ISSN 0439-755X
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
CN 11-1911/B
主办:中国心理学会
中国科学院心理研究所
出版:科学出版社
心理学报 ›› 2022, Vol. 54 ›› Issue (4): 411-425.doi: 10.3724/SP.J.1041.2022.00411 cstr: 32110.14.2022.00411
刘玥1, 刘红云2,3( ), 游晓锋4, 杨建芹4
), 游晓锋4, 杨建芹4
收稿日期:2021-04-08
发布日期:2022-02-21
出版日期:2022-04-25
基金资助:
LIU Yue1, LIU Hongyun2,3(), YOU Xiaofeng4, YANG Jianqin4
Received:2021-04-08
Online:2022-02-21
Published:2022-04-25
摘要:
文章采用模拟研究, 分别在混合多层模型假设满足和违背的情境下, 比较了混合多层模型方法与标准化残差系列方法在识别不努力作答和参数估计方面的表现。结果显示:(1)不存在不努力作答或其严重性低时, 各方法表现接近; (2)不努力作答严重性高时, 固定参数迭代标准化残差法普遍更优, 混合多层模型法仅在假设满足且两种作答反应时差异大的条件下表现较好。建议实际应用中优先选择固定参数迭代标准化残差法。
中图分类号:
刘玥, 刘红云, 游晓锋, 杨建芹. (2022). 用于处理不努力作答的标准化残差系列方法和混合多层模型法的比较. 心理学报, 54(4), 411-425.
LIU Yue, LIU Hongyun, YOU Xiaofeng, YANG Jianqin. (2022). A comparison of standard residual methods and a mixture hierarchical model for detecting non-effortful responses. Acta Psychologica Sinica, 54(4), 411-425.
| 情境 | π | $\pi _{i}^{non}$ | ${{d}_{RT}}$ | 作答分类 参数(Δij) | 题目 参数 | 被试 参数 | 合计 |
|---|---|---|---|---|---|---|---|
| 情境1 | 0% | 0.05 | 0.00 | 0.00 | 0.05 | ||
| 20% | 低 | 小 | 15.83 | 0.00 | 0.00 | 14.80 | |
| 大 | 11.70 | 0.00 | 0.00 | 10.94 | |||
| 高 | 小 | 11.10 | 0.00 | 0.00 | 10.38 | ||
| 大 | 12.11 | 0.00 | 0.01 | 11.33 | |||
| 40% | 低 | 小 | 12.88 | 0.00 | 0.00 | 12.04 | |
| 大 | 12.73 | 0.00 | 0.00 | 11.91 | |||
| 高 | 小 | 9.30 | 0.00 | 0.00 | 8.70 | ||
| 大 | 13.15 | 0.00 | 0.00 | 12.30 | |||
| 情境2 | 20% | 低 | 16.75 | 0.00 | 0.00 | 15.67 | |
| 高 | 15.53 | 0.00 | 0.00 | 14.52 | |||
| 40% | 低 | 7.08 | 0.00 | 0.00 | 6.62 | ||
| 高 | 11.93 | 0.00 | 0.00 | 11.15 |
表1 各条件下MHM不收敛百分比(%)
| 情境 | π | $\pi _{i}^{non}$ | ${{d}_{RT}}$ | 作答分类 参数(Δij) | 题目 参数 | 被试 参数 | 合计 |
|---|---|---|---|---|---|---|---|
| 情境1 | 0% | 0.05 | 0.00 | 0.00 | 0.05 | ||
| 20% | 低 | 小 | 15.83 | 0.00 | 0.00 | 14.80 | |
| 大 | 11.70 | 0.00 | 0.00 | 10.94 | |||
| 高 | 小 | 11.10 | 0.00 | 0.00 | 10.38 | ||
| 大 | 12.11 | 0.00 | 0.01 | 11.33 | |||
| 40% | 低 | 小 | 12.88 | 0.00 | 0.00 | 12.04 | |
| 大 | 12.73 | 0.00 | 0.00 | 11.91 | |||
| 高 | 小 | 9.30 | 0.00 | 0.00 | 8.70 | ||
| 大 | 13.15 | 0.00 | 0.00 | 12.30 | |||
| 情境2 | 20% | 低 | 16.75 | 0.00 | 0.00 | 15.67 | |
| 高 | 15.53 | 0.00 | 0.00 | 14.52 | |||
| 40% | 低 | 7.08 | 0.00 | 0.00 | 6.62 | ||
| 高 | 11.93 | 0.00 | 0.00 | 11.15 |
| 情境 | π | $\pi _{i}^{non}$ | ${{d}_{RT}}$ | 指标 | OSR | CSR | CSRI | MHM |
|---|---|---|---|---|---|---|---|---|
| 情境1 | 0% | FPR | 0.05 | 0.05 | 0.06 | 0.00 | ||
| 20% | 低 (0.025) | 小 | TPR | 0.59 | 0.59 | 0.69 | 0.39 | |
| FDR | 0.69 | 0.69 | 0.71 | 0.20 | ||||
| Pr | 0.05 | 0.05 | 0.06 | 0.01 | ||||
| 大 | TPR | 0.91 | 0.91 | 0.97 | 0.87 | |||
| FDR | 0.47 | 0.49 | 0.53 | 0.09 | ||||
| Pr | 0.04 | 0.04 | 0.05 | 0.02 | ||||
| 高 (0.125) | 小 | TPR | 0.19 | 0.25 | 0.50 | 0.03 | ||
| FDR | 0.48 | 0.54 | 0.43 | 0.08 | ||||
| Pr | 0.04 | 0.07 | 0.11 | 0.00 | ||||
| 大 | TPR | 0.31 | 0.50 | 0.93 | 0.82 | |||
| FDR | 0.16 | 0.36 | 0.28 | 0.07 | ||||
| Pr | 0.05 | 0.10 | 0.16 | 0.11 | ||||
| 40% | 低 (0.050) | 小 | TPR | 0.55 | 0.55 | 0.65 | 0.51 | |
| FDR | 0.46 | 0.45 | 0.47 | 0.20 | ||||
| Pr | 0.05 | 0.05 | 0.06 | 0.03 | ||||
| 大 | TPR | 0.87 | 0.87 | 0.94 | 0.91 | |||
| FDR | 0.17 | 0.16 | 0.18 | 0.09 | ||||
| Pr | 0.05 | 0.05 | 0.06 | 0.05 | ||||
| 高 (0.250) | 小 | TPR | 0.13 | 0.24 | 0.49 | 0.16 | ||
| FDR | 0.23 | 0.31 | 0.23 | 0.10 | ||||
| Pr | 0.04 | 0.09 | 0.16 | 0.05 | ||||
| 大 | TPR | 0.17 | 0.49 | 0.93 | 0.94 | |||
| FDR | 0.03 | 0.17 | 0.14 | 0.07 | ||||
| Pr | 0.04 | 0.15 | 0.27 | 0.25 | ||||
| 情境2 | 20% | 低 (0.025) | TPR | 0.77 | 0.78 | 0.90 | 0.64 | |
| FDR | 0.52 | 0.53 | 0.55 | 0.10 | ||||
| Pr | 0.04 | 0.04 | 0.05 | 0.02 | ||||
| 高 (0.125) | TPR | 0.27 | 0.34 | 0.72 | 0.18 | |||
| FDR | 0.17 | 0.35 | 0.24 | 0.01 | ||||
| Pr | 0.04 | 0.07 | 0.12 | 0.02 | ||||
| 40% | 低 (0.050) | TPR | 0.70 | 0.69 | 0.82 | 0.73 | ||
| FDR | 0.22 | 0.21 | 0.22 | 0.11 | ||||
| Pr | 0.04 | 0.04 | 0.05 | 0.04 | ||||
| 高 (0.250) | TPR | 0.20 | 0.29 | 0.56 | 0.13 | |||
| FDR | 0.02 | 0.10 | 0.06 | 0.00 | ||||
| Pr | 0.05 | 0.08 | 0.15 | 0.03 |
表2 各条件下各方法识别准确性指标结果
| 情境 | π | $\pi _{i}^{non}$ | ${{d}_{RT}}$ | 指标 | OSR | CSR | CSRI | MHM |
|---|---|---|---|---|---|---|---|---|
| 情境1 | 0% | FPR | 0.05 | 0.05 | 0.06 | 0.00 | ||
| 20% | 低 (0.025) | 小 | TPR | 0.59 | 0.59 | 0.69 | 0.39 | |
| FDR | 0.69 | 0.69 | 0.71 | 0.20 | ||||
| Pr | 0.05 | 0.05 | 0.06 | 0.01 | ||||
| 大 | TPR | 0.91 | 0.91 | 0.97 | 0.87 | |||
| FDR | 0.47 | 0.49 | 0.53 | 0.09 | ||||
| Pr | 0.04 | 0.04 | 0.05 | 0.02 | ||||
| 高 (0.125) | 小 | TPR | 0.19 | 0.25 | 0.50 | 0.03 | ||
| FDR | 0.48 | 0.54 | 0.43 | 0.08 | ||||
| Pr | 0.04 | 0.07 | 0.11 | 0.00 | ||||
| 大 | TPR | 0.31 | 0.50 | 0.93 | 0.82 | |||
| FDR | 0.16 | 0.36 | 0.28 | 0.07 | ||||
| Pr | 0.05 | 0.10 | 0.16 | 0.11 | ||||
| 40% | 低 (0.050) | 小 | TPR | 0.55 | 0.55 | 0.65 | 0.51 | |
| FDR | 0.46 | 0.45 | 0.47 | 0.20 | ||||
| Pr | 0.05 | 0.05 | 0.06 | 0.03 | ||||
| 大 | TPR | 0.87 | 0.87 | 0.94 | 0.91 | |||
| FDR | 0.17 | 0.16 | 0.18 | 0.09 | ||||
| Pr | 0.05 | 0.05 | 0.06 | 0.05 | ||||
| 高 (0.250) | 小 | TPR | 0.13 | 0.24 | 0.49 | 0.16 | ||
| FDR | 0.23 | 0.31 | 0.23 | 0.10 | ||||
| Pr | 0.04 | 0.09 | 0.16 | 0.05 | ||||
| 大 | TPR | 0.17 | 0.49 | 0.93 | 0.94 | |||
| FDR | 0.03 | 0.17 | 0.14 | 0.07 | ||||
| Pr | 0.04 | 0.15 | 0.27 | 0.25 | ||||
| 情境2 | 20% | 低 (0.025) | TPR | 0.77 | 0.78 | 0.90 | 0.64 | |
| FDR | 0.52 | 0.53 | 0.55 | 0.10 | ||||
| Pr | 0.04 | 0.04 | 0.05 | 0.02 | ||||
| 高 (0.125) | TPR | 0.27 | 0.34 | 0.72 | 0.18 | |||
| FDR | 0.17 | 0.35 | 0.24 | 0.01 | ||||
| Pr | 0.04 | 0.07 | 0.12 | 0.02 | ||||
| 40% | 低 (0.050) | TPR | 0.70 | 0.69 | 0.82 | 0.73 | ||
| FDR | 0.22 | 0.21 | 0.22 | 0.11 | ||||
| Pr | 0.04 | 0.04 | 0.05 | 0.04 | ||||
| 高 (0.250) | TPR | 0.20 | 0.29 | 0.56 | 0.13 | |||
| FDR | 0.02 | 0.10 | 0.06 | 0.00 | ||||
| Pr | 0.05 | 0.08 | 0.15 | 0.03 |
| 评价标准 | 方法 | OSR | CSR | CSRI | MHM |
|---|---|---|---|---|---|
| bias | a | -0.01 | -0.01 | -0.01 | 0.01 |
| b | 0.00 | 0.00 | 0.00 | 0.00 | |
| α | -0.21 | -0.22 | -0.26 | 0.00 | |
| β | -0.07 | -0.07 | -0.08 | 0.02 | |
| θ | 0.00 | -0.01 | -0.01 | 0.01 | |
| τ | -0.01 | -0.01 | -0.01 | 0.02 | |
| RMSE | a | 0.11 | 0.11 | 0.11 | 0.10 |
| b | 0.05 | 0.05 | 0.05 | 0.05 | |
| α | 0.22 | 0.22 | 0.27 | 0.03 | |
| β | 0.07 | 0.07 | 0.08 | 0.02 | |
| θ | 0.29 | 0.29 | 0.29 | 0.28 | |
| τ | 0.10 | 0.10 | 0.11 | 0.09 |
表3 情境1中不含不努力作答条件下各方法参数估计准确性
| 评价标准 | 方法 | OSR | CSR | CSRI | MHM |
|---|---|---|---|---|---|
| bias | a | -0.01 | -0.01 | -0.01 | 0.01 |
| b | 0.00 | 0.00 | 0.00 | 0.00 | |
| α | -0.21 | -0.22 | -0.26 | 0.00 | |
| β | -0.07 | -0.07 | -0.08 | 0.02 | |
| θ | 0.00 | -0.01 | -0.01 | 0.01 | |
| τ | -0.01 | -0.01 | -0.01 | 0.02 | |
| RMSE | a | 0.11 | 0.11 | 0.11 | 0.10 |
| b | 0.05 | 0.05 | 0.05 | 0.05 | |
| α | 0.22 | 0.22 | 0.27 | 0.03 | |
| β | 0.07 | 0.07 | 0.08 | 0.02 | |
| θ | 0.29 | 0.29 | 0.29 | 0.28 | |
| τ | 0.10 | 0.10 | 0.11 | 0.09 |
| $\pi $ | 评价 标准 | 参数 | $\pi _{i}^{non}$低 | $\pi _{i}^{non}$高 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ${{d}_{RT}}$小 | ${{d}_{RT}}$大 | ${{d}_{RT}}$小 | ${{d}_{RT}}$大 | ||||||||||||||||||
| OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | ||||||
| 20% | bias | a | 0.05 | 0.05 | 0.04 | -0.03 | 0.01 | 0.01 | 0.00 | -0.02 | 0.24 | 0.24 | 0.20 | 0.20 | 0.20 | 0.18 | 0.04 | -0.03 | |||
| b | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | -0.01 | -0.12 | -0.12 | -0.09 | -0.13 | -0.13 | -0.08 | -0.02 | -0.03 | |||||
| α | -0.15 | -0.15 | -0.19 | 0.01 | -0.10 | -0.11 | -0.14 | -0.01 | 0.08 | 0.01 | -0.16 | 0.24 | 0.24 | 0.20 | -0.21 | 0.05 | |||||
| β | -0.05 | -0.05 | -0.06 | -0.01 | -0.04 | -0.04 | -0.05 | -0.02 | 0.09 | 0.06 | 0.00 | 0.13 | 0.13 | 0.10 | -0.05 | 0.03 | |||||
| θ | 0.00 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | -0.01 | -0.01 | |||||
| τ | -0.02 | -0.01 | -0.01 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | -0.02 | -0.01 | -0.01 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | |||||
| RMSE | a | 0.13 | 0.13 | 0.12 | 0.12 | 0.11 | 0.11 | 0.11 | 0.11 | 0.39 | 0.38 | 0.31 | 0.36 | 0.33 | 0.28 | 0.13 | 0.13 | ||||
| b | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.17 | 0.16 | 0.13 | 0.18 | 0.14 | 0.11 | 0.06 | 0.06 | |||||
| α | 0.15 | 0.15 | 0.20 | 0.04 | 0.11 | 0.11 | 0.15 | 0.04 | 0.12 | 0.06 | 0.17 | 0.26 | 0.40 | 0.22 | 0.22 | 0.07 | |||||
| β | 0.05 | 0.05 | 0.06 | 0.02 | 0.04 | 0.04 | 0.05 | 0.02 | 0.09 | 0.06 | 0.02 | 0.13 | 0.18 | 0.11 | 0.05 | 0.03 | |||||
| θ | 0.30 | 0.30 | 0.30 | 0.29 | 0.29 | 0.29 | 0.29 | 0.29 | 0.43 | 0.42 | 0.40 | 0.43 | 0.41 | 0.40 | 0.34 | 0.35 | |||||
| τ | 0.11 | 0.11 | 0.11 | 0.10 | 0.10 | 0.10 | 0.10 | 0.10 | 0.30 | 0.29 | 0.22 | 0.33 | 0.45 | 0.39 | 0.17 | 0.22 | |||||
| 40% | bias | a | 0.11 | 0.11 | 0.09 | -0.07 | 0.03 | 0.04 | 0.02 | -0.03 | 0.42 | 0.42 | 0.38 | 0.14 | 0.35 | 0.33 | 0.10 | -0.06 | |||
| b | -0.03 | -0.03 | -0.02 | -0.02 | -0.01 | -0.01 | -0.01 | -0.01 | -0.25 | -0.23 | -0.19 | -0.20 | -0.22 | -0.15 | -0.03 | -0.02 | |||||
| α | -0.08 | -0.08 | -0.13 | 0.01 | -0.02 | -0.02 | -0.06 | -0.02 | 0.30 | 0.18 | -0.06 | 0.34 | 0.72 | 0.47 | -0.18 | -0.01 | |||||
| β | -0.03 | -0.03 | -0.04 | -0.01 | -0.02 | -0.02 | -0.03 | -0.02 | 0.24 | 0.19 | 0.08 | 0.22 | 0.47 | 0.28 | -0.03 | 0.01 | |||||
| θ | 0.00 | 0.00 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | -0.01 | |||||
| τ | -0.01 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | |||||
| RMSE | a | 0.17 | 0.17 | 0.15 | 0.14 | 0.12 | 0.12 | 0.11 | 0.12 | 0.59 | 0.57 | 0.50 | 0.32 | 0.53 | 0.45 | 0.17 | 0.16 | ||||
| b | 0.07 | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 | 0.05 | 0.06 | 0.32 | 0.29 | 0.23 | 0.24 | 0.27 | 0.19 | 0.07 | 0.06 | |||||
| α | 0.09 | 0.09 | 0.14 | 0.04 | 0.05 | 0.05 | 0.07 | 0.04 | 0.33 | 0.21 | 0.08 | 0.37 | 0.75 | 0.49 | 0.19 | 0.05 | |||||
| β | 0.03 | 0.03 | 0.04 | 0.02 | 0.02 | 0.02 | 0.03 | 0.02 | 0.25 | 0.19 | 0.08 | 0.22 | 0.47 | 0.28 | 0.03 | 0.02 | |||||
| θ | 0.31 | 0.31 | 0.31 | 0.30 | 0.30 | 0.30 | 0.29 | 0.29 | 0.53 | 0.52 | 0.48 | 0.50 | 0.52 | 0.48 | 0.39 | 0.37 | |||||
| τ | 0.11 | 0.11 | 0.11 | 0.11 | 0.10 | 0.10 | 0.10 | 0.10 | 0.39 | 0.36 | 0.28 | 0.37 | 0.61 | 0.49 | 0.21 | 0.18 | |||||
表4 情境1中含有不努力作答条件下各方法参数估计准确性
| $\pi $ | 评价 标准 | 参数 | $\pi _{i}^{non}$低 | $\pi _{i}^{non}$高 | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ${{d}_{RT}}$小 | ${{d}_{RT}}$大 | ${{d}_{RT}}$小 | ${{d}_{RT}}$大 | ||||||||||||||||||
| OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | ||||||
| 20% | bias | a | 0.05 | 0.05 | 0.04 | -0.03 | 0.01 | 0.01 | 0.00 | -0.02 | 0.24 | 0.24 | 0.20 | 0.20 | 0.20 | 0.18 | 0.04 | -0.03 | |||
| b | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | -0.01 | -0.12 | -0.12 | -0.09 | -0.13 | -0.13 | -0.08 | -0.02 | -0.03 | |||||
| α | -0.15 | -0.15 | -0.19 | 0.01 | -0.10 | -0.11 | -0.14 | -0.01 | 0.08 | 0.01 | -0.16 | 0.24 | 0.24 | 0.20 | -0.21 | 0.05 | |||||
| β | -0.05 | -0.05 | -0.06 | -0.01 | -0.04 | -0.04 | -0.05 | -0.02 | 0.09 | 0.06 | 0.00 | 0.13 | 0.13 | 0.10 | -0.05 | 0.03 | |||||
| θ | 0.00 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | -0.01 | -0.01 | |||||
| τ | -0.02 | -0.01 | -0.01 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | -0.02 | -0.01 | -0.01 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | |||||
| RMSE | a | 0.13 | 0.13 | 0.12 | 0.12 | 0.11 | 0.11 | 0.11 | 0.11 | 0.39 | 0.38 | 0.31 | 0.36 | 0.33 | 0.28 | 0.13 | 0.13 | ||||
| b | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.17 | 0.16 | 0.13 | 0.18 | 0.14 | 0.11 | 0.06 | 0.06 | |||||
| α | 0.15 | 0.15 | 0.20 | 0.04 | 0.11 | 0.11 | 0.15 | 0.04 | 0.12 | 0.06 | 0.17 | 0.26 | 0.40 | 0.22 | 0.22 | 0.07 | |||||
| β | 0.05 | 0.05 | 0.06 | 0.02 | 0.04 | 0.04 | 0.05 | 0.02 | 0.09 | 0.06 | 0.02 | 0.13 | 0.18 | 0.11 | 0.05 | 0.03 | |||||
| θ | 0.30 | 0.30 | 0.30 | 0.29 | 0.29 | 0.29 | 0.29 | 0.29 | 0.43 | 0.42 | 0.40 | 0.43 | 0.41 | 0.40 | 0.34 | 0.35 | |||||
| τ | 0.11 | 0.11 | 0.11 | 0.10 | 0.10 | 0.10 | 0.10 | 0.10 | 0.30 | 0.29 | 0.22 | 0.33 | 0.45 | 0.39 | 0.17 | 0.22 | |||||
| 40% | bias | a | 0.11 | 0.11 | 0.09 | -0.07 | 0.03 | 0.04 | 0.02 | -0.03 | 0.42 | 0.42 | 0.38 | 0.14 | 0.35 | 0.33 | 0.10 | -0.06 | |||
| b | -0.03 | -0.03 | -0.02 | -0.02 | -0.01 | -0.01 | -0.01 | -0.01 | -0.25 | -0.23 | -0.19 | -0.20 | -0.22 | -0.15 | -0.03 | -0.02 | |||||
| α | -0.08 | -0.08 | -0.13 | 0.01 | -0.02 | -0.02 | -0.06 | -0.02 | 0.30 | 0.18 | -0.06 | 0.34 | 0.72 | 0.47 | -0.18 | -0.01 | |||||
| β | -0.03 | -0.03 | -0.04 | -0.01 | -0.02 | -0.02 | -0.03 | -0.02 | 0.24 | 0.19 | 0.08 | 0.22 | 0.47 | 0.28 | -0.03 | 0.01 | |||||
| θ | 0.00 | 0.00 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | -0.01 | |||||
| τ | -0.01 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | -0.02 | -0.02 | -0.01 | -0.02 | |||||
| RMSE | a | 0.17 | 0.17 | 0.15 | 0.14 | 0.12 | 0.12 | 0.11 | 0.12 | 0.59 | 0.57 | 0.50 | 0.32 | 0.53 | 0.45 | 0.17 | 0.16 | ||||
| b | 0.07 | 0.07 | 0.06 | 0.06 | 0.06 | 0.06 | 0.05 | 0.06 | 0.32 | 0.29 | 0.23 | 0.24 | 0.27 | 0.19 | 0.07 | 0.06 | |||||
| α | 0.09 | 0.09 | 0.14 | 0.04 | 0.05 | 0.05 | 0.07 | 0.04 | 0.33 | 0.21 | 0.08 | 0.37 | 0.75 | 0.49 | 0.19 | 0.05 | |||||
| β | 0.03 | 0.03 | 0.04 | 0.02 | 0.02 | 0.02 | 0.03 | 0.02 | 0.25 | 0.19 | 0.08 | 0.22 | 0.47 | 0.28 | 0.03 | 0.02 | |||||
| θ | 0.31 | 0.31 | 0.31 | 0.30 | 0.30 | 0.30 | 0.29 | 0.29 | 0.53 | 0.52 | 0.48 | 0.50 | 0.52 | 0.48 | 0.39 | 0.37 | |||||
| τ | 0.11 | 0.11 | 0.11 | 0.11 | 0.10 | 0.10 | 0.10 | 0.10 | 0.39 | 0.36 | 0.28 | 0.37 | 0.61 | 0.49 | 0.21 | 0.18 | |||||
| $\pi $ | 评价标准 | 参数 | $\pi _{i}^{non}$低 | $\pi _{i}^{non}$高 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | |||
| 20% | bias | a | 0.00 | 0.00 | 0.00 | -0.08 | -0.03 | -0.02 | 0.04 | -0.08 |
| b | 0.00 | 0.00 | 0.00 | 0.00 | -0.07 | -0.07 | -0.03 | -0.07 | ||
| α | -0.09 | -0.10 | -0.14 | 0.01 | 0.28 | 0.19 | -0.08 | 0.37 | ||
| β | -0.04 | -0.04 | -0.05 | -0.01 | 0.15 | 0.12 | 0.01 | 0.18 | ||
| θ | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | -0.01 | ||
| τ | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | ||
| RMSE | a | 0.11 | 0.11 | 0.11 | 0.14 | 0.17 | 0.17 | 0.14 | 0.18 | |
| b | 0.05 | 0.05 | 0.05 | 0.05 | 0.15 | 0.14 | 0.08 | 0.15 | ||
| α | 0.10 | 0.10 | 0.15 | 0.04 | 0.30 | 0.21 | 0.10 | 0.38 | ||
| β | 0.04 | 0.04 | 0.05 | 0.02 | 0.15 | 0.12 | 0.02 | 0.18 | ||
| θ | 0.29 | 0.29 | 0.29 | 0.29 | 0.34 | 0.34 | 0.34 | 0.34 | ||
| τ | 0.10 | 0.10 | 0.10 | 0.10 | 0.39 | 0.37 | 0.23 | 0.41 | ||
| 40% | bias | a | 0.02 | 0.02 | 0.02 | -0.15 | -0.07 | -0.04 | 0.07 | -0.12 |
| b | -0.01 | -0.01 | -0.01 | -0.01 | -0.15 | -0.14 | -0.11 | -0.15 | ||
| α | 0.00 | 0.01 | -0.05 | 0.01 | 0.57 | 0.48 | 0.21 | 0.65 | ||
| β | -0.01 | -0.01 | -0.02 | -0.01 | 0.38 | 0.32 | 0.18 | 0.41 | ||
| θ | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| τ | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | ||
| RMSE | a | 0.12 | 0.13 | 0.12 | 0.21 | 0.26 | 0.24 | 0.22 | 0.27 | |
| b | 0.06 | 0.06 | 0.05 | 0.05 | 0.27 | 0.25 | 0.17 | 0.29 | ||
| α | 0.05 | 0.05 | 0.07 | 0.04 | 0.59 | 0.50 | 0.23 | 0.67 | ||
| β | 0.02 | 0.02 | 0.03 | 0.02 | 0.38 | 0.32 | 0.18 | 0.41 | ||
| θ | 0.30 | 0.30 | 0.29 | 0.29 | 0.39 | 0.38 | 0.37 | 0.39 | ||
| τ | 0.11 | 0.11 | 0.10 | 0.11 | 0.51 | 0.47 | 0.36 | 0.54 | ||
表5 情境2中各条件下各方法参数估计准确性
| $\pi $ | 评价标准 | 参数 | $\pi _{i}^{non}$低 | $\pi _{i}^{non}$高 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | |||
| 20% | bias | a | 0.00 | 0.00 | 0.00 | -0.08 | -0.03 | -0.02 | 0.04 | -0.08 |
| b | 0.00 | 0.00 | 0.00 | 0.00 | -0.07 | -0.07 | -0.03 | -0.07 | ||
| α | -0.09 | -0.10 | -0.14 | 0.01 | 0.28 | 0.19 | -0.08 | 0.37 | ||
| β | -0.04 | -0.04 | -0.05 | -0.01 | 0.15 | 0.12 | 0.01 | 0.18 | ||
| θ | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | -0.01 | ||
| τ | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | ||
| RMSE | a | 0.11 | 0.11 | 0.11 | 0.14 | 0.17 | 0.17 | 0.14 | 0.18 | |
| b | 0.05 | 0.05 | 0.05 | 0.05 | 0.15 | 0.14 | 0.08 | 0.15 | ||
| α | 0.10 | 0.10 | 0.15 | 0.04 | 0.30 | 0.21 | 0.10 | 0.38 | ||
| β | 0.04 | 0.04 | 0.05 | 0.02 | 0.15 | 0.12 | 0.02 | 0.18 | ||
| θ | 0.29 | 0.29 | 0.29 | 0.29 | 0.34 | 0.34 | 0.34 | 0.34 | ||
| τ | 0.10 | 0.10 | 0.10 | 0.10 | 0.39 | 0.37 | 0.23 | 0.41 | ||
| 40% | bias | a | 0.02 | 0.02 | 0.02 | -0.15 | -0.07 | -0.04 | 0.07 | -0.12 |
| b | -0.01 | -0.01 | -0.01 | -0.01 | -0.15 | -0.14 | -0.11 | -0.15 | ||
| α | 0.00 | 0.01 | -0.05 | 0.01 | 0.57 | 0.48 | 0.21 | 0.65 | ||
| β | -0.01 | -0.01 | -0.02 | -0.01 | 0.38 | 0.32 | 0.18 | 0.41 | ||
| θ | -0.01 | -0.01 | -0.01 | -0.01 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| τ | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | -0.02 | ||
| RMSE | a | 0.12 | 0.13 | 0.12 | 0.21 | 0.26 | 0.24 | 0.22 | 0.27 | |
| b | 0.06 | 0.06 | 0.05 | 0.05 | 0.27 | 0.25 | 0.17 | 0.29 | ||
| α | 0.05 | 0.05 | 0.07 | 0.04 | 0.59 | 0.50 | 0.23 | 0.67 | ||
| β | 0.02 | 0.02 | 0.03 | 0.02 | 0.38 | 0.32 | 0.18 | 0.41 | ||
| θ | 0.30 | 0.30 | 0.29 | 0.29 | 0.39 | 0.38 | 0.37 | 0.39 | ||
| τ | 0.11 | 0.11 | 0.10 | 0.11 | 0.51 | 0.47 | 0.36 | 0.54 | ||
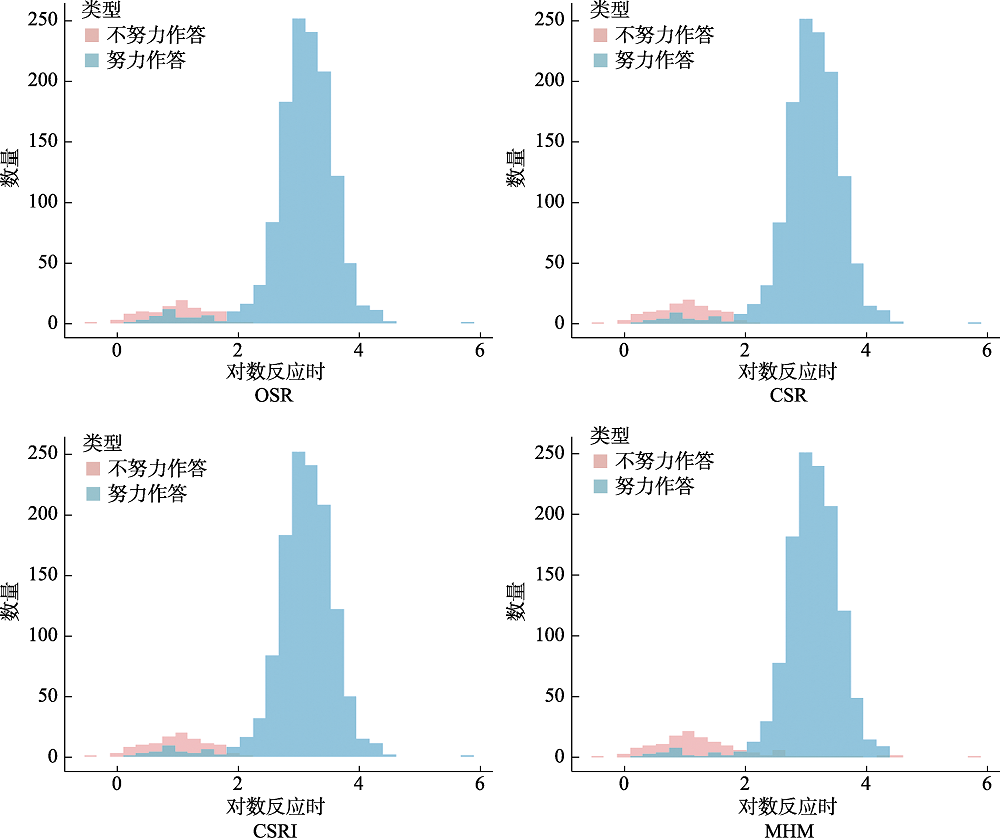
图1 实证研究各方法识别出的两种作答行为在题目层面反应时分布(以48题为例)
| RTE | 认真完成测验重要性评价 | 完成测验努力程度评价 |
|---|---|---|
| OSR | 0.055* | 0.193** |
| CSR | 0.075** | 0.238** |
| CSRI | 0.073** | 0.271** |
| MHM | 0.087** | 0.288** |
表6 实证研究不同方法RTE指标与认真完成测验重要性评价以及完成测验努力程度评价的相关
| RTE | 认真完成测验重要性评价 | 完成测验努力程度评价 |
|---|---|---|
| OSR | 0.055* | 0.193** |
| CSR | 0.075** | 0.238** |
| CSRI | 0.073** | 0.271** |
| MHM | 0.087** | 0.288** |
| 方法 | 分组 | 0~5% | 6%~25% | 26%~50% | 大于50% |
|---|---|---|---|---|---|
| OSR | 努力作答组 | 27.96 | 41.63 | 21.81 | 8.60 |
| 不努力作答组 | 9.23 | 47.69 | 26.15 | 16.92 | |
| CSR | 努力作答组 | 28.25 | 41.94 | 21.52 | 8.29 |
| 不努力作答组 | 10.11 | 41.57 | 29.21 | 19.10 | |
| CSRI | 努力作答组 | 28.80 | 42.00 | 21.28 | 7.92 |
| 不努力作答组 | 8.55 | 41.03 | 29.92 | 20.51 | |
| MHM | 努力作答组 | 28.84 | 41.77 | 21.12 | 8.27 |
| 不努力作答组 | 9.02 | 43.44 | 31.15 | 16.39 |
表7 实证研究不同组被试在随机猜测比例上选择的人数百分比(%)
| 方法 | 分组 | 0~5% | 6%~25% | 26%~50% | 大于50% |
|---|---|---|---|---|---|
| OSR | 努力作答组 | 27.96 | 41.63 | 21.81 | 8.60 |
| 不努力作答组 | 9.23 | 47.69 | 26.15 | 16.92 | |
| CSR | 努力作答组 | 28.25 | 41.94 | 21.52 | 8.29 |
| 不努力作答组 | 10.11 | 41.57 | 29.21 | 19.10 | |
| CSRI | 努力作答组 | 28.80 | 42.00 | 21.28 | 7.92 |
| 不努力作答组 | 8.55 | 41.03 | 29.92 | 20.51 | |
| MHM | 努力作答组 | 28.84 | 41.77 | 21.12 | 8.27 |
| 不努力作答组 | 9.02 | 43.44 | 31.15 | 16.39 |
| 方法 | 卡方值 | 显著性 | 效应量 |
|---|---|---|---|
| OSR | 13.86 | 0.003 | 0.20 |
| CSR | 23.15 | <0.001 | 0.26 |
| CSRI | 38.72 | <0.001 | 0.34 |
| MHM | 29.41 | <0.001 | 0.30 |
表8 实证研究不同组被试在随机猜测比例上选择的卡方检验及效应量结果
| 方法 | 卡方值 | 显著性 | 效应量 |
|---|---|---|---|
| OSR | 13.86 | 0.003 | 0.20 |
| CSR | 23.15 | <0.001 | 0.26 |
| CSRI | 38.72 | <0.001 | 0.34 |
| MHM | 29.41 | <0.001 | 0.30 |
| 参数 | RD | RRMSD | ||||||
|---|---|---|---|---|---|---|---|---|
| OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | |
| a | 0.02 | 0.03 | 0.06 | 0.02 | 0.06 | 0.08 | 0.11 | 0.33 |
| b | 0.05 | 0.07 | 0.12 | 0.17 | 0.10 | 0.14 | 0.21 | 0.28 |
| α | -0.77 | -0.84 | -0.96 | -1.14 | 0.82 | 0.90 | 1.02 | 1.20 |
| β | -0.11 | -0.12 | -0.14 | -0.02 | 0.12 | 0.14 | 0.16 | 0.10 |
| θ | 0.00 | 0.00 | -0.01 | -0.03 | 0.10 | 0.11 | 0.15 | 0.21 |
| τ | 0.00 | 0.00 | 0.00 | 0.09 | 0.15 | 0.15 | 0.20 | 0.21 |
表9 实证研究不同方法和原始数据参数估计结果比较
| 参数 | RD | RRMSD | ||||||
|---|---|---|---|---|---|---|---|---|
| OSR | CSR | CSRI | MHM | OSR | CSR | CSRI | MHM | |
| a | 0.02 | 0.03 | 0.06 | 0.02 | 0.06 | 0.08 | 0.11 | 0.33 |
| b | 0.05 | 0.07 | 0.12 | 0.17 | 0.10 | 0.14 | 0.21 | 0.28 |
| α | -0.77 | -0.84 | -0.96 | -1.14 | 0.82 | 0.90 | 1.02 | 1.20 |
| β | -0.11 | -0.12 | -0.14 | -0.02 | 0.12 | 0.14 | 0.16 | 0.10 |
| θ | 0.00 | 0.00 | -0.01 | -0.03 | 0.10 | 0.11 | 0.15 | 0.21 |
| τ | 0.00 | 0.00 | 0.00 | 0.09 | 0.15 | 0.15 | 0.20 | 0.21 |
| 比较指标 | 标准化残差系列方法 | MHM | ||
|---|---|---|---|---|
| OSR | CSR | CSRI | ||
| 收敛情况 | 全部收敛 | 全部收敛 | 全部收敛 | 作答分类参数不易收敛 |
| 所需时间 | 短 | 短 | 较短 | 长 |
| 正确识别率 | 不如CSRI | 不如CSRI | 相对最好 | 不如CSRI |
| 错误识别率 | 相对较大 | 相对较大 | 相对较大 | 最低 |
| 参数估计准确性 | 不如CSRI | 不如CSRI | 相对较好, 但部分条件下对时间区分度估计误差较大 | 在数据符合其假设且两种作答反应时差异大的条件下较好 |
| 适用情况 | 不努力作答严重性低 | 不努力作答严重性低 | 不努力作答严重性高或中 | 不努力作答严重性高或中, 产生数据符合MHM假设, 两种作答反应时差异大 |
表10 研究中比较的4种方法特点小结
| 比较指标 | 标准化残差系列方法 | MHM | ||
|---|---|---|---|---|
| OSR | CSR | CSRI | ||
| 收敛情况 | 全部收敛 | 全部收敛 | 全部收敛 | 作答分类参数不易收敛 |
| 所需时间 | 短 | 短 | 较短 | 长 |
| 正确识别率 | 不如CSRI | 不如CSRI | 相对最好 | 不如CSRI |
| 错误识别率 | 相对较大 | 相对较大 | 相对较大 | 最低 |
| 参数估计准确性 | 不如CSRI | 不如CSRI | 相对较好, 但部分条件下对时间区分度估计误差较大 | 在数据符合其假设且两种作答反应时差异大的条件下较好 |
| 适用情况 | 不努力作答严重性低 | 不努力作答严重性低 | 不努力作答严重性高或中 | 不努力作答严重性高或中, 产生数据符合MHM假设, 两种作答反应时差异大 |
| [1] | Borghans, L., & Schils, T. (2012). The leaning tower of PISA: Decomposing achievement test scores into cognitive and noncognitive components. The Netherlands: School of Business and Economics, Maastricht University. |
| [2] |
Clark, M. E., Gironda, R. J., & Young, R. W. (2003). Detection of back random responding: Effectiveness of MMPI-2 and personality assessment inventory validity indices. Psychological Assessment, 15(2), 223-234.
doi: 10.1037/1040-3590.15.2.223 URL |
| [3] | Feinberg, R., & Jurich, D. (2018, April). Using rapid responses to evaluate test speededness. Paper presented at the meeting of the National Council of Measurement in Education (NCME), New York, NY. |
| [4] | Gelman, A., & Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences. Statistical Science, 7(4), 457-472. |
| [5] |
Hong, M., Rebouças, D. A., & Cheng, Y. (2021). Robust estimation for response time modeling. Journal of Educational Measurement. 58(2), 262-280.
doi: 10.1111/jedm.v58.2 URL |
| [6] |
Köhler, C., Pohl, S., & Carstensen, C. H. (2017). Dealing with item nonresponse in large-scale cognitive assessments: The impact of missing data methods on estimated explanatory relationships. Journal of Educational Measurement, 54(4), 397-419.
doi: 10.1111/jedm.2017.54.issue-4 URL |
| [7] |
Liu, Y., Cheng, Y., & Liu, H. (2020). Identifying effortful individuals with mixture modeling response accuracy and response time simultaneously to improve item parameter estimation. Educational and Psychological Measurement, 80(4), 775-807.
doi: 10.1177/0013164419895068 URL |
| [8] |
Liu, Y., & Liu, H. (2021). Detecting noneffortful responses based on a residual method using an iterative purification process. Journal of Educational and Behavioral Statistics, 46(6), 717-752.
doi: 10.3102/1076998621994366 URL |
| [9] |
Lu, J., Wang, C., Zhang, J., & Tao, J. (2020). A mixture model for responses and response times with a higher‐order ability structure to detect rapid guessing behaviour. British Journal of Mathematical and Statistical Psychology, 73(2), 261-288.
doi: 10.1111/bmsp.v73.2 URL |
| [10] |
Matzke, D., Love, J., & Heathcote, A. (2017). A Bayesian approach for estimating the probability of trigger failures in the stop-signal paradigm. Behavior Research Methods, 49(1), 267-281.
doi: 10.3758/s13428-015-0695-8 pmid: 26822670 |
| [11] |
McHugh, M. L. (2013). The chi-square test of independence. Biochemia medica, 23(2), 143-149.
pmid: 23894860 |
| [12] |
Molenaar, D., Bolsinova, M., & Vermunt, J. K. (2018). A semi-parametric within-subject mixture approach to the analyses of responses and response times. British Journal of Mathematical and Statistical Psychology, 71(2), 205-228.
doi: 10.1111/bmsp.2018.71.issue-2 URL |
| [13] |
Pastor, D. A., Ong, T. Q., & Strickman, S. N. (2019). Patterns of solution behavior across items in low-stakes assessments. Educational Assessment, 24(3), 189-212.
doi: 10.1080/10627197.2019.1615373 URL |
| [14] | Plummer, M. (2003, March). JAGS: A program for analysis of Bayesian graphical models using Gibbs sampling. Retrieved from https://www.r-project.org/conferences/DSC-2003/Drafts/Plummer. |
| [15] | Qian, H., Staniewska, D., Reckase, M., & Woo, A. (2016). Using response time to detect item preknowledge in computer-based licensure examinations. Educational Measurement: Issues and Practice, 35(1), 38-47. |
| [16] |
Ranger, J., Wolgast, A., & Kuhn, J. T. (2019). Robust estimation of the hierarchical model for responses and response times. British Journal of Mathematical and Statistical Psychology, 72(1), 83-107.
doi: 10.1111/bmsp.2019.72.issue-1 URL |
| [17] | R Development Core Team. (2009). R: A language and environment for statistical computing [Computer software Manual]. Vienna, Austria: Retrieved from http://www.Rproject. org (ISBN 3-900051-07-0) |
| [18] |
Rios, J. A., Guo, H., Mao, L., & Liu, O. L. (2017). Evaluating the impact of careless responding on aggregated-scores: To filter unmotivated examinees or not? International Journal of Testing, 17(1), 74-104.
doi: 10.1080/15305058.2016.1231193 URL |
| [19] | Rose, N. (2013). Item nonresponses in educational and psychological measurement (Unpublished doctorial dissertation). Friedrich Schiller University, Jena, Germany. |
| [20] |
Setzer, J. C., Wise, S. L., van den Heuvel, J. R., & Ling, G. (2013). An investigation of examinee test-taking effort on a large-scale assessment. Applied Measurement in Education, 26(1), 34-49.
doi: 10.1080/08957347.2013.739453 URL |
| [21] |
Ulitzsch, E., von Davier, M., & Pohl, S. (2020). A hierarchical latent response model for inferences about examinee engagement in terms of guessing and item‐level non‐response. British Journal of Mathematical and Statistical Psychology, 73(S1), 83-112.
doi: 10.1111/bmsp.v73.s1 URL |
| [22] |
van der Linden, W. J. (2007). A hierarchical framework for modeling speed and accuracy on test items. Psychometrika, 72(3), 287-308.
doi: 10.1007/s11336-006-1478-z URL |
| [23] |
van der Linden, W. J., & Guo, F. (2008). Bayesian procedures for identifying aberrant response-time patterns in adaptive testing. Psychometrika, 73(3), 365-384.
doi: 10.1007/s11336-007-9046-8 URL |
| [24] |
Wang, C., & Xu, G. (2015). A mixture hierarchical model for response times and response accuracy. British Journal of Mathematical and Statistical Psychology, 68(3), 456-477.
doi: 10.1111/bmsp.2015.68.issue-3 URL |
| [25] |
Wang, C., Xu, G., & Shang, Z. (2018). A two-stage approach to differentiating normal and aberrant behavior in computer based testing. Psychometrika, 83(1), 223-254.
doi: 10.1007/s11336-016-9525-x URL |
| [26] |
Wang, C., Xu, G., Shang, Z., & Kuncel, N. (2018). Detecting aberrant behavior and item preknowledge: A comparison of mixture modeling method and residual method. Journal of Educational and Behavioral Statistics, 43(4), 469-501.
doi: 10.3102/1076998618767123 URL |
| [27] |
Wise, S. L. (2015). Effort analysis: Individual score validation of achievement test data. Applied Measurement in Education, 28(3), 237-252.
doi: 10.1080/08957347.2015.1042155 URL |
| [28] |
Wise, S. L. (2017). Rapid-guessing behavior: Its identification, interpretation, and implications. Educational Measurement: Issues and Practice, 36(4), 52-61.
doi: 10.1111/emip.2017.36.issue-4 URL |
| [29] |
Wise, S. L., & DeMars, C. E. (2006). An application of item response time: The effort-moderated IRT model. Journal of Educational Measurement, 43(1), 19-38.
doi: 10.1111/jedm.2006.43.issue-1 URL |
| [30] |
Wise, S. L., & Kingsbury, G. G. (2016). Modeling student test- taking motivation in the context of an adaptive achievement test. Journal of Educational Measurement, 53(1), 86-105.
doi: 10.1111/jedm.12102 URL |
| [1] | 刘红云, 袁克海, 甘凯宇. 有中介的调节模型的拓展及其效应量[J]. 心理学报, 2021, 53(3): 322-336. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||