ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
Advances in Psychological Science ›› 2023, Vol. 31 ›› Issue (6): 887-904.doi: 10.3724/SP.J.1042.2023.00887
• Research Method • Next Articles
BAO Han-Wu-Shuang1,2,3, WANG Zi-Xi1,2, CHENG Xi1,2, SU Zhan1,2, YANG Ying1,2, ZHANG Guang-Yao1,2,4, WANG Bo5, CAI Hua-Jian1,2( )
)
Received:2022-08-23
Online:2023-06-15
Published:2023-03-07
Contact:
CAI Hua-Jian
E-mail:caihj@psych.ac.cn
CLC Number:
BAO Han-Wu-Shuang, WANG Zi-Xi, CHENG Xi, SU Zhan, YANG Ying, ZHANG Guang-Yao, WANG Bo, CAI Hua-Jian. Using word embeddings to investigate human psychology: Methods and applications[J]. Advances in Psychological Science, 2023, 31(6): 887-904.
| 方法/模型 | 运算处理对象 | 向量生成方法 | 维度数值含义 |
|---|---|---|---|
| 词分布表示 | (小规模语料) | (矩阵降维) | (可解释) |
| 潜在语义分析(LSA) | 词−文档共现矩阵 | 奇异值分解(SVD) | 独立的潜在语义特征 |
| 主题模型(Topic Model) | 词−文档共现矩阵 | 潜在狄利克雷分配(LDA) | 词出现于主题的概率 |
| 词嵌入表示[提出年份] | (大规模语料) | (训练预测) | (不可解释) |
| 静态词嵌入模型 | (不随上下文变化) | ||
| Word2Vec[2013] | 词−上下文局部窗口 | 浅层(单层)神经网络 | 神经网络隐含层权重 |
| − CBOW子模型 | — | (根据上下文预测中心词) | — |
| − SG/SGNS子模型 | — | (根据中心词预测上下文) | — |
| GloVe[2014] | 词−上下文共现矩阵 | 加权最小二乘回归 | 回归迭代求解的参数 |
| FastText[2016] | 字符级n-gram窗口 | 浅层(单层)神经网络 | 神经网络隐含层权重 |
| − CBOW子模型 | — | (根据上下文预测中心词) | — |
| − SG/SGNS子模型 | — | (根据中心词预测上下文) | — |
| 动态词嵌入(语言)模型 | (上下文相关) | ||
| ELMo[2018] | 字符级文本序列 | 卷积神经网络+双向语言模型 | 隐含层输出权重组合 |
| GPT[2018] | 词−上文文本序列 | 深层单向转换解码器 | 隐含层输出权重组合 |
| BERT[2018] | 子词文本序列 | 深层双向转换编码器 | 隐含层输出权重组合 |
| 方法/模型 | 运算处理对象 | 向量生成方法 | 维度数值含义 |
|---|---|---|---|
| 词分布表示 | (小规模语料) | (矩阵降维) | (可解释) |
| 潜在语义分析(LSA) | 词−文档共现矩阵 | 奇异值分解(SVD) | 独立的潜在语义特征 |
| 主题模型(Topic Model) | 词−文档共现矩阵 | 潜在狄利克雷分配(LDA) | 词出现于主题的概率 |
| 词嵌入表示[提出年份] | (大规模语料) | (训练预测) | (不可解释) |
| 静态词嵌入模型 | (不随上下文变化) | ||
| Word2Vec[2013] | 词−上下文局部窗口 | 浅层(单层)神经网络 | 神经网络隐含层权重 |
| − CBOW子模型 | — | (根据上下文预测中心词) | — |
| − SG/SGNS子模型 | — | (根据中心词预测上下文) | — |
| GloVe[2014] | 词−上下文共现矩阵 | 加权最小二乘回归 | 回归迭代求解的参数 |
| FastText[2016] | 字符级n-gram窗口 | 浅层(单层)神经网络 | 神经网络隐含层权重 |
| − CBOW子模型 | — | (根据上下文预测中心词) | — |
| − SG/SGNS子模型 | — | (根据中心词预测上下文) | — |
| 动态词嵌入(语言)模型 | (上下文相关) | ||
| ELMo[2018] | 字符级文本序列 | 卷积神经网络+双向语言模型 | 隐含层输出权重组合 |
| GPT[2018] | 词−上文文本序列 | 深层单向转换解码器 | 隐含层输出权重组合 |
| BERT[2018] | 子词文本序列 | 深层双向转换编码器 | 隐含层输出权重组合 |

| 应用形式 | 具体分析指标 | 用途特点 | 利用的语义信息 |
|---|---|---|---|
| 词向量 | |||
| 原始值 | 数值向量 | 作为机器学习模型(比如岭回归)的输入参数, 预测个体的认知判断、大脑活动等 | 语义表征 |
| 线性运算结果 | 相加后的向量总和、相减后的向量差异 | 作为语义共性或语义差异的量化表示, 或以向量差异建立一个心理概念维度两极的坐标系, 计算与其他心理概念间的语义联系 | 语义共性和差异的表征 |
| 词向量的关系 | |||
| 绝对相似度 | 余弦相似度、欧氏距离 | 作为词汇或概念间语义联系的直接测量指标, 测量个体的发散思维水平(远距离联想)等 | 语义关联或距离 |
| 相对相似度 | 词嵌入联系测验(WEAT)、单类词嵌入联系测验(SC-WEAT)、相对范数(欧氏)距离(RND) | 作为词汇或概念间语义联系的相对测量指标, 测量复杂概念间的联系, 如群体的社会态度、偏见、刻板印象、文化与心理的联系等 | 语义关联或距离 |
| 应用形式 | 具体分析指标 | 用途特点 | 利用的语义信息 |
|---|---|---|---|
| 词向量 | |||
| 原始值 | 数值向量 | 作为机器学习模型(比如岭回归)的输入参数, 预测个体的认知判断、大脑活动等 | 语义表征 |
| 线性运算结果 | 相加后的向量总和、相减后的向量差异 | 作为语义共性或语义差异的量化表示, 或以向量差异建立一个心理概念维度两极的坐标系, 计算与其他心理概念间的语义联系 | 语义共性和差异的表征 |
| 词向量的关系 | |||
| 绝对相似度 | 余弦相似度、欧氏距离 | 作为词汇或概念间语义联系的直接测量指标, 测量个体的发散思维水平(远距离联想)等 | 语义关联或距离 |
| 相对相似度 | 词嵌入联系测验(WEAT)、单类词嵌入联系测验(SC-WEAT)、相对范数(欧氏)距离(RND) | 作为词汇或概念间语义联系的相对测量指标, 测量复杂概念间的联系, 如群体的社会态度、偏见、刻板印象、文化与心理的联系等 | 语义关联或距离 |
| 语料库 | 预训练算法模型 | ||
|---|---|---|---|
| Word2Vec (SGNS) | GloVe | FastText | |
| 谷歌新闻 (Google News) | √ | ||
| 谷歌图书 (Google Books) | √(多语种、分年代) | ||
| 美式英语历史语料 (COHA) | √(分年代) | ||
| 维基百科 (Wikipedia) | √(多语种) | √ | √(多语种) |
| 共享网络爬虫 (Common Crawl) | √ | √(多语种) | |
| 新闻报道千兆语料 (Gigaword) | √ | ||
| 推特(Twitter) | √ | ||
| 百度百科 | √(汉语) | ||
| 新浪微博 | √(汉语) | ||
| 人民日报 | √(汉语) | ||
| 搜狗新闻 | √(汉语) | ||
| 知乎问答 | √(汉语) | ||
| 四库全书 | √(古代汉语) | ||
| 语料库 | 预训练算法模型 | ||
|---|---|---|---|
| Word2Vec (SGNS) | GloVe | FastText | |
| 谷歌新闻 (Google News) | √ | ||
| 谷歌图书 (Google Books) | √(多语种、分年代) | ||
| 美式英语历史语料 (COHA) | √(分年代) | ||
| 维基百科 (Wikipedia) | √(多语种) | √ | √(多语种) |
| 共享网络爬虫 (Common Crawl) | √ | √(多语种) | |
| 新闻报道千兆语料 (Gigaword) | √ | ||
| 推特(Twitter) | √ | ||
| 百度百科 | √(汉语) | ||
| 新浪微博 | √(汉语) | ||
| 人民日报 | √(汉语) | ||
| 搜狗新闻 | √(汉语) | ||
| 知乎问答 | √(汉语) | ||
| 四库全书 | √(古代汉语) | ||
| 编程语言-工具包 | 可实现的预训练算法 | 其他功能 |
|---|---|---|
| MATLAB | ||
| Text Analytics Toolbox | Word2Vec | 文本预处理、传统文本分析(词袋模型、潜在语义分析LSA、主题模型LDA等)、文本相似度计算、文本情感分析、词云图绘制等 |
| Python | ||
| gensim库 | Word2Vec、FastText | 文本预处理、传统文本分析(词袋模型、潜在语义分析LSA、主题模型LDA等) |
| fasttext库 | FastText | 有监督的文本分类 |
| allennlp库 | ELMo | 多种NLP下游任务 |
| openai库 | GPT | 多种NLP下游任务 |
| transformers库 | GPT、BERT等 | 预训练语言模型的调用和分析 |
| R | ||
| word2vec包 | Word2Vec | — |
| text2vec包 | GloVe | 分词预处理、潜在语义分析LSA、主题模型LDA |
| fastTextR包 | FastText | — |
| wordsalad包 | Word2Vec、GloVe、 FastText (整合前3个包) | — |
| sweater包 | — | 概念联系测量(WEAT、RND等)的统计分析 |
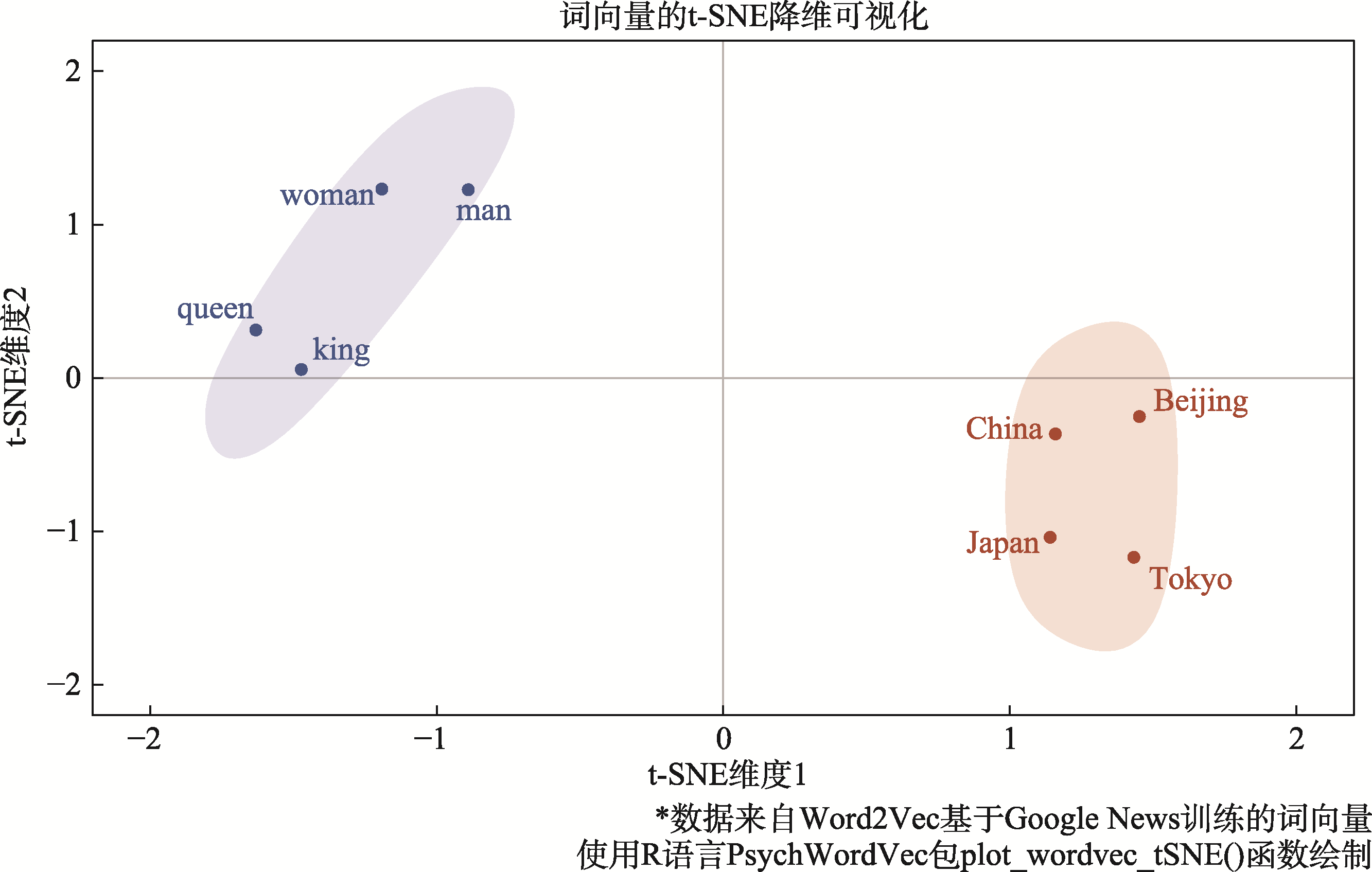
| PsychWordVec包 | Word2Vec、GloVe、 FastText (整合上述R包) | 词向量数据的统一管理、词向量可视化和t-SNE降维、词相似度计算、WEAT (SC-WEAT)与RND分析和统计检验、词向量网络分析、不同词嵌入矩阵的正交对齐、预训练语言模型(如GPT和BERT)的调用等 |
| 编程语言-工具包 | 可实现的预训练算法 | 其他功能 |
|---|---|---|
| MATLAB | ||
| Text Analytics Toolbox | Word2Vec | 文本预处理、传统文本分析(词袋模型、潜在语义分析LSA、主题模型LDA等)、文本相似度计算、文本情感分析、词云图绘制等 |
| Python | ||
| gensim库 | Word2Vec、FastText | 文本预处理、传统文本分析(词袋模型、潜在语义分析LSA、主题模型LDA等) |
| fasttext库 | FastText | 有监督的文本分类 |
| allennlp库 | ELMo | 多种NLP下游任务 |
| openai库 | GPT | 多种NLP下游任务 |
| transformers库 | GPT、BERT等 | 预训练语言模型的调用和分析 |
| R | ||
| word2vec包 | Word2Vec | — |
| text2vec包 | GloVe | 分词预处理、潜在语义分析LSA、主题模型LDA |
| fastTextR包 | FastText | — |
| wordsalad包 | Word2Vec、GloVe、 FastText (整合前3个包) | — |
| sweater包 | — | 概念联系测量(WEAT、RND等)的统计分析 |
| PsychWordVec包 | Word2Vec、GloVe、 FastText (整合上述R包) | 词向量数据的统一管理、词向量可视化和t-SNE降维、词相似度计算、WEAT (SC-WEAT)与RND分析和统计检验、词向量网络分析、不同词嵌入矩阵的正交对齐、预训练语言模型(如GPT和BERT)的调用等 |
| [1] |
蔡华俭, 黄梓航, 林莉, 张明杨, 王潇欧, 朱慧珺, … 敬一鸣. (2020). 半个多世纪来中国人的心理与行为变化——心理学视野下的研究. 心理科学进展, 28(10), 1599-1688.
doi: 10.3724/SP.J.1042.2020.01599 |
| [2] |
蔡华俭, 张明杨, 包寒吴霜, 朱慧珺, 杨紫嫣, 程曦, … 王梓西. (2023). 心理学视野下的社会变迁研究: 研究设计与分析方法. 心理科学进展, 31(2), 159-172.
doi: 10.3724/SP.J.1042.2023.00159 |
| [3] | 车万翔, 郭江, 崔一鸣. (2021). 自然语言处理: 基于预训练模型的方法. 北京: 电子工业出版社. |
| [4] | 陈萌, 和志强, 王梦雪. (2021). 词嵌入模型研究综述. 河北省科学院学报, 38(2), 8-16. |
| [5] |
黄梓航, 敬一鸣, 喻丰, 古若雷, 周欣悦, 张建新, 蔡华俭. (2018). 个人主义上升, 集体主义式微? ——全球文化变迁与民众心理变化. 心理科学进展, 26(11), 2068-2080.
doi: 10.3724/SP.J.1042.2018.02068 |
| [6] |
黄梓航, 王俊秀, 苏展, 敬一鸣, 蔡华俭. (2021). 中国社会转型过程中的心理变化: 社会学视角的研究及其对心理学家的启示. 心理科学进展, 29(12), 2246-2259.
doi: 10.3724/SP.J.1042.2021.02246 |
| [7] | 王垚, 贾宝龙, 杜依宁, 张晗, 陈响. (2022). 基于词向量的多维度正则化SVM社交网络抑郁倾向检测方法. 计算机应用与软件, 39(3), 116-120. |
| [8] | 吴胜涛, 杨晨曦, 王世强, 马瑞启, 韩布新. (2020). 正义动机的他人凸显效应: 基于词嵌入联想测验的证据. 科学通报, 65(19), 2047-2054. |
| [9] | 薛栢祥. (2019). 社会媒体语言中外显及内隐社会态度的自动化分析 (硕士学位论文). 天津大学. |
| [10] |
杨紫嫣, 刘云芝, 余震坤, 蔡华俭. (2015). 内隐联系测验的应用: 国内外研究现状. 心理科学进展, 23(11), 1966-1980.
doi: 10.3724/SP.J.1042.2015.01966 |
| [11] | Agarwal, O., Durupınar, F., Badler, N. I., & Nenkova, A. (2019). Word embeddings (also) encode human personality stereotypes. In Proceedings of the Eighth Joint Conference on Lexical and Computational Semantics (pp. 205-211), Minneapolis, Minnesota. Association for Computational Linguistics. https://doi.org/10.18653/v1/S19-1023 |
| [12] |
Aka, A., & Bhatia, S. (2022). Machine learning models for predicting, understanding, and influencing health perception. Journal of the Association for Consumer Research, 7(2), 142-153.
doi: 10.1086/718456 URL |
| [13] | Arseniev-Koehler, A., Cochran, S. D., Mays, V. M., Chang, K.-W., & Foster, J. G. (2022). Integrating topic modeling and word embedding to characterize violent deaths. Proceedings of the National Academy of Sciences, 119(10), Article e2108801119. |
| [14] | Bailey, A. H., Williams, A., & Cimpian, A. (2022). Based on billions of words on the internet, PEOPLE = MEN. Science Advances, 8(13), Article eabm2463. |
| [15] | Bao, H.-W.-S. (2022). PsychWordVec: Word embedding research framework for psychological science [Computer software]. https://CRAN.R-project.org/package=PsychWordVec |
| [16] |
Bao, H.-W.-S., Cai, H., & Huang, Z. (2022). Discerning cultural shifts in China? Commentary on Hamamura et al. (2021). American Psychologist, 77(6), 786-788.
doi: 10.1037/amp0001013 URL |
| [17] |
Beaty, R. E., & Johnson, D. R. (2021). Automating creativity assessment with SemDis: An open platform for computing semantic distance. Behavior Research Methods, 53, 757-780.
doi: 10.3758/s13428-020-01453-w |
| [18] | Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of Machine Learning Research, 3, 1137-1155. |
| [19] |
Bhatia, N., & Bhatia, S. (2021). Changes in gender stereotypes over time: A computational analysis. Psychology of Women Quarterly, 45(1), 106-125.
doi: 10.1177/0361684320977178 URL |
| [20] |
Bhatia, S. (2017a). Associative judgment and vector space semantics. Psychological Review, 124(1), 1-20.
doi: 10.1037/rev0000047 URL |
| [21] |
Bhatia, S. (2017b). The semantic representation of prejudice and stereotypes. Cognition, 164, 46-60.
doi: 10.1016/j.cognition.2017.03.016 URL |
| [22] |
Bhatia, S. (2019a). Predicting risk perception: New insights from data science. Management Science, 65(8), 3800-3823.
doi: 10.1287/mnsc.2018.3121 URL |
| [23] |
Bhatia, S. (2019b). Semantic processes in preferential decision making. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45(4), 627-640.
doi: 10.1037/xlm0000618 URL |
| [24] |
Bhatia, S., Goodwin, G. P., & Walasek, L. (2018). Trait associations for Hillary Clinton and Donald Trump in news media: A computational analysis. Social Psychological and Personality Science, 9(2), 123-130.
doi: 10.1177/1948550617751584 URL |
| [25] | Bhatia, S., Olivola, C. Y., Bhatia, N., & Ameen, A. (2022). Predicting leadership perception with large-scale natural language data. The Leadership Quarterly, 33(5), Article 101535. |
| [26] |
Bhatia, S., Richie, R., & Zou, W. (2019). Distributed semantic representations for modeling human judgment. Current Opinion in Behavioral Sciences, 29, 31-36.
doi: 10.1016/j.cobeha.2019.01.020 |
| [27] | Blei, D. M., Ng, A.Y., & Jordan, M. I. (2003). Latent Dirichlet allocation. Journal of Machine Learning Research 3, 993-1022. |
| [28] | Bolukbasi, T., Chang, K.-W., Zou, J., Saligrama, V., & Kalai, A. (2016). Man is to computer programmer as woman is to homemaker? Debiasing word embeddings. arXiv. https://doi.org/10.48550/arXiv.1607.06520 |
| [29] |
Caliskan, A., Bryson, J. J., & Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334), 183-186.
doi: 10.1126/science.aal4230 pmid: 28408601 |
| [30] | Charlesworth, T. E. S., Caliskan, A., & Banaji, M. R. (2022). Historical representations of social groups across 200 years of word embeddings from Google Books. Proceedings of the National Academy of Sciences, 119(28), Article e2121798119. |
| [31] |
Charlesworth, T. E. S., Yang, V., Mann, T. C., Kurdi, B., & Banaji, M. R. (2021). Gender stereotypes in natural language: Word embeddings show robust consistency across child and adult language corpora of more than 65 million words. Psychological Science, 32(2), 218-240.
doi: 10.1177/0956797620963619 pmid: 33400629 |
| [32] |
Chen, H., Yang, C., Zhang, X., Liu, Z., Sun, M., & Jin, J. (2021). From symbols to embeddings: A tale of two representations in computational social science. Journal of Social Computing, 2(2), 103-156.
doi: 10.23919/JSC.2021.0011 URL |
| [33] | Cutler, A., & Condon, D. M. (2023). Deep lexical hypothesis: Identifying personality structure in natural language. Journal of Personality and Social Psychology. Advance online publication. https://doi.org/10.1037/pspp0000443 |
| [34] |
DeFranza, D., Mishra, H., & Mishra, A. (2020). How language shapes prejudice against women: An examination across 45 world languages. Journal of Personality and Social Psychology, 119(1), 7-22.
doi: 10.1037/pspa0000188 pmid: 32077734 |
| [35] | Du, Y., Fang, Q., & Nguyen, D. (2021). Assessing the reliability of word embedding gender bias measures. arXiv. https://doi.org/10.48550/arXiv.2109.04732 |
| [36] |
Durrheim, K., Schuld, M., Mafunda, M., & Mazibuko, S. (2023). Using word embeddings to investigate cultural biases. British Journal of Social Psychology, 62(1), 617-629.
doi: 10.1111/bjso.v62.1 URL |
| [37] |
Gandhi, N., Zou, W., Meyer, C., Bhatia, S., & Walasek, L. (2022). Computational methods for predicting and understanding food judgment. Psychological Science, 33(4), 579-594.
doi: 10.1177/09567976211043426 pmid: 35298316 |
| [38] | Garg, N., Schiebinger, L., Jurafsky, D., & Zou, J. (2018). Word embeddings quantify 100 years of gender and ethnic stereotypes. Proceedings of the National Academy of Sciences, 115(16), E3635-E3644. |
| [39] |
Grand, G., Blank, I. A., Pereira, F., & Fedorenko, E. (2022). Semantic projection recovers rich human knowledge of multiple object features from word embeddings. Nature Human Behaviour, 6(7), 975-987.
doi: 10.1038/s41562-022-01316-8 pmid: 35422527 |
| [40] | Grave, E., Bojanowski, P., Gupta, P., Joulin, A., & Mikolov, T. (2018). Learning word vectors for 157 languages. arXiv. https://doi.org/10.48550/arXiv.1802.06893 |
| [41] |
Greenwald, A. G., McGhee, D. E., & Schwartz, J. L. K. (1998). Measuring individual differences in implicit cognition: The Implicit Association Test. Journal of Personality and Social Psychology, 74(6), 1464-1480.
doi: 10.1037//0022-3514.74.6.1464 pmid: 9654756 |
| [42] |
Griffiths, T. L., Steyvers, M., & Tenenbaum, J. B. (2007). Topics in semantic representation. Psychological Review, 114(2), 211-244.
pmid: 17500626 |
| [43] | Guo, W., & Caliskan, A. (2021). Detecting emergent intersectional biases: Contextualized word embeddings contain a distribution of human-like biases. arXiv. https://doi.org/10.48550/arXiv.2006.03955 |
| [44] |
Günther, F., Rinaldi, L., & Marelli, M. (2019). Vector-space models of semantic representation from a cognitive perspective: A discussion of common misconceptions. Perspectives on Psychological Science, 14(6), 1006-1033.
doi: 10.1177/1745691619861372 pmid: 31505121 |
| [45] |
Hamamura, T., Chen, Z., Chan, C. S., Chen, S. X., & Kobayashi, T. (2021). Individualism with Chinese characteristics? Discerning cultural shifts in China using 50 years of printed texts. American Psychologist, 76(6), 888-903.
doi: 10.1037/amp0000840 pmid: 34914428 |
| [46] | Hamilton, W. L., Leskovec, J., & Jurafsky, D. (2016). Diachronic word embeddings reveal statistical laws of semantic change. arXiv. https://doi.org/10.48550/arXiv.1605.09096 |
| [47] | Harris, Z. S. (1954). Distributional structure. Words, 10(2-3), 146-162. |
| [48] |
Heinen, D. J. P., & Johnson, D. R. (2018). Semantic distance: An automated measure of creativity that is novel and appropriate. Psychology of Aesthetics, Creativity, and the Arts, 12(2), 144-156.
doi: 10.1037/aca0000125 URL |
| [49] |
Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science, 313(5786), 504-507.
doi: 10.1126/science.1127647 pmid: 16873662 |
| [50] |
Hirschberg, J., & Manning, C. D. (2015). Advances in natural language processing. Science, 349(6245), 261-266.
doi: 10.1126/science.aaa8685 pmid: 26185244 |
| [51] |
Huth, A. G., de Heer, W. A., Griffiths, T. L., Theunissen, F. E., & Gallant, J. L. (2016). Natural speech reveals the semantic maps that tile human cerebral cortex. Nature, 532(7600), 453-458.
doi: 10.1038/nature17637 |
| [52] | Izzidien, A. (2022). Word vector embeddings hold social ontological relations capable of reflecting meaningful fairness assessments. AI & Society, 37, 299-318. |
| [53] |
Jackson, J. C., Gelfand, M., De, S., & Fox, A. (2019). The loosening of American culture over 200 years is associated with a creativity-order trade-off. Nature Human Behaviour, 3(3), 244-250.
doi: 10.1038/s41562-018-0516-z pmid: 30953010 |
| [54] |
Jackson, J. C., Watts, J., List, J.-M., Puryear, C., Drabble, R., & Lindquist, K. A. (2022). From text to thought: How analyzing language can advance psychological science. Perspectives on Psychological Science, 17(3), 805-826.
doi: 10.1177/17456916211004899 URL |
| [55] |
Johnson, D. R., Cuthbert, A. S., & Tynan, M. E. (2021). The neglect of idea diversity in creative idea generation and evaluation. Psychology of Aesthetics, Creativity, and the Arts, 15(1), 125-135.
doi: 10.1037/aca0000235 URL |
| [56] | Jonauskaite, D., Sutton, A., Cristianini, N., & Mohr, C. (2021). English colour terms carry gender and valence biases: A corpus study using word embeddings. PLoS ONE, 16(6), Article e0251559. |
| [57] | Joseph, K., & Morgan, J. H. (2020). When do word embeddings accurately reflect surveys on our beliefs about people? arXiv. https://doi.org/10.48550/arXiv.2004.12043 |
| [58] | Kalyan, K. S., & Sangeetha, S. (2020). SECNLP: A survey of embeddings in clinical natural language processing. Journal of Biomedical Informatics, 101, Article 103323. |
| [59] |
Karpinski, A., & Steinman, R. B. (2006). The Single Category Implicit Association Test as a measure of implicit social cognition. Journal of Personality and Social Psychology, 91(1), 16-32.
doi: 10.1037/0022-3514.91.1.16 pmid: 16834477 |
| [60] |
Kozlowski, A. C., Taddy, M., & Evans, J. A. (2019). The geometry of culture: Analyzing the meanings of class through word embeddings. American Sociological Review, 84(5), 905-949.
doi: 10.1177/0003122419877135 |
| [61] | Kroon, A. C., Trilling, D., & Raats, T. (2021). Guilty by association: Using word embeddings to measure ethnic stereotypes in news coverage. Journalism & Mass Communication Quarterly, 98(2), 451-477. |
| [62] |
Kurdi, B., Mann, T. C., Charlesworth, T. E. S., & Banaji, M. R. (2019). The relationship between implicit intergroup attitudes and beliefs. Proceedings of the National Academy of Sciences, 116(13), 5862-5871.
doi: 10.1073/pnas.1820240116 URL |
| [63] | Kurpicz-Briki, M., & Leoni, T. (2021). A world full of stereotypes? Further investigation on origin and gender bias in multi-lingual word embeddings. Frontiers in Big Data, 4, Article 625290. |
| [64] | Lake, B. M., & Murphy, G. L. (2021). Word meaning in minds and machines. Psychological Review. Advance online publication. https://doi.org/10.1037/rev0000297 |
| [65] |
Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104(2), 211-240.
doi: 10.1037/0033-295X.104.2.211 URL |
| [66] | Lawson, M. A., Martin, A. E., Huda, I., & Matz, S. C. (2022). Hiring women into senior leadership positions is associated with a reduction in gender stereotypes in organizational language. Proceedings of the National Academy of Sciences, 119(9), Article e2026443119. |
| [67] |
Lazer, D., Pentland, A., Adamic, L., Aral, S., Barabási, A.-L., Brewer, D., … van Alstyne, M. (2009). Computational social science. Science, 323(5915), 721-723.
doi: 10.1126/science.1167742 URL |
| [68] |
Lazer, D. M. J., Pentland, A., Watts, D. J., Aral, S., Athey, S., Contractor, N., … Wagner, C. (2020). Computational social science: Obstacles and opportunities. Science, 369(6507), 1060-1062.
doi: 10.1126/science.aaz8170 pmid: 32855329 |
| [69] | Le, T. H., Arcodia, C., Abreu Novais, M., Kralj, A., & Phan, T. C. (2021). Exploring the multi-dimensionality of authenticity in dining experiences using online reviews. Tourism Management, 85, Article 104292. |
| [70] |
Lee, K., Braithwaite, J., & Atchikpa, M. (2021). Word embedding analysis on colonial history, present issues, and optimism toward the future in Senegal. Computational and Mathematical Organization Theory, 27(3), 343-356.
doi: 10.1007/s10588-021-09335-y |
| [71] |
Lenci, A. (2018). Distributional models of word meaning. Annual Review of Linguistics, 4, 151-171.
doi: 10.1146/linguistics.2018.4.issue-1 URL |
| [72] |
Lewis, M., & Lupyan, G. (2020). Gender stereotypes are reflected in the distributional structure of 25 languages. Nature Human Behaviour, 4, 1021-1028.
doi: 10.1038/s41562-020-0918-6 |
| [73] |
Li, H.-X., Lu, B., Chen, X., Li, X.-Y., Castellanos, F. X., & Yan, C.-G. (2022). Exploring self-generated thoughts in a resting state with natural language processing. Behavior Research Methods, 54, 1725-1743.
doi: 10.3758/s13428-021-01710-6 |
| [74] | Li, M.-H., Li, P.-W., & Rao, L.-L. (2021). Self-other moral bias: Evidence from implicit measures and the Word- Embedding Association Test. Personality and Individual Differences, 183, Article 111107. |
| [75] |
Li, Y., Engelthaler, T., Siew, C. S. Q., & Hills, T. T. (2019). The Macroscope: A tool for examining the historical structure of language. Behavior Research Methods, 51, 1864-1877.
doi: 10.3758/s13428-018-1177-6 pmid: 30746643 |
| [76] | Li, Y., Hills, T., & Hertwig, R. (2020). A brief history of risk. Cognition, 203, Article 104344. |
| [77] |
Li, Y., & Siew, C. S. Q. (2022). Diachronic semantic change in language is constrained by how people use and learn language. Memory & Cognition, 50(6), 1284-1298.
doi: 10.3758/s13421-022-01331-0 |
| [78] | Lin, L., Chen, X., Shen, Y., & Zhang, L. (2020). Towards automatic depression detection: A BiLSTM/1D CNN- based model. Applied Sciences, 10(23), Article 8701. |
| [79] | Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv. https://doi.org/10.48550/arXiv.1301.3781 |
| [80] |
Nicolas, G., Bai, X., & Fiske, S. T. (2021). Comprehensive stereotype content dictionaries using a semi-automated method. European Journal of Social Psychology, 51(1), 178-196.
doi: 10.1002/ejsp.v51.1 URL |
| [81] | Olson, J. A., Nahas, J., Chmoulevitch, D., Cropper, S. J., & Webb, M. E. (2021). Naming unrelated words predicts creativity. Proceedings of the National Academy of Sciences, 118(25), Article e2022340118. |
| [82] | Prystawski, B., Grant, E., Nematzadeh, A., Lee, S. W. S., Stevenson, S., & Xu, Y. (2020). Tracing the emergence of gendered language in childhood. In S.Denison, M.Mack, Y.Xu, & B. C.Armstrong (Eds.), Proceedings of the 42nd Annual Conference of the Cognitive Science Society (pp. 1087-1093). Cognitive Science Society. https://cognitive sciencesociety.org/cogsci20/papers/0190/0190.pdf |
| [83] |
Rheault, L., & Cochrane, C. (2020). Word embeddings for the analysis of ideological placement in parliamentary corpora. Political Analysis, 28(1), 112-133.
doi: 10.1017/pan.2019.26 URL |
| [84] | Rice, D., Rhodes, J. H., & Nteta, T. (2019). Racial bias in legal language. Research and Politics, 6(2), 1-7. |
| [85] | Richie, R., & Bhatia, S. (2021). Similarity judgment within and across categories: A comprehensive model comparison. Cognitive Science, 45(8), Article e13030. |
| [86] | Richie, R., Zou, W., & Bhatia, S. (2019). Predicting high- level human judgment across diverse behavioral domains. Collabra: Psychology, 5(1), Article 50. |
| [87] |
Rodman, E. (2020). A timely intervention: Tracking the changing meanings of political concepts with word vectors. Political Analysis, 28(1), 87-111.
doi: 10.1017/pan.2019.23 URL |
| [88] |
Rozado, D., & al-Gharbi, M. (2022). Using word embeddings to probe sentiment associations of politically loaded terms in news and opinion articles from news media outlets. Journal of Computational Social Science, 5, 427-448.
doi: 10.1007/s42001-021-00130-y |
| [89] | Salas-Zárate, R., Alor-Hernández, G., Salas-Zárate, M. d. P., Paredes-Valverde, M. A., Bustos-López, M., & Sánchez-Cervantes, J. L. (2022). Detecting depression signs on social media: A systematic literature review. Healthcare, 10(2), Article 291. |
| [90] |
Schönemann, P. H. (1966). A generalized solution of the orthogonal Procrustes problem. Psychometrika, 31(1), 1-10.
doi: 10.1007/BF02289451 URL |
| [91] |
Thompson, B., Roberts, S. G., & Lupyan, G. (2020). Cultural influences on word meanings revealed through large-scale semantic alignment. Nature Human Behaviour, 4, 1029-1038.
doi: 10.1038/s41562-020-0924-8 |
| [92] | Toney-Wails, A., & Caliskan, A. (2021). ValNorm quantifies semantics to reveal consistent valence biases across languages and over centuries. arXiv. https://doi.org/10.48550/arXiv.2006.03950 |
| [93] |
Tsai, J. L. (2007). Ideal affect: Cultural causes and behavioral consequences. Perspectives on Psychological Science, 2(3), 242-259.
doi: 10.1111/j.1745-6916.2007.00043.x pmid: 26151968 |
| [94] | Utsumi, A. (2020). Exploring what is encoded in distributional word vectors: A neurobiologically motivated analysis. Cognitive Science, 44(6), Article e12844. |
| [95] | van der Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9, 2579-2605. |
| [96] | Wang, B., Xue, B., & Greenwald, A. G. (2019). Can we derive explicit and implicit bias from corpus? arXiv. https://doi.org/10.48550/arXiv.1905.13364 |
| [97] | Xie, J. Y., Pinto, R. F., Jr., Hirst, G., & Xu, Y. (2019). Text-based inference of moral sentiment change. arXiv. https://doi.org/10.48550/arXiv.2001.07209 |
| [98] | Xu, H., Zhang, Z., Wu, L., & Wang, C.-J. (2019). The Cinderella Complex: Word embeddings reveal gender stereotypes in movies and books. PLoS ONE, 14(11), Article e0225385. |
| [99] | Zhang, Y., Han, K., Worth, R., & Liu, Z. (2020). Connecting concepts in the brain by mapping cortical representations of semantic relations. Nature Communications, 11, Article 1877. |
| [100] | Zou, W., & Bhatia, S. (2021). Judgment errors in naturalistic numerical estimation. Cognition, 211, Article 104647. |
| [1] | ZHANG Xiangyang, WANG Xiaojuan, YANG Jianfeng. The role of the left Angular Gyrus in lexical-semantic processing [J]. Advances in Psychological Science, 2024, 32(4): 616-626. |
| [2] | JIANG Jiahao, ZHAO Guoyu, MA Yingbo, DING Guosheng, LIU Lanfang. Distributed representation of semantics in the human brain: Evidence from studies using natural language processing techniques [J]. Advances in Psychological Science, 2023, 31(6): 1002-1019. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||