ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
心理科学进展 ›› 2025, Vol. 33 ›› Issue (12): 2027-2042.doi: 10.3724/SP.J.1042.2025.2027 cstr: 32111.14.2025.2027
• 第二十七届中国科协年会学术论文 • 下一篇
杜传晨1, 郑远霞1,2, 郭倩倩1, 刘国雄1( )
)
收稿日期:2025-05-10
出版日期:2025-12-15
发布日期:2025-10-27
通讯作者:
刘国雄, E-mail: 17219367@qq.com基金资助:
DU Chuanchen1, ZHENG Yuanxia1,2, GUO Qianqian1, LIU Guoxiong1()
Received:2025-05-10
Online:2025-12-15
Published:2025-10-27
摘要:
传统观点认为, 心理理论是有意识的生物独有的社会认知能力。然而, 近来迅速发展的大语言模型能够解决多种心理理论任务, 这引发了关于其是否具有心理理论的激烈争议。大语言模型的人工心理理论在表现上与心理理论类似, 但内部过程不同。本文首先从评估对象和任务特征两个方面系统梳理人工心理理论研究, 通过综合分析GPT-4在心理理论任务中的较高通过率及使其表现受限的内外因素, 指出当前模型的心理理论表现与人类相似。其次, 通过深入对比支撑心理理论与人工心理理论的神经基础和发展因素, 揭示二者的内部过程存在本质差异, 进而补充了人工心理理论的定义。未来研究应关注制定并采用标准化的评估方案, 在共同心理理论框架下探究人工心理理论机制, 以及与人类心理理论对齐。
中图分类号:
杜传晨, 郑远霞, 郭倩倩, 刘国雄. (2025). 大语言模型的人工心理理论: 证据、界定与挑战. 心理科学进展 , 33(12), 2027-2042.
DU Chuanchen, ZHENG Yuanxia, GUO Qianqian, LIU Guoxiong. (2025). Artificial theory of mind in large language models: Evidence, conceptualization, and challenges. Advances in Psychological Science, 33(12), 2027-2042.
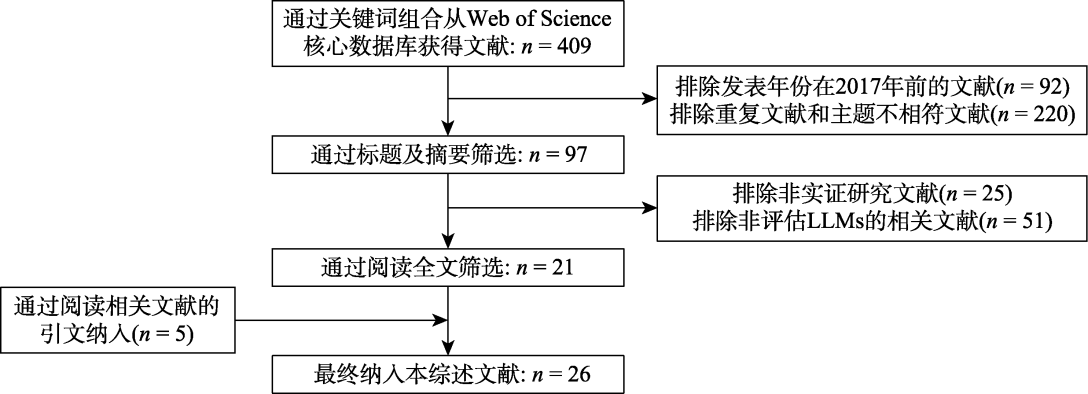
图1 文献检索与筛选流程
| 文献 | LLMs | 人类被试 | 定制任务 | 模态 | ATOMS心理状态 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 一阶 信念 | 高阶 信念 | 行动 意图 | 交流 意图 | 愿望 | 情感 | 知识 | 感知 | 非字面交际 | |||||
| Sap et al., | GPT-3 | 文本 | √ | ||||||||||
| Trott et al., | GPT-3 | √ | 文本 | √ | |||||||||
| Van Duijn et al., | GPT-3, 3.5, 4; Llama等 | √ | 文本 | √ | √ | √ | √ | ||||||
| Shapira et al., | GPT3 | 文本 | √ | √ | |||||||||
| He et al., | GPT-3.5, 4 | √ | 文本 | √ | √ | ||||||||
| Kim et al., | GPT-3.5, 4; Llama-2等 | √ | √ | 文本 | √ | √ | √ | ||||||
| Li et al., | GPT-3.5, 4 | √ | 文本 | √ | √ | √ | √ | ||||||
| Sileo & Lernould, | GPT-3, 3.5, 4 | √ | √ | 文本 | √ | √ | |||||||
| Ma et al., | GPT-3.5, 4 | 文本 | √ | √ | |||||||||
| Ullman, | GPT-3.5 | 文本 | √ | ||||||||||
| Gandhi et al., | GPT-3.5, 4; Claude等 | √ | 文本 | √ | √ | √ | √ | ||||||
| Brunet-Gouet et al., | GPT-3.5, 4 | 文本 | √ | √ | √ | √ | |||||||
| Jones et al., | GPT-3 | √ | 文本 | √ | √ | √ | √ | √ | √ | ||||
| Verma et al., | GPT-3.5, 4 | √ | √ | 视觉; 文本 | √ | √ | √ | ||||||
| Wilf et al., | GPT-3.5, 4; Llama-2等 | √ | 文本 | √ | √ | √ | √ | ||||||
| Shapira et al., | GPT-3.5, 4; Flan等 | √ | 文本 | √ | √ | √ | √ | √ | |||||
| Strachan et al., | GPT-3.5, 4; Llama-2 | √ | 文本 | √ | √ | √ | √ | ||||||
| Chen et al., | GPT-4 | √ | √ | 文本 | √ | √ | √ | √ | √ | √ | √ | ||
| Jin et al., | GPT-3.5, 4; Llama-2等 | √ | √ | 视觉; 文本 | √ | √ | √ | ||||||
| Xu et al., | GPT-3.5, 4; Mixtral等 | √ | 文本 | √ | √ | √ | √ | √ | √ | ||||
| Yongsatianchot et al., | GPT-4; Claude3等 | √ | 文本 | √ | √ | √ | √ | √ | |||||
| Amirizaniani et al., | GPT-4; Llama-2等 | √ | √ | 文本 | √ | √ | |||||||
| Attanasio et al., | GPT-3.5, 4 | √ | 文本 | √ | √ | ||||||||
| Kosinski, | GPT-1, 2, 3, 3.5, 4等 | 文本 | √ | ||||||||||
| Nickel et al., | Llama-2; Mixtral等 | √ | 文本 | √ | √ | ||||||||
| Ünlütabak & Bal, | GPT-3.5, 4 | 文本 | √ | √ | |||||||||
表1 人工心理理论研究总结
| 文献 | LLMs | 人类被试 | 定制任务 | 模态 | ATOMS心理状态 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 一阶 信念 | 高阶 信念 | 行动 意图 | 交流 意图 | 愿望 | 情感 | 知识 | 感知 | 非字面交际 | |||||
| Sap et al., | GPT-3 | 文本 | √ | ||||||||||
| Trott et al., | GPT-3 | √ | 文本 | √ | |||||||||
| Van Duijn et al., | GPT-3, 3.5, 4; Llama等 | √ | 文本 | √ | √ | √ | √ | ||||||
| Shapira et al., | GPT3 | 文本 | √ | √ | |||||||||
| He et al., | GPT-3.5, 4 | √ | 文本 | √ | √ | ||||||||
| Kim et al., | GPT-3.5, 4; Llama-2等 | √ | √ | 文本 | √ | √ | √ | ||||||
| Li et al., | GPT-3.5, 4 | √ | 文本 | √ | √ | √ | √ | ||||||
| Sileo & Lernould, | GPT-3, 3.5, 4 | √ | √ | 文本 | √ | √ | |||||||
| Ma et al., | GPT-3.5, 4 | 文本 | √ | √ | |||||||||
| Ullman, | GPT-3.5 | 文本 | √ | ||||||||||
| Gandhi et al., | GPT-3.5, 4; Claude等 | √ | 文本 | √ | √ | √ | √ | ||||||
| Brunet-Gouet et al., | GPT-3.5, 4 | 文本 | √ | √ | √ | √ | |||||||
| Jones et al., | GPT-3 | √ | 文本 | √ | √ | √ | √ | √ | √ | ||||
| Verma et al., | GPT-3.5, 4 | √ | √ | 视觉; 文本 | √ | √ | √ | ||||||
| Wilf et al., | GPT-3.5, 4; Llama-2等 | √ | 文本 | √ | √ | √ | √ | ||||||
| Shapira et al., | GPT-3.5, 4; Flan等 | √ | 文本 | √ | √ | √ | √ | √ | |||||
| Strachan et al., | GPT-3.5, 4; Llama-2 | √ | 文本 | √ | √ | √ | √ | ||||||
| Chen et al., | GPT-4 | √ | √ | 文本 | √ | √ | √ | √ | √ | √ | √ | ||
| Jin et al., | GPT-3.5, 4; Llama-2等 | √ | √ | 视觉; 文本 | √ | √ | √ | ||||||
| Xu et al., | GPT-3.5, 4; Mixtral等 | √ | 文本 | √ | √ | √ | √ | √ | √ | ||||
| Yongsatianchot et al., | GPT-4; Claude3等 | √ | 文本 | √ | √ | √ | √ | √ | |||||
| Amirizaniani et al., | GPT-4; Llama-2等 | √ | √ | 文本 | √ | √ | |||||||
| Attanasio et al., | GPT-3.5, 4 | √ | 文本 | √ | √ | ||||||||
| Kosinski, | GPT-1, 2, 3, 3.5, 4等 | 文本 | √ | ||||||||||
| Nickel et al., | Llama-2; Mixtral等 | √ | 文本 | √ | √ | ||||||||
| Ünlütabak & Bal, | GPT-3.5, 4 | 文本 | √ | √ | |||||||||
| 固有局限 | 表现形式 | 形成原因 |
|---|---|---|
| 幻觉 (hallucinations) | 答案包含无法从任务叙述中推断出的或与叙述相矛盾的信息; 编造不符合事实的细节和意图以补全推理过程 | 源于模型获取能力过程中的多方面因素, 贯穿数据层面、训练过程和推理阶段 |
| 超保守主义 (hyperconservatism) | 过于谨慎而拒绝对任务中角色的信念做出推断 | 模型难以自发地减少推理中的不确定性; 避免提供错误答案 |
| 常识错误 (commonsense errors) | 生成违背常识的回答, 或不具备某些常识 | 模型对常识的掌握与其在复杂推理中有效运用常识的能力割裂 |
| 捷径/伪相关 (heuristics/spurious correlations) | 利用任务描述中简单的、表面的模式解决任务 | 模型倾向于生成续写内容; 表现出过度配合性, 即假设所有输入细节都重要 |
| 时间无知 (lack of temporal information) | 对任务中主人公行为序列的时序理解存在偏差 | 模型尚未形成对时序关系的实质性理解 |
| 虚假因果推断 (spurious causal inference) | 仅基于问题的表层模式做出错误或误导性的因果推断 | 模型难以把握文本间统计关联背后的深层逻辑 |
| 长时程上下文 (long-horizon contexts) | 回答问题时忽略距离过远的上文内容 | 模型处理长文本的能力有限 |
| 推理深度不足 (insufficient reasoning depth) | 跳过一些必要的推理步骤, 将高阶问题转化为低阶问题 | 训练数据中包含较多的简单模式; 模型难以有效保持并整合多步骤信息 |
表2 GPT-4的固有局限
| 固有局限 | 表现形式 | 形成原因 |
|---|---|---|
| 幻觉 (hallucinations) | 答案包含无法从任务叙述中推断出的或与叙述相矛盾的信息; 编造不符合事实的细节和意图以补全推理过程 | 源于模型获取能力过程中的多方面因素, 贯穿数据层面、训练过程和推理阶段 |
| 超保守主义 (hyperconservatism) | 过于谨慎而拒绝对任务中角色的信念做出推断 | 模型难以自发地减少推理中的不确定性; 避免提供错误答案 |
| 常识错误 (commonsense errors) | 生成违背常识的回答, 或不具备某些常识 | 模型对常识的掌握与其在复杂推理中有效运用常识的能力割裂 |
| 捷径/伪相关 (heuristics/spurious correlations) | 利用任务描述中简单的、表面的模式解决任务 | 模型倾向于生成续写内容; 表现出过度配合性, 即假设所有输入细节都重要 |
| 时间无知 (lack of temporal information) | 对任务中主人公行为序列的时序理解存在偏差 | 模型尚未形成对时序关系的实质性理解 |
| 虚假因果推断 (spurious causal inference) | 仅基于问题的表层模式做出错误或误导性的因果推断 | 模型难以把握文本间统计关联背后的深层逻辑 |
| 长时程上下文 (long-horizon contexts) | 回答问题时忽略距离过远的上文内容 | 模型处理长文本的能力有限 |
| 推理深度不足 (insufficient reasoning depth) | 跳过一些必要的推理步骤, 将高阶问题转化为低阶问题 | 训练数据中包含较多的简单模式; 模型难以有效保持并整合多步骤信息 |
| 提示框架 | 简要叙述 | 文献 |
|---|---|---|
| 思维链 (chain of thought) | 通过向模型提供包含输入、中间推理步骤和输出的示例, 提示模型生成类似的中间步骤, 从而逐步解决问题 | Chen et al., |
| 显式信念表征 (explicit belief representations) | 提示模型实时存储与任务相关的关键信念, 并在推理过程中整合心理状态 | Amirizaniani et al., |
| 模拟心理理论 (simulated theory of mind) | 提示模型首先根据目标角色已知的信息对上下文进行筛选, 然后再回答关于其心理状态的问题 | Wilf et al., |
| 自我问答 (self-ask prompting) | 提示模型在回答初始问题前, 自省式地生成并回答后续问题, 直至得出确定结论 | Press et al., |
| 预见与反思 (foresee and reflect) | 提示模型先基于观察预测潜在未来事件, 再反思不同行动选择如何帮助角色应对潜在挑战, 最终确定最优方案 | Zhou et al., |
| 符号心理理论 (symbolic theory of mind) | 提示模型进行显式符号表征, 并对任务中多角色信念状态进行多级推理 | Sclar et al., |
| 时间心理理论 (time theory of mind) | 为任务文本添加时序维度来构建时空体系, 提示模型依据各角色在时间线上感知的事件构建时空信念状态链 | Hou et al., |
| 离散世界模型 (discrete world models) | 将任务文本分割成多个序列块, 在每块后插入要求描述角色当前信念的提示, 最后提示模型生成答案 | Huang et al., |
表3 人工心理理论研究使用的提示框架
| 提示框架 | 简要叙述 | 文献 |
|---|---|---|
| 思维链 (chain of thought) | 通过向模型提供包含输入、中间推理步骤和输出的示例, 提示模型生成类似的中间步骤, 从而逐步解决问题 | Chen et al., |
| 显式信念表征 (explicit belief representations) | 提示模型实时存储与任务相关的关键信念, 并在推理过程中整合心理状态 | Amirizaniani et al., |
| 模拟心理理论 (simulated theory of mind) | 提示模型首先根据目标角色已知的信息对上下文进行筛选, 然后再回答关于其心理状态的问题 | Wilf et al., |
| 自我问答 (self-ask prompting) | 提示模型在回答初始问题前, 自省式地生成并回答后续问题, 直至得出确定结论 | Press et al., |
| 预见与反思 (foresee and reflect) | 提示模型先基于观察预测潜在未来事件, 再反思不同行动选择如何帮助角色应对潜在挑战, 最终确定最优方案 | Zhou et al., |
| 符号心理理论 (symbolic theory of mind) | 提示模型进行显式符号表征, 并对任务中多角色信念状态进行多级推理 | Sclar et al., |
| 时间心理理论 (time theory of mind) | 为任务文本添加时序维度来构建时空体系, 提示模型依据各角色在时间线上感知的事件构建时空信念状态链 | Hou et al., |
| 离散世界模型 (discrete world models) | 将任务文本分割成多个序列块, 在每块后插入要求描述角色当前信念的提示, 最后提示模型生成答案 | Huang et al., |
| [1] | 李开阳. (2025). 弱具身、具身认知与具身AI. 自然辩证法研究, 41(3), 81-87. https://doi.org/10.19484/j.cnki.1000-8934.2025.03.014 |
| [2] | 林曦. (2025, 3月). 人工智能“幻觉”的存在主义阐释. 社会科学辑刊, (2), 81-91. |
| [3] | 舒文韬, 李睿潇, 孙天祥, 黄萱菁, 邱锡鹏. (2023). 大型语言模型:原理、实现与发展. 计算机研究与发展, 61(2), 351-361. |
| [4] | 张珺皓. (2025). 算法黑箱研究:基于认知科学的视角. 科学学研究, 43(9), 1872-1880. https://doi.org/10.16192/j.cnki.1003-2053.20250107.001 |
| [5] | 赵泽林, 程聪瑞. (2024). ChatGPT、 人类心灵与人工心灵——科辛斯基ChatGPT实验的考察与反思. 江汉论坛, (7), 99-105. |
| [6] | Amirizaniani M., Martin E., Sivachenko M., Mashhadi A., & Shah C. (2024, October). Can LLMs reason like humans? Assessing theory of mind reasoning in LLMs for open-ended questions. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (pp.34-44). Association for Computing Machinery. https://doi.org/10.1145/3627673.3679832 |
| [7] |
Aru J. (2025). Artificial intelligence and the internal processes of creativity. The Journal of Creative Behavior, 59(2), e1530. https://doi.org/10.1002/jocb.1530
doi: 10.1002/jocb.v59.2 URL |
| [8] |
Aru J., Larkum M. E., & Shine J. M. (2023). The feasibility of artificial consciousness through the lens of neuroscience. Trends in Neurosciences, 46(12), 1008-1017. https://doi.org/10.1016/j.tins.2023.09.009
doi: 10.1016/j.tins.2023.09.009 URL pmid: 37863713 |
| [9] |
Attanasio M., Mazza M., Le Donne I., Masedu F., Greco M. P., & Valenti M. (2024). Does ChatGPT have a typical or atypical theory of mind? Frontiers in Psychology, 15, 1488172. https://doi.org/10.3389/fpsyg.2024.1488172
doi: 10.3389/fpsyg.2024.1488172 URL |
| [10] | Baker C. L., Saxe R. R., & Tenenbaum J. B. (2011). Bayesian theory of mind: Modeling joint belief-desire attribution. In Proceedings of the annual meeting of the cognitive science society (Vol. 33, No. 33, pp. 2469-2474). Cognitive Science Society. |
| [11] |
Beaudoin C., Leblanc É., Gagner C., & Beauchamp M. H. (2020). Systematic review and inventory of theory of mind measures for young children. Frontiers in Psychology, 10, 2905. https://doi.org/10.3389/fpsyg.2019.02905
doi: 10.3389/fpsyg.2019.02905 URL |
| [12] |
Bendell R., Williams J., Fiore S. M., & Jentsch F. (2024). Individual and team profiling to support theory of mind in artificial social intelligence. Scientific Reports, 14(1), 12635. https://doi.org/10.1038/s41598-024-63122-8
doi: 10.1038/s41598-024-63122-8 URL |
| [13] |
Blank I. A. (2023). What are large language models supposed to model? Trends in Cognitive Sciences, 27(11), 987-989. https://doi.org/10.1016/j.tics.2023.08.006
doi: 10.1016/j.tics.2023.08.006 URL pmid: 37659920 |
| [14] |
Bridgelall R. (2024). Unraveling the mysteries of AI chatbots. Artificial Intelligence Review, 57(4), 89. https://doi.org/10.1007/s10462-024-10720-7
doi: 10.1007/s10462-024-10720-7 URL |
| [15] | Brunet-Gouet E., Vidal N., & Roux P. (2023, September). Can a conversational agent pass theory-of-mind tasks? A case study of ChatGPT with the hinting, false beliefs, and strange stories paradigms. In: J. Baratgin, B. Jacquet, & H. Yama (Eds.), Human and Artificial Rationalities (HAR 2023). Lecture Notes in Computer Science, vol 14522 (pp. 107-126). Springer, Cham. https://doi.org/10.1007/978-3-031-55245-8_7 |
| [16] |
Call J., & Tomasello M. (2008). Does the chimpanzee have a theory of mind? 30 years later. Trends in Cognitive Sciences, 12(5), 187-192. http://dx.doi.org/10.1016/j.tics.2008.02.010
doi: 10.1016/j.tics.2008.02.010 URL pmid: 18424224 |
| [17] | Chang, E. Y. (2023, December). Examining GPT-4’s capabilities and enhancement with SocraSynth. In 2023 International Conference on Computational Science and Computational Intelligence (CSCI) (pp. 7-14). IEEE. https://doi.org/10.1109/CSCI62032.2023.00009 |
| [18] | Chen Z., Wu J., Zhou J., Wen B., Bi G., Jiang G., ... Huang M. (2024, August). ToMBench: Benchmarking theory of mind in large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 15959-15983). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.847 |
| [19] | Deshpande M., & Magerko B. (2024, May). Embracing embodied social cognition in AI: Moving away from computational theory of mind. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (pp. 1-7). Association for Computing Machinery. https://doi.org/10.1145/3613905.3650998 |
| [20] |
Devine R. T., & Hughes C. (2013). Silent films and strange stories: Theory of mind, gender, and social experiences in middle childhood. Child Development, 84(3), 989-1003. https://doi.org/10.1111/cdev.12017
doi: 10.1111/cdev.12017 URL pmid: 23199139 |
| [21] | Dong Q., Li L., Dai D., Zheng C., Ma J., Li R., ... Sui Z. (2024, November). A survey on in-context learning. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp.1107-1128). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.emnlp-main.64 |
| [22] |
Duan Q., Jing Z., Zou X., Wang Y., Yang K., Zhang T., ... Yang Y. (2020). Spiking neurons with spatiotemporal dynamics and gain modulation for monolithically integrated memristive neural networks. Nature Communications, 11(1), 3399. https://doi.org/10.1038/s41467-020-17215-3
doi: 10.1038/s41467-020-17215-3 URL |
| [23] |
Ebert S. (2020). Theory of mind, language, and reading: Developmental relations from early childhood to early adolescence. Journal of Experimental Child Psychology, 191, 104739. https://doi.org/10.1016/j.jecp.2019.104739
doi: 10.1016/j.jecp.2019.104739 URL |
| [24] | Feng J., Jirsa V., & Lu W. (2024). Human brain computing and brain-inspired intelligence. National Science Review, 11(5), nwae144. https://doi.org/10.1093/nsr/nwae144 |
| [25] |
Flavell J. H. (1999). Cognitive development: Children's knowledge about the mind. Annual Review of Psychology, 50(1), 21-45. https://doi.org/10.1146/annurev.psych.50.1.21
doi: 10.1146/psych.1999.50.issue-1 URL |
| [26] |
Frank M. C. (2023). Bridging the data gap between children and large language models. Trends in Cognitive Sciences, 27(11), 990-992. https://doi.org/10.1016/j.tics.2023.08.007
doi: 10.1016/j.tics.2023.08.007 URL pmid: 37659919 |
| [27] |
Fu I. N., Chen K. L., Liu M. R., Jiang D. R., Hsieh C. L., & Lee S. C. (2023). A systematic review of measures of theory of mind for children. Developmental Review, 67, 101061. https://doi.org/10.1016/j.dr.2022.101061
doi: 10.1016/j.dr.2022.101061 URL |
| [28] | Gandhi K., Fränken J. P., Gerstenberg T., & Goodman N. D. (2023, December). Understanding social reasoning in language models with language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NIPS '23) (pp. 13518-13529). Curran Associates Inc. https://doi.org/10.48550/arXiv.2306.15448 |
| [29] |
Griffiths T. L., Zhu J. Q., Grant E., & Thomas McCoy R. (2024). Bayes in the age of intelligent machines. Current Directions in Psychological Science, 33(5), 283-291. https://doi.org/10.1177/09637214241262329
doi: 10.1177/09637214241262329 URL |
| [30] | Hagendorff T. (2024). Deception abilities emerged in large language models. Proceedings of the National Academy of Sciences, 121(24), e2317967121. https://doi.org/10.1073/pnas.2317967121 |
| [31] | He Y., Wu Y., Jia Y., Mihalcea R., Chen Y., & Deng N. (2023, December). Hi-ToM: A benchmark for evaluating higher-order theory of mind reasoning in large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 10691-10706). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-emnlp.717 |
| [32] | Hou G., Zhang W., Shen Y., Wu L., & Lu W. (2024, August). TimeToM: Temporal space is the key to unlocking the door of large language models’ theory-of-mind. In Findings of the Association for Computational Linguistics ACL 2024 (pp. 11532-11547). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-acl.685 |
| [33] | Huang L., Yu W., Ma W., Zhong W., Feng Z., Wang H., ... Liu T. (2025). A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43(2), 1-55. https://doi.org/10.1145/3703155 |
| [34] | Huang X. A., La Malfa E., Marro S., Asperti A., Cohn A. G., & Wooldridge M. J. (2024, November). A notion of complexity for theory of mind via discrete world models. In Findings of the Association for Computational Linguistics: EMNLP 2024 (pp. 2964-2983). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.findings-emnlp.167 |
| [35] | Huang Y., Zhu H., Guo T., Jiao J., Sojoudi S., Jordan M. I., ... Mei S. (2025). Generalization or hallucination? Understanding out-of-context reasoning in transformers. arxiv preprint arxiv:2506.10887. https://doi.org/10.48550/arXiv.2506.10887 |
| [36] |
Hutchins T. L., Prelock P. A., & Bonazinga L. (2012). Psychometric evaluation of the theory of mind inventory (ToMI): A study of typically developing children and children with autism spectrum disorder. Journal of Autism and Developmental Disorders, 42(3), 327-341. https://doi.org/10.1007%2Fs10803-011-1244-7
doi: 10.1007/s10803-011-1244-7 URL pmid: 21484516 |
| [37] |
Jamali M., Grannan B. L., Fedorenko E., Saxe R., Báez- Mendoza R., & Williams Z. M. (2021). Single-neuronal predictions of others’ beliefs in humans. Nature, 591(7851), 610-614. https://doi.org/10.1038/s41586-021-03184-0
doi: 10.1038/s41586-021-03184-0 URL |
| [38] |
Jiao L., Ma M., He P., Geng X., Liu X., Liu F., ... Tang X. (2025). Brain-inspired learning, perception, and cognition: A comprehensive review. IEEE Transactions on Neural Networks and Learning Systems, 36(4), 5921-5941. https://doi.org/10.1109/TNNLS.2024.3401711
doi: 10.1109/TNNLS.2024.3401711 URL |
| [39] | Jin C., Wu Y., Cao J., Xiang J., Kuo Y.-L., Hu Z., ... Shu T. (2024, August). MMToM-QA: Multimodal theory of mind question answering. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 16077-16102). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.851 |
| [40] |
Jones C. R., Trott S., & Bergen B. (2024). Comparing humans and large language models on an experimental protocol inventory for theory of mind evaluation (EPITOME). Transactions of the Association for Computational Linguistics, 12, 803-819. https://doi.org/10.1162/tacl_a_00674
doi: 10.1162/tacl_a_00674 URL |
| [41] | Kim H., Sclar M., Zhou X., Bras R. L., Kim G., Choi Y., & Sap M. (2023). FANToM: A benchmark for stress- testing machine theory of mind in interactions. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 14397-14413). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.890 |
| [42] |
Korman J., & Malle B. F. (2016). Grasping for traits or reasons? How people grapple with puzzling social behaviors. Personality and Social Psychology Bulletin, 42(11), 1451-1465. https://doi.org/10.1177%2F0146167216663704
doi: 10.1177/0146167216663704 URL pmid: 27633856 |
| [43] | Kosinski M. (2023). Theory of mind might have spontaneously emerged in large language models. arxiv preprint arxiv: 2302.02083v5. https://doi.org/10.48550/arXiv.2302.02083 |
| [44] | Kosinski M. (2024). Evaluating large language models in theory of mind tasks. Proceedings of the National Academy of Sciences, 121(45), e2405460121. https://doi.org/10.1073/pnas.2405460121 |
| [45] | Laskar M. T. R., Alqahtani S., Bari M. S., Rahman M., Khan M. A. M., Khan H., ... Huang J. (2024, November). A systematic survey and critical review on evaluating large language models: Challenges, limitations, and recommendations. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (pp. 13785-13816). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.emnlp-main.764 |
| [46] |
Lebiere C., Pirolli P., Johnson M., Martin M., & Morrison D. (2025). Cognitive models for machine theory of mind. Topics in Cognitive Science, 17(2), 268-290. https://doi.org/10.1111/tops.12773
doi: 10.1111/tops.v17.2 URL |
| [47] |
LeCun Y., Bengio Y., & Hinton G. (2015). Deep learning. Nature, 521(7553), 436-444. https://doi.org/10.1038%2Fnature14539
doi: 10.1038/nature14539 URL |
| [48] | Li H., Chong Y., Stepputtis S., Campbell J., Hughes D., Lewis C., & Sycara K. (2023, December). Theory of mind for multi-agent collaboration via large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp.180-192). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.13 |
| [49] |
Lin Z. (2024). How to write effective prompts for large language models. Nature Human Behaviour, 8(4), 611-615. https://doi.org/10.1038/s41562-024-01847-2
doi: 10.1038/s41562-024-01847-2 URL pmid: 38438650 |
| [50] | Liu H., Guo D., & Cangelosi A. (2025). Embodied intelligence: A synergy of morphology, action, perception and learning. ACM Computing Surveys, 57(7), 1-36. https://doi.org/10.1145/3717059 |
| [51] | Lu J. G., Song L. L., & Zhang L. D. (2025). Cultural tendencies in generative AI. Nature Human Behaviour. https://doi.org/10.1038/s41562-025-02242-1 |
| [52] | Lu Y. L., Zhang C., Song J., Fan L., & Wang W. (2025). Do theory of mind benchmarks need explicit human-like reasoning in language models?. arxiv preprint arxiv:2504. 01698. https://doi.org/10.48550/arXiv.2504.01698 |
| [53] | Ma X., Gao L., & Xu Q. (2023, December). ToMChallenges: A principle-guided dataset and diverse evaluation tasks for exploring theory of mind. In Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL) (pp. 15-26). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.conll-1.2 |
| [54] |
Mao Y., Liu S., Ni Q., Lin X., & He L. (2024). A review on machine theory of mind. IEEE Transactions on Computational Social Systems, 11(6), 7114-7132. https://doi.org/10.1109/TCSS.2024.3416707
doi: 10.1109/TCSS.2024.3416707 URL |
| [55] |
Marchetti A., Di Dio C., Cangelosi A., Manzi F., & Massaro D. (2023). Developing ChatGPT’s theory of mind. Frontiers in Robotics and AI, 10, 1189525. https://doi.org/10.3389/frobt.2023.1189525
doi: 10.3389/frobt.2023.1189525 URL |
| [56] |
Marchetti A., Manzi F., Riva G., Gaggioli A., & Massaro D. (2025). Artificial intelligence and the illusion of understanding: A systematic review of theory of mind and large language models. Cyberpsychology, Behavior, and Social Networking, 28(7), 505-514. http://dx.doi.org/10.1089/cyber.2024.0536
doi: 10.1089/cyber.2024.0536 URL |
| [57] |
Meskó B. (2023). Prompt engineering as an important emerging skill for medical professionals: Tutorial. Journal of Medical Internet Research, 25, e50638. http://dx.doi.org/10.2196/50638
doi: 10.2196/50638 URL |
| [58] |
Milligan K., Astington J. W., & Dack L. A. (2007). Language and theory of mind: Meta-analysis of the relation between language ability and false-belief understanding. Child Development, 78(2), 622-646. https://doi.org/10.1111/j.1467-8624.2007.01018.x
doi: 10.1111/j.1467-8624.2007.01018.x URL pmid: 17381794 |
| [59] | Nickel C., Schrewe L., & Flek L. (2024). Probing the robustness of theory of mind in large language models. arxiv preprint arxiv:2410.06271. https://doi.org/10.48550/arXiv.2410.06271 |
| [60] |
O’Hare, A. E., Bremner, L., Nash, M., Happé, F., & Pettigrew, L. M. (2009). A clinical assessment tool for advanced theory of mind performance in 5 to 12 year olds. Journal of Autism and Developmental Disorders, 39(6), 916-928. https://doi.org/10.1007%2Fs10803-009-0699-2
doi: 10.1007/s10803-009-0699-2 URL pmid: 19205858 |
| [61] |
Osterhaus C., Koerber S., & Sodian B. (2016). Scaling of advanced theory-of-mind tasks. Child Development, 87(6), 1971-1991. https://doi.org/10.1111%2Fcdev.12566
doi: 10.1111/cdev.12566 URL pmid: 27338116 |
| [62] | Ouyang L., Wu J., Jiang X., Almeida D., Wainwright C., Mishkin P., ... Lowe R. (2022). Training language models to follow instructions with human feedback. In Proceedings of the 36th International Conference on Neural Information Processing Systems (pp.27730-27744). Curran Associates Inc. https://doi.org/10.48550/arXiv.2203.02155 |
| [63] |
Paus T. (2023). Tracking development of connectivity in the human brain: Axons and dendrites. Biological Psychiatry, 93(5), 455-463. https://doi.org/10.1016/j.biopsych.2022.08.019
doi: 10.1016/j.biopsych.2022.08.019 URL |
| [64] |
Pei Z., Yin J., & Zhang J. (2025). Language models for materials discovery and sustainability: Progress, challenges, and opportunities. Progress in Materials Science, 154, 101495. https://doi.org/10.1016/j.pmatsci.2025.101495
doi: 10.1016/j.pmatsci.2025.101495 URL |
| [65] |
Peng Y., Han J., Zhang Z., Fan L., Liu T., Qi S., ... Zhu S. C. (2024). The tong test: Evaluating artificial general intelligence through dynamic embodied physical and social interactions. Engineering, 34, 12-22. https://doi.org/10.1016/j.eng.2023.07.006
doi: 10.1016/j.eng.2023.07.006 URL |
| [66] | Pi Z., Vadaparty A., Bergen B. K., & Jones C. R. (2024). Dissecting the Ullman variations with a SCALPEL: Why do LLMs fail at trivial alterations to the false belief task?. arxiv preprint arxiv:2406.14737. https://doi.org/10.48550/arXiv.2406.14737 |
| [67] |
Premack D., & Woodruff G. (1978). Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences, 1(4), 515-526. https://doi.org/10.1017/S0140525X00076512
doi: 10.1017/S0140525X00076512 URL |
| [68] | Press O., Zhang M., Min S., Schmidt L., Smith N., & Lewis M. (2023, December). Measuring and narrowing the compositionality gap in language models. In Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 5687-5711). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-emnlp.378 |
| [69] |
Quesque F., & Rossetti Y. (2020). What do theory-of-mind tasks actually measure? Theory and practice. Perspectives on Psychological Science, 15(2), 384-396. https://doi.org/10.1177/1745691619896607
doi: 10.1177/1745691619896607 URL pmid: 32069168 |
| [70] | Rabinowitz N., Perbet F., Song F., Zhang C., Eslami S. A., & Botvinick M. (2018, July). Machine theory of mind. In Proceedings of the 35th International Conference on Machine Learning (pp.4218-4227). PMLR. https://doi.org/10.48550/arXiv.1802.07740 |
| [71] |
Rakoczy H. (2022). Foundations of theory of mind and its development in early childhood. Nature Reviews Psychology, 1(4), 223-235. https://doi.org/10.1038/s44159-022-00037-z
doi: 10.1038/s44159-022-00037-z URL |
| [72] | Rathje S., Mirea D.-M., Sucholutsky I., Marjieh R., Robertson C. E., & Van Bavel J. J. (2024). GPT is an effective tool for multilingual psychological text analysis. Proceedings of the National Academy of Sciences, 121(34), e2308950121. https://doi.org/10.1073/pnas.2308950121 |
| [73] | Ren L., Dong J., Liu S., Zhang L., & Wang L. (2024, August). Embodied intelligence toward future smart manufacturing in the era of AI foundation model. IEEE/ ASME Transactions on Mechatronics, 30(4), 2632-2642. https://doi.org/10.1109/TMECH.2024.3456250 |
| [74] |
Richter F. (2025). From human-system interaction to human-system co-action and back: Ethical assessment of generative AI and mutual theory of mind. AI and Ethics, 5(1), 19-28. https://doi.org/10.1007/s43681-024-00626-z
doi: 10.1007/s43681-024-00626-z URL |
| [75] |
Riva G., Mantovani F., Wiederhold B. K., Marchetti A., & Gaggioli A. (2025). Psychomatics—A multidisciplinary framework for understanding artificial minds. Cyberpsychology, Behavior, and Social Networking, 28(7), 515-523. http://dx.doi.org/10.1089/cyber.2024.0409
doi: 10.1089/cyber.2024.0409 URL |
| [76] |
Ruffman T. (2023). Belief it or not: How children construct a theory of mind. Child Development Perspectives, 17(2), 106-112. https://doi.org/10.1111%2Fcdep.12483
doi: 10.1111/cdep.v17.2 URL |
| [77] | Sap M., Le Bras R., Fried D., & Choi Y. (2022, December). Neural theory-of-mind? On the limits of social intelligence in large LMs. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (pp.3762-3780). Association for Computational Linguistics. https://doi.org/10.18653/v1/2022.emnlp-main.248 |
| [78] | Sarıtaş K., Tezören K., & Durmazkeser Y. (2025). A systematic review on the evaluation of large language models in theory of mind tasks. arxiv preprint arxiv:2502. 08796/ https://doi.org/10.48550/arXiv.2502.08796 |
| [79] |
Schaafsma S. M., Pfaff D. W., Spunt R. P., & Adolphs R. (2015). Deconstructing and reconstructing theory of mind. Trends in Cognitive Sciences, 19(2), 65-72. https://doi.org/10.1016/j.tics.2014.11.007
doi: 10.1016/j.tics.2014.11.007 URL pmid: 25496670 |
| [80] |
Schurz M., Radua J., Tholen M. G., Maliske L., Margulies D. S., Mars R. B., ... Kanske P. (2021). Toward a hierarchical model of social cognition: A neuroimaging meta-analysis and integrative review of empathy and theory of mind. Psychological Bulletin, 147(3), 293-327. http://dx.doi.org/10.1037/bul0000303
doi: 10.1037/bul0000303 URL pmid: 33151703 |
| [81] | Sclar M., Kumar S., West P., Suhr A., Choi Y., & Tsvetkov Y. (2023, July). Minding language models’ (lack of) theory of mind: A plug-and-play multi-character belief tracker. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 13960-13980). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.acl-long.780 |
| [82] | Sclar M., Neubig G., & Bisk Y. (2022, June). Symmetric machine theory of mind. In Proceedings of the 39th International Conference on Machine Learning (pp.19450-19466). PMLR. |
| [83] | Seth A. K. (2024). Conscious artificial intelligence and biological naturalism. Behavioral and Brain Sciences, 1-42. https://doi.org/10.1017/S0140525X25000032 |
| [84] |
Shanahan M., McDonell K., & Reynolds L. (2023). Role play with large language models. Nature, 623(7987), 493-498. https://doi.org/10.1038/s41586-023-06647-8
doi: 10.1038/s41586-023-06647-8 URL |
| [85] | Shapira N., Levy M., Alavi S. H., Zhou X., Choi Y., Goldberg Y., ... Shwartz V. (2024, March). Clever hans or neural theory of mind? Stress testing social reasoning in large language models. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1:Long Papers) (pp. 2257-2273). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.eacl-long.138 |
| [86] | Shapira N., Zwirn G., & Goldberg Y. (2023, July). How well do large language models perform on faux pas tests? In Findings of the Association for Computational Linguistics: ACL 2023 (pp. 10438-10451). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-acl.663 |
| [87] | Sileo D., & Lernould A. (2023, December). MindGames: Targeting theory of mind in large language models with dynamic epistemic modal logic. In Findings of the Association for Computational Linguistics: EMNLP 2023 (pp. 4570-4577). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.findings-emnlp.303 |
| [88] |
Sodian B., Kristen-Antonow S., & Kloo D. (2020). How does children’s theory of mind become explicit? A review of longitudinal findings. Child Development Perspectives, 14(3), 171-177. https://doi.org/10.1111%2Fcdep.12381
doi: 10.1111/cdep.v14.3 URL |
| [89] |
Strachan J. W. A., Albergo D., Borghini G., Pansardi O., Scaliti E., Gupta S., ... Becchio C. (2024). Testing theory of mind in large language models and humans. Nature Human Behaviour, 8(7), 1285-1295. https://doi.org/10.1038/s41562-024-01882-z
doi: 10.1038/s41562-024-01882-z URL pmid: 38769463 |
| [90] |
Tait I., Bensemann J., & Wang Z. (2024). Is GPT-4 conscious? Journal of Artificial Intelligence and Consciousness, 11(1), 1-16. https://doi.org/10.1142/S270507852450005X
doi: 10.1142/S270507852450005X URL |
| [91] |
Trott S., Jones C., Chang T., Michaelov J., & Bergen B. (2023). Do large language models know what humans know? Cognitive Science, 47(7), e13309. https://doi.org/10.1111%2Fcogs.13309
doi: 10.1111/cogs.v47.7 URL |
| [92] | Ullman T. (2023). Large language models fail on trivial alterations to theory-of-mind tasks. arxiv preprint arxiv: 2302.08399. https://doi.org/10.48550/arXiv.2302.08399 |
| [93] | Ünlütabak B., & Bal O. (2025). Theory of mind performance of large language models: A comparative analysis of Turkish and English. Computer Speech & Language, 89, 101698. https://doi.org/10.1016/j.csl.2024.101698 |
| [94] |
Van Der Meer L., Groenewold N. A., Nolen W. A., Pijnenborg M., & Aleman A. (2011). Inhibit yourself and understand the other: Neural basis of distinct processes underlying theory of mind. NeuroImage, 56(4), 2364-2374. http://dx.doi.org/10.1016/j.neuroimage.2011.03.053
doi: 10.1016/j.neuroimage.2011.03.053 URL pmid: 21440642 |
| [95] | Van Duijn M., Van Dijk B., Kouwenhoven T., De Valk W., Spruit M., & van der Putten P. (2023, December). Theory of mind in large language models:Examining performance of 11 state-of-the-art models vs. children aged 7-10 on advanced tests. In Proceedings of the 27th Conference on Computational Natural Language Learning (CoNLL) (pp. 389-402). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.conll-1.25 |
| [96] | Vaswani A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A. N., ... Polosukhin I. (2017, December). Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS '17) (pp. 6000-6010). Curran Associates Inc. https://doi.org/10.48550/arXiv.1706.03762 |
| [97] | Verma M., Bhambri S., & Kambhampati S. (2024, March). Theory of mind abilities of large language models in human-robot interaction: An illusion?. In Companion of the 2024 ACM/IEEE International Conference on Human- Robot Interaction (pp. 36-45). Association for Computing Machinery. https://doi.org/10.1145/3610978.3640767 |
| [98] | Wang J., Zhang C., Li J., Ma Y., Niu L., Han J., ... Fan L. (2024, May). Evaluating and modeling social intelligence: A comparative study of human and ai capabilities. In Proceedings of the Annual Meeting of the Cognitive Science Society (Vol. 46) (pp. 5983-5990). Cognitive Science Society. https://doi.org/10.48550/arXiv.2405.11841 |
| [99] | Wang Q., & Goel A. K. (2024). Mutual theory of mind for human-AI communication. arxiv preprint arxiv:2210. 03842. https://doi.org/10.48550/arXiv.2210.03842 |
| [100] | Wang Q., Walsh S., Si M., Kephart J., Weisz J. D., & Goel A. K. (2024, May). Theory of mind in human-AI interaction. In Extended Abstracts of the CHI Conference on Human Factors in Computing Systems (pp.1-6). Association for Computing Machinery. https://doi.org/10.1145/3613905.3636308 |
| [101] | Wei J., Tay Y., Bommasani R., Raffel C., Zoph B., Borgeaud S., ... Fedus W. (2022). Emergent abilities of large language models. arxiv preprint arxiv:2206. 07682. https://doi.org/10.48550/arXiv.2206.07682 |
| [102] | Wei J., Wang X., Schuurmans D., Bosma M., Ichter B., Xia F., ... Zhou D. (2022). Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS '22) (pp. 24824-24837). Curran Associates Inc. https://doi.org/10.48550/arXiv.2201.11903 |
| [103] |
Wellman H. M. (2017). The development of theory of mind: Historical reflections. Child Development Perspectives, 11(3), 207-214. https://doi.org/10.1111%2Fcdep.12236
doi: 10.1111/cdep.2017.11.issue-3 URL |
| [104] |
Wellman H. M., & Liu D. (2004). Scaling of theory- of-mind tasks. Child Development, 75(2), 523-541. https://doi.org/10.1111/j.1467-8624.2004.00691.x
doi: 10.1111/j.1467-8624.2004.00691.x URL pmid: 15056204 |
| [105] |
Westby C., & Robinson L. (2014). A developmental perspective for promoting theory of mind. Topics in Language Disorders, 34(4), 362-382. https://doi.org/10.1097%2FTLD.0000000000000035
doi: 10.1097/TLD.0000000000000035 URL |
| [106] | Wilf A., Lee S., Liang P. P., & Morency L. P. (2024, August). Think twice: Perspective-taking improves large language models’ theory-of-mind capabilities. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 8292-8308). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.451 |
| [107] |
Williams J., Fiore S. M., & Jentsch F. (2022). Supporting artificial social intelligence with theory of mind. Frontiers in Artificial Intelligence, 5, 750763. https://doi.org/10.3389/frai.2022.750763
doi: 10.3389/frai.2022.750763 URL |
| [108] | Winfield A. F. (2018). Experiments in artificial theory of mind: From safety to story-telling. Frontiers in Robotics and AI, 5, 357467. https://doi.org/10.3389/frobt.2018.00075 |
| [109] |
Wu T., He S., Liu J., Sun S., Liu K., Han Q. L., & Tang Y. (2023). A brief overview of ChatGPT: The history, status quo and potential future development. IEEE/CAA Journal of Automatica Sinica, 10(5), 1122-1136. https://doi.org/10.1109/JAS.2023.123618
doi: 10.1109/JAS.2023.123618 URL |
| [110] | Xu H., Zhao R., Zhu L., Du J., & He Y. (2024, August). OpenToM: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 8593-8623). Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.acl-long.466 |
| [111] |
Yildirim I., & Paul L. A. (2024). From task structures to world models: what do LLMs know? Trends in Cognitive Sciences, 28(5), 404-415. https://doi.org/10.1016/j.tics.2024.02.008
doi: 10.1016/j.tics.2024.02.008 URL pmid: 38443199 |
| [112] |
Yıldız T. (2025). The minds we make: A philosophical inquiry into theory of mind and artificial intelligence. Integrative Psychological and Behavioral Science, 59(1), 10. https://doi.org/10.1007/s12124-024-09876-2
doi: 10.1007/s12124-024-09876-2 URL |
| [113] | Yin S., Fu C., Zhao S., Li K., Sun X., Xu T., & Chen E. (2024). A survey on multimodal large language models. National Science Review, 11(12), nwae403. https://doi.org/10.1093/nsr/nwae403 |
| [114] | Yongsatianchot N., Thejll-Madsen T., & Marsella S. (2024, September). Exploring theory of mind in large language models through multimodal negotiation. In Proceedings of the ACM International Conference on Intelligent Virtual Agents (pp.1-9). Association for Computing Machinery. https://doi.org/10.1145/3652988.3673960 |
| [115] |
Yu C. L., & Wellman H. M. (2024). A meta-analysis of sequences in theory-of-mind understandings: Theory of mind scale findings across different cultural contexts. Developmental Review, 74, 101162. https://doi.org/10.1016/j.dr.2024.101162
doi: 10.1016/j.dr.2024.101162 URL |
| [116] |
Yuan L., Gao X., Zheng Z., Edmonds M., Wu Y. N., Rossano F., ... Zhu S. C. (2022). In situ bidirectional human-robot value alignment. Science Robotics, 7(68), eabm4183. https://doi.org/10.1126/scirobotics.abm4183
doi: 10.1126/scirobotics.abm4183 URL |
| [117] |
Zelazo P. D. (2004). The development of conscious control in childhood. Trends in Cognitive Sciences, 8(1), 12-17. https://doi.org/10.1016/j.tics.2003.11.001
URL pmid: 14697398 |
| [118] | Zhao W. X., Zhou K., Li J., Tang T., Wang X., Hou Y., ... Wen J. R. (2023). A survey of large language models. arxiv preprint arxiv:2303.18223. https://doi.org/10.48550/arXiv.2303.18223 |
| [119] |
Zhou L., Schellaert W., Martínez-Plumed F., Moros-Daval Y., Ferri C., & Hernández-Orallo J. (2024). Larger and more instructable language models become less reliable. Nature, 634(8032), 61-68. https://doi.org/10.1038/s41586-024-07930-y
doi: 10.1038/s41586-024-07930-y URL |
| [120] | Zhou P., Madaan A., Potharaju S. P., Gupta A., McKee K. R., Holtzman A., ... Faruqui M. (2023). How far are large language models from agents with theory-of-mind?. arxiv preprint arxiv:2310.03051. https://doi.org/10.48550/arXiv.2310.03051 |
| [1] | 武靖宇, 金鑫. 算法介导下的情感趋同:生成式人工智能情感传染机制[J]. 心理科学进展, 2026, 34(1): 123-133. |
| [2] | 李研, 陈维, 武瑞娟. AI技术背景下虚拟影响者营销效应及其作用机制[J]. 心理科学进展, 2025, 33(8): 1425-1442. |
| [3] | 宗树伟, 杨付, 龙立荣, 韩翼. 促进还是抑制?生成式人工智能建议采纳对创造力的双刃剑效应[J]. 心理科学进展, 2025, 33(6): 905-915. |
| [4] | 解煜彬, 周荣刚. 新型人机关系下的人机双向信任[J]. 心理科学进展, 2025, 33(6): 916-932. |
| [5] | 谭美丽, 殷向洲, 张光磊, 熊普臻. 工作场所人工智能角色划分:对员工心理与行为的影响及应对策略[J]. 心理科学进展, 2025, 33(6): 933-947. |
| [6] | 项典典, 尹雨乐, 葛梦琦, 王子涵. 自建IP还是合作IP:虚拟影响者代言人选择策略对消费者融入的影响[J]. 心理科学进展, 2025, 33(6): 965-983. |
| [7] | 罗莉娟, 王康, 胡金淼, 徐四华. 当人工智能面对人类情感:服务机器人情感表达对用户体验的影响机制[J]. 心理科学进展, 2025, 33(6): 1006-1026. |
| [8] | 彭晨明, 屈奕帆, 郭晓凌, 陈增祥. 人工智能服务对消费者道德行为的双刃剑效应[J]. 心理科学进展, 2025, 33(2): 236-255. |
| [9] | 孙芳, 李绍龙, 龙立荣, 雷宣, 曾祥麟, 黄夏虹. 人工智能反馈寻求行为的驱动机制及其影响效应[J]. 心理科学进展, 2025, 33(10): 1647-1662. |
| [10] | 徐敏亚, 陈丽萍, 刘贝妮. 人工智能对知识型员工的影响及作用机制——基于工具性和人本性视角[J]. 心理科学进展, 2025, 33(10): 1663-1683. |
| [11] | 郑宇, 谌怡, 吴月燕. 生成式人工智能队友如何影响团队新产品创意生成?基于团队过程的视角[J]. 心理科学进展, 2025, 33(10): 1684-1697. |
| [12] | 韩雨婷, 王文轩, 刘红云, 游晓锋. 题目自动生成的技术革新与现实挑战[J]. 心理科学进展, 2025, 33(10): 1766-1782. |
| [13] | 周倩伊, 蔡亚琦, 张亚. 大语言模型的共情模拟:评估、提升与挑战[J]. 心理科学进展, 2025, 33(10): 1783-1793. |
| [14] | 翁智刚, 陈潇潇, 张小妹, 张琚. 面向新型人机关系的社会临场感[J]. 心理科学进展, 2025, 33(1): 146-162. |
| [15] | 吴波, 张傲杰, 曹菲. 专业设计、用户设计还是AI设计?设计源效应的心理机制[J]. 心理科学进展, 2024, 32(6): 995-1009. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||