ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
心理科学进展 ›› 2024, Vol. 32 ›› Issue (9): 1379-1392.doi: 10.3724/SP.J.1042.2024.01379 cstr: 32111.14.2024.01379
• 研究构想 • 下一篇
李兴珊1,2( ), 张淇玮1,2(), 黄林洁琼1
), 张淇玮1,2(), 黄林洁琼1
收稿日期:2023-12-06
出版日期:2024-09-15
发布日期:2024-06-26
基金资助:
LI Xingshan1,2(), ZHANG Qiwei1,2(), HUANG Linjieqiong1
Received:2023-12-06
Online:2024-09-15
Published:2024-06-26
摘要:
中文是全球华人广泛使用的文字, 特点鲜明。由于其特异性, 西方语言理论和模型无法直接应用于中文。现有中文词汇加工研究中, 缺乏系统的计算模型来模拟词汇语义加工过程。本研究旨在通过计算建模和实验研究方法解决上述问题。研究将系统回顾中文词汇加工已有研究并进行元分析, 构建模型以模拟中文词汇在孤立呈现及句子语境中的加工过程。该模型能够加工单字词和多字词, 模拟词的形、音、义的加工过程及交互作用, 并考虑语境中上下文的影响。最后, 通过实验研究验证模型假设。本研究建立的中文词汇语义加工模型有助于理解中文阅读特异性认知机制和词汇加工的动态过程。
中图分类号:
李兴珊, 张淇玮, 黄林洁琼. (2024). 中文词汇语义加工过程的计算模拟与实验验证. 心理科学进展 , 32(9), 1379-1392.
LI Xingshan, ZHANG Qiwei, HUANG Linjieqiong. (2024). Computational modeling and experimental validation of Chinese lexical and semantic processing. Advances in Psychological Science, 32(9), 1379-1392.
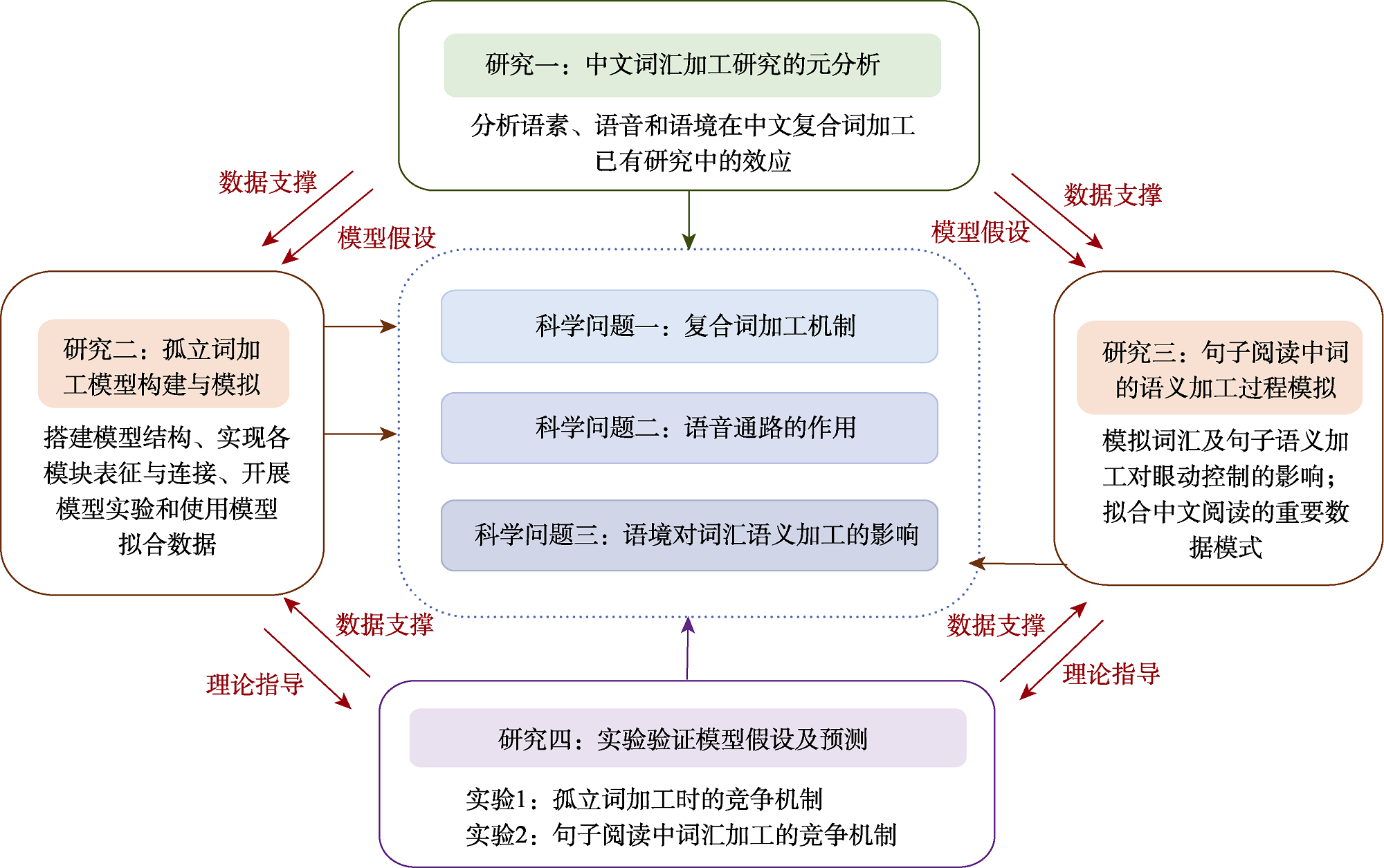
图1 本研究框架图
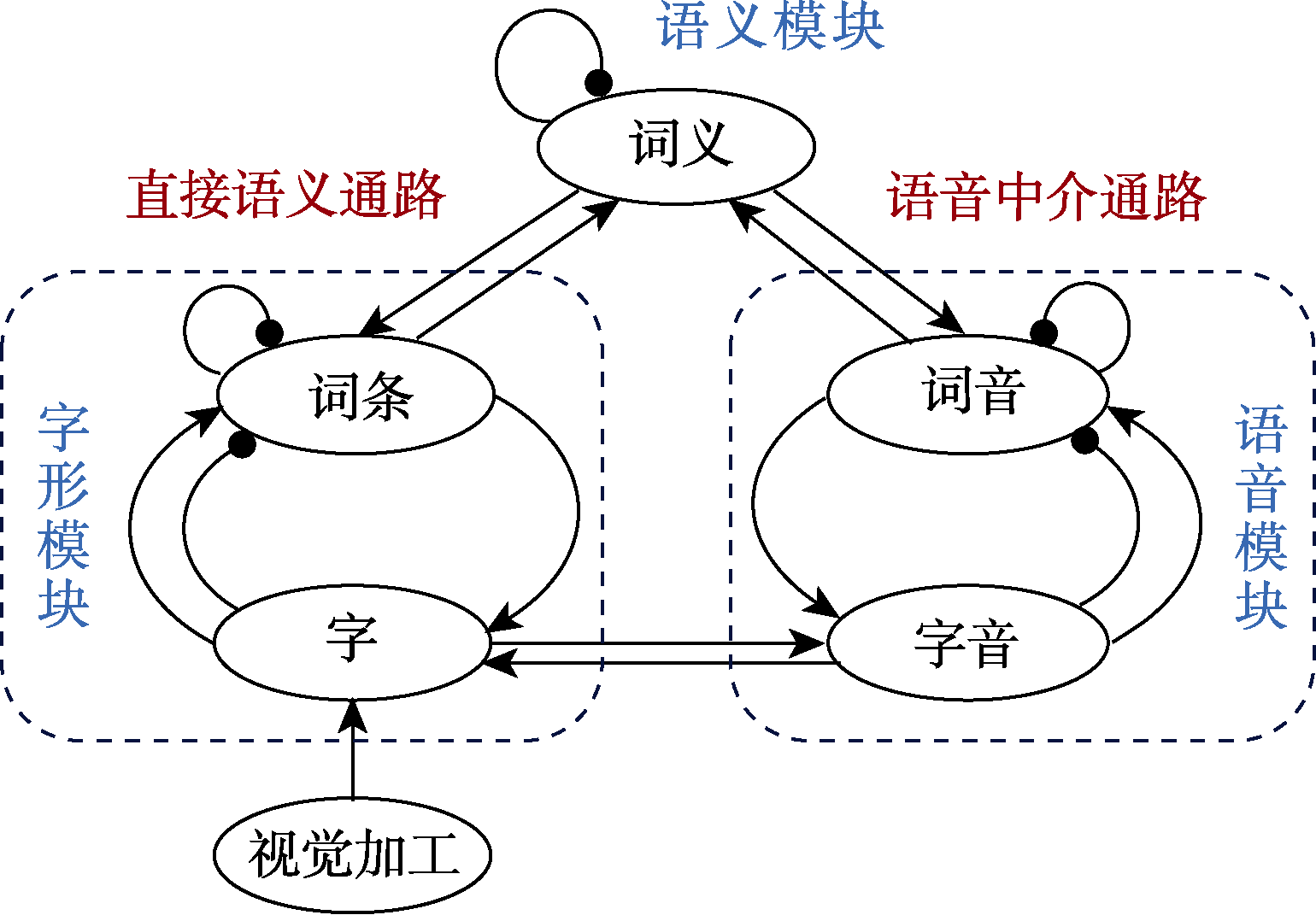
图2 中文阅读字词加工计算模型框架图
| [1] |
曹海波, 兰泽波, 高峰, 于海涛, 李鹏, 王敬欣. (2023). 词素位置概率在中文阅读中的作用:词汇判断和眼动研究. 心理学报, 55(2), 159-176. https://doi.org/10.3724/SP.J.1041.2023.00159
doi: 10.3724/SP.J.1041.2023.00159 URL |
| [2] |
刘志方, 仝文, 张智君, 赵亚军. (2020). 语境预测性对阅读中字词加工过程的影响:眼动证据. 心理学报, 52(9), 1031-1047. https://doi.org/10.3724/SP.J.1041.2020.01031
doi: 10.3724/SP.J.1041.2020.01031 URL |
| [3] | 申薇, 李兴珊. (2012). 中文阅读中词优效应的特异性. 科学通报, 57(35), 3414-3420. https://doi.org/10.1360/972012-666 |
| [4] | 王春茂, 彭聃龄. (1999). 合成词加工中的词频、词素频率及语义透明度. 心理学报, 31(3), 266-273. |
| [5] | Bai, X., Yan, G., Liversedge, S., Zang, C., & Rayner, K. (2008). Reading spaced and unspaced Chinese text: Evidence from eye movements. Journal of Experimental Psychology: Human Perception and Performance, 34(5), 1277-1287. https://doi.org/10.1037/0096-1523.34.5.1277 |
| [6] | Bemis, D. K., & Pylkkänen, L. (2011). Simple composition: A magnetoencephalography investigation into the comprehension of minimal linguistic phrases. The Journal of Neuroscience, 31(8), 2801-2814. https://doi.org/10.1523/JNEUROSCI.5003-10.2011 |
| [7] |
Cao, H., Gao, M., & Yan, H. (2016). Character decomposition and transposition processes in Chinese compound words modulates attentional blink. Frontiers in Psychology, 7, 923. https://doi.org/10.3389/fpsyg.2016.00923
doi: 10.3389/fpsyg.2016.00923 URL pmid: 27379003 |
| [8] | Chang, Y.-N., Welbourne, S., & Lee, C.-Y. (2016). Exploring orthographic neighborhood size effects in a computational model of Chinese character naming. Cognitive Psychology, 91, 1-23. https://doi.org/10.1016/j.cogpsych.2016.09.001 |
| [9] | Chen, L., Perfetti, C., Leng, Y., & Li, Y. (2018). Word superiority effect for native Chinese readers and low-proficiency Chinese learners. Applied Psycholinguistics, 39(6), 1097-1115. https://doi.org/10.1017/S0142716418000255 |
| [10] | Cui, L., Wang, J., Zhang, Y., Cong, F., Zhang, W., & Hyona, J. (2021). Compound word frequency modifies the effect of character frequency in reading Chinese. Quarterly Journal of Experimental Psychology, 74(4), 610-633. https://doi.org/10.1177/1747021820973661 |
| [11] | Cui, L., Zang, C., Xu, X., Zhang, W., Su, Y., & Liversedge, S. P. (2022). Predictability effects and parafoveal processing of compound words in natural Chinese reading. Quarterly Journal of Experimental Psychology, 75(1), 18-29. https://doi.org/10.1177/17470218211048193 |
| [12] | Dehaene, S. (2009). Reading in the brain: The science and evolution of a human invention. New York, NY: Penguin Press. https://api.semanticscholar.org/CorpusID:141548807 |
| [13] | Engbert, R., & Kliegl, R. (2011). Parallel graded attention models of reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), The Oxford handbook of eye movements. (pp.787-800). Oxford University Press. https://doi.org/10.1093/oxfordhb/9780199539789.001.0001 |
| [14] |
Flick, G., Oseki, Y., Kaczmarek, A. R., Al Kaabi, M., Marantz, A., & Pylkkänen, L. (2018). Building words and phrases in the left temporal lobe. Cortex, 106, 213-236. https://doi.org/10.1016/j.cortex.2018.06.004
doi: S0010-9452(18)30190-4 URL pmid: 30007863 |
| [15] |
Harm, M. W., & Seidenberg, M. S. (2004). Computing the meanings of words in reading: Cooperative division of labor between visual and phonological processes. Psychological Review, 111(3), 662-720. https://doi.org/10.1037/0033-295X.111.3.662
URL pmid: 15250780 |
| [16] | Hsiao, J. H., & Shillcock, R. (2004). Connectionist modelling of Chinese character pronunciation based on foveal splitting. In K. Forbus, D. Gentner, & T. Regier (Eds.), Proceedings of the Twenty-Sixth Annual Conference of the Cognitive Science Society (pp. 601-606). Mahwah, NJ: Lawrence Erlbaum Associates. |
| [17] | Hsiao, J. H., & Shillcock, R. (2005). Foveal splitting causes differential processing of Chinese orthography in the male and female brain. Brain Research. Cognitive Brain Research, 25(2), 531-536. https://doi.org/10.1016/j.cogbrainres.2005.08.005 |
| [18] | Hsu, C.-H., Pylkkänen, L., & Lee, C.-Y. (2019). Effects of morphological complexity in left temporal cortex: An MEG study of reading Chinese disyllabic words. Journal of Neurolinguistics, 49, 168-177. https://doi.org/10.1016/j.jneuroling.2018.06.004 |
| [19] | Huang, L., & Li, X. (2020). Early, but not overwhelming: The effect of prior context on segmenting overlapping ambiguous strings when reading Chinese. Quarterly Journal of Experimental Psychology, 73(9), 1382-1395. https://doi.org/10.1177/1747021820926012 |
| [20] | Huang, L., Staub, A., & Li, X. (2021). Prior context influences lexical competition when segmenting Chinese overlapping ambiguous strings. Journal of Memory and Language, 118, 104218. https://doi.org/10.1016/j.jml.2021.104218 |
| [21] | Inhoff, A. W., & Wu, C. (2005). Eye movements and the identification of spatially ambiguous words during Chinese sentence reading. Memory & Cognition, 33(8), 1345-1356. https://doi.org/10.3758/BF03193367 |
| [22] | Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104(2), 211-240. |
| [23] | Leck, K. J., Weekes, B. S., & Chen, M. J. (1995). Visual and phonological pathways to the lexicon: Evidence from Chinese readers. Memory & Cognition, 23(4), 468-476. https://doi.org/10.3758/bf03197248 |
| [24] | Li, X., Bicknell, K., Liu, P., Wei, W., & Rayner, K. (2014). Reading is fundamentally similar across disparate writing systems: A systematic characterization of how words and characters influence eye movements in Chinese reading. Journal of Experimental Psychology: General, 143(2), 895-913. https://doi.org/10.1037/a0033580 |
| [25] | Li, X., Gu, J., Liu, P., & Rayner, K. (2013). The advantage of word-based processing in Chinese reading: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(3), 879-889. https://doi.org/10.1037/a0030337 |
| [26] | Li, X., Huang, L., Yao, P., & Hyönä, J. (2022). Universal and specific reading mechanisms across different writing systems. Nature Reviews Psychology, 1(3), 133-144. https://doi.org/10.1038/s44159-022-00022-6 |
| [27] | Li, X., & Pollatsek, A. (2020). An integrated model of word processing and eye-movement control during Chinese reading. Psychological Review, 127(6), 1139-1162. https://doi.org/10.1037/rev0000248 |
| [28] |
Li, X., Rayner, K., & Cave, K. R. (2009). On the segmentation of Chinese words during reading. Cognitive Psychology, 58(4), 525-552. https://doi.org/10.1016/j.cogpsych.2009.02.003
doi: 10.1016/j.cogpsych.2009.02.003 URL pmid: 19345938 |
| [29] |
Ma, G., Li, X., & Rayner, K. (2014). Word segmentation of overlapping ambiguous strings during Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 40(3), 1046-1059. https://doi.org/10.1037/a0035389
doi: 10.1037/a0035389 URL pmid: 24417292 |
| [30] |
Ma, G., Li, X., & Rayner, K. (2015). Readers extract character frequency information from nonfixated-target word at long pretarget fixations during Chinese reading. Journal of Experimental Psychology: Human Perception and Performance, 41(5), 1409-1419. https://doi.org/10.1037/xhp0000072
doi: 10.1037/xhp0000072 URL pmid: 26168144 |
| [31] | McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: I. An account of basic findings. Psychological Review, 88(5), 375-407. https://doi.org/10.1037/0033-295X.88.5.375 |
| [32] | McCutchen, D., & Perfetti, C. A. (1982). The visual tongue- twister effect: Phonological activation in silent reading. Journal of Verbal Learning and Verbal Behavior, 21(6), 672-687. https://doi.org/10.1016/S0022-5371(82)90870-2 |
| [33] | Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems, 26, 3111-3119. |
| [34] | Peng, D. L., Liu, Y., & Wang, C. (1999). How is access representation organized? The relation of polymorphemic words and their morphemes in Chinese. In J. Wang, A. W. Inhoff, & H.-C. Chen (Eds.), Reading Chinese script: A cognitive analysis (pp. 65-89). Erlbaum. |
| [35] |
Perfetti, C. A., Liu, Y., & Tan, L. H. (2005). The lexical constituency model: Some implications of research on Chinese for general theories of reading. Psychological Review, 112(1), 43-59. https://doi.org/10.1037/0033-295X.112.1.43
URL pmid: 15631587 |
| [36] | Perfetti, C. A., & Zhang, S. (1995). Very early phonological activation in Chinese reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(1), 24-33. https://doi.org/10.1037/0278-7393.21.1.24 |
| [37] |
Plaut, D. C., McClelland, J. L., Seidenberg, M. S., & Patterson, K. (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103(1), 56-115. https://doi.org/10.1037/0033-295X.103.1.56
doi: 10.1037/0033-295x.103.1.56 URL pmid: 8650300 |
| [38] | Pylkkänen, L. (2020). Neural basis of basic composition: What we have learned from the red-boat studies and their extensions. Philosophical Transactions of the Royal Society B: Biological Sciences, 375(1791), 20190299. https://doi.org/10.1098/rstb.2019.0299 |
| [39] | Rayner, K., Li, X., Juhasz, B. J., & Yan, G. (2005). The effect of word predictability on the eye movements of Chinese readers. Psychonomic Bulletin & Review, 12(6), 1089-1093. https://doi.org/10.3758/BF03206448 |
| [40] | Rayner, K., Pollatsek, A., Ashby, J., & Clifton, C., Jr. (2011). Psychology of reading (2nd ed.). London, UK: Psychology Press. https://doi.org/10.4324/9780203155158 |
| [41] |
Reicher, G. M. (1969). Perceptual recognition as a function of meaningfulness of stimulus material. Journal of Experimental Psychology, 81(2), 275-280. https://doi.org/10.1037/h0027768
URL pmid: 5811803 |
| [42] | Reichle, E. D. (2021). Computational models of reading: A handbook. Oxford, UK: Oxford University Press. https://doi.org/10.1093/oso/9780195370669.001.0001 |
| [43] |
Reichle, E. D., Pollatsek, A., Fisher, D. L., & Rayner, K. (1998). Toward a model of eye movement control in reading. Psychological Review, 105(1), 125-157. https://doi.org/10.1037/0033-295x.105.1.125
URL pmid: 9450374 |
| [44] | Seidenberg, M. S. (2017). Language at the speed of sight: How we read, why so many can’t, and what can be done about it. New York: Basic Books. |
| [45] |
Seidenberg, M. S., & McClelland, J. L. (1989). A distributed, developmental model of word recognition and naming. Psychological Review, 96(4), 523-568. https://doi.org/10.1037/0033-295x.96.4.523
doi: 10.1037/0033-295x.96.4.523 URL pmid: 2798649 |
| [46] | Share, D. L. (2008). On the Anglocentricities of current reading research and practice: The perils of overreliance on an “outlier” orthography. Psychological Bulletin, 134(4), 584-615. |
| [47] | Shen, W., & Li, X. (2016). Processing and representation of ambiguous words in Chinese reading: Evidence from eye movements. Frontiers in Psychology, 7. https://doi.org/10.3389/fpsyg.2016.01713 |
| [48] | Shen, W., Li, X., & Pollatsek, A. (2018). The processing of Chinese compound words with ambiguous morphemes in sentence context. Quarterly Journal of Experimental Psychology, 71(1), 131-139. https://doi.org/10.1080/17470218.2016.1270975 |
| [49] | Taft, M., Huang, J., & Zhu, X. (1994). The influence of character frequency on word recognition responses in Chinese. In H. W. Chang, J. T. Hung, C. W. Hue, & O. Tzeng (Eds.), Advances in the study of Chinese language processing (pp. 59-73). Taipei: National Taiwan University. |
| [50] | Taft, M., & Nguyen-Hoan, M. (2010). A sticky stick? The locus of morphological representation in the lexicon. Language and Cognitive Processes, 25(2), 277-296. https://doi.org/10.1080/01690960903043261 |
| [51] | Taft, M., & Zhu, X. P. (1997). Submorphemic processing in reading Chinese. Journal of Experimental Psychology: Learning Memory and Cognition, 23(3), 761-775. https://doi.org/10.1037/0278-7393.23.3.761 |
| [52] | Taft, M., Zhu, X., & Peng, D. (1999). Positional specificity of radicals in Chinese character recognition. Journal of Memory and Language, 40(4), 498-519. https://doi.org/ 10.1006/jmla.1998.2625 |
| [53] | Tan, L. H., & Perfetti, C. A. (1997). Visual Chinese character recognition: Does phonological information mediate access to meaning? Journal of Memory and Language, 37(1), 41-57. https://doi.org/10.1006/jmla.1997.2508 |
| [54] | Tan, L. H., & Perfetti, C. A. (1998). Phonological codes as early sources of constraint in Chinese word identification:A review of current discoveries and theoretical accounts. In C. K. Leong & K. Tamaoka (Eds.), Cognitive processing of the Chinese and the Japanese languages (Vol. 14, pp. 11-46). Springer Netherlands. https://doi.org/10.1007/978-94-015-9161-4_2 |
| [55] | Tan, L. H., & Perfetti, C. A. (1999). Phonological activation in visual identification of Chinese two-character words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25(2), 382-393. |
| [56] | Tsang, Y.-K., & Chen, H.-C. (2013). Early morphological processing is sensitive to morphemic meanings: Evidence from processing ambiguous morphemes. Journal of Memory and Language, 68(3), 223-239. https://doi.org/10.1016/j.jml.2012.11.003 |
| [57] | Tsang, Y.-K., & Chen, H.-C. (2014). Activation of morphemic meanings in processing opaque words. Psychonomic Bulletin & Review, 21(5), 1281-1286. https://doi.org/10.3758/s13423-014-0589-2 |
| [58] | Tsang, Y.-K., Wong, A. W.-K., Huang, J., & Chen, H.-C. (2014). Morpho-orthographic and morpho-semantic processing in word recognition and production: Evidence from ambiguous morphemes. Language, Cognition and Neuroscience, 29(5), 543-560. https://doi.org/10.1080/01690965.2013.790554 |
| [59] | Tse, C.-S., & Yap, M. J. (2018). The role of lexical variables in the visual recognition of two-character Chinese compound words: A megastudy analysis. Quarterly Journal of Experimental Psychology, 71(9), 2022-2038. https://doi.org/10.1177/1747021817738965 |
| [60] | Van Orden, G. C., & Kloos, H. (2005). The question of phonology and reading. In M. J. Snowling, & C. Hulme (Eds.), The science of reading: A handbook. (pp.61-78). Blackwell Publishing. https://doi.org/10.1002/9780470757642.ch4 |
| [61] |
Westerlund, M., & Pylkkänen, L. (2014). The role of the left anterior temporal lobe in semantic composition vs. Semantic memory. Neuropsychologia, 57, 59-70. https://doi.org/10.1016/j.neuropsychologia.2014.03.001
doi: 10.1016/j.neuropsychologia.2014.03.001 URL pmid: 24631260 |
| [62] |
Wong, A. W.-K., Wu, Y., & Chen, H.-C. (2014). Limited role of phonology in reading Chinese two-character compounds: Evidence from an ERP study. Neuroscience, 256, 342-351. https://doi.org/10.1016/j.neuroscience.2013.10.035
URL pmid: 24505608 |
| [63] | Xing, H., Shu, H., & Li, P. (2002). A self-organizing connectionist model of character acquisition in Chinese. In W. D. Gray & C. D. Schunn (Eds.), Proceedings of the twenty-fourth annual conference of the cognitive science society (pp. 950-955). Mahwah, NJ: Lawrence Erlbaum. https://doi.org/10.4324/9781315782379-198 |
| [64] | Xing, H., Shu, H., & Li, P. (2004). The acquisition of Chinese characters: Corpus analyses and connectionist simulations. Journal of Cognitive Science, 5(1), 1-49. |
| [65] | Xiong, J., Yu, L., Veldre, A., Reichle, E. D., & Andrews, S. (2023). A multitask comparison of word- and character- frequency effects in Chinese reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 49(5), 793-811. https://doi.org/10.1037/xlm0001192 |
| [66] | Yan, G., Tian, H., Bai, X., & Rayner, K. (2006). The effect of word and character frequency on the eye movements of Chinese readers. British Journal of Psychology, 97(2), 259-268. https://doi.org/10.1348/000712605X70066 |
| [67] | Yan, M., Richter, E. M., Shu, H., & Kliegl, R. (2009). Readers of Chinese extract semantic information from parafoveal words. Psychonomic Bulletin & Review, 16(3), 561-566. https://doi.org/10.3758/pbr.16.3.561 |
| [68] | Yang, J. F., McCandliss, B. D., Shu, H., & Zevin, J. D. (2009). Simulating language-specific and language- general effects in a statistical learning model of Chinese reading. Journal of Memory and Language, 61(2), 238-257. https://doi.org/10.1016/j.jml.2009.05.001 |
| [69] | Yang, J. F., Shu, H., McCandliss, B. D., & Zevin, J. D. (2013). Orthographic influences on division of labor in learning to read Chinese and English: Insights from computational modeling. Bilingualism: Language and Cognition, 16(2), 354-366. https://doi.org/10.1017/S1366728912000296 |
| [70] | Yang, J. F., Zevin, J. D., Shu, H., McCandliss, B. D., & Li, P. (2006). A “triangle model” of Chinese reading. In R. Sun (Ed.), Proceedings of the twenty eighth annual conference of the cognitive science society (pp. 912-917). Erlbaum. |
| [71] | Yang, J. M., Staub, A., Li, N., Wang, S., & Rayner, K. (2012). Plausibility effects when reading one- and two-character words in Chinese: Evidence from eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 38(6), 1801-1809. https://doi.org/10.1037/a0028478 |
| [72] | Yao, P., Alkhammash, R., & Li, X. (2022). Plausibility and syntactic reanalysis in processing novel noun-noun combinations during Chinese reading: Evidence from native and non-native speakers. Scientific Studies of Reading, 26(5), 390-408. https://doi.org/10.1080/10888438.2021.2020796 |
| [73] | Yao, P., Staub, A., & Li, X. (2022). Predictability eliminates neighborhood effects during Chinese sentence reading. Psychonomic Bulletin & Review, 29(1), 243-252. https://doi.org/10.3758/s13423-021-01966-1 |
| [74] | Yu, L., Cutter, M. G., Yan, G., Bai, X., Fu, Y., Drieghe, D., & Liversedge, S. P. (2016). Word n + 2 preview effects in three-character Chinese idioms and phrases. Language, Cognition and Neuroscience, 31(9), 1130-1149. https://doi.org/10.1080/23273798.2016.1197954 |
| [75] | Yu, L., Liu, Y., & Reichle, E. D. (2021). A corpus-based versus experimental examination of word- and character- frequency effects in Chinese reading: Theoretical implications for models of reading. Journal of Experimental Psychology: General, 150(8), 1612-1641. https://doi.org/10.1037/xge0001014 |
| [76] | Zang, C. (2019). New perspectives on serialism and parallelism in oculomotor control during reading: The multi-constituent unit hypothesis. Vision, 3(4), 50. https://doi.org/10.3390/vision3040050 |
| [77] | Zhang, H., Su, I.-F., Chen, F., Ng, M. L., Wang, L., & Yan, N. (2020). The time course of orthographic and semantic activation in Chinese character recognition: Evidence from an ERP study. Language, Cognition and Neuroscience, 35(3), 292-309. https://doi.org/10.1080/23273798.2019.1652762 |
| [78] | Zhang, S., & Perfetti, C. A. (1993). The tongue-twister effect in reading Chinese. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(5), 1082-1093. https://doi.org/10.1037/0278-7393.19.5.1082 |
| [79] | Zhou, J., & Li, X. (2021). On the segmentation of Chinese incremental words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 47(8), 1353-1368. https://doi.org/10.1037/xlm0000984 |
| [80] | Zhou, W., Shu, H., Miller, K., & Yan, M. (2018). Reliance on orthography and phonology in reading of Chinese: A developmental study. Journal of Research in Reading, 41(2), 370-391. https://doi.org/10.1111/1467-9817.12111 |
| [81] | Zhou, X., & Marslen-Wilson, W. (2000). The relative time course of semantic and phonological activation in reading Chinese. Journal of Experimental Psychology: Learning Memory and Cognition, 26(5), 1245-1265. https://doi.org/10.1037//0278-7393.26.5.1245 |
| [82] | Zhou, X., Marslen-Wilson, W., Taft, M., & Shu, H. (1999). Morphology, orthography, and phonology reading Chinese compound words. Language and Cognitive Processes, 14(5-6), 525-565. https://doi.org/10.1080/016909699386185 |
| [83] | Zhou, X., Ye, Z., Cheung, H., & Chen, H.-C. (2009). Processing the Chinese language: An introduction. Language and Cognitive Processes, 24(7-8), 929-946. https://doi.org/10.1080/01690960903201281 |
| [1] | 温秀娟, 马毓璟, 谭斯祺, 李芸, 刘文华. 身体还是认知努力的损害?抑郁症努力奖赏动机评估及计算模型应用[J]. 心理科学进展, 2025, 33(1): 107-122. |
| [2] | 张向阳, 王小娟, 杨剑峰. 左侧角回在词汇语义加工中的作用[J]. 心理科学进展, 2024, 32(4): 616-626. |
| [3] | 郭鸣谦, 潘晚坷, 胡传鹏. 认知建模中模型比较的方法[J]. 心理科学进展, 2024, 32(10): 1736-1756. |
| [4] | 韩宜瑾, 朱金丽, 侯方. 弱视视觉系统的对比度增益研究[J]. 心理科学进展, 2023, 31(suppl.): 4-4. |
| [5] | 黎穗卿, 陈新玲, 翟瑜竹, 张怡洁, 章植鑫, 封春亮. 人际互动中社会学习的计算神经机制[J]. 心理科学进展, 2021, 29(4): 677-696. |
| [6] | 高青林, 周媛. 计算模型视角下信任形成的心理和神经机制——基于信任博弈中投资者的角度[J]. 心理科学进展, 2021, 29(1): 178-189. |
| [7] | 张银花, 李红, 吴寅. 计算模型在道德认知研究中的应用[J]. 心理科学进展, 2020, 28(7): 1042-1055. |
| [8] | 张慢慢, 臧传丽, 白学军. 中文阅读中副中央凹预加工的范围与程度[J]. 心理科学进展, 2020, 28(6): 871-882. |
| [9] | 李精精, 张剑, 田慧荣, Jeffrey B.Vancouver. 动态计算模型在组织行为学研究中的应用[J]. 心理科学进展, 2020, 28(2): 368-380. |
| [10] | 区健新, 吴寅, 刘金婷, 李红. 计算精神病学:抑郁症研究和临床应用的新视角[J]. 心理科学进展, 2020, 28(1): 111-127. |
| [11] | 高绍兵, 李永杰. 结合视觉自底向上和自顶向下机制的多光源颜色恒常性算法研究[J]. 心理科学进展, 2019, 27(suppl.): 96-96. |
| [12] | 臧传丽, 鹿子佳, 张志超. 语义和句法信息在副中央凹加工中的作用[J]. 心理科学进展, 2019, 27(1): 11-19. |
| [13] | 杨剑峰, 党敏, 张瑞, 王小娟. 汉字阅读的语义神经回路及其与语音回路的协作机制[J]. 心理科学进展, 2018, 26(3): 381-390. |
| [14] | 李玉刚;黄忍;滑慧敏;李兴珊. 阅读中的眼跳目标选择问题[J]. 心理科学进展, 2017, 25(3): 404-412. |
| [15] | 李松清;赵庆柏;周治金;张依. 多媒体学习中图文加工的认知神经机制[J]. 心理科学进展, 2015, 23(8): 1361-1370. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||