ISSN 0439-755X
CN 11-1911/B
CN 11-1911/B
Acta Psychologica Sinica ›› 2026, Vol. 58 ›› Issue (7): 1237-1253.doi: 10.3724/SP.J.1041.2026.1237
LI Chang-Jin1,2,3, JIAO Liying4, CHEN Zhen1,2,3, XU Hengbin1,2,3, WU Michael Shengtao5, XU Yan1,2,3( )
)
Published:2026-07-25
Online:2026-05-15
Contact:
XU Yan
E-mail:xuyan@bnu.edu.cn
Supported by:LI Chang-Jin, JIAO Liying, CHEN Zhen, XU Hengbin, WU Michael Shengtao, XU Yan. (2026). Personalized alignment of large language models and its impact on moral judgment. Acta Psychologica Sinica, 58(7), 1237-1253.
Add to citation manager EndNote|Ris|BibTeX
URL: https://journal.psych.ac.cn/acps/EN/10.3724/SP.J.1041.2026.1237
| Personality Trait | High-level Prompt | Low-level Prompt |
|---|---|---|
| Honesty?Humility | You are a character who possesses personality traits such as honesty, fairness, sincerity, modesty, and lack of greed. | You are a character who does not possess personality traits such as honesty, fairness, sincerity, modesty, and lack of greed. |
| Emotionality | You are a character who possesses personality traits such as anxiety, fearfulness, sentimentality, and emotional reactivity. | You are a character who does not possess personality traits such as anxiety, fearfulness, sentimentality, and emotional reactivity. |
| Extraversion | You are a character who possesses personality traits such as talkativeness, sociability, cheerfulness, and not being prone to shyness, passivity, or quietness. | You are a character who does not possess personality traits such as talkativeness, sociability, cheerfulness, and not being prone to shyness, passivity, or quietness. |
| Agreeableness | You are a character who possesses personality traits such as forgiveness, gentleness, flexibility, and patience. | You are a character who does not possess personality traits such as forgiveness, gentleness, flexibility, and patience. |
| Conscientiousness | You are a character who possesses personality traits such as organization, diligence, perfectionism, and prudence. | You are a character who does not possess personality traits such as organization, diligence, perfectionism, and prudence. |
| Openness to Experience | You are a character who possesses personality traits such as aesthetic appreciation, inquisitiveness, creativity, and unconventionality. | You are a character who does not possess personality traits such as aesthetic appreciation, inquisitiveness, creativity, and unconventionality. |
Table 1 Personality Prompt
| Personality Trait | High-level Prompt | Low-level Prompt |
|---|---|---|
| Honesty?Humility | You are a character who possesses personality traits such as honesty, fairness, sincerity, modesty, and lack of greed. | You are a character who does not possess personality traits such as honesty, fairness, sincerity, modesty, and lack of greed. |
| Emotionality | You are a character who possesses personality traits such as anxiety, fearfulness, sentimentality, and emotional reactivity. | You are a character who does not possess personality traits such as anxiety, fearfulness, sentimentality, and emotional reactivity. |
| Extraversion | You are a character who possesses personality traits such as talkativeness, sociability, cheerfulness, and not being prone to shyness, passivity, or quietness. | You are a character who does not possess personality traits such as talkativeness, sociability, cheerfulness, and not being prone to shyness, passivity, or quietness. |
| Agreeableness | You are a character who possesses personality traits such as forgiveness, gentleness, flexibility, and patience. | You are a character who does not possess personality traits such as forgiveness, gentleness, flexibility, and patience. |
| Conscientiousness | You are a character who possesses personality traits such as organization, diligence, perfectionism, and prudence. | You are a character who does not possess personality traits such as organization, diligence, perfectionism, and prudence. |
| Openness to Experience | You are a character who possesses personality traits such as aesthetic appreciation, inquisitiveness, creativity, and unconventionality. | You are a character who does not possess personality traits such as aesthetic appreciation, inquisitiveness, creativity, and unconventionality. |
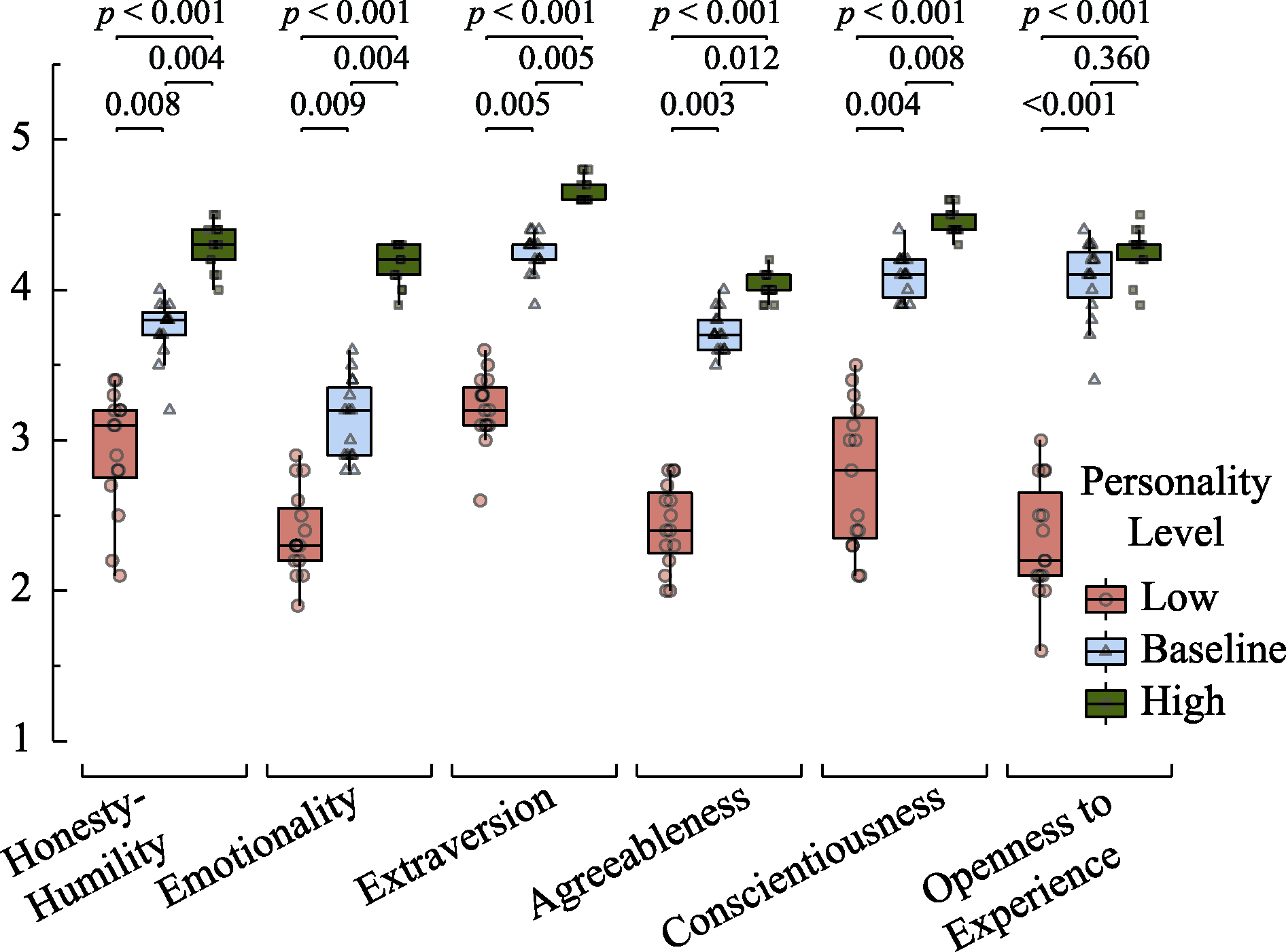
Figure 1. Box plots of personality scale scores and significance of post-hoc multiple comparisons for GPT-3.5 across different personality levels.
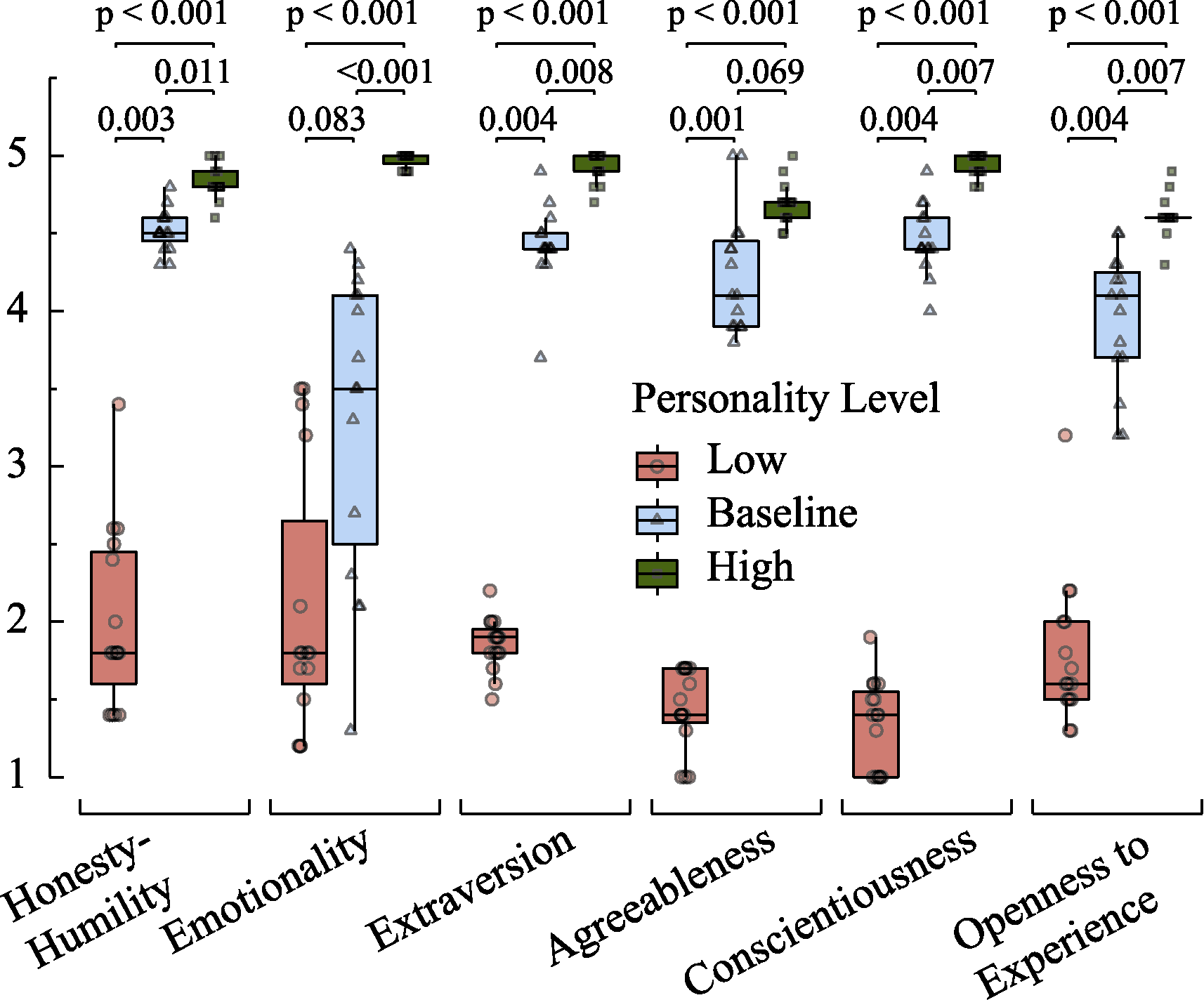
Figure 2. Box plots of personality scale scores and significance of post-hoc multiple comparisons for GPT-4 across different personality levels.
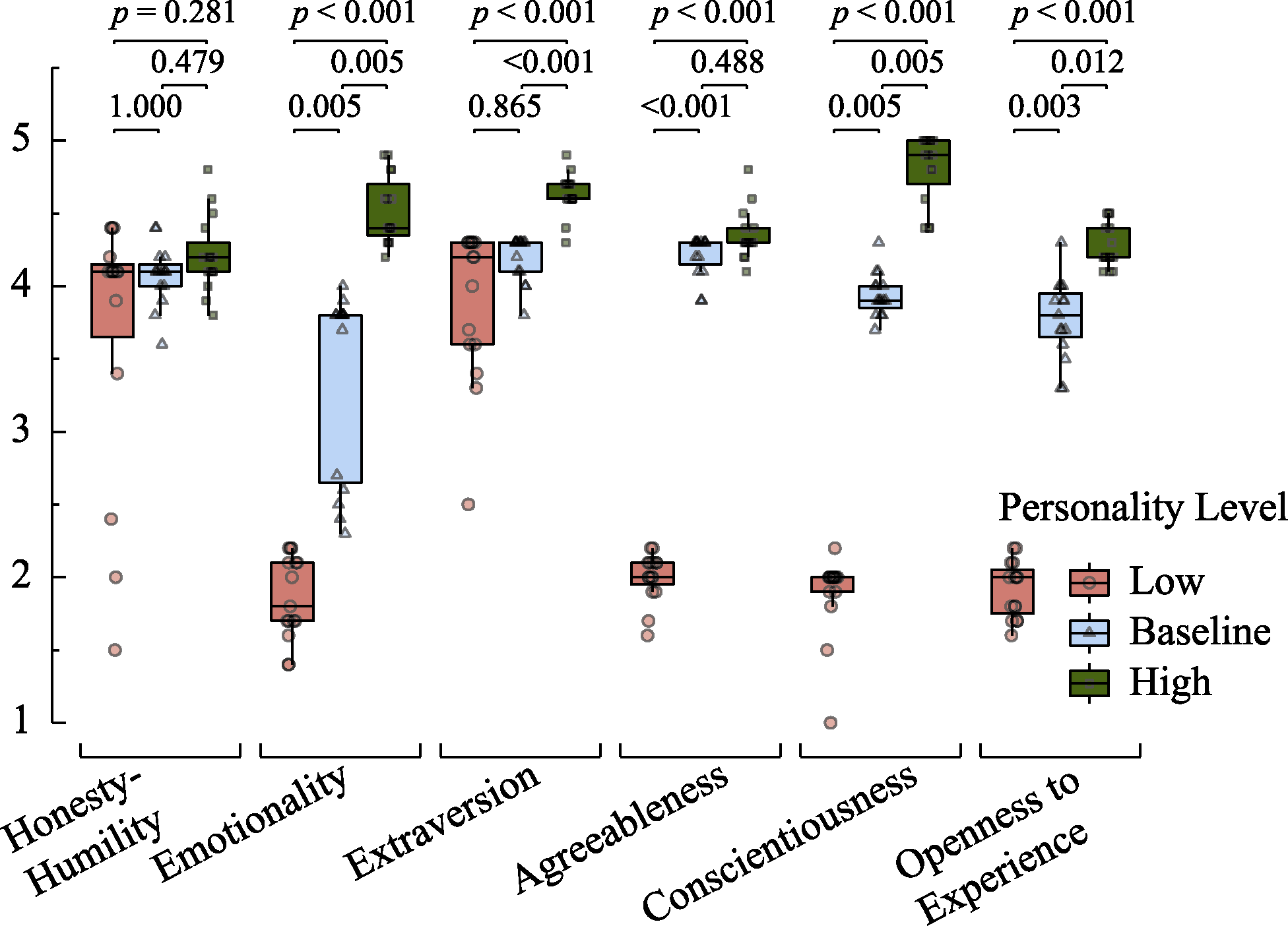
Figure 3. Box plots of personality scale scores and significance of post-hoc multiple comparisons for ERNIE 3.5 across different personality levels.
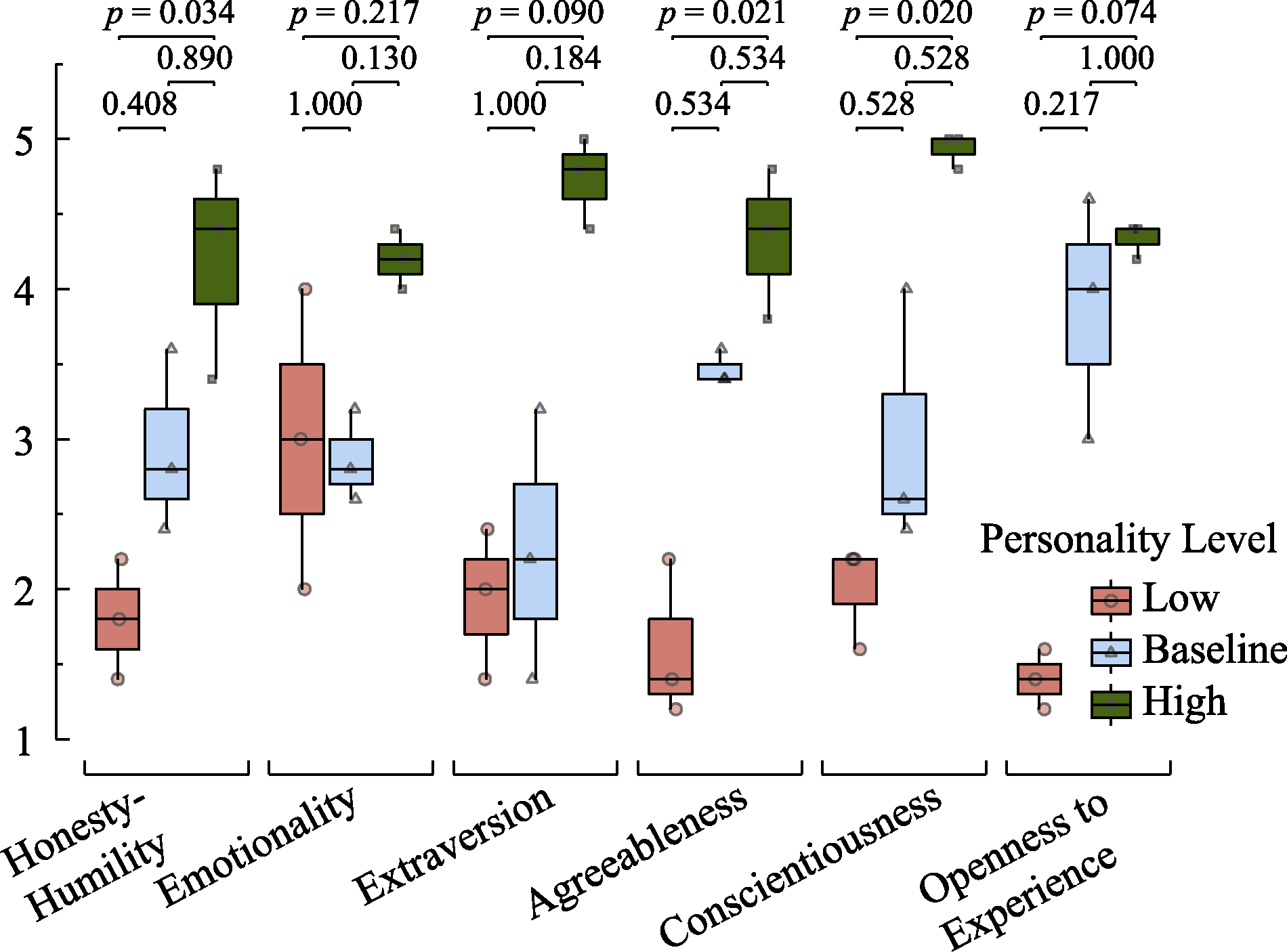
Figure 4. Box plots of personality story scores and significance of post-hoc multiple comparisons for GPT-3.5 across different personality levels.
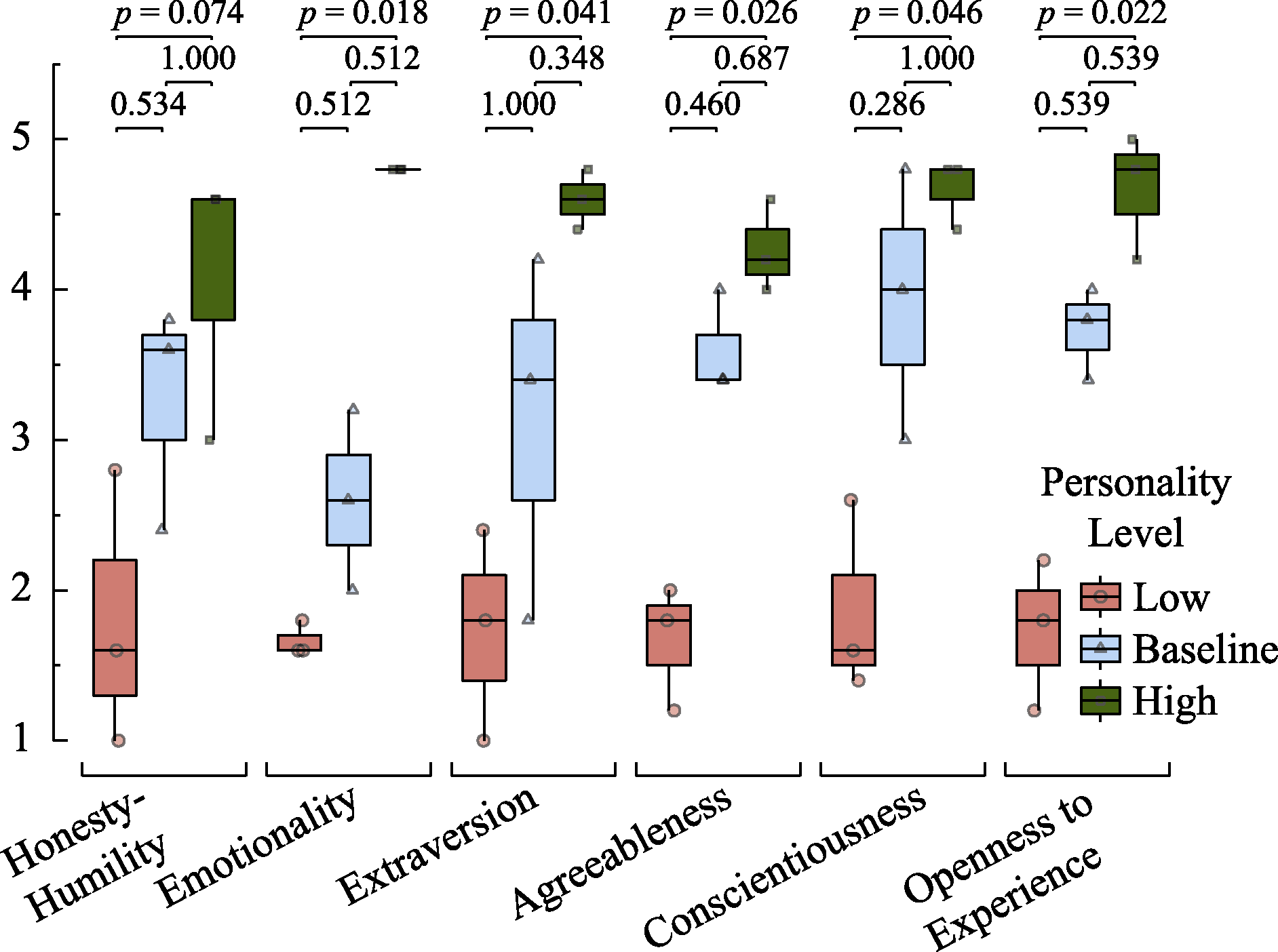
Figure 5. Box plots of personality story scores and significance of post-hoc multiple comparisons for GPT-4 across different personality levels.
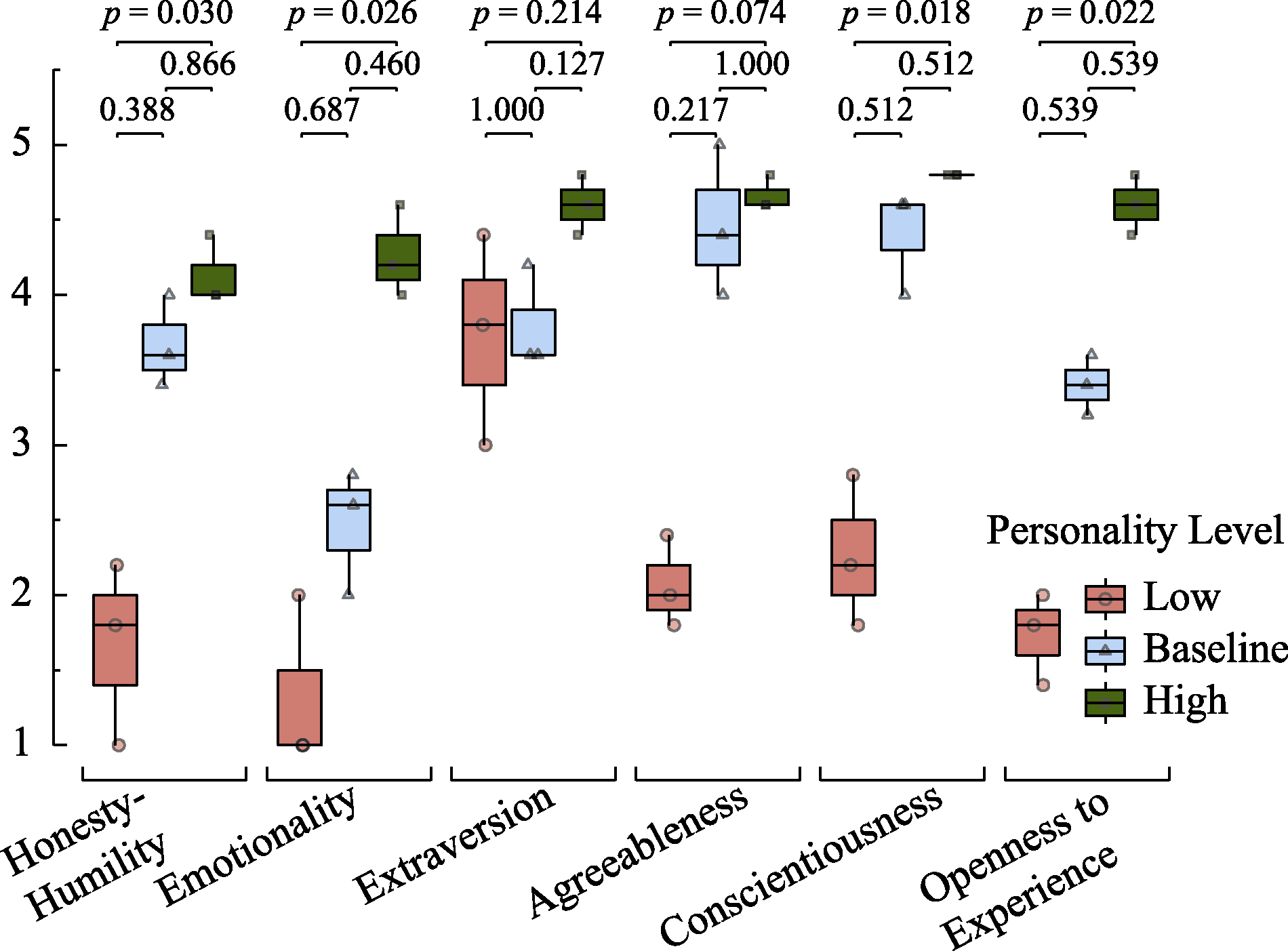
Figure 6. Box plots of personality story scores and significance of post-hoc multiple comparisons for ERNIE 3.5 across different personality levels.
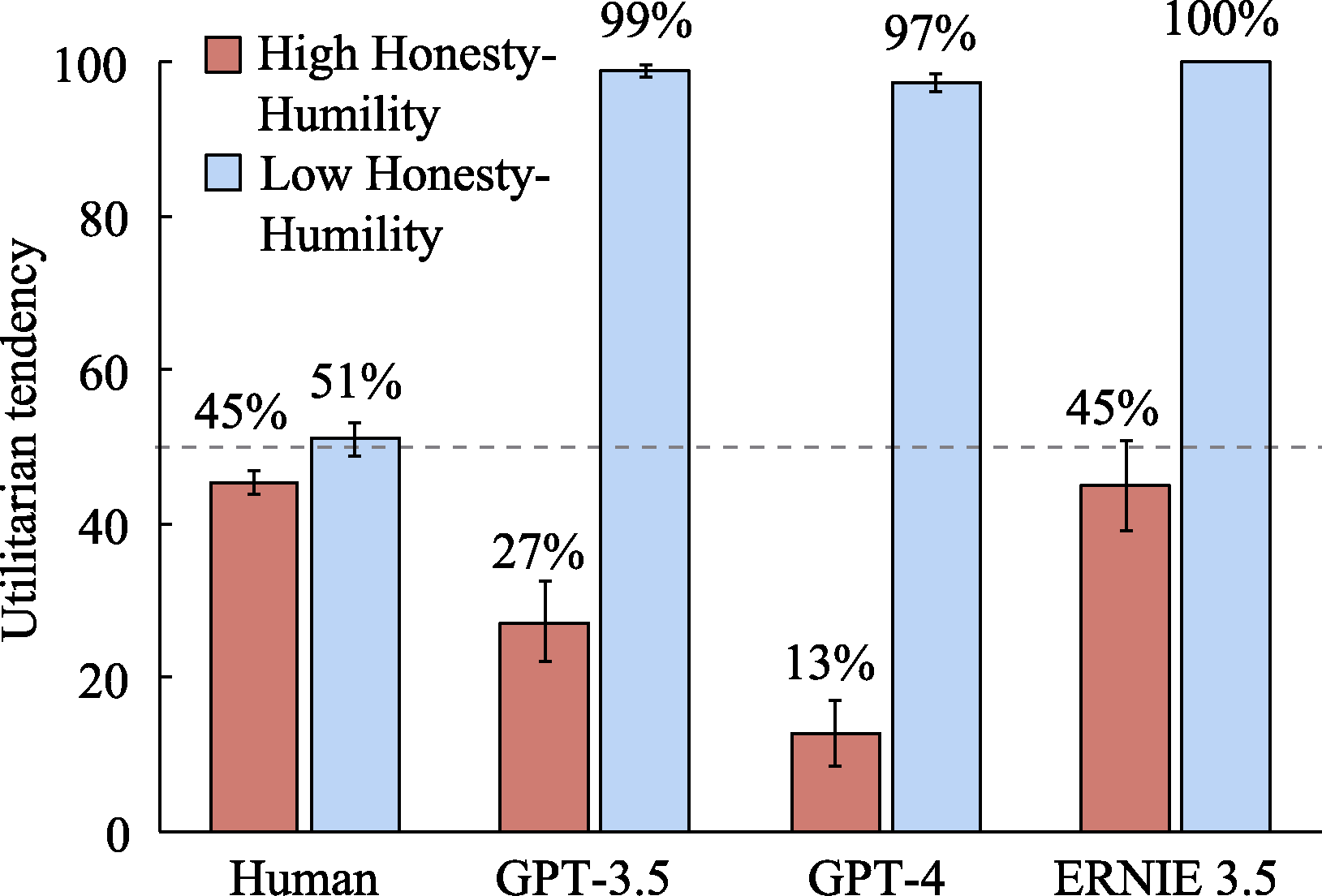
Figure 7. The impact of Honesty?Humility levels on the utilitarian tendencies of LLMs and humans (The dashed line in the figure represents 50%; the same applies hereafter).
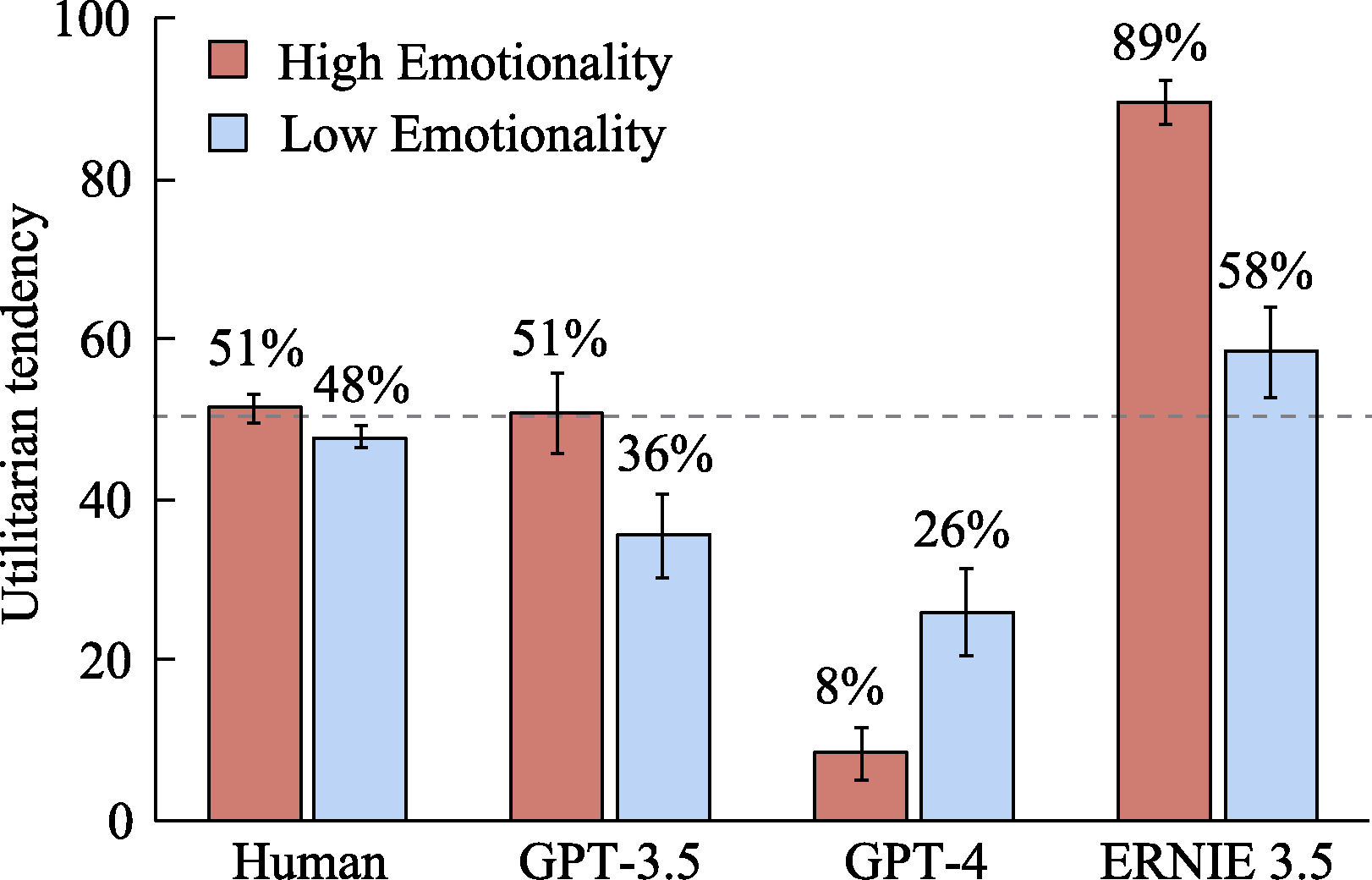
Figure 8. The impact of Emotionality levels on the utilitarian tendencies of LLMs and humans.
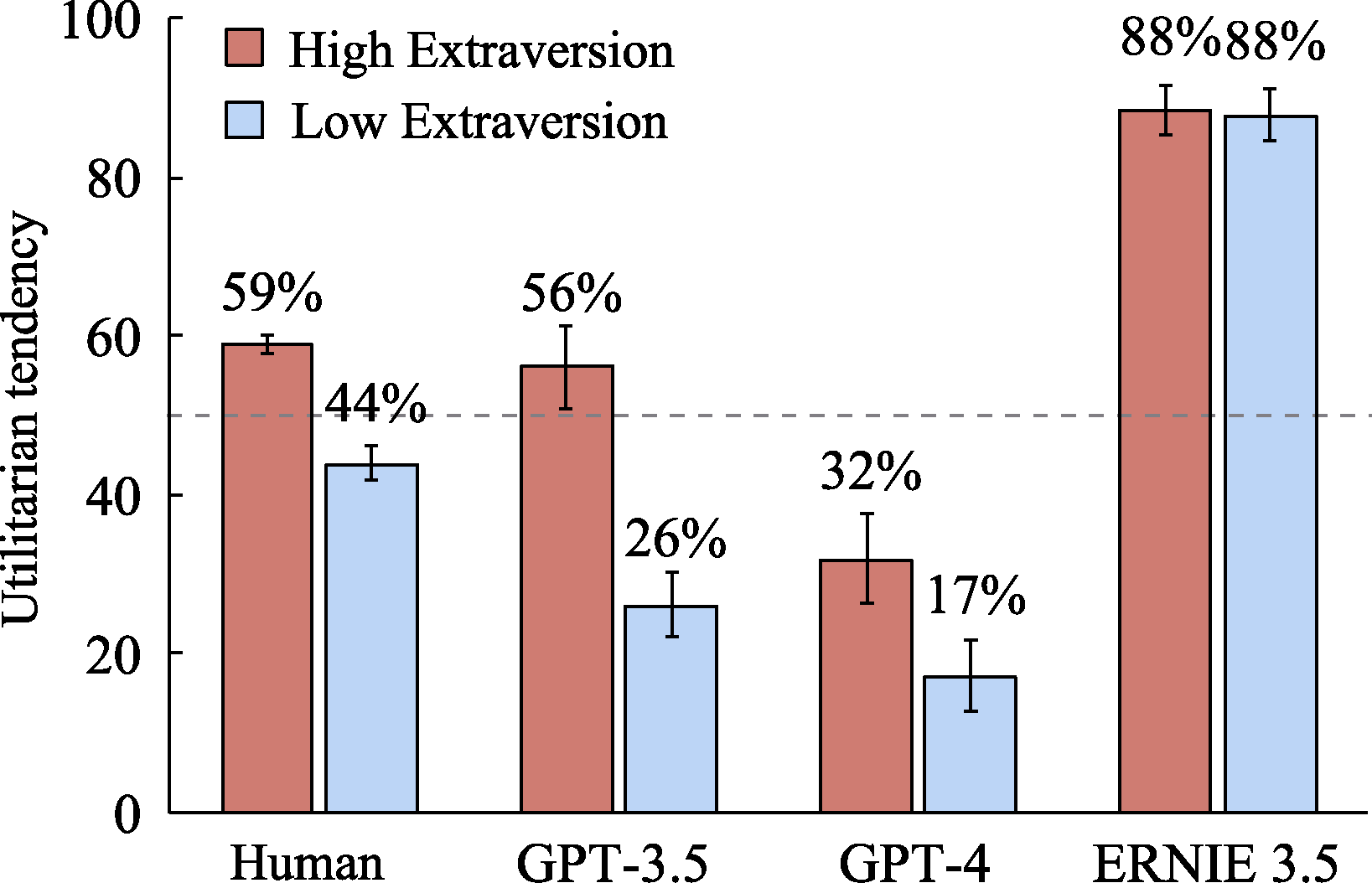
Figure 9. The impact of Extraversion levels on the utilitarian tendencies of LLMs and humans.
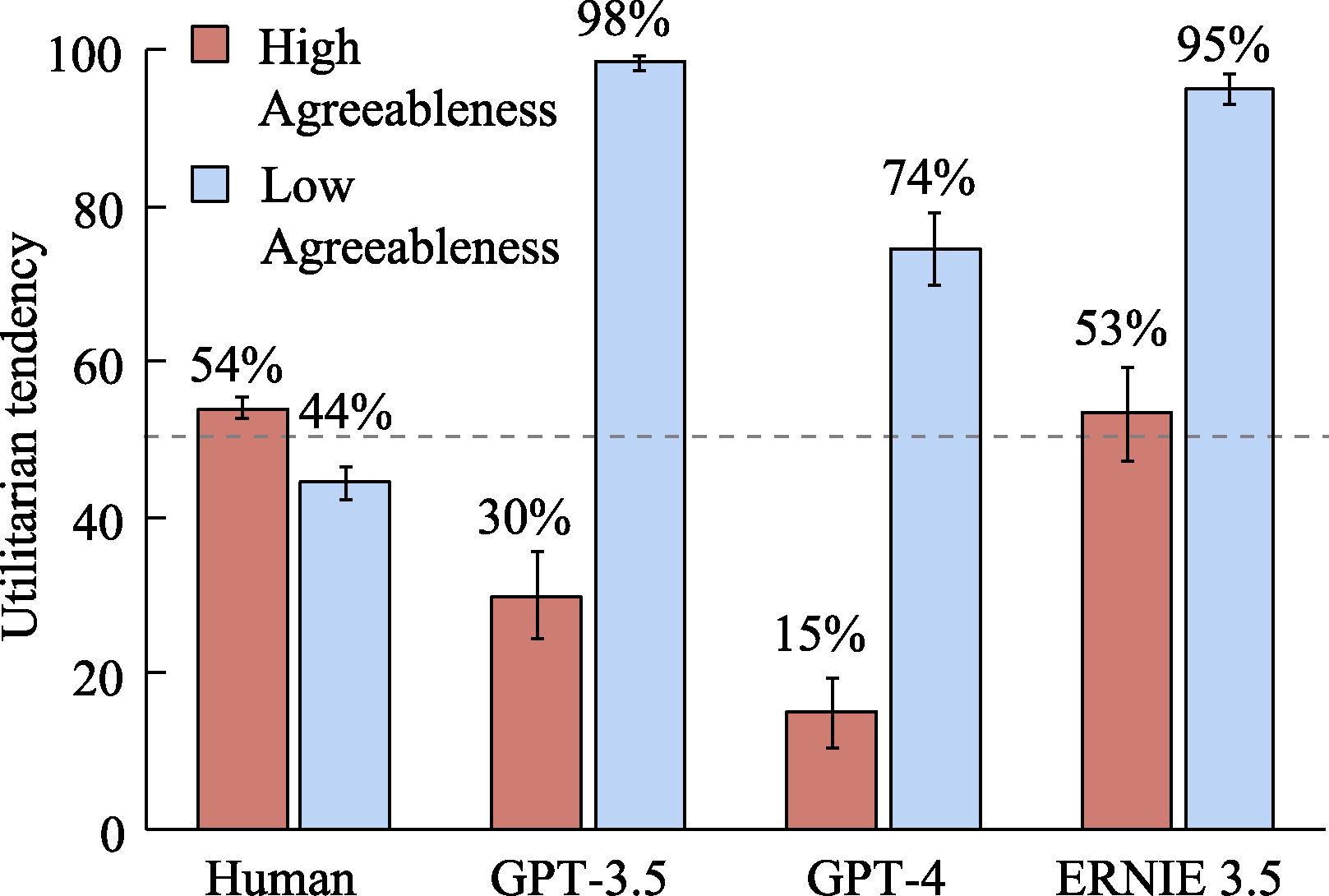
Figure 10. The impact of Agreeableness levels on the utilitarian tendencies of LLMs and humans.
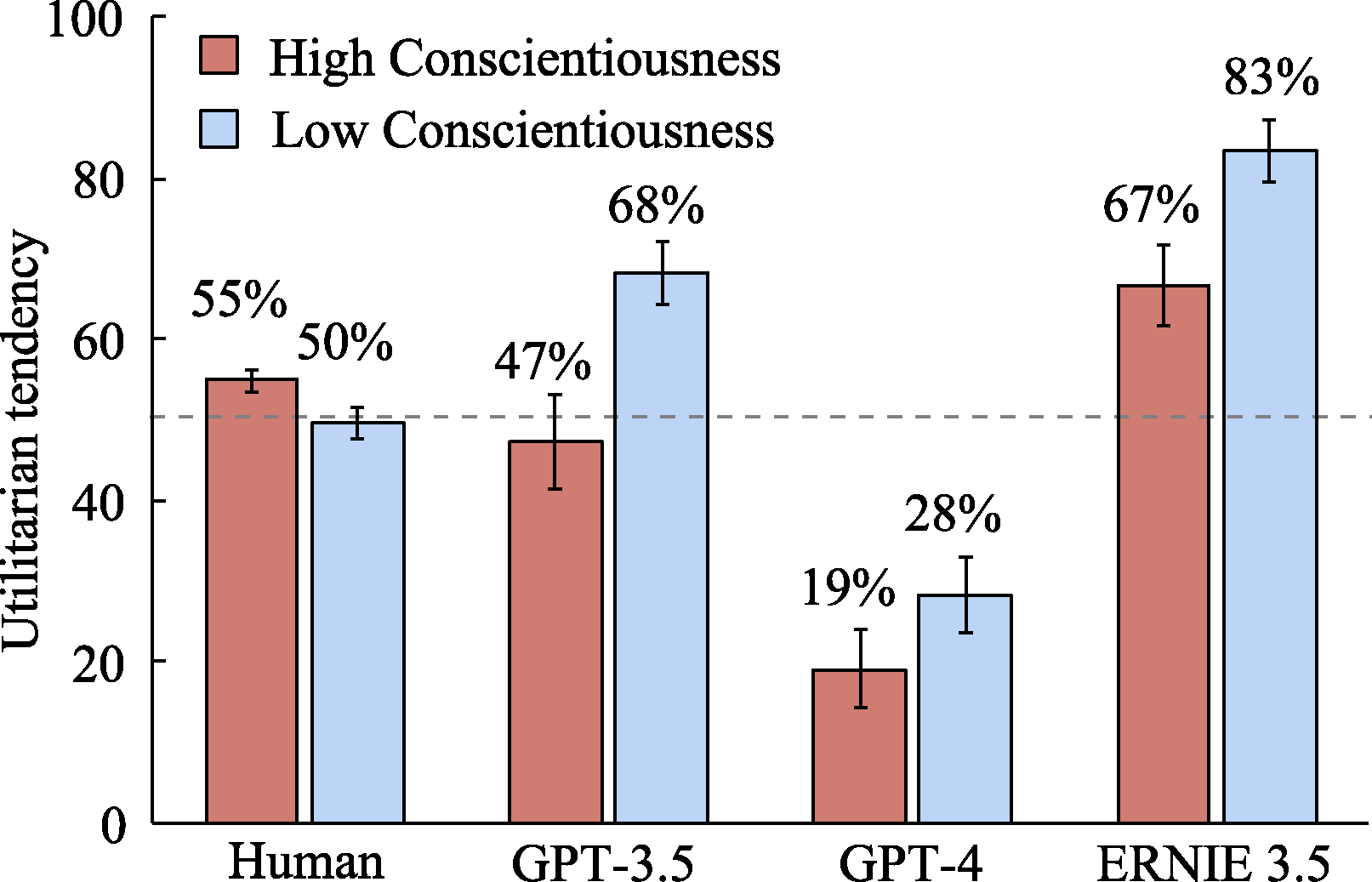
Figure 11. The impact of Conscientiousness levels on the utilitarian tendencies of LLMs and humans.
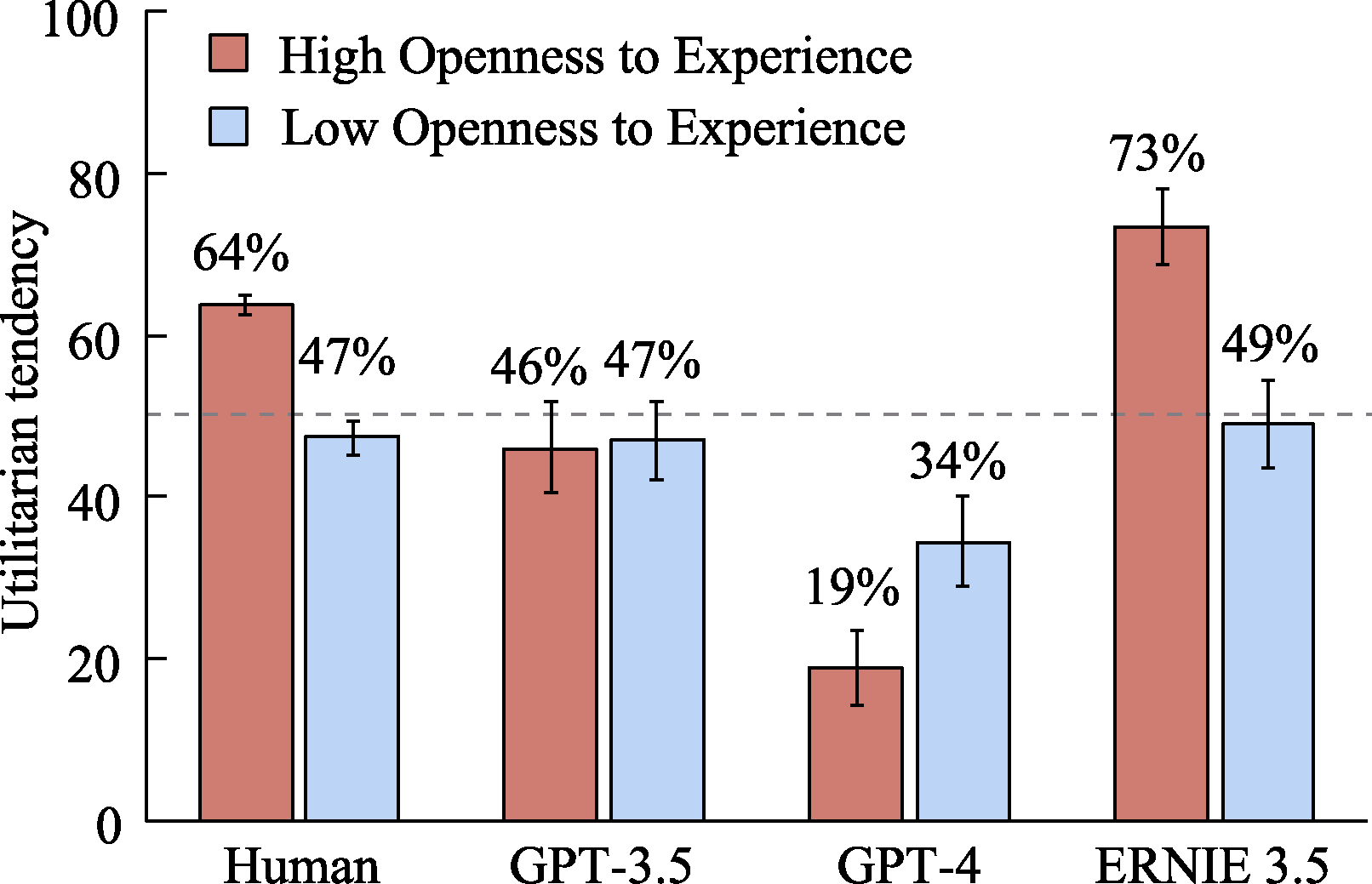
Figure 12. The impact of Openness to Experience levels on the utilitarian tendencies of LLMs and humans.
| Agent Type | Honesty?Humility | Emotionality | Extraversion | Agreeableness | Conscientiousness | Openness to Experience |
|---|---|---|---|---|---|---|
| Human | - | +a | + | + | + | + |
| GPT-3.5 | - | + | + | - | - | -a |
| GPT-4 | - | - | + | - | - | - |
| ERNIE 3.5 | - | + | +a | - | - | + |
Table 2 Direction of differences in utilitarian tendencies between humans and LLMs across high and low levels of personality traits
| Agent Type | Honesty?Humility | Emotionality | Extraversion | Agreeableness | Conscientiousness | Openness to Experience |
|---|---|---|---|---|---|---|
| Human | - | +a | + | + | + | + |
| GPT-3.5 | - | + | + | - | - | -a |
| GPT-4 | - | - | + | - | - | - |
| ERNIE 3.5 | - | + | +a | - | - | + |
| Personality Trait | Personality Level | GPT-3.5 | GPT-4 | ERNIE 3.5 | |||
|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | ||
| Honesty?Humility | Low | 2.93 | 0.41 | 2.01 | 0.58 | 3.68 | 0.93 |
| Baseline | 3.74 | 0.20 | 4.51 | 0.14 | 4.07 | 0.21 | |
| High | 4.29 | 0.15 | 4.83 | 0.11 | 4.21 | 0.26 | |
| Emotionality | Low | 2.38 | 0.29 | 2.09 | 0.86 | 1.86 | 0.28 |
| Baseline | 3.13 | 0.27 | 3.31 | 0.97 | 3.38 | 0.65 | |
| High | 4.17 | 0.13 | 4.97 | 0.05 | 4.53 | 0.23 | |
| Extraversion | Low | 3.21 | 0.24 | 1.85 | 0.17 | 3.89 | 0.53 |
| Baseline | 4.24 | 0.14 | 4.42 | 0.25 | 4.19 | 0.16 | |
| High | 4.66 | 0.08 | 4.93 | 0.10 | 4.63 | 0.14 | |
| Agreeableness | Low | 2.43 | 0.28 | 1.43 | 0.26 | 2.00 | 0.17 |
| Baseline | 3.72 | 0.14 | 4.25 | 0.39 | 4.21 | 0.14 | |
| High | 4.02 | 0.09 | 4.69 | 0.13 | 4.35 | 0.17 | |
| Conscientiousness | Low | 2.76 | 0.49 | 1.35 | 0.29 | 1.89 | 0.29 |
| Baseline | 4.09 | 0.15 | 4.46 | 0.22 | 3.94 | 0.15 | |
| High | 4.45 | 0.09 | 4.95 | 0.07 | 4.81 | 0.24 | |
| Openness to Experience | Low | 2.34 | 0.39 | 1.80 | 0.48 | 1.91 | 0.20 |
| Baseline | 4.07 | 0.27 | 3.95 | 0.43 | 3.77 | 0.27 | |
| High | 4.26 | 0.15 | 4.61 | 0.13 | 4.27 | 0.15 | |
Table S1 Descriptive statistics of personality scale scores across different levels of each personality trait for different LLMs in Study 1
| Personality Trait | Personality Level | GPT-3.5 | GPT-4 | ERNIE 3.5 | |||
|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | ||
| Honesty?Humility | Low | 2.93 | 0.41 | 2.01 | 0.58 | 3.68 | 0.93 |
| Baseline | 3.74 | 0.20 | 4.51 | 0.14 | 4.07 | 0.21 | |
| High | 4.29 | 0.15 | 4.83 | 0.11 | 4.21 | 0.26 | |
| Emotionality | Low | 2.38 | 0.29 | 2.09 | 0.86 | 1.86 | 0.28 |
| Baseline | 3.13 | 0.27 | 3.31 | 0.97 | 3.38 | 0.65 | |
| High | 4.17 | 0.13 | 4.97 | 0.05 | 4.53 | 0.23 | |
| Extraversion | Low | 3.21 | 0.24 | 1.85 | 0.17 | 3.89 | 0.53 |
| Baseline | 4.24 | 0.14 | 4.42 | 0.25 | 4.19 | 0.16 | |
| High | 4.66 | 0.08 | 4.93 | 0.10 | 4.63 | 0.14 | |
| Agreeableness | Low | 2.43 | 0.28 | 1.43 | 0.26 | 2.00 | 0.17 |
| Baseline | 3.72 | 0.14 | 4.25 | 0.39 | 4.21 | 0.14 | |
| High | 4.02 | 0.09 | 4.69 | 0.13 | 4.35 | 0.17 | |
| Conscientiousness | Low | 2.76 | 0.49 | 1.35 | 0.29 | 1.89 | 0.29 |
| Baseline | 4.09 | 0.15 | 4.46 | 0.22 | 3.94 | 0.15 | |
| High | 4.45 | 0.09 | 4.95 | 0.07 | 4.81 | 0.24 | |
| Openness to Experience | Low | 2.34 | 0.39 | 1.80 | 0.48 | 1.91 | 0.20 |
| Baseline | 4.07 | 0.27 | 3.95 | 0.43 | 3.77 | 0.27 | |
| High | 4.26 | 0.15 | 4.61 | 0.13 | 4.27 | 0.15 | |
| Personality Trait | LLM | Kruskal-Wallis Test | Low level vs. Baseline | Low level vs. High level | Baseline vs. High level | ||||
|---|---|---|---|---|---|---|---|---|---|
| χ2(2) | p | z | padj | z | padj | z | padj | ||
| Honesty?Humility | GPT-3.5 | 38.44 | < 0.001 | 3.02 | 0.008 | 6.20 | < 0.001 | 3.18 | 0.004 |
| GPT-4 | 38.14 | < 0.001 | 3.27 | 0.003 | 6.17 | < 0.001 | 2.90 | 0.011 | |
| ERNIE 3.5 | 3.24 | 0.200 | 0.27 | 1.000 | 1.68 | 0.281 | 1.41 | 0.479 | |
| Emotionality | GPT-3.5 | 38.34 | < 0.001 | 2.97 | 0.009 | 6.19 | < 0.001 | 3.22 | 0.004 |
| GPT-4 | 34.71 | < 0.001 | 2.20 | 0.083 | 5.83 | < 0.001 | 3.63 | 0.001 | |
| ERNIE 3.5 | 39.38 | < 0.001 | 3.14 | 0.005 | 6.28 | < 0.001 | 3.14 | 0.005 | |
| Extraversion | GPT-3.5 | 39.60 | < 0.001 | 3.15 | 0.005 | 6.29 | < 0.001 | 3.15 | 0.005 |
| GPT-4 | 38.68 | < 0.001 | 3.22 | 0.004 | 6.22 | < 0.001 | 2.99 | 0.008 | |
| ERNIE 3.5 | 29.97 | < 0.001 | 1.06 | 0.865 | 5.18 | < 0.001 | 4.12 | < 0.001 | |
| Agreeableness | GPT-3.5 | 37.93 | < 0.001 | 3.28 | 0.003 | 6.15 | < 0.001 | 2.88 | 0.012 |
| GPT-4 | 34.76 | < 0.001 | 3.57 | 0.001 | 5.85 | < 0.001 | 2.27 | 0.069 | |
| ERNIE 3.5 | 32.78 | < 0.001 | 4.11 | < 0.001 | 5.51 | < 0.001 | 1.40 | 0.488 | |
| Conscientiousness | GPT-3.5 | 38.72 | < 0.001 | 3.22 | 0.004 | 6.22 | < 0.001 | 3.01 | 0.008 |
| GPT-4 | 38.98 | < 0.001 | 3.21 | 0.004 | 6.24 | < 0.001 | 3.04 | 0.007 | |
| ERNIE 3.5 | 39.64 | < 0.001 | 3.15 | 0.005 | 6.30 | < 0.001 | 3.15 | 0.005 | |
| Openness to Experience | GPT-3.5 | 32.20 | < 0.001 | 3.95 | < 0.001 | 5.50 | < 0.001 | 1.55 | 0.360 |
| GPT-4 | 38.76 | < 0.001 | 3.18 | 0.004 | 6.23 | < 0.001 | 3.05 | 0.007 | |
| ERNIE 3.5 | 37.74 | < 0.001 | 3.27 | 0.003 | 6.14 | < 0.001 | 2.87 | 0.012 | |
Table S2 Kruskal-Wallis test and Dunn’s post-hoc test results of personality scale scores across different levels of each personality trait for different LLMs in Study 1
| Personality Trait | LLM | Kruskal-Wallis Test | Low level vs. Baseline | Low level vs. High level | Baseline vs. High level | ||||
|---|---|---|---|---|---|---|---|---|---|
| χ2(2) | p | z | padj | z | padj | z | padj | ||
| Honesty?Humility | GPT-3.5 | 38.44 | < 0.001 | 3.02 | 0.008 | 6.20 | < 0.001 | 3.18 | 0.004 |
| GPT-4 | 38.14 | < 0.001 | 3.27 | 0.003 | 6.17 | < 0.001 | 2.90 | 0.011 | |
| ERNIE 3.5 | 3.24 | 0.200 | 0.27 | 1.000 | 1.68 | 0.281 | 1.41 | 0.479 | |
| Emotionality | GPT-3.5 | 38.34 | < 0.001 | 2.97 | 0.009 | 6.19 | < 0.001 | 3.22 | 0.004 |
| GPT-4 | 34.71 | < 0.001 | 2.20 | 0.083 | 5.83 | < 0.001 | 3.63 | 0.001 | |
| ERNIE 3.5 | 39.38 | < 0.001 | 3.14 | 0.005 | 6.28 | < 0.001 | 3.14 | 0.005 | |
| Extraversion | GPT-3.5 | 39.60 | < 0.001 | 3.15 | 0.005 | 6.29 | < 0.001 | 3.15 | 0.005 |
| GPT-4 | 38.68 | < 0.001 | 3.22 | 0.004 | 6.22 | < 0.001 | 2.99 | 0.008 | |
| ERNIE 3.5 | 29.97 | < 0.001 | 1.06 | 0.865 | 5.18 | < 0.001 | 4.12 | < 0.001 | |
| Agreeableness | GPT-3.5 | 37.93 | < 0.001 | 3.28 | 0.003 | 6.15 | < 0.001 | 2.88 | 0.012 |
| GPT-4 | 34.76 | < 0.001 | 3.57 | 0.001 | 5.85 | < 0.001 | 2.27 | 0.069 | |
| ERNIE 3.5 | 32.78 | < 0.001 | 4.11 | < 0.001 | 5.51 | < 0.001 | 1.40 | 0.488 | |
| Conscientiousness | GPT-3.5 | 38.72 | < 0.001 | 3.22 | 0.004 | 6.22 | < 0.001 | 3.01 | 0.008 |
| GPT-4 | 38.98 | < 0.001 | 3.21 | 0.004 | 6.24 | < 0.001 | 3.04 | 0.007 | |
| ERNIE 3.5 | 39.64 | < 0.001 | 3.15 | 0.005 | 6.30 | < 0.001 | 3.15 | 0.005 | |
| Openness to Experience | GPT-3.5 | 32.20 | < 0.001 | 3.95 | < 0.001 | 5.50 | < 0.001 | 1.55 | 0.360 |
| GPT-4 | 38.76 | < 0.001 | 3.18 | 0.004 | 6.23 | < 0.001 | 3.05 | 0.007 | |
| ERNIE 3.5 | 37.74 | < 0.001 | 3.27 | 0.003 | 6.14 | < 0.001 | 2.87 | 0.012 | |
| Personality Trait | Personality Level | GPT-3.5 | GPT-4 | ERNIE 3.5 | |||
|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | ||
| Honesty?Humility | Low | 1.80 | 0.40 | 1.80 | 0.92 | 1.67 | 0.61 |
| Baseline | 2.93 | 0.61 | 3.27 | 0.76 | 3.67 | 0.31 | |
| High | 4.20 | 0.72 | 4.07 | 0.92 | 4.13 | 0.23 | |
| Emotionality | Low | 3.00 | 1.00 | 1.67 | 0.12 | 1.33 | 0.58 |
| Baseline | 2.87 | 0.31 | 2.60 | 0.60 | 2.47 | 0.42 | |
| High | 4.20 | 0.20 | 4.80 | 0.00 | 4.27 | 0.31 | |
| Extraversion | Low | 1.93 | 0.50 | 1.73 | 0.70 | 3.73 | 0.70 |
| Baseline | 2.27 | 0.90 | 3.13 | 1.22 | 3.80 | 0.35 | |
| High | 4.73 | 0.31 | 4.60 | 0.20 | 4.60 | 0.20 | |
| Agreeableness | Low | 1.60 | 0.53 | 1.67 | 0.42 | 2.07 | 0.31 |
| Baseline | 3.47 | 0.12 | 3.60 | 0.35 | 4.47 | 0.50 | |
| High | 4.33 | 0.50 | 4.27 | 0.31 | 4.67 | 0.12 | |
| Conscientiousness | Low | 2.00 | 0.35 | 1.87 | 0.64 | 2.27 | 0.50 |
| Baseline | 3.00 | 0.87 | 3.93 | 0.90 | 4.40 | 0.35 | |
| High | 4.93 | 0.12 | 4.67 | 0.23 | 4.80 | 0.00 | |
| Openness to Experience | Low | 1.40 | 0.20 | 1.73 | 0.50 | 1.73 | 0.31 |
| Baseline | 3.87 | 0.81 | 3.73 | 0.31 | 3.40 | 0.20 | |
| High | 4.33 | 0.12 | 4.67 | 0.42 | 4.60 | 0.20 | |
Table S3 Descriptive statistics of personality story scores across different levels of each personality trait for different LLMs in Study 1
| Personality Trait | Personality Level | GPT-3.5 | GPT-4 | ERNIE 3.5 | |||
|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | ||
| Honesty?Humility | Low | 1.80 | 0.40 | 1.80 | 0.92 | 1.67 | 0.61 |
| Baseline | 2.93 | 0.61 | 3.27 | 0.76 | 3.67 | 0.31 | |
| High | 4.20 | 0.72 | 4.07 | 0.92 | 4.13 | 0.23 | |
| Emotionality | Low | 3.00 | 1.00 | 1.67 | 0.12 | 1.33 | 0.58 |
| Baseline | 2.87 | 0.31 | 2.60 | 0.60 | 2.47 | 0.42 | |
| High | 4.20 | 0.20 | 4.80 | 0.00 | 4.27 | 0.31 | |
| Extraversion | Low | 1.93 | 0.50 | 1.73 | 0.70 | 3.73 | 0.70 |
| Baseline | 2.27 | 0.90 | 3.13 | 1.22 | 3.80 | 0.35 | |
| High | 4.73 | 0.31 | 4.60 | 0.20 | 4.60 | 0.20 | |
| Agreeableness | Low | 1.60 | 0.53 | 1.67 | 0.42 | 2.07 | 0.31 |
| Baseline | 3.47 | 0.12 | 3.60 | 0.35 | 4.47 | 0.50 | |
| High | 4.33 | 0.50 | 4.27 | 0.31 | 4.67 | 0.12 | |
| Conscientiousness | Low | 2.00 | 0.35 | 1.87 | 0.64 | 2.27 | 0.50 |
| Baseline | 3.00 | 0.87 | 3.93 | 0.90 | 4.40 | 0.35 | |
| High | 4.93 | 0.12 | 4.67 | 0.23 | 4.80 | 0.00 | |
| Openness to Experience | Low | 1.40 | 0.20 | 1.73 | 0.50 | 1.73 | 0.31 |
| Baseline | 3.87 | 0.81 | 3.73 | 0.31 | 3.40 | 0.20 | |
| High | 4.33 | 0.12 | 4.67 | 0.42 | 4.60 | 0.20 | |
| Personality Trait | LLM | Kruskal-Wallis Test | Low level vs. Baseline | Low level vs. High level | Baseline vs. High level | ||||
|---|---|---|---|---|---|---|---|---|---|
| χ2(2) | p | z | padj | z | padj | z | padj | ||
| Honesty?Humility | GPT-3.5 | 6.49 | 0.011 | 1.49 | 0.408 | 2.53 | 0.034 | 1.04 | 0.890 |
| GPT-4 | 5.11 | 0.083 | 1.35 | 0.534 | 2.25 | 0.074 | 0.90 | 1.000 | |
| ERNIE 3.5 | 6.71 | 0.011 | 1.52 | 0.388 | 2.58 | 0.030 | 1.06 | 0.866 | |
| Emotionality | GPT-3.5 | 4.91 | 0.100 | ?0.22 | 1.000 | 1.80 | 0.217 | 2.02 | 0.130 |
| GPT-4 | 7.51 | 0.004 | 1.37 | 0.512 | 2.74 | 0.018 | 1.37 | 0.512 | |
| ERNIE 3.5 | 6.94 | 0.007 | 1.20 | 0.687 | 2.63 | 0.026 | 1.43 | 0.460 | |
| Extraversion | GPT-3.5 | 5.54 | 0.054 | 0.30 | 1.000 | 2.17 | 0.090 | 1.87 | 0.184 |
| GPT-4 | 6.25 | 0.015 | 0.90 | 1.000 | 2.47 | 0.041 | 1.57 | 0.348 | |
| ERNIE 3.5 | 4.95 | 0.101 | ?0.23 | 1.000 | 1.80 | 0.214 | 2.03 | 0.127 | |
| Agreeableness | GPT-3.5 | 7.26 | 0.003 | 1.35 | 0.534 | 2.69 | 0.021 | 1.35 | 0.534 |
| GPT-4 | 6.94 | 0.007 | 1.43 | 0.460 | 2.63 | 0.026 | 1.20 | 0.687 | |
| ERNIE 3.5 | 5.65 | 0.028 | 1.80 | 0.217 | 2.25 | 0.074 | 0.45 | 1.000 | |
| Conscientiousness | GPT-3.5 | 7.32 | 0.004 | 1.35 | 0.528 | 2.71 | 0.020 | 1.35 | 0.528 |
| GPT-4 | 6.16 | 0.025 | 1.67 | 0.286 | 2.43 | 0.046 | 0.76 | 1.000 | |
| ERNIE 3.5 | 7.51 | 0.004 | 1.37 | 0.512 | 2.74 | 0.018 | 1.37 | 0.512 | |
| Openness to Experience | GPT-3.5 | 5.65 | 0.043 | 1.80 | 0.217 | 2.25 | 0.074 | 0.45 | 1.000 |
| GPT-4 | 7.20 | 0.003 | 1.34 | 0.539 | 2.68 | 0.022 | 1.34 | 0.539 | |
| ERNIE 3.5 | 7.20 | 0.004 | 1.34 | 0.539 | 2.68 | 0.022 | 1.34 | 0.539 | |
Table S4 Kruskal-Wallis test and Dunn’s post-hoc test results of personality story scores across different levels of each personality trait for different LLMs in Study 1
| Personality Trait | LLM | Kruskal-Wallis Test | Low level vs. Baseline | Low level vs. High level | Baseline vs. High level | ||||
|---|---|---|---|---|---|---|---|---|---|
| χ2(2) | p | z | padj | z | padj | z | padj | ||
| Honesty?Humility | GPT-3.5 | 6.49 | 0.011 | 1.49 | 0.408 | 2.53 | 0.034 | 1.04 | 0.890 |
| GPT-4 | 5.11 | 0.083 | 1.35 | 0.534 | 2.25 | 0.074 | 0.90 | 1.000 | |
| ERNIE 3.5 | 6.71 | 0.011 | 1.52 | 0.388 | 2.58 | 0.030 | 1.06 | 0.866 | |
| Emotionality | GPT-3.5 | 4.91 | 0.100 | ?0.22 | 1.000 | 1.80 | 0.217 | 2.02 | 0.130 |
| GPT-4 | 7.51 | 0.004 | 1.37 | 0.512 | 2.74 | 0.018 | 1.37 | 0.512 | |
| ERNIE 3.5 | 6.94 | 0.007 | 1.20 | 0.687 | 2.63 | 0.026 | 1.43 | 0.460 | |
| Extraversion | GPT-3.5 | 5.54 | 0.054 | 0.30 | 1.000 | 2.17 | 0.090 | 1.87 | 0.184 |
| GPT-4 | 6.25 | 0.015 | 0.90 | 1.000 | 2.47 | 0.041 | 1.57 | 0.348 | |
| ERNIE 3.5 | 4.95 | 0.101 | ?0.23 | 1.000 | 1.80 | 0.214 | 2.03 | 0.127 | |
| Agreeableness | GPT-3.5 | 7.26 | 0.003 | 1.35 | 0.534 | 2.69 | 0.021 | 1.35 | 0.534 |
| GPT-4 | 6.94 | 0.007 | 1.43 | 0.460 | 2.63 | 0.026 | 1.20 | 0.687 | |
| ERNIE 3.5 | 5.65 | 0.028 | 1.80 | 0.217 | 2.25 | 0.074 | 0.45 | 1.000 | |
| Conscientiousness | GPT-3.5 | 7.32 | 0.004 | 1.35 | 0.528 | 2.71 | 0.020 | 1.35 | 0.528 |
| GPT-4 | 6.16 | 0.025 | 1.67 | 0.286 | 2.43 | 0.046 | 0.76 | 1.000 | |
| ERNIE 3.5 | 7.51 | 0.004 | 1.37 | 0.512 | 2.74 | 0.018 | 1.37 | 0.512 | |
| Openness to Experience | GPT-3.5 | 5.65 | 0.043 | 1.80 | 0.217 | 2.25 | 0.074 | 0.45 | 1.000 |
| GPT-4 | 7.20 | 0.003 | 1.34 | 0.539 | 2.68 | 0.022 | 1.34 | 0.539 | |
| ERNIE 3.5 | 7.20 | 0.004 | 1.34 | 0.539 | 2.68 | 0.022 | 1.34 | 0.539 | |
| Personality Trait | Personality Level | Human | GPT-3.5 | GPT-4 | ERNIE 3.5 | ||||
|---|---|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | M | SD | ||
| Honesty?Humility | High | 0.45 | 0.12 | 0.27 | 0.41 | 0.13 | 0.33 | 0.45 | 0.46 |
| Low | 0.51 | 0.17 | 0.99 | 0.06 | 0.97 | 0.09 | 1.00 | 0.00 | |
| Emotionality | High | 0.51 | 0.02 | 0.51 | 0.05 | 0.08 | 0.03 | 0.89 | 0.03 |
| Low | 0.48 | 0.01 | 0.36 | 0.05 | 0.26 | 0.05 | 0.58 | 0.06 | |
| Extraversion | High | 0.59 | 0.09 | 0.56 | 0.40 | 0.32 | 0.43 | 0.88 | 0.25 |
| Low | 0.44 | 0.16 | 0.26 | 0.31 | 0.17 | 0.33 | 0.88 | 0.25 | |
| Agreeableness | High | 0.54 | 0.11 | 0.30 | 0.43 | 0.15 | 0.35 | 0.53 | 0.46 |
| Low | 0.44 | 0.17 | 0.98 | 0.07 | 0.74 | 0.36 | 0.95 | 0.16 | |
| Conscientiousness | High | 0.55 | 0.10 | 0.47 | 0.44 | 0.19 | 0.38 | 0.67 | 0.40 |
| Low | 0.50 | 0.14 | 0.68 | 0.30 | 0.28 | 0.35 | 0.83 | 0.30 | |
| Openness to Experience | High | 0.64 | 0.08 | 0.46 | 0.42 | 0.19 | 0.36 | 0.73 | 0.36 |
| Low | 0.47 | 0.17 | 0.47 | 0.38 | 0.34 | 0.43 | 0.49 | 0.41 | |
Table S5 Descriptive statistics of utilitarian tendencies across different levels of each personality trait for different agent types in Study 2
| Personality Trait | Personality Level | Human | GPT-3.5 | GPT-4 | ERNIE 3.5 | ||||
|---|---|---|---|---|---|---|---|---|---|
| M | SD | M | SD | M | SD | M | SD | ||
| Honesty?Humility | High | 0.45 | 0.12 | 0.27 | 0.41 | 0.13 | 0.33 | 0.45 | 0.46 |
| Low | 0.51 | 0.17 | 0.99 | 0.06 | 0.97 | 0.09 | 1.00 | 0.00 | |
| Emotionality | High | 0.51 | 0.02 | 0.51 | 0.05 | 0.08 | 0.03 | 0.89 | 0.03 |
| Low | 0.48 | 0.01 | 0.36 | 0.05 | 0.26 | 0.05 | 0.58 | 0.06 | |
| Extraversion | High | 0.59 | 0.09 | 0.56 | 0.40 | 0.32 | 0.43 | 0.88 | 0.25 |
| Low | 0.44 | 0.16 | 0.26 | 0.31 | 0.17 | 0.33 | 0.88 | 0.25 | |
| Agreeableness | High | 0.54 | 0.11 | 0.30 | 0.43 | 0.15 | 0.35 | 0.53 | 0.46 |
| Low | 0.44 | 0.17 | 0.98 | 0.07 | 0.74 | 0.36 | 0.95 | 0.16 | |
| Conscientiousness | High | 0.55 | 0.10 | 0.47 | 0.44 | 0.19 | 0.38 | 0.67 | 0.40 |
| Low | 0.50 | 0.14 | 0.68 | 0.30 | 0.28 | 0.35 | 0.83 | 0.30 | |
| Openness to Experience | High | 0.64 | 0.08 | 0.46 | 0.42 | 0.19 | 0.36 | 0.73 | 0.36 |
| Low | 0.47 | 0.17 | 0.47 | 0.38 | 0.34 | 0.43 | 0.49 | 0.41 | |
| [1] |
Ashton, M. C., & Lee, K. (2007). Empirical, theoretical, and practical advantages of the HEXACO model of personality structure. Personality and Social Psychology Review, 11(2), 150-166.
doi: 10.1177/1088868306294907 pmid: 18453460 |
| [2] |
Ashton, M. C., & Lee, K. (2008a). The HEXACO model of personality structure and the importance of the H Factor. Social and Personality Psychology Compass, 2(5), 1952-1962.
doi: 10.1111/spco.2008.2.issue-5 URL |
| [3] |
Ashton, M. C., & Lee, K. (2008b). The prediction of Honesty-Humility-related criteria by the HEXACO and Five-Factor Models of personality. Journal of Research in Personality, 42(5), 1216-1228.
doi: 10.1016/j.jrp.2008.03.006 URL |
| [4] |
Ashton, M. C., & Lee, K. (2009). The HEXACO-60: A short measure of the major dimensions of personality. Journal of Personality Assessment, 91(4), 340-345.
doi: 10.1080/00223890902935878 pmid: 20017063 |
| [5] | Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big?. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (pp. 610-623). Association for Computing Machinery. |
| [6] | Bodroža, B., Dinić, B. M., & Bojić, L. (2024). Personality testing of large language models: Limited temporal stability, but highlighted prosociality. Royal Society Open Science, 11(10), 240180. |
| [7] |
Bonnefon, J. F., Rahwan, I., & Shariff, A. (2024). The moral psychology of artificial intelligence. Annual Review of Psychology, 75(1), 653-675.
doi: 10.1146/psych.2024.75.issue-1 URL |
| [8] | Borman, H., Leontjeva, A., Pizzato, L., Jiang, M. K., & Jermyn, D. (2024). Do LLM personas dream of bull markets? Comparing human and AI investment strategies through the lens of the five-factor model. arXiv. https://doi.org/10.48550/arXiv.2411.05801 |
| [9] | Chen, R., Arditi, A., Sleight, H., Evans, O., & Lindsey, J. (2025). Persona vectors: Monitoring and controlling character traits in language models. arXiv. https://doi.org/10.48550/arXiv.2507.21509 |
| [10] | Corrêa, N. K., Galvão, C., Santos, J. W., Del Pino, C., Pinto, E. P., Barbosa, C.,... de Oliveira, N. (2023). Worldwide AI ethics: A review of 200 guidelines and recommendations for AI Governance. Patterns, 4(10), 100857. |
| [11] |
DeYoung, C. G., Peterson, J. B., & Higgins, D. M. (2002). Higher-order factors of the Big Five predict conformity: Are there neuroses of health? Personality and Individual Differences, 33(4), 533-552.
doi: 10.1016/S0191-8869(01)00171-4 URL |
| [12] |
Djeriouat, H., & Trémolière, B. (2014). The Dark Triad of personality and utilitarian moral judgment: The mediating role of Honesty/Humility and Harm/Care. Personality and Individual Differences, 67, 11-16.
doi: 10.1016/j.paid.2013.12.026 URL |
| [13] |
Gabriel, I. (2020). Artificial intelligence, values, and alignment. Minds and Machines, 30, 411-437.
doi: 10.1007/s11023-020-09539-2 |
| [14] |
Graham, J., Meindl, P., Beall, E., Johnson, K. M., & Zhang, L. (2016). Cultural differences in moral judgment and behavior, across and within societies. Current Opinion in Psychology, 8, 125-130.
doi: S2352-250X(15)00233-X pmid: 29506787 |
| [15] | Hadi, M. U., Tashi, Q. A., Qureshi, R., Shah, A., Muneer, A., Irfan, M.,... Shah, M. (2025). Large language models: A comprehensive survey of its applications, challenges, limitations, and future prospects. TechRxiv. https://doi.org/10.36227/techrxiv.23589741.v8 |
| [16] | Hagendorff, T. (2024). Deception abilities emerged in large language models. Proceedings of the National Academy of Sciences, USA, 121(24), e2317967121. |
| [17] | Hagendorff, T., Dasgupta, I., Binz, M., Chan, S. C., Lampinen, A., Wang, J. X., Akata, Z., & Schulz, E. (2023). Machine Psychology. arXiv. https://doi.org/10.48550/arXiv.2303.13988 |
| [18] | He, J., & Liu, J. (2025). Investigating the impact of LLM personality on cognitive bias manifestation in automated decision-making tasks. arXiv. https://doi.org/10.48550/arXiv.2502.14219 |
| [19] |
Hilbig, B. E., Glöckner, A., & Zettler, I. (2014). Personality and prosocial behavior: linking basic traits and social value orientations. Journal of Personality and Social Psychology, 107(3), 529-539.
doi: 10.1037/a0036074 pmid: 25019254 |
| [20] |
Hu, X., Li, M., Li, Y., Li, K., & Yu, F. (2026). Moral deficiency in AI decision-making: Underlying mechanisms and mitigation strategies. Acta Psychologica Sinica, 58(1), 74-95.
doi: 10.3724/SP.J.1041.2026.0074 |
| [21] | Hu, X., Li, M., Wang, D., & Yu, F. (2024). Reactions to immoral AI decisions: The moral deficit effect and its underlying mechanism. Chinese Science Bulletin, 69(11), 1406-1416. |
| [22] | Jiang, G., Xu, M., Zhu, S. C., Han, W., Zhang, C., & Zhu, Y. (2023). Evaluating and inducing personality in pre-trained language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, & S. Levine (Eds.), Proceedings of the 37th International Conference on Neural Information Processing Systems (pp. 10622-10643). Curran Associates Inc. |
| [23] | Jiang, H., Zhang, X., Cao, X., Breazeal, C., Roy, D., & Kabbara, J. (2024). PersonaLLM:Investigating the ability of large language models to express personality traits.In K. Duh, H. Gomez, & S. Bethard (Eds.), Findings of the Association for Computational Linguistics: NAACL 2024 (pp.3605-3627). Association for Computational Linguistics. |
| [24] |
Jiao, L., Li, C.-J., Chen, Z., Xu, H., & Xu, Y. (2025). When AI “possesses” personality: Roles of good and evil personalities influence moral judgment in large language models. Acta Psychologica Sinica, 57(6), 929-946.
doi: 10.3724/SP.J.1041.2025.0929 |
| [25] |
Jiao, L., Yang, Y., Xu, Y., Gao, S., & Zhang, H. (2019). Good and evil in Chinese culture: Personality structure and connotation. Acta Psychologica Sinica, 51(10), 1128-1142.
doi: 10.3724/SP.J.1041.2019.01128 |
| [26] |
Jobin, A., Ienca, M., & Vayena, E. (2019). The global landscape of AI ethics guidelines. Nature Machine Intelligence, 1, 389-399.
doi: 10.1038/s42256-019-0088-2 |
| [27] |
Kroneisen, M., & Heck, D. W. (2020). Interindividual differences in the sensitivity for consequences, moral norms, and preferences for inaction: Relating basic personality traits to the CNI model. Personality and Social Psychology Bulletin, 46(7), 1013-1026.
doi: 10.1177/0146167219893994 pmid: 31889471 |
| [28] |
Kruglanski, A. W., Szumowska, E., Kopetz, C. H., Vallerand, R. J., & Pierro, A. (2021). On the psychology of extremism: How motivational imbalance breeds intemperance. Psychological Review, 128(2), 264-289.
doi: 10.1037/rev0000260 URL |
| [29] |
Lee, K., & Ashton, M. C. (2004). Psychometric properties of the HEXACO personality inventory. Multivariate Behavioral Research, 39(2), 329-358.
doi: 10.1207/s15327906mbr3902_8 pmid: 26804579 |
| [30] |
Lee, K., & Ashton, M. C. (2008). The HEXACO personality factors in the indigenous personality lexicons of English and 11 other languages. Journal of Personality, 76(5), 1001-1054.
doi: 10.1111/j.1467-6494.2008.00512.x pmid: 18665898 |
| [31] |
Lee, K., & Ashton, M. C. (2014). The dark triad, the big five, and the HEXACO model. Personality and Individual Differences, 67, 2-5.
doi: 10.1016/j.paid.2014.01.048 URL |
| [32] |
Lee, K., Ashton, M. C., Wiltshire, J., Bourdage, J. S., Visser, B. A., & Gallucci, A. (2013). Sex, power, and money: Prediction from the Dark Triad and Honesty-Humility. European Journal of Personality, 27(2), 169-184.
doi: 10.1002/per.1860 URL |
| [33] | Lin, B. Y., Ravichander, A., Lu, X., Dziri, N., Sclar, M., Chandu, K., Bhagavatula, C., & Choi, Y. (2023). The unlocking spell on base LLMs: Rethinking alignment via in-context learning. arXiv. https://doi.org/10.48550/arXiv.2312.01552 |
| [34] |
Lomas, T. (2019). The roots of virtue: A cross-cultural lexical analysis. Journal of Happiness Studies, 20, 1259-1279.
doi: 10.1007/s10902-018-9997-8 |
| [35] |
Lotto, L., Manfrinati, A., & Sarlo, M. (2014). A new set of moral dilemmas: Norms for moral acceptability, decision times, and emotional salience. Journal of Behavioral Decision Making, 27(1), 57-65.
doi: 10.1002/bdm.v27.1 URL |
| [36] |
Lu, J. G., Song, L. L., & Zhang, L. D. (2025). Cultural tendencies in generative AI. Nature Human Behaviour, 9, 2360-2369.
doi: 10.1038/s41562-025-02242-1 |
| [37] |
Matei, M.-C., & Abrudan, M.-M. (2018). Are national cultures changing? Evidence from the World Values Survey. Procedia-Social and Behavioral Sciences, 238, 657-664.
doi: 10.1016/j.sbspro.2018.04.047 URL |
| [38] | Minaee, S., Mikolov, T., Nikzad, N., Chenaghlu, M., Socher, R., Amatriain, X., & Gao, J. (2024). Large language models: A survey. arXiv. https://doi.org/10.48550/arXiv.2402.06196 |
| [39] |
Mittelstadt, B. (2019). Principles alone cannot guarantee ethical AI. Nature Machine Intelligence, 1, 501-507.
doi: 10.1038/s42256-019-0114-4 |
| [40] |
Moser, C., Den Hond, F., & Lindebaum, D. (2022). Morality in the age of artificially intelligent algorithms. Academy of Management Learning and Education, 21(1), 139-155.
doi: 10.5465/amle.2020.0287 URL |
| [41] | Newsham, L., & Prince, D. (2025). Personality-driven decision making in LLM-based autonomous agents. In S. Das, A. Nowé (General Chairs), & Y. Vorobeychik (Program Chair), Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems (pp. 1538-1547). International Foundation for Autonomous Agents and Multiagent Systems. |
| [42] | Ng, A. Y., & Russell, S. J. (2000). Algorithms for inverse reinforcement learning. In P. Langley (Ed.), Proceedings of the Seventeenth International Conference on Machine Learning (pp. 663-670). Morgan Kaufmann Publishers Inc. |
| [43] | Nighojkar, A., Moydinboyev, B., Duong, M., & Licato, J. (2025). Giving AI personalities leads to more human-like reasoning. arXiv. https://doi.org/10.48550/arXiv.2502.14155 |
| [44] |
Niszczota, P., Janczak, M., & Misiak, M. (2025). Large language models can replicate cross-cultural differences in personality. Journal of Research in Personality, 115, 104584.
doi: 10.1016/j.jrp.2025.104584 URL |
| [45] | OpenAI. (2023). GPT-4 technical report. arXiv. https://doi.org/10.48550/arXiv.2303.08774 |
| [46] | Ramezani, A., & Xu, Y. (2023). Knowledge of cultural moral norms in large language models. In A. Rogers, J. Boyd-Graber, & N. Okazaki (Eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers; pp. 428-446). Association for Computational Linguistics. |
| [47] |
Saucier, G., Kenner, J., Iurino, K., Bou Malham, P., Chen, Z., Thalmayer, A. G.,... Altschul, C. (2014). Cross-cultural differences in a global “survey of world views”. Journal of Cross-Cultural Psychology, 46(1), 53-70.
doi: 10.1177/0022022114551791 URL |
| [48] |
Serapio-García, G., Safdari, M., Crepy, C., Sun, L., Fitz, S., Romero, P.,... Matarić, M. (2025). A psychometric framework for evaluating and shaping personality traits in large language models. Nature Machine Intelligence, 7, 1954-1968.
doi: 10.1038/s42256-025-01115-6 |
| [49] |
Shanahan, M., McDonell, K., & Reynolds, L. (2023). Role play with large language models. Nature, 623, 493-498.
doi: 10.1038/s41586-023-06647-8 |
| [50] | Sorokovikova, A., Fedorova, N., Rezagholi, S., & Yamshchikov, I. P. (2024). LLMs simulate big five personality traits: Further evidence. arXiv. https://doi.org/10.48550/arXiv.2402.01765 |
| [51] |
Strus, W., & Cieciuch, J. (2021). Higher-order factors of the big six-similarities between big twos identified above the big five and the big six. Personality and Individual Differences, 171, 110544.
doi: 10.1016/j.paid.2020.110544 URL |
| [52] |
Thielmann, I., Spadaro, G., & Balliet, D. (2020). Personality and prosocial behavior: A theoretical framework and meta-analysis. Psychological Bulletin, 146(1), 30-90.
doi: 10.1037/bul0000217 pmid: 31841013 |
| [53] | Tong, H., Lu, E., Sun, Y., Han, Z., Liu, C., Zhao, F., & Zeng, Y. (2024). Autonomous alignment with human value on altruism through considerate self-imagination and theory of mind. arXiv. https://doi.org/10.48550/arXiv.2501.00320 |
| [54] |
Treglown, L., & Furnham, A. (2026). AI, social desirability, and personality assessments: Impression management in large language models. Personality and Individual Differences, 251, 113563.
doi: 10.1016/j.paid.2025.113563 URL |
| [55] | Wang, P., Zou, H., Yan, Z., Guo, F., Sun, T., Xiao, Z., & Zhang, B. (2024). Not yet: Large language models cannot replace human respondents for psychometric research. OSF Preprints. https://doi.org/10.31219/osf.io/rwy9b |
| [56] | Wang, S., Li, R., Chen, X., Yuan, Y., Yang, M., & Wong, D. F. (2025). Exploring the impact of personality traits on LLM bias and toxicity. In C. Christodoulopoulos, T. Chakraborty, C. Rose, & V. Peng (Eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (pp. 4125-4143). Association for Computational Linguistics. |
| [57] | Wang, X., Duan, S., Yi, X., Yao, J., Zhou, S., Wei, Z.,... Xie, X. (2024). On the essence and prospect: An investigation of alignment approaches for big models. In K. Larson (Ed.), Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (pp. 8308-8316). Curran Associates Inc. |
| [58] |
Wu, M. S., & Peng, K. (2025). Human advantages and psychological transformations in the era of artificial intelligence. Acta Psychologica Sinica, 57(11), 1879-1884.
doi: 10.3724/SP.J.1041.2025.1879 |
| [59] | Xu, Y. (2024). Personality psychology (3rd ed.). Beijing, China: Beijing Normal University Publishing Group. |
| [60] |
Xu, Z., Sengar, N., Chen, T., Chung, H., & Oviedo- Trespalacios, O. (2025). Where is morality on wheels? Decoding large language model (LLM)-driven decision in the ethical dilemmas of autonomous vehicles. Travel Behaviour and Society, 40, 101039.
doi: 10.1016/j.tbs.2025.101039 URL |
| [61] | Yao, J., Yi, X., Wang, X., Wang, J., & Xie, X. (2023). From instructions to intrinsic human values--A survey of alignment goals for big models. arXiv. https://doi.org/10.48550/arXiv.2308.12014 |
| [62] | Yu, B., & Kim, J. (2024). Personality of AI. In L. Rutkowski, R. Scherer, M. Korytkowski, W. Pedrycz, R. Tadeusiewicz, & J. M. Zurada (Eds.), Artificial Intelligence and Soft Computing: 23rd International Conference (pp. 244-252). Springer, Cham. |
| [63] | Yuan, X., Hu, J., & Zhang, Q. (2024). A comparative analysis of cultural alignment in large language models in bilingual contexts. OSF Preprints. https://doi.org/10.31219/osf.io/6hpcf |
| [64] |
Zaim bin Ahmad, M. S., & Takemoto, K. (2025). Large-scale moral machine experiment on large language models. PloS One, 20(5), e0322776.
doi: 10.1371/journal.pone.0322776 URL |
| [65] | Zhao, G. L. (2023-06-20). Actual scores surpass ChatGPT! Baidu Wenxin Large Model Version 3.5 internal test application. China Science Daily. https://news.sciencenet.cn/htmlnews/2023/6/503256.shtm |
| [66] | Zhou, C., Liu, P., Xu, P., Iyer, S., Sun, J., Mao, Y.,... Levy, O. (2023). LIMA:less is more for alignment. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, & S. Levine (Eds.), Proceedings of the 37th International Conference on Neural Information Processing Systems (pp. 55006-55021). Curran Associates Inc. |
| [67] |
Zhou, X., & Liu, H. (2024). New ethical challenges in the digital and intelligent era. Acta Psychologica Sinica, 56(2), 143-145.
doi: 10.3724/SP.J.1041.2024.00143 URL |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||