ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
Advances in Psychological Science ›› 2025, Vol. 33 ›› Issue (5): 863-886.doi: 10.3724/SP.J.1042.2025.0863
• Regular Articles • Previous Articles
LI Huangxia1, CHEN Xinwei2, YAO Panpan1( )
)
Received:2024-12-17
Online:2025-05-15
Published:2025-03-20
Contact:
YAO Panpan
E-mail:yaopp@blcu.edu.cn
CLC Number:
LI Huangxia, CHEN Xinwei, YAO Panpan. Comparison of models for letter position encoding and their explanations of experimental effects[J]. Advances in Psychological Science, 2025, 33(5): 863-886.
| 对比项 | 模型 | ||||||
|---|---|---|---|---|---|---|---|
| 开放双字母 组模型 | SERIOL模型 | 空间编码 模型 | 重叠模型 | 贝叶斯读者 模型 | PONG模型 | ||
| 模型 | |||||||
| 基于语言 | 英语 | 英语 | 英语 | 英语 | 英语、法语、荷兰语 | 英语 | |
| 模型结构 | 主要模块 | 字母层、双字母组层、词汇层 | 视网膜层、特征层、字母层、双字母组层、词汇层 | 特征层、字母层、词汇层、外部字母库、空间编码器 | 噪声输入 | 噪声通道 | 视觉层、和注意层、N-字母组层、N-字母组偏侧化估计、词汇表征 |
| 特征层 | 未建模 | 位置梯度 横向抑制 | 字母特征 | 未建模 | 未建模 | 视觉输入和注意力分布 | |
| 字母层级 | 字母身份信息 | 时间激活 | 抽象字母 | 未建模 | 未建模 | 未建模 | |
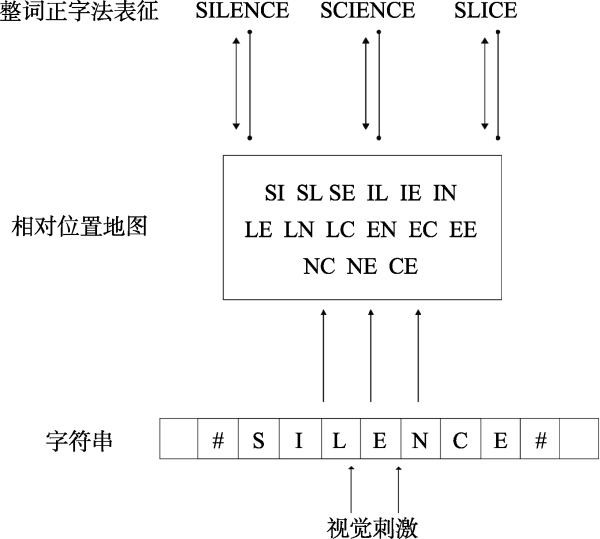
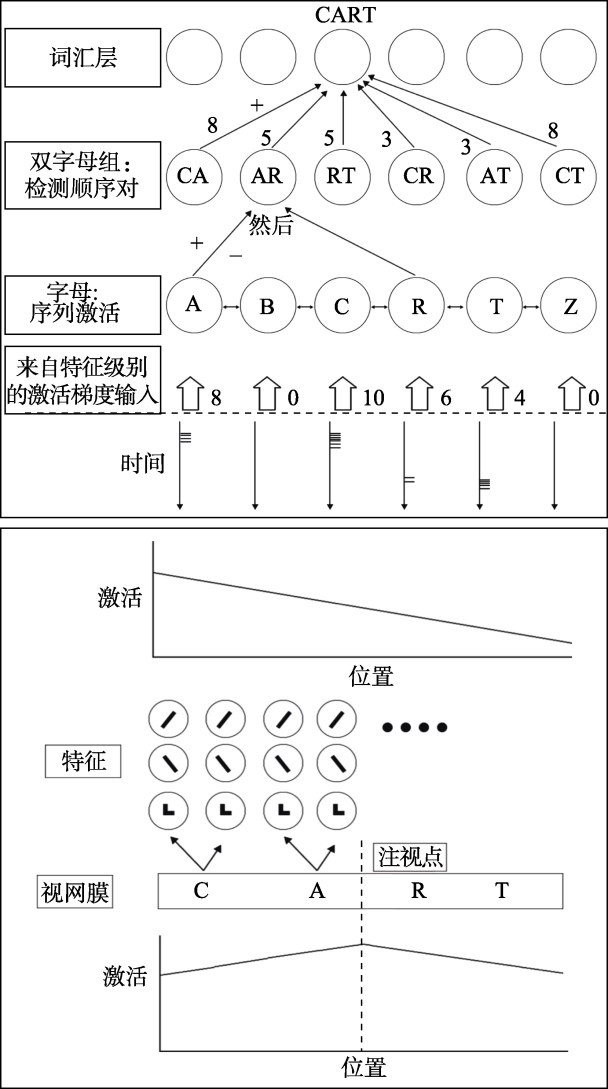
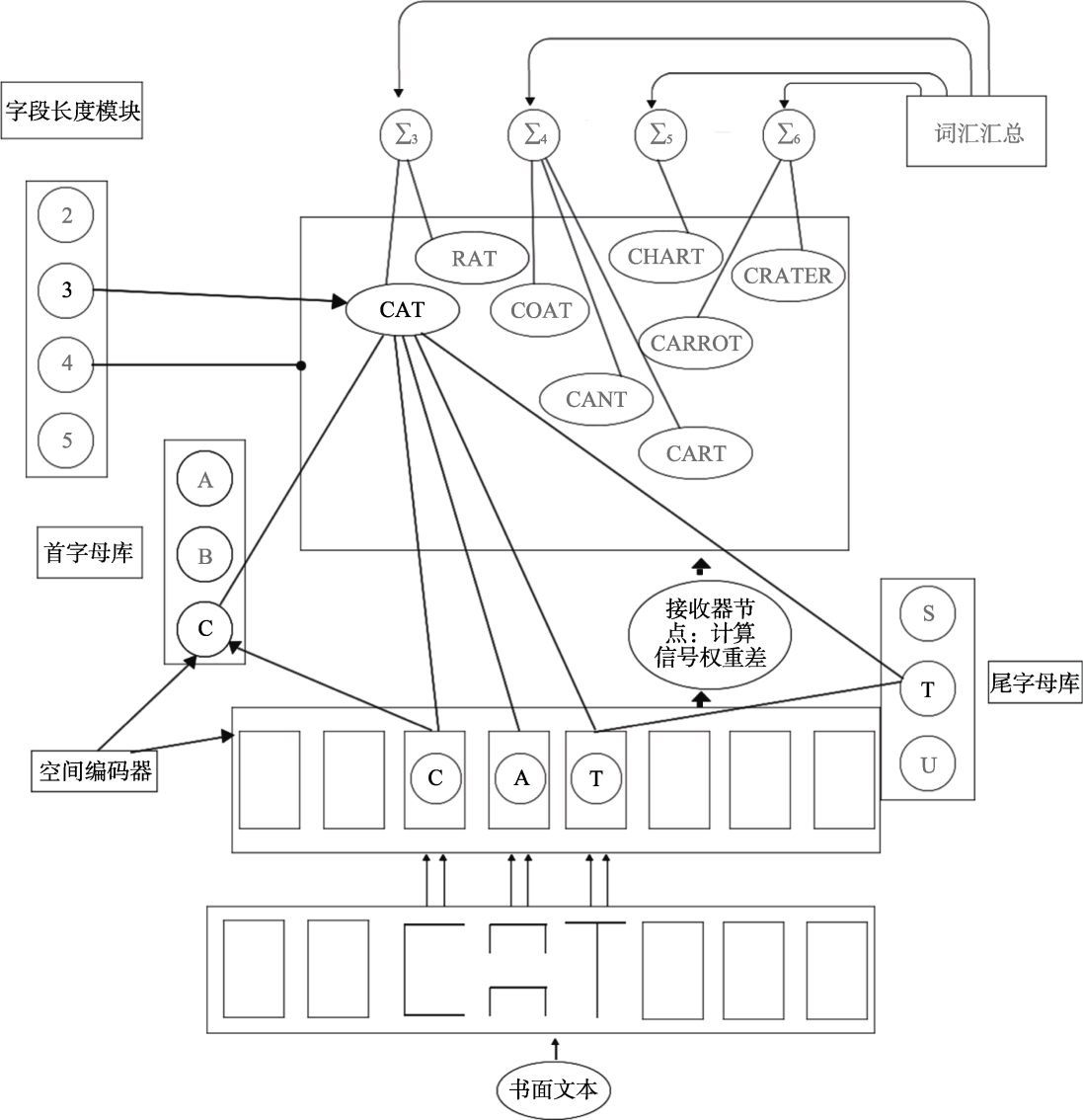
| 字词中间层 | 开放双字母组:相对位置 | 开放双字母组:有序字母对 | 外部字母库; 空间编码器, 接收器节点 | 未建模 | 未建模 | N-字母组; N-字母组偏侧性估计 | |
| 词汇层 | 激活加权, 相互竞争 | 激活加权 | 叠加函数匹配值 | 未建模 | 未建模 | 词长匹配, N-字母组激活、频率和偏侧性估计匹配 | |
| 其他结构 | 未建模 | 视网膜层:感知敏锐度 | 词长估计 | 未建模 | 未建模 | 学习者模块:先验知识; 词长估计 | |
| 理论基础 | 相对位置编码理论 | 相对位置编码理论 | 空间编码理论 | 噪声编码理论 | 噪声编码理论 | 分割加工理论, 相对位置和绝对位置混合编码 | |
| 词汇识别 | 双字母组和词汇层的相互促进和抑制 | 跨上下文单元的激活模式 | 叠加匹配算法, 相互竞争 | 拼写相似度计算(重叠度) | 贝叶斯定理, 噪声积累 | N-字母组的激活、偏侧性估计、词长匹配度 | |
| 跨语言差异 | 未解释 | 未解释 | 未解释 | 未解释 | 未解释 | 学习模型 | |
| 对常见实验效应的解释 | 转置效应 | 开放双字母组的检测和激活 | 开放双字母组, 激活梯度 | 空间相位编码 | 重叠度 | 噪声积累 | N-字母组的偏侧性估计 |
| 非相邻转置效应 | 相对位置跨度 | 振荡周期内激活的时间 | 空间相位编码 | 重叠度 | 未解释 | N-字母组的偏侧性估计 | |
| 字母重复、插入和删除 | 未解释 | 序列编码的灵活性 | 克隆字母节点; 相位编码 | 重叠匹配度 | 噪声通道:编辑距离 | 未解释 | |
| 侧翼效应 | 双字母组 | 未解释 | 未解释 | 未解释 | 噪声通道 | 半球激活重叠 | |
| 最佳注视位置 | 未解释 | 序列加工机制 | 未解释 | 未解释 | 未解释 | N-字母组视敏度 | |
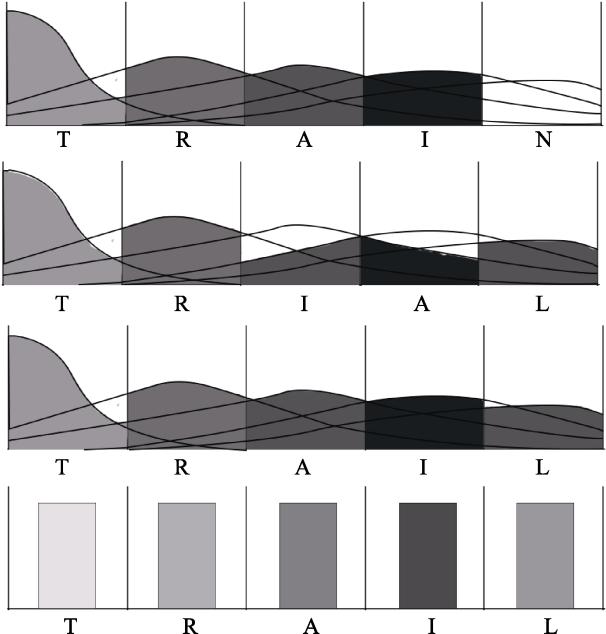
| 首字母和尾字母的重要性 | 相对位置编码标记 | 激活梯度与亚阈值振荡相互作用周期 | 外部字母库 | 首字母与内部字母标准偏差大小 | 未解释 | 未解释 | |
| 阅读方向 | 字母检测器基于水平线上注视的相对位置 | 未解释 | 未解释 | 未解释 | 未解释 | 未解释 | |
| 对比项 | 模型 | ||||||
|---|---|---|---|---|---|---|---|
| 开放双字母 组模型 | SERIOL模型 | 空间编码 模型 | 重叠模型 | 贝叶斯读者 模型 | PONG模型 | ||
| 模型 | |||||||
| 基于语言 | 英语 | 英语 | 英语 | 英语 | 英语、法语、荷兰语 | 英语 | |
| 模型结构 | 主要模块 | 字母层、双字母组层、词汇层 | 视网膜层、特征层、字母层、双字母组层、词汇层 | 特征层、字母层、词汇层、外部字母库、空间编码器 | 噪声输入 | 噪声通道 | 视觉层、和注意层、N-字母组层、N-字母组偏侧化估计、词汇表征 |
| 特征层 | 未建模 | 位置梯度 横向抑制 | 字母特征 | 未建模 | 未建模 | 视觉输入和注意力分布 | |
| 字母层级 | 字母身份信息 | 时间激活 | 抽象字母 | 未建模 | 未建模 | 未建模 | |
| 字词中间层 | 开放双字母组:相对位置 | 开放双字母组:有序字母对 | 外部字母库; 空间编码器, 接收器节点 | 未建模 | 未建模 | N-字母组; N-字母组偏侧性估计 | |
| 词汇层 | 激活加权, 相互竞争 | 激活加权 | 叠加函数匹配值 | 未建模 | 未建模 | 词长匹配, N-字母组激活、频率和偏侧性估计匹配 | |
| 其他结构 | 未建模 | 视网膜层:感知敏锐度 | 词长估计 | 未建模 | 未建模 | 学习者模块:先验知识; 词长估计 | |
| 理论基础 | 相对位置编码理论 | 相对位置编码理论 | 空间编码理论 | 噪声编码理论 | 噪声编码理论 | 分割加工理论, 相对位置和绝对位置混合编码 | |
| 词汇识别 | 双字母组和词汇层的相互促进和抑制 | 跨上下文单元的激活模式 | 叠加匹配算法, 相互竞争 | 拼写相似度计算(重叠度) | 贝叶斯定理, 噪声积累 | N-字母组的激活、偏侧性估计、词长匹配度 | |
| 跨语言差异 | 未解释 | 未解释 | 未解释 | 未解释 | 未解释 | 学习模型 | |
| 对常见实验效应的解释 | 转置效应 | 开放双字母组的检测和激活 | 开放双字母组, 激活梯度 | 空间相位编码 | 重叠度 | 噪声积累 | N-字母组的偏侧性估计 |
| 非相邻转置效应 | 相对位置跨度 | 振荡周期内激活的时间 | 空间相位编码 | 重叠度 | 未解释 | N-字母组的偏侧性估计 | |
| 字母重复、插入和删除 | 未解释 | 序列编码的灵活性 | 克隆字母节点; 相位编码 | 重叠匹配度 | 噪声通道:编辑距离 | 未解释 | |
| 侧翼效应 | 双字母组 | 未解释 | 未解释 | 未解释 | 噪声通道 | 半球激活重叠 | |
| 最佳注视位置 | 未解释 | 序列加工机制 | 未解释 | 未解释 | 未解释 | N-字母组视敏度 | |
| 首字母和尾字母的重要性 | 相对位置编码标记 | 激活梯度与亚阈值振荡相互作用周期 | 外部字母库 | 首字母与内部字母标准偏差大小 | 未解释 | 未解释 | |
| 阅读方向 | 字母检测器基于水平线上注视的相对位置 | 未解释 | 未解释 | 未解释 | 未解释 | 未解释 | |
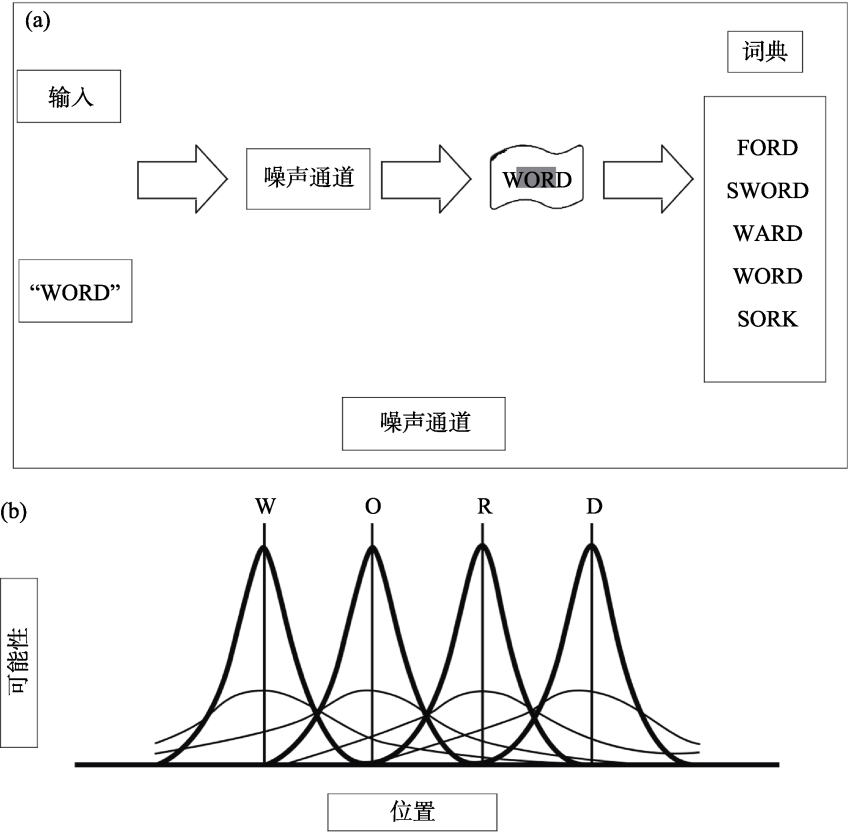
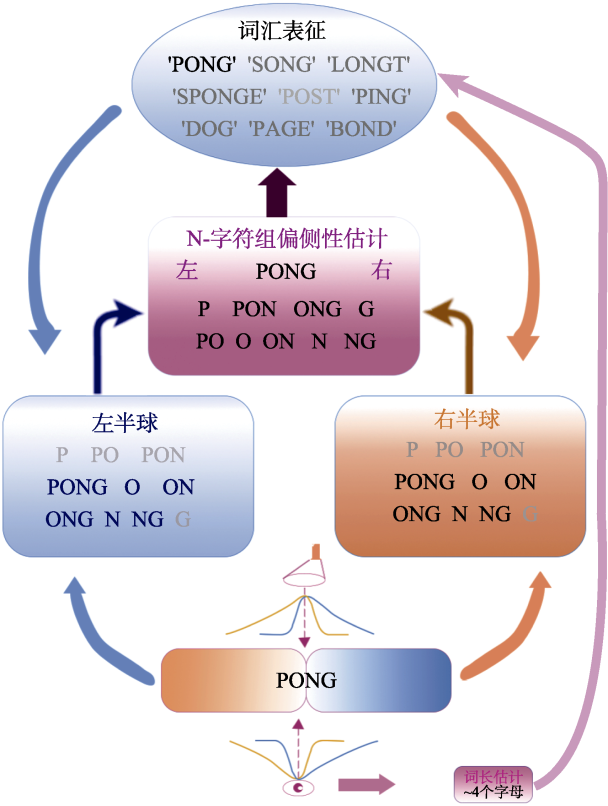
| [1] |
顾俊娟, 高志华, 马绍扬. (2022). 嵌套词汉字位置加工的亚词边界效应. 心理与行为研究, 20(1), 1-7.
doi: 10.12139/j.1672-0628.2022.01.001 |
| [2] | 顾俊娟, 高志华, 屈青青. (2020). 汉字位置加工的词边界效应. 心理与行为研究, 18(2), 193-199. |
| [3] |
顾俊娟, 石金富. (2021). 汉字位置加工和词边界效应的认知机制. 心理科学进展, 29(2), 191-201.
doi: 10.3724/SP.J.1042.2021.00191 |
| [4] | 滑慧敏, 顾俊娟, 林楠, 李兴珊. (2017). 视觉词汇识别中的字符位置编码. 心理科学进展, 25(7), 1132-1138. |
| [5] |
徐迩嘉, 隋雪. (2018). 身份信息与位置信息的加工进程及语境预测性的影响. 心理学报, 50(6), 606-621.
doi: 10.3724/SP.J.1041.2018.00606 |
| [6] | 张妍萃, 常敏, 王敬欣, B.Paterson, K. (2021). 中文阅读中汉字身份信息和位置信息加工受词频调节——来自眼动的证据. 第二十三届全国心理学学术会议摘要集(下), (pp. 356-357). https://doi.org/10.26914/c.cnkihy.2021.040013 |
| [7] |
Acha, J., & Perea, M. (2008). The effects of length and transposed-letter similarity in lexical decision: Evidence with beginning, intermediate, and adult readers. British Journal of Psychology, 99, 245-264.
pmid: 17631694 |
| [8] | Andrews, S. (1996). Lexical retrieval and selection processes: Effects of transposed-letter confusability. Journal of Memory and Language, 35(6), 775-800. https://doi.org/10.1006/jmla.1996.0040 |
| [9] | Andrews, S., & Lo, S. (2012). Not all skilled readers have cracked the code: Individual differences in masked form priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38(1), 152-163.https://doi.org/10.1037/a0024953 |
| [10] |
Aschenbrenner, A. J., Balota, D. A., Weigand, A. J., Scaltritti, M., & Besner, D. (2017). The first letter position effect in visual word recognition: The role of spatial attention. Journal of Experimental Psychology: Human Perception and Performance, 43(4), 700-718. https://doi.org/10.1037/xhp0000342
doi: 10.1037/xhp0000342 URL pmid: 28182479 |
| [11] | Beyersmann, E., McCormick, S. F., & Rastle, K. (2013). Letter Transpositions within Morphemes and across Morpheme Boundaries. Quarterly Journal of Experimental Psychology, 66(12), 2389-2410. https://doi.org/10.1080/17470218.2013.782326 |
| [12] | Brysbaert, M., & Nazir, T. (2005). Visual constraints in written word recognition: Evidence from the optimal viewing-position effect. Journal of Research in Reading, 28(3), 216-228. https://doi.org/10.1111/j.1467-9817.2005.00266.x |
| [13] | Brysbaert, M., Vitu, F., & Schroyens, W. (1996). The right visual field advantage and the optimal viewing position effect: On the relation between foveal and parafoveal word recognition. Neuropsychology, 10(3), 385-395. https://doi.org/10.1037/0894-4105.10.3.385 |
| [14] | Cao, H.-W., Zhang, E.-H., & Xiang, X.-T. (2022). An ERP investigation of morpheme transposition in rapid serial visual presentation. International Journal of Psychophysiology, 182, 159-168. https://doi.org/10.1016/j.ijpsycho.2022.10.009 |
| [15] | Castles, A., Davis, C., & Forster, K. I. (2003). Word recognition development in children:Insights from masked priming. In S.Kinoshita & S.Lupker (Eds.), Masked priming: State of the art (pp. 345-360). New York: Psychology Press. |
| [16] |
Castles, A., Davis, C., Cavalot, P., & Forster, K. (2007). Tracking the acquisition of orthographic skills in developing readers: Masked priming effects. Journal of Experimental Child Psychology, 97(3), 165-182. https://doi.org/10.1016/j.jecp.2007.01.006
URL pmid: 17408686 |
| [17] | Chen, Y., Liu, H., Yu, M., & Dang, J. (2020). The development on transposed-letter effect in English word recognition: Evidence from Late unbalanced Chinese-English bilinguals. Lingua, 235, 102777. https://doi.org/10.1016/j.lingua.2019.102777 |
| [18] | Christianson, K., Johnson, R. L., & Rayner, K. (2005). Letter transpositions within and across morphemes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(6), 1327-1339. https://doi.org/10.1037/0278-7393.31.6.1327 |
| [19] | Cohen, L., Dehaene, S., Naccache, L., Lehéricy, S., Dehaene- Lambertz, G., Hénaff, M. A., & Michel, F. (2000). The visual word form area: Spatial and temporal characterization of an initial stage of reading in normal subjects and posterior split-brain patients. Brain: A Journal of Neurology, 123(2), 291-307. https://doi.org/10.1093/brain/123.2.291 |
| [20] |
Colombo, L., Sulpizio, S., & Peressotti, F. (2019). The developmental trend of transposed letters effects in masked priming. Journal Of Experimental Child Psychology, 186, 117-130. https://doi.org/10.1016/j.jecp.2019.05.007
doi: S0022-0965(19)30033-5 URL pmid: 31226631 |
| [21] |
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108(1), 204-256.
doi: 10.1037/0033-295x.108.1.204 pmid: 11212628 |
| [22] | Cong, F., & Chen, B. (2022). The letter position coding mechanism of second language words during sentence reading: Evidence from eye movements. Quarterly Journal of Experimental Psychology, 75(10), 1932-1947. https://doi.org/10.1177/17470218211064539 |
| [23] | Damerau, F. J. (1964). A technique for computer detection and correction of spelling errors. Communications of the ACM, 7, 171-176. https://doi.org/10.1145/363958.363994 |
| [24] | Dare, N., & Shillcock, R. (2013). Serial and parallel processing in reading: Investigating the effects of parafoveal orthographic information on nonisolated word recognition. Quarterly Journal of Experimental Psychology, 66(3), 487-504. https://doi.org/10.1080/17470218.2012.703212 |
| [25] | Davis, C. J. (1999). The self-organising lexical acquisition and recognition (SOLAR) model of visual word recognition [Unpublished doctoral dissertation]. University of New South Wales, Sydney, Australia. https://doi.org/10.26190/unsworks/13769 |
| [26] |
Davis, C. J. (2010). The spatial coding model of visual word identification. Psychological Review, 117(3), 713-758. https://doi.org/10.1037/a0019738
doi: 10.1037/a0019738 URL pmid: 20658851 |
| [27] | Davis, C. J., & Bowers, J. S. (2006). Contrasting five different theories of letter position coding: Evidence from orthographic similarity effects. Journal of Experimental Psychology: Human Perception and Performance, 32(3), 535-557. |
| [28] |
Davis, C., Kim, J., & Forster, K. I. (2008). Being forward not backward: Lexical limits to masked priming. Cognition, 107(2), 673-684. https://doi.org/10.1037/0096-1523.32.3.535
doi: 10.1016/j.cognition.2007.07.016 URL pmid: 17765887 |
| [29] |
Dehaene, S., & Cohen, L. (2011). The unique role of the visual word form area in reading. Trends in Cognitive Sciences, 15(6), 254-262. https://doi.org/10.1016/j.tics.2011.04.003
doi: 10.1016/j.tics.2011.04.003 URL pmid: 21592844 |
| [30] | Delooze, M. A., Langerock, N., Macy, R., Vergauwe, E., & Morey, C. C. (2022). Encode a letter and get its location for free? Assessing incidental binding of verbal and spatial features. Brain Sciences, 12(6), Article 685. https://doi.org/10.3390/brainsci12060685 |
| [31] | Duñabeitia, J. A., Perea, M., & Carreiras, M. (2014). Revisiting letter transpositions within and across morphemic boundaries. Psychonomic Bulletin & Review, 21(6), 1557-1575. https://doi.org/10.3758/s13423-014-0609-2 |
| [32] |
Ellis, A. W., & Brysbaert, M. (2010). Split fovea theory and the role of the two cerebral hemispheres in reading: A review of the evidence. Neuropsychologia, 48(2), 353-365. https://doi.org/10.1016/j.neuropsychologia.2009.08.021
doi: 10.1016/j.neuropsychologia.2009.08.021 URL pmid: 19720073 |
| [33] | Fernández-López, M., & Perea, M. (2023). A letter is a letter and its co-occurrences: Cracking the emergence of position-invariance processing. Psychonomic Bulletin & Review, 30(6), 2328-2337. https://doi.org/10.3758/s13423-023-02265-7 |
| [34] | Fernández-López, M., Gómez, P., & Perea, M. (2023). Letter rotations: Through the magnifying glass and what evidence found there. Language, Cognition and Neuroscience, 38(2), 127-138. |
| [35] |
Frost, R. (1998). Toward a strong phonological theory of visual word recognition: True issues and false trails. Psychological Bulletin, 123(1), 71-99.
pmid: 9461854 |
| [36] | Frost, R. (2009). Reading in Hebrew versus reading in English:Is there a qualitative difference? In K.Pugh & P.McCradle (Eds.), How children learn to read: Current issues and new directions in the integration of cognition, neurobiology and genetics of reading and dyslexia research and practice (pp. 235-254). New York: Psychology Press. |
| [37] | Frost, R. (2012). A universal approach to modeling visual word recognition and reading: Not only possible, but also inevitable. Behavioural and Brain Sciences, 35(5), 310-329. https://doi.org/10.1017/S0140525X12000635 |
| [38] |
Gomez, P., Ratcliff, R., & Perea, M. (2008). The overlap model: A model of letter position coding. Psychological Review, 115(3), 577-601. https://doi.org/10.1037/a0012667
doi: 10.1037/a0012667 URL pmid: 18729592 |
| [39] | Gomez, P., Marcet, A., & Perea, M. (2021). Are better young readers more likely to confuse their mother with their mohter? Quarterly Journal of Experimental Psychology, 74(9), 1542-1552. https://doi.org/10.1177/17470218211012960 |
| [40] | Grainger, J. (2008). Cracking the orthographic code: An introduction. Language and Cognitive Processes, 23(1), 1-35. https://doi.org/10.1080/01690960701578013 |
| [41] | Grainger, J. (2018). Orthographic processing: A “mid-level” vision of reading: The 44th Sir Frederic Bartlett Lecture. Quarterly Journal of Experimental Psychology, 71(2), 335-359. https://doi.org/10.1080/17470218.2017.1314515 |
| [42] | Grainger, J., Granier, J.-P., Farioli, F., Van Assche, E., & Van Heuven, W. J. B. (2006). Letter position information and printed word perception: The relative-position priming constraint. Journal of Experimental Psychology: Human Perception and Performance, 32(4), 865-884. https://doi. org/10.1037/0096-1523.32.4.865 |
| [43] | Grainger, J., & Holcomb, P. J. (2009a). An ERP investigation of orthographic priming with relative-position and absolute-position primes. Brain Research, 1270, 45-53. https://doi.org/10.1016/j.brainres.2009.02.080 |
| [44] | Grainger, J., & Holcomb, P. J. (2009b). Watching the word go by: On the time-course of component processes in visual word recognition. Language and Linguistics Compass, 3(1), 128-156. https://doi.org/10.1111/j.1749-818X.2008.00121.x |
| [45] |
Grainger, J., & Jacobs, A. M. (1996). Orthographic processing in visual word recognition: A multiple read-out model. Psychological Review, 103(3), 518-565.
pmid: 8759046 |
| [46] |
Grainger, J., Mathôt, S., & Vitu, F. (2014). Tests of a model of multi-word reading: Effects of parafoveal flanking letters on foveal word recognition. Acta Psychologica, 146, 35-40. https://doi.org/10.1016/j.actpsy.2013.11.014
doi: 10.1016/j.actpsy.2013.11.014 URL pmid: 24370788 |
| [47] | Grainger, J., & van Heuven, W. J. B. (2003). Modeling letter position coding in printed word perception. In P. Bonin (Ed.), Mental lexicon: “Some words to talk about words” (pp. 1-23). New York: Nova Science. |
| [48] |
Grainger, J., & Whitney, C. (2004). Does the huamn mnid raed wrods as a wlohe? Trends in Cognitive Sciences, 8, 58-59.
pmid: 15588808 |
| [49] | Grossberg, S. (1978). A theory of human memory:Self-organization and performance of sensory-motor codes, maps, and plans. In R. Rosen & F. Snell (Eds.), Progress in theoretical biology (pp. 233-374). New York, NY: Academic Press. |
| [50] | Gu, J., & Li, X. (2015). The effects of character transposition within and across words in Chinese reading. Attention Perception & Psychophysics, 77(1), 272-281. https://doi. org/10.3758/s13414-014-0749-5 |
| [51] |
Gu, J., Li, X., & Liversedge, S. P. (2015). Character order processing in Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 41(1), 127-137. https://doi.org/10.1037/a0038639
doi: 10.1037/a0038639 URL pmid: 25621586 |
| [52] | Gu, J., Zhou, J., Bao, Y., Liu, J., Perea, M., & Li, X. (2022). The effect of transposed-character distance in Chinese reading. Journal of Experimental Psychology: Learning, Memory, and Cognition. Advance online publication. https://doi.org/10.1037/xlm0001180 |
| [53] | Jordan, T. R., Thomas, S. M., Patching, G. R., & Scott-Brown, K. C. (2003). Assessing the importance of letter pairs in initial, exterior, and interior positions in reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29(5), 883-893. https://doi.org/10.1037/0278-7393.29.5.883 |
| [54] |
Johnson, R. L., & Eisler, M. E. (2012). The importance of the first and last letter in words during sentence reading. Acta Psychologica, 141(3), 336-351. https://doi.org/10.1016/j.actpsy.2012.09.013
doi: 10.1016/j.actpsy.2012.09.013 URL pmid: 23089042 |
| [55] | Johnson, R. L., Perea, M., & Rayner, K. (2007). Transposed- letter effects in reading: Evidence from eye movements and parafoveal preview. Journal of Experimental Psychology: Human Perception and Performance, 33(1), 209-229. https://doi.org/10.1037/0096-1523.33.1.209 |
| [56] |
Kirkby, J. A., Barrington, R. S., Drieghe, D., & Liversedge, S. P. (2022). Parafoveal processing and transposed‐letter effects in dyslexic reading. Dyslexia, 28(3), 359-374. https://doi.org/10.1002/dys.1721
doi: 10.1002/dys.1721 URL pmid: 35818161 |
| [57] |
Kronbichler, M., Hutzler, F., Wimmer, H., Mair, A., Staffen, W., & Ladurner, G. (2004). The visual word form area and the frequency with which words are encountered: Evidence from a parametric fMRI study. NeuroImage, 21(3), 946-953. https://doi.org/10.1016/j.neuroimage.2003.10.021
URL pmid: 15006661 |
| [58] | Lally, C., Taylor, J. S. H., Lee, C. H., & Rastle, K. (2020). Shaping the precision of letter position coding by varying properties of a writing system. Language, Cognition and Neuroscience, 35(3), 374-382. |
| [59] | Lee, C. H., & Taft, M. (2009). Are onsets and codas important in processing letter position? A comparison of TL effects in English and Korean. Journal of Memory and Language, 60(4), 530-542. https://doi.org/10.1016/j.jml.2009.01.002 |
| [60] |
Lerner, I., Armstrong, B. C., & Frost, R. (2014). What can we learn from learning models about sensitivity to letter-order in visual word recognition? Journal of Memory and Language, 77, 40-58. https://doi.org/10.1016/j.jml.2014.09.002
URL pmid: 25431521 |
| [61] | Levenshtein, V. I. (1966). Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady, 10, 707-710. |
| [62] | Li, X., & Pollatsek, A. (2020). An integrated model of word processing and eye-movement control during Chinese reading. Psychological Review, 127(6), 1139-1162. https://doi.org/10.1037/rev0000248 |
| [63] |
Li, X., Rayner, K., & Cave, K. R. (2009). On the segmentation of Chinese words during reading. Cognitive Psychology, 58(4), 525-552.
doi: 10.1016/j.cogpsych.2009.02.003 pmid: 19345938 |
| [64] | Lin, Y. -C., & Lin, P. -Y. (2016). Mouse tracking traces the “Camrbidge Unievrsity” effects in monolingual and bilingual minds. ActaPsychologica, 167, 52-62. https://doi.org/10.1016/j.actpsy.2016.04.001 |
| [65] |
Liu, Y., Yu, L., & Reichle, E. D. (2019). The influence of parafoveal preview, character transposition, and word frequency on saccadic targeting in Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 45(4), 537-552.
doi: 10.1037/xhp0000630 pmid: 30920286 |
| [66] | Logan, G. D. (2021). Serial order in perception, memory, and action. Psychological Review, 128(1), 1-44. https://doi.org/10.1037/rev0000253 |
| [67] | Luke, S. G., & Christianson, K. (2012). Semantic predictability eliminates the transposed-letter effect. Memory & Cognition, 40(4), 628-641. https://doi.org/10.3758/s13421-011-0170-4 |
| [68] | Luke, S. G., & Christianson, K. (2013). The influence of frequency across the time course of morphological processing: Evidence from the transposed-letter effect. Journal of Cognitive Psychology, 25(4), 781-799.https://doi.org/10.1080/20445911.2013.832682 |
| [69] | Lupker, S. J., Perea, M., & Davis, C. J. (2008). Transposed- letter effects: Consonants, vowels and letter frequency. Language and Cognitive Processes, 23(1), 93-116. https://doi.org/10.1080/01690960701579714 |
| [70] | Marcet, A., Perea, M., Baciero, A., & Gomez, P. (2019). Can letter position encoding be modified by visual perceptual elements? Quarterly Journal of Experimental Psychology, 72(6), 1344-1353. https://doi.org/10.1177/1747021818789876 |
| [71] | McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychological Review, 88(5), 375-407. https://doi.org/10.1037/0033-295X.88.5.375 |
| [72] | Meade, G., Mahnich, C., Holcomb, P. J., & Grainger, J. (2021). Orthographic neighborhood density modulates the size of transposed-letter priming effects. Cognitive, Affective, & Behavioral Neuroscience, 21, 948-959. |
| [73] |
Norris, D. (2006). The Bayesian reader: Explaining word recognition as an optimal Bayesian decision process. Psychological Review, 113(2), 327-357. https://doi.org/10.1037/0033-295X.113.2.327
doi: 10.1037/0033-295X.113.2.327 URL pmid: 16637764 |
| [74] | Norris, D., & Kinoshita, S. (2012). Reading through a noisy channel: Why there’s nothing special about the perception of orthography. Psychological Review, 119(3), 517-545. https://doi.org/10.1037/a0028450 |
| [75] | Norris, D., Kinoshita, S., & van Casteren, M. (2010). A stimulus sampling theory of letter identity and order. Journal of Memory and Language, 62(3), 254-271. https://doi.org/10.1016/j.jml.2009.11.002 |
| [76] |
Paap, K. R., Newsome, S. L., McDonald, J. E., & Schvaneveldt, R. W. (1982). An activation-verification model for letter and word recognition: The word-superiority effect. Psychological Review, 89(5), 573-594.
pmid: 7178333 |
| [77] | Pagan, A., Paterson, K. B., Blythe, H. I., & Liversedge, S. P. (2016). An inhibitory influence of transposed-letter neighbors on eye movements during reading. Psychonomic Bulletin & Review, 23(1), 278-284. https://doi.org/10.3758/s13423-015-0869-5 |
| [78] | Perea, M., Abu Mallouh, R., García-Orza, J., & Carreiras, M. (2011). Masked priming effects are modulated by expertise in the script. Quarterly Journal of Experimental Psychology, 64(5), 902-919. Q2. https://doi.org/10.1080/17470218.2010.512088 |
| [79] |
Perea, M., & Acha, J. (2009). Does letter position coding depend on consonant/vowel status? Evidence with the masked priming technique. Acta Psychologica, 130(2), 127-137. https://doi.org/10.1016/j.actpsy.2008.11.001
doi: 10.1016/j.actpsy.2008.11.001 URL pmid: 19081083 |
| [80] | Perea, M., & Carreiras, M. (2006). Do transposed-letter effects occur across lexeme boundaries? Psychonomic Bulletin & Review, 13(3), 418-422. https://doi.org/10.3758/BF03193863 |
| [81] | Perea, M., & Estévez, A. (2008). Transposed-letter similarity effects in naming pseudowords: Evidence from children and adults. European Journal of Cognitive Psychology, 20(1), 33-46. |
| [82] | Perea, M., Gatt, A., Moret-Tatay, C., & Fabri, R. (2012). Are all Semitic languages immune to letter transpositions? The case of Maltese. Psychonomic Bulletin & Review, 19(5), 942-947. https://doi.org/10.3758/s13423-012-0273-3 |
| [83] | Perea, M., Jiménez, M., & Gomez, P. (2016). Does location uncertainty in letter position coding emerge because of literacy training? Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(6), 996-1001. https://doi.org/10.1037/xlm0000208 |
| [84] | Perea, M., & Lupker, S. J. (2004). Can CANISO activate CASINO? Transposed-letter similarity effects with nonadjacent letter positions. Journal of Memory and Language, 51(2), 231-246. https://doi.org/10.1016/j.jml.2004.05.005 |
| [85] | Perea, M., Marcet, A., & Fernández-López, M. (2018). Does letter rotation slow down orthographic processing in word recognition? Psychonomic Bulletin & Review, 25(6), 2295-2300. https://doi.org/10.3758/s13423-017-1428-z |
| [86] | Perea, M., Rosa, E., & Gómez, C. (2005). The frequency effect for pseudowords in the lexical decision task. Perception & Psychophysics, 67(2), 301-314. https://doi.org/10.3758/BF03206493 |
| [87] |
Perfetti, C. A., Liu, Y., & Tan, L. H. (2005). The lexical constituency model: Some implications of research on Chinese for general theories of reading. Psychological Review, 112(1), 43-59.
pmid: 15631587 |
| [88] | Perfetti, C. A., & Tan, L. H. (1998). The time course of graphic, phonological, and semantic activation in Chinese character identification. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24(1), 101-118. |
| [89] | Rastle, K., Davis, M. H., & New, B. (2004). The broth in my brother’s brothel: Morpho-orthographic segmentation in visual word recognition. Psychonomic Bulletin & Review, 11(6), 1090-1098. https://doi.org/10.3758/BF03196742 |
| [90] | Rauschecker, A. M., Bowen, R. F., Parvizi, J., & Wandell, B. A. (2012). Position sensitivity in the visual word form area. PNAS Proceedings of the National Academy of Sciences of the United States of America, 109(24), E1568- E1577. https://doi.org/10.1073/pnas.1121304109 |
| [91] |
Rayner, K., White, S. J., Johnson, R. L., & Liversedge, S. P. (2006). Raeding wrods with jubmled lettres: There is a cost. Psychological Science, 17(3), 192-193.
doi: 10.1111/j.1467-9280.2006.01684.x pmid: 16507057 |
| [92] |
Rueckl, J. G., & Rimzhim, A. (2011). On the interaction of letter transpositions and morphemic boundaries. Language and Cognitive Processes, 26(4-6), 482-508. https://doi.org/10.1080/01690965.2010.500020
doi: 10.1080/01690965.2010.500020 URL pmid: 22933829 |
| [93] | Rumelhart, D. E., & McClelland, J. L. (1981). An interactive activation model of context effects in letter perception: Part 2. The contextual enhancement effect and some tests and extensions of the model. Psychological Review, 88(5), 375-407. |
| [94] | Sánchez-Gutiérrez, C., & Rastle, K. (2013). Letter transpositions within and across morphemic boundaries: Is there a cross- language difference? Psychonomic Bulletin & Review, 20(5), 988-996.https://doi.org/10.3758/s13423-013-0425-0 |
| [95] | Schoonbaert, S., & Grainger, J. (2004). Letter position coding in printed word perception: Effects of repeated and transposed letters. Language and Cognitive Processes, 19(3), 333-367. https://doi.org/10.1080/01690960344000198 |
| [96] |
Shillcock, R., Ellison, T. M., & Monaghan, P. (2000). Eye-fixation behavior, lexical storage, and visual word recognition in a split processing model. Psychological Review, 107(4), 824-851. https://doi.org/10.1037/0033-295X.107.4.824
URL pmid: 11089408 |
| [97] | Snell, J. (2024). PONG: A computational model of visual word recognition through bihemispheric activation. Psychological Review, 132(3), 505-527. https://doi.org/10.1037/rev0000461 |
| [98] | Snell, J., Bertrand, D., & Grainger, J. (2018). Parafoveal letter-position coding in reading. Memory & Cognition, 46(4), 589-599. https://doi.org/10.3758/s13421-017-0786-0 |
| [99] |
Snell, J., Bertrand, D., Meeter, M., & Grainger, J. (2018). Integrating orthographic information across time and space. Experimental Psychology, 65(1), 32-39. https://doi.org/10.1027/1618-3169/a000386
doi: 10.1027/1618-3169/a000386 URL pmid: 29415643 |
| [100] | Snell, J., & Grainger, J. (2018). Parallel word processing in the flanker paradigm has a rightward bias. Attention, Perception, & Psychophysics, 80(6), 1512-1519. https://doi.org/10.3758/s13414-018-1547-2 |
| [101] |
Snell, J., & Grainger, J. (2019). Readers are parallel processors. Trends in Cognitive Sciences, 23(7), 537-546. https://doi.org/10.1016/j.tics.2019.04.006
doi: S1364-6613(19)30098-1 URL pmid: 31138515 |
| [102] | Snell, J., Grainger, J., & Meeter, M. (2022). Relative letter- position coding revisited. Psychonomic Bulletin & Review, 29(3), 995-1002. https://doi.org/10.3758/s13423-021-02039-z |
| [103] |
Stites, M. C., Federmeier, K. D., & Christianson, K. (2016). Do morphemes matter when reading compound words with transposed letters? Evidence from eye-tracking and event-related potentials. Language, Cognition and Neuroscience, 31(10), 1299-1319. https://doi.org/10.1080/23273798.2016.1212082
doi: 10.1080/23273798.2016.1212082 URL pmid: 28791313 |
| [104] | Taft, M., & Zhu, X. (1997). Submorphemic processing in reading Chinese. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23(3), 761-775. |
| [105] | Trauzettel-Klosinski, S., Dietz, K., & the, IReST Study Group. (2012). Standardized assessment of reading performance: The new international reading speed texts IReST. Investigative Ophthalmology & Visual Science, 53(9), 5452-5461. https://doi.org/10.1167/iovs.11-8284 |
| [106] | Van Assche, E., & Grainger, J. (2006). A study of relative- position priming with superset primes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32(2), 399-415. https://doi.org/10.1037/0278-7393.32.2.399 |
| [107] |
Vergara-Martínez, M., Perea, M., Gómez, P., & Swaab, T. Y. (2013). ERP correlates of letter identity and letter position are modulated by lexical frequency. Brain and Language, 125(1), 11-27. https://doi.org/10.1016/j.bandl.2012.12.009
doi: 10.1016/j.bandl.2012.12.009 URL pmid: 23454070 |
| [108] |
Warrington, K. L., McGowan, V. A., Paterson, K. B., & White, S. J. (2019). Effects of adult aging on letter position coding in reading: Evidence from eye movements. Psychology and Aging, 34(4), 598-612. https://doi.org/10.1037/pag0000342
doi: 10.1037/pag0000342 URL pmid: 30920243 |
| [109] |
Welvaert, M., Farioli, F., & Grainger, J. (2008). Graded effects of number of inserted letters in superset priming. Experimental Psychology, 55(1), 54-63.
pmid: 18271354 |
| [110] | White, S. J., Johnson, R. L., Liversedge, S. P., & Rayner, K. (2008). Eye movements when reading transposed text: The importance of word-beginning letters. Journal of Experimental Psychology: Human Perception and Performance, 34(5), 1261-1276. https://doi.org/10.1037/0096-1523.34.5.1261 |
| [111] | Whitney, C. (2001). How the brain encodes the order of letters in a printed word: The SERIOL model and selective literature review. Psychonomic Bulletin & Review, 8(2), 221-243. https://doi.org/10.3758/BF03196158 |
| [112] |
Whitney, C., & Berndt, R. S. (1999). A new model of letter string encoding: Simulating right neglect dyslexia. Progress in Brain Research, 121, 143-163.
pmid: 10551025 |
| [113] | Whitney, C., Bertrand, D., & Grainger, J. (2012). On coding the position of letters in words: a test of two models. Experimental Psychology, 59(2), 109-114. https://doi.org/10.1027/1618-3169/a000132 |
| [114] | Winskel, H., & Perea, M. (2013). Consonant/vowel asymmetries in letter position coding during normal reading: Evidence from parafoveal previews in Thai. Journal of Cognitive Psychology, 25(1), 119-130. https://doi.org/10.1080/20445911.2012.753077 |
| [115] |
Witzel, N., Qiao, X., & Forster, K. (2011). Transposed letter priming with horizontal and vertical text in Japanese and English readers. Journal of Experimental Psychology: Human Perception and Performance, 37(3), 914-920. https://doi.org/10.1037/a0022194
doi: 10.1037/a0022194 URL pmid: 21639675 |
| [116] | Yang, H., Chen, J., Spinelli, G., & Lupker, S. J. (2019). The impact of text orientation on form priming effects in four-character Chinese words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45(8), 1511-1526. https://doi.org/10.1037/xlm0000655 |
| [117] | Yang, H., Hino, Y., Chen, J., Yoshihara, M., Nakayama, M., Xue, J., & Lupker, S. J. (2020). The origins of backward priming effects in logographic scripts for four-character words. Journal of Memory and Language, 113, 104107. https://doi.org/10.1016/j.jml.2020.104107 |
| [118] | Yang, H., Jared, D., Perea, M., & Lupker, S. J. (2021). Is letter position coding when reading in L2 affected by the nature of position coding used when bilinguals read in their L1? Memory & Cognition, 49(4), 771-786. https://doi.org/10.3758/s13421-020-01126-1 |
| [119] | Yang, H., Taikh, A., & Lupker, S. J. (2022). A reexamination of the impact of morphology on transposed character priming effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 48(6), 785-797. https://doi.org/10.1037/xlm0001119 |
| [120] | Zhang, E.-H., Lai, X.-X., Li, D., Lei, V. L. C., Chen, Y., & Cao, H.-W. (2021). Electrophysiological correlates of character transposition in the left and right visual fields. Frontiers in Psychology, 12, 684849. https://doi.org/10.3389/fpsyg.2021.684849 |
| [121] | Zhou, X., & Marslen-Wilson, W. (1999). Phonology, orthography, and semantic activation in reading Chinese. Journal of Memory and Language, 41(4), 579-606. |
| [122] |
Ziegler, J. C., Bertrand, D., Lété, B., & Grainger, J. (2014). Orthographic and phonological contributions to reading development: Tracking developmental trajectories using masked priming. Developmental Psychology, 50(4), 1026-1036.
doi: 10.1037/a0035187 pmid: 24294878 |
| [1] | HAN Haibin, LI Xingshan. The mechanism of phonetic position encoding in spoken word recognition [J]. Advances in Psychological Science, 2024, 32(9): 1488-1501. |
| [2] | GUO Mingqian, PAN Wanke, HU Chuanpeng. Model comparison in cognitive modeling [J]. Advances in Psychological Science, 2024, 32(10): 1736-1756. |
| [3] | SHEN Si-Chu, WANG Yao-Min, ZHANG Han-Bing, MA Jia-Tao. Discount or trade off: The psychological mechanisms of intertemporal choice with double-dated mixed outcomes [J]. Advances in Psychological Science, 2023, 31(7): 1121-1132. |
| [4] | LI Yutong, SUI Xue. Semantic association effect and its neural mechanism from the perspective of lexical co-occurrence frequency [J]. Advances in Psychological Science, 2021, 29(1): 112-122. |
| [5] | HUA Huimin, GU Junjuan, LIN Nan, LI Xingshan. Letter/character position encoding in visual word recognition [J]. Advances in Psychological Science, 2017, 25(7): 1132-1138. |
| [6] | Fang Hou; Yukai Zhao; Luis A. Lesmes; Zhong-Lin Lu. The Shape of the Contrast Sensitivity Function: Invariant across Light Conditions, Varies Across Observers [J]. Advances in Psychological Science, 2016, 24(Suppl.): 37-. |
| [7] | BAI Xuejun;ZHANG Manman;ZANG Chuanli;LI Xin;CHEN Lu;YAN Guoli. The Effect of Word Boundary Information on Chinese Word Acquisition and Recognition: Evidence from Eye Movements [J]. Advances in Psychological Science, 2014, 22(1): 1-8. |
| [8] | ZHANG Lingyan;JIN Tan;TIAN Zhaoxia. On the Time Axis of Morpho-semantic Activation: Form-then-meaning or Form-with-meaning? [J]. Advances in Psychological Science, 2013, 21(8): 1382-1389. |
| [9] | REN Gui-Qin;HAN Yu-Chang;LIU Ying. On-line Study on Chinese Word Recognition During Sentence Reading [J]. , 2012, 20(4): 493-503. |
| [10] | LI Xing-Shan;LIU Ping-Ping;MA Guo-Jie. Advances in Cognitive Mechanisms of Word Segmentation During Chinese Reading [J]. , 2011, 19(4): 459-470. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||