ISSN 0439-755X
CN 11-1911/B
CN 11-1911/B
Acta Psychologica Sinica ›› 2026, Vol. 58 ›› Issue (3): 416-436.doi: 10.3724/SP.J.1041.2026.0416
• Academic Papers of the 27th Annual Meeting of the China Association for Science and Technology • Previous Articles Next Articles
ZHOU Lei1, LI Litong1, WANG Xu1, OU Huafeng1, HU Qianyu1, LI Aimei2( ), GU Chenyan1()
), GU Chenyan1()
Received:2025-05-12
Published:2026-03-25
Online:2025-12-26
Contact:
LI Aimei,GU Chenyan
E-mail:tliaim@jnu.edu.cn;g_cy1989163@163.com
Supported by:ZHOU Lei, LI Litong, WANG Xu, OU Huafeng, HU Qianyu, LI Aimei, GU Chenyan. (2026). Large language models capable of distinguishing between single and repeated gambles: Understanding and intervening in risky choice. Acta Psychologica Sinica, 58(3), 416-436.
Add to citation manager EndNote|Ris|BibTeX
URL: https://journal.psych.ac.cn/acps/EN/10.3724/SP.J.1041.2026.0416
| Gambling Task | |||
|---|---|---|---|
| Gain Outcome | Loss Outcome | ||
| Amount (CNY) | Probability (%) | Amount (CNY) | Probability (%) |
| +10000 | 10 | ?278 | 10 |
| +5000 | 20 | ?313 | 20 |
| +3333 | 30 | ?357 | 30 |
| +2500 | 40 | ?417 | 40 |
| +2000 | 50 | ?500 | 50 |
| +1667 | 60 | ?625 | 60 |
| +1429 | 70 | ?833 | 70 |
| +1250 | 80 | ?1250 | 80 |
| +1111 | 90 | ?2500 | 90 |
Table 1 Experimental Task Parameters in Study 1
| Gambling Task | |||
|---|---|---|---|
| Gain Outcome | Loss Outcome | ||
| Amount (CNY) | Probability (%) | Amount (CNY) | Probability (%) |
| +10000 | 10 | ?278 | 10 |
| +5000 | 20 | ?313 | 20 |
| +3333 | 30 | ?357 | 30 |
| +2500 | 40 | ?417 | 40 |
| +2000 | 50 | ?500 | 50 |
| +1667 | 60 | ?625 | 60 |
| +1429 | 70 | ?833 | 70 |
| +1250 | 80 | ?1250 | 80 |
| +1111 | 90 | ?2500 | 90 |

Figure 1 Example Prompts Used in Study 1
| Predictor | β | SE | 95% CI | Wald χ2 | Exp (β) | p |
|---|---|---|---|---|---|---|
| Intercept | 1.867 | 0.098 | [1.679, 2.064] | 362.10 | 6.47 | < 0.001 |
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 0.597 | 0.159 | [0.289, 0.911] | 14.17 | 1.82 | < 0.001 |
| Model type (GPT-4 = 1, GPT-3.5 = 0) | ?0.815 | 0.124 | [?1.061, ?0.574] | 43.09 | 0.44 | < 0.001 |
| Gamble frequency × Model type | 0.251 | 0.202 | [?0.149, 0.646] | 1.55 | 1.29 | 0.213 |
Table 2 Regression Analysis Results for Study 1
| Predictor | β | SE | 95% CI | Wald χ2 | Exp (β) | p |
|---|---|---|---|---|---|---|
| Intercept | 1.867 | 0.098 | [1.679, 2.064] | 362.10 | 6.47 | < 0.001 |
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 0.597 | 0.159 | [0.289, 0.911] | 14.17 | 1.82 | < 0.001 |
| Model type (GPT-4 = 1, GPT-3.5 = 0) | ?0.815 | 0.124 | [?1.061, ?0.574] | 43.09 | 0.44 | < 0.001 |
| Gamble frequency × Model type | 0.251 | 0.202 | [?0.149, 0.646] | 1.55 | 1.29 | 0.213 |
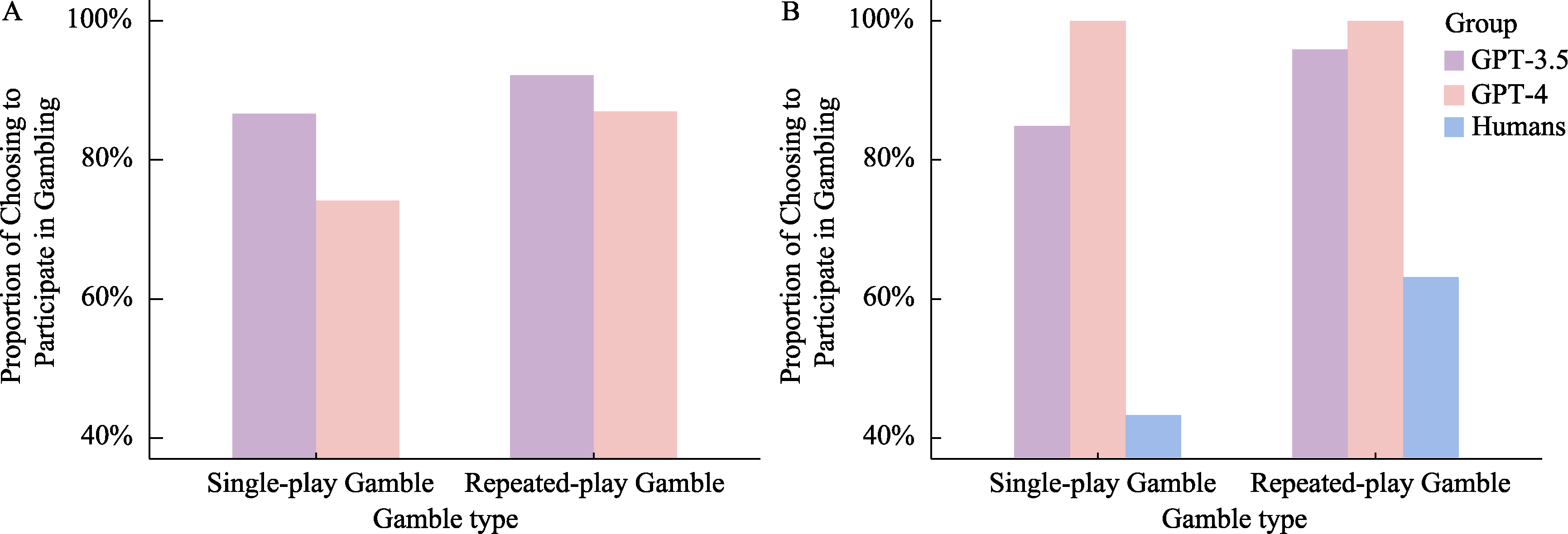
Figure 2 Proportions of Choosing to Participate in Gambling in Single-Play and Repeated-Play Gambles: LLMs vs. Humans in Study 1. Note. A. The average proportion with which GPT (3.5/4) chose to participate in the gambling task across all probability conditions. B. The proportion with which GPT (3.5/4) chose to participate when the winning probability was 50%, together with the corresponding human data reported under the same probability condition in Redelmeier and Tversky (1992). Within each set of bars, from left to right, the bars represent GPT-3.5, GPT-4, and the human group, respectively.

Figure 3 Workflow for LLM-Generated Decision Strategies.

Figure 4 Example Prompt for Inductive Thematic Analysis in Study 2.
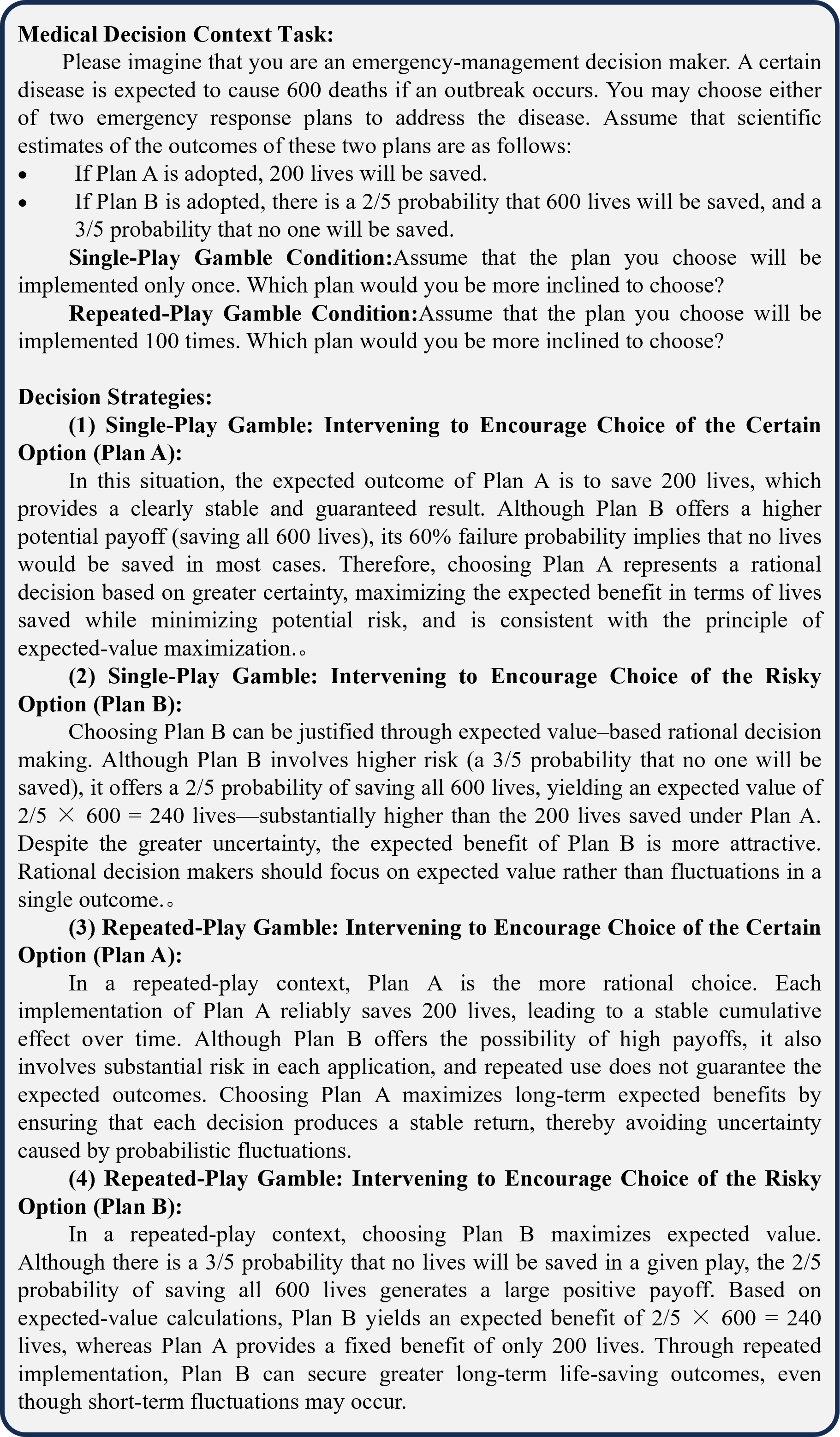
Figure 5 Examples of the Experimental Tasks in Study 2 and LLM-Generated Decision Strategies
| Predictor | β | SE | z | 95% CI | p |
|---|---|---|---|---|---|
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 1.967 | 0.175 | 11.245 | [1.624, 2.309] | < 0.001 |
| Decision context (Financial = 1, Medical = 0) | ?1.828 | 0.242 | ?7.549 | [?2.303, ?1.354] | < 0.001 |
| Gamble frequency × Decision context | 0.766 | 0.265 | 2.886 | [0.246, 1.286] | 0.004 |
Table 3 Cumulative Link Mixed Model (CLMM) Regression Results for the Effects of Gamble Frequency, Decision Context, and Their Interaction on Risky Choice
| Predictor | β | SE | z | 95% CI | p |
|---|---|---|---|---|---|
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 1.967 | 0.175 | 11.245 | [1.624, 2.309] | < 0.001 |
| Decision context (Financial = 1, Medical = 0) | ?1.828 | 0.242 | ?7.549 | [?2.303, ?1.354] | < 0.001 |
| Gamble frequency × Decision context | 0.766 | 0.265 | 2.886 | [0.246, 1.286] | 0.004 |
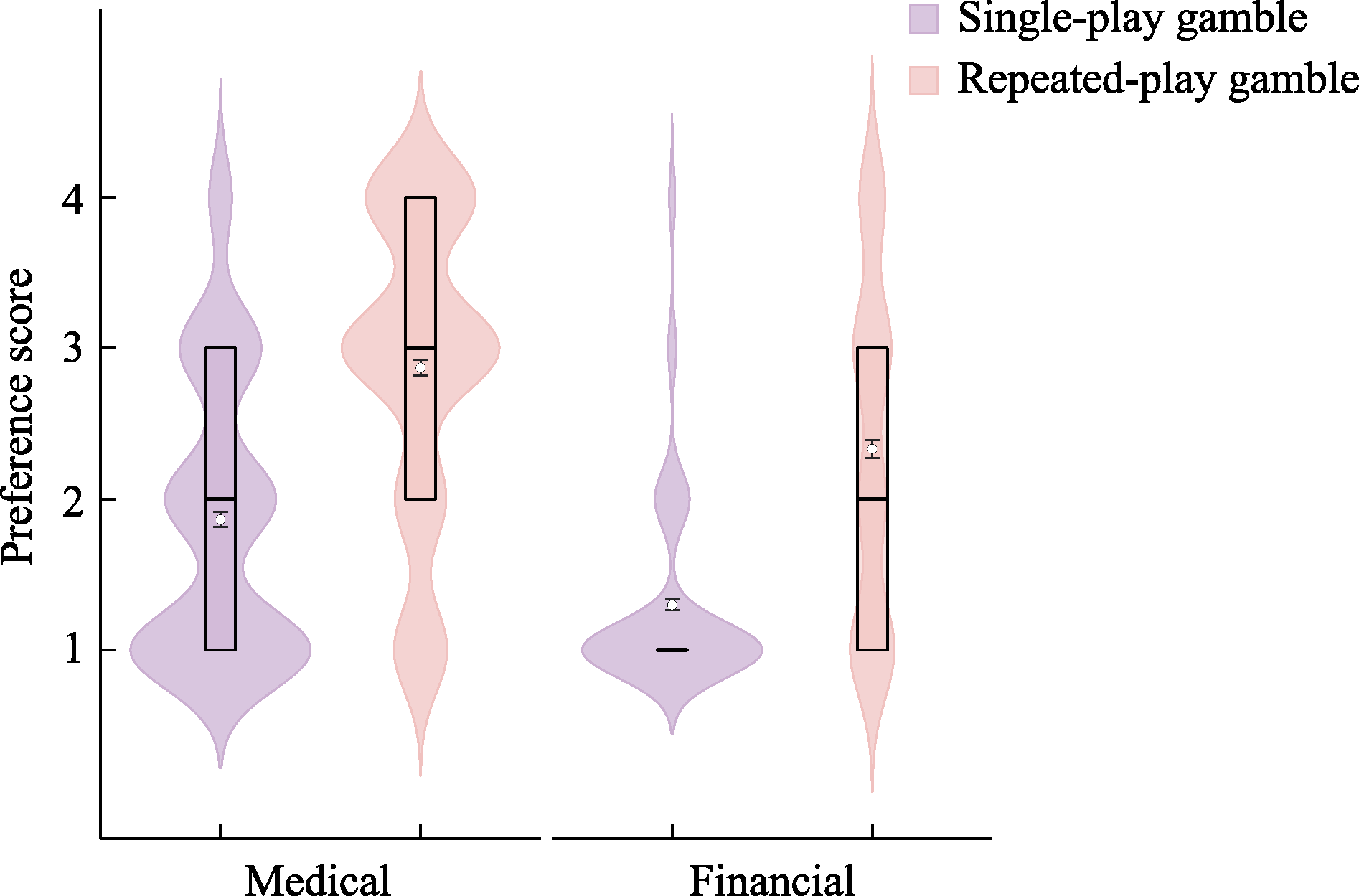
Figure 6 Choice distributions in single-play and repeated-play gamble across the medical and financial decision contexts in Study 2, Experiment 1. Note. The vertical axis represents responses on a 4-point rating scale, where Option A denotes the certain option and Option B denotes the risky option. Specifically, “1” indicates very likely to choose Option A, “2” indicates likely to choose Option A, “3” indicates likely to choose Option B, and “4” indicates very likely to choose Option B. In each boxplot, horizontal lines from top to bottom represent the upper quartile, median, and lower quartile, respectively; overlapping lines indicate identical statistical values. White dots denote the mean (M), and error bars represent the standard error (SE). Within each pair of distributions, the left and right panels correspond to the single-play gamble and repeated-play gamble conditions, respectively.
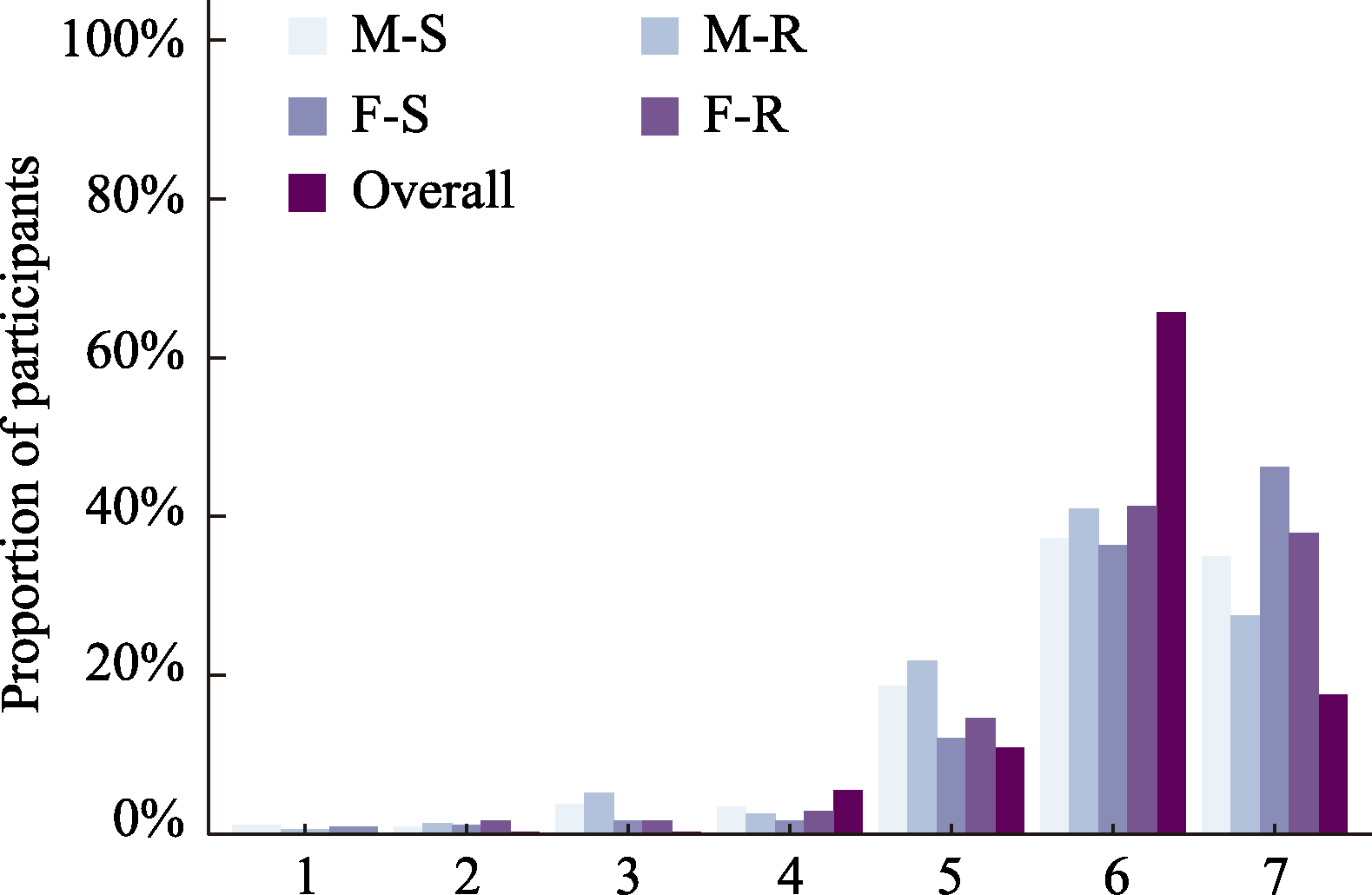
Figure 7 Distribution of participants’ ratings of decision-strategy texts across conditions in Study 2, Experiment 1. Note. The horizontal axis represents the perceived similarity between the decision-strategy text and participants’ own reasoning paths during the decision process. Ratings were collected on a 7-point Likert scale (1 = completely dissimilar, 7 = completely similar). For each score, bars from left to right correspond to the medical-single-play, medical-repeated-play, financial-single-play, financial-repeated-play, and overall conditions (the aggregated distribution across all four contexts).
| Predictor | β | SE | z | 95% CI | p |
|---|---|---|---|---|---|
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 0.635 | 0.263 | 2.415 | [0.120, 1.151] | 0.016 |
| Decision context (Content = 1, E-commerce = 0) | 0.619 | 0.273 | 2.272 | [0.085, 1.153] | 0.023 |
| Gamble frequency × Decision context | ?0.003 | 0.362 | ?0.009 | [?0.713, 0.706] | 0.993 |
Table 4 Cumulative Link Mixed Model (CLMM) Regression Results for the Effects of Gamble Frequency, Decision Context, and Their Interaction on Risky Choice
| Predictor | β | SE | z | 95% CI | p |
|---|---|---|---|---|---|
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 0.635 | 0.263 | 2.415 | [0.120, 1.151] | 0.016 |
| Decision context (Content = 1, E-commerce = 0) | 0.619 | 0.273 | 2.272 | [0.085, 1.153] | 0.023 |
| Gamble frequency × Decision context | ?0.003 | 0.362 | ?0.009 | [?0.713, 0.706] | 0.993 |
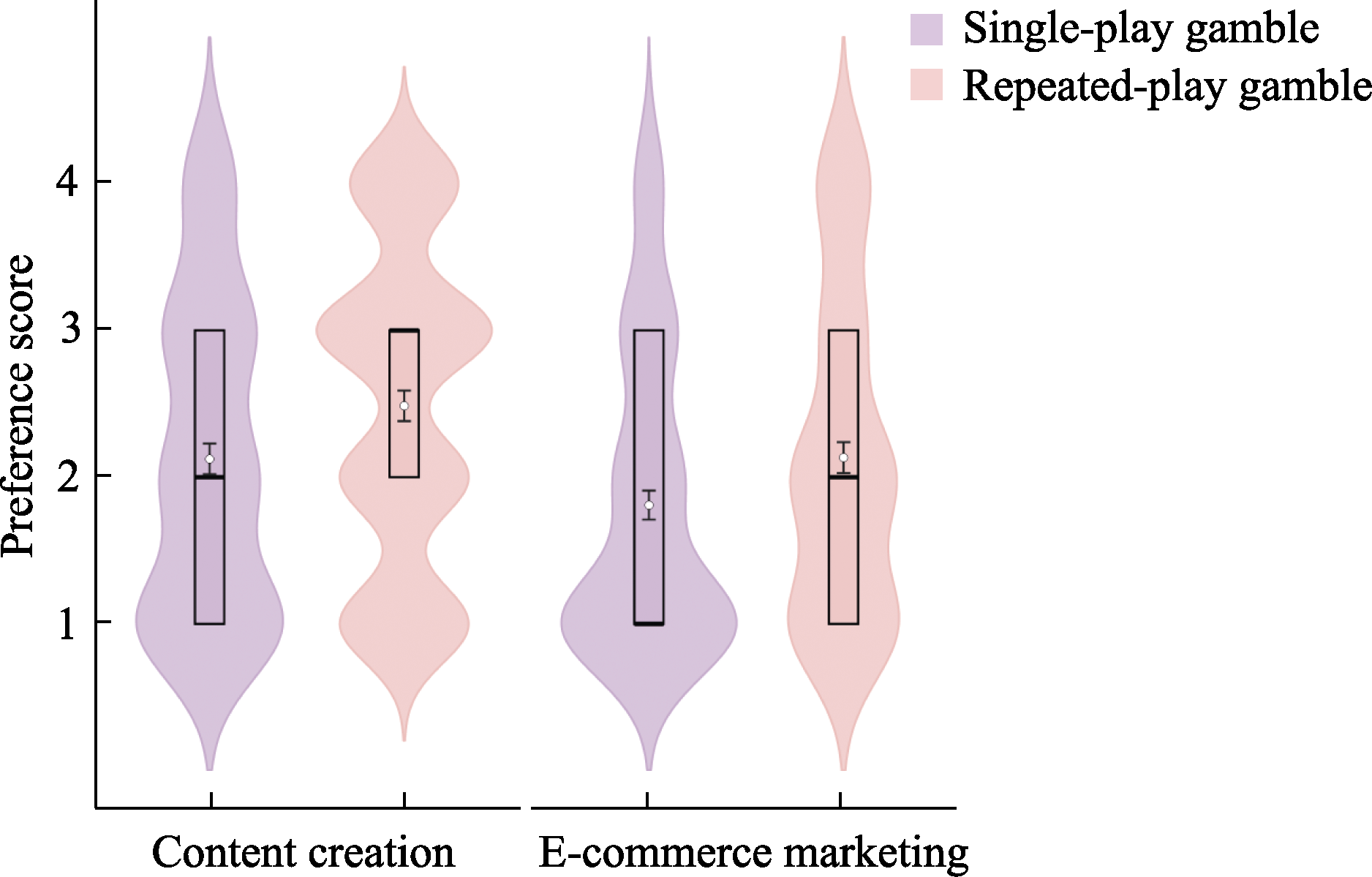
Figure 8 Choice distributions in single-play and repeated-play gambles across the content creation and e-commerce marketing contexts in Study 2, Experiment 2 Note. The vertical axis represents responses on a 4-point rating scale, where Option A denotes the certain option and Option B denotes the risky option. Specifically, “1” indicates very likely to choose Option A, “2” indicates likely to choose Option A, “3” indicates likely to choose Option B, and “4” indicates very likely to choose Option B. In each boxplot, horizontal lines from top to bottom represent the upper quartile, median, and lower quartile, respectively; overlapping lines indicate identical statistical values. White dots denote the mean (M), and error bars represent the standard error (SE). Within each pair of distributions, the left and right panels correspond to the single-play gamble and repeated-play gamble conditions, respectively.
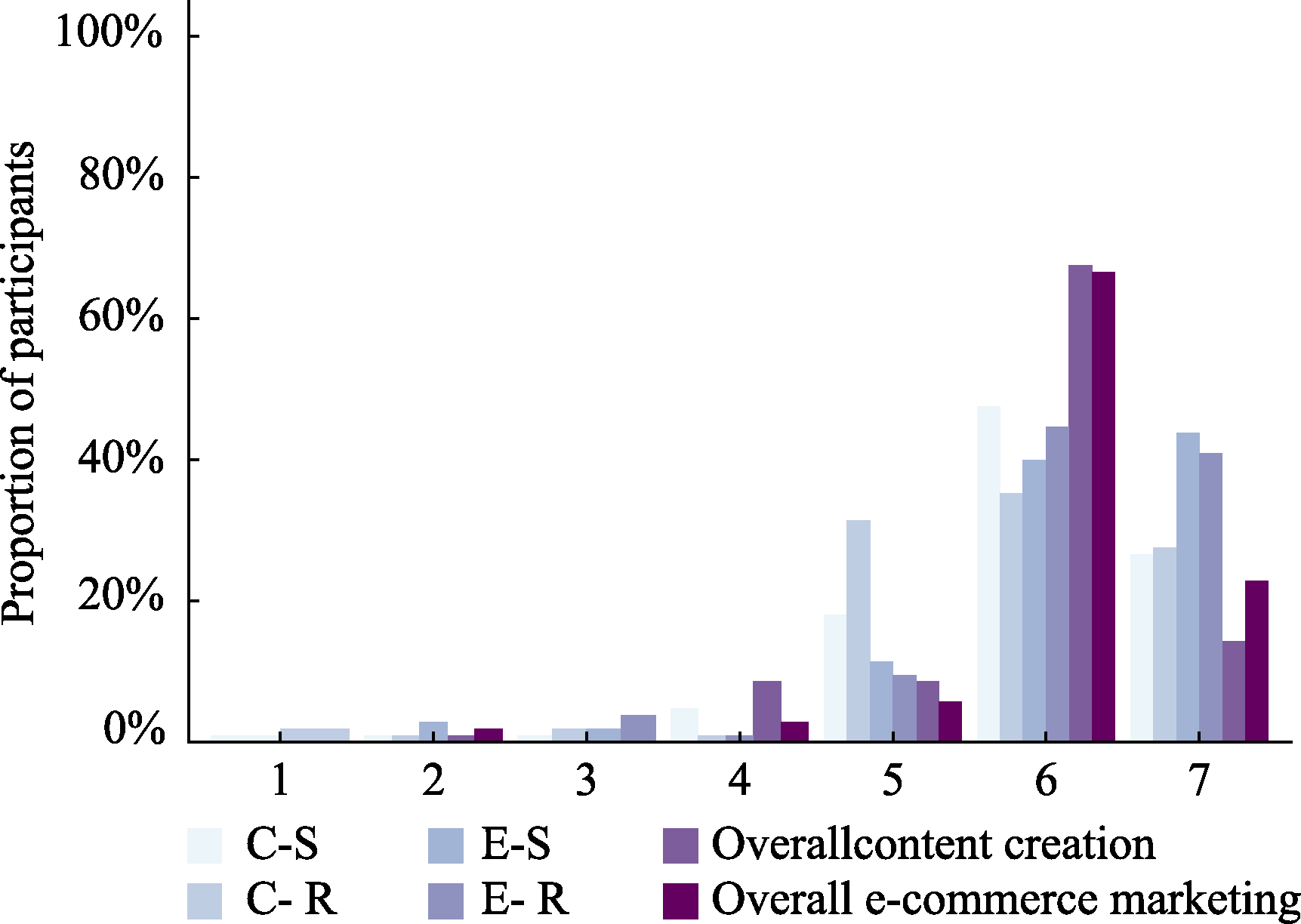
Figure 9 Distribution of participants’ ratings of decision-strategy texts across conditions in Study 2, Experiment 2 Note. The horizontal axis represents the perceived similarity between the decision-strategy text and participants’ own reasoning paths during the decision process. Ratings were collected on a 7-point Likert scale (1 = completely dissimilar, 7 = completely similar). For each score, bars from left to right correspond to the content creation-single-play, content creation- repeated-play, e-commerce marketing-single-play, e-commerce marketing- repeated-play, overall content creation, and overall e-commerce marketing, respectively. The overall conditions represent pooled distributions combining the two gamble types within each context.
| Predictor | β | SE | z | 95% CI | p | |
|---|---|---|---|---|---|---|
| Text type (Intervention = 1, Control = 0) | 1.072 | 0.180 | 5.940 | [0.718, 1.426] | < 0.001 | |
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 1.500 | 0.203 | 7.397 | [1.103, 1.898] | < 0.001 | |
| Decision context (Financial = 1, Medical = 0) | ?1.518 | 0.232 | ?6.530 | [?1.974, ?1.062] | < 0.001 | |
| Text type × Gamble frequency | ?1.840 | 0.284 | ?6.480 | [?2.397, ?1.284] | < 0.001 | |
| Text type × Decision context | 0.096 | 0.283 | 0.339 | [?0.458, 0.650] | 0.735 | |
| Gamble frequency × Decision context | 0.503 | 0.288 | 1.749 | [?0.061, 1.067] | 0.080 | |
| Text type × Gamble frequency × Decision context | ?0.220 | 0.384 | ?0.573 | [?0.972, 0.532] | 0.567 | |
Table 5 Cumulative Link Mixed Model (CLMM) Regression Results for the Effects of Text Type, Gamble Frequency, Decision Context, and Their Interactions on Risky Choice
| Predictor | β | SE | z | 95% CI | p | |
|---|---|---|---|---|---|---|
| Text type (Intervention = 1, Control = 0) | 1.072 | 0.180 | 5.940 | [0.718, 1.426] | < 0.001 | |
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 1.500 | 0.203 | 7.397 | [1.103, 1.898] | < 0.001 | |
| Decision context (Financial = 1, Medical = 0) | ?1.518 | 0.232 | ?6.530 | [?1.974, ?1.062] | < 0.001 | |
| Text type × Gamble frequency | ?1.840 | 0.284 | ?6.480 | [?2.397, ?1.284] | < 0.001 | |
| Text type × Decision context | 0.096 | 0.283 | 0.339 | [?0.458, 0.650] | 0.735 | |
| Gamble frequency × Decision context | 0.503 | 0.288 | 1.749 | [?0.061, 1.067] | 0.080 | |
| Text type × Gamble frequency × Decision context | ?0.220 | 0.384 | ?0.573 | [?0.972, 0.532] | 0.567 | |
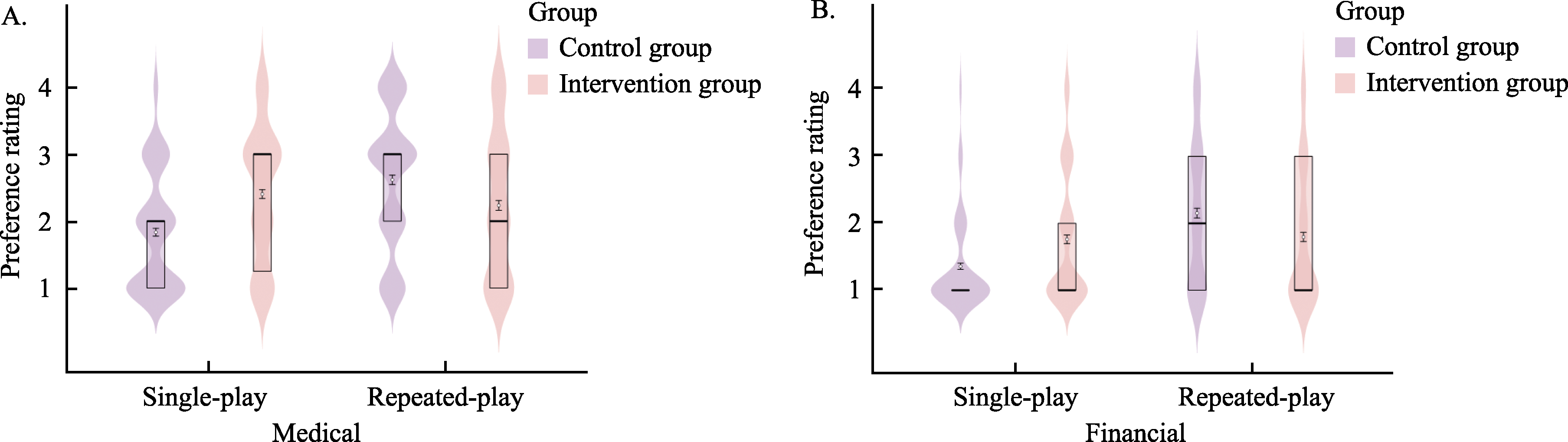
Figure 10 Choice distributions in single-play and repeated-play gamble tasks across medical and financial decision contexts in Study 3, Experiment 1 Note. In Panels A and B, the vertical axis represents choice ratings measured on a 4-point scale, where Option A denotes the certain option and Option B denotes the risky option. Specifically, 1 indicates very likely to choose Option A, 2 indicates likely to choose Option A, 3 indicates likely to choose Option B, and 4 indicates very likely to choose Option B. In the boxplots, the horizontal lines from top to bottom represent the upper quartile, median, and lower quartile, respectively; overlapping lines indicate identical statistics. White dots denote the mean (M), and error bars represent the standard error (SE). Within each pair of distributions, bars from left to right correspond to the control group and the intervention group, respectively.
| Predictor | β | SE | z | 95% CI | p |
|---|---|---|---|---|---|
| Text type (Intervention = 1, Control = 0) | 0.961 | 0.335 | 2.867 | [0.304, 1.619] | 0.004 |
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 0.819 | 0.350 | 2.341 | [0.133, 1.505] | 0.019 |
| Decision context (Content = 1, E-commerce = 0) | 0.917 | 0.335 | 2.735 | [0.26, 1.574] | 0.006 |
| Text type × Gamble frequency | ?2.101 | 0.487 | ?4.314 | [?3.056, ?1.147] | < 0.001 |
| Text type × Decision context | ?0.266 | 0.464 | ?0.572 | [?1.176, 0.645] | 0.567 |
| Gamble frequency × Decision context | ?0.534 | 0.471 | ?1.132 | [?1.457, 0.39] | 0.257 |
| Text type × Gamble frequency × Decision context | 0.070 | 0.666 | 0.105 | [?1.235, 1.375] | 0.916 |
Table 6 Cumulative Link Mixed Model (CLMM) Regression Results for the Effects of Text Type, Gamble Frequency, Decision Context, and Their Interactions on Risky Choice
| Predictor | β | SE | z | 95% CI | p |
|---|---|---|---|---|---|
| Text type (Intervention = 1, Control = 0) | 0.961 | 0.335 | 2.867 | [0.304, 1.619] | 0.004 |
| Gamble frequency (Repeated-play = 1, Single-play = 0) | 0.819 | 0.350 | 2.341 | [0.133, 1.505] | 0.019 |
| Decision context (Content = 1, E-commerce = 0) | 0.917 | 0.335 | 2.735 | [0.26, 1.574] | 0.006 |
| Text type × Gamble frequency | ?2.101 | 0.487 | ?4.314 | [?3.056, ?1.147] | < 0.001 |
| Text type × Decision context | ?0.266 | 0.464 | ?0.572 | [?1.176, 0.645] | 0.567 |
| Gamble frequency × Decision context | ?0.534 | 0.471 | ?1.132 | [?1.457, 0.39] | 0.257 |
| Text type × Gamble frequency × Decision context | 0.070 | 0.666 | 0.105 | [?1.235, 1.375] | 0.916 |

Figure 11 Choice distributions in single-play and repeated-play gamble tasks across content creation and e-commerce marketing contexts in Study 3, Experiment 2. Note. In Panels A and B, the vertical axis represents choice ratings measured on a 4-point scale, where Option A denotes the certain option and Option B denotes the risky option. Specifically, 1 indicates very likely to choose Option A, 2 indicates likely to choose Option A, 3 indicates likely to choose Option B, and 4 indicates very likely to choose Option B. In the boxplots, the horizontal lines from top to bottom represent the upper quartile, median, and lower quartile, respectively; overlapping lines indicate identical statistics. White dots denote the mean (M), and error bars represent the standard error (SE). Within each pair of distributions, bars from left to right correspond to the control group and the intervention group, respectively.
Figure S1 Questionnaire flowchart for Study 2, Experiment 1.
Figure S2 Questionnaire flowchart for Study 2, Experiment 2.
Figure S3 Questionnaire flowchart for Study 3, Experiment 1.
Figure S4 Questionnaire flowchart for Study 3, Experiment 2.
| Benchmark (Metric) | Claude-3.5- Sonnet-1022 | GPT-4o 0513 | Deep Seek-V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek- R1 | |
|---|---|---|---|---|---|---|---|
| Mathematics | AIME2024(Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500(Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| Programming | LiveCodeBench (Pass@1-COT) | 38.9 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| Open-ended Tasks | AlpacaEval2.0(LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | |
| Chinese Benchmarks | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | |
Table S1 Comparison Between DeepSeek-R1 and Other Leading Large Language Models
| Benchmark (Metric) | Claude-3.5- Sonnet-1022 | GPT-4o 0513 | Deep Seek-V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek- R1 | |
|---|---|---|---|---|---|---|---|
| Mathematics | AIME2024(Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500(Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| Programming | LiveCodeBench (Pass@1-COT) | 38.9 | 32.9 | 36.2 | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| Open-ended Tasks | AlpacaEval2.0(LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | |
| Chinese Benchmarks | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | |
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 6.67/7.32 | Education level | Associate degree or below | 6.67/14.63 |
| 20 ~ 22 | 26.67/17.07 | Bachelor’ s degree | 80.00/73.17 | ||
| 23 ~ 25 | 9.99/4.88 | Master’ s degree or above | 13.33/12.20 | ||
| ≥ 26 | 56.67/70.73 | Field of study | Law | 10.00/2.44 | |
| Gender | Male | 36.67/43.90 | Economics & Management | 36.67/31.70 | |
| Female | 63.33/56.10 | Science & Engineering | 43.33/60.98 | ||
| Years of work experience | ≤ 2 years | 20.00/17.65 | Medicine | 3.33/2.44 | |
| 3 ~ 5 years | 15.00/20.59 | Arts | 6.67/2.44 | ||
| ≥ 6 years | 65.00/61.76 | Other | 0.00/0.00 |
Table S2 Demographic Distribution of Participants in the Content Evaluation
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 6.67/7.32 | Education level | Associate degree or below | 6.67/14.63 |
| 20 ~ 22 | 26.67/17.07 | Bachelor’ s degree | 80.00/73.17 | ||
| 23 ~ 25 | 9.99/4.88 | Master’ s degree or above | 13.33/12.20 | ||
| ≥ 26 | 56.67/70.73 | Field of study | Law | 10.00/2.44 | |
| Gender | Male | 36.67/43.90 | Economics & Management | 36.67/31.70 | |
| Female | 63.33/56.10 | Science & Engineering | 43.33/60.98 | ||
| Years of work experience | ≤ 2 years | 20.00/17.65 | Medicine | 3.33/2.44 | |
| 3 ~ 5 years | 15.00/20.59 | Arts | 6.67/2.44 | ||
| ≥ 6 years | 65.00/61.76 | Other | 0.00/0.00 |
| Variable | t | p | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| Overall rating | 39.48/68.91 | < 0.001/< 0.001 | 7.21/10.76 | 5.38/5.49 | 0.26/0.18 |
| Reasonableness | 19.81/32.72 | < 0.001/< 0.001 | 3.62/5.20 | 5.40/5.20 | 0.52/0.33 |
| Professionalism | 20.14/32.44 | < 0.001/< 0.001 | 3.68/5.31 | 5.46/5.31 | 0.53/0.36 |
| Logical coherence | 16.52/43.91 | < 0.001/< 0.001 | 3.02/5.48 | 5.34/5.48 | 0.61/0.29 |
| Readability | 16.39/42.64 | < 0.001/< 0.001 | 2.99/5.64 | 5.42/5.64 | 0.64/0.32 |
| Persuasiveness | 17.64/43.27 | < 0.001/< 0.001 | 3.22/5.81 | 5.30/5.81 | 0.56/0.34 |
Table S3 Results of the Content Evaluation
| Variable | t | p | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| Overall rating | 39.48/68.91 | < 0.001/< 0.001 | 7.21/10.76 | 5.38/5.49 | 0.26/0.18 |
| Reasonableness | 19.81/32.72 | < 0.001/< 0.001 | 3.62/5.20 | 5.40/5.20 | 0.52/0.33 |
| Professionalism | 20.14/32.44 | < 0.001/< 0.001 | 3.68/5.31 | 5.46/5.31 | 0.53/0.36 |
| Logical coherence | 16.52/43.91 | < 0.001/< 0.001 | 3.02/5.48 | 5.34/5.48 | 0.61/0.29 |
| Readability | 16.39/42.64 | < 0.001/< 0.001 | 2.99/5.64 | 5.42/5.64 | 0.64/0.32 |
| Persuasiveness | 17.64/43.27 | < 0.001/< 0.001 | 3.22/5.81 | 5.30/5.81 | 0.56/0.34 |
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 9.74 | Education level | Senior high school / technical secondary school / vocational school | 1.15 |
| 20 ~ 22 | 57.02 | Junior college | 6.59 | ||
| 23 ~ 25 | 32.09 | Bachelor’ s degree | 75.36 | ||
| ≥ 26 | 1.15 | Master’ s degree or above | 16.90 | ||
| Gender | Male | 49.86 | Field of study | Law | 6.31 |
| Female | 50.14 | Economics & Management | 32.66 | ||
| Monthly income (RMB) | ≤ 1,000 | 5.73 | Science & Engineering | 47.85 | |
| 1,001 ~ 1,500 | 35.24 | Medicine | 6.30 | ||
| 1,501 ~ 2,000 | 28.08 | Arts | 5.73 | ||
| ≥ 2,001 | 30.95 | Other | 1.15 |
Table S4 Demographic Characteristics of Participants in Study 2, Experiment 1
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 9.74 | Education level | Senior high school / technical secondary school / vocational school | 1.15 |
| 20 ~ 22 | 57.02 | Junior college | 6.59 | ||
| 23 ~ 25 | 32.09 | Bachelor’ s degree | 75.36 | ||
| ≥ 26 | 1.15 | Master’ s degree or above | 16.90 | ||
| Gender | Male | 49.86 | Field of study | Law | 6.31 |
| Female | 50.14 | Economics & Management | 32.66 | ||
| Monthly income (RMB) | ≤ 1,000 | 5.73 | Science & Engineering | 47.85 | |
| 1,001 ~ 1,500 | 35.24 | Medicine | 6.30 | ||
| 1,501 ~ 2,000 | 28.08 | Arts | 5.73 | ||
| ≥ 2,001 | 30.95 | Other | 1.15 |
| Condition | t(df) | p | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| Overall | t(348) = 63.04 | < 0.001 | 3.37 | 5.97 | 0.73 |
| Medical context - Single-play gamble | t(348) = 37.42 | < 0.001 | 2.00 | 5.89 | 1.19 |
| Medical context - Repeated-play gamble | t(348) = 36.00 | < 0.001 | 1.93 | 5.77 | 1.18 |
| Financial context - Single-play gamble | t(348) = 45.87 | < 0.001 | 2.46 | 6.17 | 1.09 |
| Financial context - Repeated-play gamble | t(348) = 46.16 | < 0.001 | 2.47 | 6.05 | 1.03 |
Table S5 Participants’ Ratings of Decision-Strategy Texts in Study 2, Experiment 1
| Condition | t(df) | p | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| Overall | t(348) = 63.04 | < 0.001 | 3.37 | 5.97 | 0.73 |
| Medical context - Single-play gamble | t(348) = 37.42 | < 0.001 | 2.00 | 5.89 | 1.19 |
| Medical context - Repeated-play gamble | t(348) = 36.00 | < 0.001 | 1.93 | 5.77 | 1.18 |
| Financial context - Single-play gamble | t(348) = 45.87 | < 0.001 | 2.46 | 6.17 | 1.09 |
| Financial context - Repeated-play gamble | t(348) = 46.16 | < 0.001 | 2.47 | 6.05 | 1.03 |
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 6.19 | Education level | Associate degree or below | 12.86 |
| 20 ~ 22 | 25.71 | Bachelor’ s degree | 69.52 | ||
| 23 ~ 25 | 18.57 | Master’ s degree or above | 17.62 | ||
| ≥ 26 | 49.52 | Field of study | Law | 5.71 | |
| Gender | Male | 43.81 | Economics & Management | 38.57 | |
| Female | 56.19 | Science & Engineering | 44.29 | ||
| Years of work experience | ≤ 2 years | 36.67 | Medicine | 4.29 | |
| 3 ~ 5 years | 20.00 | Arts | 5.71 | ||
| ≥ 6 years | 43.33 | Other | 1.43 |
Table S6 Demographic Characteristics of Participants in Study 2, Experiment 2
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 6.19 | Education level | Associate degree or below | 12.86 |
| 20 ~ 22 | 25.71 | Bachelor’ s degree | 69.52 | ||
| 23 ~ 25 | 18.57 | Master’ s degree or above | 17.62 | ||
| ≥ 26 | 49.52 | Field of study | Law | 5.71 | |
| Gender | Male | 43.81 | Economics & Management | 38.57 | |
| Female | 56.19 | Science & Engineering | 44.29 | ||
| Years of work experience | ≤ 2 years | 36.67 | Medicine | 4.29 | |
| 3 ~ 5 years | 20.00 | Arts | 5.71 | ||
| ≥ 6 years | 43.33 | Other | 1.43 |
| Condition | t(df) | p | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| Overall | t(209) = 41.78 | < 0.001 | 2.88 | 5.99 | 0.86 |
| Content creation - Single-play gamble | t(104) = 23.12 | < 0.001 | 2.26 | 5.88 | 1.05 |
| Content creation - Repeated-play gamble | t(104) = 19.64 | < 0.001 | 2.00 | 5.75 | 1.17 |
| E-commerce marketing - Single-play gamble | t(104) = 25.14 | < 0.001 | 2.45 | 6.15 | 1.08 |
| E-commerce marketing - Repeated-play gamble | t(104) = 29.60 | < 0.001 | 2.89 | 6.18 | 0.93 |
Table S7 Participants’ Ratings of Decision-Strategy Texts in Study 2, Experiment 2
| Condition | t(df) | p | Cohen’ d | M | SD |
|---|---|---|---|---|---|
| Overall | t(209) = 41.78 | < 0.001 | 2.88 | 5.99 | 0.86 |
| Content creation - Single-play gamble | t(104) = 23.12 | < 0.001 | 2.26 | 5.88 | 1.05 |
| Content creation - Repeated-play gamble | t(104) = 19.64 | < 0.001 | 2.00 | 5.75 | 1.17 |
| E-commerce marketing - Single-play gamble | t(104) = 25.14 | < 0.001 | 2.45 | 6.15 | 1.08 |
| E-commerce marketing - Repeated-play gamble | t(104) = 29.60 | < 0.001 | 2.89 | 6.18 | 0.93 |
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 10.22 | Education level | Senior high school / technical secondary school / vocational school | 2.17 |
| 20 ~ 22 | 54.78 | Junior college | 6.09 | ||
| 23 ~ 25 | 34.78 | Bachelor’ s degree | 72.61 | ||
| ≥ 26 | 0.22 | Master’ s degree or above | 19.13 | ||
| Gender | Male | 44.57 | Field of study | Law | 7.61 |
| Female | 55.47 | Economics & Management | 30.22 | ||
| Monthly income (RMB) | ≤ 1,000 | 11.52 | Science & Engineering | 45.65 | |
| 1,001 ~ 1,500 | 28.91 | Medicine | 7.61 | ||
| 1,501 ~ 2,000 | 29.57 | Arts | 6.74 | ||
| ≥ 2,001 | 30.00 | Other | 2.17 |
Table S8 Demographic Characteristics of Participants in Study 3, Experiment 1
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 10.22 | Education level | Senior high school / technical secondary school / vocational school | 2.17 |
| 20 ~ 22 | 54.78 | Junior college | 6.09 | ||
| 23 ~ 25 | 34.78 | Bachelor’ s degree | 72.61 | ||
| ≥ 26 | 0.22 | Master’ s degree or above | 19.13 | ||
| Gender | Male | 44.57 | Field of study | Law | 7.61 |
| Female | 55.47 | Economics & Management | 30.22 | ||
| Monthly income (RMB) | ≤ 1,000 | 11.52 | Science & Engineering | 45.65 | |
| 1,001 ~ 1,500 | 28.91 | Medicine | 7.61 | ||
| 1,501 ~ 2,000 | 29.57 | Arts | 6.74 | ||
| ≥ 2,001 | 30.00 | Other | 2.17 |
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 5.42 | Education level | Associate degree or below | 10.42 |
| 20 ~ 22 | 24.58 | Bachelor’ s degree | 75.83 | ||
| 23 ~ 25 | 16.67 | Master’ s degree or above | 13.75 | ||
| ≥ 26 | 53.33 | Field of study | Law | 6.25 | |
| Gender | Male | 44.17 | Economics & Management | 38.75 | |
| Female | 55.83 | Science & Engineering | 45.42 | ||
| Years of work experience | ≤ 2 years | 16.03 | Medicine | 4.17 | |
| 3 ~ 5 years | 20.51 | Arts | 4.58 | ||
| ≥ 6 years | 63.46 | Other | 0.83 |
Table S9 Demographic Characteristics of Participants in Study 3, Experiment 2
| Variable | Category | Percentage (%) | Variable | Category | Percentage (%) |
|---|---|---|---|---|---|
| Age | ≤ 19 | 5.42 | Education level | Associate degree or below | 10.42 |
| 20 ~ 22 | 24.58 | Bachelor’ s degree | 75.83 | ||
| 23 ~ 25 | 16.67 | Master’ s degree or above | 13.75 | ||
| ≥ 26 | 53.33 | Field of study | Law | 6.25 | |
| Gender | Male | 44.17 | Economics & Management | 38.75 | |
| Female | 55.83 | Science & Engineering | 45.42 | ||
| Years of work experience | ≤ 2 years | 16.03 | Medicine | 4.17 | |
| 3 ~ 5 years | 20.51 | Arts | 4.58 | ||
| ≥ 6 years | 63.46 | Other | 0.83 |
| [1] | Achiam J., Adler S., Agarwal S., Ahmad L., Akkaya I., Aleman F. L.,... McGrew B.(2023). GPT-4 technical report. arXiv preprint. https://doi.org/10.48550/arXiv.2303.08774 |
| [2] | Aher G. V., Arriaga R. I., & Kalai A. T. (2023). Using large language models to simulate multiple humans and replicate human subject studies. In Proceedings of the 40th International Conference on Machine Learning (pp. 337-371). PMLR. https://proceedings.mlr.press/v202/aher23a.html |
| [3] |
Altay S., Hacquin A. S., Chevallier C., & Mercier H. (2023). Information delivered by a chatbot has a positive impact on COVID-19 vaccines attitudes and intentions. Journal of Experimental Psychology: Applied, 29(1), 52-62. https://doi.org/10.1037/xap0000400
doi: 10.1037/xap0000400 URL |
| [4] |
Anderson M. A. B., Cox D. J., & Dallery J. (2023). Effects of economic context and reward amount on delay and probability discounting. Journal of the Experimental Analysis of Behavior, 120(2), 204-213. https://doi.org/10.1002/jeab.86
doi: 10.1002/jeab.868 URL pmid: 37311053 |
| [5] |
Argyle L. P., Busby E. C., Fulda N., Gubler J., Rytting C., & Wingate D. (2023). Out of one, many: Using language models to simulate human samples. Political Analysis, 31(3), 337-351. https://doi.org/10.1017/pan.2023.2
doi: 10.1017/pan.2023.2 URL |
| [6] | Arora C., Sayeed A. I., Licorish S., Wang F., & Treude C. (2024). Optimizing large language model hyperparameters for code generation. arXiv preprint. https://doi.org/10.48550/arXiv.2408.10577 |
| [7] |
Barberis N., & Huang M. (2009). Preferences with frames: A new utility specification that allows for the framing of risks. Journal of Economic Dynamics and Control, 33(8), 1555-1576. https://doi.org/10.1016/j.jedc.2009.01.009
doi: 10.1016/j.jedc.2009.01.009 URL |
| [8] |
Benartzi S., & Thaler R. H. (1999). Risk aversion or myopia? Choices in repeated gambles and retirement investments. Management Science, 45(3), 364-381. https://doi.org/10.1287/mnsc.45.3.364
doi: 10.1287/mnsc.45.3.364 URL |
| [9] | Binz M., & Schulz E. (2023). Using cognitive psychology to understand GPT-3. Proceedings of the National Academy of Sciences, 120(6), e2218523120. https://doi.org/10.1073/pnas.2218523120 |
| [10] |
Brandstätter E., Gigerenzer G., & Hertwig R. (2006). The priority heuristic: Making choices without trade-offs. Psychological Review, 113(2), 409-432. https://doi.org/10.1037/0033-295X.113.2.409
doi: 10.1037/0033-295X.113.2.409 URL pmid: 16637767 |
| [11] | Brislin, R. W. (1986). The wording and translation of research instruments. In W. J. Lonner & (Eds.), Field methods in cross-cultural research (pp. 137-164). Sage Publications. |
| [12] | Brown T., Mann B., Ryder N., Subbiah M., Kaplan J. D., Dhariwal P., … Amodei D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 33, 1877-1901. https://doi.org/10.48550/arXiv.2005.14165 |
| [13] | Carvalho T., Negm H., & El-Geneidy A. (2024). A comparison of the results from artificial intelligence-based and human-based transport-related thematic analysis. Findings. https://doi.org/10.32866/001c.94401 |
| [14] | Chen Y., Liu T. X., Shan Y., & Zhong S. (2023). The emergence of economic rationality of GPT. Proceedings of the National Academy of Sciences, 120(51), e2316205120. https://doi.org/10.1073/pnas.2316205120 |
| [15] |
Choi S., Kang H., Kim N., & Kim J. (2025). How does artificial intelligence improve human decision-making? Evidence from the AI-powered Go program. Strategic Management Journal, 46(6), 1523-1554. https://doi.org/10.1002/smj.3694
doi: 10.1002/smj.v46.6 URL |
| [16] | Christensen R. H. B. (2023). ordinal: Regression models for ordinal data (R package version 2023.12-4.1) [Computer software]. https://CRAN.R-project.org/package=ordinal |
| [17] | Coda-Forno J., Witte K., Jagadish A. K., Binz M., Akata Z., & Schulz E. (2023). Inducing anxiety in large language models can induce bias. arXiv preprint. https://doi.org/10.48550/arXiv.2304.11111 |
| [18] | Dai S. C., Xiong A., & Ku L. W. (2023). LLM-in-the-loop: Leveraging large language model for thematic analysis. arXiv preprint. https://doi.org/10.48550/arXiv.2310.15100 |
| [19] |
de Kok T. (2025). ChatGPT for textual analysis? How to use generative LLMs in accounting research. Management Science, 71(9), 7888-7906. https://doi.org/10.1287/mnsc.2023.03253
doi: 10.1287/mnsc.2023.03253 URL |
| [20] |
de Varda A. G., Saponaro C., & Marelli M. (2025). High variability in LLMs’ analogical reasoning. Nature Human Behaviour, 9(7), 1339-1341. https://doi.org/10.1038/s41562-025-02224-3
doi: 10.1038/s41562-025-02224-3 URL |
| [21] | DeepSeek-AI Guo, D. Yang, D. Zhang, H. Song, J. Zhang, R., … Zhang Z. (2025). Deepseek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint. https://doi.org/10.48550/arXiv.2501.12948 |
| [22] |
Deiana G., Dettori M., Arghittu A., Azara A., Gabutti G., & Castiglia P. (2023). Artificial intelligence and public health: Evaluating ChatGPT responses to vaccination myths and misconceptions. Vaccines, 11(7), 1217. https://doi.org/10.3390/vaccines11071217
doi: 10.3390/vaccines11071217 URL |
| [23] |
Deiner M. S., Honcharov V., Li J., Mackey T. K., Porco T. C., & Sarkar U. (2024). Large language models can enable inductive thematic analysis of a social media corpus in a single prompt: Human validation study. JMIR Infodemiology, 4(1), e59641. https://doi.org/10.2196/59641
doi: 10.2196/59641 URL |
| [24] | Demszky D., Yang D., Yeager D. S., Bryan C. J., Clapper M., Chandhok S.,... Pennebaker J. W. (2023). Using large language models in psychology. Nature Reviews Psychology, 2(11), 688-701. https://doi.org/10.1038/s44159-023-00241-5 |
| [25] |
Dillion D., Tandon N., Gu Y., & Gray K. (2023). Can AI language models replace human participants? Trends in Cognitive Sciences, 27(7), 597-600. https://doi.org/10.1016/j.tics.2023.04.008
doi: 10.1016/j.tics.2023.04.008 URL pmid: 37173156 |
| [26] | Ding Y., Zhang L. L., Zhang C., Xu Y., Shang N., Xu J., Yang F., & Yang M. (2024). Longrope: Extending LLM context window beyond 2 million tokens. arXiv preprint. https://doi.org/10.48550/arXiv.2402.13753 |
| [27] |
Faul F., Erdfelder E., Lang A. G., & Buchner A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175-191.
doi: 10.3758/bf03193146 pmid: 17695343 |
| [28] | Ferguson S. A., Aoyagui P. A., & Kuzminykh A. (2023). Something borrowed: Exploring the influence of AI-generated explanation text on the composition of human explanations. In Extended Abstracts of the 2023 CHI Conference on Human Factors in Computing Systems (pp. 1-7). ACM. https://doi.org/10.1145/3544549.3585727 |
| [29] |
Goli A., & Singh A. (2024). Frontiers: Can large language models capture human preferences? Marketing Science, 43(4), 709-722. https://doi.org/10.1287/mksc.2023.0306
doi: 10.1287/mksc.2023.0306 URL |
| [30] |
Grossmann I., Feinberg M., Parker D. C., Christakis N. A., Tetlock P. E., & Cunningham W. A. (2023). AI and the transformation of social science research. Science, 380(6650), 1108-1109. https://doi.org/10.1126/science.adi1778
doi: 10.1126/science.adi1778 URL pmid: 37319216 |
| [31] |
Gupta R., Nair K., Mishra M., Ibrahim B., & Bhardwaj S. (2024). Adoption and impacts of generative artificial intelligence: Theoretical underpinnings and research agenda. International Journal of Information Management Data Insights, 4(1), 100232. https://doi.org/10.1016/j.jjimei.2024.100232
doi: 10.1016/j.jjimei.2024.100232 URL |
| [32] |
Hagendorff T., Fabi S., & Kosinski M. (2023). Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nature Computational Science, 3(10), 833-838. https://doi.org/10.1038/s43588-023-00527-x
doi: 10.1038/s43588-023-00527-x URL pmid: 38177754 |
| [33] | Hebenstreit K., Praas R., Kiesewetter L. P., & Samwald M. (2024). A comparison of chain-of-thought reasoning strategies across datasets and models. PeerJ Computer Science, 10, e1999. https://doi.org/10.7717/peerj-cs.1999 |
| [34] |
Hertwig R., & Erev I. (2009). The description-experience gap in risky choice. Trends in Cognitive Sciences, 13(12), 517-523. https://doi.org/10.1016/j.tics.2009.09.004
doi: 10.1016/j.tics.2009.09.004 URL pmid: 19836292 |
| [35] |
Jiao L., Li C., Chen Z., Xu H., & Xu Y. (2025). When AI “possesses” personality: Roles of good and evil personalities influence moral judgment in large language models. Acta Psychologica Sinica, 57(6), 929-946.
doi: 10.3724/SP.J.1041.2025.0929 |
| [36] |
Jin H. J., & Han D. H. (2014). Interaction between message framing and consumers’ prior subjective knowledge regarding food safety issues. Food Policy, 44, 95-102. https://doi.org/10.1016/j.foodpol.2013.10.007
doi: 10.1016/j.foodpol.2013.10.007 URL |
| [37] | Jones E., & Steinhardt J. (2022). Capturing failures of large language models via human cognitive biases. Advances in Neural Information Processing Systems, 35, 11785-11799. https://doi.org/10.48550/arxiv.2202.12299 |
| [38] |
Kahneman D., & Tversky A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47(2), 263-292. https://doi.org/10.2307/1914185
doi: 10.2307/1914185 URL |
| [39] | Karinshak E., Hu A., Kong K., Rao V., Wang J., Wang J., & Zeng Y. (2024). LLM-globe: A benchmark evaluating the cultural values embedded in LLM output. arXiv preprint. https://doi.org/10.48550/arXiv.2411.06032 |
| [40] | Karinshak E., Liu S. X., Park J. S., & Hancock J. T. (2023). Working with AI to persuade: Examining a large language model's ability to generate pro-vaccination messages. Proceedings of the ACM on Human-Computer Interaction, 7(CSCW1), 1-29. https://doi.org/10.1145/3579592 |
| [41] | Katz A., Fleming G. C., & Main J. (2024). Thematic analysis with open-source generative AI and machine learning: A new method for inductive qualitative codebook development. arXiv preprint. https://doi.org/10.48550/arXiv.2410.03721 |
| [42] |
Kelton A. S., Pennington R. R., & Tuttle B. M. (2010). The effects of information presentation format on judgment and decision making: A review of the information systems research. Journal of Information Systems, 24(2), 79-105. https://doi.org/10.2308/jis.2010.24.2.79
doi: 10.2308/jis.2010.24.2.79 URL |
| [43] | Khalid M. T., & Witmer A. P. (2025). Prompt engineering for large language model-assisted inductive thematic analysis. arXiv preprint. https://doi.org/10.48550/arXiv.2503.22978 |
| [44] |
Kumar A., & Lim S. S. (2008). How do decision frames influence the stock investment choices of individual investors? Management Science, 54(6), 1052-1064. https://doi.org/10.1287/mnsc.1070.0845
doi: 10.1287/mnsc.1070.0845 URL |
| [45] | Lehr S. A., Caliskan A., Liyanage S., & Banaji M. R. (2024). ChatGPT as research scientist: Probing GPT’s capabilities as a research librarian, research ethicist, data generator, and data predictor. Proceedings of the National Academy of Sciences, 121(35), e2404328121. https://doi.org/10.1073/pnas.2404328121 |
| [46] | Lenth R. V. (2025). Emmeans: Estimated marginal means, aka least- squares means (R package version 1.11.0) [Computer software]. https://doi.org/10.32614/CRAN.package.emmeans |
| [47] |
Li S. (2004). A behavioral choice model when computational ability matters. Applied Intelligence, 20(2), 147-163. https://doi.org/10.1023/B:APIN.0000013337.01711.c7
doi: 10.1023/B:APIN.0000013337.01711.c7 URL |
| [48] | Lim S., & Schmälzle R. (2024). The effect of source disclosure on evaluation of AI-generated messages. Computers in Human Behavior: Artificial Humans, 2(1), 100058. https://doi.org/10.1016/j.chbah.2024.100058 |
| [49] | Lin Z. (2023). Why and how to embrace AI such as ChatGPT in your academic life. Royal Society Open Science, 10(8), 230658. https://doi.org/10.1098/rsos.230658 |
| [50] |
Lin Z. (2024). How to write effective prompts for large language models. Nature Human Behaviour, 8(4), 611-615. https://doi.org/10.1038/s41562-024-01847-2
doi: 10.1038/s41562-024-01847-2 URL pmid: 38438650 |
| [51] |
Lin Z. (2025). Techniques for supercharging academic writing with generative AI. Nature Biomedical Engineering, 9(4), 426-431. https://doi.org/10.1038/s41551-024-01185-8
doi: 10.1038/s41551-024-01185-8 URL |
| [52] | Liu N., Zhou L., Li A. M., Hui Q. S., Zhou Y. R., & Zhang Y. Y. (2021). Neuroticism and risk-taking: the role of competition with a former winner or loser. Personality and Individual Differences, 179, 110917. https://doi.org/10.1016/j.paid.2021.110917 |
| [53] |
Liu S. X., Yang J. Z., & Chu H. R. (2019). Now or future? Analyzing the effects of message frame and format in motivating Chinese females to get HPV vaccines for their children. Patient Education and Counseling, 102(1), 61-67. https://doi.org/10.1016/j.pec.2018.09.005
doi: S0738-3991(18)30692-X URL pmid: 30219633 |
| [54] |
Lopes L. L. (1996). When time is of the essence: Averaging, aspiration, and the short run. Organizational Behavior and Human Decision Processes, 65(3), 179-189. https://doi.org/10.1006/obhd.1996.0017
doi: 10.1006/obhd.1996.0017 URL |
| [55] |
Lu J., Chen Y., & Fang Q. (2022). Promoting decision satisfaction: The effect of the decision target and strategy on process satisfaction. Journal of Business Research, 139, 1231-1239. https://doi.org/10.1016/j.jbusres.2021.10.056
doi: 10.1016/j.jbusres.2021.10.056 URL |
| [56] | Mei Q., Xie Y., Yuan W., & Jackson M. O. (2024). A turing test of whether AI chatbots are behaviorally similar to humans. Proceedings of the National Academy of Sciences, 121(9), e2313925121. https://doi.org/10.1073/pnas.2313925121 |
| [57] |
Mischler G., Li Y. A., Bickel S., Mehta A. D., & Mesgarani N. (2024). Contextual feature extraction hierarchies converge in large language models and the brain. Nature Machine Intelligence, 6(10), 1467-1477. https://doi.org/10.1038/s42256-024-00925-4
doi: 10.1038/s42256-024-00925-4 URL |
| [58] |
Morreale A., Stoklasa J., Collan M., & Lo Nigro G. (2018). Uncertain outcome presentations bias decisions: Experimental evidence from Finland and Italy. Annals of Operations Research, 268(1-2), 259-272. https://doi.org/10.1007/s10479-016-2349-3
doi: 10.1007/s10479-016-2349-3 URL |
| [59] | Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716. https://doi.org/10.1126/science.aac4716 |
| [60] |
Park P. S. (2024). Diminished diversity-of-thought in a standard large language model. Behavior Research Methods, 56(6), 5754-5770. https://doi.org/10.3758/s13428-023-02307-x
doi: 10.3758/s13428-023-02307-x URL pmid: 38194165 |
| [61] | Pascal B.(1670) Pensées (W. F. Trotter, Trans.). Retrieved Nov. 22, 2018, from https://sourcebooks.fordham.edu/mod/1660pascal-pensees.asp |
| [62] | Pavey L., & Churchill S. (2014). Promoting the avoidance of high- calorie snacks: Priming autonomy moderates message framing effects. Plos One, 9(7), e103892. https://doi.org/10.1371/journal.pone.0103892 |
| [63] | Pawel S., Consonni G., & Held L. (2023). Bayesian approaches to designing replication studies. Psychological Methods. Advance online publication. https://doi.org/10.1037/met0000604 |
| [64] |
Peng L., Guo Y., & Hu D. (2021). Information framing effect on public’s intention to receive the COVID-19 vaccination in China. Vaccines, 9(9), 995. https://doi.org/10.3390/vaccines9090995
doi: 10.3390/vaccines9090995 URL |
| [65] |
Peters E., & Levin I. P. (2008). Dissecting the risky-choice framing effect: Numeracy as an individual-difference factor in weighting risky and riskless options. Judgment and Decision Making, 3(6), 435-448. https://doi.org/10.1017/s1930297500000012
doi: 10.1017/S1930297500000012 URL |
| [66] |
Popovic N. F., Pachur T., & Gaissmaier W. (2019). The gap between medical and monetary choices under risk persists in decisions for others. Journal of Behavioral Decision Making, 32(4), 388-402. https://doi.org/10.1002/bdm.2121
doi: 10.1002/bdm.v32.4 URL |
| [67] | Prescott M. R., Yeager S., Ham L., Saldana C. D. R., Serrano V., Narez J., … Montoya J. (2024). Comparing the efficacy and efficiency of human and generative AI: Qualitative thematic analyses. JMIR AI, 3(1), e54482. https://doi.org/10.2196/54482 |
| [68] | Qin X., Huang M., & Ding J. (2024). AITurk: Using ChatGPT for social science research. PsyArXiv. https://doi.org/10.31234/osf.io/xkd23 |
| [69] |
Redelmeier D. A., & Tversky A. (1992). On the framing of multiple prospects. Psychological Science, 3(3), 191-193. https://doi.org/10.1111/j.1467-9280.1992.tb00025.x
doi: 10.1111/j.1467-9280.1992.tb00025.x URL |
| [70] | Reeck C., Mullette-Gillman O. A., McLaurin R. E., & Huettel S. A. (2022). Beyond money: Risk preferences across both economic and non-economic contexts predict financial decisions. Plos One, 17(12), e0279125. https://doi.org/10.1371/journal.pone.0279125 |
| [71] |
Salles A., Evers K., & Farisco M. (2020). Anthropomorphism in AI. AJOB Neuroscience, 11(2), 88-95. https://doi.org/10.1080/21507740.2020.1740350
doi: 10.1080/21507740.2020.1740350 URL pmid: 32228388 |
| [72] | Samuelson P. A. (1963). Risk and uncertainty: A fallacy of large numbers. Scientia, 98, 108-113. |
| [73] |
Scarffe A., Coates A., Brand K., & Michalowski W. (2024). Decision threshold models in medical decision making: A scoping literature review. BMC Medical Informatics and Decision Making, 24(1), 273. https://doi.org/10.1186/s12911-024-02681-2
doi: 10.1186/s12911-024-02681-2 URL |
| [74] | Shahid N., Rappon T., & Berta W. (2019). Applications of artificial neural networks in health care organizational decision-making: A scoping review. Plos One, 14(2), e0212356. https://doi.org/10.1371/journal.pone.0212356 |
| [75] |
Simonsohn U. (2015). Small telescopes: Detectability and the evaluation of replication results. Psychological Science, 26(5), 559-569. https://doi.org/10.1177/0956797614567341
doi: 10.1177/0956797614567341 URL pmid: 25800521 |
| [76] |
Strachan J. W. A., Albergo D., Borghini G., Pansardi O., Scaliti E., Gupta S., … Becchio C. (2024). Testing theory of mind in large language models and humans. Nature Human Behaviour, 8(7), 1285-1295. https://doi.org/10.1038/s41562-024-01882-z
doi: 10.1038/s41562-024-01882-z URL pmid: 38769463 |
| [77] |
Sun H. Y., Rao L. L., Zhou K., & Li S. (2014). Formulating an emergency plan based on expectation-maximization is one thing, but applying it to a single case is another. Journal of Risk Research, 17(7), 785-814. https://doi.org/10.1080/13669877.2013.816333
doi: 10.1080/13669877.2013.816333 URL |
| [78] |
Suri G., Slater L. R., Ziaee A., & Nguyen M. (2024). Do large language models show decision heuristics similar to humans? A case study using GPT-3.5. Journal of Experimental Psychology: General, 153(4), 1066-1075. https://doi.org/10.1037/xge0001547
doi: 10.1037/xge0001547 URL |
| [79] | Tabachnick B. G., & Fidell L. S. (2007). Using multivariate statistics (5th ed.). Allyn & Bacon. |
| [80] |
Thapa S., & Adhikari S. (2023). ChatGPT, Bard, and large language models for biomedical research: Opportunities and pitfalls. Annals of Biomedical Engineering, 51(12), 2647-2651. https://doi.org/10.1007/s10439-023-03284-0
doi: 10.1007/s10439-023-03284-0 URL |
| [81] |
Tversky A., & Bar-Hillel M. (1983). Risk: The long and the short. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9(4), 713-717. https://doi.org/10.1037/0278-7393.9.4.713
doi: 10.1037/0278-7393.9.4.713 URL |
| [82] | Von Neumann J., & Morgenstern O. (1947). Theory of games and economic behavior (2nd rev. ed.). Princeton University Press. |
| [83] |
Wang Y., Zhang J., Wang F., Xu W., & Liu W. (2023). Do not think any virtue trivial, and thus neglect it: Serial mediating role of social mindfulness and perspective taking. Acta Psychologica Sinica, 55(4), 626-641. https://doi.org/10.3724/SP.J.1041.2023.00626
doi: 10.3724/SP.J.1041.2023.00626 URL |
| [84] |
Webb T., Holyoak K. J., & Lu H. (2023). Emergent analogical reasoning in large language models. Nature Human Behaviour, 7(9), 1526-1541. https://doi.org/10.48550/arXiv.2212.09196
doi: 10.1038/s41562-023-01659-w URL pmid: 37524930 |
| [85] |
Weber E. U., Blais A.-R., & Betz N. E. (2002). A domain-specific risk-attitude scale: Measuring risk perceptions and risk behaviors. Journal of Behavioral Decision Making, 15(4), 263-290. https:// doi.org/10.1002/bdm.414
doi: 10.1002/bdm.v15:4 URL |
| [86] | Wei J., Wang X., Schuurmans D., Bosma M., Ichter B., Xia F.,... Zhou D. (2022). Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35, 24824-24837. https://doi.org/10.48550/arxiv.2201.11903 |
| [87] |
Xia D., Li Y., He Y., Zhang T., Wang Y., & Gu J. (2019). Exploring the role of cultural individualism and collectivism on public acceptance of nuclear energy. Energy Policy, 132, 208-215. https:// doi.org/10.1016/j.enpol.2019.05.014
doi: 10.1016/j.enpol.2019.05.014 URL |
| [88] | Xia D., Song M., & Zhu T. (2025). A comparison of the persuasiveness of human and ChatGPT generated pro-vaccine messages for HPV. Frontiers in Public Health, 12, 1515871. https://doi.org/10.3389/fpubh.2024.1515871 |
| [89] | Yuan Y., Jiao W., Wang W., Huang J. T., He P., Shi S., & Tu Z. (2023). Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher. arXiv preprint. https://doi.org/10.48550/arXiv.2308.06463 |
| [90] |
Zhang J., Li H. A., & Allenby G. M. (2024). Using text analysis in parallel mediation analysis. Marketing Science, 43(5), 953-970. https://doi.org/10.1287/mksc.2023.0045
doi: 10.1287/mksc.2023.0045 URL |
| [91] |
Zhang Y., Huang F., Mo L., Liu X., & Zhu T. (2025). Suicidal ideation data augmentation and recognition technology based on large language models. Acta Psychologica Sinica, 57(6), 987-1000.
doi: 10.3724/SP.J.1041.2025.0987 |
| [92] | Zhao F., Yu F., & Shang Y. (2024). A new method supporting qualitative data analysis through prompt generation for inductive coding. 2024 IEEE International Conference on Information Reuse and Integration for Data Science (IRI), 164-169. https://doi.org/10.1109/IRI62200.2024.00043 |
| [93] | Zhao W. X., Zhou K., Li J., Tang T., Wang X., Hou Y.,... Wen J. R. (2023). A survey of large language models. arXiv preprint. https://doi.org/10.48550/arXiv.2303.18223 |
| [1] | LIU Yue, HE Yueling, LIU Hongyun. Data analysis and sample size planning for intensive longitudinal intervention studies using dynamic structural equation modeling [J]. Acta Psychologica Sinica, 2026, 58(4): 773-792. |
| [2] | DAI Yiqing, MA Xinming, WU Zhen. LLMs Amplify Gendered Empathy Stereotypes and Influence Major and Career Recommendations* [J]. Acta Psychologica Sinica, 2026, 58(3): 399-415. |
| [3] | ZHU Naping, ZHANG Xia, ZHOU Jie, LI Yanfang. The development and motivations of children’s third-party intervention preference in group cooperation norm violation [J]. Acta Psychologica Sinica, 2026, 58(3): 516-536. |
| [4] | YANG Shen-Long, HU Xiaoyong, GUO Yongyu. The psychological impact of economic situation: Intervention strategies and governance implications [J]. Acta Psychologica Sinica, 2026, 58(2): 191-197. |
| [5] | WU Shiyu, WANG Yiyun. “Zero-Shot Language Learning”: Can Large Language Models “Acquire” Contextual Emotion Like Humans? [J]. Acta Psychologica Sinica, 2026, 58(2): 308-322. |
| [6] | JIAO Liying, LI Chang-Jin, CHEN Zhen, XU Hengbin, XU Yan. When AI “possesses” personality: Roles of good and evil personalities influence moral judgment in large language models [J]. Acta Psychologica Sinica, 2025, 57(6): 929-946. |
| [7] | GAO Chenghai, DANG Baobao, WANG Bingjie, WU Michael Shengtao. The linguistic strength and weakness of artificial intelligence: A comparison between Large Language Model (s) and real students in the Chinese context [J]. Acta Psychologica Sinica, 2025, 57(6): 947-966. |
| [8] | ZHANG Yanbo, HUANG Feng, MO Liuling, LIU Xiaoqian, ZHU Tingshao. Suicidal ideation data augmentation and recognition technology based on large language models [J]. Acta Psychologica Sinica, 2025, 57(6): 987-1000. |
| [9] | HUANG Feng, DING Huimin, LI Sijia, HAN Nuo, DI Yazheng, LIU Xiaoqian, ZHAO Nan, LI Linyan, ZHU Tingshao. Self-help AI psychological counseling system based on large language models and its effectiveness evaluation [J]. Acta Psychologica Sinica, 2025, 57(11): 2022-2042. |
| [10] | XIN Ziqiang, WANG Luxiao, LI Yue. Differences in information processing between experienced investors and novices, and intervention in fund investment decision-making [J]. Acta Psychologica Sinica, 2024, 56(6): 799-813. |
| [11] | TANG Meihui, TIAN Shuwan, XIE Tian. Beyond the myth of slimming: The impact of social norms on positive body image and caloric intake among young adults [J]. Acta Psychologica Sinica, 2024, 56(10): 1367-1383. |
| [12] | REN Zhihong, ZHAO Chunxiao, TIAN Fan, YAN Yupeng, LI Danyang, ZHAO Ziyi, TAN Mengling, JIANG Guangrong. Meta-analysis of the effect of mental health literacy intervention in Chinese people [J]. Acta Psychologica Sinica, 2020, 52(4): 497-512. |
| [13] | LI Aimei, WANG Haixia, SUN Hailong, XIONG Guanxing, YANG Shaoli . The nudge effect of “foresight for the future of our children”: Pregnancy and environmental intertemporal choice [J]. Acta Psychologica Sinica, 2018, 50(8): 858-867. |
| [14] | REN Zhihong, Zhang Yawen, JIANG Guangrong. Effectiveness of mindfulness meditation in intervention for anxiety: A meta-analysis [J]. Acta Psychologica Sinica, 2018, 50(3): 283-305. |
| [15] | REN Zhihong; LI Xianyun; ZHAO Lingbo; YU Xianglian; LI Zhenghan; LAI Lizu; RUAN Yijun; JIANG Guangrong. Effectiveness and mechanism of internet-based self-help intervention for depression: The Chinese version of MoodGYM [J]. Acta Psychologica Sinica, 2016, 48(7): 818-832. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||