ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
Advances in Psychological Science ›› 2025, Vol. 33 ›› Issue (10): 1766-1782.doi: 10.3724/SP.J.1042.2025.1766
• Research Method • Previous Articles Next Articles
HAN Yuting1,2,3, WANG Wenxuan4, LIU Hongyun5,6( ), YOU Xiaofeng7
), YOU Xiaofeng7
Received:2025-02-22
Online:2025-10-15
Published:2025-08-18
Contact:
LIU Hongyun
E-mail:hyliu@bnu.edu.cn
CLC Number:
HAN Yuting, WANG Wenxuan, LIU Hongyun, YOU Xiaofeng. Technical innovations and practical challenges in automatic item generation[J]. Advances in Psychological Science, 2025, 33(10): 1766-1782.
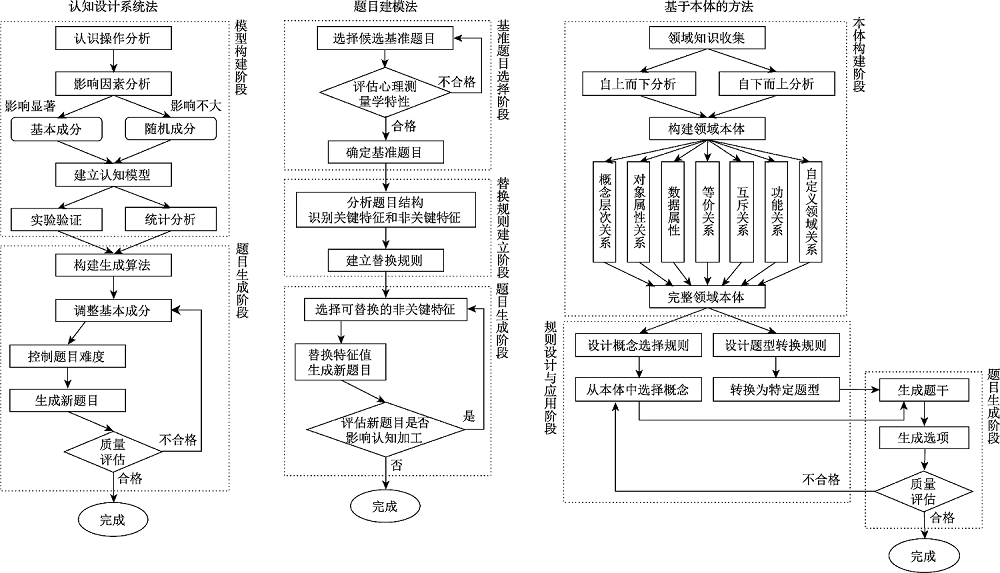
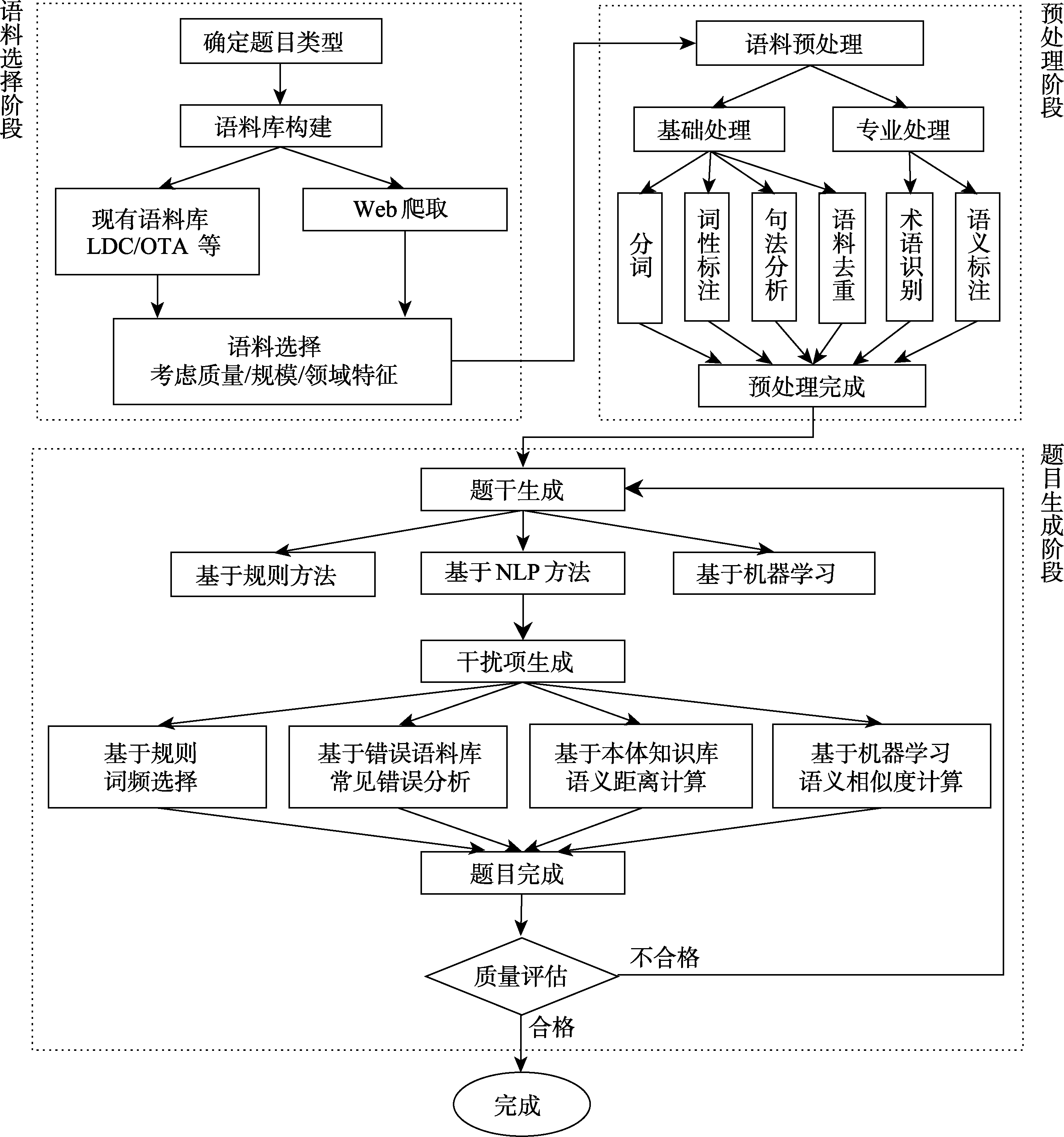
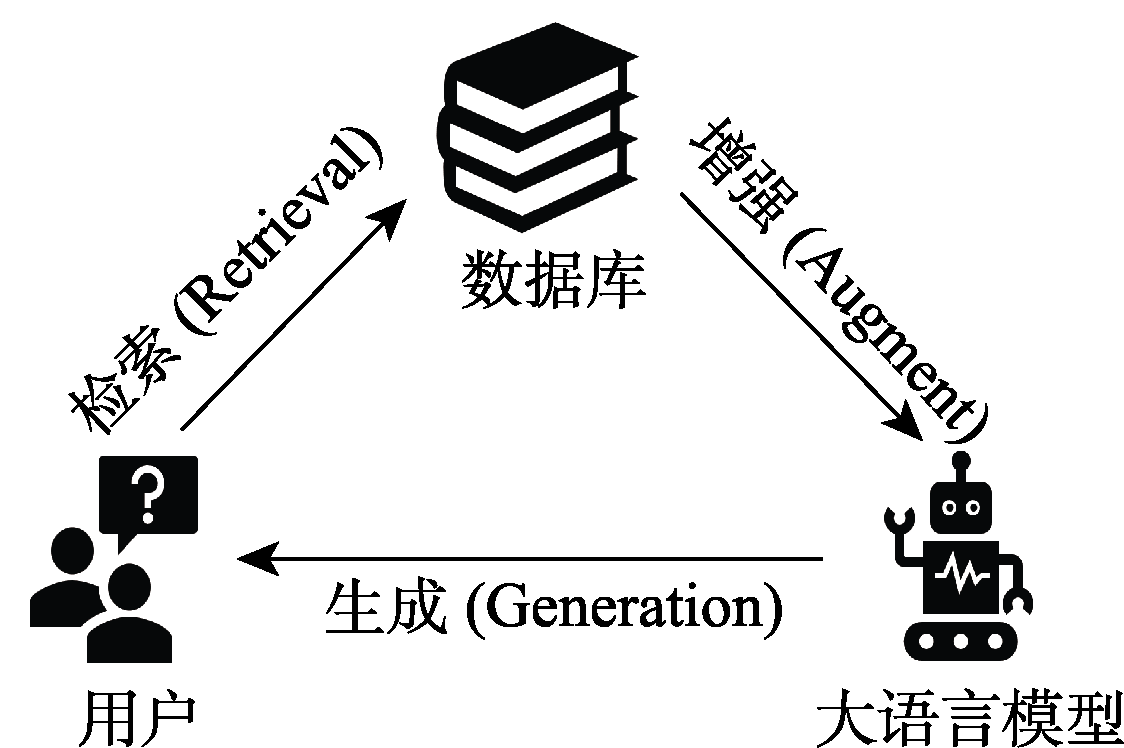

| 审核维度 | 审核子维度 | 具体内容 |
|---|---|---|
| 内容有效性与准确性 | 1. 概念相关性与内容有效性 | 题目与测验目标的一致性; 题目与测量目标构念相关; 题目与源领域一致; 题目准确测量其预期测量内容; 题目明确表现构念特征 |
| 2. 内容(专业)准确性 | 学科概念的准确性; 专业术语的正确使用; 专业测验中事实性内容的验证; 不包含误导性信息、防止错误信息传播 | |
| 3. 信息(概念)深度与完整性 | 解释性内容的详细程度与质量; 对测验中复杂概念的完整解释; 超出表面层次的专业原理阐述; 专业测验与实际专业实践的关联性; 医学测验中临床情境的合理设计与描述完整性(如实验室检测值的临床意义、诊断标准的合理性、临床场景的真实性、与实际医疗实践的关联、医学概念的整合应用) | |
| 4. 题目内容多样性 | 测验题目中不同情境与场景的多样体现; 医学测验中临床情境的代表性多样化(医学案例中患者人口统计学的多样化、不同疾病阶段与共病情况的体现) | |
| 5. 难度符合预期 | 符合布鲁姆分类法的不同认知水平; 题目难度与目标群体水平的匹配度; 问题的认知挑战程度; 答案不应过于明显; 区分事实型问题(可从单一句子推断)与推理型问题(需要深入理解或更长上下文); 阅读测验中语料的适当水平 | |
| 题目结构与语言表达 | 1. 语言表达质量 | 表述的语法正确性、拼写正确性、表述清晰度、阅读流畅性、文本可读性连贯性、语言无歧义性 |
| 2. 题目结构与格式 | 题目整体结构和格式的适当性; 符合标准题目模板与规范; 避免题干在选项中重复 | |
| 3. 选项设计 | 选择题中选项格式(如长度、数字格式、百分比符号等)、词性类别、语法形式、详细程度的一致性; 正确答案的唯一性; 正确答案的准确性与有效性; 干扰项的迷惑性、连贯性; 干扰项语法正确、符合人类的逻辑和常识; 干扰项在语境中合理但不正确; 避免选项之间的重复或过度重叠 | |
| 4. 阅读语料 | 阅读语料不存在令人困惑或分散注意力的元素; 阅读语料的趣味性(是否能够吸引受试者回答) | |
| 5. 关联性与逻辑 | 题目与阅读语料主题相关、语义相关、逻辑一致; 题目涵盖阅读语料中重要、有趣的方面; 选项与题目和语料的相关性 | |
| 6. 完善性与可回答性 | 包含题目、答案和必要解析等完整组成部分; 不需人工填补缺失内容; 题目提供了足够的信息使问题可回答; 答案明确 | |
| 7. 内容冗余与重复 | 题目集合中无相似(冗余)题目; 自动生成的题目避免与源题目过于相似 | |
| 伦理与公平性 | 1. 公平性与偏见 | 测验内容以尊重的方式对待各群体; 最小化与构念无关的知识或技能的影响; 避免不必要的有争议、煽动性、冒犯或令人不安的材料; 使用适当的术语指代人群; 避免刻板印象; 在描述人物时体现多样性; 不包含过于文化特定的内容、技术或特定领域的专业术语、对测试者可能敏感的材料 |
| 2. 道德性 | 题目内容不挑战任何既有法律与法规; 尊重作答者的认知和道德水平; 不作任何价值观上的误导; 不包含可能有害的内容 | |
| 教育适用性 | 1. 与教学内容的匹配度 | 匹配课程中教授的内容(不超纲)、考查所学课程涵盖的知识点; 反映课程中强调的重点; |
| 2. 教学实用性 | 具有教学价值和意义; 对特定教学背景/培训情境的适合度 | |
| 元评估与生成过程 | 1. 评估确定性 | 评估者对自己评分的确定程度 |
| 2. 提示有效性 | 用来生成题目的提示框架和模板的有效性、可解释性、实用性和全面性 |
| 审核维度 | 审核子维度 | 具体内容 |
|---|---|---|
| 内容有效性与准确性 | 1. 概念相关性与内容有效性 | 题目与测验目标的一致性; 题目与测量目标构念相关; 题目与源领域一致; 题目准确测量其预期测量内容; 题目明确表现构念特征 |
| 2. 内容(专业)准确性 | 学科概念的准确性; 专业术语的正确使用; 专业测验中事实性内容的验证; 不包含误导性信息、防止错误信息传播 | |
| 3. 信息(概念)深度与完整性 | 解释性内容的详细程度与质量; 对测验中复杂概念的完整解释; 超出表面层次的专业原理阐述; 专业测验与实际专业实践的关联性; 医学测验中临床情境的合理设计与描述完整性(如实验室检测值的临床意义、诊断标准的合理性、临床场景的真实性、与实际医疗实践的关联、医学概念的整合应用) | |
| 4. 题目内容多样性 | 测验题目中不同情境与场景的多样体现; 医学测验中临床情境的代表性多样化(医学案例中患者人口统计学的多样化、不同疾病阶段与共病情况的体现) | |
| 5. 难度符合预期 | 符合布鲁姆分类法的不同认知水平; 题目难度与目标群体水平的匹配度; 问题的认知挑战程度; 答案不应过于明显; 区分事实型问题(可从单一句子推断)与推理型问题(需要深入理解或更长上下文); 阅读测验中语料的适当水平 | |
| 题目结构与语言表达 | 1. 语言表达质量 | 表述的语法正确性、拼写正确性、表述清晰度、阅读流畅性、文本可读性连贯性、语言无歧义性 |
| 2. 题目结构与格式 | 题目整体结构和格式的适当性; 符合标准题目模板与规范; 避免题干在选项中重复 | |
| 3. 选项设计 | 选择题中选项格式(如长度、数字格式、百分比符号等)、词性类别、语法形式、详细程度的一致性; 正确答案的唯一性; 正确答案的准确性与有效性; 干扰项的迷惑性、连贯性; 干扰项语法正确、符合人类的逻辑和常识; 干扰项在语境中合理但不正确; 避免选项之间的重复或过度重叠 | |
| 4. 阅读语料 | 阅读语料不存在令人困惑或分散注意力的元素; 阅读语料的趣味性(是否能够吸引受试者回答) | |
| 5. 关联性与逻辑 | 题目与阅读语料主题相关、语义相关、逻辑一致; 题目涵盖阅读语料中重要、有趣的方面; 选项与题目和语料的相关性 | |
| 6. 完善性与可回答性 | 包含题目、答案和必要解析等完整组成部分; 不需人工填补缺失内容; 题目提供了足够的信息使问题可回答; 答案明确 | |
| 7. 内容冗余与重复 | 题目集合中无相似(冗余)题目; 自动生成的题目避免与源题目过于相似 | |
| 伦理与公平性 | 1. 公平性与偏见 | 测验内容以尊重的方式对待各群体; 最小化与构念无关的知识或技能的影响; 避免不必要的有争议、煽动性、冒犯或令人不安的材料; 使用适当的术语指代人群; 避免刻板印象; 在描述人物时体现多样性; 不包含过于文化特定的内容、技术或特定领域的专业术语、对测试者可能敏感的材料 |
| 2. 道德性 | 题目内容不挑战任何既有法律与法规; 尊重作答者的认知和道德水平; 不作任何价值观上的误导; 不包含可能有害的内容 | |
| 教育适用性 | 1. 与教学内容的匹配度 | 匹配课程中教授的内容(不超纲)、考查所学课程涵盖的知识点; 反映课程中强调的重点; |
| 2. 教学实用性 | 具有教学价值和意义; 对特定教学背景/培训情境的适合度 | |
| 元评估与生成过程 | 1. 评估确定性 | 评估者对自己评分的确定程度 |
| 2. 提示有效性 | 用来生成题目的提示框架和模板的有效性、可解释性、实用性和全面性 |
| 文献 | 基座模型 | 应用领域 | 题型 | 参数微调策略 | 微调训练数据集 | 提示策略 | 结果 |
|---|---|---|---|---|---|---|---|
| 窦若琳( | BERT | 数学应用题自动解题和自动出题 | 数学应用题(文本数学题) | 研究分别训练了三个主要模型:MBERT预训练模型, 通过回归、分类和掩码预测任务对BERT进行领域适应; 自动解题模型利用预训练模型中间层语义特征构造依赖图, 并使用目标驱动的树解码器生成答案; 自动出题模型采用图卷积网络编码结构信息, 并利用解题模型反馈进行质量评估和参数优化。 | Math23K (含23, 161道中文数学应用题)和Ape210K (含210, 488道中文数学应用题) | 自动解题模型在Math23K上表达式准确率72.0%, 答案数值准确率84.2%, 在Ape210K上表达式准确率65.2%, 答案数值准确率78.1%; 生成问题的表达多样性高, 与输入表达式的逻辑一致性好, 问题描述符合数学应用题的规范 | |
| 张津旭( | UniLM和mT5 | 中文阅读理解测验 | 简答题 | 两个模型都通过随机替换(构造负样本增强模型泛化能力)缓解训练与推理不一致问题; 通过对抗训练(在Embedding层添加扰动)增强模型泛化能力。UniLM额外将问题类型作为特征输入提高问题精确性, 利用伪标签再训练扩充数据集, 并采用基于词粒度的WoBERT预训练参数; 而mT5则通过自定义输入格式优化任务表示。 | CMRC2018(中文阅读理解数据集)和中医药数据集 | 优化后的UniLM和mT5模型在问题生成效果(BLEU、ROUGE-L指标)上均优于基线模型; mT5模型速度比UniLM快60%, 但准确率略低; 75%以上学生认为系统有助于提升提问能力 | |
| 杨生文(2021) | 问题生成使用UniLM; 干扰项生成使用BERT | 英语阅读理解测验 | 选择题 | 问题生成部分先通过BERT+BiLSTM+ CRF结构抽取答案, 将答案用特殊标记<a>替换, 然后微调UniLM模型生成问题, 并应用语义相似度计算增加多样性。干扰项生成部分利用BERT编码问题和文章, 获取上下文表示, 使用LSTM单独编码正确答案, 通过双线性变换提取干扰信息, 最后基于干扰注意力机制解码生成具有迷惑性的选项。 | 问题生成使用SQuAD 1.1(一个包含超过10万个问题-答案对的阅读理解数据集); 干扰项生成使用RACE数据集(来自中国初高中英语考试) | 问题生成:BLEU-4=22.15, 生成的问题很少包含目标答案; 干扰项生成:BLEU-4=12.33, 人工评估干扰项的流利度、连贯性和迷惑性均较高 | |
| Lelkes等( | PEGASUS; T5; T5-Large | 新闻知识评估 | 选择题 | 先在现有问答数据集上微调, 训练了一个问题-答案生成(QAG)模型, 再基于自生成问答数据训练干扰项生成(DG)模型; 输入前缀标签(如 “Style SQuAD:”)区分不同数据集风格。 | NewsQuizQA (20K问答对, 5K新闻摘要)SQuAD、NQ、NewsQA | QAG模型在ROUGE-QAG指标上优于所有基线; DG模型在多个人工评估指标上表现良好; 44%用户认为测验有教育价值, 49%希望将其纳入常规新闻阅读体验 | |
| Rathod等( | ProphetNet用作题目生成、T5用作题目改写 | 阅读理解测验 | 多个语义相似但用词不同的测量相同概念的平行问题 | 使用ProphetNet从SQuAD中的问题-答案对生成问题, 构建初始训练数据; 将生成的问题输入已经在Quora Question Pairs上训练过的T5改写模型获得改写版本; 使用拓展后的数据集对ProphetNet进行微调, 使其学会直接生成成对的问题。 | SQuAD 1.1; 训练T5改写模型使用Quora Question Pairs数据集 | 问题可回答性与词汇多样性存在权衡; 问题与上下文段落的低重叠能提高独特性但保持可回答性; 词汇多样性与语义相似性呈反比; 随着生成问题数量增加, 问题间独特性显著下降 | |
| von Davier ( | GPT-2 (345M参数) | 医学考试 | 医学临床病例描述与选择题干扰项 | 使用tensorflow-gpu进行全参数微调; 使用内存高效梯度存储技术解决GPU内存不足问题。 | PubMed开放获取数据库中约800, 000篇医学文章(约8GB文本) | 使用不同类型的提示来引导微调后的模型生成特定类型的医学内容。包括文本续写提示:提供医学情境开头句子; 问答格式提示:“Q: [问题]? A:”; 案例描述提示:“[年龄]患者来到急诊室抱怨[症状]” | 相比字符级RNN, 微调后的Transformer模型(GPT-2)能生成更高质量文本; 生成的医学案例描述可作为人类编写临床病例的初稿; 能生成合理的选择题干扰项; 生成文本中仍有不准确内容, 需要医学专家修改 |
| Hommel等( | GPT-2(355M参数) | 人格测验/心理学构念测量 | 自陈量表题目 | 隐式参数化; 分段训练模式:使用分隔符将构念标签与题目连接起来(如 “#Extraversion@I am the life of the party”); 条件生成:输入构念标签(如 “#Pessimism@”), 模型能生成相应题目(如 “I am not likely to succeed in my goals”)。 | IPIP (国际人格项目池)中的1715个题目 | 64%的生成题目显示良好心理测量特性(因子负荷>0.40); 其中32%的题目与人工题目质量相当; 未训练构念的生成题目中76%仍有良好因子负荷, 部分量表内部一致性达到0.70以上 | |
| Zu等( | GPT-2(1.5B参数) | 词汇测试 | 选择题 | 设计5种不同具体性的提示模板(含一个完整句子和一个干扰项), 基于训练集构建相应样本, 分别微调5个模型, 其中最具体提示为:[输入句子] The word [“关键词”] in the previous sentence should not be replaced by [干扰项]。 | 4, 572个来自标准化英语水平测试的词汇题 | 对于验证集中的每个题目, 使用最优提示格式构建输入, 提供给微调后的模型; 过滤与关键词相同、同义词、高排名填空词和禁用词 | 更具体的提示产生更好的性能; 生成的干扰项在标准化频率指数和语义相似度上与人类专家创建的干扰项高度相似; 基于提示的干扰项比原始干扰项更贴近上下文; 基于提示学习的方法能够学习并复现人类专家应用的隐含规则 |
| Hernandez和Nie ( | 题目生成用GPT-2- XL; 预测相关性用 | 人格测验 | 自陈量表题目 | 对GPT-2-XL进行了5个epoch的微调; 使用top-k采样生成策略; 采用配对架构微调DistilBERT预测项目间相关性。 | GPT-2微调使用IPIP; 相关性预测模型使用Open Psychometrics和 | 成功生成100万个人格项目; 93%语言可接受; AI生成的量表与传统量表在心理测量特性上相当; 项目间相关性预测模型准确度高 | |
| DistilBERT; 结果验证用多种零样本分类器模型 | Eugene-Springfield的IPIP数据集 | (r=0.96); 零样本分类可有效进行内容验证 | |||||
| Dijkstra等( | GPT-3 (Curie, 6.7B参数) | 英语阅读理解测验 | 选择题 | 通过OpenAI API进行全参数指令微调(Instruction Fine-tuning); 设计了一个固定的测验结构模板(包含问题-答案-干扰项), 作为微调过程中的目标输出格式; 保持默认微调超参数。 | 包含英语考试阅读理解题的EQG-RACE数据集(18, 501个训练实例; 1, 035个验证实例; 950个测试实例); 使用完整的文本-测验对作为训练数据 | 人工评估认为生成的测验在流畅性(99%)、相关性(97%)方面表现优, 总体质量高(90.5%), 主要挑战在于答案的有效性(78%)和干扰项的干扰能力(60%); 端到端生成比步骤式生成效率更高; 自动评估BLEU-4得分优异 | |
| Zou等人( | BART | 英语阅读理解测验 | 判断题 | 模板基础框架:基于20篇英语文章, 采用7种基础模板(如移除文本中的否定词来生成错误陈述、交换文本中的数字信息来生成错误陈述等)生成判断陈述句; 生成式框架:使用多种掩码选择协议(如遮蔽从属连词、遮蔽句子中宾语等), 再执行文本填充生成判断陈述句 | 专家评估生成题目具有良好的流畅性、语义、相关性和可回答性; 基于模板基础框架生成的题目与原文相关度高, 可回答性好; 基于生成式框架生成的题目流畅性更好, 能生成推理性问题 | ||
| Götz等( | GPT-2 (774M参数) | 人格测验/心理学构念测量 | 自陈量表题目 | 向模型提供目标构念的示例项目; 分别为正向和反向计分项目创建提示 | 能快速生成大量表面效度良好的项目; 生成的N-BFI-20量表显示良好至优秀的心理测量学特性, 信度、结构效度和预测效度与现有量表相当, 重测信度超过0.70, 预测效度为80% | ||
| Maertens等( | GPT-2(1.5B参数) | 错误信息敏感性测试 | 判断题 | 使用现有5种错误信息量表的项目作为虚假新闻示例 | 创建了有良好的心理测量特性的三个错误信息敏感性测试工具(MIST-20/16/8); 测验有良好的聚合效度和跨文化性; 测验得分与 | ||
| 积极开放思维、认知反思能力呈正相关, 与阴谋论倾向和胡说八道接受性呈负相关 | |||||||
| Attali等( | GPT-3 | 英语阅读理解测验 | 完形填空; 句子补全题; 阅读理解选择题; 主旨选择题; 标题选择题 | 少样本学习: 向GPT-3提供3-5个示例; 条件生成:提供文本输出的特征; 层级式提示:先生成文章, 再基于文章生成问题和答案, 最后生成干扰项; 替代文本生成:生成与原文相似风格但内容不同的文本, 用于生成干扰项 | 58%自动生成内容通过专家审核; 题目难度适中(平均0.70); 良好的区分度(平均0.27); 题目间依赖性低 | ||
| Laverghetta & Licato ( | GPT-3 | 自然语言推理能测量 | 判断前提与假设之间的关系(蕴含、矛盾或中性) | 使用高区分度和低区分度题目示例来教导模型目标特性 | 良好的内容、聚合和区分效度, 比人工编写的题目有更好的区分度和信度, 更接近最佳难度水平; 在命题结构和量词类别的题目上表现更好; 初始生成的400个题目中92个通过了专家内容审查 | ||
| Lee等( | GPT-3(175B参数) | 人格测验 | 自陈量表题目 | 每个人格维度提供5个示例(来自IPIP); 包含任务描述和示例的结构化提示; 使用“简单冒号”格式的变量参数(如 “Trait: x”和“Items (k):”)来控制生成题目的特质类型和数量 | 模型拟合优于人类编写测试(CFI=0.93, TLI=0.93); 良好的信度(Omega=0.77~0.86); 与人类编写测试相当的聚合、区分和效标关联效度; 高区分度和良好分布的项目参数; 88%的题目无DIF, 支持性别群体间的测量不变性 | ||
| Bezirhan & von Davier ( | 优化的GPT-3(text-davinci-002, 175B参数) | 阅读理解测验 | 阅读理解测验文章(语料) | 仅提供指令, 不提供示例的零样本(zero-shot)学习; 提供一个示例(来自国际阅读素养进展研究PIRLS的文章)和指令的单样本(one-shot)学习; 在提示中包含目标读者年龄/年级信息; 操控temperature参数(0.5、0.7、0.9)控制输出多样性; 迭代提示生成较长故事; 人工后期编辑校正 | GPT-3能生成难度匹配四年级学生的高质量阅读文章; 人类评估显示生成文章与PIRLS原始文章在可读性、连贯性和适合度方面高度相似; 单样本学习加上年级信息的提示在匹配原始文章难度方面效果最佳; 信息类文章在识别主题方面稍逊于原始文章; 文学类文章在吸引力和减少干扰性方面评分高于原始文章 | ||
| Lee等( | 最初使用GPT-3, 后改用ChatGPT (未指明版本) | 英语阅读理解测验 | 判断题、Wh-问题、完形填空(分别有选择和开放两种形式) | 创建了一个包含问题类型(文字理解层次)和题型的提示框架, 为每种问题类型与题型组合设计包含明确指令、问题生成要求和期望输出格式的特定提示模板; 运用多步骤提示策略, 不断根据专家反馈迭代优化问题生成方法 | 专家评估提示模板有效性高(平均CVI=0.84)、一致性极高(IRA=1); 专家和教师均指出判断题和完形填空题有效性较低, 而主题句等个别问题类型有效性较高 | ||
| Sayin & Gierl ( | GPT-3.5 | 阅读理解测验 | 识别文章中不相关句子 | 模板化提示:使用结构化指令模板; 少样本学习:提供一个示例(父题目); 约束条件指导:应用语义、组织和文本特征的具体约束; 层级式提示:先生成相关句子, 再生成不相关句子, 最后组装 | 生成12, 500个题目; 6个题目样本全部被专家判定为可接受; 题目难度适中(平均0.62); 良好的区分度(平均r=0.43, 鉴别指数=0.50); 干扰项表现良好 | ||
| Wang等( | ChatGPT (GPT-3.5) | 中文阅读理解测验 | 选择题、填空题等11种问题类型 | 结构化提示模式:包含角色定义、输出指示器、类型、定义、特征和示例代码6个组件; 集体知识库融合:从318份教学设计中提取问题特征, 建立知识库; 特征引导生成:为每种问题提供典型特征和表达方式 | 成功生成多种中文阅读理解题及答案; 90%参与者对系统可用性表示满意; 专家评估认为基于提示模式的系统在可回答性和质量维度上明显优于非提示模式系统, 与人工创建问题相比, 在正确性和流畅性方面没有显著差异 | ||
| Zuckerman等( | ChatGPT (未指明GPT版本) | 医学考试 | 案例型选择题(包含临床情境、生命体征和检查结果) | 通过调整格式和语法描述创建可重用的通用提示模板; 结构化提示:指定情境长度、包含生命体征等; 目标导向提示:结合特定学习目标/测试点/疾病状态; 利用再生成功能创建题目的多个变体 | 题目创建时间从30-60分钟减至5-15分钟; AI题目与非AI题目表现相似(P值0.71 vs 0.72, 区分度略高); 生成的题目格式一致, 遵循最佳实践; 仍需内容专家编辑, 但编辑时间显著减少; 在回忆型题目方面表现优于应用型题目 | ||
| Kıyak ( | ChatGPT (GPT-3.5) | 医学考试 | 案例型选择题 | 提供一个包含详细指南的提示词模板; 扮演医学考试题库开发者; 指定题目应包含案例、问题干、选项和解释; 要求遵循医 | 专家评审认为10道生成题目在科学/临床知识方面均正确, 有且仅有一个正确答案; 其中2题纳入考试, 有较高区分度(0.41和0.39), | ||
| 学教育中构建选择题原则; 通过填充主题(如“在原发性高血压患者中合理用药”)和难度级别(简单/困难)来定制生成过程 | 但其中1题干扰项选择频率低 | ||||||
| Kıyak & Kononowicz ( | ChatGPT (未指明GPT版本) | 医学考试 | 案例型选择题 | 整合Zuckerman等( | 提高题目生成效率; 生成更符合医学教育语境的题目; 解决了标准ChatGPT缺乏医学语境的问题 | ||
| Maity等( | GPT-3.5、GPT-4 | 多语种语言测试 | 选择题 | 从SQuAD (英语)、GermanQuAD (德语)、HiQuAD (印地语)、BanglaRQA (孟加拉语)每个问答数据集中随机抽取850个文本作为提示内容一部分; 多阶段提示(MSP):包括释义生成(为每个上下文生成多个释义)、关键词提取(从释义中提取关键词)、问题生成(基于释义和关键词生成问题)和干扰项生成四个阶段; 对比不提供任何示例的零样本策略和提供一个示例的单样本策略 | MSP方法在BLEU、ROUGE-L和余弦相似度等指标上优于单阶段提示; MSP生成的问题在语法性、可回答性和难度方面表现更好; 英语在单样本设置下表现最佳; 单样本比零样本效果好; 高资源语言(英语和德语)表现优于低资源语言(印地语和孟加拉语) |
| 文献 | 基座模型 | 应用领域 | 题型 | 参数微调策略 | 微调训练数据集 | 提示策略 | 结果 |
|---|---|---|---|---|---|---|---|
| 窦若琳( | BERT | 数学应用题自动解题和自动出题 | 数学应用题(文本数学题) | 研究分别训练了三个主要模型:MBERT预训练模型, 通过回归、分类和掩码预测任务对BERT进行领域适应; 自动解题模型利用预训练模型中间层语义特征构造依赖图, 并使用目标驱动的树解码器生成答案; 自动出题模型采用图卷积网络编码结构信息, 并利用解题模型反馈进行质量评估和参数优化。 | Math23K (含23, 161道中文数学应用题)和Ape210K (含210, 488道中文数学应用题) | 自动解题模型在Math23K上表达式准确率72.0%, 答案数值准确率84.2%, 在Ape210K上表达式准确率65.2%, 答案数值准确率78.1%; 生成问题的表达多样性高, 与输入表达式的逻辑一致性好, 问题描述符合数学应用题的规范 | |
| 张津旭( | UniLM和mT5 | 中文阅读理解测验 | 简答题 | 两个模型都通过随机替换(构造负样本增强模型泛化能力)缓解训练与推理不一致问题; 通过对抗训练(在Embedding层添加扰动)增强模型泛化能力。UniLM额外将问题类型作为特征输入提高问题精确性, 利用伪标签再训练扩充数据集, 并采用基于词粒度的WoBERT预训练参数; 而mT5则通过自定义输入格式优化任务表示。 | CMRC2018(中文阅读理解数据集)和中医药数据集 | 优化后的UniLM和mT5模型在问题生成效果(BLEU、ROUGE-L指标)上均优于基线模型; mT5模型速度比UniLM快60%, 但准确率略低; 75%以上学生认为系统有助于提升提问能力 | |
| 杨生文(2021) | 问题生成使用UniLM; 干扰项生成使用BERT | 英语阅读理解测验 | 选择题 | 问题生成部分先通过BERT+BiLSTM+ CRF结构抽取答案, 将答案用特殊标记<a>替换, 然后微调UniLM模型生成问题, 并应用语义相似度计算增加多样性。干扰项生成部分利用BERT编码问题和文章, 获取上下文表示, 使用LSTM单独编码正确答案, 通过双线性变换提取干扰信息, 最后基于干扰注意力机制解码生成具有迷惑性的选项。 | 问题生成使用SQuAD 1.1(一个包含超过10万个问题-答案对的阅读理解数据集); 干扰项生成使用RACE数据集(来自中国初高中英语考试) | 问题生成:BLEU-4=22.15, 生成的问题很少包含目标答案; 干扰项生成:BLEU-4=12.33, 人工评估干扰项的流利度、连贯性和迷惑性均较高 | |
| Lelkes等( | PEGASUS; T5; T5-Large | 新闻知识评估 | 选择题 | 先在现有问答数据集上微调, 训练了一个问题-答案生成(QAG)模型, 再基于自生成问答数据训练干扰项生成(DG)模型; 输入前缀标签(如 “Style SQuAD:”)区分不同数据集风格。 | NewsQuizQA (20K问答对, 5K新闻摘要)SQuAD、NQ、NewsQA | QAG模型在ROUGE-QAG指标上优于所有基线; DG模型在多个人工评估指标上表现良好; 44%用户认为测验有教育价值, 49%希望将其纳入常规新闻阅读体验 | |
| Rathod等( | ProphetNet用作题目生成、T5用作题目改写 | 阅读理解测验 | 多个语义相似但用词不同的测量相同概念的平行问题 | 使用ProphetNet从SQuAD中的问题-答案对生成问题, 构建初始训练数据; 将生成的问题输入已经在Quora Question Pairs上训练过的T5改写模型获得改写版本; 使用拓展后的数据集对ProphetNet进行微调, 使其学会直接生成成对的问题。 | SQuAD 1.1; 训练T5改写模型使用Quora Question Pairs数据集 | 问题可回答性与词汇多样性存在权衡; 问题与上下文段落的低重叠能提高独特性但保持可回答性; 词汇多样性与语义相似性呈反比; 随着生成问题数量增加, 问题间独特性显著下降 | |
| von Davier ( | GPT-2 (345M参数) | 医学考试 | 医学临床病例描述与选择题干扰项 | 使用tensorflow-gpu进行全参数微调; 使用内存高效梯度存储技术解决GPU内存不足问题。 | PubMed开放获取数据库中约800, 000篇医学文章(约8GB文本) | 使用不同类型的提示来引导微调后的模型生成特定类型的医学内容。包括文本续写提示:提供医学情境开头句子; 问答格式提示:“Q: [问题]? A:”; 案例描述提示:“[年龄]患者来到急诊室抱怨[症状]” | 相比字符级RNN, 微调后的Transformer模型(GPT-2)能生成更高质量文本; 生成的医学案例描述可作为人类编写临床病例的初稿; 能生成合理的选择题干扰项; 生成文本中仍有不准确内容, 需要医学专家修改 |
| Hommel等( | GPT-2(355M参数) | 人格测验/心理学构念测量 | 自陈量表题目 | 隐式参数化; 分段训练模式:使用分隔符将构念标签与题目连接起来(如 “#Extraversion@I am the life of the party”); 条件生成:输入构念标签(如 “#Pessimism@”), 模型能生成相应题目(如 “I am not likely to succeed in my goals”)。 | IPIP (国际人格项目池)中的1715个题目 | 64%的生成题目显示良好心理测量特性(因子负荷>0.40); 其中32%的题目与人工题目质量相当; 未训练构念的生成题目中76%仍有良好因子负荷, 部分量表内部一致性达到0.70以上 | |
| Zu等( | GPT-2(1.5B参数) | 词汇测试 | 选择题 | 设计5种不同具体性的提示模板(含一个完整句子和一个干扰项), 基于训练集构建相应样本, 分别微调5个模型, 其中最具体提示为:[输入句子] The word [“关键词”] in the previous sentence should not be replaced by [干扰项]。 | 4, 572个来自标准化英语水平测试的词汇题 | 对于验证集中的每个题目, 使用最优提示格式构建输入, 提供给微调后的模型; 过滤与关键词相同、同义词、高排名填空词和禁用词 | 更具体的提示产生更好的性能; 生成的干扰项在标准化频率指数和语义相似度上与人类专家创建的干扰项高度相似; 基于提示的干扰项比原始干扰项更贴近上下文; 基于提示学习的方法能够学习并复现人类专家应用的隐含规则 |
| Hernandez和Nie ( | 题目生成用GPT-2- XL; 预测相关性用 | 人格测验 | 自陈量表题目 | 对GPT-2-XL进行了5个epoch的微调; 使用top-k采样生成策略; 采用配对架构微调DistilBERT预测项目间相关性。 | GPT-2微调使用IPIP; 相关性预测模型使用Open Psychometrics和 | 成功生成100万个人格项目; 93%语言可接受; AI生成的量表与传统量表在心理测量特性上相当; 项目间相关性预测模型准确度高 | |
| DistilBERT; 结果验证用多种零样本分类器模型 | Eugene-Springfield的IPIP数据集 | (r=0.96); 零样本分类可有效进行内容验证 | |||||
| Dijkstra等( | GPT-3 (Curie, 6.7B参数) | 英语阅读理解测验 | 选择题 | 通过OpenAI API进行全参数指令微调(Instruction Fine-tuning); 设计了一个固定的测验结构模板(包含问题-答案-干扰项), 作为微调过程中的目标输出格式; 保持默认微调超参数。 | 包含英语考试阅读理解题的EQG-RACE数据集(18, 501个训练实例; 1, 035个验证实例; 950个测试实例); 使用完整的文本-测验对作为训练数据 | 人工评估认为生成的测验在流畅性(99%)、相关性(97%)方面表现优, 总体质量高(90.5%), 主要挑战在于答案的有效性(78%)和干扰项的干扰能力(60%); 端到端生成比步骤式生成效率更高; 自动评估BLEU-4得分优异 | |
| Zou等人( | BART | 英语阅读理解测验 | 判断题 | 模板基础框架:基于20篇英语文章, 采用7种基础模板(如移除文本中的否定词来生成错误陈述、交换文本中的数字信息来生成错误陈述等)生成判断陈述句; 生成式框架:使用多种掩码选择协议(如遮蔽从属连词、遮蔽句子中宾语等), 再执行文本填充生成判断陈述句 | 专家评估生成题目具有良好的流畅性、语义、相关性和可回答性; 基于模板基础框架生成的题目与原文相关度高, 可回答性好; 基于生成式框架生成的题目流畅性更好, 能生成推理性问题 | ||
| Götz等( | GPT-2 (774M参数) | 人格测验/心理学构念测量 | 自陈量表题目 | 向模型提供目标构念的示例项目; 分别为正向和反向计分项目创建提示 | 能快速生成大量表面效度良好的项目; 生成的N-BFI-20量表显示良好至优秀的心理测量学特性, 信度、结构效度和预测效度与现有量表相当, 重测信度超过0.70, 预测效度为80% | ||
| Maertens等( | GPT-2(1.5B参数) | 错误信息敏感性测试 | 判断题 | 使用现有5种错误信息量表的项目作为虚假新闻示例 | 创建了有良好的心理测量特性的三个错误信息敏感性测试工具(MIST-20/16/8); 测验有良好的聚合效度和跨文化性; 测验得分与 | ||
| 积极开放思维、认知反思能力呈正相关, 与阴谋论倾向和胡说八道接受性呈负相关 | |||||||
| Attali等( | GPT-3 | 英语阅读理解测验 | 完形填空; 句子补全题; 阅读理解选择题; 主旨选择题; 标题选择题 | 少样本学习: 向GPT-3提供3-5个示例; 条件生成:提供文本输出的特征; 层级式提示:先生成文章, 再基于文章生成问题和答案, 最后生成干扰项; 替代文本生成:生成与原文相似风格但内容不同的文本, 用于生成干扰项 | 58%自动生成内容通过专家审核; 题目难度适中(平均0.70); 良好的区分度(平均0.27); 题目间依赖性低 | ||
| Laverghetta & Licato ( | GPT-3 | 自然语言推理能测量 | 判断前提与假设之间的关系(蕴含、矛盾或中性) | 使用高区分度和低区分度题目示例来教导模型目标特性 | 良好的内容、聚合和区分效度, 比人工编写的题目有更好的区分度和信度, 更接近最佳难度水平; 在命题结构和量词类别的题目上表现更好; 初始生成的400个题目中92个通过了专家内容审查 | ||
| Lee等( | GPT-3(175B参数) | 人格测验 | 自陈量表题目 | 每个人格维度提供5个示例(来自IPIP); 包含任务描述和示例的结构化提示; 使用“简单冒号”格式的变量参数(如 “Trait: x”和“Items (k):”)来控制生成题目的特质类型和数量 | 模型拟合优于人类编写测试(CFI=0.93, TLI=0.93); 良好的信度(Omega=0.77~0.86); 与人类编写测试相当的聚合、区分和效标关联效度; 高区分度和良好分布的项目参数; 88%的题目无DIF, 支持性别群体间的测量不变性 | ||
| Bezirhan & von Davier ( | 优化的GPT-3(text-davinci-002, 175B参数) | 阅读理解测验 | 阅读理解测验文章(语料) | 仅提供指令, 不提供示例的零样本(zero-shot)学习; 提供一个示例(来自国际阅读素养进展研究PIRLS的文章)和指令的单样本(one-shot)学习; 在提示中包含目标读者年龄/年级信息; 操控temperature参数(0.5、0.7、0.9)控制输出多样性; 迭代提示生成较长故事; 人工后期编辑校正 | GPT-3能生成难度匹配四年级学生的高质量阅读文章; 人类评估显示生成文章与PIRLS原始文章在可读性、连贯性和适合度方面高度相似; 单样本学习加上年级信息的提示在匹配原始文章难度方面效果最佳; 信息类文章在识别主题方面稍逊于原始文章; 文学类文章在吸引力和减少干扰性方面评分高于原始文章 | ||
| Lee等( | 最初使用GPT-3, 后改用ChatGPT (未指明版本) | 英语阅读理解测验 | 判断题、Wh-问题、完形填空(分别有选择和开放两种形式) | 创建了一个包含问题类型(文字理解层次)和题型的提示框架, 为每种问题类型与题型组合设计包含明确指令、问题生成要求和期望输出格式的特定提示模板; 运用多步骤提示策略, 不断根据专家反馈迭代优化问题生成方法 | 专家评估提示模板有效性高(平均CVI=0.84)、一致性极高(IRA=1); 专家和教师均指出判断题和完形填空题有效性较低, 而主题句等个别问题类型有效性较高 | ||
| Sayin & Gierl ( | GPT-3.5 | 阅读理解测验 | 识别文章中不相关句子 | 模板化提示:使用结构化指令模板; 少样本学习:提供一个示例(父题目); 约束条件指导:应用语义、组织和文本特征的具体约束; 层级式提示:先生成相关句子, 再生成不相关句子, 最后组装 | 生成12, 500个题目; 6个题目样本全部被专家判定为可接受; 题目难度适中(平均0.62); 良好的区分度(平均r=0.43, 鉴别指数=0.50); 干扰项表现良好 | ||
| Wang等( | ChatGPT (GPT-3.5) | 中文阅读理解测验 | 选择题、填空题等11种问题类型 | 结构化提示模式:包含角色定义、输出指示器、类型、定义、特征和示例代码6个组件; 集体知识库融合:从318份教学设计中提取问题特征, 建立知识库; 特征引导生成:为每种问题提供典型特征和表达方式 | 成功生成多种中文阅读理解题及答案; 90%参与者对系统可用性表示满意; 专家评估认为基于提示模式的系统在可回答性和质量维度上明显优于非提示模式系统, 与人工创建问题相比, 在正确性和流畅性方面没有显著差异 | ||
| Zuckerman等( | ChatGPT (未指明GPT版本) | 医学考试 | 案例型选择题(包含临床情境、生命体征和检查结果) | 通过调整格式和语法描述创建可重用的通用提示模板; 结构化提示:指定情境长度、包含生命体征等; 目标导向提示:结合特定学习目标/测试点/疾病状态; 利用再生成功能创建题目的多个变体 | 题目创建时间从30-60分钟减至5-15分钟; AI题目与非AI题目表现相似(P值0.71 vs 0.72, 区分度略高); 生成的题目格式一致, 遵循最佳实践; 仍需内容专家编辑, 但编辑时间显著减少; 在回忆型题目方面表现优于应用型题目 | ||
| Kıyak ( | ChatGPT (GPT-3.5) | 医学考试 | 案例型选择题 | 提供一个包含详细指南的提示词模板; 扮演医学考试题库开发者; 指定题目应包含案例、问题干、选项和解释; 要求遵循医 | 专家评审认为10道生成题目在科学/临床知识方面均正确, 有且仅有一个正确答案; 其中2题纳入考试, 有较高区分度(0.41和0.39), | ||
| 学教育中构建选择题原则; 通过填充主题(如“在原发性高血压患者中合理用药”)和难度级别(简单/困难)来定制生成过程 | 但其中1题干扰项选择频率低 | ||||||
| Kıyak & Kononowicz ( | ChatGPT (未指明GPT版本) | 医学考试 | 案例型选择题 | 整合Zuckerman等( | 提高题目生成效率; 生成更符合医学教育语境的题目; 解决了标准ChatGPT缺乏医学语境的问题 | ||
| Maity等( | GPT-3.5、GPT-4 | 多语种语言测试 | 选择题 | 从SQuAD (英语)、GermanQuAD (德语)、HiQuAD (印地语)、BanglaRQA (孟加拉语)每个问答数据集中随机抽取850个文本作为提示内容一部分; 多阶段提示(MSP):包括释义生成(为每个上下文生成多个释义)、关键词提取(从释义中提取关键词)、问题生成(基于释义和关键词生成问题)和干扰项生成四个阶段; 对比不提供任何示例的零样本策略和提供一个示例的单样本策略 | MSP方法在BLEU、ROUGE-L和余弦相似度等指标上优于单阶段提示; MSP生成的问题在语法性、可回答性和难度方面表现更好; 英语在单样本设置下表现最佳; 单样本比零样本效果好; 高资源语言(英语和德语)表现优于低资源语言(印地语和孟加拉语) |
| 文献 | 基座模型 | 题目领域 | 题型 | 知识库构建 | 知识检索方案 | 生成方案 | 研究结果 |
|---|---|---|---|---|---|---|---|
| Oldensand ( | GPT-3.5 (gpt- 3.5-turbo- 0125); GPT-4 (gpt-4-turbo- 2024-04-09); Llama 3 (llama3-70b- 8192) | 坦桑尼亚中学二年级地理课程 | 简答题、长答题、判断题 | 1.知识来源:坦桑尼亚教育研究所(TIE)出版的《Geography for Secondary Schools, Student's Book Form II》地理教科书; 2.使用LlamaParse将PDF教科书转换为markdown格式; 3.对内容文件和习题文件使用不同的分块策略; 4.使用文本分割器MarkdownHeaderTextSplitter按标题、章节、小节分块; 5.对大于1000字符的块使用递归字符分割器RecursiveCharacterTextSplitter进一步分割; 6.习题文件手动按单个问题分块; 7.使用all-MiniLM-l6-v2模型将文本块转化为密集向量表示, 使用BM25算法创建稀疏向量表示 | 1.查询重写:使用(Groq平台)Llama 3-8B-8192将用户原始查询重写为更丰富、更具领域相关性的查询; 2.使用相同嵌入模型编码查询; 3.混合检索:使用Okapi BM25算法实现Lucene稀疏检索、通过余弦相似度计算查询与块的相关性, 实现密集检索; 4.通过排名融合(RRF)合并多种检索结果; 5.使用cross-encoder/ms-marco- MiniLM-L-6-v2跨编码器对检索结果进行重排序; 6.从知识库返回5个内容文档和2个样例习题作为上下文 | 角色定义:将模型定位为坦桑尼亚教师; 单样本提示:提供示例互动指导模型; 上下文集成:将检索到的文档和样例习题融入提示; 指令细化:明确解释生成任务要求 | GPT-4和Llama 3在遵循指令和拒绝不相关查询方面优于GPT-3.5; 教师在超过70%的情况下更喜欢AI生成的习题而非人类编写的; 查询重写器可能不必要, 但单样本提示很重要; 教师反馈表明系统帮助他们更快完成工作, 适用于生成考题、笔记和评分方案 |
| 陈欣等( | ERNIE-Bot 4.0 | 信息检索、数据结构课程 | 选择题、应用题 | 1.知识来源:《信息检索》教材(314.62K字符)、《数据结构》教材(191.48K字符)、PPT、在线视频等; 2.对教材文本进行解析、分段和清洗; 3.采用千帆企业级大模型服务平台的知识库插件, 使用文心Embedding_V1模型将文本转化为向量 | 1.由教师和专家将课程内容拆分为细粒度知识点; 2.知识点导向检索:以单个知识点作为查询语句检索相关内容; 3.使用相同嵌入模型编码查询; 4.语义检索:采用最大内积搜索(MIPS)进行语义匹配和文档排序 | 结合结构化知识点和检索内容增强提示效果; 对比实验5种提示方法:指令提示、少样本提示、角色提示、正面反馈、任务分解 | 试题合格率86.47%; 试题平均难度0.67; 学生评价积极, 认为试题符合课程要求; 角色提示效果优于其他提示方法; 细粒度知识点比宽泛知识点生成效果更好 |
| 王鹏等( | 文心一言、ChatGPT (FastGPT配置) | 青少年心理危机评估 | 自陈量表题目 | 1.知识来源:GitHub上的心理咨询领域语料库(20, 000对话) 2.将语料库导入开源架构FastGPT, 其结构由库、集合和数据三个层次组成; 3.使用OpenAI的第二代嵌入模型text-embedding-ada-002进行文本向量化 | 1.使用相同嵌入模型编码查询; 2.使用PostgresSQL的PG Vector插件作为向量检索器; 3.使用HNSW索引优化检索效率; 4.使用双数据库架构:PostgresSQL负责向量检索, MongoDB用于其他数据存取 | 角色定义:明确AI在生成内容中的角色和领域背景; 作者信息: 增强内容的权威性和可信度; 目标设定:明确生成内容的目的和期望效果; 限制条件:限制AI生成内容的范围和方向; 技能描述:强化AI在特定领域的知识和能力; 工作流程:指导AI如何生成和输出内容; 初始化对话:重申关注重点和引导对话方向 | 未给出具体的验证结果数据 |
| 文献 | 基座模型 | 题目领域 | 题型 | 知识库构建 | 知识检索方案 | 生成方案 | 研究结果 |
|---|---|---|---|---|---|---|---|
| Oldensand ( | GPT-3.5 (gpt- 3.5-turbo- 0125); GPT-4 (gpt-4-turbo- 2024-04-09); Llama 3 (llama3-70b- 8192) | 坦桑尼亚中学二年级地理课程 | 简答题、长答题、判断题 | 1.知识来源:坦桑尼亚教育研究所(TIE)出版的《Geography for Secondary Schools, Student's Book Form II》地理教科书; 2.使用LlamaParse将PDF教科书转换为markdown格式; 3.对内容文件和习题文件使用不同的分块策略; 4.使用文本分割器MarkdownHeaderTextSplitter按标题、章节、小节分块; 5.对大于1000字符的块使用递归字符分割器RecursiveCharacterTextSplitter进一步分割; 6.习题文件手动按单个问题分块; 7.使用all-MiniLM-l6-v2模型将文本块转化为密集向量表示, 使用BM25算法创建稀疏向量表示 | 1.查询重写:使用(Groq平台)Llama 3-8B-8192将用户原始查询重写为更丰富、更具领域相关性的查询; 2.使用相同嵌入模型编码查询; 3.混合检索:使用Okapi BM25算法实现Lucene稀疏检索、通过余弦相似度计算查询与块的相关性, 实现密集检索; 4.通过排名融合(RRF)合并多种检索结果; 5.使用cross-encoder/ms-marco- MiniLM-L-6-v2跨编码器对检索结果进行重排序; 6.从知识库返回5个内容文档和2个样例习题作为上下文 | 角色定义:将模型定位为坦桑尼亚教师; 单样本提示:提供示例互动指导模型; 上下文集成:将检索到的文档和样例习题融入提示; 指令细化:明确解释生成任务要求 | GPT-4和Llama 3在遵循指令和拒绝不相关查询方面优于GPT-3.5; 教师在超过70%的情况下更喜欢AI生成的习题而非人类编写的; 查询重写器可能不必要, 但单样本提示很重要; 教师反馈表明系统帮助他们更快完成工作, 适用于生成考题、笔记和评分方案 |
| 陈欣等( | ERNIE-Bot 4.0 | 信息检索、数据结构课程 | 选择题、应用题 | 1.知识来源:《信息检索》教材(314.62K字符)、《数据结构》教材(191.48K字符)、PPT、在线视频等; 2.对教材文本进行解析、分段和清洗; 3.采用千帆企业级大模型服务平台的知识库插件, 使用文心Embedding_V1模型将文本转化为向量 | 1.由教师和专家将课程内容拆分为细粒度知识点; 2.知识点导向检索:以单个知识点作为查询语句检索相关内容; 3.使用相同嵌入模型编码查询; 4.语义检索:采用最大内积搜索(MIPS)进行语义匹配和文档排序 | 结合结构化知识点和检索内容增强提示效果; 对比实验5种提示方法:指令提示、少样本提示、角色提示、正面反馈、任务分解 | 试题合格率86.47%; 试题平均难度0.67; 学生评价积极, 认为试题符合课程要求; 角色提示效果优于其他提示方法; 细粒度知识点比宽泛知识点生成效果更好 |
| 王鹏等( | 文心一言、ChatGPT (FastGPT配置) | 青少年心理危机评估 | 自陈量表题目 | 1.知识来源:GitHub上的心理咨询领域语料库(20, 000对话) 2.将语料库导入开源架构FastGPT, 其结构由库、集合和数据三个层次组成; 3.使用OpenAI的第二代嵌入模型text-embedding-ada-002进行文本向量化 | 1.使用相同嵌入模型编码查询; 2.使用PostgresSQL的PG Vector插件作为向量检索器; 3.使用HNSW索引优化检索效率; 4.使用双数据库架构:PostgresSQL负责向量检索, MongoDB用于其他数据存取 | 角色定义:明确AI在生成内容中的角色和领域背景; 作者信息: 增强内容的权威性和可信度; 目标设定:明确生成内容的目的和期望效果; 限制条件:限制AI生成内容的范围和方向; 技能描述:强化AI在特定领域的知识和能力; 工作流程:指导AI如何生成和输出内容; 初始化对话:重申关注重点和引导对话方向 | 未给出具体的验证结果数据 |
| [1] | 陈欣, 李蜜如, 周悦琦, 周同, 张峰. (2024). 基于大语言模型的试题自动生成路径研究. 中国考试, (12), 39-48. |
| [2] | 窦若琳. (2023). 基于数学语义理解的自动解题与出题系统实现 [硕士学位论文]. 北京邮电大学, 北京. |
| [3] | 高凯. (2024). 基于预训练模型的初等数学题目自动生成 [硕士学位论文]. 电子科技大学, 成都. |
| [4] | 李中权, 张厚粲. (2008). 计算机自动化项目生成概述. 心理科学进展, 16(2), 348-352. |
| [5] | 王蕾. (2023). 人工智能生成内容技术在教育考试中应用探析. 中国考试, (8), 19-27. |
| [6] | 王鹏, 封迅, 康艳俊, 康春花. (2024). 青少年心理危机量表的项目自动生成: 基于生成式人工智能和RAG技术. ChinaXiv. https://chinaxiv.org/abs/202406.00361V1 |
| [7] | 徐坚. (2024). 语义图支持的阅读理解型问题的自动生成. 智能系统学报, 19(2), 420-428. |
| [8] | 杨生文. (2021). 基于深度学习的阅读理解题目生成研究[硕士学位论文].华中师范大学, 武汉. |
| [9] | 张津旭. (2022). 基于预训练语言模型的智能提问系统的设计与实现 [硕士学位论文]. 西南大学, 重庆. |
| [10] | Agarwal, M., & Mannem P. (2011). Automatic gap-fill question generation from text books. In J. Tetreault, J. Burstein, & C. Leacock (Eds.), Proceedings of the sixth workshop on innovative use of NLP for building educational applications (pp. 56-64). Association for Computational Linguistics. |
| [11] | Alayrac J. B., Donahue J., Luccioni P., Aghajanyan A., Clark S., Sriram A., … Vinyals O. (2022). Flamingo: A visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35, 23716-23736. |
| [12] | Alkaissi H., & McFarlane S I.. (2023). Artificial hallucinations in ChatGPT: Implications in scientific writing. Cureus, 15(2), e35179. |
| [13] | Attali Y., Runge A., LaFlair G. T., Yancey K., Goodwin S., Park Y., & von Davier A. A. (2022). The interactive reading task: Transformer-based automatic item generation. Frontiers in Artificial Intelligence, 5, 903077. |
| [14] | Barker F. (2006). Corpora and language assessment: Trends and prospects. Research Notes, 26, 2-4. |
| [15] | Becker L., Basu S., & Vanderwende L. (2012). Mind the gap: Learning to choose gaps for question generation. In Proceedings of the 2012 conference of the north American chapter of the association for computational linguistics: Human language technologies(pp. 742-751). Association for Computational Linguistics. https://aclanthology.org/N12-1092 |
| [16] | Bejar I. I., Lawless R. R., Morley M. E., Wagner M. E., Bennett R. E., & Revuelta J. (2003). A feasibility study of on-the-fly item generation in adaptive testing. Journal of Technology, Learning, and Assessment, 2(3), 1-29. |
| [17] | Bezirhan U., & von Davier M. (2023). Automated reading passage generation with OpenAI’s large language model. Computers and Education: Artificial Intelligence, 5, 100161. |
| [18] | Biber D., Conrad S., Reppen R., Byrd P., Helt M., Clark V.,... Urzua A. (2004). Representing language use in the university: Analysis of the TOEFFL 2000 spoken and written academic language corpus. Educational Testing Service. https://starryvalve.com/wp-content/uploads/2024/09/using-mustang-fuse-when-recording-with-audacity-aaf779.pdf |
| [19] | Brohan A., Brown N., Carbajal J., Chebotar Y., Dabis J., Finn C.,... Zitkovich B. (2023). RT-2: Vision-language- action models transfer web knowledge to robotic control. arXiv. https://doi.org/10.48550/arXiv.2307.15818 |
| [20] | Brown T., Mann B., Ryder N., Subbiah M., Kaplan J. D., Dhariwal P.,... Amodei D. (2020). Language models are few-shot learners. In Proceedings of the 34th conference on neural information processing systems(pp. 1877-1901). Curran Associates, Inc. |
| [21] | Chan S., Somasundaran S., Ghosh D., & Zhao M. (2022). Agree: A system for generating automated grammar reading exercises. arXiv. https://doi.org/10.48550/arXiv.2210.16302 |
| [22] | Circi R., Hicks J., & Sikali E. (2023). Automatic item generation: Foundations and machine learning-based approaches for assessments. Frontiers in Education, 8, Article 858273. |
| [23] | Coniam D. (1997). A preliminary inquiry into using corpus word frequency data in the automatic generation of English language cloze tests. CALICO Journal, 14(2-4), 15-33. |
| [24] | De Angelis L., Baglivo F., Arzilli G., Privitera G. P., Ferragina P., Tozzi A. E., & Rizzo C. (2023). ChatGPT and the rise of large language models: The new AI-driven infodemic threat in public health. Front Public Health, 11, 1166120. |
| [25] | Dettmers T., Pagnoni A., Holtzman A., & Zettlemoyer L. (2023). QLoRA: Efficient finetuning of quantized LLMs. Advances in Neural Information Processing Systems, 36, 10088-10115. |
| [26] | Devlin, J., Chang M. W., Lee K., & Toutanova K. (2019). BERT:Pre-training of deep bidirectional transformers for language understanding. In J. Burstein, C. Doran, & T. Solorio (Eds.), Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies (pp. 4171-4186). Association for Computational Linguistics. |
| [27] | Dijkstra R., Genç Z., Kayal S., & Kamps J. (2022). Reading comprehension quiz generation using generative pre-trained transformers. In Proceedings of the Fourth International Workshop on Intelligent Textbooks 2022 co-located with 23rd International Conference on Artificial Intelligence in Education (pp. 4-17). CEUR Workshop Proceedings. https://www.e.humanities.uva.nl/publications/2022/dijk_read22.pdf |
| [28] | Du, X., Shao J., & Cardie C. (2017). Learning to ask:Neural question generation for reading comprehension. In R. Barzilay, & M. Y. Kan (Eds.), Proceedings of the 55th annual meeting of the association for computational linguistics (Volume 1: Long papers) (pp. 1342-1352). Association for Computational Linguistics. |
| [29] | Du Y., Li S., Torralba A., Tenenbaum J. B., & Mordatch I. (2023). Improving factuality and reasoning in language models through multiagent debate. In Forty-first international conference on machine learning (pp. 11733-11763). Proceedings of Machine Learning Research. |
| [30] | Embretson S. E. (1998). A cognitive design system approach to generating valid tests: Application to abstract reasoning. Psychological Methods, 3(3), 380-396. |
| [31] | Embretson, S. E., & Yang X. (2006). Automatic item generation and cognitive psychology. In C. R. Rao & S. Sinharay (Eds.), Handbook of statistics (Vol. 26, pp. 747-768). Elsevier. |
| [32] | Falcão F., Pereira D. M., Gonçalves N., De Champlain A., Costa P., & Pêgo J. M. (2023). A suggestive approach for assessing item quality, usability and validity of automatic item generation. Advances in Health Sciences Education, 28(5), 1441-1465. |
| [33] | Gallegos I. O., Rossi R. A., Barrow J., Tanjim M. M., Kim S., Dernoncourt F.,... Ahmed N. K. (2024). Bias and fairness in large language models: A survey. Computational Linguistics, 50(3), 1097-1179. |
| [34] |
Gao C. A., Howard F. M., Markov N. S., Dyer E. C., Ramesh S., Luo Y., & Pearson A. T. (2023). Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers. NPJ Digital Medicine, 6(1), 75.
doi: 10.1038/s41746-023-00819-6 pmid: 37100871 |
| [35] | Gierl, M. J., Lai H., & Tanygin V. (Eds.). (2021). Advanced methods in automatic item generation. England: Routledge. |
| [36] | Gorgun G., & Bulut O. (2024). Instruction-tuned large- language models for quality control in automatic item generation: A feasibility study. Educational Measurement: Issues and Practice, 44(1), 96-107. |
| [37] | Goto T., Kojiri T., Watanabe T., Iwata T., & Yamada T. (2010). Automatic generation system of multiple-choice cloze questions and its evaluation. Knowledge Management & E-Learning, 2(3), 210-224. |
| [38] | Götz F. M., Maertens R., Loomba S., & van der Linden S. (2024). Let the algorithm speak: How to use neural networks for automatic item generation in psychological scale development. Psychological Methods, 29(3), 494-518. |
| [39] | Hambleton R. K. (2004). Theory, methods, and practices in testing for the 21st century. Psicothema, 16(4), 696-701. |
| [40] | Han Z., Battaglia F., Udaiyar A., Fooks A., & Terlecky S. R. (2024). An explorative assessment of ChatGPT as an aid in medical education: Use it with caution. Medical Teacher, 46(5), 657-664. |
| [41] | Hernandez I., & Nie W. (2023). The AI‐IP: Minimizing the guesswork of personality scale item development through artificial intelligence. Personnel Psychology, 76(4), 1011-1035. |
| [42] | Hommel B. E., Wollang F. -J. M., Kotova V., Zacher H., & Schmukle S. C. (2022). Transformer-based deep neural language modeling for construct-specific automatic item generation. Psychometrika, 87(2), 749-772. |
| [43] | Hu E. J., Shen Y., Wallis P., Allen-Zhu Z., Li Y., Wang S.,... Chen W. (2022). Lora: Low-rank adaptation of large language models. ICLR, 1(2), 3. |
| [44] | Indran I. R., Paranthaman P., Gupta N., & Mustafa N. (2024). Twelve tips to leverage AI for efficient and effective medical question generation: A guide for educators using Chat GPT. Medical Teacher, 46(8), 1021-1026. |
| [45] | Ji S., Pan S., Cambria E., Marttinen P., & Yu P. S. (2022). A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Transactions on Neural Networks and Learning Systems, 33(2), 494-514. |
| [46] | Jiang, S., & Lee J. S. (2017). Distractor generation for Chinese fill-in-the-blank items. In J. Tetreault, J. Burstein, C. Leacock, & H. Yannakoudakis (Eds.), Proceedings of the 12th workshop on innovative use of NLP for building educational applications (pp. 143-148). Association for Computational Linguistics. |
| [47] | Karamanis, N., Ha L. A., & Mitkov R. (2006). Generating multiple-choice test items from medical text:A pilot study.In N. Colineau, C. Paris, S. Wan, & R. Dale (Eds.), Proceedings of the fourth international natural language generation conference (pp. 111-113). Association for Computational Linguistics. |
| [48] | Kim Y., Lee H., Shin J., & Jung K. (2019). Improving neural question generation using answer separation. Proceedings of the AAAI Conference on Artificial Intelligence, 33(1), 6602-6609. |
| [49] | Kıyak Y. S. (2023). A ChatGPT prompt for writing case- based multiple-choice questions. Revista Española de Educación Médica, 4(3), 98-103. |
| [50] |
Kıyak Y. S., Coşkun Ö., Budakoğlu I. İ., & Uluoğlu C. (2024). ChatGPT for generating multiple-choice questions: Evidence on the use of artificial intelligence in automatic item generation for a rational pharmacotherapy exam. European Journal of Clinical Pharmacology, 80(5), 729-735.
doi: 10.1007/s00228-024-03649-x pmid: 38353690 |
| [51] | Kıyak Y. S., & Kononowicz A. A. (2024). Case-based MCQ generator: A custom ChatGPT based on published prompts in the literature for automatic item generation. Medical Teacher, 46(8), 1018-1020. |
| [52] | Kosh A. E., Simpson M. A., Bickel L., Kellogg M., & Sanford-Moore E. (2019). A cost-benefit analysis of automatic item generation. Educational Measurement: Issues and Practice, 38(1), 48-53. |
| [53] | Kurdi G., Leo J., Parsia B., Sattler U., & Al-Emari S. (2020). A systematic review of automatic question generation for educational purposes. International Journal of Artificial Intelligence in Education, 30(1), 121-204. |
| [54] | LaFlair, G., Yancey K., Settles B., & von Davier A. A. (2023). Computational psychometrics for digital-first assessments:A blend of ML and psychometrics for item generation and scoring. In V. Yaneva & M. von Davier (Eds.), Advancing natural language processing in educational assessment (pp. 107-123). Routledge. |
| [55] | Lai H., Alves C., & Gierl M. J. (2009). Using automatic item generation to address item demands for CAT. In 2009 GMAC Conference on Computerized Adaptive Testing (pp. 1-16). Graduate Management Admission Council. |
| [56] | Laverghetta, A., & Licato J. (2023). Generating better items for cognitive assessments using large language models. In E. Kochmar, J. Burstein, A. Horbach, R. Laarmann-Quante, N. Madnani, A. Tack,... T. Zesch (Eds.), Proceedings of the 18th workshop on innovative use of NLP for building educational applications (pp. 414-428). Association for Computational Linguistics. |
| [57] | Lee P., Fyffe S., Son M., Jia Z., & Yao Z. (2023). A paradigm shift from “human writing” to “machine generation” in personality test development: An application of state-of-the-art natural language processing. Journal of Business and Psychology, 38(1), 163-190. |
| [58] | Lee U., Jung H., Jeon Y., Sohn Y., Hwang W., Moon J., & Kim H. (2024). Few-shot is enough: Exploring ChatGPT prompt engineering method for automatic question generation in English education. Education and Information Technologies, 29(9), 11483-11515. |
| [59] | Lelkes A. D., Tran V. Q., & Yu C. (2021). Quiz-style question generation for news stories. In Proceedings of the web conference 2021 (pp. 2501-2511). Association for Computing Machinery. |
| [60] | Lewis P., Perez E., Piktus A., Petroni F., Karpukhin V., Goyal N.,... Kiela D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474. |
| [61] | Lightning AI. (2023, October 12). Finetuning LLMs with LoRA and QLoRA: Insights from hundreds of experiments. Lightning AI. |
| [62] | Liyanage V., & Ranathunga S. (2020). Multi-lingual mathematical word problem generation using long short term memory networks with enhanced input features. In Proceedings of the twelfth language resources and evaluation conference (pp. 4709-4716). European Language Resources Association. |
| [63] | Madaan A., Tandon N., Gupta P., Hallinan S., Gao L., Wiegreffe S.,... Clark P. (2023). Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36, 46534-46594. |
| [64] | Maertens R., Götz F. M., Golino H. F., Roozenbeek J., Schneider C. R., Kyrychenko Y.,... van der Linden S. (2024). The Misinformation Susceptibility Test (MIST): A psychometrically validated measure of news veracity discernment. Behavior Research Methods, 56(3), 1863-1899. |
| [65] | Maity, S., Deroy A., & Sarkar S. (2024). A novel multi- stage prompting approach for language agnostic MCQ generation using GPT. In N. Goharian, N. Tonellotto, Y. He, A. Lipani, G. McDonald, C. Macdonald, & I. Ounis (Eds.), Advances in information retrieval: 46th European conference on information retrieval (pp. 268-277). Cham: Springer Nature Switzerland AG. |
| [66] | Microsoft. (2024, May 21). Azure AI Vision at Microsoft Build 2024: Multimodal AI for Everyone. Microsoft Community Hub. https://techcommunity.microsoft.com/blog/azure-ai-services-blog/azure-ai-vision-at-microsoft-build-2024-multimodal-ai-for-everyone/4146911 |
| [67] | Mitkov R., & Ha L. A. (2003). Computer-aided generation of multiple-choice tests . In Proceedings of the HLT- NAACL 03 workshop on building educational applications using natural language processing (pp. 17-22). Association for Computational Linguistics. |
| [68] | Mitkov R., Ha L. A., & Karamanis N. (2006). A computer- aided environment for generating multiple-choice test items. Natural Language Engineering, 12(2), 177-194. |
| [69] | Mitkov, R., Maslak H., Ranasinghe T., & Sosoni V. (2023). Automatic generation of multiple-choice test items from paragraphs using deep neural networks. In V. Yaneva & M. von Davier (Eds.), Advancing natural language processing in educational assessment (pp. 77-89). Routledge. |
| [70] | Navigli R., Conia S., & Ross B. (2023). Biases in large language models: Origins, inventory, and discussion. ACM Journal of Data and Information Quality, 15(2), 1-21. |
| [71] | Ngo N. T., Van Nguyen C., Dernoncourt F., & Nguyen T. H. (2024). Comprehensive and Practical Evaluation of Retrieval-Augmented Generation Systems for Medical Question Answering. arXiv. https://doi.org/10.48550/arXiv.2411.09213 |
| [72] | Nickel M., Murphy K., Tresp V., & Gabrilovich E. (2016). A review of relational machine learning for knowledge graphs. Proceedings of the IEEE, 104(1), 11-33. |
| [73] | Oldensand V. M. (2024). Developing a RAG system for automatic question generation: A case study in the Tanzanian education sector [Unpublished master’s thesis]. KTH Royal Institute of Technology. https://www.diva-portal.org/smash/get/diva2:1903662/FULLTEXT01.pdf |
| [74] | OpenAI. (2023). DALL·E 3 system card. OpenAI. https://cdn.openai.com/papers/DALL_E_3_System_Card.pdf |
| [75] | OpenAI. (2024). GPT-4 technical report. arXiv. https://doi.org/10.48550/arXiv.2303.08774 |
| [76] | Papasalouros, A., Kanaris K., & Kotis K. (2008). Automatic generation of multiple choice questions from domain ontologies. In M. B. Nunes & M. McPherson (Eds.), Proceedings of the IADIS International conference on e-learning 2008 (pp.427-434). International Association for Development of the Information Society. |
| [77] | Qin L., Liu J., Huang Z., Zhang K., Liu Q., Jin B., & Chen E. (2023). A Mathematical Word Problem Generator with Structure Planning and Knowledge Enhancement. In Proceedings of the 46th international ACM SIGIR conference on research and development in information retrieval (pp. 1750-1754). Association for Computing Machinery. |
| [78] | Radford A., Kim J. W., Hallacy C., Ramesh A., Goh G., Agarwal S.,... Sutskever I. (2021). Learning transferable visual models from natural language supervision . In Proceedings of the international conference on machine learning (pp. 8748-8763). Proceedings of Machine Learning Research. |
| [79] | Raffel C., Shazeer N., Roberts A., Lee K., Narang S., Matena M.,... Liu P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140), 1-67. |
| [80] | Rathod M., Tu T., & Stasaski K. (2022). Educational multi-question generation for reading comprehension . In Proceedings of the 17th workshop on innovative use of NLP for building educational applications (BEA 2022) (pp. 216-223). Association for Computational Linguistics. |
| [81] | Rudner, L. (2010). Implementing the graduate management admission test computerized adaptive test. In W. van der Linden & C. Glas (Eds.), Elements of adaptive testing (pp. 151-165). Springer. |
| [82] | Sahoo P., Singh A. K., Saha S., Jain V., Mondal S., & Chadha A. (2024). A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv. https://doi.org/10.48550/arXiv.2402.07927 |
| [83] | Sakaguchi, K., Arase Y., & Komachi M. (2013). Discriminative approach to fill-in-the-blank quiz generation for language learners. In H. Schuetze, P. Fung, & M. Poesio (Eds.), Proceedings of the 51st annual meeting of the association for computational linguistics (pp. 238-242). Association for Computational Linguistics. |
| [84] | Sarmah B., Hall B., Rao R., Patel S., Pasquali S., & Mehta D. (2024). HybridRAG: Integrating knowledge graphs and vector retrieval augmented generation for efficient information extraction. arXiv. https://doi.org/10.48550/arXiv.2408.04948 |
| [85] | Sayin A., & Gierl M. (2024). Using OpenAI GPT to generate reading comprehension items. Educational Measurement: Issues and Practice, 43(1), 5-18. |
| [86] | Shanahan M., McDonell K., & Reynolds L. (2023). Role play with large language models. Nature, 623(7987), 493-498. |
| [87] | Smith S., Avinesh P. V. S., & Kilgarriff A. (2010). Gap-fill tests for language learners: Corpus-driven item generation . In Proceedings of the ICON-2010: 8th international conference on natural language processing (pp. 1-6). Macmillan Publishers. |
| [88] | Sumita, E., Sugaya F., & Yamamoto S. (2005). Measuring non-native speakers’ proficiency of English by using a test with automatically-generated fill-in-the-blank questions. In J. Burstein & C. Leacock (Eds.), Proceedings of the second workshop on building educational applications using NLP (pp. 61-68). Association for Computational Linguistics. |
| [89] | Vaswani, A., Shazeer N., Parmar N., Uszkoreit J., Jones L., Gomez A. N.,... Polosukhin I. (2017). Attention is all you need. In U. von Luxburg, I. Guyon, S. Bengio, H. Wallach, R. Fergus, S. V. N. Vishwanathan, & R. Garnett (Eds.), Proceedings of the 31st international conference on neural information processing systems (pp. 5999-6009). Curran Associates Inc. |
| [90] |
von Davier M. (2018). Automated item generation with recurrent neural networks. Psychometrika, 83(4), 847-857.
doi: 10.1007/s11336-018-9608-y pmid: 29532403 |
| [91] | von Davier M. (2019). Training optimus prime, M.D.: Generating medical certification items by fine-tuning OpenAI’s GPT2 transformer model. arXiv. https://doi.org/10.48550/arXiv.1908.08594 |
| [92] | Wang L., Song R., Guo W., & Yang H. (2025). Exploring prompt pattern for generative artificial intelligence in automatic question generation. Interactive Learning Environments, 33(3), 2559-2584. |
| [93] | Wang Q., Mao Z., Wang B., & Guo L. (2017). Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge and Data Engineering, 29(12), 2724-2743. |
| [94] | Wang X., Wei J., Schuurmans D., Le Q., Chi E., Narang S.,... Zhou D. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv. https://doi.org/10.48550/arXiv.2203.11171 |
| [95] | Wei J., Wang X., Schuurmans D., Bosma M., Xia F., Chi E. H.,... Zhou D. (2022). Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th conference on neural information processing systems (pp. 24824-24837). Curran Associates, Inc. |
| [96] | Weng Y., Zhu M., Xia F., Li B., He S., Liu S.,... Zhao J. (2022). Large language models are better reasoners with self-verification. arXiv. https://doi.org/10.48550/arXiv.2212.09561 |
| [97] | Xie R., Liu Z., & Sun M. (2016). Representation learning of knowledge graphs with hierarchical types . In Proceedings of the 25th international joint conference on artificial intelligence (IJCAI) (pp. 2965-2971). AAAI Press. |
| [98] | Yao S., Yu D., Zhao J., Shafran I., Griffiths T., Cao Y., & Narasimhan K. (2023). Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 11809-11822. |
| [99] | Yao Y., Yu T., Zhang A., Wang C., Cui J., Zhu H.,... Sun M. (2024). Minicpm-v: A gpt-4v level mllm on your phone. arXiv. https://doi.org/10.48550/arXiv.2408.01800 |
| [100] | Zhao Y., Ni X., Ding Y., & Ke Q. (2018). Paragraph-level neural question generation with maxout pointer and gated self-attention networks. In Proceedings of the 2018 conference on empirical methods in natural language processing (pp. 3901-3910). Association for Computational Linguistics. |
| [101] | Zhou Q., & Huang D. (2019). Towards generating math word problems from equations and topics. In Proceedings of the 12th international conference on natural language generation (pp. 494-503). Association for Computational Linguistics. |
| [102] | Zhou Y., Muresanu A. I., Han Z., Paster K., Pitis S., Chan H., & Ba J. (2022). Large language models are human- level prompt engineers . In Proceedings of the eleventh international conference on learning representations. OpenReview. |
| [103] | Zieky, M. J. (2006). Fairness reviews in assessment. In S. M. Downing & T. M. Haladyna (Eds.), Handbook of test development (pp. 359-376). Routledge. |
| [104] | Zou B., Li P., Pan L., & Aw A. (2022). Automatic true/false question generation for educational purpose . In Proceedings of the 17th workshop on innovative use of NLP for building educational applications(BEA 2022) (pp. 61-70). Association for Computational Linguistics. |
| [105] | Zu J., Choi I., & Hao J. (2023). Automated distractor generation for fill-in-the-blank items using a prompt- based learning approach. Psychological Testing and Assessment Modeling, 65(1), 55-75. |
| [106] |
Zuckerman M., Flood R., Tan R. J., Kelp N., Ecker D. J., Menke J., & Lockspeiser T. (2023). ChatGPT for assessment writing. Medical Teacher, 45(11), 1224-1227.
doi: 10.1080/0142159X.2023.2249239 pmid: 37789636 |
| [1] | DU Chuanchen, ZHENG Yuanxia, GUO Qianqian, LIU Guoxiong. Artificial theory of mind in large language models: Evidence, onceptualization, and challenges [J]. Advances in Psychological Science, 2025, 33(12): 2027-2042. |
| [2] | ZHOU Qianyi, CAI Yaqi, ZHANG Ya. Empathy in large language models: Evaluation, enhancement, and challenges [J]. Advances in Psychological Science, 2025, 33(10): 1783-1793. |
| [3] | YANG Xiangdong. Toward A Principled Structure Analysis Method of Algebra Story Problems for Item Generation [J]. Advances in Psychological Science, 2014, 22(3): 558-570. |
| [4] | LI Guangming;ZHANG Minqiang;ZHANG Wenyi. Application of Generalizability Theory in Personnel Evaluation [J]. Advances in Psychological Science, 2013, 21(1): 166-174. |
| [5] | Li Zhongquan;Zhang Houcan. Computerized Automatic Item Generation: An Overview [J]. , 2008, 16(2): 348-352. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||