A:夏洛 D:秋雅 | A和D是同学, A在追求D | |
| 爱情 | 北京遇上西雅图 | B的家里 | A:文佳佳 B:Frank/郝志 | B是西雅图月子中心的司机, A是从中国飞过去的待产妈妈 |
| 非诚勿扰 | B打给A的电话 | A:秦奋 B:梁笑笑 | A和B相过一次亲 | |
| 山楂树之恋 | B和M的家里 | B:静秋 M:静秋母亲 | M是B的妈妈 | |
| 失恋33天 | 餐厅门口 | F:陆然 I:黄小仙 | F是I的前男友 | |
| 悬疑 | 催眠大师 | A的心理咨询工作室 | A:徐瑞宁 B:任小妍 | A是B的心理咨询师 |
| 风声 | A和B的临时住处 | A:顾晓梦 B:李宁玉 | A和B都在伪军司令部工作, 被上级怀疑是中共间谍“老鬼” | |
| 神探 | 警车里 | C:高志伟 E:王国柱 | C和E是警察同事 | |
| 剧情 | 芳华 | A的寝室 | A:刘峰 B:何小萍 | A是文工团的男兵, B是文工团的女兵 |
| 让子弹飞 | 县长办公室 | A:张牧之 B:马邦德 | A是县长, B是师爷 | |
| 我不是药神 | 办公室 | A:程勇 J:曹玲 | J是A的前妻 | |
| 无间道 | E的心理咨询工作室 | B:陈永仁 E:李心儿 | E是B的心理咨询师 | |

图1 情感能力表现测评设计及其说明 注:彩图见电子版, 下同
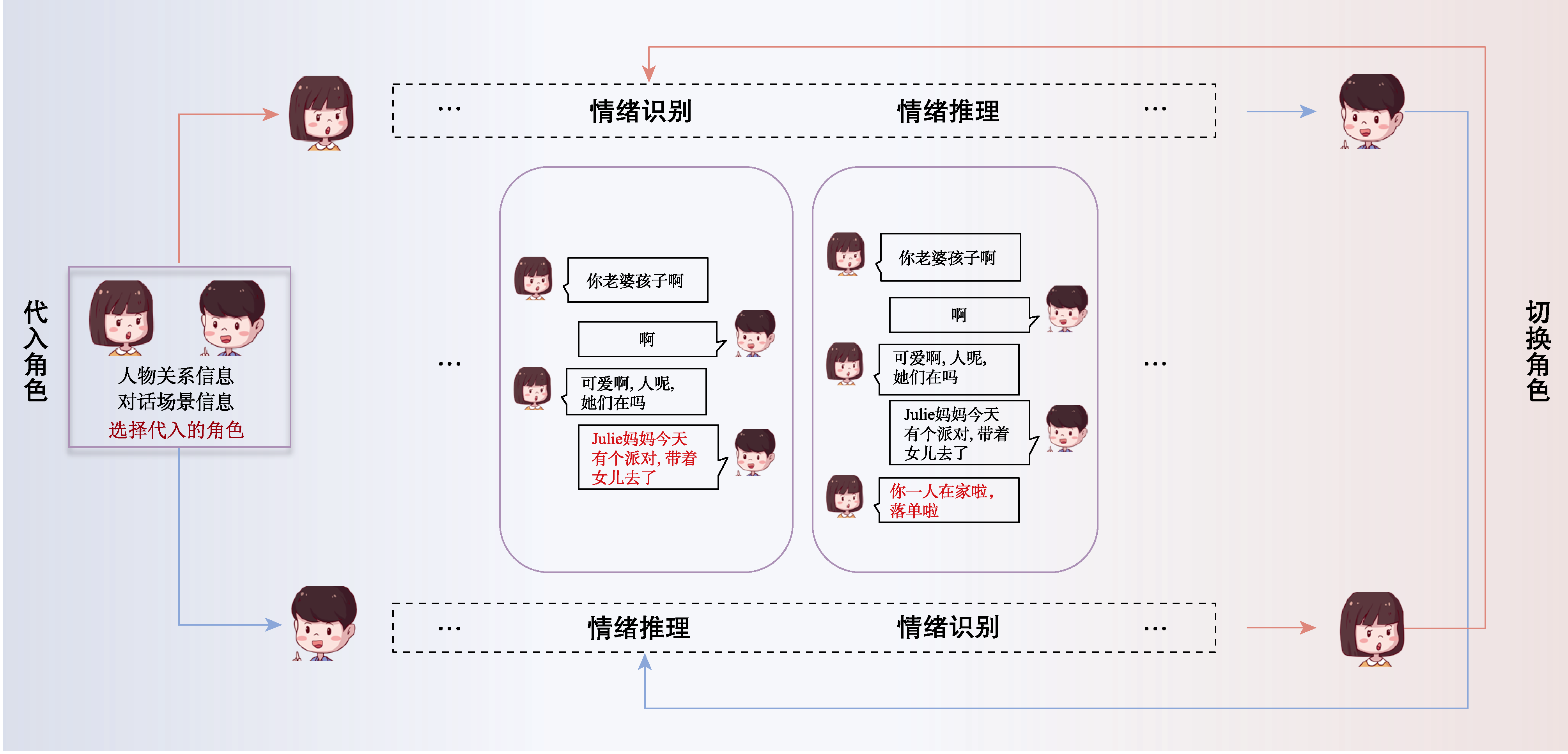
图2 人类被试测评流程图示例

图3 人类被试情绪识别的情绪标签−双人对话场景概率分布矩阵和情绪标签概率分布均值
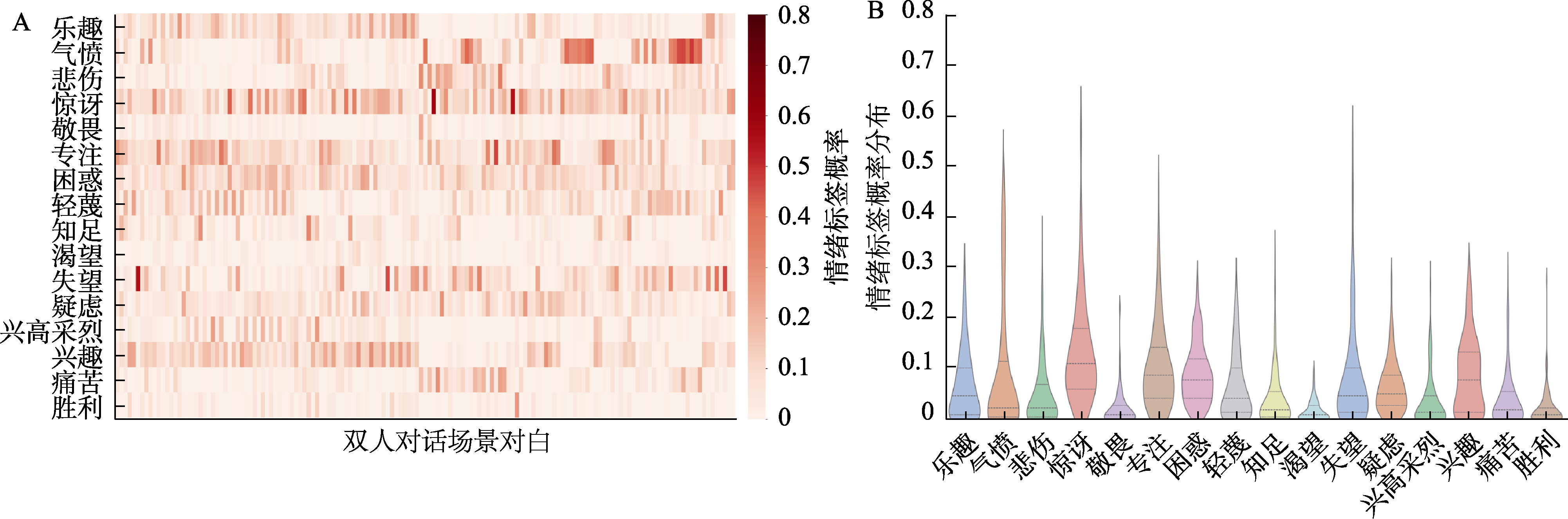
图4 人类被试情绪推理的情绪标签−双人对话场景概率分布矩阵和情绪标签概率分布均值
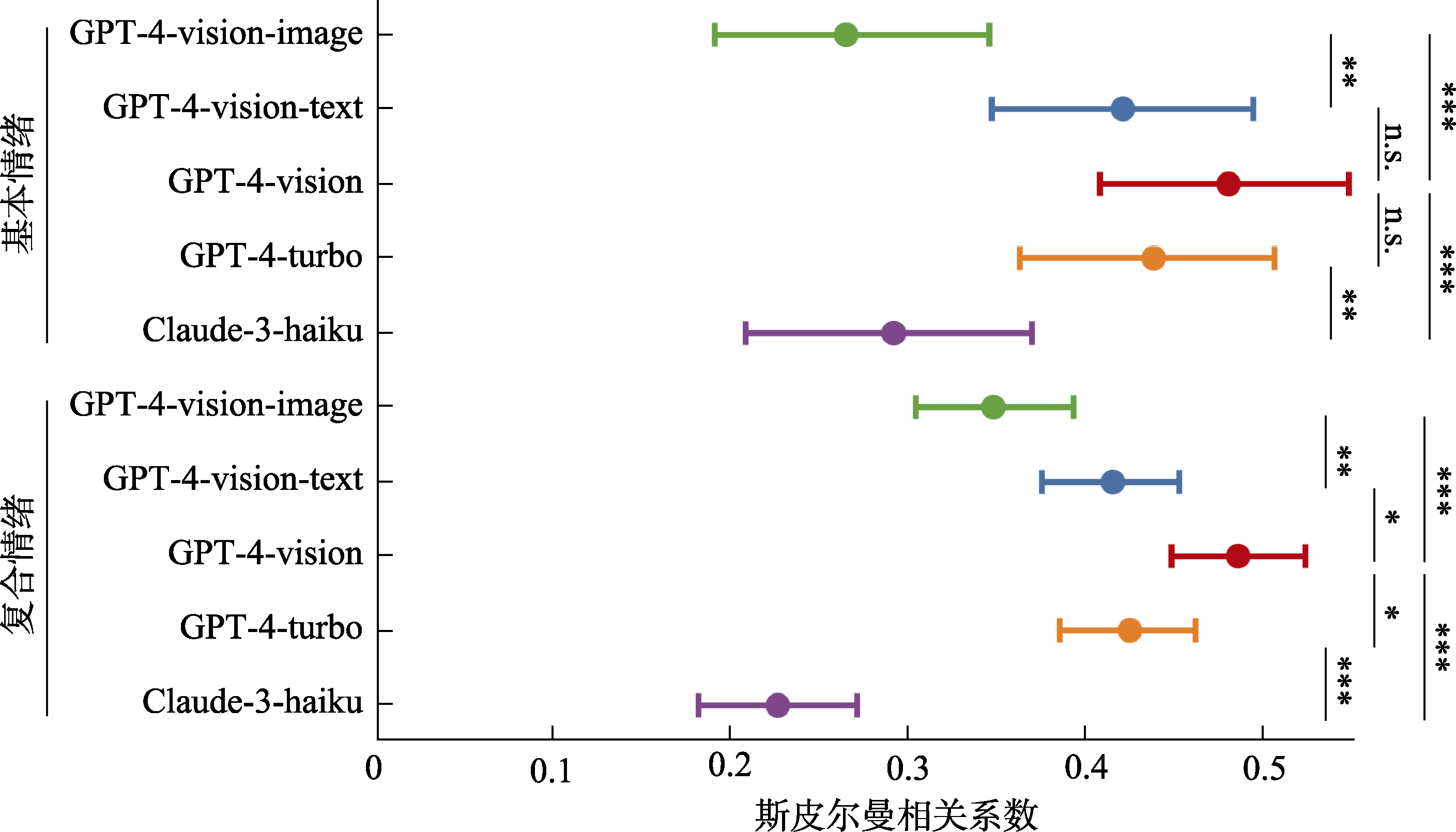
图5 多模态大语言模型zero-shot情绪识别斯皮尔曼相关分析与对比 注:*p < 0.05, **p < 0.01, *** p < 0.001, n.s. p > 0.05, 下同。
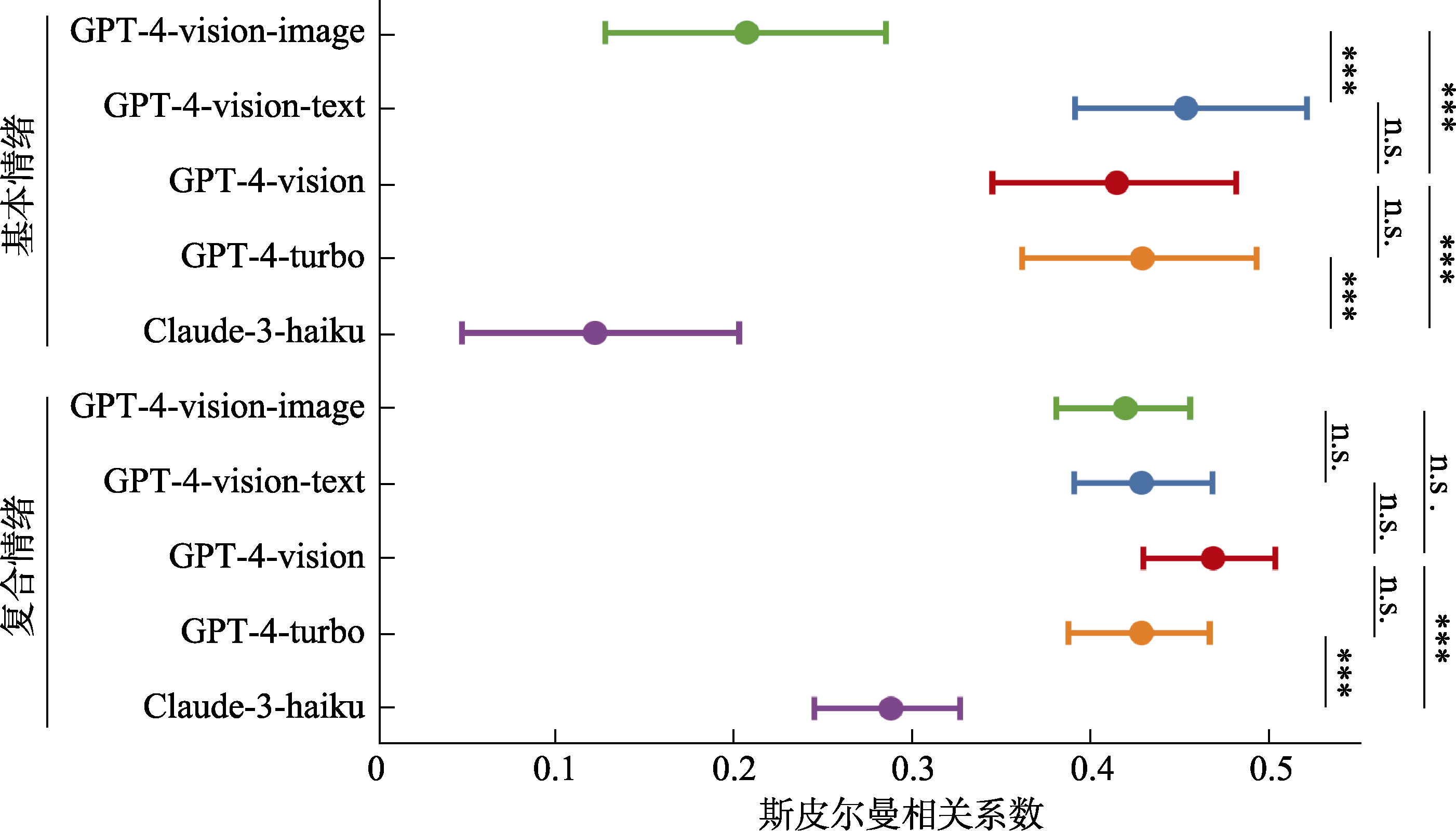
图6 多模态大语言模型zero-shot情绪推理斯皮尔曼相关分析与对比
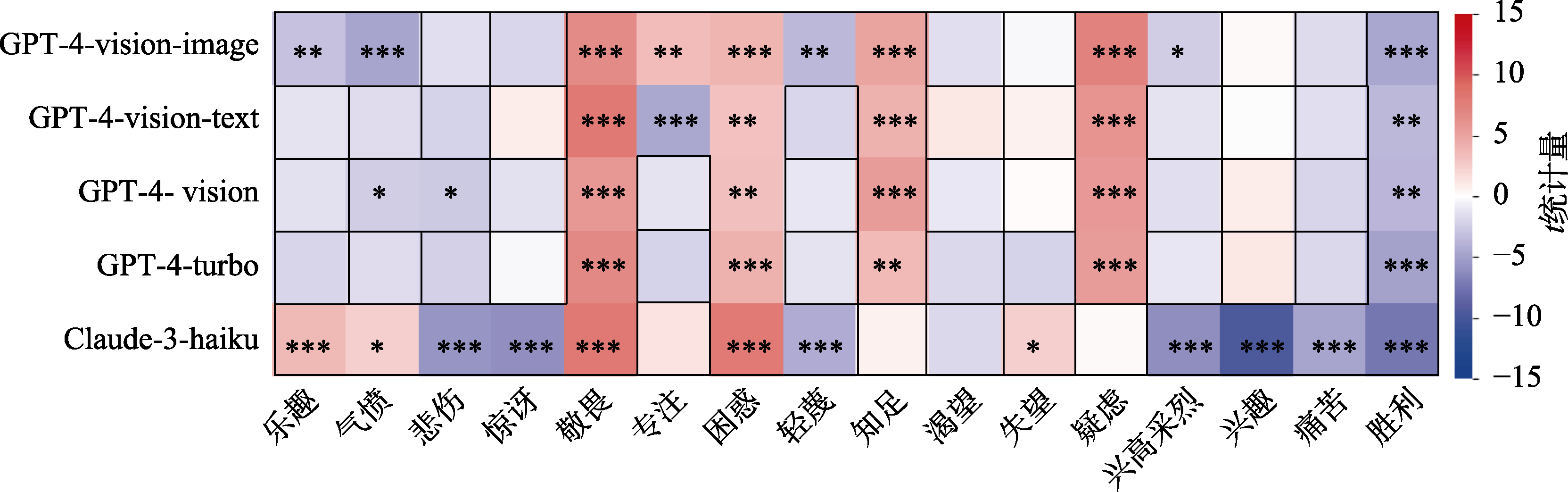
图7 多模态大语言模型zero-shot情绪识别独立样本t检验
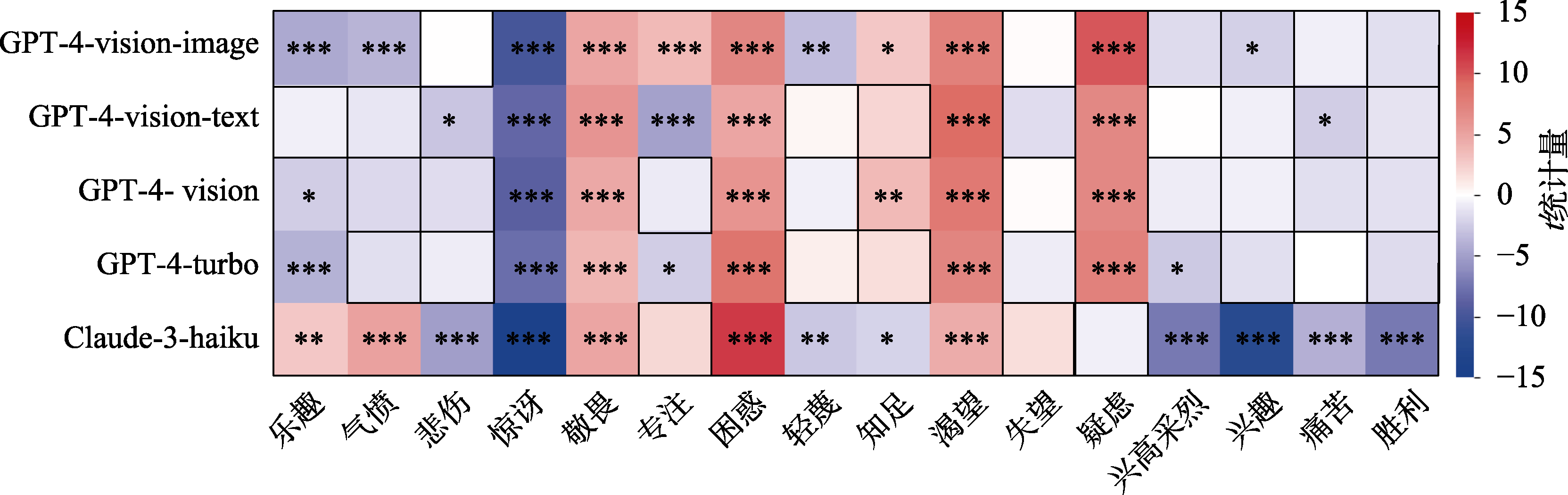
图8 多模态大语言模型zero-shot情绪推理独立样本t检验
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-imag eM ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.04 ± 0.07 | 296 | −3.11 | 0.004 | −0.36 | [−0.05, −0.01] |
| 气愤 | 0.11 ± 0.17 | 0.04 ± 0.07 | 296 | −4.75 | 0.000 | −0.55 | [−0.10, −0.04] |
| 悲伤 | 0.05 ± 0.07 | 0.04 ± 0.06 | 296 | −1.45 | 0.178 | −0.17 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.03 ± 0.05 | 296 | −1.93 | 0.080 | −0.22 | [−0.03, 0.00] |
| 敬畏 | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 6.66 | 0.000 | 0.77 | [0.01, 0.02] |
| 专注 | 0.12 ± 0.12 | 0.17 ± 0.14 | 296 | 3.41 | 0.001 | 0.40 | [0.02, 0.08] |
| 困惑 | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.96 | 0.000 | 0.46 | [0.02, 0.07] |
| 轻蔑 | 0.09 ± 0.11 | 0.05 ± 0.07 | 296 | −3.52 | 0.001 | −0.41 | [−0.06, −0.02] |
| 知足 | 0.03 ± 0.05 | 0.08 ± 0.10 | 296 | 4.93 | 0.000 | 0.57 | [0.03, 0.06] |
| 渴望 | 0.05 ± 0.08 | 0.04 ± 0.05 | 296 | −1.42 | 0.178 | −0.16 | [−0.03, 0.00] |
| 失望 | 0.07 ± 0.08 | 0.06 ± 0.05 | 296 | −0.27 | 0.796 | −0.03 | [−0.02, 0.01] |
| 疑虑 | 0.06 ± 0.07 | 0.12 ± 0.09 | 296 | 7.23 | 0.000 | 0.84 | [0.05, 0.08] |
| 兴高采烈 | 0.05 ± 0.10 | 0.03 ± 0.08 | 296 | −2.43 | 0.025 | −0.28 | [−0.05, 0.00] |
| 兴趣 | 0.08 ± 0.08 | 0.08 ± 0.09 | 296 | 0.26 | 0.796 | 0.03 | [−0.02, 0.02] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | −1.73 | 0.112 | −0.20 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | −4.60 | 0.000 | −0.53 | [−0.04, −0.02] |
附表S1 GPT-4-vision-image zero-shot和人类被试情绪识别独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-imag eM ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.04 ± 0.07 | 296 | −3.11 | 0.004 | −0.36 | [−0.05, −0.01] |
| 气愤 | 0.11 ± 0.17 | 0.04 ± 0.07 | 296 | −4.75 | 0.000 | −0.55 | [−0.10, −0.04] |
| 悲伤 | 0.05 ± 0.07 | 0.04 ± 0.06 | 296 | −1.45 | 0.178 | −0.17 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.03 ± 0.05 | 296 | −1.93 | 0.080 | −0.22 | [−0.03, 0.00] |
| 敬畏 | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 6.66 | 0.000 | 0.77 | [0.01, 0.02] |
| 专注 | 0.12 ± 0.12 | 0.17 ± 0.14 | 296 | 3.41 | 0.001 | 0.40 | [0.02, 0.08] |
| 困惑 | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.96 | 0.000 | 0.46 | [0.02, 0.07] |
| 轻蔑 | 0.09 ± 0.11 | 0.05 ± 0.07 | 296 | −3.52 | 0.001 | −0.41 | [−0.06, −0.02] |
| 知足 | 0.03 ± 0.05 | 0.08 ± 0.10 | 296 | 4.93 | 0.000 | 0.57 | [0.03, 0.06] |
| 渴望 | 0.05 ± 0.08 | 0.04 ± 0.05 | 296 | −1.42 | 0.178 | −0.16 | [−0.03, 0.00] |
| 失望 | 0.07 ± 0.08 | 0.06 ± 0.05 | 296 | −0.27 | 0.796 | −0.03 | [−0.02, 0.01] |
| 疑虑 | 0.06 ± 0.07 | 0.12 ± 0.09 | 296 | 7.23 | 0.000 | 0.84 | [0.05, 0.08] |
| 兴高采烈 | 0.05 ± 0.10 | 0.03 ± 0.08 | 296 | −2.43 | 0.025 | −0.28 | [−0.05, 0.00] |
| 兴趣 | 0.08 ± 0.08 | 0.08 ± 0.09 | 296 | 0.26 | 0.796 | 0.03 | [−0.02, 0.02] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | −1.73 | 0.112 | −0.20 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | −4.60 | 0.000 | −0.53 | [−0.04, −0.02] |
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-image M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.03 ± 0.05 | 296 | −4.44 | 0.000 | −0.51 | [−0.04, −0.02] |
| 气愤 | 0.09 ± 0.13 | 0.04 ± 0.05 | 296 | −3.82 | 0.000 | −0.44 | [−0.07, −0.02] |
| 悲伤 | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | 0.05 | 0.963 | 0.01 | [−0.01, 0.01] |
| 惊讶 | 0.13 ± 0.10 | 0.04 ± 0.04 | 296 | −9.87 | 0.000 | −1.14 | [−0.11, −0.07] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.87 | 0.000 | 0.56 | [0.01, 0.02] |
| 专注 | 0.10 ± 0.09 | 0.14 ± 0.09 | 296 | 3.63 | 0.001 | 0.42 | [0.02, 0.06] |
| 困惑 | 0.09 ± 0.06 | 0.14 ± 0.07 | 296 | 6.98 | 0.000 | 0.81 | [0.04, 0.07] |
| 轻蔑 | 0.06 ± 0.07 | 0.04 ± 0.04 | 296 | −3.19 | 0.003 | −0.37 | [−0.03, −0.01] |
| 知足 | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.70 | 0.012 | 0.31 | [0.00, 0.03] |
| 渴望 | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 7.44 | 0.000 | 0.86 | [0.02, 0.04] |
| 失望 | 0.08 ± 0.10 | 0.08 ± 0.05 | 296 | 0.20 | 0.897 | 0.02 | [−0.02, 0.02] |
| 疑虑 | 0.07 ± 0.05 | 0.13 ± 0.06 | 296 | 9.95 | 0.000 | 1.15 | [0.05, 0.08] |
| 兴高采烈 | 0.03 ± 0.05 | 0.02 ± 0.05 | 296 | −1.71 | 0.118 | −0.20 | [−0.02, 0.00] |
| 兴趣 | 0.09 ± 0.08 | 0.07 ± 0.06 | 296 | −2.30 | 0.033 | −0.27 | [−0.03, 0.00] |
| 痛苦 | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | −0.64 | 0.599 | −0.07 | [−0.02, 0.01] |
| 胜利 | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | −1.44 | 0.186 | −0.17 | [−0.01, 0.00] |
附表S2 GPT-4-vision-image zero-shot和人类被试情绪推理独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-image M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.03 ± 0.05 | 296 | −4.44 | 0.000 | −0.51 | [−0.04, −0.02] |
| 气愤 | 0.09 ± 0.13 | 0.04 ± 0.05 | 296 | −3.82 | 0.000 | −0.44 | [−0.07, −0.02] |
| 悲伤 | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | 0.05 | 0.963 | 0.01 | [−0.01, 0.01] |
| 惊讶 | 0.13 ± 0.10 | 0.04 ± 0.04 | 296 | −9.87 | 0.000 | −1.14 | [−0.11, −0.07] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.87 | 0.000 | 0.56 | [0.01, 0.02] |
| 专注 | 0.10 ± 0.09 | 0.14 ± 0.09 | 296 | 3.63 | 0.001 | 0.42 | [0.02, 0.06] |
| 困惑 | 0.09 ± 0.06 | 0.14 ± 0.07 | 296 | 6.98 | 0.000 | 0.81 | [0.04, 0.07] |
| 轻蔑 | 0.06 ± 0.07 | 0.04 ± 0.04 | 296 | −3.19 | 0.003 | −0.37 | [−0.03, −0.01] |
| 知足 | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.70 | 0.012 | 0.31 | [0.00, 0.03] |
| 渴望 | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 7.44 | 0.000 | 0.86 | [0.02, 0.04] |
| 失望 | 0.08 ± 0.10 | 0.08 ± 0.05 | 296 | 0.20 | 0.897 | 0.02 | [−0.02, 0.02] |
| 疑虑 | 0.07 ± 0.05 | 0.13 ± 0.06 | 296 | 9.95 | 0.000 | 1.15 | [0.05, 0.08] |
| 兴高采烈 | 0.03 ± 0.05 | 0.02 ± 0.05 | 296 | −1.71 | 0.118 | −0.20 | [−0.02, 0.00] |
| 兴趣 | 0.09 ± 0.08 | 0.07 ± 0.06 | 296 | −2.30 | 0.033 | −0.27 | [−0.03, 0.00] |
| 痛苦 | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | −0.64 | 0.599 | −0.07 | [−0.02, 0.01] |
| 胜利 | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | −1.44 | 0.186 | −0.17 | [−0.01, 0.00] |
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | −1.22 | 0.300 | −0.14 | [−0.03, 0.01] |
| 气愤 | 0.11 ± 0.17 | 0.08 ± 0.12 | 296 | −1.56 | 0.208 | −0.18 | [−0.06, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | −2.19 | 0.066 | −0.25 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.06 ± 0.08 | 296 | 0.92 | 0.412 | 0.11 | [−0.01, 0.03] |
| 敬畏 | 0.01 ± 0.02 | 0.04 ± 0.03 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.03] |
| 专注 | 0.12 ± 0.12 | 0.06 ± 0.08 | 296 | −4.47 | 0.000 | −0.52 | [−0.08, −0.03] |
| 困惑 | 0.09 ± 0.11 | 0.12 ± 0.09 | 296 | 3.12 | 0.005 | 0.36 | [0.01, 0.06] |
| 轻蔑 | 0.09 ± 0.11 | 0.07 ± 0.07 | 296 | −1.92 | 0.111 | −0.22 | [−0.04, 0.00] |
| 知足 | 0.03 ± 0.05 | 0.06 ± 0.07 | 296 | 4.21 | 0.000 | 0.49 | [0.02, 0.04] |
| 渴望 | 0.05 ± 0.08 | 0.06 ± 0.06 | 296 | 1.10 | 0.336 | 0.13 | [−0.01, 0.03] |
| 失望 | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.67 | 0.534 | 0.08 | [−0.01, 0.02] |
| 疑虑 | 0.06 ± 0.07 | 0.11 ± 0.07 | 296 | 6.06 | 0.000 | 0.70 | [0.03, 0.07] |
| 兴高采烈 | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | −1.22 | 0.300 | −0.14 | [−0.03, 0.01] |
| 兴趣 | 0.08 ± 0.08 | 0.08 ± 0.07 | 296 | −0.16 | 0.870 | −0.02 | [−0.02, 0.02] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | −1.52 | 0.208 | −0.18 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.02 ± 0.03 | 296 | −3.60 | 0.001 | −0.42 | [−0.03, −0.01] |
附表S3 GPT-4-vision-text zero-shot和人类被试情绪识别独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | −1.22 | 0.300 | −0.14 | [−0.03, 0.01] |
| 气愤 | 0.11 ± 0.17 | 0.08 ± 0.12 | 296 | −1.56 | 0.208 | −0.18 | [−0.06, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | −2.19 | 0.066 | −0.25 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.06 ± 0.08 | 296 | 0.92 | 0.412 | 0.11 | [−0.01, 0.03] |
| 敬畏 | 0.01 ± 0.02 | 0.04 ± 0.03 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.03] |
| 专注 | 0.12 ± 0.12 | 0.06 ± 0.08 | 296 | −4.47 | 0.000 | −0.52 | [−0.08, −0.03] |
| 困惑 | 0.09 ± 0.11 | 0.12 ± 0.09 | 296 | 3.12 | 0.005 | 0.36 | [0.01, 0.06] |
| 轻蔑 | 0.09 ± 0.11 | 0.07 ± 0.07 | 296 | −1.92 | 0.111 | −0.22 | [−0.04, 0.00] |
| 知足 | 0.03 ± 0.05 | 0.06 ± 0.07 | 296 | 4.21 | 0.000 | 0.49 | [0.02, 0.04] |
| 渴望 | 0.05 ± 0.08 | 0.06 ± 0.06 | 296 | 1.10 | 0.336 | 0.13 | [−0.01, 0.03] |
| 失望 | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.67 | 0.534 | 0.08 | [−0.01, 0.02] |
| 疑虑 | 0.06 ± 0.07 | 0.11 ± 0.07 | 296 | 6.06 | 0.000 | 0.70 | [0.03, 0.07] |
| 兴高采烈 | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | −1.22 | 0.300 | −0.14 | [−0.03, 0.01] |
| 兴趣 | 0.08 ± 0.08 | 0.08 ± 0.07 | 296 | −0.16 | 0.870 | −0.02 | [−0.02, 0.02] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | −1.52 | 0.208 | −0.18 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.02 ± 0.03 | 296 | −3.60 | 0.001 | −0.42 | [−0.03, −0.01] |
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.06 ± 0.07 | 296 | −0.61 | 0.619 | −0.07 | [−0.02, 0.01] |
| 气愤 | 0.09 ± 0.13 | 0.07 ± 0.10 | 296 | −1.08 | 0.375 | −0.13 | [−0.04, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.04 | 296 | −2.84 | 0.011 | −0.33 | [−0.03, −0.01] |
| 惊讶 | 0.13 ± 0.10 | 0.05 ± 0.06 | 296 | −8.33 | 0.000 | −0.97 | [−0.10, −0.06] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 5.98 | 0.000 | 0.69 | [0.02, 0.03] |
| 专注 | 0.10 ± 0.09 | 0.06 ± 0.07 | 296 | −4.84 | 0.000 | −0.56 | [−0.06, −0.03] |
| 困惑 | 0.09 ± 0.06 | 0.13 ± 0.08 | 296 | 4.86 | 0.000 | 0.56 | [0.02, 0.06] |
| 轻蔑 | 0.06 ± 0.07 | 0.07 ± 0.07 | 296 | 0.37 | 0.757 | 0.04 | [−0.01, 0.02] |
| 知足 | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.10 | 0.065 | 0.24 | [0.00, 0.03] |
| 渴望 | 0.02 ± 0.02 | 0.06 ± 0.05 | 296 | 9.09 | 0.000 | 1.05 | [0.03, 0.05] |
| 失望 | 0.08 ± 0.10 | 0.07 ± 0.05 | 296 | −1.57 | 0.188 | −0.18 | [−0.03, 0.00] |
| 疑虑 | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.85 | 0.000 | 0.79 | [0.04, 0.06] |
| 兴高采烈 | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | 0.08 | 0.935 | 0.01 | [−0.01, 0.01] |
| 兴趣 | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | −0.63 | 0.619 | −0.07 | [−0.02, 0.01] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | −2.34 | 0.039 | −0.27 | [−0.02, 0.00] |
| 胜利 | 0.02 ± 0.03 | 0.02 ± 0.03 | 296 | −1.26 | 0.305 | −0.15 | [−0.01, 0.00] |
附表S4 GPT-4-vision-text zero-shot和人类被试情绪推理独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.06 ± 0.07 | 296 | −0.61 | 0.619 | −0.07 | [−0.02, 0.01] |
| 气愤 | 0.09 ± 0.13 | 0.07 ± 0.10 | 296 | −1.08 | 0.375 | −0.13 | [−0.04, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.04 | 296 | −2.84 | 0.011 | −0.33 | [−0.03, −0.01] |
| 惊讶 | 0.13 ± 0.10 | 0.05 ± 0.06 | 296 | −8.33 | 0.000 | −0.97 | [−0.10, −0.06] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 5.98 | 0.000 | 0.69 | [0.02, 0.03] |
| 专注 | 0.10 ± 0.09 | 0.06 ± 0.07 | 296 | −4.84 | 0.000 | −0.56 | [−0.06, −0.03] |
| 困惑 | 0.09 ± 0.06 | 0.13 ± 0.08 | 296 | 4.86 | 0.000 | 0.56 | [0.02, 0.06] |
| 轻蔑 | 0.06 ± 0.07 | 0.07 ± 0.07 | 296 | 0.37 | 0.757 | 0.04 | [−0.01, 0.02] |
| 知足 | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.10 | 0.065 | 0.24 | [0.00, 0.03] |
| 渴望 | 0.02 ± 0.02 | 0.06 ± 0.05 | 296 | 9.09 | 0.000 | 1.05 | [0.03, 0.05] |
| 失望 | 0.08 ± 0.10 | 0.07 ± 0.05 | 296 | −1.57 | 0.188 | −0.18 | [−0.03, 0.00] |
| 疑虑 | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.85 | 0.000 | 0.79 | [0.04, 0.06] |
| 兴高采烈 | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | 0.08 | 0.935 | 0.01 | [−0.01, 0.01] |
| 兴趣 | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | −0.63 | 0.619 | −0.07 | [−0.02, 0.01] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | −2.34 | 0.039 | −0.27 | [−0.02, 0.00] |
| 胜利 | 0.02 ± 0.03 | 0.02 ± 0.03 | 296 | −1.26 | 0.305 | −0.15 | [−0.01, 0.00] |
| 情绪标签 | 人类被试 M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | −1.30 | 0.282 | −0.15 | [−0.03, 0.01] |
| 气愤 | 0.11 ± 0.17 | 0.07 ± 0.11 | 296 | −2.44 | 0.035 | −0.28 | [−0.07, −0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | −2.61 | 0.026 | −0.30 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.04 ± 0.04 | 296 | −1.32 | 0.282 | −0.15 | [−0.03, 0.01] |
| 敬畏 | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 5.68 | 0.000 | 0.66 | [0.01, 0.02] |
| 专注 | 0.12 ± 0.12 | 0.10 ± 0.10 | 296 | −1.22 | 0.296 | −0.14 | [−0.04, 0.01] |
| 困惑 | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.18 | 0.005 | 0.37 | [0.01, 0.06] |
| 轻蔑 | 0.09 ± 0.11 | 0.08 ± 0.09 | 296 | −1.11 | 0.329 | −0.13 | [−0.04, 0.01] |
| 知足 | 0.03 ± 0.05 | 0.07 ± 0.08 | 296 | 5.51 | 0.000 | 0.64 | [0.03, 0.06] |
| 渴望 | 0.05 ± 0.08 | 0.05 ± 0.05 | 296 | −0.98 | 0.377 | −0.11 | [−0.02, 0.01] |
| 失望 | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.13 | 0.898 | 0.01 | [−0.02, 0.02] |
| 疑虑 | 0.06 ± 0.07 | 0.11 ± 0.08 | 296 | 5.52 | 0.000 | 0.64 | [0.03, 0.06] |
| 兴高采烈 | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | −1.52 | 0.232 | −0.18 | [−0.03, 0.00] |
| 兴趣 | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 0.86 | 0.414 | 0.10 | [−0.01, 0.03] |
| 痛苦 | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | −2.04 | 0.084 | −0.24 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | −3.70 | 0.001 | −0.43 | [−0.03, −0.01] |
附表S5 GPT-4-vision zero-shot和人类被试情绪识别独立样本t检验结果
| 情绪标签 | 人类被试 M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | −1.30 | 0.282 | −0.15 | [−0.03, 0.01] |
| 气愤 | 0.11 ± 0.17 | 0.07 ± 0.11 | 296 | −2.44 | 0.035 | −0.28 | [−0.07, −0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | −2.61 | 0.026 | −0.30 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.04 ± 0.04 | 296 | −1.32 | 0.282 | −0.15 | [−0.03, 0.01] |
| 敬畏 | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 5.68 | 0.000 | 0.66 | [0.01, 0.02] |
| 专注 | 0.12 ± 0.12 | 0.10 ± 0.10 | 296 | −1.22 | 0.296 | −0.14 | [−0.04, 0.01] |
| 困惑 | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.18 | 0.005 | 0.37 | [0.01, 0.06] |
| 轻蔑 | 0.09 ± 0.11 | 0.08 ± 0.09 | 296 | −1.11 | 0.329 | −0.13 | [−0.04, 0.01] |
| 知足 | 0.03 ± 0.05 | 0.07 ± 0.08 | 296 | 5.51 | 0.000 | 0.64 | [0.03, 0.06] |
| 渴望 | 0.05 ± 0.08 | 0.05 ± 0.05 | 296 | −0.98 | 0.377 | −0.11 | [−0.02, 0.01] |
| 失望 | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.13 | 0.898 | 0.01 | [−0.02, 0.02] |
| 疑虑 | 0.06 ± 0.07 | 0.11 ± 0.08 | 296 | 5.52 | 0.000 | 0.64 | [0.03, 0.06] |
| 兴高采烈 | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | −1.52 | 0.232 | −0.18 | [−0.03, 0.00] |
| 兴趣 | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 0.86 | 0.414 | 0.10 | [−0.01, 0.03] |
| 痛苦 | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | −2.04 | 0.084 | −0.24 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | −3.70 | 0.001 | −0.43 | [−0.03, −0.01] |
| 情绪标签 | 人类被试M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.05 ± 0.06 | 296 | −2.37 | 0.042 | −0.27 | [−0.03, 0.00] |
| 气愤 | 0.09 ± 0.13 | 0.06 ± 0.09 | 296 | −1.87 | 0.126 | −0.22 | [−0.05, 0.00] |
| 悲伤 | 0.05 ± 0.07 | 0.04 ± 0.04 | 296 | −1.61 | 0.193 | −0.19 | [−0.02, 0.00] |
| 惊讶 | 0.13 ± 0.10 | 0.05 ± 0.05 | 296 | −8.82 | 0.000 | −1.02 | [−0.10, −0.06] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.68 | 0.000 | 0.54 | [0.01, 0.02] |
| 专注 | 0.10 ± 0.09 | 0.10 ± 0.08 | 296 | −0.87 | 0.513 | −0.10 | [−0.03, 0.01] |
| 困惑 | 0.09 ± 0.06 | 0.13 ± 0.07 | 296 | 5.99 | 0.000 | 0.69 | [0.03, 0.06] |
| 轻蔑 | 0.06 ± 0.07 | 0.06 ± 0.06 | 296 | −0.68 | 0.571 | −0.08 | [−0.02, 0.01] |
| 知足 | 0.04 ± 0.06 | 0.07 ± 0.07 | 296 | 3.53 | 0.001 | 0.41 | [0.01, 0.04] |
| 渴望 | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.04] |
| 失望 | 0.08 ± 0.10 | 0.08 ± 0.06 | 296 | 0.16 | 0.870 | 0.02 | [−0.02, 0.02] |
| 疑虑 | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.82 | 0.000 | 0.79 | [0.03, 0.06] |
| 兴高采烈 | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | −0.80 | 0.521 | −0.09 | [−0.02, 0.01] |
| 兴趣 | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | −0.62 | 0.571 | −0.07 | [−0.02, 0.01] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | −1.46 | 0.233 | −0.17 | [−0.02, 0.00] |
| 胜利 | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | −1.41 | 0.234 | −0.16 | [−0.01, 0.00] |
附表S6 GPT-4-vision zero-shot和人类被试情绪推理独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.05 ± 0.06 | 296 | −2.37 | 0.042 | −0.27 | [−0.03, 0.00] |
| 气愤 | 0.09 ± 0.13 | 0.06 ± 0.09 | 296 | −1.87 | 0.126 | −0.22 | [−0.05, 0.00] |
| 悲伤 | 0.05 ± 0.07 | 0.04 ± 0.04 | 296 | −1.61 | 0.193 | −0.19 | [−0.02, 0.00] |
| 惊讶 | 0.13 ± 0.10 | 0.05 ± 0.05 | 296 | −8.82 | 0.000 | −1.02 | [−0.10, −0.06] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.68 | 0.000 | 0.54 | [0.01, 0.02] |
| 专注 | 0.10 ± 0.09 | 0.10 ± 0.08 | 296 | −0.87 | 0.513 | −0.10 | [−0.03, 0.01] |
| 困惑 | 0.09 ± 0.06 | 0.13 ± 0.07 | 296 | 5.99 | 0.000 | 0.69 | [0.03, 0.06] |
| 轻蔑 | 0.06 ± 0.07 | 0.06 ± 0.06 | 296 | −0.68 | 0.571 | −0.08 | [−0.02, 0.01] |
| 知足 | 0.04 ± 0.06 | 0.07 ± 0.07 | 296 | 3.53 | 0.001 | 0.41 | [0.01, 0.04] |
| 渴望 | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.04] |
| 失望 | 0.08 ± 0.10 | 0.08 ± 0.06 | 296 | 0.16 | 0.870 | 0.02 | [−0.02, 0.02] |
| 疑虑 | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.82 | 0.000 | 0.79 | [0.03, 0.06] |
| 兴高采烈 | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | −0.80 | 0.521 | −0.09 | [−0.02, 0.01] |
| 兴趣 | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | −0.62 | 0.571 | −0.07 | [−0.02, 0.01] |
| 痛苦 | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | −1.46 | 0.233 | −0.17 | [−0.02, 0.00] |
| 胜利 | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | −1.41 | 0.234 | −0.16 | [−0.01, 0.00] |
| 情绪标签 | 人类被试M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.05 ± 0.08 | 296 | −2.04 | 0.075 | −0.24 | [−0.04, 0.00] |
| 气愤 | 0.11 ± 0.17 | 0.08 ± 0.14 | 296 | −1.58 | 0.153 | −0.18 | [−0.06, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | −2.31 | 0.057 | −0.27 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.05 ± 0.07 | 296 | −0.25 | 0.804 | −0.03 | [−0.02, 0.02] |
| 敬畏 | 0.01 ± 0.02 | 0.04 ± 0.05 | 296 | 6.77 | 0.000 | 0.78 | [0.02, 0.04] |
| 专注 | 0.12 ± 0.12 | 0.09 ± 0.11 | 296 | −2.18 | 0.069 | −0.25 | [−0.05, 0.00] |
| 困惑 | 0.09 ± 0.11 | 0.14 ± 0.12 | 296 | 4.12 | 0.000 | 0.48 | [0.03, 0.08] |
| 轻蔑 | 0.09 ± 0.11 | 0.07 ± 0.09 | 296 | −1.18 | 0.293 | −0.14 | [−0.04, 0.01] |
| 知足 | 0.03 ± 0.05 | 0.06 ± 0.08 | 296 | 3.62 | 0.001 | 0.42 | [0.01, 0.04] |
| 渴望 | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | −1.83 | 0.099 | −0.21 | [−0.03, 0.00] |
| 失望 | 0.07 ± 0.08 | 0.05 ± 0.06 | 296 | −2.12 | 0.070 | −0.25 | [−0.03, 0.00] |
| 疑虑 | 0.06 ± 0.07 | 0.11 ± 0.10 | 296 | 5.42 | 0.000 | 0.63 | [0.03, 0.07] |
| 兴高采烈 | 0.05 ± 0.10 | 0.04 ± 0.08 | 296 | −1.13 | 0.293 | −0.13 | [−0.03, 0.01] |
| 兴趣 | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 1.09 | 0.293 | 0.13 | [−0.01, 0.03] |
| 痛苦 | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | −1.85 | 0.099 | −0.21 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | −4.81 | 0.000 | −0.56 | [−0.04, −0.02] |
附表S7 GPT-4-turbo zero-shot和人类被试情绪识别独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.05 ± 0.08 | 296 | −2.04 | 0.075 | −0.24 | [−0.04, 0.00] |
| 气愤 | 0.11 ± 0.17 | 0.08 ± 0.14 | 296 | −1.58 | 0.153 | −0.18 | [−0.06, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | −2.31 | 0.057 | −0.27 | [−0.03, 0.00] |
| 惊讶 | 0.05 ± 0.09 | 0.05 ± 0.07 | 296 | −0.25 | 0.804 | −0.03 | [−0.02, 0.02] |
| 敬畏 | 0.01 ± 0.02 | 0.04 ± 0.05 | 296 | 6.77 | 0.000 | 0.78 | [0.02, 0.04] |
| 专注 | 0.12 ± 0.12 | 0.09 ± 0.11 | 296 | −2.18 | 0.069 | −0.25 | [−0.05, 0.00] |
| 困惑 | 0.09 ± 0.11 | 0.14 ± 0.12 | 296 | 4.12 | 0.000 | 0.48 | [0.03, 0.08] |
| 轻蔑 | 0.09 ± 0.11 | 0.07 ± 0.09 | 296 | −1.18 | 0.293 | −0.14 | [−0.04, 0.01] |
| 知足 | 0.03 ± 0.05 | 0.06 ± 0.08 | 296 | 3.62 | 0.001 | 0.42 | [0.01, 0.04] |
| 渴望 | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | −1.83 | 0.099 | −0.21 | [−0.03, 0.00] |
| 失望 | 0.07 ± 0.08 | 0.05 ± 0.06 | 296 | −2.12 | 0.070 | −0.25 | [−0.03, 0.00] |
| 疑虑 | 0.06 ± 0.07 | 0.11 ± 0.10 | 296 | 5.42 | 0.000 | 0.63 | [0.03, 0.07] |
| 兴高采烈 | 0.05 ± 0.10 | 0.04 ± 0.08 | 296 | −1.13 | 0.293 | −0.13 | [−0.03, 0.01] |
| 兴趣 | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 1.09 | 0.293 | 0.13 | [−0.01, 0.03] |
| 痛苦 | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | −1.85 | 0.099 | −0.21 | [−0.02, 0.00] |
| 胜利 | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | −4.81 | 0.000 | −0.56 | [−0.04, −0.02] |
| 情绪标签 | 人类被试 M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.04 ± 0.05 | 296 | −3.88 | 0.000 | −0.45 | [−0.04, −0.01] |
| 气愤 | 0.09 ± 0.13 | 0.07 ± 0.09 | 296 | −1.48 | 0.192 | −0.17 | [−0.04, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | −0.72 | 0.504 | −0.08 | [−0.02, 0.01] |
| 惊讶 | 0.13 ± 0.10 | 0.06 ± 0.06 | 296 | −7.88 | 0.000 | −0.91 | [−0.09, −0.06] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 3.83 | 0.000 | 0.44 | [0.01, 0.02] |
| 专注 | 0.10 ± 0.09 | 0.08 ± 0.08 | 296 | −2.37 | 0.037 | −0.27 | [−0.04, 0.00] |
| 困惑 | 0.09 ± 0.06 | 0.16 ± 0.08 | 296 | 8.36 | 0.000 | 0.97 | [0.05, 0.08] |
| 轻蔑 | 0.06 ± 0.07 | 0.07 ± 0.06 | 296 | 0.77 | 0.504 | 0.09 | [−0.01, 0.02] |
| 知足 | 0.04 ± 0.06 | 0.05 ± 0.06 | 296 | 1.60 | 0.176 | 0.19 | [0.00, 0.03] |
| 渴望 | 0.02 ± 0.02 | 0.05 ± 0.05 | 296 | 7.05 | 0.000 | 0.82 | [0.02, 0.04] |
| 失望 | 0.08 ± 0.10 | 0.07 ± 0.06 | 296 | −0.77 | 0.504 | −0.09 | [−0.03, 0.01] |
| 疑虑 | 0.07 ± 0.05 | 0.12 ± 0.07 | 296 | 7.38 | 0.000 | 0.85 | [0.04, 0.07] |
| 兴高采烈 | 0.03 ± 0.05 | 0.02 ± 0.04 | 296 | −2.63 | 0.020 | −0.31 | [−0.02, 0.00] |
| 兴趣 | 0.09 ± 0.08 | 0.07 ± 0.07 | 296 | −1.47 | 0.192 | −0.17 | [−0.03, 0.00] |
| 痛苦 | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | −0.06 | 0.953 | −0.01 | [−0.01, 0.01] |
| 胜利 | 0.02 ± 0.03 | 0.01 ± 0.02 | 296 | −1.75 | 0.143 | −0.20 | [−0.01, 0.00] |
附表S8 GPT-4-turbo zero-shot和人类被试情绪推理独立样本t检验结果
| 情绪标签 | 人类被试 M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.04 ± 0.05 | 296 | −3.88 | 0.000 | −0.45 | [−0.04, −0.01] |
| 气愤 | 0.09 ± 0.13 | 0.07 ± 0.09 | 296 | −1.48 | 0.192 | −0.17 | [−0.04, 0.01] |
| 悲伤 | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | −0.72 | 0.504 | −0.08 | [−0.02, 0.01] |
| 惊讶 | 0.13 ± 0.10 | 0.06 ± 0.06 | 296 | −7.88 | 0.000 | −0.91 | [−0.09, −0.06] |
| 敬畏 | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 3.83 | 0.000 | 0.44 | [0.01, 0.02] |
| 专注 | 0.10 ± 0.09 | 0.08 ± 0.08 | 296 | −2.37 | 0.037 | −0.27 | [−0.04, 0.00] |
| 困惑 | 0.09 ± 0.06 | 0.16 ± 0.08 | 296 | 8.36 | 0.000 | 0.97 | [0.05, 0.08] |
| 轻蔑 | 0.06 ± 0.07 | 0.07 ± 0.06 | 296 | 0.77 | 0.504 | 0.09 | [−0.01, 0.02] |
| 知足 | 0.04 ± 0.06 | 0.05 ± 0.06 | 296 | 1.60 | 0.176 | 0.19 | [0.00, 0.03] |
| 渴望 | 0.02 ± 0.02 | 0.05 ± 0.05 | 296 | 7.05 | 0.000 | 0.82 | [0.02, 0.04] |
| 失望 | 0.08 ± 0.10 | 0.07 ± 0.06 | 296 | −0.77 | 0.504 | −0.09 | [−0.03, 0.01] |
| 疑虑 | 0.07 ± 0.05 | 0.12 ± 0.07 | 296 | 7.38 | 0.000 | 0.85 | [0.04, 0.07] |
| 兴高采烈 | 0.03 ± 0.05 | 0.02 ± 0.04 | 296 | −2.63 | 0.020 | −0.31 | [−0.02, 0.00] |
| 兴趣 | 0.09 ± 0.08 | 0.07 ± 0.07 | 296 | −1.47 | 0.192 | −0.17 | [−0.03, 0.00] |
| 痛苦 | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | −0.06 | 0.953 | −0.01 | [−0.01, 0.01] |
| 胜利 | 0.02 ± 0.03 | 0.01 ± 0.02 | 296 | −1.75 | 0.143 | −0.20 | [−0.01, 0.00] |
| 情绪标签 | 人类被试M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.13 ± 0.15 | 296 | 3.74 | 0.000 | 0.43 | [0.03, 0.08] |
| 气愤 | 0.11 ± 0.17 | 0.16 ± 0.17 | 296 | 2.42 | 0.023 | 0.28 | [0.01, 0.09] |
| 悲伤 | 0.05 ± 0.07 | 0.01 ± 0.03 | 296 | −5.69 | 0.000 | −0.66 | [−0.05, −0.02] |
| 惊讶 | 0.05 ± 0.09 | 0.00 ± 0.02 | 296 | −6.09 | 0.000 | −0.71 | [−0.06, −0.03] |
| 敬畏 | 0.01 ± 0.02 | 0.06 ± 0.07 | 296 | 8.01 | 0.000 | 0.93 | [0.04, 0.06] |
| 专注 | 0.12 ± 0.12 | 0.13 ± 0.12 | 296 | 1.29 | 0.227 | 0.15 | [−0.01, 0.04] |
| 困惑 | 0.09 ± 0.11 | 0.19 ± 0.12 | 296 | 7.90 | 0.000 | 0.92 | [0.08, 0.14] |
| 轻蔑 | 0.09 ± 0.11 | 0.04 ± 0.07 | 296 | −4.24 | 0.000 | −0.49 | [−0.07, −0.02] |
| 知足 | 0.03 ± 0.05 | 0.04 ± 0.07 | 296 | 0.69 | 0.526 | 0.08 | [−0.01, 0.02] |
| 渴望 | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | −1.79 | 0.092 | −0.21 | [−0.03, 0.00] |
| 失望 | 0.07 ± 0.08 | 0.09 ± 0.11 | 296 | 2.35 | 0.026 | 0.27 | [0.00, 0.05] |
| 疑虑 | 0.06 ± 0.07 | 0.06 ± 0.08 | 296 | 0.24 | 0.814 | 0.03 | [−0.02, 0.02] |
| 兴高采烈 | 0.05 ± 0.10 | 0.00 ± 0.01 | 296 | −6.20 | 0.000 | −0.72 | [−0.07, −0.03] |
| 兴趣 | 0.08 ± 0.08 | 0.01 ± 0.03 | 296 | −9.54 | 0.000 | −1.11 | [−0.09, −0.06] |
| 痛苦 | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | −4.77 | 0.000 | −0.55 | [−0.04, −0.02] |
| 胜利 | 0.04 ± 0.06 | 0.00 ± 0.00 | 296 | −7.32 | 0.000 | −0.85 | [−0.05, −0.03] |
附表S9 Claude-3-haiku zero-shot和人类被试情绪识别独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.08 | 0.13 ± 0.15 | 296 | 3.74 | 0.000 | 0.43 | [0.03, 0.08] |
| 气愤 | 0.11 ± 0.17 | 0.16 ± 0.17 | 296 | 2.42 | 0.023 | 0.28 | [0.01, 0.09] |
| 悲伤 | 0.05 ± 0.07 | 0.01 ± 0.03 | 296 | −5.69 | 0.000 | −0.66 | [−0.05, −0.02] |
| 惊讶 | 0.05 ± 0.09 | 0.00 ± 0.02 | 296 | −6.09 | 0.000 | −0.71 | [−0.06, −0.03] |
| 敬畏 | 0.01 ± 0.02 | 0.06 ± 0.07 | 296 | 8.01 | 0.000 | 0.93 | [0.04, 0.06] |
| 专注 | 0.12 ± 0.12 | 0.13 ± 0.12 | 296 | 1.29 | 0.227 | 0.15 | [−0.01, 0.04] |
| 困惑 | 0.09 ± 0.11 | 0.19 ± 0.12 | 296 | 7.90 | 0.000 | 0.92 | [0.08, 0.14] |
| 轻蔑 | 0.09 ± 0.11 | 0.04 ± 0.07 | 296 | −4.24 | 0.000 | −0.49 | [−0.07, −0.02] |
| 知足 | 0.03 ± 0.05 | 0.04 ± 0.07 | 296 | 0.69 | 0.526 | 0.08 | [−0.01, 0.02] |
| 渴望 | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | −1.79 | 0.092 | −0.21 | [−0.03, 0.00] |
| 失望 | 0.07 ± 0.08 | 0.09 ± 0.11 | 296 | 2.35 | 0.026 | 0.27 | [0.00, 0.05] |
| 疑虑 | 0.06 ± 0.07 | 0.06 ± 0.08 | 296 | 0.24 | 0.814 | 0.03 | [−0.02, 0.02] |
| 兴高采烈 | 0.05 ± 0.10 | 0.00 ± 0.01 | 296 | −6.20 | 0.000 | −0.72 | [−0.07, −0.03] |
| 兴趣 | 0.08 ± 0.08 | 0.01 ± 0.03 | 296 | −9.54 | 0.000 | −1.11 | [−0.09, −0.06] |
| 痛苦 | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | −4.77 | 0.000 | −0.55 | [−0.04, −0.02] |
| 胜利 | 0.04 ± 0.06 | 0.00 ± 0.00 | 296 | −7.32 | 0.000 | −0.85 | [−0.05, −0.03] |
| 情绪标签 | 人类被试M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.10 ± 0.13 | 296 | 2.75 | 0.009 | 0.32 | [0.01, 0.06] |
| 气愤 | 0.09 ± 0.13 | 0.17 ± 0.15 | 296 | 5.09 | 0.000 | 0.59 | [0.05, 0.11] |
| 悲伤 | 0.05 ± 0.07 | 0.02 ± 0.04 | 296 | −5.15 | 0.000 | −0.60 | [−0.05, −0.02] |
| 惊讶 | 0.13 ± 0.10 | 0.01 ± 0.03 | 296 | −14.07 | 0.000 | −1.63 | [−0.14, −0.11] |
| 敬畏 | 0.02 ± 0.03 | 0.05 ± 0.06 | 296 | 4.83 | 0.000 | 0.56 | [0.02, 0.04] |
| 专注 | 0.10 ± 0.09 | 0.13 ± 0.11 | 296 | 1.93 | 0.063 | 0.22 | [0.00, 0.04] |
| 困惑 | 0.09 ± 0.06 | 0.20 ± 0.11 | 296 | 11.28 | 0.000 | 1.31 | [0.09, 0.13] |
| 轻蔑 | 0.06 ± 0.07 | 0.05 ± 0.05 | 296 | −2.71 | 0.009 | −0.31 | [−0.03, −0.01] |
| 知足 | 0.04 ± 0.06 | 0.03 ± 0.06 | 296 | −2.16 | 0.039 | −0.25 | [−0.03, 0.00] |
| 渴望 | 0.02 ± 0.02 | 0.04 ± 0.06 | 296 | 4.34 | 0.000 | 0.50 | [0.01, 0.03] |
| 失望 | 0.08 ± 0.10 | 0.10 ± 0.10 | 296 | 1.62 | 0.113 | 0.19 | [0.00, 0.04] |
| 疑虑 | 0.07 ± 0.05 | 0.06 ± 0.07 | 296 | −0.68 | 0.499 | −0.08 | [−0.02, 0.01] |
| 兴高采烈 | 0.03 ± 0.05 | 0.00 ± 0.01 | 296 | −7.15 | 0.000 | −0.83 | [−0.04, −0.02] |
| 兴趣 | 0.09 ± 0.08 | 0.01 ± 0.02 | 296 | −12.03 | 0.000 | −1.39 | [−0.09, −0.07] |
| 痛苦 | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | −4.08 | 0.000 | −0.47 | [−0.04, −0.01] |
| 胜利 | 0.02 ± 0.03 | 0.00 ± 0.00 | 296 | −7.17 | 0.000 | −0.83 | [−0.02, −0.01] |
附表S10 Claude-3-haiku zero-shot和人类被试情绪推理独立样本t检验结果
| 情绪标签 | 人类被试M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| 乐趣 | 0.07 ± 0.07 | 0.10 ± 0.13 | 296 | 2.75 | 0.009 | 0.32 | [0.01, 0.06] |
| 气愤 | 0.09 ± 0.13 | 0.17 ± 0.15 | 296 | 5.09 | 0.000 | 0.59 | [0.05, 0.11] |
| 悲伤 | 0.05 ± 0.07 | 0.02 ± 0.04 | 296 | −5.15 | 0.000 | −0.60 | [−0.05, −0.02] |
| 惊讶 | 0.13 ± 0.10 | 0.01 ± 0.03 | 296 | −14.07 | 0.000 | −1.63 | [−0.14, −0.11] |
| 敬畏 | 0.02 ± 0.03 | 0.05 ± 0.06 | 296 | 4.83 | 0.000 | 0.56 | [0.02, 0.04] |
| 专注 | 0.10 ± 0.09 | 0.13 ± 0.11 | 296 | 1.93 | 0.063 | 0.22 | [0.00, 0.04] |
| 困惑 | 0.09 ± 0.06 | 0.20 ± 0.11 | 296 | 11.28 | 0.000 | 1.31 | [0.09, 0.13] |
| 轻蔑 | 0.06 ± 0.07 | 0.05 ± 0.05 | 296 | −2.71 | 0.009 | −0.31 | [−0.03, −0.01] |
| 知足 | 0.04 ± 0.06 | 0.03 ± 0.06 | 296 | −2.16 | 0.039 | −0.25 | [−0.03, 0.00] |
| 渴望 | 0.02 ± 0.02 | 0.04 ± 0.06 | 296 | 4.34 | 0.000 | 0.50 | [0.01, 0.03] |
| 失望 | 0.08 ± 0.10 | 0.10 ± 0.10 | 296 | 1.62 | 0.113 | 0.19 | [0.00, 0.04] |
| 疑虑 | 0.07 ± 0.05 | 0.06 ± 0.07 | 296 | −0.68 | 0.499 | −0.08 | [−0.02, 0.01] |
| 兴高采烈 | 0.03 ± 0.05 | 0.00 ± 0.01 | 296 | −7.15 | 0.000 | −0.83 | [−0.04, −0.02] |
| 兴趣 | 0.09 ± 0.08 | 0.01 ± 0.02 | 296 | −12.03 | 0.000 | −1.39 | [−0.09, −0.07] |
| 痛苦 | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | −4.08 | 0.000 | −0.47 | [−0.04, −0.01] |
| 胜利 | 0.02 ± 0.03 | 0.00 ± 0.00 | 296 | −7.17 | 0.000 | −0.83 | [−0.02, −0.01] |

附图S1 多模态大语言模型zero-shot情绪识别测评prompt示例

附图S2 多模态大语言模型zero-shot情绪推理测评prompt示例

附图S3 多模态大语言模型重复测量情绪识别测评prompt示例

附图S4 多模态大语言模型重复测量情绪推理测评prompt示例
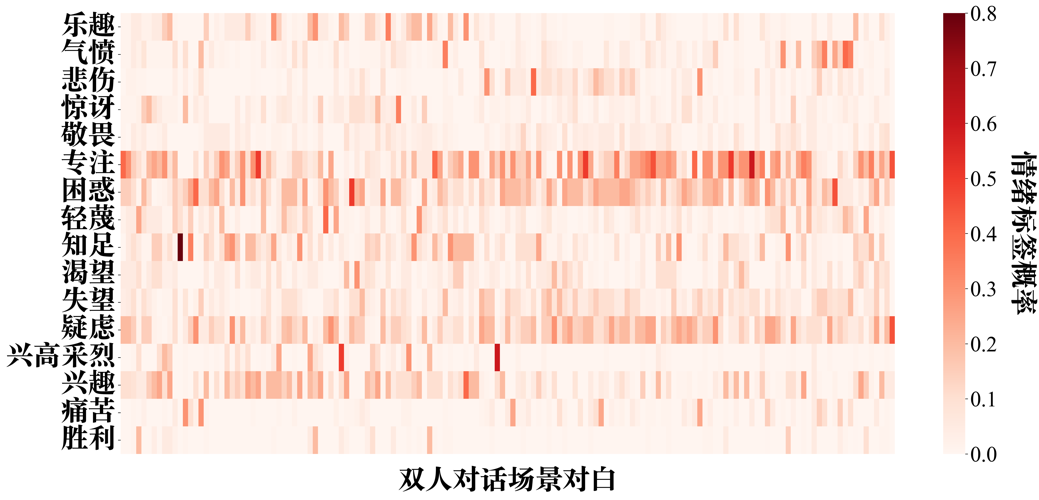
附图S5 GPT-4-vision-image zero-shot情绪识别的情绪标签-双人对话场景概率分布矩阵
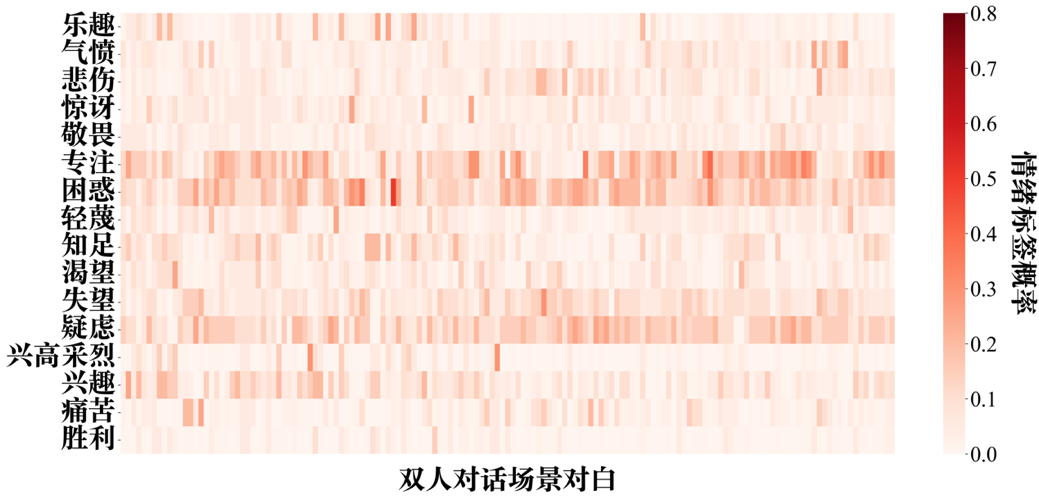
附图S6 GPT-4-vision-image zero-shot情绪推理的情绪标签-双人对话场景概率分布矩阵
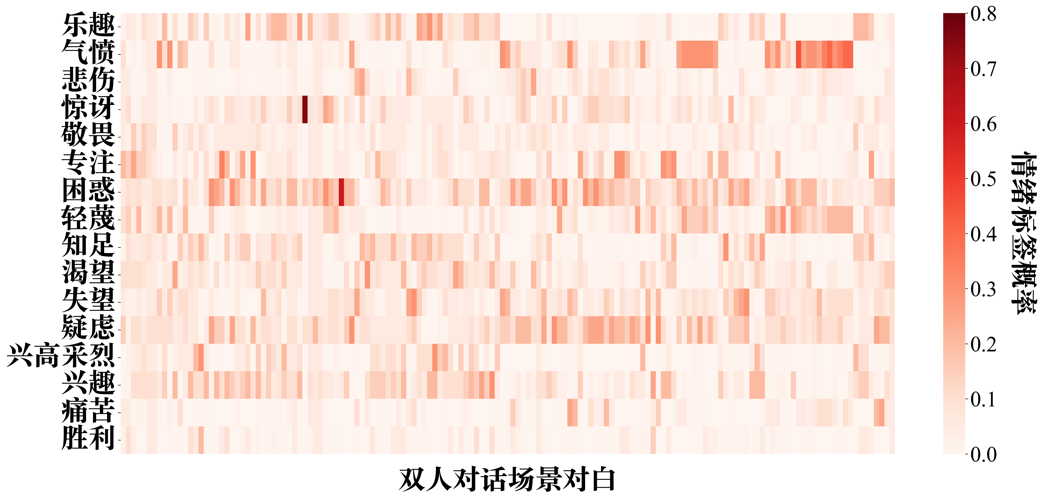
附图S7 GPT-4-vision-text zero-shot情绪识别的情绪标签-双人对话场景概率分布矩阵
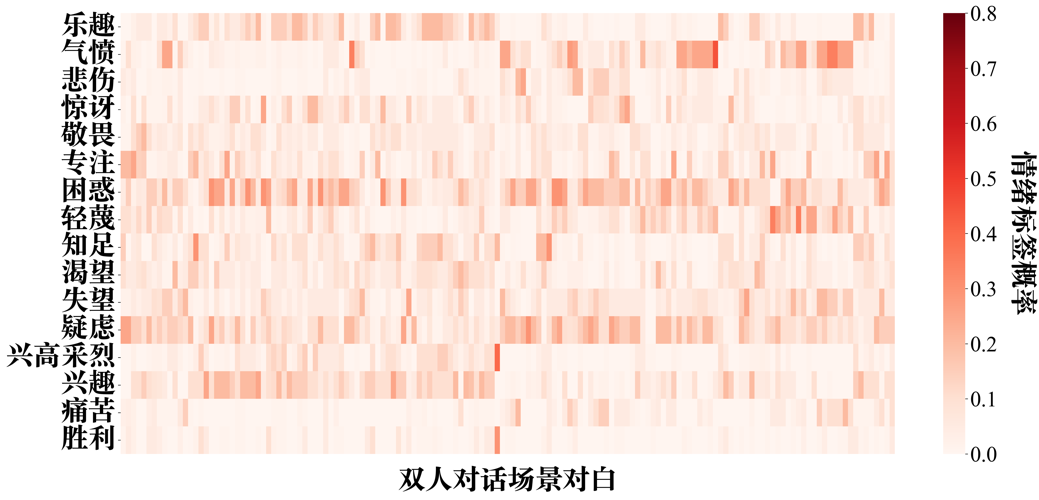
附图S8 GPT-4-vision-text zero-shot情绪推理的情绪标签-双人对话场景概率分布矩阵
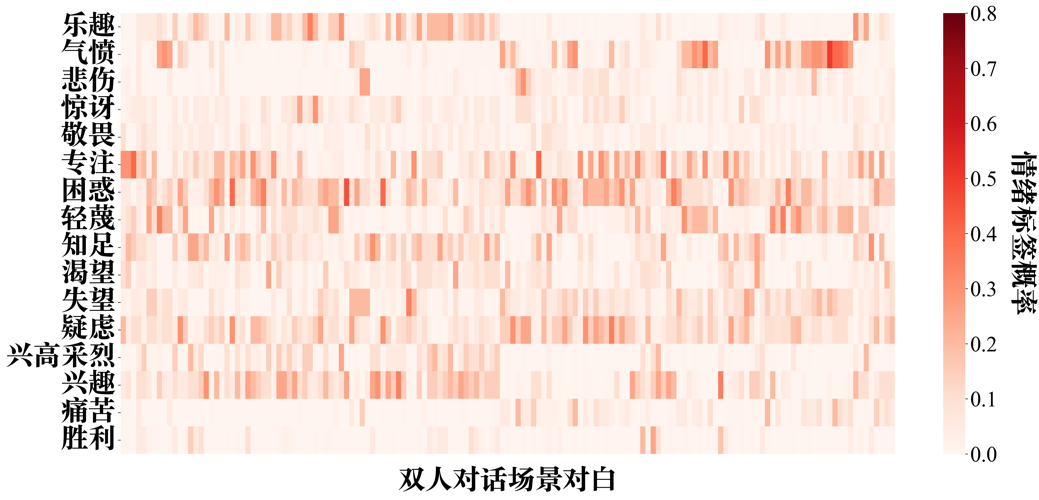
附图S9 GPT-4-vision zero-shot情绪识别的情绪标签-双人对话场景概率分布矩阵
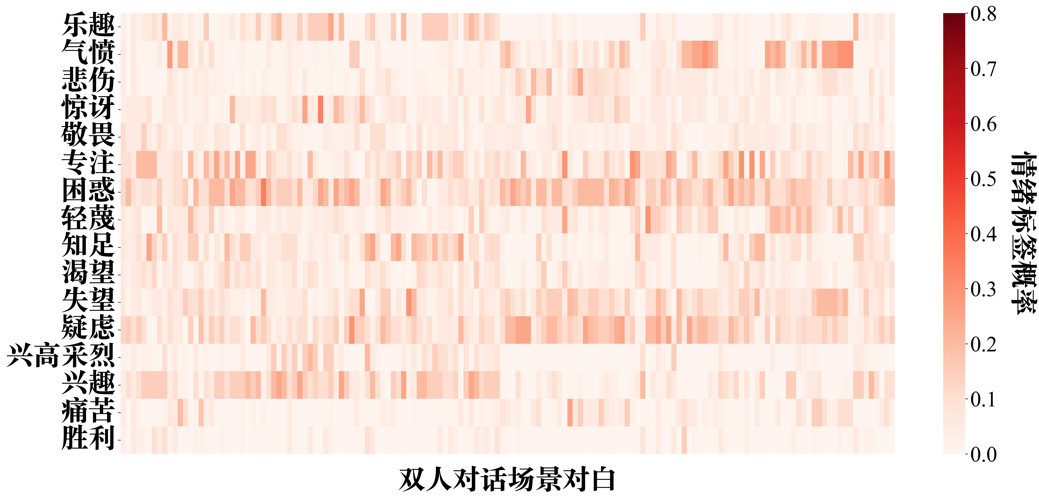
附图S10 GPT-4-vision zero-shot情绪推理的情绪标签-双人对话场景概率分布矩阵
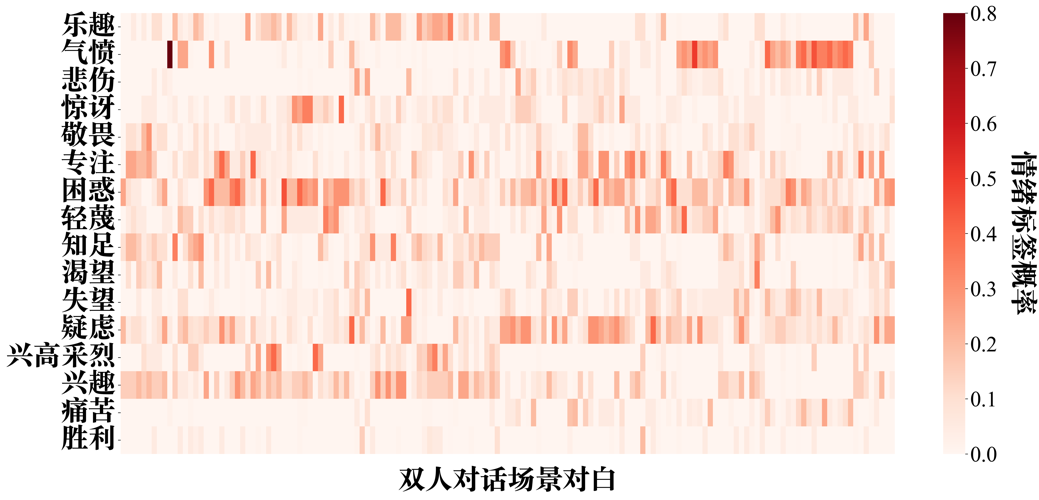
附图S11 GPT-4-turbo zero-shot情绪识别的情绪标签-双人对话场景概率分布矩阵
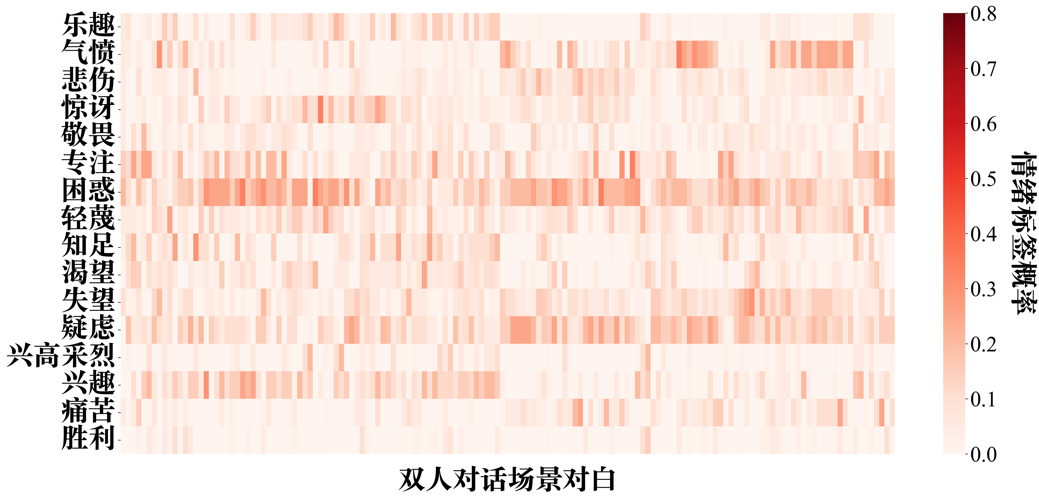
附图S12 GPT-4-turbo zero-shot情绪推理的情绪标签-双人对话场景概率分布矩阵
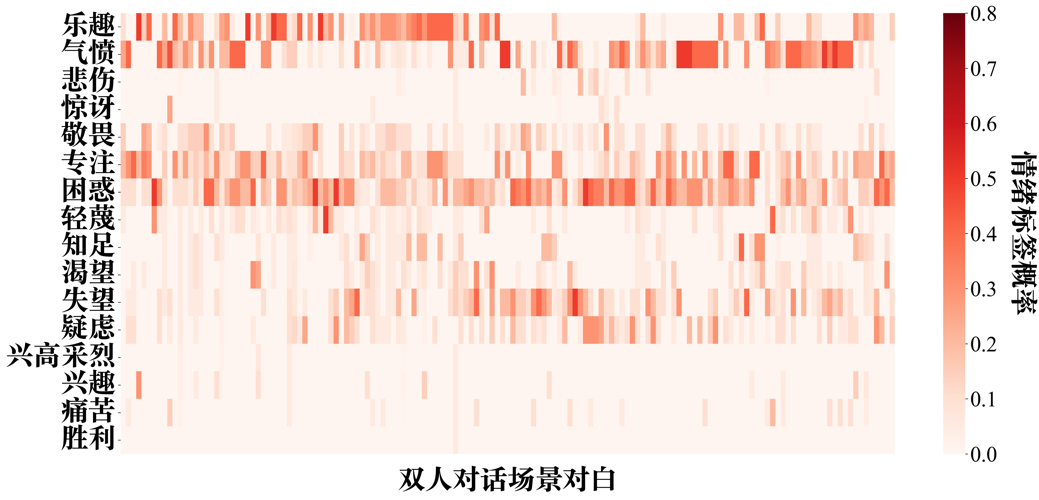
附图S13 Claude-3-haiku zero-shot情绪识别的情绪标签-双人对话场景概率分布矩阵
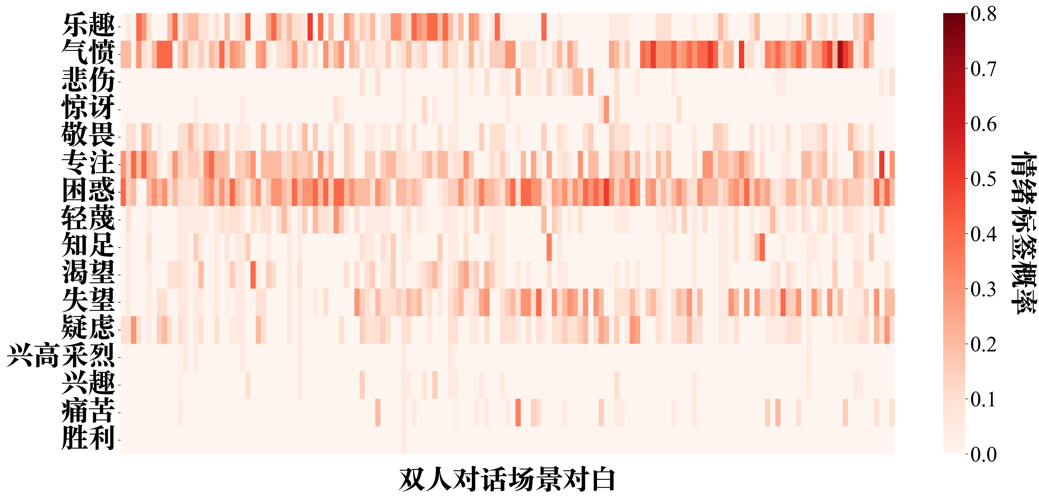
附图S14 Claude-3-haiku zero-shot情绪推理的情绪标签-双人对话场景概率分布矩阵
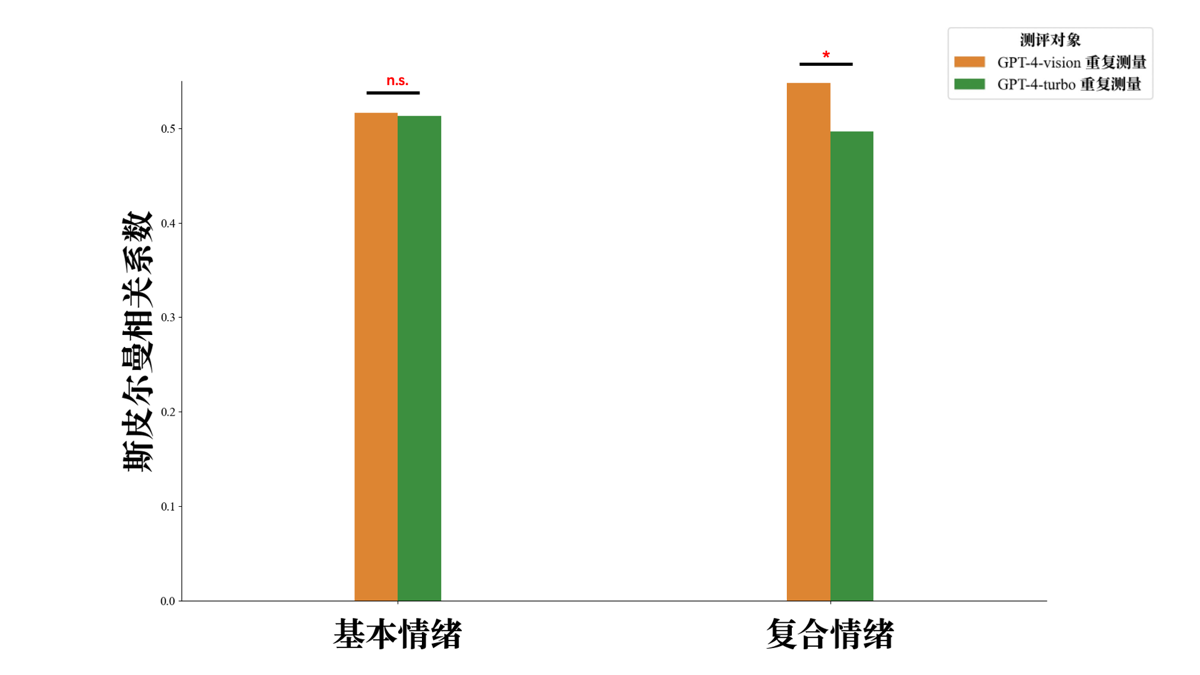
附图S15 多模态大语言模型重复测量情绪识别斯皮尔曼相关分析与对比 注:n.s. p > 0.05; *p < 0.05
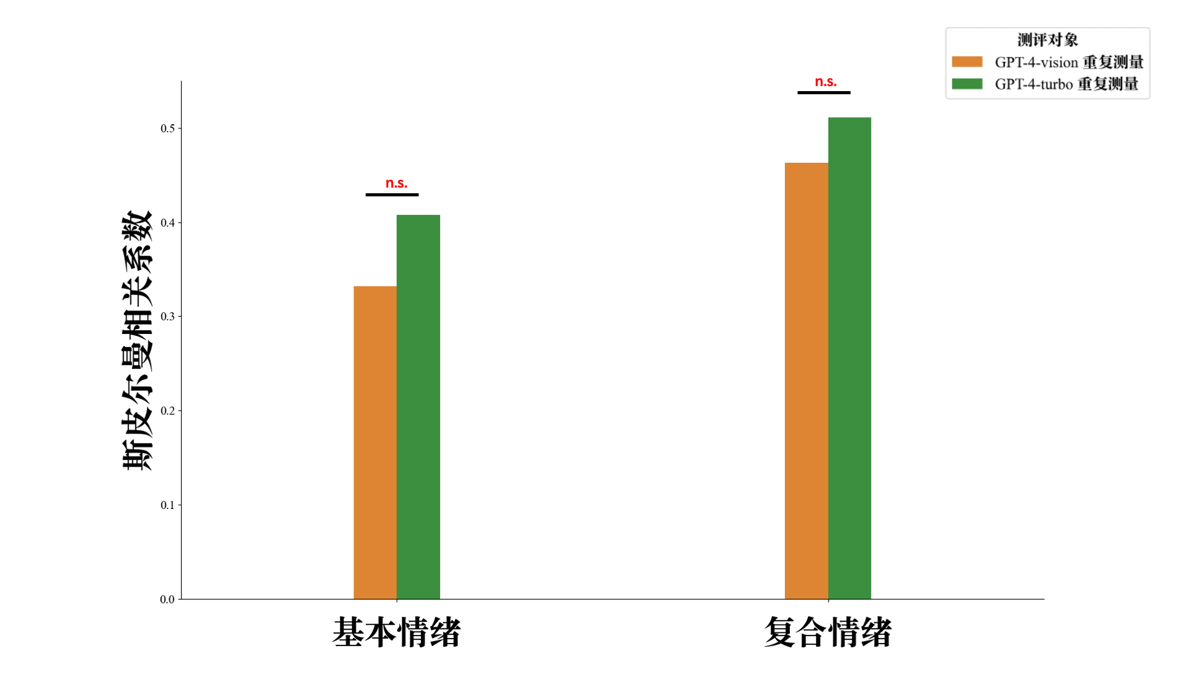
附图S16 多模态大语言模型重复测量情绪推理斯皮尔曼相关分析与对比 注:n.s. p > 0.05
| [1] |
Barrett, L. F. (2006). Are emotions natural kinds? Perspectives on Psychological Science, 1(1), 28-58.
doi: 10.1111/j.1745-6916.2006.00003.x pmid: 26151184 |
| [2] | Barrett, L. F., Mesquita, B., & Gendron, M. (2011). Context in emotion perception. Current Directions in Psychological Science, 20(5), 286-290. |
| [3] | Buck, R. (1985). Prime theory: An integrated view of motivation and emotion. Psychological Review, 92(3), 389-413. |
| [4] | Busso, C., Bulut, M., Lee, C. C., Kazemzadeh, A., Mower, E., Kim, S.,... Narayanan, S. S. (2008). IEMOCAP: Interactive emotional dyadic motion capture database. Language Resources and Evaluation, 42, 335-359. |
| [5] | Clark, H. H., & Schaefer, E. F. (1989). Contributing to discourse. Cognitive Science, 13(2), 259-294. |
| [6] |
Cordaro, D. T., Sun, R., Kamble, S., Hodder, N., Monroy, M., Cowen, A.,... Keltner, D. (2020). The recognition of 18 facial-bodily expressions across nine cultures. Emotion, 20(7), 1292-1300.
doi: 10.1037/emo0000576 pmid: 31180692 |
| [7] |
Cordaro, D. T., Sun, R., Keltner, D., Kamble, S., Huddar, N., & McNeil, G. (2018). Universals and cultural variations in 22 emotional expressions across five cultures. Emotion, 18(1), 75-93.
doi: 10.1037/emo0000302 pmid: 28604039 |
| [8] |
Cowen, A. S., & Keltner, D. (2020). What the face displays: Mapping 28 emotions conveyed by naturalistic expression. American Psychologist, 75(3), 349-364.
doi: 10.1037/amp0000488 pmid: 31204816 |
| [9] | Cowen, A. S., Keltner, D., Schroff, F., Jou, B., Adam, H., & Prasad, G. (2021). Sixteen facial expressions occur in similar contexts worldwide. Nature, 589(7841), 251-257. |
| [10] |
Cowen, A. S., Laukka, P., Elfenbein, H. A., Liu, R., & Keltner, D. (2019). The primacy of categories in the recognition of 12 emotions in speech prosody across two cultures. Nature Human Behaviour, 3(4), 369-382.
doi: 10.1038/s41562-019-0533-6 pmid: 30971794 |
| [11] | De Gelder, B., & Vroomen, J. (2000). The perception of emotions by ear and by eye. Cognition & Emotion, 14(3), 289-311. |
| [12] | Ekman, P. (1992). An argument for basic emotions. Cognition & Emotion, 6(3-4), 169-200. |
| [13] |
Ekman, P. (1993). Facial expression and emotion. American Psychologist, 48(4), 384-392.
pmid: 8512154 |
| [14] | Ekman, P., & Friesen, W. V. (1978). Facial Action Coding System (FACS) [Database record]. APA PsycTests. |
| [15] | Ekman, P., & Friesen, W. V. (2003). Unmasking the face: A guide to recognizing emotions from facial clues (Vol. 10). Ishk. |
| [16] | Fayek, H. M., Lech, M., & Cavedon, L. (2016). Modeling subjectiveness in emotion recognition with deep neural networks: Ensembles vs soft labels. In 2016 International Joint Conference on Neural Networks (IJCNN) (pp. 566-570). IEEE. |
| [17] | Ghosal, D., Majumder, N., Poria, S., Chhaya, N., & Gelbukh, A. (2019). Dialoguegcn: A graph convolutional neural network for emotion recognition in conversation. arXiv preprint arXiv:1908.11540. |
| [18] | Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press. |
| [19] | Gross, J. J. (2015). Emotion regulation: Current status and future prospects. Psychological Inquiry, 26(1), 1-26. |
| [20] | Kosti, R., Alvarez, J. M., Recasens, A., & Lapedriza, A. (2017). Emotion recognition in context. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1667-1675). IEEE. |
| [21] | Lazarus, R. S. (1991). Emotion and adaptation. Oxford University Press. |
| [22] | Li, S., & Deng, W. (2020). Deep facial expression recognition: A survey. IEEE Transactions on Affective Computing, 13(3), 1195-1215. |
| [23] |
Lindquist, K. A., Barrett, L. F., Bliss-Moreau, E., & Russell, J. A. (2006). Language and the perception of emotion. Emotion, 6(1), 125-138.
pmid: 16637756 |
| [24] |
Matsumoto, D., Yoo, S. H., & Nakagawa, S. (2008). Culture, emotion regulation, and adjustment. Journal of Personality and Social Psychology, 94(6), 925-937.
doi: 10.1037/0022-3514.94.6.925 pmid: 18505309 |
| [25] | McGurk, H., & MacDonald, J. (1976). Hearing lips and seeing voices. Nature, 264(5588), 746-748. |
| [26] | Mehrabian, A. (2017). Nonverbal communication. New York: Routledge. |
| [27] | Plutchik,, R. (1980). A general psychoevolutionary theory of emotion. In R.Plutchik & H.Kellerman (Eds.), Theories of emotion (pp. 3-33). Academic Press. |
| [28] | Pollmann, M. M., & Finkenauer, C. (2009). Empathic forecasting: How do we predict other people's feelings? Cognition and Emotion, 23(5), 978-1001. |
| [29] | Poria, S., Cambria, E., Bajpai, R., & Hussain, A. (2017). A review of affective computing: From unimodal analysis to multimodal fusion. Information Fusion, 37, 98-125. |
| [30] |
Russell, J. A. (2003). Core affect and the psychological construction of emotion. Psychological Review, 110(1), 145-172.
doi: 10.1037/0033-295x.110.1.145 pmid: 12529060 |
| [31] |
Schilbach, L., Timmermans, B., Reddy, V., Costall, A., Bente, G., Schlicht, T., & Vogeley, K. (2013). Toward a second- person neuroscience. Behavioral and Brain Sciences, 36(4), 393-414.
doi: 10.1017/S0140525X12000660 pmid: 23883742 |
| [32] | Sridhar, K., Lin, W. C., & Busso, C. (2021). Generative approach using soft-labels to learn uncertainty in predicting emotional attributes. In2021 9th International Conference on Affective Computing and Intelligent Interaction (ACII) (pp. 1-8). IEEE. |
| [33] |
Strack, F., & Deutsch, R. (2004). Reflective and impulsive determinants of social behavior. Personality and Social Psychology Review, 8(3), 220-247.
doi: 10.1207/s15327957pspr0803_1 pmid: 15454347 |
| [34] | Su, P. H., Gasic, M., Mrksic, N., Rojas-Barahona, L., Ultes, S., Vandyke, D.,... Young, S.(2016). On-line active reward learning for policy optimisation in spoken dialogue systems. arXiv preprint arXiv:1605.07669. |
| [35] | Van Kleef, G. A., & Côté, S. (2022). The social effects of emotions. Annual Review of Psychology, 73, 629-658. |
| [36] | Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N.,... Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 6000-6010. |
| [37] | Vinciarelli, A., Pantic, M., & Bourlard, H. (2009). Social signal processing: Survey of an emerging domain. Image and Vision Computing, 27(12), 1743-1759. |
| [38] | Wang, W., Zheng, V. W., Yu, H., & Miao, C. (2019). A survey of zero-shot learning: Settings, methods, and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2), 1-37. |
| [39] | Zhang, D., Yu, Y., Dong, J., Li, C., Su, D., Chu, C., & Yu, D. (2024). Mm-llms: Recent advances in multimodal large language models. arXiv preprint arXiv:2401.13601. |
| [40] | Zhao, S., Yao, X., Yang, J., Jia, G., Ding, G., & Chua, T. S. (2021). Affective image content analysis: Two decades review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10), 6729-6751. |
| [1] | 王永跃, 王静, 刘军, 金杨华. 辱虐管理变化的动态前因:一个潜变化分数模型[J]. 心理学报, 2025, 57(3): 479-494. |
| [2] | 王伟晗, 曹斐臻, 余林伟, 曾珂, 杨鑫超, 徐强. 群体信息对面部表情识别的影响[J]. 心理学报, 2024, 56(3): 268-280. |
| [3] | 杨集梅, 柴洁余, 邱天龙, 全小山, 郑茂平. 共情与中国民族音乐情绪识别的关系:来自ERP的证据[J]. 心理学报, 2022, 54(10): 1181-1192. |
| [4] | 金心怡, 周冰欣, 孟斐. 3岁幼儿的二级观点采择及合作互动的影响[J]. 心理学报, 2019, 51(9): 1028-1039. |
| [5] | 黄辛隐,张,琰,陈延伟,河林弥志,徐爱兵. 交互进化计算对焦虑测量的适用性探析[J]. 心理学报, 2010, 42(05): 625-632. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||