ISSN 0439-755X
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
心理学报 ›› 2024, Vol. 56 ›› Issue (6): 831-844.doi: 10.3724/SP.J.1041.2024.00831 cstr: 32110.14.2024.00831
• 研究报告 • 上一篇
徐静1, 骆方1, 马彦珍2, 胡路明3, 田雪涛1( )
)
收稿日期:2022-10-22
发布日期:2024-04-08
出版日期:2024-06-25
通讯作者:
田雪涛, E-mail: xttian@bnu.edu.cn基金资助:
XU Jing1, LUO Fang1, MA Yanzhen2, HU Luming3, TIAN Xuetao1()
Received:2022-10-22
Online:2024-04-08
Published:2024-06-25
摘要:
受限于评分成本, 开放式情境判断测验难以广泛使用。本研究以教师胜任力测评为例, 探索了自动化评分的应用。针对教学中的典型问题场景开发了开放式情境判断测验, 收集中小学教师作答文本, 采用有监督学习策略分别从文档层面和句子层面应用深度神经网络识别作答类别, 卷积神经网络(Convolutional Neural Network, CNN)效果理想, 各题评分准确率为70%~88%, 与人类评分一致性高, 人机评分的相关系数r为0.95, 二次加权Kappa系数(Quadratic Weighted Kappa, QWK)为0.82。结果表明, 机器评分可以获得稳定的效果, 自动化评分研究能够助力于开放式情境判断测验的广泛应用。
中图分类号:
徐静, 骆方, 马彦珍, 胡路明, 田雪涛. (2024). 开放式情境判断测验的自动化评分. 心理学报, 56(6), 831-844.
XU Jing, LUO Fang, MA Yanzhen, HU Luming, TIAN Xuetao. (2024). Automated scoring of open-ended situational judgment tests. Acta Psychologica Sinica, 56(6), 831-844.
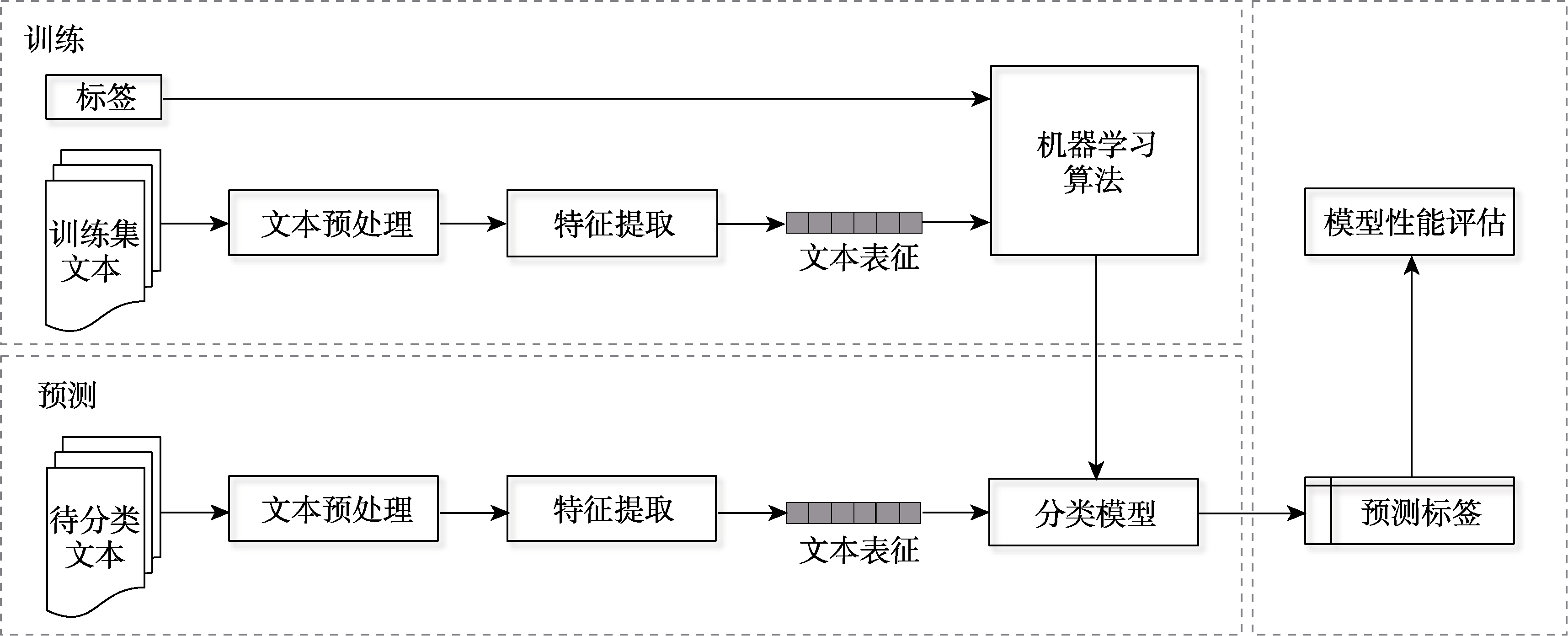
图1 有监督的文本分类流程图
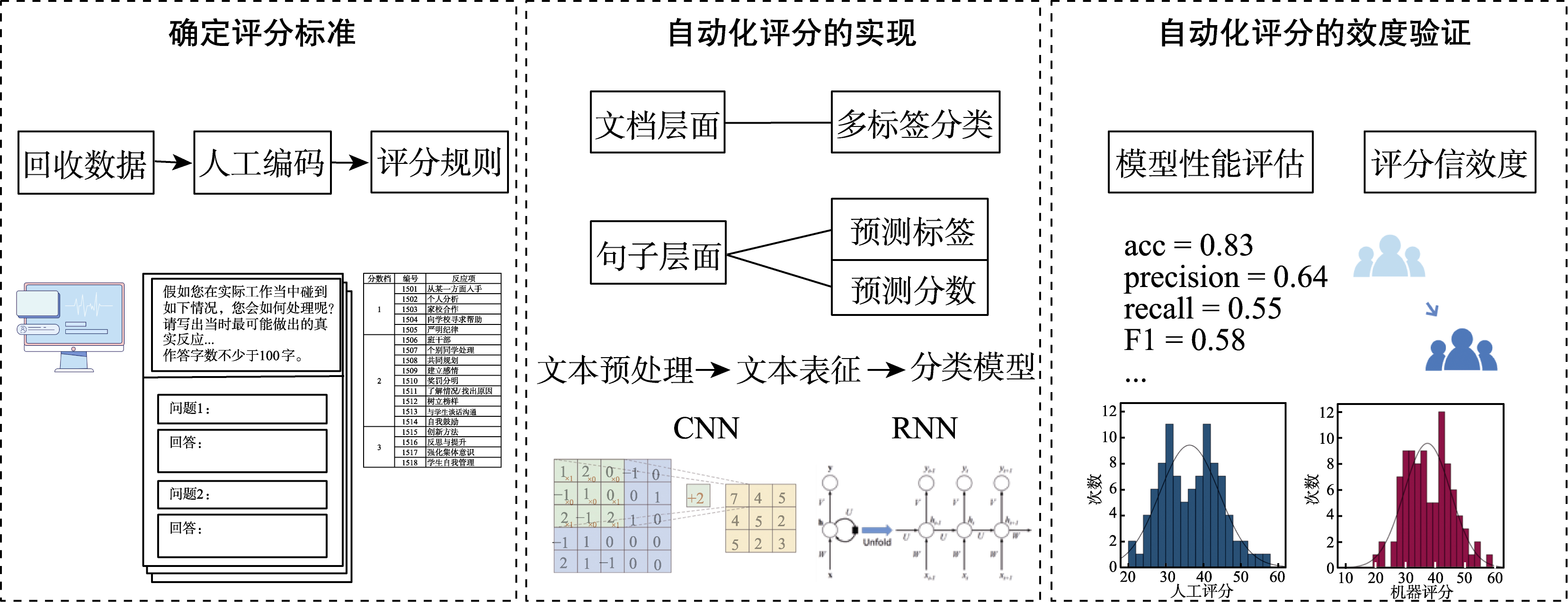
图2 开放式情境判断测验文本自动化评分流程图
| 预测正例 | 预测反例 | |
|---|---|---|
| 实际正例 | TP真正例 | FN假负例 |
| 实际反例 | FP假正例 | TN真负例 |
表1 二分类的混淆矩阵表
| 预测正例 | 预测反例 | |
|---|---|---|
| 实际正例 | TP真正例 | FN假负例 |
| 实际反例 | FP假正例 | TN真负例 |
| 模型 | χ2 | df | χ2/df | CFI | TLI | SRMR | RMSEA |
|---|---|---|---|---|---|---|---|
| M1 | 264.34 | 170 | 1.56 | 0.947 | 0.941 | 0.042 | 0.043 |
| M2 | 256.12 | 164 | 1.56 | 0.948 | 0.940 | 0.041 | 0.044 |
| M3 | 226.59 | 190 | 1.19 | 0.957 | 0.946 | 0.038 | 0.042 |
| M4 | 179.58 | 144 | 1.25 | 0.980 | 0.974 | 0.033 | 0.029 |
表2 教师胜任力情境判断测验的验证性因子分析(n = 290)
| 模型 | χ2 | df | χ2/df | CFI | TLI | SRMR | RMSEA |
|---|---|---|---|---|---|---|---|
| M1 | 264.34 | 170 | 1.56 | 0.947 | 0.941 | 0.042 | 0.043 |
| M2 | 256.12 | 164 | 1.56 | 0.948 | 0.940 | 0.041 | 0.044 |
| M3 | 226.59 | 190 | 1.19 | 0.957 | 0.946 | 0.038 | 0.042 |
| M4 | 179.58 | 144 | 1.25 | 0.980 | 0.974 | 0.033 | 0.029 |
| 变量 | M ± SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| n = 290 | |||||||||
| 1总分 | 37.77 ± 8.17 | 1 | |||||||
| 2 学生导向 | 1.89 ± 0.46 | 0.89*** | 1 | ||||||
| 3 问题解决 | 1.87 ± 0.48 | 0.87*** | 0.68*** | 1 | |||||
| 4 情绪智力 | 1.91 ± 0.50 | 0.78*** | 0.58*** | 0.55*** | 1 | ||||
| 5 成就动机 | 1.89 ± 0.54 | 0.75*** | 0.55*** | 0.58*** | 0.54*** | 1 | |||
| 6 工作满意度 | 3.88 ± 0.29 | 0.20** | 0.22*** | 0.14* | 0.15* | 0.13* | 1 | ||
| 7 公用教学理念 | 4.58 ±0.41 | 0.21*** | 0.18** | 0.15* | 0.20*** | 0.18** | 0.45*** | 1 | |
| 8 学科教学理念 | 3.58 ±0.49 | 0.22*** | 0.21** | 0.18** | 0.13* | 0.20** | 0.33*** | 0.50*** | 1 |
| n = 181 | |||||||||
| 1总分 | 38.95 ± 8.30 | 1 | |||||||
| 2 学生导向 | 1.92 ± 0.49 | 0.87*** | 1 | ||||||
| 3 问题解决 | 1.96 ± 0.47 | 0.88*** | 0.68*** | 1 | |||||
| 4 情绪智力 | 1.95 ± 0.52 | 0.76*** | 0.53*** | 0.54*** | 1 | ||||
| 5 成就动机 | 1.97 ± 0.61 | 0.71*** | 0.52*** | 0.55*** | 0.49*** | 1 | |||
| 6 教学设计 | 2.60 ± 0.31 | 0.26*** | 0.24** | 0.27*** | 0.16* | 0.18* | 1 | ||
| 7 课堂视频 | 2.54 ± 0.32 | 0.20** | 0.21** | 0.17* | 0.10 | 0.13 | 0.61*** | 1 | |
| 8 学生作业 | 2.52 ± 0.44 | 0.22** | 0.18* | 0.22** | 0.18* | 0.16* | 0.43*** | 0.39*** | 1 |
表3 教师胜任力总分及其维度与效标变量的相关分析表
| 变量 | M ± SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| n = 290 | |||||||||
| 1总分 | 37.77 ± 8.17 | 1 | |||||||
| 2 学生导向 | 1.89 ± 0.46 | 0.89*** | 1 | ||||||
| 3 问题解决 | 1.87 ± 0.48 | 0.87*** | 0.68*** | 1 | |||||
| 4 情绪智力 | 1.91 ± 0.50 | 0.78*** | 0.58*** | 0.55*** | 1 | ||||
| 5 成就动机 | 1.89 ± 0.54 | 0.75*** | 0.55*** | 0.58*** | 0.54*** | 1 | |||
| 6 工作满意度 | 3.88 ± 0.29 | 0.20** | 0.22*** | 0.14* | 0.15* | 0.13* | 1 | ||
| 7 公用教学理念 | 4.58 ±0.41 | 0.21*** | 0.18** | 0.15* | 0.20*** | 0.18** | 0.45*** | 1 | |
| 8 学科教学理念 | 3.58 ±0.49 | 0.22*** | 0.21** | 0.18** | 0.13* | 0.20** | 0.33*** | 0.50*** | 1 |
| n = 181 | |||||||||
| 1总分 | 38.95 ± 8.30 | 1 | |||||||
| 2 学生导向 | 1.92 ± 0.49 | 0.87*** | 1 | ||||||
| 3 问题解决 | 1.96 ± 0.47 | 0.88*** | 0.68*** | 1 | |||||
| 4 情绪智力 | 1.95 ± 0.52 | 0.76*** | 0.53*** | 0.54*** | 1 | ||||
| 5 成就动机 | 1.97 ± 0.61 | 0.71*** | 0.52*** | 0.55*** | 0.49*** | 1 | |||
| 6 教学设计 | 2.60 ± 0.31 | 0.26*** | 0.24** | 0.27*** | 0.16* | 0.18* | 1 | ||
| 7 课堂视频 | 2.54 ± 0.32 | 0.20** | 0.21** | 0.17* | 0.10 | 0.13 | 0.61*** | 1 | |
| 8 学生作业 | 2.52 ± 0.44 | 0.22** | 0.18* | 0.22** | 0.18* | 0.16* | 0.43*** | 0.39*** | 1 |
| 模型 | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| CNN | 0.46 | 0.51 | 0.25 | 0.58 |
| RNN | 0.51 | 0.56 | 0.36 | 0.59 |
| R-CNN | 0.55 | 0.71 | 0.36 | 0.67 |
| RNN+Attention | 0.48 | 0.60 | 0.35 | 0.60 |
表4 文档层面多标签文本分类的模型实验结果对比表
| 模型 | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| CNN | 0.46 | 0.51 | 0.25 | 0.58 |
| RNN | 0.51 | 0.56 | 0.36 | 0.59 |
| R-CNN | 0.55 | 0.71 | 0.36 | 0.67 |
| RNN+Attention | 0.48 | 0.60 | 0.35 | 0.60 |
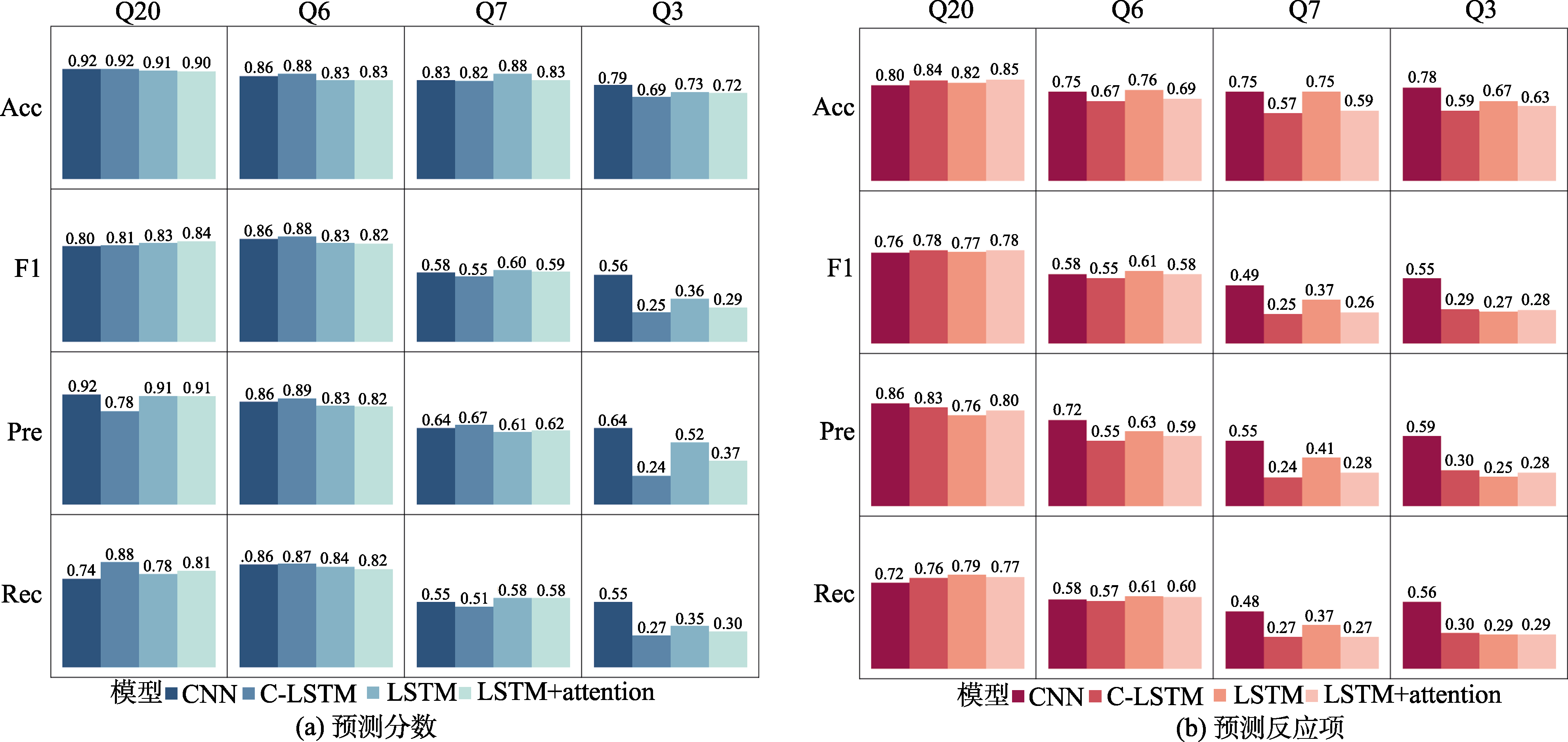
图3 四种模型在4道题目上预测反应项和预测分数任务的结果对比图 注:Acc为准确率(Accuracy); F1为F1-score; Pre为精确率(Precision); Rec为召回率(Recall), 下同。

图4 CNN在20道题上的结果图

图5 人工评分与机器评分总分的分数频率分布图
| 变量 | M ± SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 1机评总分 | 37.23 ± 7.83 | 1 | |||||||
| 2机评学生导向 | 1.89 ± 0.44 | 0.90*** | 1 | ||||||
| 3机评问题解决 | 1.84 ± 0.47 | 0.88*** | 0.69*** | 1 | |||||
| 4机评情绪智力 | 1.87 ± 0.47 | 0.80*** | 0.63*** | 0.58*** | 1 | ||||
| 5机评成就动机 | 1.82 ± 0.53 | 0.72*** | 0.53*** | 0.54*** | 0.51*** | 1 | |||
| 6公用教学理念 | 3.85 ± 0.27 | 0.22* | 0.11 | 0.22* | 0.24* | 0.19 | 1 | ||
| 7学科教学理念 | 4.28 ± 0.39 | 0.21 | 0.17 | 0.27* | 0.19 | 0.01 | 0.63*** | 1 | |
| 8工作满意度 | 3.65 ± 0.58 | 0.13 | 0.15 | 0.09 | 0.10 | 0.08 | 0.32** | 0.44*** | 1 |
表5 机器评分的描述性统计和相关分析表(n = 94)
| 变量 | M ± SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 1机评总分 | 37.23 ± 7.83 | 1 | |||||||
| 2机评学生导向 | 1.89 ± 0.44 | 0.90*** | 1 | ||||||
| 3机评问题解决 | 1.84 ± 0.47 | 0.88*** | 0.69*** | 1 | |||||
| 4机评情绪智力 | 1.87 ± 0.47 | 0.80*** | 0.63*** | 0.58*** | 1 | ||||
| 5机评成就动机 | 1.82 ± 0.53 | 0.72*** | 0.53*** | 0.54*** | 0.51*** | 1 | |||
| 6公用教学理念 | 3.85 ± 0.27 | 0.22* | 0.11 | 0.22* | 0.24* | 0.19 | 1 | ||
| 7学科教学理念 | 4.28 ± 0.39 | 0.21 | 0.17 | 0.27* | 0.19 | 0.01 | 0.63*** | 1 | |
| 8工作满意度 | 3.65 ± 0.58 | 0.13 | 0.15 | 0.09 | 0.10 | 0.08 | 0.32** | 0.44*** | 1 |
| [1] | Arthur, W., Edwards, B. D., & Barrett, G. V. (2002). Multiple- choice and constructed response tests of ability: Race-based subgroup performance differences on alternative paper- and-pencil test formats. Personnel Psychology, 55(4), 985-1008. |
| [2] | Bacon, D. R. (2003). Assessing learning outcomes: A comparison of multiple-choice and short-answer questions in a marketing context. Jounal of Marketing Education, 25(1), 31-36. |
| [3] | Basu, T., & Murthy, C. A. (2013, December). Effective text classification by a supervised feature selection approach. IEEE 12th International Conference on Data Mining Workshops (ICDM) (pp. 918-925). Brussels, Belgium. |
| [4] | Burrows, S., Gurevych, I., & Stein, B. (2015). The eras and trends of automatic short answer grading. International Journal of Artificial Intelligence in Education, 25(1), 60-117. |
| [5] | Burrus, J., Betancourt, A., Holtzman, S., Minsky, J., MacCann, C., & Roberts, R. D. (2012). Emotional intelligence relates to well-being: Evidence from the situational judgment test of emotional management. Applied Psychology: Health and Well-Being, 4(2), 151-166. |
| [6] | Cucina, J. M., Su, C., Busciglio, H. H., Thomas, P. H., & Peyton, S. T. (2015). Video-based testing: A high-fidelity job simulation that demonstrates reliability, validity, and utility. International Journal of Selection and Assessment, 23(3), 197-209. |
| [7] | Downer, K., Wells, C., & Crichton, C. (2019). All work and no play: A text analysis. International Journal of Market Research, 61(3), 236-251. |
| [8] |
Edwards, B. D., & Arthur, W.,Jr. (2007). An examination of factors contributing to a reduction in subgroup differences on a constructed-response paper-and-pencil test of scholastic achievement. Journal of Applied Psychology, 92(3), 794-801.
pmid: 17484558 |
| [9] | Finch, W. H., Finch, M. E. H., Mcintosh, C. E., & Braun, C. (2018). The use of topic modeling with latent dirichlet analysis with open-ended survey items. Translational Issues in Psychological Science, 4(4), 403-424. |
| [10] | Funke, U., & Schuler, H. (1998). Validity of stimulus and response components in a video test of social competence. International Journal of Selection and Assessment, 6(2), 115-123. |
| [11] | Gu, H. L., & Wen, Z. L. (2017). Reporting and interpreting multidimensional test scores: A bi-factor perspective. Psychological Development and Education, 33(4), 504-512. |
| [顾红磊, 温忠麟. (2017). 多维测验分数的报告与解释: 基于双因子模型的视角. 心理发展与教育, 33(4), 504-512.] | |
| [12] | Guo, F., Gallagher, C. M., Sun, T., Tavoosi, S., & Min, H. (2021). Smarter people analytics with organizational text data: Demonstrations using classic and advanced NLP models. Human Resource Management Journal. https://doi.org/10.1111/1748-8583.12426 |
| [13] | Iliev, R., Dehghani, M., & Sagi, E. (2015). Automated text analysis in psychology: Methods, applications, and future developments. Language and Cognition, 7(2), 265-290. |
| [14] | Kastner, M., & Stangla, B. (2011). Multiple choice and constructed response tests: Do test format and scoring matter? Procedia-Social and Behavioral Sciences. 12, 263-273. |
| [15] | Kim, Y. (2014). Convolutional neural networks for sentence classification. Proceedings of the 19th Conference on Empirical Methods in Natural Language Processing, 1746-1751. |
| [16] |
Kjell, O. E., Kjell, K., Garcia, D., & Sikstrom, S. (2019). Semantic measures: Using natural language processing to measure, differentiate, and describe psychological constructs. Psychological Methods, 24(1), 92-115.
doi: 10.1037/met0000191 pmid: 29963879 |
| [17] | Lai, S., Xu, L., Liu, K., & Zhao, J. (2015). Recurrent convolutional neural networks for text classification. Proceedings of the 29th AAAI Conference on Artificial Intelligence, 2267-2273. |
| [18] | Lee, B. C., & Kim, B. Y. (2021). Development of an AI-based interview system for remote hiring. International Journal of Advanced Research in Engineering and Technology, 12(3), 654-663. |
| [19] | Lievens, F., de Corte, W., & Westerveld, L. (2015). Understanding the building blocks of selection procedures: Effects of response fidelity on performance and validity. Journal of Management, 41(6), 1604-1627. |
| [20] |
Lievens, F., Sackett, P. R., Dahlke, J. A., Oostrom, J. K., & de Soete, B. (2019). Constructed response formats and their effects on minority-majority differences and validity. Journal of Applied Psychology, 104(5), 715-726.
doi: 10.1037/apl0000367 pmid: 30431296 |
| [21] | Ling, C. (2020). Development of Classroom Observation Scale to Promote the Professional Development of New Teachers (Unpublished master's thesis). Beijing Normal University. |
| [凌晨. (2020). 课堂观察量表的开发——促进初任教师专业发展 (硕士学位论文). 北京师范大学.] | |
| [22] | Lubis, F. F., Mutaqin, Putri, A., Waskita, D., Sulistyaningtyas, T., Arman, A. A., & Rosmansyah, Y. (2021). Automated short-answer grading using semantic similarity based on word embedding. International Journal of Technology. 12(3), 571-581. |
| [23] | Marentette, B. J., Meyers, L. S., Hurtz, G. M., & Kuang, D. C. (2012). Order effects on situational judgment test items: A case of construct-irrelevant difficulty. International Journal of Selection and Assessment, 20(3), 319-332. |
| [24] | McDaniel, M. A., Hartman, N. S., Whetzel, D. L., & Grubb, W. L. (2007). Situational judgment tests, response instructions, and validity: A meta‐analysis. Personnel Psychology, 60(1), 63-91. |
| [25] |
McDaniel, M. A., Morgeson, F. P., Finnegan, E. B., Campion, M. A., & Braverman, E. P. (2001). Use of situational judgment tests to predict job performance: A clarification of the literature. Journal of Applied Psychology, 86(4), 730-740.
pmid: 11519656 |
| [26] |
McDaniel, M. A., Psotka, J., Legree, P. J., Yost, A. P., & Weekley, J. A. (2011). Toward an understanding of situational judgment item validity and group differences. Journal of Applied Psychology, 96(2), 327-336.
doi: 10.1037/a0021983 pmid: 21261409 |
| [27] | Oostrom, J. K., Born, M. P., Serlie, A. W., & van der Molen, H. T. (2010). Webcam testing: Validation of an innovative open-ended multimedia test. European Journal of Work and Organizational Psychology, 19(5), 532-550. |
| [28] | Oostrom, J. K., Born, M. P., Serlie, A. W., & van der Molen, H. T. (2011). A multimedia situational test with a constructed-response format: Its relationship with personality, cognitive ability, job experience, and academic performance. Journal of Personnel Psychology, 10(2), 78-88. |
| [29] | Oostrom, J. K., Born, M. P., Serlie, A. W., & van der Molen, H. T. (2012). Implicit trait policies in multimedia situational judgment tests for leadership skills: Can they predict leadership behavior? Human Performance, 25(4), 335-353. |
| [30] | Pang, N., Zhao, X., Wang, W., Xiao, W., & Guo, D. (2021). Few-shot text classification by leveraging bi-directional attention and cross-class knowledge. Science China Information Sciences. 64(3), 130103. |
| [31] | Qi, S. Q., & Dai, H. Q. (2003). The property, function and the development of situational judgment tests. Psychological Exploration, 23(4), 42-46. |
| [漆书青, 戴海琦. (2003). 情景判断测验的性质、功能与开发编制. 心理学探新, 23(4), 42-46.] | |
| [32] | Ramesh, D., & Sanampudi, S. K. (2022). An automated essay scoring systems: A systematic literature review. Artificial Intelligence Review, 55(3), 2495-2527. |
| [33] | Ramineni, C., Trapani, C. S., Williamson, D. M., David, T., & Bridgeman, B. (2012). Evaluation of the e-rater® scoring engine for the GRE® Issue and Argument Prompts. ETS Research Report Series, (1), i-106. |
| [34] | Robson, S. M., Jones, A., & Abraham, J. (2007). Personality, faking, and convergent validity: A warning concerning warning statements. Human Performance, 21(1), 89-106. |
| [35] | Rogers, W. T., & Harley, D. (1999). An empirical comparison of three-and four-choice items and tests: Susceptibility to testwiseness and internal consistency reliability. Educational and Psychological Measurement, 59(2), 234-247. |
| [36] | Rudner, L. M., & Liang, T. (2002). Automated essay scoring using Bayes’ theorem. The Journal of Technology, Learning and Assessment, 1(2), 1-22. |
| [37] | Slaughter, J. E., Christian, M. S., Podsakoff, N. P., Sinar, E. F., & Lievens, F. (2014). On the limitations of using situational judgment tests to measure interpersonal skills: The moderating influence of employee anger. Personnel Psychology, 67(4), 847-885. |
| [38] | Süzen, N., Gorban, A. N., Levesley, J., & Mirkes, E. M. (2020). Automatic short answer grading and feed-back using text mining methods. Procedia Computer Science, 169, 726-743. |
| [39] | Tavoosi, S. (2022). Development and validation of a counterproductive work behavior situational judgment test with an open-ended response format: A computerized scoring approach (Unpublished master’s thesis). University of Central Florida. |
| [40] | Wang, Y., & Peng, H. L. (2019). Validation on automatic scoring for open-ended questions in Chinese oral tests. China Examinations, 9, 63-71. |
| [王妍, 彭恒利. (2019). 汉语口语开放性试题计算机自动评分的效度验证. 中国考试, 9, 63-71.] | |
| [41] | Weekley, J. A., & Ployhart, R. E. (2005). Situational judgment: Antecedents and relationships with performance. Human Performance, 18(1), 81-104. |
| [42] | Whetzel, D. L., & McDaniel, M. A. (2009). Situational judgment tests: An overview of current research. Human Resource Management Review, 19(3), 188-202. |
| [43] | Williamson, D. M., Xi, X., & Breyer, F. J. (2012). A framework for evaluation and use of automated scoring. Educational Measurement: Issues and Practice, 31(1), 2-13. |
| [44] | Xie, X. Q. (2013). Validation: From reasonable to plausible interpretation of test score. China Examinations, 7, 3-8. |
| [谢小庆. (2013). 效度: 从分数的合理解释到可接受解释. 中国考试, 7, 3-8.] | |
| [45] | Xu, J. P. (2004). Research on teacher competency model and evaluation (Unpublished doctorial dissertation). Beijing Normal University. |
| [徐建平. (2004). 教师胜任力模型与测评研究 (博士学位论文). 北京师范大学.] | |
| [46] | Yang, L., Xin, T., Luo, F., Zhang, S., & Tian, X. (2022). Automated evaluation of the quality of ideas in compositions based on concept maps. Natural Language Engineering, 28(4), 449-486. |
| [47] | Zhang, Y., Lin, C., & Chi, M. (2020). Going deeper: Automatic short-answer grading by combining student and question models. User Modeling and User-Adapted Interaction, 30(1), 51-80. |
| [48] | Zhao, Y., Shen, Y., & Yao, J. (2019, August). Recurrent neural network for text classification with hierarchical multiscale dense connections. Proceedings of the 28th International Joint Conference on Artificial Intelligence, 5450-5456. |
| [1] | 赵立, 郑怡, 赵均榜, 张芮, 方方, 傅根跃, 李康. 人工智能方法在探究小学生作业作弊行为及其关键预测因子中的应用[J]. 心理学报, 2024, 56(2): 239-254. |
| [2] | 李为, 边子茗, 陈曦梅, 王俊杰, 罗一君, 刘永, 宋诗情, 高笑, 陈红. 9~12岁儿童应激与额颞区的关联: 来自多模态脑影像的证据[J]. 心理学报, 2023, 55(4): 572-587. |
| [3] | 孙芳, 宋巍, 温晓通, 李欢欢, 欧阳李晟, 魏诗洁. 痛苦逃避和自我参照惩罚条件下脑电特征对自杀意念的分类效能[J]. 心理学报, 2022, 54(9): 1031-1047. |
| [4] | 章文佩, 沈群伦, 宋锦涛, 周仁来. 基于事件相关电位(ERPs)和机器学习的考试焦虑诊断 *[J]. 心理学报, 2019, 51(10): 1116-1127. |
| [5] | 孙鑫, 黎坚, 符植煜. 利用游戏log-file预测学生推理能力和数学成绩——机器学习的应用[J]. 心理学报, 2018, 50(7): 761-770. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||