ISSN 1671-3710
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
CN 11-4766/R
主办:中国科学院心理研究所
出版:科学出版社
心理科学进展 ›› 2022, Vol. 30 ›› Issue (6): 1393-1409.doi: 10.3724/SP.J.1042.2022.01393 cstr: 32111.14.2022.01393
韩雨婷1, 肖悦2,3, 刘红云2,3( )
)
收稿日期:2021-08-04
出版日期:2022-06-15
发布日期:2022-04-26
基金资助:
HAN Yuting1, XIAO Yue2,3, LIU Hongyun2,3()
Received:2021-08-04
Online:2022-06-15
Published:2022-04-26
摘要:
基于计算机的问题解决测验可以实时记录被试探索环境和解决问题时的详细行动痕迹, 并保存为过程数据。首先介绍了过程数据的分析流程, 然后从问题解决测验入手, 分别对过程数据的特征抽取和能力估计建模两方面的研究进行了梳理和评价。未来研究应注意:提高分析结果的可解释性; 特征提取时纳入更多信息; 实现更复杂问题情景下的能力评估; 注重方法的实用性; 以及融合与借鉴不同领域的分析方法。
中图分类号:
韩雨婷, 肖悦, 刘红云. (2022). 问题解决测验中过程数据的特征抽取与能力评估. 心理科学进展 , 30(6), 1393-1409.
HAN Yuting, XIAO Yue, LIU Hongyun. (2022). Feature extraction and ability estimation of process data in the problem-solving test. Advances in Psychological Science, 30(6), 1393-1409.

图1 基于ECD的过程数据收集与分析流程
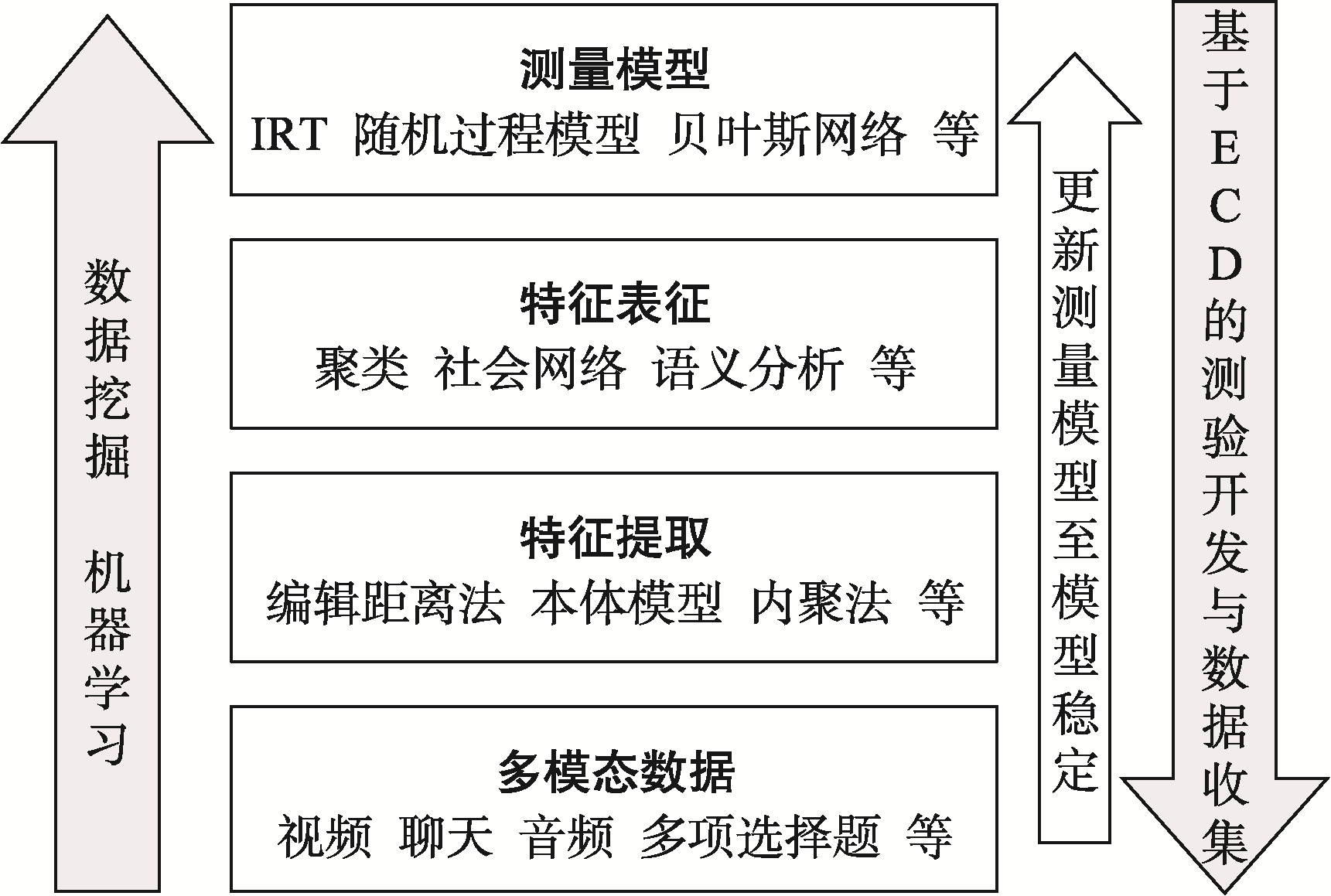
图2 计算心理测量学(改编自von Davier, 2017)
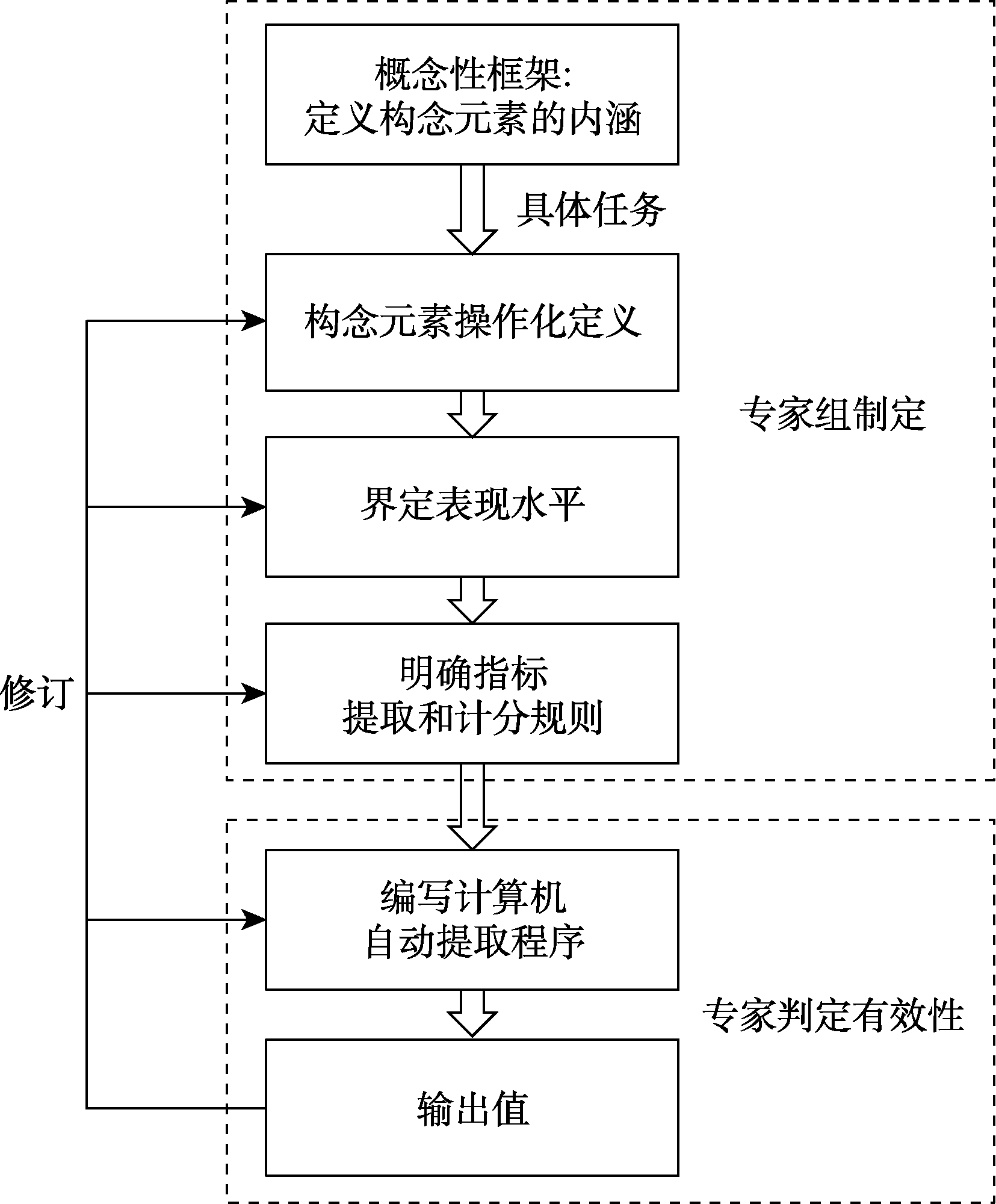
图3 自上而下的特征提取流程
| 类型 | 算法 | 适用情景 | 分析目的 | 后续分析 | 优势 | 不足 | |
|---|---|---|---|---|---|---|---|
| 自上 而下 | 专家制定评分或指标构建规则 | 所有类型的任务 | 构建指标提取和计分规则 | 用于能力估计 | 具有理论依据, 强解释性, 适用于传统测量模型分析 | 成本高; 信息遗漏 | |
| 自下 而上 | 基于 NLP | N-Gram | 可执行操作较少的任务 | 构建行为指标, 获得反应序列特征向量 | 识别关键操作序列; 用于能力估计 | 指标简单, 易于理解 | 指标笼统; 遗漏顺序信息; 信息损失大 |
| 编辑距离 | 存在最佳解决路径的任务 | 构建一个反映表现水平的指标 | 完善评分规则 | ||||
| 基于LCS的指标 | 存在最佳解决路径的任务 | 以跨任务概括的方式表征解决问题的策略特点 | 比较不同群体问题解决策略的特点 | ||||
| 降维 算法 | 自编码 | 所有类型的任务 | 将反应序列用数字特征向量表征, 以提取反应序列中的全部信息 | 预测考生的最终反应, 以及在其他项目和各种认知特征上的表现; 用来提高能力估计精度 | 信息抽取全面 | 缺乏可解释性 | |
| MDS | |||||||
| 网络 分析 | 社会网络分析 | 所有类型的任务 | 可视化反应过程, 提取反应过程网络图的特征 | 预测表现; 分析高低组反应模式差异 | 可视化 | 预处理程序复杂; 难以捕获网络节点内涵; 无法直接应用于能力估计 | |
表1 基于计算机的问题解决测验过程数据的特征抽取方法总结
| 类型 | 算法 | 适用情景 | 分析目的 | 后续分析 | 优势 | 不足 | |
|---|---|---|---|---|---|---|---|
| 自上 而下 | 专家制定评分或指标构建规则 | 所有类型的任务 | 构建指标提取和计分规则 | 用于能力估计 | 具有理论依据, 强解释性, 适用于传统测量模型分析 | 成本高; 信息遗漏 | |
| 自下 而上 | 基于 NLP | N-Gram | 可执行操作较少的任务 | 构建行为指标, 获得反应序列特征向量 | 识别关键操作序列; 用于能力估计 | 指标简单, 易于理解 | 指标笼统; 遗漏顺序信息; 信息损失大 |
| 编辑距离 | 存在最佳解决路径的任务 | 构建一个反映表现水平的指标 | 完善评分规则 | ||||
| 基于LCS的指标 | 存在最佳解决路径的任务 | 以跨任务概括的方式表征解决问题的策略特点 | 比较不同群体问题解决策略的特点 | ||||
| 降维 算法 | 自编码 | 所有类型的任务 | 将反应序列用数字特征向量表征, 以提取反应序列中的全部信息 | 预测考生的最终反应, 以及在其他项目和各种认知特征上的表现; 用来提高能力估计精度 | 信息抽取全面 | 缺乏可解释性 | |
| MDS | |||||||
| 网络 分析 | 社会网络分析 | 所有类型的任务 | 可视化反应过程, 提取反应过程网络图的特征 | 预测表现; 分析高低组反应模式差异 | 可视化 | 预处理程序复杂; 难以捕获网络节点内涵; 无法直接应用于能力估计 | |
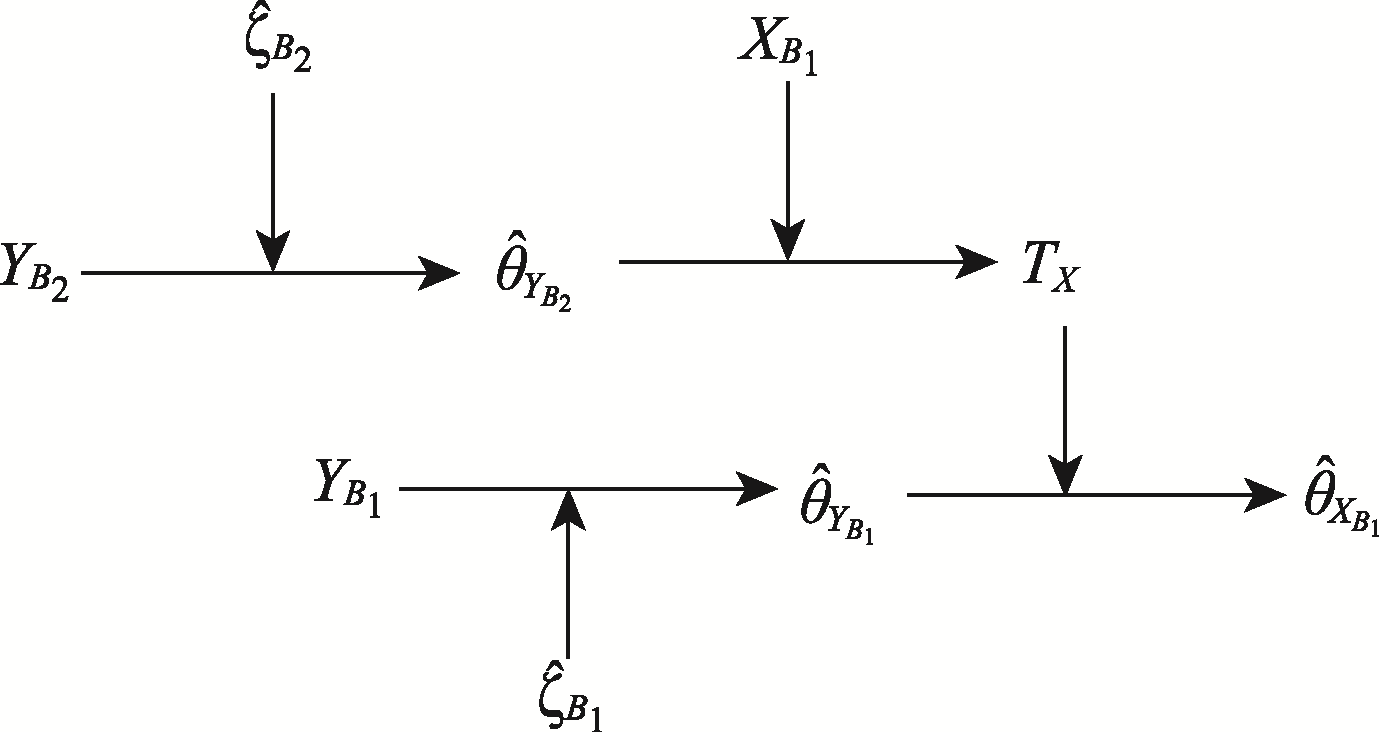
图4 两步条件期望法构造潜在特质估计值$\hat{\theta}_{X_{B_{1}}}$的流程图(Zhang et al., 2020)
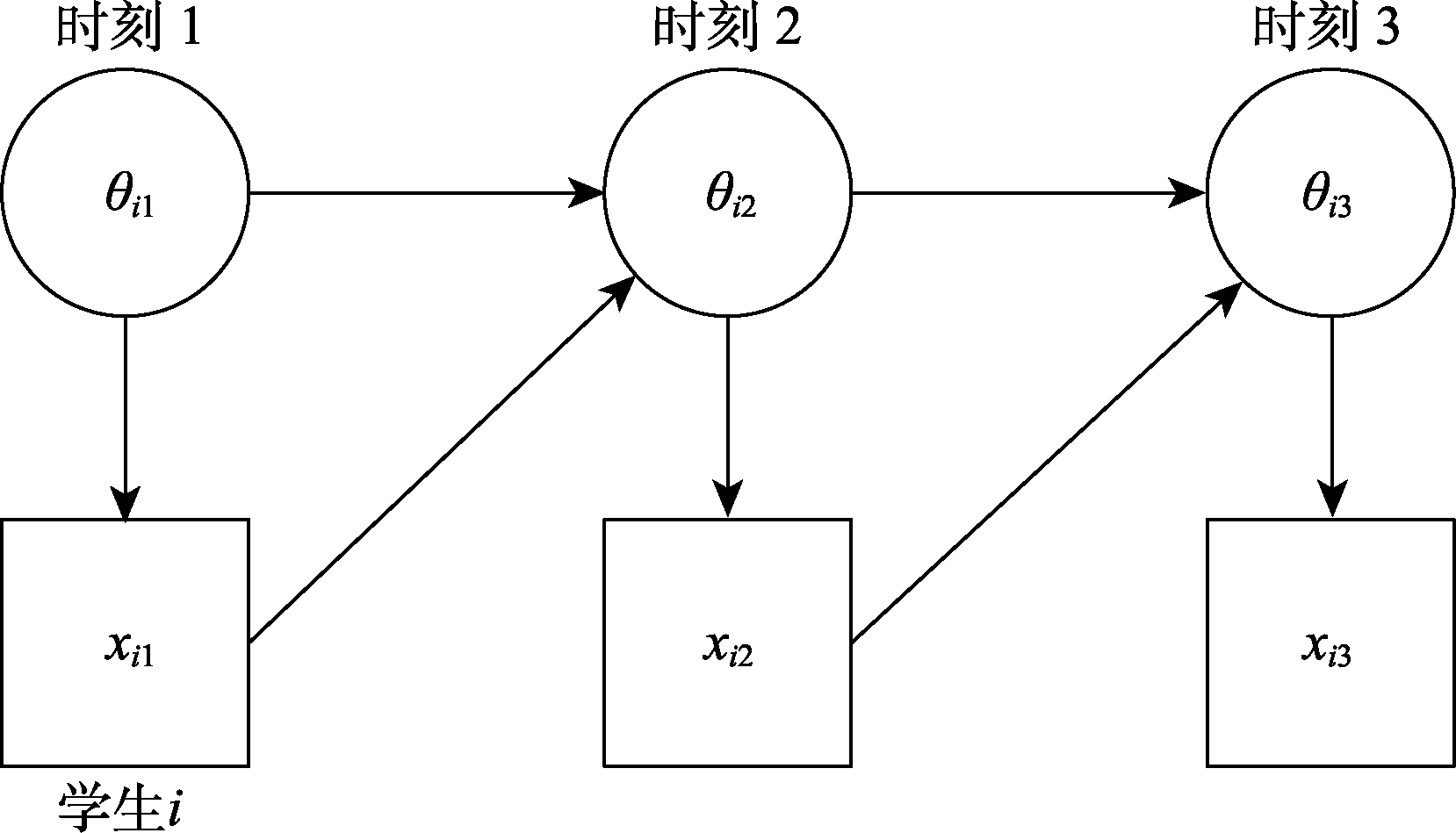
图5 一个DBN的路径图(Levy & Mislevy, 2016, page 384)
| 类型 | 模型 | 适用情景 | 过程指标要求 | 优势 | 不足 | 实证数据集 | 模型分析软件 |
|---|---|---|---|---|---|---|---|
| 心理测量模型 主要关注潜在能力的估计 | 多维IRT模型(Hesse et al., | 测验结构多维 | 需提前定义好指标与各个维度间的关系 | 具有理论依据, 估计得到的潜在能力值有明确的心理学含义 | 受限于指标定义方式, 可能造成信息的遗漏, 无法对行为顺序进行分析 | ATC21S合作问题解决测验 | ConQuest 2.0软件 (Wu et al. |
| 多水平IRT模型(Wilson et al., | 小组合作测验 | 需提前定义指标与测量构念的关系 | ATC21S-ICT测验 | Mplus软件(Muthén & Muthén, | |||
| 诊断分类模型(Zhan & Qiao, | 操作集有限的简单任务 | 标定过Q矩阵的指标 | 在评估被试连续的潜在问题解决能力的同时, 为被试的问题解决策略提供更详细的诊断信息 | 所用指标无法反应序列的整体顺序及操作频率; Q矩阵标定成本高 | PISA 2012问题解决测验“车票”单元CP038Q01题目 | R程序包GDINA (Ma & de la Torre, R程序包TAM (Robitzsch et al., | |
| 改进的多水平混合IRT模型(Liu et al., | 路径清晰且可穷举的任务 | 提前判定每种可选操作的正误, 并采取累积编码计分 | 利用信息全面; 可以同时估计出过程水平和个体水平上估计能力值, 并且对过程水平策略进行分类 | 具有任务特异性的独特编码形式; 学生水平能力估计值仅利用最后一步的作答信息 | PISA 2012问题解决测验“交通”单元CP007Q02题目 | Mplus软件(Muthén and Muthén, | |
| 两步条件期望方法(Zhang et al., | 无特殊要求 | 包含过程信息的特征向量 | 在对潜在特质进行估计时纳入了过程信息 | 利用的过程信息具有解释性问题 | PIAAC 2012的PSTRE测验 | R程序包glmnet (Friedman et al., | |
| 随机过程模型 主要关注对随机过程建模 | 隐马尔可夫模型(Bergner et al., | 潜在状态随进程发生变化的任务 | 指标在时间上连续 | 保持反应序列的序列结构; 使用潜在状态对不同的潜在特质和技能建模, 从而实现认知诊断 | 无法如心理测量模型那样获得与被试潜在能力相符合的连续且稳定的估计值 | 自适应同伴辅导系统(Walker et al., | Matlab Bayes Net工具箱(Murphy, |
| 动态贝叶斯网络(Levy, | 指标在时间上连续, 指标与潜在特质之间有明确的对应关系 | 教育游戏Save Patch (Chung et al., | OpenBUGS软件(Lunn et al., | ||||
| 类型 | 模型 | 适用情景 | 过程指标要求 | 优势 | 不足 | 实证数据集 | 模型分析软件 |
| 结合随机过程思想的测量模型 在对随机过程建模基础上进行能力估计 | 马尔可夫IRT模型(Shu et al., | 操作集有限的简单任务, 且操作转移在整个反应过程中的正误不变 | 过程指标即操作转移, 需提前判定各个操作转移的正误并计分 | 同时考虑了正确与错误的操作及其频率, 利用信息较为全面 | 将反应序列分割为离散的操作转移指标, 丢失了顺序信息; 所利用的操作序列在实际应用具有局限性 | NAEP-TEL的泵修理任务 | MIRT软件(Haberman, |
| 连续时间动态选择模型(Chen, | 事件有限的简单任务 | 提前判定任务中每种事件的有效性, 获取每个事件对应的时间戳 | 可以基于一个或多个任务上的过程数据估计出每个学生的问题解决能力和操作速度 | 每个任务仅有一个难度参数, 无法区分反应过程中每种事件的独特属性 | PISA 2012问题解决测验中“车票”单元题目CP038Q01和题目CP038Q02 | 自编最大边际似然估计程序 | |
| 马尔可夫决策过程测量模型(Lamar, | 状态集和操作集都明确的结构良好的任务 | 提前为各种操作和/或结果定义合理的奖励参数 | 利用强化学习原理考虑多步骤信息对能力进行估计 | 模型需要设定参数较多, 释放参数自由估计可能导致估计值不合理 | 公开教育游戏Microbes (Red Hill Studios, n.d.) | C++程序语言自编参数估计程序 | |
| 序列反应模型(Han et al., | 有最佳解决策略的结构良好任务 | 提前区分每种状态转移的正误 | 可以利用完整的反应序列, 获得被试能力参数和每个状态转移的倾向性参数 | 结构不良问题情景中的数据预处理方式仍需进一步探讨 | PISA 2012问题解决测验“车票”单元CP038Q02题目 | R语言自编贝叶斯估计程序 |
表2 基于计算机的问题解决测验过程数据的能力评估模型总结
| 类型 | 模型 | 适用情景 | 过程指标要求 | 优势 | 不足 | 实证数据集 | 模型分析软件 |
|---|---|---|---|---|---|---|---|
| 心理测量模型 主要关注潜在能力的估计 | 多维IRT模型(Hesse et al., | 测验结构多维 | 需提前定义好指标与各个维度间的关系 | 具有理论依据, 估计得到的潜在能力值有明确的心理学含义 | 受限于指标定义方式, 可能造成信息的遗漏, 无法对行为顺序进行分析 | ATC21S合作问题解决测验 | ConQuest 2.0软件 (Wu et al. |
| 多水平IRT模型(Wilson et al., | 小组合作测验 | 需提前定义指标与测量构念的关系 | ATC21S-ICT测验 | Mplus软件(Muthén & Muthén, | |||
| 诊断分类模型(Zhan & Qiao, | 操作集有限的简单任务 | 标定过Q矩阵的指标 | 在评估被试连续的潜在问题解决能力的同时, 为被试的问题解决策略提供更详细的诊断信息 | 所用指标无法反应序列的整体顺序及操作频率; Q矩阵标定成本高 | PISA 2012问题解决测验“车票”单元CP038Q01题目 | R程序包GDINA (Ma & de la Torre, R程序包TAM (Robitzsch et al., | |
| 改进的多水平混合IRT模型(Liu et al., | 路径清晰且可穷举的任务 | 提前判定每种可选操作的正误, 并采取累积编码计分 | 利用信息全面; 可以同时估计出过程水平和个体水平上估计能力值, 并且对过程水平策略进行分类 | 具有任务特异性的独特编码形式; 学生水平能力估计值仅利用最后一步的作答信息 | PISA 2012问题解决测验“交通”单元CP007Q02题目 | Mplus软件(Muthén and Muthén, | |
| 两步条件期望方法(Zhang et al., | 无特殊要求 | 包含过程信息的特征向量 | 在对潜在特质进行估计时纳入了过程信息 | 利用的过程信息具有解释性问题 | PIAAC 2012的PSTRE测验 | R程序包glmnet (Friedman et al., | |
| 随机过程模型 主要关注对随机过程建模 | 隐马尔可夫模型(Bergner et al., | 潜在状态随进程发生变化的任务 | 指标在时间上连续 | 保持反应序列的序列结构; 使用潜在状态对不同的潜在特质和技能建模, 从而实现认知诊断 | 无法如心理测量模型那样获得与被试潜在能力相符合的连续且稳定的估计值 | 自适应同伴辅导系统(Walker et al., | Matlab Bayes Net工具箱(Murphy, |
| 动态贝叶斯网络(Levy, | 指标在时间上连续, 指标与潜在特质之间有明确的对应关系 | 教育游戏Save Patch (Chung et al., | OpenBUGS软件(Lunn et al., | ||||
| 类型 | 模型 | 适用情景 | 过程指标要求 | 优势 | 不足 | 实证数据集 | 模型分析软件 |
| 结合随机过程思想的测量模型 在对随机过程建模基础上进行能力估计 | 马尔可夫IRT模型(Shu et al., | 操作集有限的简单任务, 且操作转移在整个反应过程中的正误不变 | 过程指标即操作转移, 需提前判定各个操作转移的正误并计分 | 同时考虑了正确与错误的操作及其频率, 利用信息较为全面 | 将反应序列分割为离散的操作转移指标, 丢失了顺序信息; 所利用的操作序列在实际应用具有局限性 | NAEP-TEL的泵修理任务 | MIRT软件(Haberman, |
| 连续时间动态选择模型(Chen, | 事件有限的简单任务 | 提前判定任务中每种事件的有效性, 获取每个事件对应的时间戳 | 可以基于一个或多个任务上的过程数据估计出每个学生的问题解决能力和操作速度 | 每个任务仅有一个难度参数, 无法区分反应过程中每种事件的独特属性 | PISA 2012问题解决测验中“车票”单元题目CP038Q01和题目CP038Q02 | 自编最大边际似然估计程序 | |
| 马尔可夫决策过程测量模型(Lamar, | 状态集和操作集都明确的结构良好的任务 | 提前为各种操作和/或结果定义合理的奖励参数 | 利用强化学习原理考虑多步骤信息对能力进行估计 | 模型需要设定参数较多, 释放参数自由估计可能导致估计值不合理 | 公开教育游戏Microbes (Red Hill Studios, n.d.) | C++程序语言自编参数估计程序 | |
| 序列反应模型(Han et al., | 有最佳解决策略的结构良好任务 | 提前区分每种状态转移的正误 | 可以利用完整的反应序列, 获得被试能力参数和每个状态转移的倾向性参数 | 结构不良问题情景中的数据预处理方式仍需进一步探讨 | PISA 2012问题解决测验“车票”单元CP038Q02题目 | R语言自编贝叶斯估计程序 |
| [1] | 李航. (2012). 统计学习方法. 北京: 清华大学出版社. |
| [2] | 李美娟. (2020). 基于过程数据的合作问题解决评分和测量模型研究 (博士学位论文). 北京师范大学. |
| [3] | 李美娟, 刘玥, 刘红云. (2020). 计算机动态测验中问题解决过程策略的分析: 多水平混合IRT模型的拓展与应用. 心理学报, 52(4), 528-540. |
| [4] | 陆璟. (2017). 基于log数据的国际学生评估项目(PISA)问题解决能力研究 (博士学位论文). 华东师范大学, 上海. |
| [5] | 骆文淑, 赵守盈. (2005). 多维尺度法及其在心理学领域中的应用. 中国考试, (4), 27-30. |
| [6] | 王永锋, 王以宁, 何克抗. (2007). 从“学习使用技术”到“使用技术学习”--解读新版美国“国家学生教育技术标准”. 电化教育研究, (12), 82-85. |
| [7] | 徐伟, 陈光辉, 曾玉, 张文新. (2011). 关系研究的新取向: 社会网络分析. 心理科学, 34(2), 499-504. |
| [8] | 袁建林. (2018). 基于行为过程表现测量合作问题解决能力的研究 (博士学位论文). 北京师范大学. |
| [9] | 袁建林, 刘红云, 张生. (2016). 数字化测验环境中学生问题解决能力影响因素分析--以PISA 2012为例. 中国电化教育, (8), 74-81. |
| [10] | Adams R., Vista A., Scoular C., Awwal N., Griffin P., & Care E. (2015). Automatic coding procedures for collaborative problem solving. In P. Griffin & E. Care (Eds.), Assessment and teaching of 21st century skills: Methods and approach (pp. 115-132). Dordrecht: Springer. |
| [11] |
Adams R. J., Wilson M., & Wang W. C. (1997). The multidimensional random coefficients multinomial logit model. Applied Psychological Measurement, 21(1), 1-23.
doi: 10.1177/0146621697211001 URL |
| [12] | Amer M. R., Siddiquie B., Khan S., Divakaran A., & Sawhney H. (2014). Multimodal fusion using dynamic hybrid models. In IEEE winter conference on applications of computer vision (pp.556-563). New York, NY: IEEE. |
| [13] |
Arieli-Attali M., Ou L., & Simmering V. R. (2019). Understanding test takers’ choices in a self-adapted test: A hidden Markov modeling of process data. Frontiers in Psychology, 10, 83.
doi: 10.3389/fpsyg.2019.00083 pmid: 30787889 |
| [14] | Bejar I. I., Mislevy R. J., & Zhang M. (2016). Automated scoring with validity in mind. In A. A. Rupp & J. P. Leighton (Eds.), The Wiley handbook of cognition and assessment (pp. 226-246). Hoboken, NJ: Wiley-Blackwell. |
| [15] | Bellman R. (1957). A markovian decision process. Journal of Mathematics and Mechanics, 6(5), 679-684. |
| [16] | Bergner Y., Walker E., & Ogan A. (2017). Dynamic bayesian network models for peer tutoring interactions. In A. A. von Davier, M. Zhu, & P. C. Kyllonen (Eds.), Innovative assessment of collaboration (pp. 249-268). Cham: Springer. |
| [17] |
Chen Y. (2020). A continuous-time dynamic choice measurement model for problem-solving process data. Psychometrika, 85(4), 1052-1075.
doi: 10.1007/s11336-020-09734-1 URL |
| [18] | Cho S. J., & Cohen A. S. (2010). A multilevel mixture IRT model with an application to DIF. Journal of Educational and Behavioral Statistics, 35(3), 336-370. |
| [19] | Chung G. K. W. K., Baker E. L., Vendlinski T. P., Buschang R., Delacruz G. C., Michiuye J. K., & Bittick S. J. (2010, April). Testing instructional design variations in a prototype math game. In R. Atkinson (Chair), Current perspectives from three national R&D centers focused on game-based learning: Issues in learning, instruction, assessment, and game design. Poster session presented at the Annual Meeting of the American Educational Research Association, Denver, CO. |
| [20] | Davis J. A., & Leinhardt S. (1972). The structure of positive interpersonal relations in small groups. In J. Berger (Ed.), Sociological theories in progress (Vol. 2, pp. 218-251). Boston, MA: Houghton Mifflin. |
| [21] | Friedman J., Hastie T., & Tibshirani R. (2009). Glmnet: Lasso and elastic-net regularized generalized linear models [R package version]. Retrieved August 4, 2021, from https://cran.r-project.org/web/packages/glmnet/ |
| [22] | Goodfellow I., Bengio Y., & Courville A. (2016). Deep learning. Cambridge, MA: MIT Press. |
| [23] | Haberman S. J. (2013). A general program for item-response analysis that employs the stabilized Newton-Raphson algorithm (No. ETS RR-13-32). Princeton, NJ: Educational Testing Service. |
| [24] | Han Y., Liu H., & Ji F. (2021). A sequential response model for analyzing process data on technology-based problem-solving tasks. Multivariate Behavioral Research. Advance online publication. https://doi.org/10.1080/00273171.2021.1932403 |
| [25] | Hao J., Shu Z., & von Davier A. (2015). Analyzing process data from game/scenario-based tasks: An edit distance approach. Journal of Educational Data Mining, 7(1), 33-50. |
| [26] | Harding S. M. E., Griffin P. E., Awwal N., Alom B. M., & Scoular C. (2017). Measuring collaborative problem solving using mathematics-based tasks. AERA Open, 3(3), 1-19. |
| [27] | He Q., Borgonovi F., & Paccagnella M. (2021). Leveraging process data to assess adults’ problem-solving skills: Using sequence mining to identify behavioral patterns across digital tasks. Computers & Education, 166, 104170. |
| [28] | He Q., & von Davier M. (2016). Analyzing process data from problem-solving items with N-grams:Insights from a computer-based large-scale assessment. In R. Yigal, F. Steve, & M. Maryam (Eds.), Handbook of research on technology tools for real-world skill development (pp. 749-776). Hershey, PA: Information Science Reference. |
| [29] | Hesse F., Care E., Buder J., Sassenberg K., & Griffin P. (2015). A framework for teachable collaborative problem solving skills. In P. Griffin & E. Care (Eds.), Assessment and teaching of 21st century skills: Methods and approach (pp. 37-56). Dordrecht: Springer. |
| [30] | Højsgaard S. (2012). Graphical independence networks with the gRain package for R. Journal of Statistical Software, 46(10), 1-26. |
| [31] | Iseli M. R., Koenig A. D., Lee J. J., & Wainess R. (2010). Automatic assessment of complex task performance in games and simulations (CRESST Report 775). Los Angeles,CA: University of California, National Center for Research on Evaluation, Standards, and Student Testing. |
| [32] | Kamata A., & Cheong Y. F. (2007). Multilevel rasch models. In M. von Davier & C. H. Carstensen (Eds.), Multivariate and mixture distribution rasch models: Extensions and applications (pp. 217-232). New York, NY: Springer. |
| [33] |
Käser T., Klingler S., Schwing A. G., & Gross M. (2017). Dynamic Bayesian networks for student modeling. IEEE Transactions on Learning Technologies, 10(4), 450-462.
doi: 10.1109/TLT.2017.2689017 URL |
| [34] | Khan S., Cheng H., & Kumar R. (2013). A hierarchical behavior analysis approach for automated trainee performance evaluation in training ranges. In D. D. Schmorrow & C. M. Fidopiastis (Eds.), Foundations of augmented cognition: Proceedings of HCI international 2013 (pp. 60-69). Berlin: Springer. |
| [35] | Khan S. M. (2017). Multimodal behavioral analytics in intelligent learning and assessment systems. In A. A. von Davier, M. Zhu, & P. C. Kyllonen (Eds.), Innovative assessment of collaboration (pp. 173-184). Cham: Springer. |
| [36] |
LaMar M. M. (2018). Markov decision process measurement model. Psychometrika, 83(1), 67-88.
doi: 10.1007/s11336-017-9570-0 URL |
| [37] | Levenshtein V. I. (1966). Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady, 10(8), 707-710. |
| [38] |
Levy R. (2019). Dynamic Bayesian network modeling of game-based diagnostic assessments. Multivariate Behavioral Research, 54(6), 771-794.
doi: 10.1080/00273171.2019.1590794 pmid: 30942094 |
| [39] | Levy R., & Mislevy R. J. (2016). Bayesian psychometric modeling. Boca Raton, FL: Chapman & Hall/CRC Press. |
| [40] |
Liu H., Liu Y., & Li M. (2018). Analysis of process data of PISA 2012 computer-based problem solving: Application of the modified multilevel mixture IRT model. Frontiers in Psychology, 9, 1372.
doi: 10.3389/fpsyg.2018.01372 URL |
| [41] | Liu O. L., Mao L., Frankel L., & Xu J. (2016). Assessing critical thinking in higher education: The HEIghtenTM approach and preliminary validity evidence. Assessment & Evaluation in Higher Education, 41(5), 677-694. |
| [42] |
Lunn D., Spiegelhalter D., Thomas A., & Best N. (2009). The BUGS project: Evolution, critique and future directions. Statistics in Medicine, 28(25), 3049-3067.
doi: 10.1002/sim.3680 URL |
| [43] | Ma W., & de la Torre J. (2020). GDINA: An R package for cognitive diagnosis modeling. Journal of Statistical Software, 93(14), 1-26. |
| [44] | Mayer R. E., & Wittrock M. C. (2006). Problem solving. In P. A. Alexander & P. H. Winne (Eds.), Handbook of educational psychology (2nd ed., pp. 287-304). Mahwah, NJ: Erlbaum. |
| [45] |
Mislevy R. J. (2019). Advances in measurement and cognition. The ANNALS of the American Academy of Political and Social Science, 683(1), 164-182.
doi: 10.1177/0002716219843816 URL |
| [46] | Mislevy R. J., Steinberg L. S., Almond R. G., & Lukas J. F. (2006). Concepts, terminology, and basic models of evidence-centered design. In D. M. Williamson, R. J. Mislevy, & I. I. Bejar (Eds.), Automated scoring of complex tasks in computer-based testing (pp. 15-48). Mahwah, NJ: Lawrence Erlbaum. |
| [47] |
Morency L.-P., de Kok I., & Gratch J. (2010). A probabilistic multimodal approach for predicting listener backchannels. Autonomous Agents and Multi-Agent Systems, 20(1), 70-84.
doi: 10.1007/s10458-009-9092-y URL |
| [48] | Murphy K. P. (2001). The bayes net toolbox for matlab. Computing science and statistics, 33(2), 1024-1034. |
| [49] | Muthén L. K., & Muthén B. O. (1998- 2015). Mplus user’s guide (7th ed.). Los Angeles, CA: Muthén and Muthén. |
| [50] | Organisation for Economic Co-operation and Development. (2013). PISA 2012 assessment and analytical framework: Mathematics, reading, science, problem solving and financial literacy. Paris: OECD Publishing. |
| [51] | Organisation for Economic Co-operation and Development. (2017). PISA 2015 assessment and analytical framework: Science, reading, mathematic, financial literacy and collaborative problem solving (Rev. ed.). Paris: OECD Publishing. |
| [52] | Puterman M. L. (1994). Markov decision processes. New York, NY: Wiley. |
| [53] |
Raudenbush S. W., Johnson C., & Sampson R. J. (2003). A multivariate, multilevel Rasch model with application to self-reported criminal behavior. Sociological Methodology, 33(1), 169-211.
doi: 10.1111/j.0081-1750.2003.t01-1-00130.x URL |
| [54] | Red Hill Studios. (n.d.). Lifeboat to mars. Retrieved August 4, 2021, from http://www.pbskids.org/lifeboat |
| [55] |
Reichenberg R. (2018). Dynamic Bayesian networks in educational measurement: Reviewing and advancing the state of the field. Applied Measurement in Education, 31(4), 335-350.
doi: 10.1080/08957347.2018.1495217 URL |
| [56] | Reye J. (2004). Student modelling based on belief networks. International Journal of Artificial Intelligence in Education, 14(1), 63-96. |
| [57] | Robitzsch A., Kiefer T., & Wu M. (2020). TAM: Test analysis modules [R package version 3.5-19]. Retrieved August 4, 2021, from http://CRAN.R-project.org/package=TAM |
| [58] |
Rosen Y. (2017). Assessing students in human-to-agent settings to inform collaborative problem-solving learning. Journal of Educational Measurement, 54(1), 36-53.
doi: 10.1111/jedm.12131 URL |
| [59] | Rowe J. P., & Lester J. C. (2010). Modeling user knowledge with dynamic Bayesian networks in interactive narrative environments. In G. M. Youngblood & V. Bulitko (Eds.), Proceedings of the sixth AAAI conference on artificial intelligence and interactive digital entertainment (pp. 57-62). Menlo Park, CA: AAAI Press. |
| [60] |
Schleicher A. (2008). Piaac: A new strategy for assessing adult competencies. International Review of Education, 54(5), 627-650.
doi: 10.1007/s11159-008-9105-0 URL |
| [61] | Shu Z., Bergner Y., Zhu M., Hao J., & von Davier A. A. (2017). An item response theory analysis of problem- solving processes in scenario-based tasks. Psychological Test and Assessment Modeling, 59(1), 109-131. |
| [62] |
Siddiq F., Gochyyev P., & Wilson M. (2017). Learning in digital networks - ICT literacy: A novel assessment of students’ 21st century skills. Computers & Education, 109, 11-37.
doi: 10.1016/j.compedu.2017.01.014 URL |
| [63] | Siddiquie B., Khan S., Divakaran A., & Sawhney H. (2013). Affect analysis in natural human interaction using joint hidden conditional random fields. In Proceedings of the 2013 IEEE international conference on multimedia and expo (ICME) (pp. 1-6). New York, NY: IEEE. |
| [64] |
Song Y., & Sparks J. R. (2019). Measuring argumentation skills through a game-enhanced scenario-based assessment. Journal of Educational Computing Research, 56(8), 1324- 1344.
doi: 10.1177/0735633117740605 |
| [65] |
Tang X., Wang Z., He Q., Liu J., & Ying Z. (2020). Latent feature extraction for process data via multidimensional scaling. Psychometrika, 85(2), 378-397.
doi: 10.1007/s11336-020-09708-3 URL |
| [66] | Tang X., Wang Z., Liu J., & Ying Z. (2021). An exploratory analysis of the latent structure of process data via action sequence autoencoders. British Journal of Mathematical and Statistical Psychology, 74(1), 1-33. |
| [67] |
Tang X., Zhang S., Wang Z., Liu J., & Ying Z. (2021). Procdata: An R package for process data analysis. Psychometrika, 86(4), 1058-1083.
doi: 10.1007/s11336-021-09798-7 URL |
| [68] | Technology and Engineering Literacy. (2013). Technology and engineering literacy assessments. Retrieved August 4, 2021, from https://nces.ed.gov/nationsreportcard/tel/ |
| [69] | VanLehn K. (2008). Intelligent tutoring systems for continuous, embedded assessment. In C. Dwyer (Ed.), The future of assessment: Shaping teaching and learning (pp. 113-138). Mahwah, NJ: Erlbaum. |
| [70] | Venables W. N., & Ripley B. D. (2002). Modern applied statistics with S-Plus(4th ed.). New York, NY: Springer. |
| [71] | Visser I., & Speekenbrink M. (2010). depmixS4: An R package for hidden Markov models. Journal of Statistical Software, 36(7), 1-21. |
| [72] |
Vista A., Care E., & Awwal N. (2017). Visualising and examining sequential actions as behavioural paths that can be interpreted as markers of complex behaviours. Computers in Human Behavior, 76, 656-671.
doi: 10.1016/j.chb.2017.01.027 URL |
| [73] |
von Davier A. A. (2017). Computational psychometrics in support of collaborative educational assessments. Journal of Educational Measurement, 54(1), 3-11.
doi: 10.1111/jedm.12129 URL |
| [74] | von Davier M., & Lee Y. S. (2019). Handbook of diagnostic classification models: Models and model extensions, applications, software packages. New York, NY: Springer. |
| [75] |
Walker E., Rummel N., & Koedinger K. R. (2009). CTRL: A research framework for providing adaptive collaborative learning support. User Modeling and User-Adapted Interaction, 19(5), 387-431.
doi: 10.1007/s11257-009-9069-1 URL |
| [76] | Wasserman S., & Faust K. (1994). Social network analysis: Methods and applications. Cambridge: Cambridge University Press. |
| [77] |
Wilson M., Gochyyev P., & Scalise K. (2017). Modeling data from collaborative assessments: Learning in digital interactive social networks. Journal of Educational Measurement, 54(1), 85-102.
doi: 10.1111/jedm.12134 URL |
| [78] | Wu M., Adams R. J., Wilson M., & Haldane S. A. (2007). ConQuest: Generalised item response modelling software (version 2.0). Camberwell: ACER Press. |
| [79] |
Xiao Y., He Q., Veldkamp B., & Liu H. (2021). Exploring latent states of problem-solving competence using hidden Markov model on process data. Journal of Computer Assisted Learning, 37(5), 1232-1247.
doi: 10.1111/jcal.12559 URL |
| [80] |
Yuan J., Xiao Y., & Liu H. (2019). Assessment of collaborative problem solving based on process stream data: A new paradigm for extracting indicators and modeling dyad data. Frontiers in Psychology, 10, 369.
doi: 10.3389/fpsyg.2019.00369 URL |
| [81] | Zhan S., Hao J., & Davier A. V. (2015). Analyzing process data from game/scenario based tasks: An edit distance approach. Journal of Educational Data Mining, 7(1), 33-50. |
| [82] | Zhan P., & Qiao X. (2020). A diagnostic classification analysis of problem-solving competence using process data. PsyArXiv. Retrieved August 4, 2021, from https://doi.org/10.31234/osf.io/wtyae |
| [83] | Zhang S., Wang Z., Qi J., Liu J., & Ying Z. (2020). Accurate assessment via process data. Retrieved August 4, 2021, from http://www.columbia.edu/-zw2393/publication/process_data_scoring/process_data_scoring . |
| [84] |
Zhu M., Shu Z., & von Davier A. A. (2016). Using networks to visualize and analyze process data for educational assessment. Journal of Educational Measurement, 53(2), 190-211.
doi: 10.1111/jedm.12107 URL |
| [85] | Zoanetti N. (2010). Interactive computer based assessment tasks: How problem-solving process data can inform instruction. Australasian Journal of Educational Technology, 26(5), 585-606. |
| [1] | 刘耀辉, 徐慧颖, 陈琦鹏, 詹沛达. 基于过程数据的问题解决能力测量及数据分析方法[J]. 心理科学进展, 2022, 30(3): 522-535. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||