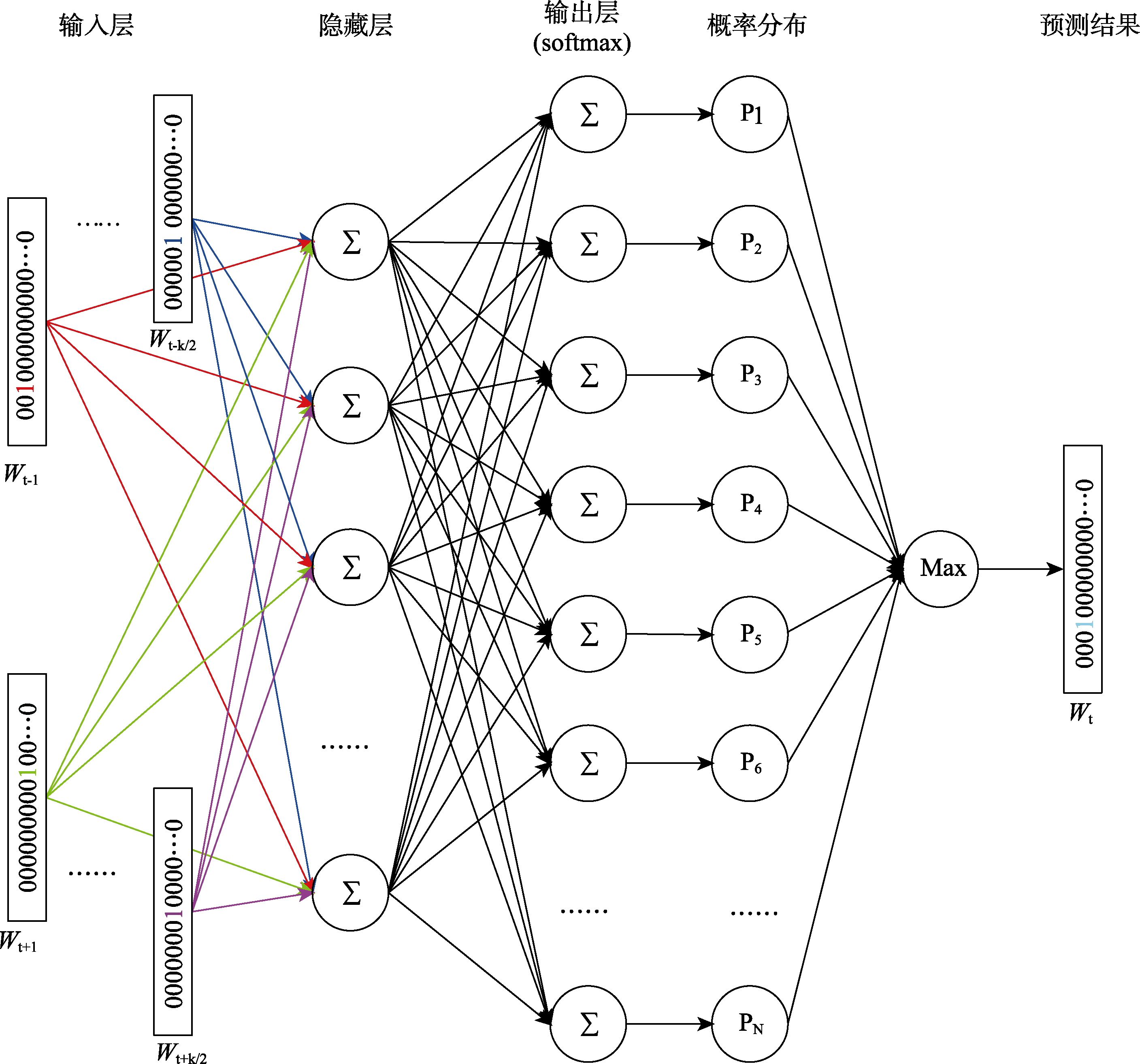
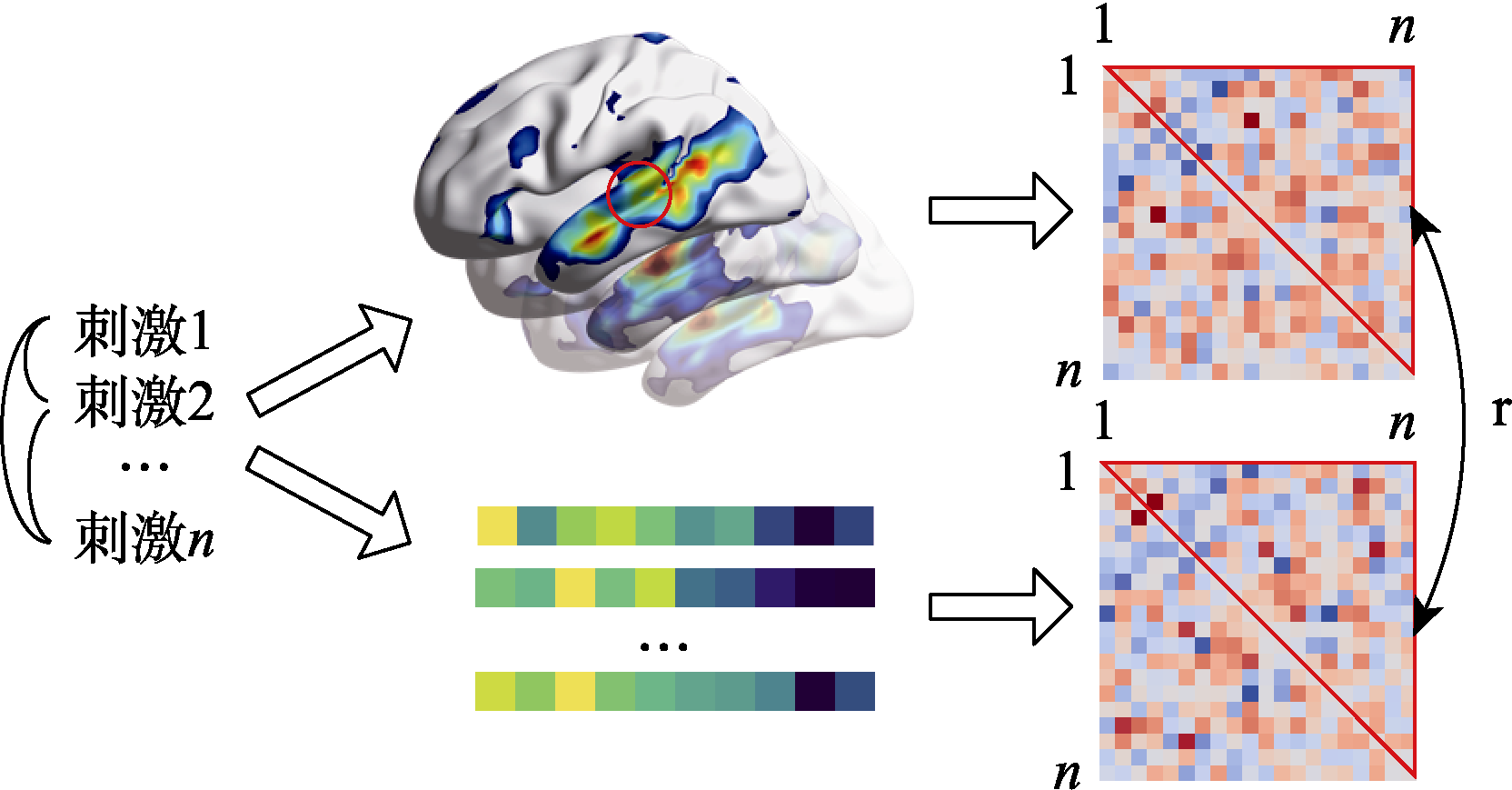
ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
Advances in Psychological Science ›› 2023, Vol. 31 ›› Issue (6): 1002-1019.doi: 10.3724/SP.J.1042.2023.01002
• Regular Articles • Previous Articles Next Articles
JIANG Jiahao1, ZHAO Guoyu2, MA Yingbo1, DING Guosheng3, LIU Lanfang2,4( )
)
Received:2022-11-06
Online:2023-06-15
Published:2023-03-07
Contact:
LIU Lanfang
E-mail:liulanfang21@bnu.edu.cn
CLC Number:
JIANG Jiahao, ZHAO Guoyu, MA Yingbo, DING Guosheng, LIU Lanfang. Distributed representation of semantics in the human brain: Evidence from studies using natural language processing techniques[J]. Advances in Psychological Science, 2023, 31(6): 1002-1019.
| [1] | 王少楠, 丁鼐, 林楠, 张家俊, 宗成庆. (2022a). 语言认知与语言计算——人与机器的语言理解. 中国科学:信息科学, 52(10), 1748-1774. https://doi.org/10.1360/SSI-2021-0100 |
| [2] | 王少楠, 张家俊, 宗成庆. (2022b). 基于语言计算方法的语言认知实验综述. 中文信息学报, 36(4), 1-11. |
| [3] | 赵京胜, 宋梦雪, 高祥, 朱巧明. (2022). 自然语言处理中的文本表示研究. 软件学报, 33(1), 102-128. https://doi.org/10.13328/j.cnki.jos.006304 |
| [4] |
Acunzo, D. J., Low, D. M., & Fairhall, S. L. (2022). Deep neural networks reveal topic-level representations of sentences in medial prefrontal cortex, lateral anterior temporal lobe, precuneus, and angular gyrus. NeuroImage, 251, 119005. https://doi.org/10.1016/j.neuroimage.2022.119005
doi: 10.1016/j.neuroimage.2022.119005 URL |
| [5] |
Anderson, A. J., Kiela, D., Binder, J. R., Fernandino, L., Humphries, C. J., Conant, L. L.,... Lalor, E. C. (2021). Deep artificial neural networks reveal a distributed cortical network encoding propositional sentence-level meaning. Journal of Neuroscience, 41(18), 4100-4119. https://doi.org/10.1523/JNEUROSCI.1152-20.2021
doi: 10.1523/JNEUROSCI.1152-20.2021 URL pmid: 33753548 |
| [6] |
Anderson, A. J., Zinszer, B. D., & Raizada, R. D. S. (2016). Representational similarity encoding for fMRI: Pattern- based synthesis to predict brain activity using stimulus- model-similarities. NeuroImage, 128, 44-53. https://doi.org/10.1016/j.neuroimage.2015.12.035
doi: S1053-8119(15)01148-9 URL pmid: 26732404 |
| [7] |
Batterink, L., & Neville, H. J. (2013). The human brain processes syntax in the absence of conscious awareness. Journal of Neuroscience, 33(19), 8528-8533. https://doi.org/10.1523/jneurosci.0618-13.2013
doi: 10.1523/JNEUROSCI.0618-13.2013 URL pmid: 23658189 |
| [8] | Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A neural probabilistic language model. Journal of Machine Learning Research, 3(6), 1137-1155. https://doi.org/10.1162/153244303322533223 |
| [9] |
Bi, Y. (2021). Dual coding of knowledge in the human brain. Trends in Cognitive Sciences, 25(10), 883-895. https://doi.org/10.1016/j.tics.2021.07.006
doi: 10.1016/j.tics.2021.07.006 URL pmid: 34509366 |
| [10] |
Binder, J. R., Conant, L. L., Humphries, C. J., Fernandino, L., Simons, S. B., Aguilar, M., & Desai, R. H. (2016). Toward a brain-based componential semantic representation. Cognitive Neuropsychology, 33(3-4), 130-174. https://doi.org/10.1080/02643294.2016.1147426
doi: 10.1080/02643294.2016.1147426 URL pmid: 27310469 |
| [11] |
Binder, J. R., Desai, R. H., Graves, W. W., & Conant, L. L. (2009). Where is the semantic system? A critical review and meta-analysis of 120 functional neuroimaging studies. Cerebral Cortex, 19(12), 2767-2796. https://doi.org/10.1093/cercor/bhp055
doi: 10.1093/cercor/bhp055 URL |
| [12] |
Bonnici, H. M., Richter, F. R., Yazar, Y., & Simons, J. S. (2016). Multimodal feature integration in the angular gyrus during episodic and semantic retrieval. Journal of Neuroscience, 36(20), 5462-5471. https://doi.org/10.1523/jneurosci.4310-15.2016
doi: 10.1523/JNEUROSCI.4310-15.2016 URL pmid: 27194327 |
| [13] |
Branzi, F. M., Humphreys, G. F., Hoffman, P., & Lambon Ralph, M. A. (2020). Revealing the neural networks that extract conceptual gestalts from continuously evolving or changing semantic contexts. NeuroImage, 220, 116802, Article 116802. https://doi.org/10.1016/j.neuroimage.2020.116802
doi: 10.1016/j.neuroimage.2020.116802 URL |
| [14] | Brown, P. F., Della Pietra, V. J., deSouza, P. V., Lai, J. C., & Mercer, R. L. (1992). Class-based n-gram models of natural language. Computational Linguistics, 18(4), 467-480. |
| [15] | Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P.,... Askell, A. (2020, December). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901. https://dl.acm.org/doi/10.5555/3495724.3495883 |
| [16] |
Bruffaerts, R., de Deyne, S., Meersmans, K., Liuzzi, A. G., Storms, G., & Vandenberghe, R. (2019). Redefining the resolution of semantic knowledge in the brain: Advances made by the introduction of models of semantics in neuroimaging. Neuroscience & Biobehavioral Reviews, 103, 3-13. https://doi.org/10.1016/j.neubiorev.2019.05.015
doi: 10.1016/j.neubiorev.2019.05.015 URL |
| [17] |
Carota, F., Nili, H., Pulvermuller, F., & Kriegeskorte, N. (2021). Distinct fronto-temporal substrates of distributional and taxonomic similarity among words: Evidence from RSA of BOLD signals. NeuroImage, 224, 117408, Article 117408. https://doi.org/10.1016/j.neuroimage.2020.117408
doi: 10.1016/j.neuroimage.2020.117408 URL |
| [18] | Caucheteux, C., Gramfort, A., & King, J.-R. (2021a, July). Disentangling syntax and semantics in the brain with deep networks. Proceedings of the 38th International Conference on Machine Learning, 139, 1336-1348. https://proceedings.mlr.press/v139/caucheteux21a.html |
| [19] | Caucheteux, C., Gramfort, A., & King, J.-R. (2021b). Long- range and hierarchical language predictions in brains and algorithms. arXiv. https://doi.org/10.48550/arXiv.2111.14232 |
| [20] |
Caucheteux, C., & King, J.-R. (2022). Brains and algorithms partially converge in natural language processing. Communications Biology, 5(1), 134. https://doi.org/10.1038/s42003-022-03036-1
doi: 10.1038/s42003-022-03036-1 URL pmid: 35173264 |
| [21] | Chomsky, N. (1957). Syntactic structures. The Hague: Mouton. https://doi.org/10.1515/9783112316009 |
| [22] |
Cichy, R. M., & Kaiser, D. (2019). Deep neural networks as scientific models. Trends in Cognitive Sciences, 23(4), 305-317. https://doi.org/10.1016/j.tics.2019.01.009
doi: S1364-6613(19)30034-8 URL pmid: 30795896 |
| [23] | Conneau, A., Kiela, D., Schwenk, H., Barrault, L., & Bordes, A. (2017, September). Supervised learning of universal sentence representations from natural language inference data. Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 670-680, Copenhagen, Denmark. https://doi.org/10.18653/v1/D17-1070 |
| [24] |
Cooper, K. E., & Nisbet, E. C. (2016). Green narratives: How affective responses to media messages influence risk perceptions and policy preferences about environmental hazards. Science Communication, 38(5), 626-654. https://doi.org/10.1177/1075547016666843
doi: 10.1177/1075547016666843 URL |
| [25] |
Cree, G. S., & McRae, K. (2003). Analyzing the factors underlying the structure and computation of the meaning of chipmunk, cherry, chisel, cheese, and cello (and many other such concrete nouns). Journal of Experimental Psychology: General, 132(2), 163-201. https://doi.org/10.1037/0096-3445.132.2.163
doi: 10.1037/0096-3445.132.2.163 URL |
| [26] | Day, M., Dey, R. K., Baucum, M., Paek, E. J., Park, H., & Khojandi, A. (2021, November). Predicting severity in people with aphasia: A natural language processing and machine learning approach. Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), 2021, 2299-2302, Mexico. https://doi.org/10.1109/embc46164.2021.9630694 |
| [27] |
de Boer, J. N., Voppel, A. E., Begemann, M. J. H., Schnack, H. G., Wijnen, F., & Sommer, I. E. C. (2018). Clinical use of semantic space models in psychiatry and neurology: A systematic review and meta-analysis. Neuroscience & Biobehavioral Reviews, 93, 85-92. https://doi.org/10.1016/j.neubiorev.2018.06.008
doi: 10.1016/j.neubiorev.2018.06.008 URL |
| [28] |
Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer, T. K., & Harshman, R. (1990). Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41(6), 391-407. https://doi.org/10.1002/(sici)1097-4571(199009)41:6<391::aid-asi1>3.0.co;2-9
doi: 10.1002/(ISSN)1097-4571 URL |
| [29] | Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv. https://doi.org/10.48550/arXiv.1810.04805 |
| [30] |
Dubova, M. (2022). Building human-like communicative intelligence: A grounded perspective. Cognitive Systems Research, 72, 63-79. https://doi.org/10.1016/j.cogsys.2021.12.002
doi: 10.1016/j.cogsys.2021.12.002 URL |
| [31] | Dumais, S. T. (2004). Latent semantic analysis. Annual Review of Information Science and Technology, 38(1), 189-230. https://doi.org/10.1002/aris.1440380105 |
| [32] |
Dupre la Tour, T., Eickenberg, M., Nunez-Elizalde, A. O., & Gallant, J. L. (2022). Feature-space selection with banded ridge regression. NeuroImage, 264, 119728. https://doi.org/10.1016/j.neuroimage.2022.119728
doi: 10.1016/j.neuroimage.2022.119728 URL |
| [33] |
Elman, J. L. (1990). Finding structure in time. Cognitive Science, 14(2), 179-211. https://doi.org/10.1207/s15516709cog1402_1
doi: 10.1207/s15516709cog1402_1 URL |
| [34] |
Fedorenko, E., Nieto-Castanon, A., & Kanwisher, N. (2012). Lexical and syntactic representations in the brain: An fMRI investigation with multi-voxel pattern analyses. Neuropsychologia, 50(4), 499-513. https://doi.org/10.1016/j.neuropsychologia.2011.09.014
doi: 10.1016/j.neuropsychologia.2011.09.014 URL pmid: 21945850 |
| [35] |
Fernandino, L., Binder, J. R., Desai, R. H., Pendl, S. L., Humphries, C. J., Gross, W. L.,... Seidenberg, M. S. (2016a). Concept representation reflects multimodal abstraction: A framework for embodied semantics. Cerebral Cortex, 26(5), 2018-2034. https://doi.org/10.1093/cercor/bhv020
doi: 10.1093/cercor/bhv020 URL |
| [36] |
Fernandino, L., Humphries, C. J., Conant, L. L., Seidenberg, M. S., & Binder, J. R. (2016b). Heteromodal cortical areas encode sensory-motor features of word meaning. Journal of Neuroscience, 36(38), 9763-9769. https://doi.org/10.1523/jneurosci.4095-15.2016
doi: 10.1523/JNEUROSCI.4095-15.2016 URL |
| [37] | Fernandino, L., Tong, J.-Q., Conant, L. L., Humphries, C. J., & Binder, J. R. (2022). Decoding the information structure underlying the neural representation of concepts. Proceedings of the National Academy of Sciences of the United States of America, 119(6). https://doi.org/10.1073/pnas.2108091119 |
| [38] |
Finn, E. S., & Bandettini, P. A. (2021). Movie-watching outperforms rest for functional connectivity-based prediction of behavior. NeuroImage, 235, 117963. https://doi.org/10.1016/j.neuroimage.2021.117963
doi: 10.1016/j.neuroimage.2021.117963 URL |
| [39] | Fraser, K. C., Meltzer, J. A., & Rudzicz, F. (2016). Linguistic features identify Alzheimer's disease in narrative speech. Journal of Alzheimers Disease, 49(2), 407-422. https://doi.org/10.3233/jad-150520 |
| [40] |
Gao, Z., Zheng, L., Gouws, A., Krieger-Redwood, K., Wang, X., Varga, D.,... & Jefferies, E. (2023). Context free and context-dependent conceptual representation in the brain. Cerebral Cortex, 33(1), 152-166. https://doi.org/10.1093/cercor/bhac058
doi: 10.1093/cercor/bhac058 URL |
| [41] | Goldberg, Y. (2019). Assessing BERT's syntactic abilities. arXiv. https://doi.org/10.48550/arXiv.1901.05287 |
| [42] |
Goldstein, A., Zada, Z., Buchnik, E., Schain, M., Price, A., Aubrey, B.,... Hasson, U. (2022). Shared computational principles for language processing in humans and deep language models. Nature Neuroscience, 25(3), 369-380. https://doi.org/10.1038/s41593-022-01026-4
doi: 10.1038/s41593-022-01026-4 URL pmid: 35260860 |
| [43] |
Gonzalez, J., Barros-Loscertales, A., Pulvermüller, F., Meseguer, V., Sanjuan, A., Belloch, V., & Avila, C. (2006). Reading cinnamon activates olfactory brain regions. NeuroImage, 32(2), 906-912. https://doi.org/10.1016/j.neuroimage.2006.03.037
doi: 10.1016/j.neuroimage.2006.03.037 URL pmid: 16651007 |
| [44] | Graves, A., Mohamed, A.-r., & Hinton, G. (2013, May). Speech recognition with deep recurrent neural networks. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, 6645-6649, Vancouver, BC, Canada. https://doi.org/10.1109/ICASSP.2013.6638947 |
| [45] |
Hagoort, P., & Indefrey, P. (2014). The neurobiology of language beyond single words. Annual Review of Neuroscience, 37(1), 347-362. https://doi.org/10.1146/annurev-neuro-071013-013847
doi: 10.1146/neuro.2014.37.issue-1 URL |
| [46] | Hamilton, L. S., & Huth, A. G. (2020). The revolution will not be controlled: Natural stimuli in speech neuroscience. Language, Cognition and Neuroscience, 35(5), 573582. https://doi.org/10.1080/23273798.2018.1499946 |
| [47] | Harris, Z. S. (1954). Distributional structure. Word-Journal of the International Linguistic Association, 10(2-3), 146-162. https://doi.org/10.1080/00437956.1954.11659520 |
| [48] |
Hasson, U., Yang, E., Vallines, I., Heeger, D. J., & Rubin, N. (2008). A hierarchy of temporal receptive windows in human cortex. Journal of Neuroscience, 28(10), 2539-2550. https://doi.org/10.1523/JNEUROSCI.5487-07.2008
doi: 10.1523/JNEUROSCI.5487-07.2008 URL pmid: 18322098 |
| [49] | Hobbs, J. R. (1977). Pronoun resolution. ACM SIGART Bulletin (61), 28-28. https://doi.org/10.1145/1045283.1045292 |
| [50] |
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780. https://doi.org/10.1162/neco.1997.9.8.1735
doi: 10.1162/neco.1997.9.8.1735 URL pmid: 9377276 |
| [51] |
Humphreys, G. F., Lambon Ralph, M. A., & Simons, J. S. (2021). A unifying account of angular gyrus contributions to episodic and semantic cognition. Trends in Neurosciences, 44(6), 452-463. https://doi.org/10.1016/j.tins.2021.01.006
doi: 10.1016/j.tins.2021.01.006 URL pmid: 33612312 |
| [52] |
Huth, A. G., de Heer, W. A., Griffiths, T. L., Theunissen, F. E., & Gallant, J. L. (2016). Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600), 453-458. https://doi.org/10.1038/nature17637
doi: 10.1038/nature17637 URL |
| [53] | Jain, S., & Huth, A. G. (2018, December). Incorporating context into language encoding models for fMRI. Advances in Neural Information Processing Systems, 31, 6629-6638, Montreal, Canada. |
| [54] |
Jelodar, H., Wang, Y., Yuan, C., Feng, X., Jiang, X., Li, Y., & Zhao, L. (2019). Latent dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimedia Tools and Applications, 78(11), 15169-15211. https://doi.org/10.1007/s11042-018-6894-4
doi: 10.1007/s11042-018-6894-4 URL |
| [55] |
Kiefer, M., & Pulvermüller, F. (2012). Conceptual representations in mind and brain: Theoretical developments, current evidence and future directions. Cortex, 48(7), 805-825. https://doi.org/10.1016/j.cortex.2011.04.006
doi: 10.1016/j.cortex.2011.04.006 URL pmid: 21621764 |
| [56] |
Kivisaari, S. L., van Vliet, M., Hulten, A., Lindh-Knuutila, T., Faisal, A., & Salmelin, R. (2019). Reconstructing meaning from bits of information. Nature Communications, 10(1), 927. https://doi.org/10.1038/s41467-019-08848-0
doi: 10.1038/s41467-019-08848-0 URL pmid: 30804334 |
| [57] |
Kriegeskorte, N., & Douglas, P. K. (2018). Cognitive computational neuroscience. Nature Neuroscience, 21(9), 1148-1160. https://doi.org/10.1038/s41593-018-0210-5
doi: 10.1038/s41593-018-0210-5 URL pmid: 30127428 |
| [58] |
Kriegeskorte, N., & Douglas, P. K. (2019). Interpreting encoding and decoding models. Current Opinion in Neurobiology, 55, 167-179. https://doi.org/10.1016/j.conb.2019.04.002
doi: S0959-4388(18)30100-4 URL pmid: 31039527 |
| [59] |
Kriegeskorte, N., Mur, M., & Bandettini, P. (2008). Representational similarity analysis - connecting the branches of systems neuroscience. Frontiers in Systems Neuroscience, 2, 4. https://doi.org/10.3389/neuro.06.004.2008
doi: 10.3389/neuro.06.004.2008 URL pmid: 19104670 |
| [60] |
Kumar, A. A. (2021). Semantic memory: A review of methods, models, and current challenges. Psychonomic Bulletin & Review, 28(1), 40-80. https://doi.org/10.3758/s13423-020-01792-x
doi: 10.3758/s13423-020-01792-x URL |
| [61] |
Kuperberg, G. R. (2007). Neural mechanisms of language comprehension: Challenges to syntax. Brain Research, 1146, 23-49. https://doi.org/10.1016/j.brainres.2006.12.063
URL pmid: 17400197 |
| [62] |
Lahat, D., Adali, T., & Jutten, C. (2015). Multimodal data fusion: An overview of methods, challenges, and prospects. Proceedings of the IEEE, 103(9), 1449-1477,. https://doi.org/10.1109/jproc.2015.2460697
doi: 10.1109/JPROC.2015.2460697 URL |
| [63] |
Lambon Ralph, M. A., Jefferies, E., Patterson, K., & Rogers, T. T. (2017). The neural and computational bases of semantic cognition. Nature Reviews: Neuroscience, 18(1), 42-55. https://doi.org/10.1038/nrn.2016.150
doi: 10.1038/nrn.2016.150 URL |
| [64] |
Laurino Dos Santos, H., & Berger, J. (2022). The speed of stories: Semantic progression and narrative success. Journal of Experimental Psychology: General, 151(8), 1833-1842. https://doi.org/10.1037/xge0001171
doi: 10.1037/xge0001171 URL |
| [65] |
Law, R., & Pylkkanen, L. (2021). Lists with and without syntax: A new approach to measuring the neural processing of syntax. Journal of Neuroscience, 41(10), 2186-2196. https://doi.org/10.1523/JNEUROSCI.1179-20.2021
doi: 10.1523/JNEUROSCI.1179-20.2021 URL pmid: 33500276 |
| [66] |
Lee, D. D., & Seung, H. S. (1999). Learning the parts of objects by non-negative matrix factorization. Nature, 401(6755), 788-791. https://doi.org/10.1038/44565
doi: 10.1038/44565 URL |
| [67] |
Lee, H., & Chen, J. (2022). Predicting memory from the network structure of naturalistic events. Nature Communications, 13(1), 4235. https://doi.org/10.1038/s41467-022-31965-2
doi: 10.1038/s41467-022-31965-2 URL pmid: 35869083 |
| [68] |
Lerner, Y., Honey, C. J., Silbert, L. J., & Hasson, U. (2011). Topographic mapping of a hierarchy of temporal receptive windows using a narrated story. Journal of Neuroscience, 31(8), 2906-2915. https://doi.org/10.1523/jneurosci.3684-10.2011
doi: 10.1523/JNEUROSCI.3684-10.2011 URL pmid: 21414912 |
| [69] |
Margulies, D. S., Ghosh, S. S., Goulas, A., Falkiewicz, M., Huntenburg, J. M., Langs, G.,... Smallwood, J. (2016). Situating the default-mode network along a principal gradient of macroscale cortical organization. Proceedings of the National Academy of Sciences of the United States of America, 113(44), 12574-12579. https://doi.org/10.1073/pnas.1608282113
URL pmid: 27791099 |
| [70] |
Matchin, W., Brodbeck, C., Hammerly, C., & Lau, E. (2019). The temporal dynamics of structure and content in sentence comprehension: Evidence from fMRI-constrained MEG. Human Brain Mapping, 40(2), 663-678. https://doi.org/10.1002/hbm.24403
doi: 10.1002/hbm.24403 URL pmid: 30259599 |
| [71] |
McClelland, J. L., Hill, F., Rudolph, M., Baldridge, J., & Schutze, H. (2020). Placing language in an integrated understanding system: Next steps toward human-level performance in neural language models. Proceedings of the National Academy of Sciences of the United States of America, 117(42), 25966-25974. https://doi.org/10.1073/pnas.1910416117
doi: 10.1073/pnas.1910416117 URL pmid: 32989131 |
| [72] |
Mcculloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics, 5(4), 115-133. https://doi.org/10.1007/bf02478259
doi: 10.1007/BF02478259 URL |
| [73] |
Miani, A., Hills, T., & Bangerter, A. (2022). Interconnectedness and (in)coherence as a signature of conspiracy worldviews. Science Advances, 8(43), eabq3668. https://doi.org/10.1126/sciadv.abq3668
doi: 10.1126/sciadv.abq3668 URL |
| [74] | Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013a). Efficient estimation of word representations in vector space. arXiv. https://doi.org/10.48550/arXiv.1301.3781 |
| [75] | Mikolov, T., Karafiat, M., Burget, L., Cernocky, J. H., & Khudanpur, S. (2010, September). Recurrent neural network based language model. 11th Annual Conference of the International Speech Communication Association 2010, 1045-1048, Makuhari, Chiba, Japan. |
| [76] | Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013b). Distributed representations of words and phrases and their compositionality. arXiv. https://doi.org/10.48550/arXiv.1310.4546 |
| [77] |
Mitchell, T. M., Shinkareva, S. V., Carlson, A., Chang, K.-M., Malave, V. L., Mason, R. A., & Just, M. A. (2008). Predicting human brain activity associated with the meanings of nouns. Science, 320(5880), 1191-1195. https://doi.org/10.1126/science.1152876
doi: 10.1126/science.1152876 URL pmid: 18511683 |
| [78] |
Nastase, S. A., Connolly, A. C., Oosterhof, N. N., Halchenko, Y. O., Guntupalli, J. S., Visconti Di Oleggio Castello, M.,... Haxby, J. V. (2017). Attention selectively reshapes the geometry of distributed semantic representation. Cerebral Cortex, 27(8), 4277-4291. https://doi.org/10.1093/cercor/bhx138
doi: 10.1093/cercor/bhx138 URL |
| [79] | Nevler, N., Ash, S., McMillan, C., Elman, L., McCluskey, L., Irwin, D. J.,... Grossman, M. (2020). Automated analysis of natural speech in amyotrophic lateral sclerosis spectrum disorders. Neurology, 95(12), E1629-E1639. https://doi.org/10.1212/wnl.0000000000010366 |
| [80] |
Nguyen, M., Vanderwal, T., & Hasson, U. (2019). Shared understanding of narratives is correlated with shared neural responses. NeuroImage, 184, 161-170. https://doi.org/10.1016/j.neuroimage.2018.09.010
doi: S1053-8119(18)30794-8 URL pmid: 30217543 |
| [81] |
Paivio, A. (1991). Dual coding theory: Retrospect and current status. Canadian Journal of Psychology / Revue canadienne de psychologie, 45(3), 255-287. https://doi.org/10.1037/h0084295
doi: 10.1037/h0084295 URL |
| [82] | Patel, T., Morales, M., Pickering, M. J., & Hoffman, P. (2022). A common neural code for meaning in discourse production and comprehension. bioRxiv. https://doi.org/10.1101/2022.10.15.512349 |
| [83] |
Patterson, K., Nestor, P. J., & Rogers, T. T. (2007). Where do you know what you know? The representation of semantic knowledge in the human brain. Nature Reviews Neuroscience, 8(12), 976-987. https://doi.org/10.1038/nrn2277
doi: 10.1038/nrn2277 URL pmid: 18026167 |
| [84] | Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018, June). Deep contextualized word representations. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1, 2227-2237, New Orleans, Louisiana, USA. https://doi.org/10.18653/v1/N18-1202 |
| [85] |
Petersson, K.-M., Folia, V., & Hagoort, P. (2012). What artificial grammar learning reveals about the neurobiology of syntax. Brain and Language, 120(2), 83-95. https://doi.org/10.1016/j.bandl.2010.08.003
doi: 10.1016/j.bandl.2010.08.003 URL |
| [86] |
Poldrack, R. A., Wagner, A. D., Prull, M. W., Desmond, J. E., Glover, G. H., & Gabrieli, J. D. (1999). Functional specialization for semantic and phonological processing in the left inferior prefrontal cortex. NeuroImage, 10(1), 15-35. https://doi.org/10.1006/nimg.1999.0441
doi: 10.1006/nimg.1999.0441 URL pmid: 10385578 |
| [87] |
Prince, J. S., Charest, I., Kurzawski, J. W., Pyles, J. A., Tarr, M. J., & Kay, K. N. (2022). Improving the accuracy of single-trial fMRI response estimates using GLMsingle. eLife, 11, e77599. https://doi.org/10.7554/elife.77599
doi: 10.7554/eLife.77599 URL |
| [88] |
Pulvermüller, F. (2013). How neurons make meaning: Brain mechanisms for embodied and abstract-symbolic semantics. Trends in Cognitive Sciences, 17(9), 458-470. https://doi.org/10.1016/j.tics.2013.06.004
doi: 10.1016/j.tics.2013.06.004 URL pmid: 23932069 |
| [89] |
Pulvermüller, F., Harle, M., & Hummel, F. (2001). Walking or talking? Behavioral and neurophysiological correlates of action verb processing. Brain and Language, 78(2), 143-168. https://doi.org/10.1006/brln.2000.2390
URL pmid: 11500067 |
| [90] |
Pulvermüller, F., Kherif, F., Hauk, O., Mohr, B., & Nimmo-Smith, I. (2009). Distributed cell assemblies for general lexical and category-specific semantic processing as revealed by fMRI cluster analysis. Human Brain Mapping, 30(12), 3837-3850. https://doi.org/10.1002/hbm.20811
doi: 10.1002/hbm.20811 URL pmid: 19554560 |
| [91] |
Pulvermüller, F., Lutzenberger, W., & Preissl, H. (1999). Nouns and verbs in the intact brain: Evidence from event-related potentials and high-frequency cortical responses. Cerebral Cortex, 9(5), 497-506. https://doi.org/10.1093/cercor/9.5.497
URL pmid: 10450894 |
| [92] |
Pylkkanen, L. (2019). The neural basis of combinatory syntax and semantics. Science, 366(6461), 62-66. https://doi.org/10.1126/science.aax0050
doi: 10.1126/science.aax0050 URL pmid: 31604303 |
| [93] | Quoc, L., & Mikolov, T. (2014, June). Distributed representations of sentences and documents. Proceedings of the 31st International Conference on Machine Learning, 32, 1188-1196, Beijing, China. |
| [94] | Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9. |
| [95] |
Rodd, J., Gaskell, G., & Marslen-Wilson, W. (2002). Making sense of semantic ambiguity: Semantic competition in lexical access. Journal of Memory and Language, 46(2), 245-266. https://doi.org/10.1006/jmla.2001.2810
doi: 10.1006/jmla.2001.2810 URL |
| [96] |
Salton, G., Wong, A., & Yang, C. S. (1975). A vector space model for automatic indexing. Communications of the ACM, 18(11), 613-620. https://doi.org/10.1145/361219.361220
doi: 10.1145/361219.361220 URL |
| [97] | Schrimpf, M., Blank, I. A., Tuckute, G., Kauf, C., Hosseini, E. A., Kanwisher, N.,... Fedorenko, E. (2021). The neural architecture of language: Integrative modeling converges on predictive processing. Proceedings of the National Academy of Sciences of the United States of America, 118(45). https://doi.org/10.1073/pnas.2105646118 |
| [98] | Schwartz, D., Toneva, M., & Wehbe, L. (2019, December). Inducing brain-relevant bias in natural language processing models. Advances in Neural Information Processing Systems, 32, 14123-14133, Vancouver, Canada. https://dl.acm.org/doi/10.5555/3454287.3455553 |
| [99] |
Segaert, K., Menenti, L., Weber, K., Petersson, K. M., & Hagoort, P. (2012). Shared syntax in language production and language comprehension—an fMRI study. Cerebral Cortex, 22(7), 1662-1670. https://doi.org/10.1093/cercor/bhr249
doi: 10.1093/cercor/bhr249 URL |
| [100] |
Simony, E., Honey, C. J., Chen, J., Lositsky, O., Yeshurun, Y., Wiesel, A., & Hasson, U. (2016). Dynamic reconfiguration of the default mode network during narrative comprehension. Nature Communications, 7(1), 12141. https://doi.org/10.1038/ncomms12141
doi: 10.1038/ncomms12141 URL |
| [101] |
Smallwood, J., Bernhardt, B. C., Leech, R., Bzdok, D., Jefferies, E., & Margulies, D. S. (2021). The default mode network in cognition: A topographical perspective. Nature Reviews Neuroscience, 22(8), 503-513. https://doi.org/10.1038/s41583-021-00474-4
doi: 10.1038/s41583-021-00474-4 URL pmid: 34226715 |
| [102] | Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A., & Potts, C. (2013, October). Recursive deep models for semantic compositionality over a sentiment treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1631-1642, Seattle, Washington, USA. |
| [103] |
Solomon, S. H., Medaglia, J. D., & Thompson-Schill, S. L. (2019). Implementing a concept network model. Behavior Research Methods, 51(4), 1717-1736. https://doi.org/10.3758/s13428-019-01217-1
doi: 10.3758/s13428-019-01217-1 URL pmid: 30891712 |
| [104] | Sun, X., Yang, D., Li, X., Zhang, T., Meng, Y., Qiu, H.,... Li, J. (2021). Interpreting deep learning models in natural language processing: A review. arXiv. https://doi.org/10.48550/arXiv.2110.10470 |
| [105] | Sundermeyer, M., Schluter, R., & Ney, H. (2012, September). LSTM neural networks for language modeling. 13th Annual Conference of the International Speech Communication Association, 194-197, Portland, Oregon, USA. https://doi.org/10.21437/Interspeech.2012-65 |
| [106] | Sutskever, I., Vinyals, O., & Le, Q. V. (2014, December). Sequence to sequence learning with neural networks. Advances in Neural Information Processing Systems, 27, Montreal, Canada. https://dl.acm.org/doi/10.5555/2969033.2969173 |
| [107] | Tikochinski, R., Goldstein, A., Yeshurun, Y., Hasson, U., & Reichart, R. (2021). Fine-tuning of deep language models as a computational framework of modeling listeners’ perspective during language comprehension. bioRxiv. https://doi.org/10.1101/2021.11.22.469596 |
| [108] | Toneva, M., & Wehbe, L. (2019, December). Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain). Advances in Neural Information Processing Systems, 32, 14954-14964, Vancouver, Canada. https://dl.acm.org/doi/10.5555/3454287.3455626 |
| [109] |
Tong, J., Binder, J. R., Humphries, C., Mazurchuk, S., Conant, L. L., & Fernandino, L. (2022). A distributed network for multimodal experiential representation of concepts. Journal of Neuroscience, 42(37), 7121-7130. https://doi.org/10.1523/JNEUROSCI.1243-21.2022
doi: 10.1523/JNEUROSCI.1243-21.2022 URL |
| [110] | Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N.,... Polosukhin, I. (2017, December). Attention is all you need. Advances in Neural Information Processing Systems, 30, Long Beach, California, USA. https://dl.acm.org/doi/10.5555/3295222.3295349 |
| [111] |
Vodrahalli, K., Chen, P.-H., Liang, Y., Baldassano, C., Chen, J., Yong, E.,... Arora, S. (2018). Mapping between fMRI responses to movies and their natural language annotations. NeuroImage, 180, 223-231. https://doi.org/10.1016/j.neuroimage.2017.06.042
doi: S1053-8119(17)30512-8 URL pmid: 28648889 |
| [112] | Wang, S., Zhang, J., Lin, N., & Zong, C. (2018, February). Investigating inner properties of multimodal representation and semantic compositionality with brain-based componential semantics. Proceedings of the AAAI Conference on Artificial Intelligence, 30(1), 5964-5972, New Orleans, Louisiana, USA. https://doi.org/10.1609/aaai.v32i1.12032 |
| [113] | Wang, S., Zhang, J., Lin, N., & Zong, C. (2020, February). Probing brain activation patterns by dissociating semantics and syntax in sentences. Proceedings of the AAAI Conference on Artificial Intelligence, 34(05), 9201-9208, New York, USA. https://doi.org/10.1609/aaai.v34i05.6457 |
| [114] | Wang, S., Zhang, J., & Zong, C. (2018, October-November). Associative multichannel autoencoder for multimodal word representation. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 115-124, Brussels, Belgium. https://doi.org/10.18653/v1/D18-1011 |
| [115] |
Wang, X., Wu, W., Ling, Z., Xu, Y., Fang, Y., Wang, X.,... Bi, Y. (2018). Organizational principles of abstract words in the human brain. Cerebral Cortex, 28(12), 4305-4318. https://doi.org/10.1093/cercor/bhx283
doi: 10.1093/cercor/bhx283 URL |
| [116] |
Warburton, E., Wise, R. J., Price, C. J., Weiller, C., Hadar, U., Ramsay, S., & Frackowiak, R. S. (1996). Noun and verb retrieval by normal subjects studies with PET. Brain, 119, 159-179. https://doi.org/10.1093/brain/119.1.159
doi: 10.1093/brain/119.1.159 URL |
| [117] |
Wehbe, L., Murphy, B., Talukdar, P., Fyshe, A., Ramdas, A., & Mitchell, T. (2014). Simultaneously uncovering the patterns of brain regions involved in different story reading subprocesses. PLoS One, 9(11), e112575. https://doi.org/10.1371/journal.pone.0112575
doi: 10.1371/journal.pone.0112575 URL |
| [118] | Wu, S., & Dredze, M. (2019, November). Beto, bentz, becas:The surprising cross-lingual effectiveness of BERT. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), 833-844, Hong Kong, China. https://doi.org/10.18653/v1/D19-1077 |
| [119] |
Wurm, M. F., & Caramazza, A. (2019). Distinct roles of temporal and frontoparietal cortex in representing actions across vision and language. Nature Communications, 10(1), 289. https://doi.org/10.1038/s41467-018-08084-y
doi: 10.1038/s41467-018-08084-y URL pmid: 30655531 |
| [120] |
Xu, C., Zhang, Y., Zhu, G., Rui, Y., Lu, H., & Huang, Q. (2008). Using webcast text for semantic event detection in broadcast sports video. IEEE Transactions on Multimedia, 10(7), 1342-1355. https://doi.org/10.1109/Tmm.2008.2004912
doi: 10.1109/TMM.2008.2004912 URL |
| [121] |
Yee, E., & Thompson-Schill, S. L. (2016). Putting concepts into context. Psychonomic Bulletin & Review, 23(4), 1015-1027. https://doi.org/10.3758/s13423-015-0948-7
doi: 10.3758/s13423-015-0948-7 URL |
| [122] |
Yeshurun, Y., Nguyen, M., & Hasson, U. (2021). The default mode network: Where the idiosyncratic self meets the shared social world. Nature Reviews: Neuroscience, 22(3), 181-192. https://doi.org/10.1038/s41583-020-00420-w
doi: 10.1038/s41583-020-00420-w URL |
| [123] | Yin, W., Kann, K., Yu, M., & Schütze, H. (2017). Comparative study of cnn and rnn for natural language processing. arXiv. https://doi.org/10.48550/arXiv.1702.01923 |
| [124] | Zhang, X., Wang, S., Lin, N., Zhang, J., & Zong, C. (2022, February). Probing word syntactic representations in the brain by a feature elimination method. Proceedings of the AAAI Conference on Artificial Intelligence, 36(10), 11721-11729. https://doi.org/10.1609/aaai.v36i10.21427 |
| [125] | Zhang, Y., & Wallace, B. (2017). A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. arXiv, 253-263. https://doi.org/10.48550/arXiv.1510.03820 |
| [126] | Zhu, X., Li, Z., Wang, X., Jiang, X., Sun, P., Wang, X.,... Yuan, N. J. (2022). Multi-modal knowledge graph construction and application: A survey. IEEE Transactions on Knowledge and Data Engineering, 1-20. https://doi.org/10.1109/tkde.2022.3224228 |
| [1] | SHU Xindi, LIU Hanyin, WANG Jin, LIU Zhiyuan, LIU Lanfang. The mechanisms and functions of inter-brain synchronization [J]. Advances in Psychological Science, 2025, 33(3): 439-451. |
| [2] | GONG Fangying, SUN Yifan, HE Qin, SHI Ke, LIU Wei, CHEN Ning. Brain-to-brain synchronyduring teacher-student interactions and its regulatory factors in teaching interaction [J]. Advances in Psychological Science, 2025, 33(3): 452-464. |
| [3] | CHANG Siqin, HUANG Chen, DAI Yuanfu, JIANG Changhao. Effects of VR training on cognitive function in older adults with mild cognitive impairment and its neural mechanisms [J]. Advances in Psychological Science, 2025, 33(2): 322-335. |
| [4] | ZHANG Xiangyang, WANG Xiaojuan, YANG Jianfeng. The role of the left Angular Gyrus in lexical-semantic processing [J]. Advances in Psychological Science, 2024, 32(4): 616-626. |
| [5] | YU Jing, NIU Cheng-Cheng, XU Hong-Zhou, JIANG Hai-Xin, LIN Guo-Jun, WU Ke, XU Zi-Han. The neuropsychological mechanism underlying the effect of volunteering on older adults’ cognitive function [J]. Advances in Psychological Science, 2024, 32(3): 413-420. |
| [6] | ZHENG Hao, CHEN Rongrong, MAI Xiaoqin. The cognitive and neural mechanism of third-party punishment [J]. Advances in Psychological Science, 2024, 32(2): 398-412. |
| [7] | Ye Xie, Tinghao Zhao, Wei Zhang, Yunxia Li, Yixuan Ku. Hippocampal Deterioration and Frontal Compensation of Amnestic Mild Cognitive Impairment in Visual Short-term Memory [J]. Advances in Psychological Science, 2023, 31(suppl.): 105-105. |
| [8] | Wenjun Huang, Bao Hong, Jiahe Wu, Jing Chen, Li Li. Investigating Brain Structural Correlates of Ocular Tracking in Preadolescent Children and Young Adults [J]. Advances in Psychological Science, 2023, 31(suppl.): 141-141. |
| [9] | Zhirui Yang, Jingwen Yang, Zelin Chen, Chufen Huang, Shuo Lu. The Developing Brain Maintains Dynamic Trade-off Patterns in Visual Networks [J]. Advances in Psychological Science, 2023, 31(suppl.): 168-168. |
| [10] | ZHOU Shiren, QIU Xiufu, HE Zhenhong, ZHANG Dandan. Non-invasive brain stimulation-based emotion regulation interventions [J]. Advances in Psychological Science, 2023, 31(8): 1477-1495. |
| [11] | BAO Han-Wu-Shuang, WANG Zi-Xi, CHENG Xi, SU Zhan, YANG Ying, ZHANG Guang-Yao, WANG Bo, CAI Hua-Jian. Using word embeddings to investigate human psychology: Methods and applications [J]. Advances in Psychological Science, 2023, 31(6): 887-904. |
| [12] | PENG Yujia, WANG Yuxi, LU Di. The mechanism of emotion processing and intention inference in social anxiety disorder based on biological motion [J]. Advances in Psychological Science, 2023, 31(6): 905-914. |
| [13] | ZHANG Caihui, YE Jianqiao, YANG Jing. Brain mechanism underlying learning Chinese as a second language [J]. Advances in Psychological Science, 2023, 31(5): 747-758. |
| [14] | WANG Yongli, GE Shengnan, Lancy Lantin Huang, WAN Qin, LU Haidan. Neural mechanism of speech imagery [J]. Advances in Psychological Science, 2023, 31(4): 608-621. |
| [15] | KONG Xiang-Zhen, ZHANG Fengxiang, PU Yi. The functional brain network that supports human spatial navigation [J]. Advances in Psychological Science, 2023, 31(3): 330-337. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||