

1 问题提出
小学语文教学实践中识字和写字是两项基本任务, 汉字的正确读写是儿童阅读和写作的基础。小学低年级段是儿童识字和写字的重要时期, 识字如汉字识别是输入过程, 写字如听写是输出过程, 二者有着不同的加工过程(Verhoeven & Carlisle, 2006)。
已有研究认为在阅读中存在马太效应(Bast & Reitsma, 1998; Stanovich, 1986), 即起始水平高的学生后期的发展速度也快。因此很多学前教育机构有意识地教授儿童识字、写字, 秉承着“不让儿童输在起跑线上”的观点, 存在幼儿教育小学化的倾向(孙淼鑫, 2018), 这一现状充分体现了马太效应在实践中的影响。同时, 英语、瑞典语和德语的实证研究也发现阅读能力起始水平高的儿童, 其后期发展速度更快, 阅读成绩的差异随时间发展而增大, 出现了强者越强的马太效应(Carreker et al., 2007; Kempe, Eriksson-Gustavsson, & Samuelsson, 2011; Pfost, Dörfler, & Artelt, 2012)。然而, 另一种观点认为阅读中存在补偿效应(Walczyk & Griffith-Ross, 2007), 即起始水平低的学生后期发展速度更快。英语研究(Rasinski, 2017)发现起始水平低的儿童通过教育、教学的引导和练习, 后期阅读能力(如解码、阅读流畅等)的发展速度更快。这两种不同的观点刻画了儿童发展的不同轨迹, 那么汉语儿童汉字识别和听写的发展究竟是哪一种效应, 是一个值得探讨的问题。对这一问题的澄清有助于全面掌握儿童的读写现状, 为实践教学提供数据支持。
尽管字词识别和听写有着不同的加工过程(Verhoeven & Carlisle, 2006), 但二者均存在语素分解。语素分解理论(Verhoeven & Perfetti, 2003)认为在心理词典中存在语素的表征, 字词的识别和提取过程中存在对组成字词的最小语义单元——语素的分解加工, 语素分解有助于提高字词识别和提取能力的发展。字词识别是根据字形提取语音和语义(Ehri, 2000), 阅读者分解字词中的语素, 进而感知字词形式和意义之间的关系, 语义越透明语素分解效果越好(Verhoeven & Perfetti, 2011)。听写是由语音、语义刺激提取字形的过程(张大成, 张厚粲, 周晓林, 舒华, 1999)。Venezky (1999)指出听写结合了声音和意义, 是一个由声音到意义的理解过程, 这一加工过程聚焦于语义或者是和词根、派生语素有关的意义部分。听写中语素及语素结构的分解加工(Verhoeven & Perfetti, 2003)促进了正确字形的输出。由上述可以看出无论是字词识别还是听写, 均显示语素在字词加工过程中的重要作用。
另外, 汉语特点也决定了语义在汉字加工中的重要性。首先, 汉语是表意文字, 遵循据义构形的构字原则。汉字由象形字起源, 表征语义而不是语音, 汉字字形结构与汉字所表达的意义密切相关。其次, 汉语是语素音节(morphosyllabic)语言, 汉语的语素和音节是对应关系, 通常一个音节对应一个语素。由于汉语一音节一语素的特点, 为了表达更多的事物和意义, 语素与语素之间就通过一定的规则组合成复合词, 复合词在汉语中是主要的词的形式。语素是最小的语义单元, 对语素的感知和操作以及运用语素组合规则去理解复杂语素字词的能力即语素意识(Carlisle, 2010), 是如何影响汉字识别和听写发展的还尚不清楚。
无论拼音文字(Apel & Lawrence, 2011; Deacon, Wade-Woolley, & Kirby, 2007; Roman, Kirby, Parrila, Wade-Woolley, & Deacon, 2009)还是汉语研究(Wu et al., 2009; McBride-Chang, Shu, Zhou, Wat, & Wagner, 2003; Shu, McBride-Chang, Wu, & Liu, 2006)均发现语素意识对某个时间点上的字词识别具有重要影响作用, 支持了语素分解理论(Verhoeven & Perfetti, 2003)。例如, Apel和Lawrence (2011)调查了一年级英语儿童, 发现语素意识预测了阅读正常儿童的字词识别能力; Shu等人(2006)研究也表明语素意识是汉语儿童字词识别的强有力的预测因子, 预测的路径系数高达0.51。然而这些研究更多地是探讨共时性历程中或前后时间点变量之间的预测作用, 较少探讨对变量发展轨迹的预测。有研究者(McMaster, Fuchs, Fuchs, & Compton, 2005)认为对儿童语言能力的评估不仅依据某个时间点上的水平, 而且还要考虑儿童的发展速度, 对儿童语言能力发展轨迹的动态考察比水平的静态考察更具有实践意义。小学低段是儿童字词学习的重要时期, 研究(董琼, 李虹, 伍新春, 饶夏溦, 朱瑾, 2014)表明, 汉语儿童从学前开始汉字识别能力随年龄发展有明显的提升。最近, 对177名一年级汉语儿童每隔半年进行一次共3次测试的追踪研究(回懿 等, 2018)发现复合语素意识显著预测了汉字识别的起始水平, 但并没显著预测后期的发展速度。
语素意识不仅影响汉字识别, 而且对听写也具有显著的影响作用。大量的拼音文字研究发现语素意识和听写关系密切(Good, Lance, & Rainey, 2015; Green et al., 2003; Kemp, 2006; Nagy, Berninger, Abbott, Vaughan, & Vermeulen, 2003)。例如, Apel, Wilson-Fowler, Brimo和Perrin (2012)的横断研究考察了美国88名一年级儿童, 结果发现语素意识显著预测了语音障碍儿童和正常儿童的听写测验成绩。对加拿大115名英语儿童的追踪研究(Deacon, Kirby, & Casselman-Bell, 2009)显示在控制了IQ、快速命名、短时记忆和语音意识后, 语素意识预测了两年后的拼写成绩。Pittas和Nunes (2014)利用横断和追踪相结合的方法对希腊儿童进行了测量, 发现在控制IQ和语音意识后一年级的语素意识没有预测一年级的听写成绩, 但在追踪中一年级的语素意识预测了8个月后的听写。此外, 汉语听写的横断研究(李利平, 伍新春, 熊翠燕, 程亚华, 阮氏芳, 2016)显示在整个小学阶段语素意识均对儿童听写有显著影响, 控制了一般认知能力、口语词汇、语音意识、正字法意识和快速命名后, 语素意识分别解释了低、中、高年级段听写的15%、7%、3%的变异。已有对汉语听写的研究(李利平等, 2016; 宁宁等, 2017; Tong, McBride-Chang, Shu, & Wong, 2009)多为水平分析, 无论是李利平等人的整个小学阶段的横断研究、宁宁等人的听写困难儿童的实验研究, 还是Tong等人的错误分析, 均探讨了在某个时间点或某一水平上儿童的听写能力。上述拼音文字研究和汉语研究均探讨的是语素意识对听写发展水平的影响, 较少考察对听写发展速度的预测。
综上, 研究表明了语素意识对某个时间点的汉字识别和听写的影响作用, 但语素意识对二者发展轨迹的预测比对共时性的预测更具有实践意义。因此本研究欲探讨两个问题:第一, 汉字识别和听写的发展轨迹是怎样的; 第二, 语素意识对汉字识别和听写二者发展轨迹的影响作用是什么。鉴于拼音文字的实证研究结果(Carreker et al., 2007; Kempe et al., 2011; Pfost et al., 2012), 因此本研究提出假设1:汉字识别和听写的发展呈现马太效应; 同时, 基于语素分解理论中语素分解促进读写能力的发展(Verhoeven & Perfetti, 2003)及语素意识对汉语儿童读写发展的重要性(李利平 等, 2016; McBride- Chang et al, 2003; Tong et al, 2009), 本研究提出假设2:语素意识影响汉字识别和听写的发展轨迹。此外, 已有研究(Apel & Lawrence, 2011; 李虹, 饶夏溦, 董琼, 朱瑾, 伍新春, 2011; Shu et al., 2006; Tong et al., 2009)认为一般认知能力、语音意识、正字法意识影响儿童的读写, 因此三者在本研究中作为控制变量进行操作。
2 方法
2.1 被试
采用整群取样的方式, 选择山西省临汾市两所小学一年级共149人作为追踪对象, 男生80人, 女生69人。有22名学生流失, 流失率约15%, 因此将最后一次的127人作为最终研究对象。统计分析显示, 流失的被试和最终保留的被试在年龄[t(147) = -0.49, p = 0.63]、一般认知能力[t(147) = 0.52, p = 0.61]、性别[χ2(1) = 0.02, p = 0.88]上没有显著差异。根据语文教师的反馈, 此样本里没有语言障碍者或阅读困难的学生。
两所学校均以普通话作为授课语言。在一年级入学初, 两所学校的儿童均集中学习两个月的拼音, 以便辅助后期的汉字学习。两个学校的课堂教学方法较为传统, 在教授汉字时均为教师一笔一划在黑板上书写学生模仿进行, 然后布置家庭作业让学生进行汉字笔画分析、练习书写以便掌握汉字。
2.2 测验工具
2.2.1 语素意识
同音语素意识
考察儿童对汉语一音多字的理解和掌握程度, 采用已有的产生式任务测验(李虹 等, 2011)。口头呈现一个目标词, 例如请用月亮的“月”组词, 儿童的反应可能是“月光、月球”, 以保证学生知道是哪个“yuè”字; 接下来问儿童还有没有其他字也读“yuè”, 儿童的反应可能是“音乐”、“阅读”, 产生的多音字越多越好。共2个练习和12个题目, 儿童正确产生一个多音字计1分, 本测验为个别施测。测验的α系数为0.90。
复合语素意识
采用已有测验(Li & Wu, 2015), 考察儿童对汉语复合词中语素及语素关系的认识和操作能力, 共有8个练习和20个题目。题目分为两组:第一组问题的答案由两个语素组成, 共12个题目, 答案为3级评分2、1、0; 第二组问题的答案由3个语素组成, 共8个题目, 答案为4级评分3、2、1、0。例如:形状像耳朵的果子叫什么呢? (2分:耳果; 1分:耳朵果; 0分:使用了无关语素, 与整句意思的相关性不高)。此测验采用个别施测。该测验的α系数为0.88。
2.2.2 汉字识别
汉字识别采用已有测验(Li, Shu, McBride- Chang, Liu, & Peng, 2012), 共150个汉字, 按照难度依次增加的顺序排列。每15个汉字一组, 共10组, 在A4纸上呈现出来, 请学生按从左到右、从上到下的顺序阅读, 连续10个错误或不会即停止。每读正确一个计1分, 最高150分。本测验为个别施测。已有研究(Li et al., 2012)报告α系数为0.99, 是一项信度较好的测验。
2.2.3 听写
要求学生听写双字词中的某一个字, 例如:请写出中国的“中”。当学生不会写时就在答题纸上画圈。共1个练习和24个项目, 儿童正确听写一个计1分, 共24分, 集体施测。4次测验的内部一致性α系数分别为0.75、0.70、0.74、0.69。
2.2.4 一般认知能力
采用瑞文标准推理测验(张厚粲, 王晓平, 1989)对儿童的非言语智力进行测查。该测验包含60个项目, 正确判断一个计1分, 共60分。每个项目包括1个目标图和多个选项, 请儿童在选项中选择合适的一项使得目标图完整。集体施测, 测验的α系数为0.93。
2.2.5 语音意识
采用已有研究(Shu et al., 2006)中的音位删除任务, 考察儿童对声母、韵母等语音单位的认识和操作能力。题目分为3组:删除音节前面的发音、中间的发音、后面的发音, 各4个题目。例如:叉(chā), 不说开头的“ch”, 还剩什么?答案是“ā”。共6个练习和12个题目, 儿童正确回答一个计1分, 共12分, 个别施测。测验的α系数为0.70。
2.2.6 正字法意识
本测验采用已有测验(Li & Wu, 2015), 主要考察儿童对汉字结构的认识, 测验由4种构字方式组成:位置错误、部件错误、笔画乱写、假字。4种构字方式的项目数分别是:15、15、15、45, 共90个项目。位置错误指组成目标字的部件是正确的, 但是部件的位置不正确, 如“ 
目标字的部件本身在真实的汉字中是不存在的, 如“ 
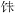

2.3 研究程序
第一次测验在一年级儿童秋季入学的两个月后进行, 之后每隔半年追踪一次, 共追踪4次。听写、一般认知能力和正字法意识为集体施测, 其余为个别施测。个别施测过程是主试口头询问儿童, 儿童口头作答, 主试记录下儿童的反应。主试为经过严格培训的某师范院校的教育学或心理学的本科生和研究生。为了确保施测过程的标准化, 在主试培训过程中询问方式、计分方式及如何与儿童顺利交流等方面都进行了详细说明并模拟训练。
2.4 数据分析
采用Mplus软件分别对4个时间点的汉字识别和听写采用潜变量增长模型(Latent Growth Model)进行分析, 潜变量增长模型的主要长处是利用一个发展的模型来精确地对增长进行建模。127名被试的数据缺失程度低, 其中有5名被试在一般认知能力测验上有缺失, 相关分析中采用了对删法的处理方式, 有条件的潜变量增长模型中使用了极大似然估计法处理。
首先, 考察汉字识别或听写的无条件潜变量增长模型, 并且同时考察起始水平是否和发展速度有关。无条件潜变量增长模型需要估计模型的截距和斜率两个参数(刘红云, 张雷, 2005)。以汉字识别为例, 第一层水平模型的方程为汉字识别Rit = αi + βiλt + εit, 其中汉字识别Rit为被试i在时间t的观测分数, αi为被试i的截距(起始水平), βi为被试i的斜率(发展速度), λt为时间分数, εit为被试i在时间t上的残差。第二层水平的模型中, 将截距和斜率视为因变量, 方程为αi = μα + ξαi; βi = μβ + ξβi。其中μα为截距的均值, μβ为斜率的均值, ξαi和ξβi分别为被试i截距和斜率的残差。图1是线性发展的无条件潜变量增长的理论模型, 本研究分两步进行, 第一步进行线性模型的拟合, 如果线性发展的理论模型不拟合, 则第二步尝试让模型自由估计发展轨迹。在自由估计时, 第一、二时间点斜率的载荷分别为“0”和“1”, 第三、四时间点斜率的载荷为自由估计(刘红云, 张雷, 2005; Meredith & Tisak, 1990; 王孟成, 毕向阳, 2018)。
图1
其次, 通过对无条件模型的第二个水平纳入一般认知能力、语音意识、正字法意识、同音语素意识和复合语素意识, 这5个变量均为第一时间点时测得, 建构有条件潜变量增长模型。一般认知能力、语音意识、正字法意识三者作为控制变量, 同音语素意识和复合语素意识作为预测变量, 来考察语素意识是否是造成汉字识别或听写的起始水平和发展速度出现个体差异的原因。在有条件潜变量增长模型中, 各预测变量之间两两相关。图2为汉字识别或听写的有条件潜变量增长的理论模型。
图2

3 结果
3.1 各变量的描述统计
表1显示了各变量的描述统计。随着时间的发展变化, 儿童的汉字识别和听写均有了显著的发展。重复测量方差分析显示汉字识别F(3,378) = 748.12, p < 0.001, 偏η2 = 0.86, 听写F(3,378) = 1854.08, p < 0.001, 偏η2 = 0.94, 二者的时间主效应显著。
表1 各变量的描述统计
| 变量 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | M ± SD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1一般认知能力T1 | 28.06 ± 9.18 | ||||||||||||
| 2语音意识T1 | 0.17* | 6.79 ± 3.81 | |||||||||||
| 3正字法意识T1 | 0.31** | 0.11 | 25.80 ± 8.74 | ||||||||||
| 4同音语素意识T1 | 0.02 | 0.12 | 0.02 | 6.79 ± 3.81 | |||||||||
| 5复合语素意识T1 | 0.23** | 0.14 | 0.12 | 0.33** | 9.57 ± 8.97 | ||||||||
| 6汉字识别T1 | 0.26** | 0.11 | 0.45*** | 0.12 | 0.30** | 25.99 ± 22.45 | |||||||
| 7汉字识别T2 | 0.30** | 0.18* | 0.37*** | 0.20* | 0.30** | 0.88*** | 43.90 ± 23.87 | ||||||
| 8汉字识别T3 | 0.22* | 0.20* | 0.28** | 0.24** | 0.29** | 0.79*** | 0.87*** | 60.63 ± 23.39 | |||||
| 9汉字识别T4 | 0.28** | 0.18* | 0.29** | 0.27** | 0.31** | 0.73*** | 0.82*** | 0.92*** | 78.16 ± 22.31 | ||||
| 10听写T1 | 0.07 | 0.23** | 0.02 | 0.04 | 0.06 | 0.32*** | 0.32*** | 0.25** | 0.25** | 6.10 ± 2.41 | |||
| 11听写T2 | 0.14 | 0.15 | 0.11 | 0.09 | 0.13 | 0.24** | 0.29*** | 0.31*** | 0.36*** | 0.26** | 14.31 ± 1.37 | ||
| 12听写T3 | 0.05 | 0.18* | 0.15 | 0.22* | 0.18* | 0.36*** | 0.41*** | 0.47*** | 0.44*** | 0.32** | 0.33** | 17.00 ± 1.78 | |
| 13听写T4 | 0.06 | 0.22* | 0.06 | 0.05 | 0.02 | 0.23** | 0.25** | 0.30** | 0.22* | 0.25** | 0.29** | 0.24** | 20.65 ± 1.88 |
注:T1第一时间点; T2第二时间点; T3第三时间点; T4第四时间点; *** p<0.001; ** p<0.01; * p <0.05。
3.2 汉字识别和听写的无条件潜变量增长模型
表2呈现了汉字识别和听写的无条件潜变量增长模型的分析结果。经检验, 汉字识别在4个时间点上斜率的路径系数分别为:0、1、2、3, 呈线性增长趋势, 模型拟合指数良好, 分别为:χ2(df = 5) = 9.95, p = 0.08, CFI = 0.99, TLI = 0.99, RMSEA = 0.08 (90% CI = 0.00~0.16), SRMR = 0.05。汉字识别的无条件潜变量增长模型中, 截距和斜率的平均数均达到了统计显著, 分别为26.02, p < 0.001; 17.51, p < 0.001, 说明儿童汉字识别的起始水平和增长速度都显著大于0, 儿童在入学初已经掌握了一定量的汉字, 并且后期儿童的汉字识别有了较大发展。此外, 截距和斜率的方差也达到统计显著, 分别为488.91, p < 0.001; 26.76, p < 0.001, 说明汉字识别在起始水平和发展速度上均具有显著的个体差异。汉字识别的起始水平和发展速度二者相关系数为-0.33 (p < 0.001), 呈现显著的负相关, 说明起始水平越低的儿童后期的发展速度越快, 汉字识别的起始水平和发展速度呈现补偿效应。
表2 汉字识别和听写的无条件潜变量增长模型的分析结果
| 变量 | 截距 | 斜率 | 水平和增长率的协方差 | ||
|---|---|---|---|---|---|
| 平均数(标准误) | 方差(标准误) | 平均数(标准误) | 方差(标准误) | 标准化系数 | |
| 汉字识别 | 26.02***(1.87) | 488.91***(62.94) | 17.51***(0.47) | 26.76***(3.73) | -0.33*** |
| 听写 | 6.10***(0.20) | 2.16(1.66) | 8.21*** (0.20) | 0.26(0.78) | -0.89** |
注:*** p < 0.001; ** p < 0.01。
经检验, 在4个时间点上听写的线性模型不正定, 表明听写的数据不拟合线性发展趋势, 因此尝试不定义曲线类型的潜变量增长模型(刘红云, 张雷, 2005; Meredith & Tisak, 1990; 王孟成, 毕向阳, 2018)。对听写发展模型中斜率的第三、四条路径进行自由估计, 得出斜率的4个路径系数分别为:0、1、1.33、1.77, 呈现非线性的发展趋势, 这时模型拟合指数不理想。根据修正指数和变量间的相关关系, 在模型中使得第一次和第二次听写相关, 第二次和第三次听写相关, 修正后的模型拟合指数为:χ2(df = 1) = 0.27, p = 0.60, CFI = 0.98, TLI = 0.99, RMSEA = 0.01 (90% CI = 0.00~0.17), SRMR = 0.02, 此模型定为最终模型。听写的无条件潜变量增长模型中, 截距和斜率的平均数均达到了统计显著, 分别为6.10, p < 0.001; 8.21, p < 0.001, 说明儿童听写的起始水平和发展速度都显著不等于0, 儿童在入学初已经会写一些汉字, 且随后的听写有显著发展。此外, 截距和斜率的方差没有达到统计显著, 分别是2.16, p = 0.19; 0.26, p = 0.74, 说明儿童在听写的起始水平和发展速度上不存在显著的个体差异。听写起始水平和发展速度二者相关系数为-0.89, p = 0.002, 呈现显著的负相关, 表明儿童听写的起始水平越低后期的发展速度越快, 起始水平和发展速度呈现补偿效应。
3.3 语素意识对汉字识别和听写发展的预测作用
汉字识别的有条件潜变量增长模型拟合较好, χ2(df = 15) = 26.94, p = 0.03, CFI = 0.98, TLI = 0.97, RMSEA = 0.07 (90% CI = 0.02~0.12), SRMR = 0.03。表3呈现了各预测变量对汉字识别起始水平和发展速度的预测作用。结果显示, 第一时间点的同音语素意识和复合语素意识显著预测了汉字识别的起始水平和发展速度。
表3 各预测变量对汉字识别和听写的起始水平和发展速度的预测作用
| 预测变量 | 截距 | 斜率 | ||
|---|---|---|---|---|
| β | SE | β | SE | |
| 一般认知能力T1 | 0.14/0.11 | 0.08/0.13 | 0.14†/0.21 | 0.08/0.41 |
| 语音意识T1 | 0.10/0.03 | 0.09/0.14 | 0.17*/0.04 | 0.09/0.29 |
| 正字法意识T1 | 0.05/0.22 | 0.12/-0.13 | 0.09/0.32 | |
| 同音语素意识T1 | 0.40***/0.01 | 0.07/0.12 | 0.28***/0.19 | 0.08/0.41 |
| 复合语素意识T1 | 0.14*/0.06 | 0.06/0.10 | 0.25***/0.06 | 0.07/0.26 |
注:T1:第一时间点; *** p < 0.001; * p < 0.05; † p < 0.10。斜杠之前为汉字识别的系数, 斜杠之后为听写的系数。
听写的有条件潜变量增长模型拟合较好, χ2(df = 13) = 13.92, p = 0.38, CFI = 0.98, TLI = 0.96, RMSEA = 0.02 (90% CI = 0.00~0.09), SRMR = 0.05。从表3可以看出, 第一时间点的同音语素意识和复合语素意识没有显著预测听写的起始水平和发展速度。
4 讨论
4.1 汉字识别和听写的发展轨迹不同, 二者均存在补偿效应
研究结果显示了一、二年级儿童的汉字识别为线性发展趋势, 这与已有3个时间点的追踪结果(回懿 等, 2018)一致。教学要求可能是汉字识别线性增长的原因之一。根据小学语文(人教版)的汉字识别要求, 4个时间点分别要求学生会认400、550、450、400个汉字, 可见识字量的增长约在400到500之间, 基本是以相同的速度在发展。但是, 听写的无条件潜变量增长模型表明听写是非线性发展的趋势。4个时间点在斜率上的路径系数分别为0、1、1.33、1.77, 可以看出第一到第二时间点的发展速度较快, 第二到第三时间点的发展速度和第三到第四时间点的发展速度相当, 呈现一种先快后慢的趋势。这一发展趋势可能和儿童在一、二年级所学的汉字特点及学习特点有关。在一年级儿童写的能力发生了从无到有的质的转变, 前两个时间点为一年级, 这一时期主要掌握独体字, 一方面独体字较为简单, 适合儿童利用机械记忆高效掌握, 另一方面字词的掌握是这一时期的重要教学任务。基于上述两点, 儿童在前两个时间点的听写能力发展较快。而从二年级开始儿童学到的合体字增多, 合体字笔画相对多、构形复杂, 掌握起来相对困难, 儿童需要付出比独体字更大的努力来学习。加之这一时期儿童不仅学习字词而且开始诵读简短的文本, 增加了文本学习任务, 这就使得后两个时间点的听写能力发展速度比一年级初时的发展速度慢。此外, 汉字识别和听写二者发展轨迹的不同可能是因为二者不同的加工机制所致(Verhoeven & Carlisle, 2006)。汉字识别是由字形刺激提取语音和语义的过程(Ehri, 2000; Verhoeven & Perfetti, 2011), 而听写是由语音、语义的刺激提取字形的过程(张大成 等, 1999)。相对而言, 汉字识别任务比听写任务简单, 因此二者的发展轨迹不同。
同时, 本研究结果也显示了汉字识别和听写的起始水平和发展速度都存在显著的负相关, 支持了汉字识别和听写发展的补偿效应(Walczyk & Griffith-Ross, 2007)而非马太效应(Bast & Reitsma, 1998; Stanovich, 1986)。补偿效应显示了个体差异随着儿童的发展呈缩小趋势, 说明起始水平低的儿童后期发展速度较快。这一发现与已有研究结果(Carreker et al., 2007; Kempe et al., 2011; Pfost et al., 2012)并不一致, 这可能和语言特征有关。Carreker、Kempe、Pfost等的研究是以拼音文字的儿童为研究对象, 相对汉语而言, 拼音文字具有形-音对应规则, 在起始点时一旦掌握规则就有利于在后期字词学习中运用, 而汉语的透明度相对较低, 儿童在字词学习中所能运用的规则较少, 后期的字词学习与前期已学的字词关系较远, 就造成了起始点水平并不促进后期发展的速度。本研究在字词的读写上没有支持人们经验中“不能让儿童输在起跑线上”的观点。这可能是因为:第一, 语言技能不同层面的高低限制程度不同, 字词的读写属高限制技能(Paris, 2005), 因字词的范围、数量有限, 儿童可以在短时间内掌握, 起点低的儿童后期的提升速度快, 而起点高的儿童后期提升空间较小, 在字词读写技能方面个体间差异随时间会不断缩小。第二, 学校教育环境和资源加速了起始点读写落后儿童的学习和成长。已有研究(张启睿, 边玉芳, 王烨晖, 苑春勇, 2012)发现学校教育环境和资源是学生学业成就的重要预测变量。起始点落后的儿童在接受了学校教育后, 潜在的学习能力得到开发和发展, 进而学习技能得到迅速提升。第三, 起始点落后的儿童虽然在客观知识的掌握上初始水平较低, 但他们在非认知因素上可能准备较好, 如他们比起始水平高的儿童有更强的学习动机、更浓的学习兴趣, 在同伴关系、生活习惯上处理较好, 能快速适应小学生活方式(马健生, 陈元龙, 2019), 这些非认知因素促进了后期学业的快速发展。
4.2 语素意识对汉字识别和听写发展的影响作用不同
有条件的潜变量增长模型显示了儿童初始的同音语素意识和复合语素意识促进了汉字识别的起始水平和后期的发展速度, 这和已有横断研究结果(Apel & Lawrence, 2011; Shu et al., 2006)一致, 说明语素意识不仅在共时性中解释了某个时间点的汉字识别, 而且在历时性中也促进了汉字识别后期发展速度。如果儿童具有较好的同音语素意识, 能更好地分辨相同发音字词的不同意义, 在心理词典中就能更加高效地表征字词的语音和语义(Perfetti, 2007), 这种高效的字词表征促进了汉字识别能力的发展。随着儿童字词经验的增加, 他们会把字放在词的背景下进行学习, 以便更好地理解字义。复合词为儿童理解字义提供了背景, 复合语素意识是要求儿童根据提供的场景或问题, 分析、选择、使用正确的语素, 利用语素的组合规则形成合适的复合新词, 体现了儿童对字词语素的分析能力。语素的分析是学习新词意义的一种方法(Carlisle, 2010; Verhoeven & Perfetti, 2011), 复合语素意识能够帮助儿童通过分析词的内部结构来学习和理解新词, 例如“剪刀”, 如果儿童不熟悉“剪”字但熟悉“刀”, 根据熟悉语素和组合规则, 他们就能推测出“剪刀”是代表刀一类的物品。在新词的背景下, 儿童扩充了字词量, 促进了后期字词掌握的速度。然而, 回懿等人(2018)研究结果显示复合语素意识并未显著预测汉字识别的发展速度, 可能是因为回懿等人最后测查的时间点是二年级初始, 而本研究最后测查的时间点是二年级后半学期, 追踪时间的不同所致, 但这一点还有待将来的研究进一步验证。
此外, 本研究结果显示了第一时间点的语素意识对听写的起始水平和发展速度均没有显著预测作用。这表明听写的成绩可能不受儿童初始的语素意识影响, 原因可能和儿童的年级发展有关。一年级多是相对简单的独体字, 直接的机械记忆和提取相对容易便捷, 无需利用语素分析。而随着时间的发展儿童所学汉字结构开始变的复杂, 儿童个体之间的发展差异开始变大, 这时语素意识的影响可能就会增大。低年级阶段听写的机械提取占主导(Bialystok, McBride-Chang, & Luk, 2005), 到了高年级阅读相关认知技能相对成熟, 在听写中儿童可能就会应用这些技能, 因此随着儿童语言经验的增加, 语素意识可能对听写的影响作用会更大(Nunes, Bryant, & Bindman, 1997)。汉语的拼写错误分析研究(Shen & Bear, 2000)也表明, 儿童在低年级较少使用语义策略, 随着语言经验的增加才逐步开始在听写过程中使用。由于本研究是从一年级初到二年级末的4个时间点的追踪, 可能会存在低年级语素意识对听写发展速度没有显著影响, 到了中、高年级段语素意识与听写发展速度的关系会比较密切。此外, 虽然已有研究(Apel et al., 2012; Deacon et al., 2009; Pittas & Nunes, 2014)显示了语素意识对某个时间点上静态的听写水平的预测, 但是本研究结果显示语素意识并不预测听写的发展轨迹, 听写的发展轨迹可能受其他因素(如记忆、动机、阅读量等)的影响。
尽管本研究得出了较有意义的结果, 但也存在一些不足。首先, 样本量较小。本研究发现汉字识别的发展轨迹具有显著的个体差异, 但受限于样本量无法进行类别分析。大样本的研究可以对发展差异进行分类研究, 在现实中针对不同发展类别的儿童实施不同的教学策略会更有意义。其次, 追踪的时间较短。两年4个时间点的追踪仅仅刻画了儿童一、二年级的发展状况, 起始水平对儿童二年级以后的发展影响可能更具有实践意义。最后, 本研究仅着眼于语素意识的影响, 实践中可能还会有其他重要的因素如家庭环境、学习兴趣等对儿童读写的影响, 在今后的研究中可以进一步探讨。
5 结论
(1)汉字识别呈线性发展趋势, 听写呈先快后慢的非线性发展趋势, 二者均存在补偿效应;
(2)同音语素意识和复合语素意识显著影响汉字识别的起始水平和发展速度, 但对听写的起始水平和发展速度均不具有显著的预测作用。
参考文献
Contributions of morphological awareness skills to word-level reading and spelling in first- grade children with and without speech sound disorder
DOI:10.1044/1092-4388(2011/10-0115)
URL
PMID:21386040
[本文引用: 4]

In this study, the authors compared the morphological awareness abilities of children with speech sound disorder (SSD) and children with typical speech skills and examined how morphological awareness ability predicted word-level reading and spelling performance above other known contributors to literacy development.
Metalinguistic contributions to reading and spelling in second and third grade students
Analyzing the development of individual differences in terms of Matthew effects in reading: Results from a Dutch longitudinal study
DOI:10.1037//0012-1649.34.6.1373
URL
PMID:9823518
[本文引用: 2]
The Matthew effect hypothesis provides a theoretical framework to describe the development of individual differences in reading ability. The model predicts an increase of individual differences in reading. Reciprocal relationships between reading and other factors seem to cause these increasing differences. This longitudinal study of 3 years was concerned with uncovering the existence and causes of increasing individual differences in reading in the early elementary grades. Data were analyzed within a structural equation modeling framework. The results clearly indicate increasing individual differences for word recognition skills. For reading comprehension, no such effects could be established for this limited time period. More important, some evidence for interactive relationships between reading and other cognitive skills, behaviors, and motivational factors, hypothesized to cause increasing differences between readers, was found.
Bilingualism, language proficiency, and learning to read in two writing systems
Effects of instruction in morphological awareness on literacy achievement: An integrative review
Teachers with linguistically informed knowledge of reading subskills are associated with a Matthew effect in reading comprehension for monolingual and bilingual students
How robust is the contribution of morphological awareness to general spelling outcomes?
DOI:10.1080/02702710802412057 URL [本文引用: 2]
Crossover: The role of morphological awareness in French immersion children's reading
DOI:10.1037/0012-1649.43.3.732
URL
PMID:17484584
[本文引用: 1]
Achieving biliteracy is a remarkable accomplishment, and it is important to understand the range of factors that permit its successful realization. The authors investigated a factor known to affect reading in monolingual children that has received little attention in the second-language literature: morphological awareness. The researchers tracked the relationships between performance on past tense analogy tasks (the measure of morphological awareness) and reading of English and French in a group of 58 French immersion children across Grades 1-3. Early measures of English morphological awareness were significantly related to both English and French reading, after controlling for several variables. In contrast, early measures of French morphological awareness were significantly related to French reading only. Later measures of morphological awareness in French were significantly related to English and French reading. These relationships persisted even after controlling for several variables. Results of this study suggest that morphological awareness can be applied to reading across orthographies and that this relationship changes as children build their language and literacy skills. These findings are discussed in light of current theories of second-language reading acquisition.
The roles of morphological awareness, phonological awareness and rapid naming in linguistic skills development of Chinese kindergartener: Evidence from a longitudinal study
语素意识、语音意识和快速命名在学前儿童言语能力发展中的预测作用: 来自追踪研究的证据
Learning to read and learning to spell: Two sides of a coin
The effects of morphological awareness training on reading, spelling, and vocabulary skills
DOI:10.3389/fpsyg.2017.02039
URL
PMID:29230186
[本文引用: 1]
Different language skills are considered fundamental for successful reading and spelling acquisition. Extensive evidence has highlighted the central role of phonological awareness in early literacy experiences. However, many orthographic systems also require the contribution of morphological awareness. The goal of this study was to examine the morphological and phonological awareness skills of preschool children as longitudinal predictors of reading and spelling ability by the end of first grade, controlling for the effects of receptive and expressive vocabulary skills. At Time 1 preschool children from kindergartens in the Greek regions of Attika, Crete, Macedonia, and Thessaly were assessed on tasks tapping receptive and expressive vocabulary, phonological awareness (syllable and phoneme), and morphological awareness (inflectional and derivational). Tasks were administered through an Android application for mobile devices (tablets) featuring automatic application of ceiling rules. At Time 2 one year later the same children attending first grade were assessed on measures of word and pseudoword reading, text reading fluency, text reading comprehension, and spelling. Complete data from 104 children are available. Hierarchical linear regression and commonality analyses were conducted for each outcome variable. Reading accuracy for both words and pseudowords was predicted not only by phonological awareness, as expected, but also by morphological awareness, suggesting that understanding the functional role of word parts supports the developing phonology-orthography mappings. However, only phonological awareness predicted text reading fluency at this age. Longitudinal prediction of reading comprehension by both receptive vocabulary and morphological awareness was already evident at this age, as expected. Finally, spelling was predicted by preschool phonological awareness, as expected, as well as by morphological awareness, the contribution of which is expected to increase due to the spelling demands of Greek inflectional and derivational suffixes introduced at later grades.
Morphological development in children's writing
Developmental trends of literacy skills of Chinese lower graders: The predicting effects of reading-related cognitive skills
小学低年级汉语儿童语言能力的发展轨迹:认知能力的预测作用
Children’s spelling of base, inflected, and derived words: Links with morphological awareness
Are there any Matthew effects in literacy and cognitive development?
DOI:10.1111/j.1743-6109.2010.01902.x
URL
PMID:20626600
[本文引用: 3]
Because of improved prostate cancer detection, more patients begin androgen deprivation therapy (ADT) earlier and remain on it longer than before. Patients now may be androgen deprived for over a decade, even when they are otherwise free of cancer symptoms.
The roles of phonological awareness, morphological awareness, and rapid naming in linguistic skills development of kindergartener
语音意识、语素意识和快速命名在儿童言语发展中的作用
Chinese children's character recognition: Visuo-orthographic, phonological processing and morphological skills
DOI:10.1111/j.1467-9817.2010.01460.x
URL
[本文引用: 2]
Tasks tapping visual skills, orthographic knowledge, phonological awareness, speeded naming, morphological awareness and Chinese character recognition were administered to 184 kindergarteners and 273 primary school students from Beijing. Regression analyses indicated that only syllable deletion, morphological construction and speeded number naming were unique correlates of Chinese character recognition in kindergarteners. Among primary school children, the independent correlates of character recognition were rime detection, homophone judgement, morpheme production, orthographic knowledge and speeded number naming. Results underscore the importance of some dimensions of both phonological processing and morphological awareness for both very early and intermediate Chinese reading acquisition. Although significantly correlated with character recognition in younger (but not older) children, visual skills were not uniquely associated with Chinese character reading at any grade level. However, orthographic skills were strongly associated with reading in primary school but not kindergarten, suggesting that orthographic skills are more important for literacy development as reading experience increases.
Effects of metalinguistic awareness on reading comprehension and the mediator role of reading fluency from grades 2 to 4
DOI:10.1371/journal.pone.0114417
URL
PMID:25799530
[本文引用: 2]
This study examined the contribution of metalinguistic awareness including morphological awareness, phonological awareness and orthographical awareness to reading comprehension, and the role of reading fluency as a mediator of the effects of metalinguistic awareness on reading comprehension from grades 2 to 4.
Effects of metalinguistic awareness and rapid automatized naming on character dictation for pupils
元语言意识和快速命名对小学生汉字听写的影响
Confusion and clarification on the primary school orientation in the preschool education: Based on the analysis of "centering on children's development" stance
学前教育小学化: 困惑与澄清——基于“儿童发展中心”的分析
Morphological awareness uniquely predicts young children's Chinese character recognition
Responding to nonresponders: An experimental field trial of identification and intervention methods
Latent curve analysis
DOI:10.1007/BF02294746 URL [本文引用: 2]
Relationship of morphology and other language skills to literacy skills in at-risk second-grade readers and at-risk fourth-grade writers
The connecting competition effect on the orthographic-phonological connection coding for children with spelling difficulties
联结竞争对听写困难儿童形音联结编码的影响
Morphological spelling strategies: Developmental stages and processes
DOI:10.1037//0012-1649.33.4.637
URL
PMID:9232379
[本文引用: 1]
The spelling of many words in English and in other orthographies involves patterns determined by morphology (e.g., ed in past regular verbs). The authors report a longitudinal study that shows that when children first adopt such spelling patterns, they do so with little regard for their morphological basis. They generalize the patterns to grammatically inappropriate words (e.g., sofed for soft). Later these generalizations are confined to the right grammatical category (e.g., keped for kept) and finally to the right group of words (regular verbs). The authors conclude that children first see these spelling patterns merely as exceptions to the phonetic system and later grasp their grammatical significance. The study included two new measures of grammatical awareness, both involving analogies, that predicted success with spelling inflectional morphemes in later sessions.
Reinterpreting the development of reading skills
Reading ability: Lexical quality to comprehension
DOI:10.1080/10888430701530730 URL [本文引用: 1]
Reading competence development of poor readers in a German elementary school sample: An empirical examination of the Matthew effect model
DOI:10.1111/jrir.2012.35.issue-4 URL [本文引用: 3]
The relation between morphological awareness and reading and spelling in Greek: A longitudinal study
DOI:10.1007/s11145-014-9503-6
URL
[本文引用: 2]
The aim of this longitudinal study is to examine the contribution of morphological awareness to the prediction of reading and spelling in Greek. The target group (N = 404) consisted of children, aged 6-9 years at the start of the project, who learn literacy in Cyprus. Because there are no standardized measures of morphological awareness for Greek Cypriot children, morphological awareness measures were developed and validated. A concurrent analysis of the first wave of data collection showed that morphological awareness made a unique contribution to the prediction of reading and spelling in Greek. The longitudinal analyses showed that morphological awareness predicted performance in reading eight months later, even after partialling out grade level, verbal intelligence, phonological awareness and initial scores in reading and spelling. This study makes theoretical, empirical and practical educational contributions. It shows the long term and specific relation of morphological awareness with reading in Greek and establishes the plausibility of a causal link between morphological awareness and reading, which must be tested in further research using intervention methods. In practice, this study contributes valid measures for assessing morphological awareness in Greek as well as a new measure of spelling skill.
Readers who struggle: Why many struggle and a modest proposal for improving their reading
Toward a comprehensive view of the skills involved in word reading in Grades 4, 6, and 8
DOI:10.1016/j.jecp.2008.01.004
URL
PMID:18329037
[本文引用: 1]
Research to date has proposed four main variables involved in reading development: phonological awareness, naming speed, orthographic knowledge, and morphological awareness. Although each of these variables has been examined in the context of one or two of the other variables, this study examines all four factors together to assess their unique contribution to reading. A sample of children in Grades 4, 6, and 8 (ages 10, 12, and 14 years) completed a battery of tests that included at least one measure of each of the four variables and two measures of reading accuracy. Phonological awareness, orthographic knowledge, and morphological awareness each contributed uniquely to real word and pseudoword reading beyond the other variables, whereas naming speed did not survive these stringent controls. The results support the sustained importance of these three skills in reading by older readers.
Development of orthographic skills in Chinese children
Understanding Chinese developmental dyslexia: Morphological awareness as a core cognitive construct
Matthew effects in reading: Some consequences of individual differences in the acquisition of literacy
Cultivation of the psychological quality in convergence of kindergartens and primary schools
幼小衔接之心理品质的培养
Morphological awareness, orthographic knowledge, and spelling errors: Keys to understanding early Chinese literacy acquisition
DOI:10.1080/10888430903162910 URL [本文引用: 3]
The American way of spelling: The structure and origins of American English orthography
Introduction to the special issue: Morphology in word identification and word spelling
Introduction to this special issue: The role of morphology in learning to read
DOI:10.1177/0022219413509967
URL
PMID:24219917
[本文引用: 4]
The purpose of this special issue of the Journal of Learning Disabilities is to bring to the attention of researchers and educators studies on morphology and literacy that either involve students with learning difficulties or have educational implications for teaching such students. In our introduction, we first provide background information about morphological knowledge and consider the role of morphology in literacy, focusing on findings that are relevant for instruction of students who struggle with reading and writing. Next we present an overview of the studies included in this issue, organized by current issues concerning the role of morphological knowledge in literacy. Collectively, the articles in this issue suggest that students with weaker literacy skills tend to lag behind their peers in morphological knowledge but that all students are likely to benefit from morphological instruction. Morphological interventions hold promise, especially for students who face challenges in language learning and literacy, but additional research is needed to provide a basis for informed decisions about the design of effective morphological interventions.
Morphological processing in reading acquisition: A cross-linguistic perspective
DOI:10.1017/S0142716411000154 URL [本文引用: 3]
How important is reading skill fluency for comprehension?
DOI:10.1598/RT.60.6.6 URL [本文引用: 2]
Morphological awareness and Chinese children's literacy development: An intervention study
DOI:10.1080/10888430802631734 URL [本文引用: 1]
Production of Chinese characters under dictation
听写任务下的字词加工
Standardization research on raven’s standard progressive matrices in China
瑞文标准推理测验在我国的修订

{kind=link}
{kind=link}
{kind=link}
{kind=link}