ISSN 0439-755X
CN 11-1911/B
CN 11-1911/B
Acta Psychologica Sinica ›› 2025, Vol. 57 ›› Issue (11): 1988-2000.doi: 10.3724/SP.J.1041.2025.1988
• Reports of Empirical Studies • Previous Articles Next Articles
ZHOU Zisen1, HUANG Qi1, TAN Zehong2, LIU Rui3, CAO Ziheng4, MU Fangman5, FAN Yachun2( ), QIN Shaozheng1()
), QIN Shaozheng1()
Published:2025-11-25
Online:2025-09-25
Contact:
Fan Yanchun, E-mail: fanyachun@bnu.edu.cn; Qin Shaozheng, E-mail: szqin@bnu.edu.cn
ZHOU Zisen, HUANG Qi, TAN Zehong, LIU Rui, CAO Ziheng, MU Fangman, FAN Yachun, QIN Shaozheng. (2025). Emotional capabilities evaluation of multimodal large language model in dynamic social interaction scenarios. Acta Psychologica Sinica, 57(11), 1988-2000.
| Genre | Film name | Two-person dialogues | ||
|---|---|---|---|---|
| Duration (seconds) | Turns | Utternces | ||
| Comedy | From Beijing with Love | 48 | 5 | 10 |
| The Dream Factory | 59 | 3 | 6 | |
| Lost in Thailand | 78 | 13 | 27 | |
| Goodbye Mr. Loser | 72 | 3 | 6 | |
| Romance | Finding Mr. Right | 105 | 7 | 15 |
| If You Are the One | 72 | 4 | 9 | |
| Under the Hawthorn Tree | 79 | 3 | 7 | |
| Love is Not Blind | 117 | 4 | 8 | |
| Mystery | The Great Hypnotist | 104 | 4 | 10 |
| The Message | 46 | 4 | 9 | |
| Mad Detective | 30 | 4 | 8 | |
| Drama | Youth | 44 | 4 | 9 |
| Let the Bullets Fly | 64 | 5 | 10 | |
| Dying to Survive | 38 | 3 | 7 | |
| Infernal Affairs | 65 | 3 | 8 | |
Table 1 The statistics of two-person dialogues
| Genre | Film name | Two-person dialogues | ||
|---|---|---|---|---|
| Duration (seconds) | Turns | Utternces | ||
| Comedy | From Beijing with Love | 48 | 5 | 10 |
| The Dream Factory | 59 | 3 | 6 | |
| Lost in Thailand | 78 | 13 | 27 | |
| Goodbye Mr. Loser | 72 | 3 | 6 | |
| Romance | Finding Mr. Right | 105 | 7 | 15 |
| If You Are the One | 72 | 4 | 9 | |
| Under the Hawthorn Tree | 79 | 3 | 7 | |
| Love is Not Blind | 117 | 4 | 8 | |
| Mystery | The Great Hypnotist | 104 | 4 | 10 |
| The Message | 46 | 4 | 9 | |
| Mad Detective | 30 | 4 | 8 | |
| Drama | Youth | 44 | 4 | 9 |
| Let the Bullets Fly | 64 | 5 | 10 | |
| Dying to Survive | 38 | 3 | 7 | |
| Infernal Affairs | 65 | 3 | 8 | |
| Genre | Film name | Two-person dialogues | ||
|---|---|---|---|---|
| Location | Character code | Relationship | ||
| Comedy | From Beijing with Love | Restaurant | A: Ling-Ling-Chat B: Xiangqin Li | B appears to cooperate with A on the surface, but is secretly tasked with assassinating him |
| The Dream Factory | Inside the car | D: Kang Qian K: Boss You | K wants to “suffer hardship,” and D arranges for him to spend two months in the countryside | |
| Lost in Thailand | On the airplane | A: Lang Xu F: Bao Wang | A and F are complete strangers | |
| Goodbye Mr. Loser | School bike shed | A: Luo Xia D: Ya Qiu | A and D are classmates, and A is pursuing D romantically | |
| Romance | Finding Mr. Right | B’s home | A: Jiajia Wen B: Zhi Hao | B is a driver working for a maternity center in Seattle, while A is a expectant mother who has flown from China to Seattle |
| If You Are the One | Phone call from B to A | A: Fen Qin B: Xiaoxiao Liang | A and B once went on a blind date | |
| Under the Hawthorn Tree | B and M’s home | B: Jingqiu M: Jingqiu’s mother | M is B’s mother | |
| Love is Not Blind | Outside of the restaurant | F: Ran Lu I: Xiaoxian Huang | F is I’s ex-boyfriend | |
| Mystery | The Great Hypnotist | A’s psychotherapy Office | A: Ruining Xu B: Xiaoyan Ren | A is B’s therapist |
| The Message | Temporary hideout A and B | A: Xiaomeng Gu B: Ningyu Li | Both work at the puppet army headquarters, but are suspected by their superiors of being the Communist spy known as “Old Ghost” | |
| Mad Detective | Inside the police car | C: Zhiwei Gao E: Guozhu Wang | C and E are police colleagues | |
| Drama | Youth | A’s Dormitory | A: Feng Liu B: Xiaoping He | A is a male soldier in the art troupe, and B is a female soldier in the same troupe |
| Let the Bullets Fly | County magistrate’s office | A: Muzhi Zhang B: Bangde Ma | A is the county magistrate, and B is his adviser | |
| Dying to Survive | Office | A: Yong Cheng J: Ling Cao | J is A’s ex-wife | |
| Infernal Affairs | E’s psychotherapy Office | B: Yongren Liu E: Xiner Li | E is B’s therapist | |
Table 2 The scene information of two-person dialogues
| Genre | Film name | Two-person dialogues | ||
|---|---|---|---|---|
| Location | Character code | Relationship | ||
| Comedy | From Beijing with Love | Restaurant | A: Ling-Ling-Chat B: Xiangqin Li | B appears to cooperate with A on the surface, but is secretly tasked with assassinating him |
| The Dream Factory | Inside the car | D: Kang Qian K: Boss You | K wants to “suffer hardship,” and D arranges for him to spend two months in the countryside | |
| Lost in Thailand | On the airplane | A: Lang Xu F: Bao Wang | A and F are complete strangers | |
| Goodbye Mr. Loser | School bike shed | A: Luo Xia D: Ya Qiu | A and D are classmates, and A is pursuing D romantically | |
| Romance | Finding Mr. Right | B’s home | A: Jiajia Wen B: Zhi Hao | B is a driver working for a maternity center in Seattle, while A is a expectant mother who has flown from China to Seattle |
| If You Are the One | Phone call from B to A | A: Fen Qin B: Xiaoxiao Liang | A and B once went on a blind date | |
| Under the Hawthorn Tree | B and M’s home | B: Jingqiu M: Jingqiu’s mother | M is B’s mother | |
| Love is Not Blind | Outside of the restaurant | F: Ran Lu I: Xiaoxian Huang | F is I’s ex-boyfriend | |
| Mystery | The Great Hypnotist | A’s psychotherapy Office | A: Ruining Xu B: Xiaoyan Ren | A is B’s therapist |
| The Message | Temporary hideout A and B | A: Xiaomeng Gu B: Ningyu Li | Both work at the puppet army headquarters, but are suspected by their superiors of being the Communist spy known as “Old Ghost” | |
| Mad Detective | Inside the police car | C: Zhiwei Gao E: Guozhu Wang | C and E are police colleagues | |
| Drama | Youth | A’s Dormitory | A: Feng Liu B: Xiaoping He | A is a male soldier in the art troupe, and B is a female soldier in the same troupe |
| Let the Bullets Fly | County magistrate’s office | A: Muzhi Zhang B: Bangde Ma | A is the county magistrate, and B is his adviser | |
| Dying to Survive | Office | A: Yong Cheng J: Ling Cao | J is A’s ex-wife | |
| Infernal Affairs | E’s psychotherapy Office | B: Yongren Liu E: Xiner Li | E is B’s therapist | |
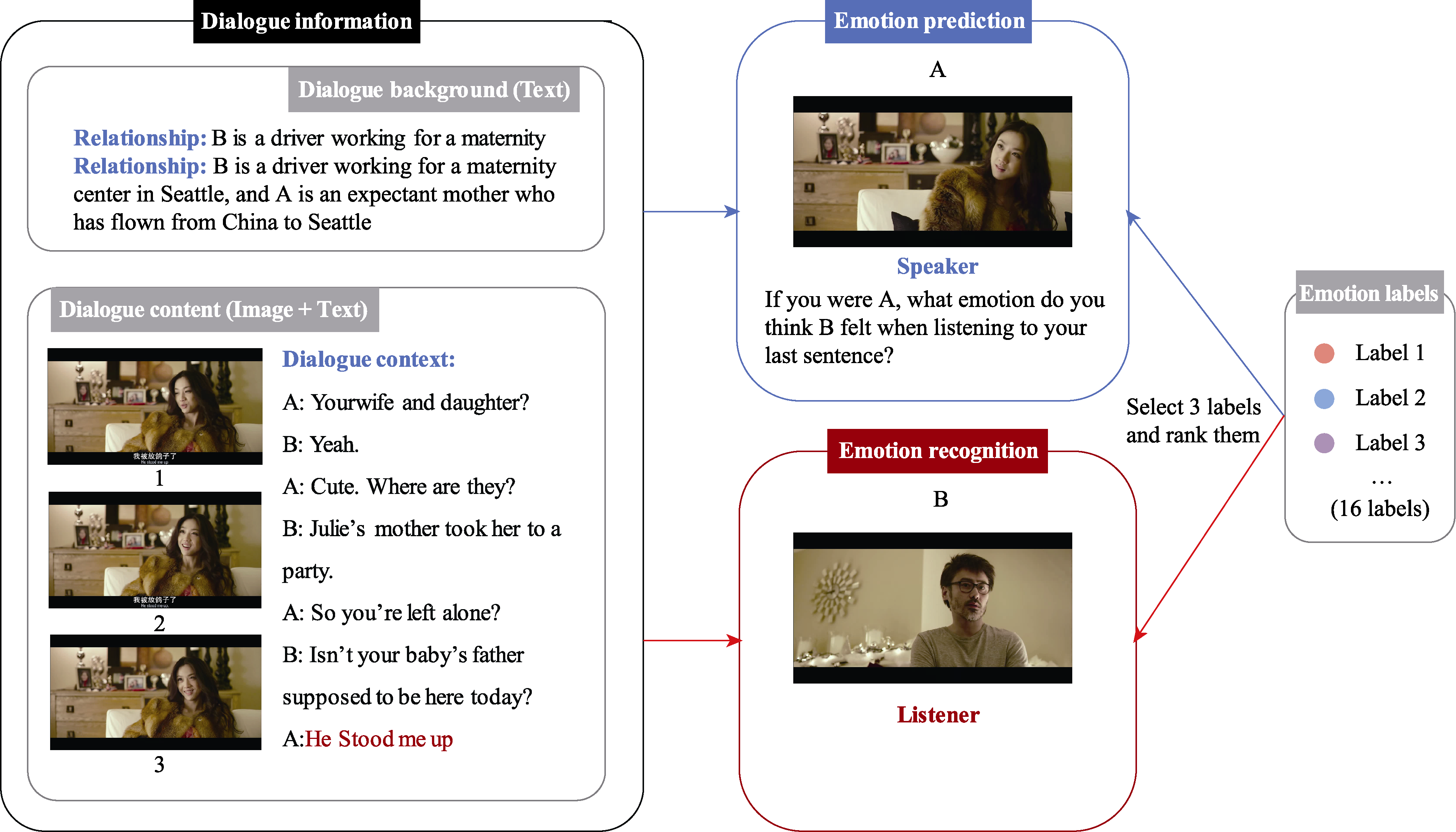
Figure 1. Design and description of the emotional capabilities evaluation.
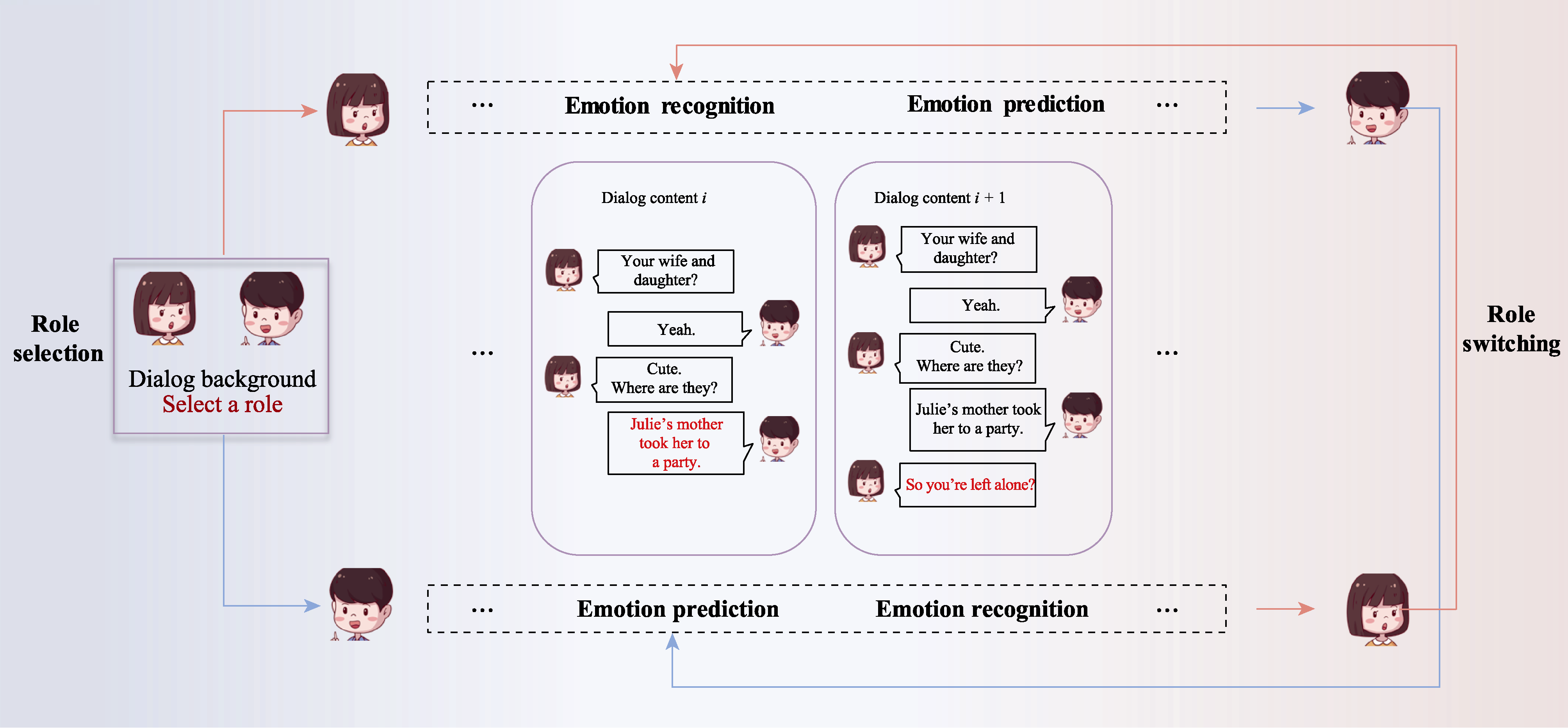
Figure 2. Example flowchart of the human participant Assessment procedure.
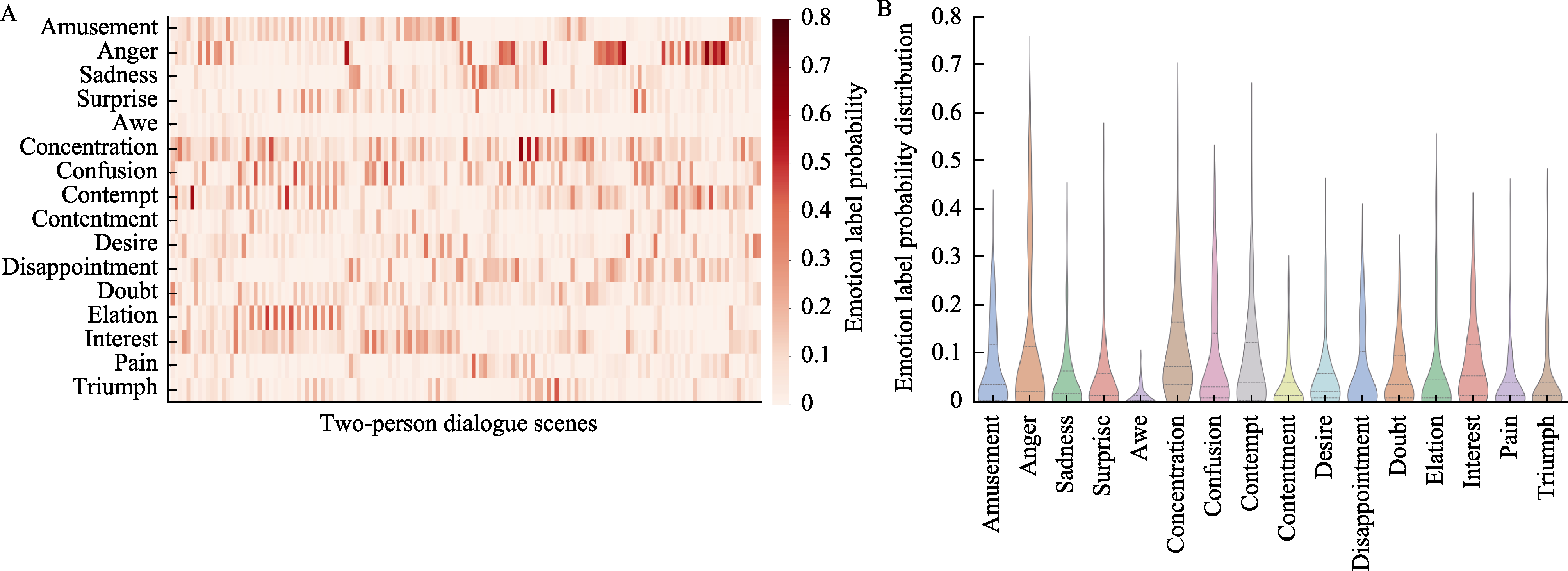
Figure 3. Probability distribution matrix of emotion labels in two-person dialogue scenes and mean probability distributions for human emotion recognition.
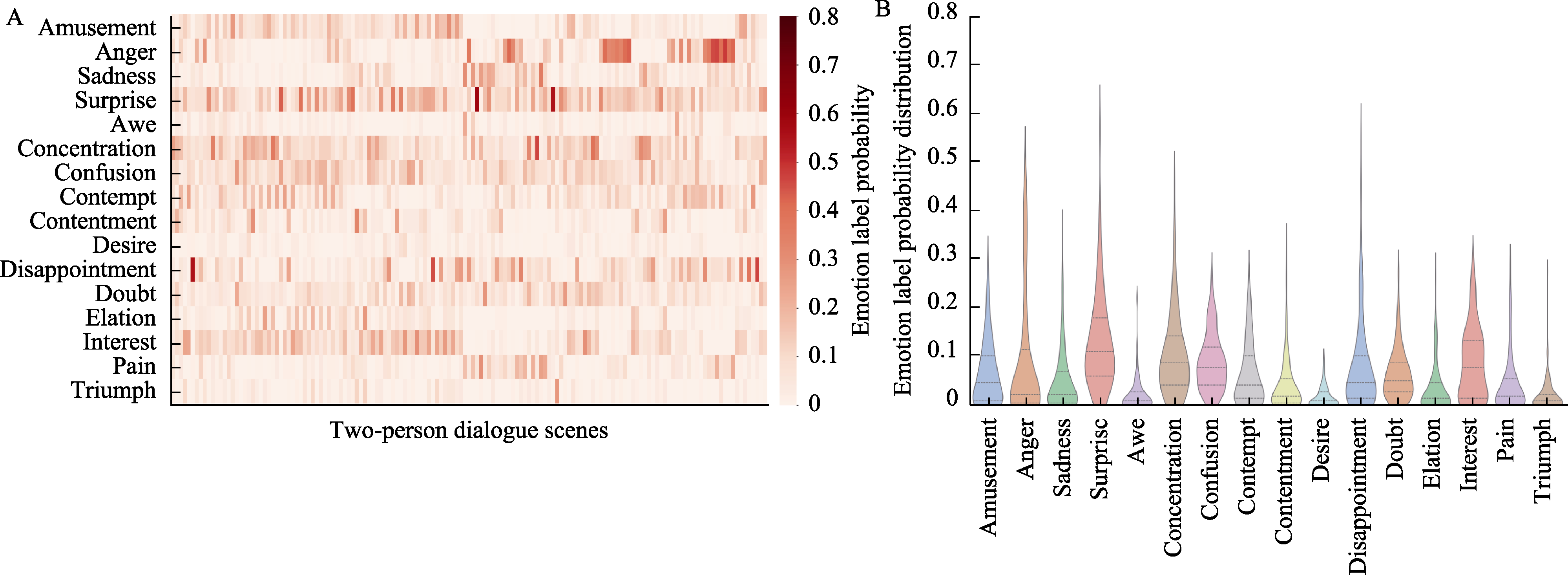
Figure 4. Probability distribution matrix of emotion labels in two-person dialogue scenes and mean probability distributions for human emotion prediction.
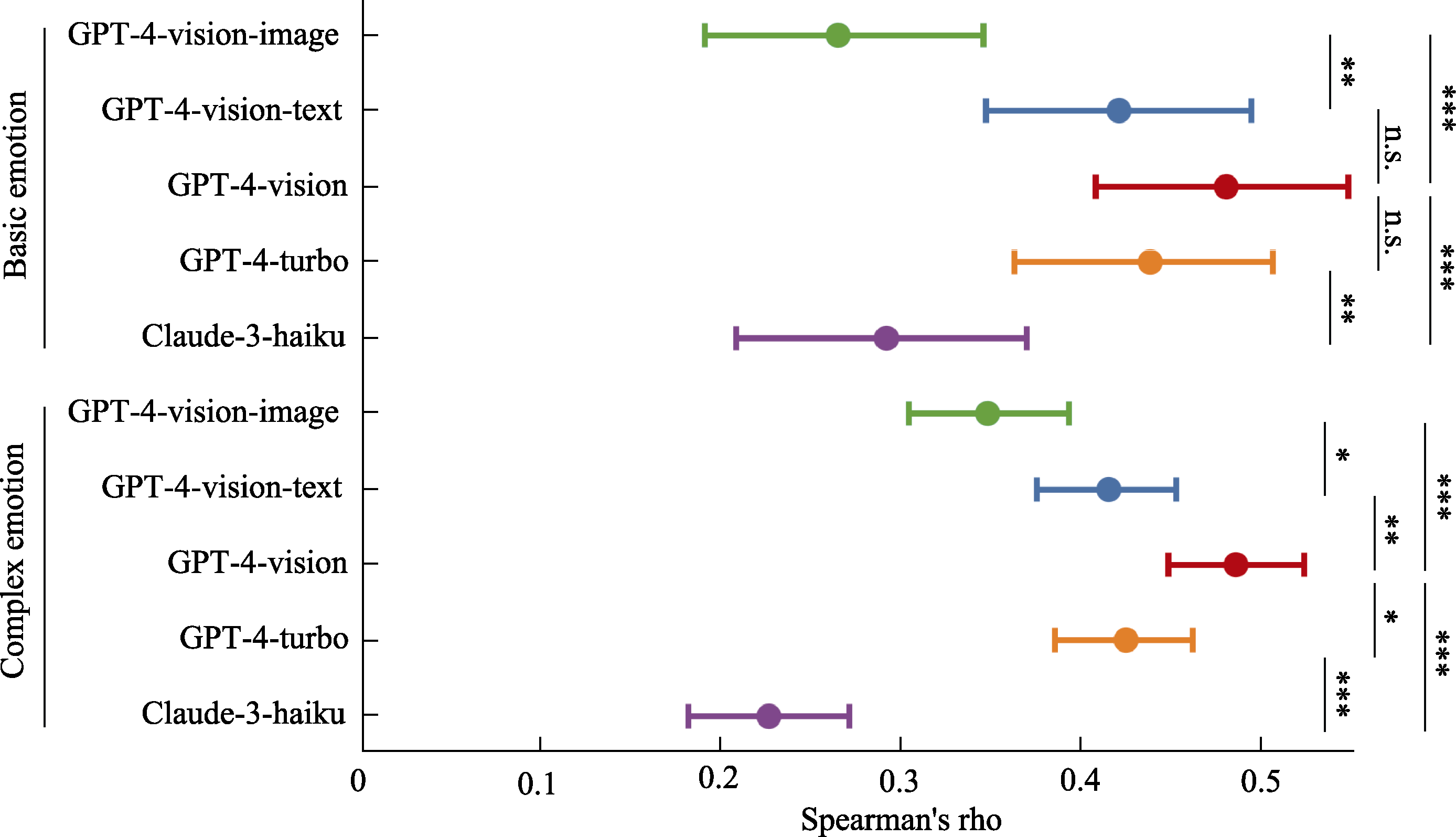
Figure 5. Spearman correlation analysis and comparison of multimodal large language models in zero-shot emotion recognition. Note. *p < 0.05, **p < 0.01, ***p < 0.001, n.s. p > 0.05, the same applies below.
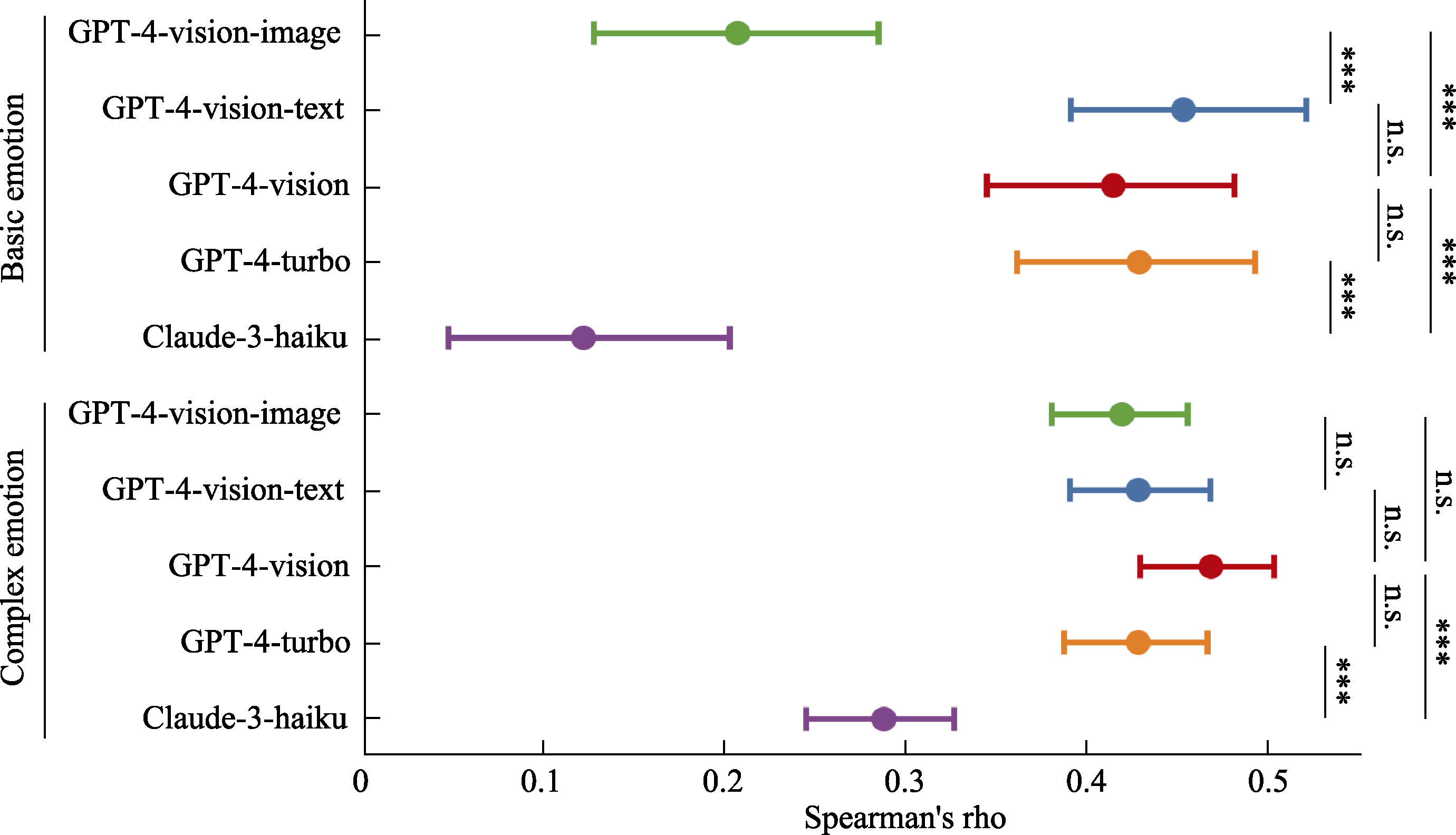
Figure 6. Spearman correlation analysis and comparison of multimodal large language models in zero-shot emotion prediction.
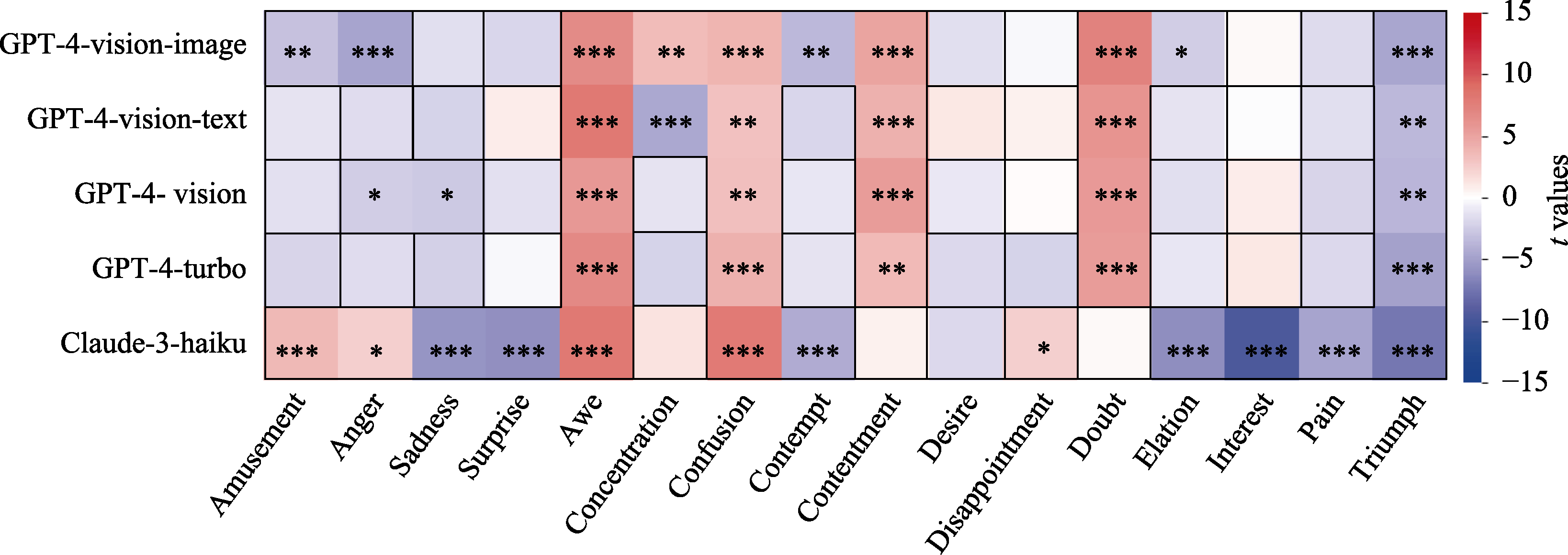
Figure 7. Independent samples t-test of multimodal large language models in zero-shot emotion recognition.
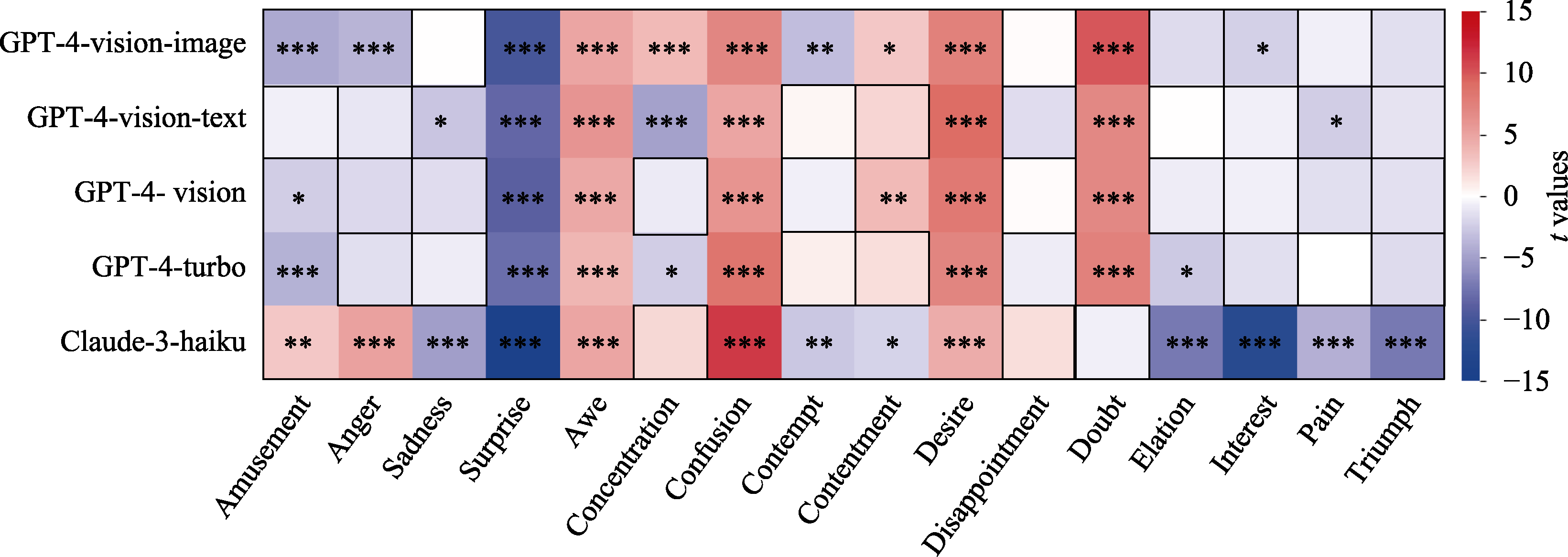
Figure 8. Independent samples t-test of multimodal large language models in zero-shot emotion prediction.
| Emotion labels | Participant M ± SD | GPT-4-vision-image M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.04 ± 0.07 | 296 | ?3.11 | 0.004 | ?0.36 | [?0.05, ?0.01] |
| Anger | 0.11 ± 0.17 | 0.04 ± 0.07 | 296 | ?4.75 | 0.000 | ?0.55 | [?0.10, ?0.04] |
| Sadness | 0.05 ± 0.07 | 0.04 ± 0.06 | 296 | ?1.45 | 0.178 | ?0.17 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.03 ± 0.05 | 296 | ?1.93 | 0.080 | ?0.22 | [?0.03, 0.00] |
| Awe | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 6.66 | 0.000 | 0.77 | [0.01, 0.02] |
| Concentration | 0.12 ± 0.12 | 0.17 ± 0.14 | 296 | 3.41 | 0.001 | 0.40 | [0.02, 0.08] |
| Confusion | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.96 | 0.000 | 0.46 | [0.02, 0.07] |
| Contempt | 0.09 ± 0.11 | 0.05 ± 0.07 | 296 | ?3.52 | 0.001 | ?0.41 | [?0.06, ?0.02] |
| Contentment | 0.03 ± 0.05 | 0.08 ± 0.10 | 296 | 4.93 | 0.000 | 0.57 | [0.03, 0.06] |
| Desire | 0.05 ± 0.08 | 0.04 ± 0.05 | 296 | ?1.42 | 0.178 | ?0.16 | [?0.03, 0.00] |
| Disappointment | 0.07 ± 0.08 | 0.06 ± 0.05 | 296 | ?0.27 | 0.796 | ?0.03 | [?0.02, 0.01] |
| Doubt | 0.06 ± 0.07 | 0.12 ± 0.09 | 296 | 7.23 | 0.000 | 0.84 | [0.05, 0.08] |
| Elation | 0.05 ± 0.10 | 0.03 ± 0.08 | 296 | ?2.43 | 0.025 | ?0.28 | [?0.05, 0.00] |
| Interest | 0.08 ± 0.08 | 0.08 ± 0.09 | 296 | 0.26 | 0.796 | 0.03 | [?0.02, 0.02] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | ?1.73 | 0.112 | ?0.20 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | ?4.60 | 0.000 | ?0.53 | [?0.04, ?0.02] |
Table S1 Results of independent samples t-test between GPT-4-vision-image zero-shot and human participant emotion recognition
| Emotion labels | Participant M ± SD | GPT-4-vision-image M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.04 ± 0.07 | 296 | ?3.11 | 0.004 | ?0.36 | [?0.05, ?0.01] |
| Anger | 0.11 ± 0.17 | 0.04 ± 0.07 | 296 | ?4.75 | 0.000 | ?0.55 | [?0.10, ?0.04] |
| Sadness | 0.05 ± 0.07 | 0.04 ± 0.06 | 296 | ?1.45 | 0.178 | ?0.17 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.03 ± 0.05 | 296 | ?1.93 | 0.080 | ?0.22 | [?0.03, 0.00] |
| Awe | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 6.66 | 0.000 | 0.77 | [0.01, 0.02] |
| Concentration | 0.12 ± 0.12 | 0.17 ± 0.14 | 296 | 3.41 | 0.001 | 0.40 | [0.02, 0.08] |
| Confusion | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.96 | 0.000 | 0.46 | [0.02, 0.07] |
| Contempt | 0.09 ± 0.11 | 0.05 ± 0.07 | 296 | ?3.52 | 0.001 | ?0.41 | [?0.06, ?0.02] |
| Contentment | 0.03 ± 0.05 | 0.08 ± 0.10 | 296 | 4.93 | 0.000 | 0.57 | [0.03, 0.06] |
| Desire | 0.05 ± 0.08 | 0.04 ± 0.05 | 296 | ?1.42 | 0.178 | ?0.16 | [?0.03, 0.00] |
| Disappointment | 0.07 ± 0.08 | 0.06 ± 0.05 | 296 | ?0.27 | 0.796 | ?0.03 | [?0.02, 0.01] |
| Doubt | 0.06 ± 0.07 | 0.12 ± 0.09 | 296 | 7.23 | 0.000 | 0.84 | [0.05, 0.08] |
| Elation | 0.05 ± 0.10 | 0.03 ± 0.08 | 296 | ?2.43 | 0.025 | ?0.28 | [?0.05, 0.00] |
| Interest | 0.08 ± 0.08 | 0.08 ± 0.09 | 296 | 0.26 | 0.796 | 0.03 | [?0.02, 0.02] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | ?1.73 | 0.112 | ?0.20 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | ?4.60 | 0.000 | ?0.53 | [?0.04, ?0.02] |
| Emotion labels | Participant M ± SD | GPT-4-vision-image M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.03 ± 0.05 | 296 | ?4.44 | 0.000 | ?0.51 | [?0.04, ?0.02] |
| Anger | 0.09 ± 0.13 | 0.04 ± 0.05 | 296 | ?3.82 | 0.000 | ?0.44 | [?0.07, ?0.02] |
| Sadness | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | 0.05 | 0.963 | 0.01 | [?0.01, 0.01] |
| Surprise | 0.13 ± 0.10 | 0.04 ± 0.04 | 296 | ?9.87 | 0.000 | ?1.14 | [?0.11, ?0.07] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.87 | 0.000 | 0.56 | [0.01, 0.02] |
| Concentration | 0.10 ± 0.09 | 0.14 ± 0.09 | 296 | 3.63 | 0.001 | 0.42 | [0.02, 0.06] |
| Confusion | 0.09 ± 0.06 | 0.14 ± 0.07 | 296 | 6.98 | 0.000 | 0.81 | [0.04, 0.07] |
| Contempt | 0.06 ± 0.07 | 0.04 ± 0.04 | 296 | ?3.19 | 0.003 | ?0.37 | [?0.03, ?0.01] |
| Contentment | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.70 | 0.012 | 0.31 | [0.00, 0.03] |
| Desire | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 7.44 | 0.000 | 0.86 | [0.02, 0.04] |
| Disappointment | 0.08 ± 0.10 | 0.08 ± 0.05 | 296 | 0.20 | 0.897 | 0.02 | [?0.02, 0.02] |
| Doubt | 0.07 ± 0.05 | 0.13 ± 0.06 | 296 | 9.95 | 0.000 | 1.15 | [0.05, 0.08] |
| Elation | 0.03 ± 0.05 | 0.02 ± 0.05 | 296 | ?1.71 | 0.118 | ?0.20 | [?0.02, 0.00] |
| Interest | 0.09 ± 0.08 | 0.07 ± 0.06 | 296 | ?2.30 | 0.033 | ?0.27 | [?0.03, 0.00] |
| Pain | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | ?0.64 | 0.599 | ?0.07 | [?0.02, 0.01] |
| Triumph | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | ?1.44 | 0.186 | ?0.17 | [?0.01, 0.00] |
Table S2 Results of independent samples t-test between GPT-4-vision-image zero-shot and human participant emotion prediction
| Emotion labels | Participant M ± SD | GPT-4-vision-image M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.03 ± 0.05 | 296 | ?4.44 | 0.000 | ?0.51 | [?0.04, ?0.02] |
| Anger | 0.09 ± 0.13 | 0.04 ± 0.05 | 296 | ?3.82 | 0.000 | ?0.44 | [?0.07, ?0.02] |
| Sadness | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | 0.05 | 0.963 | 0.01 | [?0.01, 0.01] |
| Surprise | 0.13 ± 0.10 | 0.04 ± 0.04 | 296 | ?9.87 | 0.000 | ?1.14 | [?0.11, ?0.07] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.87 | 0.000 | 0.56 | [0.01, 0.02] |
| Concentration | 0.10 ± 0.09 | 0.14 ± 0.09 | 296 | 3.63 | 0.001 | 0.42 | [0.02, 0.06] |
| Confusion | 0.09 ± 0.06 | 0.14 ± 0.07 | 296 | 6.98 | 0.000 | 0.81 | [0.04, 0.07] |
| Contempt | 0.06 ± 0.07 | 0.04 ± 0.04 | 296 | ?3.19 | 0.003 | ?0.37 | [?0.03, ?0.01] |
| Contentment | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.70 | 0.012 | 0.31 | [0.00, 0.03] |
| Desire | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 7.44 | 0.000 | 0.86 | [0.02, 0.04] |
| Disappointment | 0.08 ± 0.10 | 0.08 ± 0.05 | 296 | 0.20 | 0.897 | 0.02 | [?0.02, 0.02] |
| Doubt | 0.07 ± 0.05 | 0.13 ± 0.06 | 296 | 9.95 | 0.000 | 1.15 | [0.05, 0.08] |
| Elation | 0.03 ± 0.05 | 0.02 ± 0.05 | 296 | ?1.71 | 0.118 | ?0.20 | [?0.02, 0.00] |
| Interest | 0.09 ± 0.08 | 0.07 ± 0.06 | 296 | ?2.30 | 0.033 | ?0.27 | [?0.03, 0.00] |
| Pain | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | ?0.64 | 0.599 | ?0.07 | [?0.02, 0.01] |
| Triumph | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | ?1.44 | 0.186 | ?0.17 | [?0.01, 0.00] |
| Emotion labels | Participant M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | ?1.22 | 0.300 | ?0.14 | [?0.03, 0.01] |
| Anger | 0.11 ± 0.17 | 0.08 ± 0.12 | 296 | ?1.56 | 0.208 | ?0.18 | [?0.06, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | ?2.19 | 0.066 | ?0.25 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.06 ± 0.08 | 296 | 0.92 | 0.412 | 0.11 | [?0.01, 0.03] |
| Awe | 0.01 ± 0.02 | 0.04 ± 0.03 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.03] |
| Concentration | 0.12 ± 0.12 | 0.06 ± 0.08 | 296 | ?4.47 | 0.000 | ?0.52 | [?0.08, ?0.03] |
| Confusion | 0.09 ± 0.11 | 0.12 ± 0.09 | 296 | 3.12 | 0.005 | 0.36 | [0.01, 0.06] |
| Contempt | 0.09 ± 0.11 | 0.07 ± 0.07 | 296 | ?1.92 | 0.111 | ?0.22 | [?0.04, 0.00] |
| Contentment | 0.03 ± 0.05 | 0.06 ± 0.07 | 296 | 4.21 | 0.000 | 0.49 | [0.02, 0.04] |
| Desire | 0.05 ± 0.08 | 0.06 ± 0.06 | 296 | 1.10 | 0.336 | 0.13 | [?0.01, 0.03] |
| Disappointment | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.67 | 0.534 | 0.08 | [?0.01, 0.02] |
| Doubt | 0.06 ± 0.07 | 0.11 ± 0.07 | 296 | 6.06 | 0.000 | 0.70 | [0.03, 0.07] |
| Elation | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | ?1.22 | 0.300 | ?0.14 | [?0.03, 0.01] |
| Interest | 0.08 ± 0.08 | 0.08 ± 0.07 | 296 | ?0.16 | 0.870 | ?0.02 | [?0.02, 0.02] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | ?1.52 | 0.208 | ?0.18 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.02 ± 0.03 | 296 | ?3.60 | 0.001 | ?0.42 | [?0.03, ?0.01] |
Table S3 Results of independent samples t-test between GPT-4-vision-text zero-shot and human participant emotion recognition
| Emotion labels | Participant M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | ?1.22 | 0.300 | ?0.14 | [?0.03, 0.01] |
| Anger | 0.11 ± 0.17 | 0.08 ± 0.12 | 296 | ?1.56 | 0.208 | ?0.18 | [?0.06, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | ?2.19 | 0.066 | ?0.25 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.06 ± 0.08 | 296 | 0.92 | 0.412 | 0.11 | [?0.01, 0.03] |
| Awe | 0.01 ± 0.02 | 0.04 ± 0.03 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.03] |
| Concentration | 0.12 ± 0.12 | 0.06 ± 0.08 | 296 | ?4.47 | 0.000 | ?0.52 | [?0.08, ?0.03] |
| Confusion | 0.09 ± 0.11 | 0.12 ± 0.09 | 296 | 3.12 | 0.005 | 0.36 | [0.01, 0.06] |
| Contempt | 0.09 ± 0.11 | 0.07 ± 0.07 | 296 | ?1.92 | 0.111 | ?0.22 | [?0.04, 0.00] |
| Contentment | 0.03 ± 0.05 | 0.06 ± 0.07 | 296 | 4.21 | 0.000 | 0.49 | [0.02, 0.04] |
| Desire | 0.05 ± 0.08 | 0.06 ± 0.06 | 296 | 1.10 | 0.336 | 0.13 | [?0.01, 0.03] |
| Disappointment | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.67 | 0.534 | 0.08 | [?0.01, 0.02] |
| Doubt | 0.06 ± 0.07 | 0.11 ± 0.07 | 296 | 6.06 | 0.000 | 0.70 | [0.03, 0.07] |
| Elation | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | ?1.22 | 0.300 | ?0.14 | [?0.03, 0.01] |
| Interest | 0.08 ± 0.08 | 0.08 ± 0.07 | 296 | ?0.16 | 0.870 | ?0.02 | [?0.02, 0.02] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.05 | 296 | ?1.52 | 0.208 | ?0.18 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.02 ± 0.03 | 296 | ?3.60 | 0.001 | ?0.42 | [?0.03, ?0.01] |
| Emotion labels | Participant M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.06 ± 0.07 | 296 | ?0.61 | 0.619 | ?0.07 | [?0.02, 0.01] |
| Anger | 0.09 ± 0.13 | 0.07 ± 0.10 | 296 | ?1.08 | 0.375 | ?0.13 | [?0.04, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.04 | 296 | ?2.84 | 0.011 | ?0.33 | [?0.03, ?0.01] |
| Surprise | 0.13 ± 0.10 | 0.05 ± 0.06 | 296 | ?8.33 | 0.000 | ?0.97 | [?0.10, ?0.06] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 5.98 | 0.000 | 0.69 | [0.02, 0.03] |
| Concentration | 0.10 ± 0.09 | 0.06 ± 0.07 | 296 | ?4.84 | 0.000 | ?0.56 | [?0.06, ?0.03] |
| Confusion | 0.09 ± 0.06 | 0.13 ± 0.08 | 296 | 4.86 | 0.000 | 0.56 | [0.02, 0.06] |
| Contempt | 0.06 ± 0.07 | 0.07 ± 0.07 | 296 | 0.37 | 0.757 | 0.04 | [?0.01, 0.02] |
| Contentment | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.10 | 0.065 | 0.24 | [0.00, 0.03] |
| Desire | 0.02 ± 0.02 | 0.06 ± 0.05 | 296 | 9.09 | 0.000 | 1.05 | [0.03, 0.05] |
| Disappointment | 0.08 ± 0.10 | 0.07 ± 0.05 | 296 | ?1.57 | 0.188 | ?0.18 | [?0.03, 0.00] |
| Doubt | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.85 | 0.000 | 0.79 | [0.04, 0.06] |
| Elation | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | 0.08 | 0.935 | 0.01 | [?0.01, 0.01] |
| Interest | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | ?0.63 | 0.619 | ?0.07 | [?0.02, 0.01] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | ?2.34 | 0.039 | ?0.27 | [?0.02, 0.00] |
| Triumph | 0.02 ± 0.03 | 0.02 ± 0.03 | 296 | ?1.26 | 0.305 | ?0.15 | [?0.01, 0.00] |
Table S4 Results of independent samples t-test between GPT-4-vision-text zero-shot and human participant emotion prediction
| Emotion labels | Participant M ± SD | GPT-4-vision-text M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.06 ± 0.07 | 296 | ?0.61 | 0.619 | ?0.07 | [?0.02, 0.01] |
| Anger | 0.09 ± 0.13 | 0.07 ± 0.10 | 296 | ?1.08 | 0.375 | ?0.13 | [?0.04, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.04 | 296 | ?2.84 | 0.011 | ?0.33 | [?0.03, ?0.01] |
| Surprise | 0.13 ± 0.10 | 0.05 ± 0.06 | 296 | ?8.33 | 0.000 | ?0.97 | [?0.10, ?0.06] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 5.98 | 0.000 | 0.69 | [0.02, 0.03] |
| Concentration | 0.10 ± 0.09 | 0.06 ± 0.07 | 296 | ?4.84 | 0.000 | ?0.56 | [?0.06, ?0.03] |
| Confusion | 0.09 ± 0.06 | 0.13 ± 0.08 | 296 | 4.86 | 0.000 | 0.56 | [0.02, 0.06] |
| Contempt | 0.06 ± 0.07 | 0.07 ± 0.07 | 296 | 0.37 | 0.757 | 0.04 | [?0.01, 0.02] |
| Contentment | 0.04 ± 0.06 | 0.06 ± 0.06 | 296 | 2.10 | 0.065 | 0.24 | [0.00, 0.03] |
| Desire | 0.02 ± 0.02 | 0.06 ± 0.05 | 296 | 9.09 | 0.000 | 1.05 | [0.03, 0.05] |
| Disappointment | 0.08 ± 0.10 | 0.07 ± 0.05 | 296 | ?1.57 | 0.188 | ?0.18 | [?0.03, 0.00] |
| Doubt | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.85 | 0.000 | 0.79 | [0.04, 0.06] |
| Elation | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | 0.08 | 0.935 | 0.01 | [?0.01, 0.01] |
| Interest | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | ?0.63 | 0.619 | ?0.07 | [?0.02, 0.01] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | ?2.34 | 0.039 | ?0.27 | [?0.02, 0.00] |
| Triumph | 0.02 ± 0.03 | 0.02 ± 0.03 | 296 | ?1.26 | 0.305 | ?0.15 | [?0.01, 0.00] |
| Emotion labels | Participant M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | ?1.30 | 0.282 | ?0.15 | [?0.03, 0.01] |
| Anger | 0.11 ± 0.17 | 0.07 ± 0.11 | 296 | ?2.44 | 0.035 | ?0.28 | [?0.07, ?0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | ?2.61 | 0.026 | ?0.30 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.04 ± 0.04 | 296 | ?1.32 | 0.282 | ?0.15 | [?0.03, 0.01] |
| Awe | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 5.68 | 0.000 | 0.66 | [0.01, 0.02] |
| Concentration | 0.12 ± 0.12 | 0.10 ± 0.10 | 296 | ?1.22 | 0.296 | ?0.14 | [?0.04, 0.01] |
| Confusion | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.18 | 0.005 | 0.37 | [0.01, 0.06] |
| Contempt | 0.09 ± 0.11 | 0.08 ± 0.09 | 296 | ?1.11 | 0.329 | ?0.13 | [?0.04, 0.01] |
| Contentment | 0.03 ± 0.05 | 0.07 ± 0.08 | 296 | 5.51 | 0.000 | 0.64 | [0.03, 0.06] |
| Desire | 0.05 ± 0.08 | 0.05 ± 0.05 | 296 | ?0.98 | 0.377 | ?0.11 | [?0.02, 0.01] |
| Disappointment | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.13 | 0.898 | 0.01 | [?0.02, 0.02] |
| Doubt | 0.06 ± 0.07 | 0.11 ± 0.08 | 296 | 5.52 | 0.000 | 0.64 | [0.03, 0.06] |
| Elation | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | ?1.52 | 0.232 | ?0.18 | [?0.03, 0.00] |
| Interest | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 0.86 | 0.414 | 0.10 | [?0.01, 0.03] |
| Pain | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | ?2.04 | 0.084 | ?0.24 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | ?3.70 | 0.001 | ?0.43 | [?0.03, ?0.01] |
Table S5 Results of independent samples t-test between GPT-4-vision zero-shot and human participant emotion recognition
| Emotion labels | Participant M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.06 ± 0.08 | 296 | ?1.30 | 0.282 | ?0.15 | [?0.03, 0.01] |
| Anger | 0.11 ± 0.17 | 0.07 ± 0.11 | 296 | ?2.44 | 0.035 | ?0.28 | [?0.07, ?0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | ?2.61 | 0.026 | ?0.30 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.04 ± 0.04 | 296 | ?1.32 | 0.282 | ?0.15 | [?0.03, 0.01] |
| Awe | 0.01 ± 0.02 | 0.03 ± 0.03 | 296 | 5.68 | 0.000 | 0.66 | [0.01, 0.02] |
| Concentration | 0.12 ± 0.12 | 0.10 ± 0.10 | 296 | ?1.22 | 0.296 | ?0.14 | [?0.04, 0.01] |
| Confusion | 0.09 ± 0.11 | 0.13 ± 0.10 | 296 | 3.18 | 0.005 | 0.37 | [0.01, 0.06] |
| Contempt | 0.09 ± 0.11 | 0.08 ± 0.09 | 296 | ?1.11 | 0.329 | ?0.13 | [?0.04, 0.01] |
| Contentment | 0.03 ± 0.05 | 0.07 ± 0.08 | 296 | 5.51 | 0.000 | 0.64 | [0.03, 0.06] |
| Desire | 0.05 ± 0.08 | 0.05 ± 0.05 | 296 | ?0.98 | 0.377 | ?0.11 | [?0.02, 0.01] |
| Disappointment | 0.07 ± 0.08 | 0.07 ± 0.06 | 296 | 0.13 | 0.898 | 0.01 | [?0.02, 0.02] |
| Doubt | 0.06 ± 0.07 | 0.11 ± 0.08 | 296 | 5.52 | 0.000 | 0.64 | [0.03, 0.06] |
| Elation | 0.05 ± 0.10 | 0.04 ± 0.06 | 296 | ?1.52 | 0.232 | ?0.18 | [?0.03, 0.00] |
| Interest | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 0.86 | 0.414 | 0.10 | [?0.01, 0.03] |
| Pain | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | ?2.04 | 0.084 | ?0.24 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.02 ± 0.04 | 296 | ?3.70 | 0.001 | ?0.43 | [?0.03, ?0.01] |
| Emotion labels | Participant M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.05 ± 0.06 | 296 | ?2.37 | 0.042 | ?0.27 | [?0.03, 0.00] |
| Anger | 0.09 ± 0.13 | 0.06 ± 0.09 | 296 | ?1.87 | 0.126 | ?0.22 | [?0.05, 0.00] |
| Sadness | 0.05 ± 0.07 | 0.04 ± 0.04 | 296 | ?1.61 | 0.193 | ?0.19 | [?0.02, 0.00] |
| Surprise | 0.13 ± 0.10 | 0.05 ± 0.05 | 296 | ?8.82 | 0.000 | ?1.02 | [?0.10, ?0.06] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.68 | 0.000 | 0.54 | [0.01, 0.02] |
| Concentration | 0.10 ± 0.09 | 0.10 ± 0.08 | 296 | ?0.87 | 0.513 | ?0.10 | [?0.03, 0.01] |
| Confusion | 0.09 ± 0.06 | 0.13 ± 0.07 | 296 | 5.99 | 0.000 | 0.69 | [0.03, 0.06] |
| Contempt | 0.06 ± 0.07 | 0.06 ± 0.06 | 296 | ?0.68 | 0.571 | ?0.08 | [?0.02, 0.01] |
| Contentment | 0.04 ± 0.06 | 0.07 ± 0.07 | 296 | 3.53 | 0.001 | 0.41 | [0.01, 0.04] |
| Desire | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.04] |
| Disappointment | 0.08 ± 0.10 | 0.08 ± 0.06 | 296 | 0.16 | 0.870 | 0.02 | [?0.02, 0.02] |
| Doubt | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.82 | 0.000 | 0.79 | [0.03, 0.06] |
| Elation | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | ?0.80 | 0.521 | ?0.09 | [?0.02, 0.01] |
| Interest | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | ?0.62 | 0.571 | ?0.07 | [?0.02, 0.01] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | ?1.46 | 0.233 | ?0.17 | [?0.02, 0.00] |
| Triumph | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | ?1.41 | 0.234 | ?0.16 | [?0.01, 0.00] |
Table S6 Results of independent samples t-test between GPT-4-vision zero-shot and human participant emotion prediction
| Emotion labels | Participant M ± SD | GPT-4-vision M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.05 ± 0.06 | 296 | ?2.37 | 0.042 | ?0.27 | [?0.03, 0.00] |
| Anger | 0.09 ± 0.13 | 0.06 ± 0.09 | 296 | ?1.87 | 0.126 | ?0.22 | [?0.05, 0.00] |
| Sadness | 0.05 ± 0.07 | 0.04 ± 0.04 | 296 | ?1.61 | 0.193 | ?0.19 | [?0.02, 0.00] |
| Surprise | 0.13 ± 0.10 | 0.05 ± 0.05 | 296 | ?8.82 | 0.000 | ?1.02 | [?0.10, ?0.06] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.03 | 296 | 4.68 | 0.000 | 0.54 | [0.01, 0.02] |
| Concentration | 0.10 ± 0.09 | 0.10 ± 0.08 | 296 | ?0.87 | 0.513 | ?0.10 | [?0.03, 0.01] |
| Confusion | 0.09 ± 0.06 | 0.13 ± 0.07 | 296 | 5.99 | 0.000 | 0.69 | [0.03, 0.06] |
| Contempt | 0.06 ± 0.07 | 0.06 ± 0.06 | 296 | ?0.68 | 0.571 | ?0.08 | [?0.02, 0.01] |
| Contentment | 0.04 ± 0.06 | 0.07 ± 0.07 | 296 | 3.53 | 0.001 | 0.41 | [0.01, 0.04] |
| Desire | 0.02 ± 0.02 | 0.05 ± 0.04 | 296 | 8.00 | 0.000 | 0.93 | [0.02, 0.04] |
| Disappointment | 0.08 ± 0.10 | 0.08 ± 0.06 | 296 | 0.16 | 0.870 | 0.02 | [?0.02, 0.02] |
| Doubt | 0.07 ± 0.05 | 0.11 ± 0.07 | 296 | 6.82 | 0.000 | 0.79 | [0.03, 0.06] |
| Elation | 0.03 ± 0.05 | 0.03 ± 0.05 | 296 | ?0.80 | 0.521 | ?0.09 | [?0.02, 0.01] |
| Interest | 0.09 ± 0.08 | 0.08 ± 0.07 | 296 | ?0.62 | 0.571 | ?0.07 | [?0.02, 0.01] |
| Pain | 0.04 ± 0.06 | 0.03 ± 0.04 | 296 | ?1.46 | 0.233 | ?0.17 | [?0.02, 0.00] |
| Triumph | 0.02 ± 0.03 | 0.02 ± 0.02 | 296 | ?1.41 | 0.234 | ?0.16 | [?0.01, 0.00] |
| Emotion labels | Participant M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.05 ± 0.08 | 296 | ?2.04 | 0.075 | ?0.24 | [?0.04, 0.00] |
| Anger | 0.11 ± 0.17 | 0.08 ± 0.14 | 296 | ?1.58 | 0.153 | ?0.18 | [?0.06, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | ?2.31 | 0.057 | ?0.27 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.05 ± 0.07 | 296 | ?0.25 | 0.804 | ?0.03 | [?0.02, 0.02] |
| Awe | 0.01 ± 0.02 | 0.04 ± 0.05 | 296 | 6.77 | 0.000 | 0.78 | [0.02, 0.04] |
| Concentration | 0.12 ± 0.12 | 0.09 ± 0.11 | 296 | ?2.18 | 0.069 | ?0.25 | [?0.05, 0.00] |
| Confusion | 0.09 ± 0.11 | 0.14 ± 0.12 | 296 | 4.12 | 0.000 | 0.48 | [0.03, 0.08] |
| Contempt | 0.09 ± 0.11 | 0.07 ± 0.09 | 296 | ?1.18 | 0.293 | ?0.14 | [?0.04, 0.01] |
| Contentment | 0.03 ± 0.05 | 0.06 ± 0.08 | 296 | 3.62 | 0.001 | 0.42 | [0.01, 0.04] |
| Desire | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | ?1.83 | 0.099 | ?0.21 | [?0.03, 0.00] |
| Disappointment | 0.07 ± 0.08 | 0.05 ± 0.06 | 296 | ?2.12 | 0.070 | ?0.25 | [?0.03, 0.00] |
| Doubt | 0.06 ± 0.07 | 0.11 ± 0.10 | 296 | 5.42 | 0.000 | 0.63 | [0.03, 0.07] |
| Elation | 0.05 ± 0.10 | 0.04 ± 0.08 | 296 | ?1.13 | 0.293 | ?0.13 | [?0.03, 0.01] |
| Interest | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 1.09 | 0.293 | 0.13 | [?0.01, 0.03] |
| Pain | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | ?1.85 | 0.099 | ?0.21 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | ?4.81 | 0.000 | ?0.56 | [?0.04, ?0.02] |
Table S7 Results of independent samples t-test between GPT-4-turbo zero-shot and human participant emotion recognition
| Emotion labels | Participant M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.05 ± 0.08 | 296 | ?2.04 | 0.075 | ?0.24 | [?0.04, 0.00] |
| Anger | 0.11 ± 0.17 | 0.08 ± 0.14 | 296 | ?1.58 | 0.153 | ?0.18 | [?0.06, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.03 ± 0.05 | 296 | ?2.31 | 0.057 | ?0.27 | [?0.03, 0.00] |
| Surprise | 0.05 ± 0.09 | 0.05 ± 0.07 | 296 | ?0.25 | 0.804 | ?0.03 | [?0.02, 0.02] |
| Awe | 0.01 ± 0.02 | 0.04 ± 0.05 | 296 | 6.77 | 0.000 | 0.78 | [0.02, 0.04] |
| Concentration | 0.12 ± 0.12 | 0.09 ± 0.11 | 296 | ?2.18 | 0.069 | ?0.25 | [?0.05, 0.00] |
| Confusion | 0.09 ± 0.11 | 0.14 ± 0.12 | 296 | 4.12 | 0.000 | 0.48 | [0.03, 0.08] |
| Contempt | 0.09 ± 0.11 | 0.07 ± 0.09 | 296 | ?1.18 | 0.293 | ?0.14 | [?0.04, 0.01] |
| Contentment | 0.03 ± 0.05 | 0.06 ± 0.08 | 296 | 3.62 | 0.001 | 0.42 | [0.01, 0.04] |
| Desire | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | ?1.83 | 0.099 | ?0.21 | [?0.03, 0.00] |
| Disappointment | 0.07 ± 0.08 | 0.05 ± 0.06 | 296 | ?2.12 | 0.070 | ?0.25 | [?0.03, 0.00] |
| Doubt | 0.06 ± 0.07 | 0.11 ± 0.10 | 296 | 5.42 | 0.000 | 0.63 | [0.03, 0.07] |
| Elation | 0.05 ± 0.10 | 0.04 ± 0.08 | 296 | ?1.13 | 0.293 | ?0.13 | [?0.03, 0.01] |
| Interest | 0.08 ± 0.08 | 0.09 ± 0.09 | 296 | 1.09 | 0.293 | 0.13 | [?0.01, 0.03] |
| Pain | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | ?1.85 | 0.099 | ?0.21 | [?0.02, 0.00] |
| Triumph | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | ?4.81 | 0.000 | ?0.56 | [?0.04, ?0.02] |
| Emotion labels | Participant M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.04 ± 0.05 | 296 | ?3.88 | 0.000 | ?0.45 | [?0.04, ?0.01] |
| Anger | 0.09 ± 0.13 | 0.07 ± 0.09 | 296 | ?1.48 | 0.192 | ?0.17 | [?0.04, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | ?0.72 | 0.504 | ?0.08 | [?0.02, 0.01] |
| Surprise | 0.13 ± 0.10 | 0.06 ± 0.06 | 296 | ?7.88 | 0.000 | ?0.91 | [?0.09, ?0.06] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 3.83 | 0.000 | 0.44 | [0.01, 0.02] |
| Concentration | 0.10 ± 0.09 | 0.08 ± 0.08 | 296 | ?2.37 | 0.037 | ?0.27 | [?0.04, 0.00] |
| Confusion | 0.09 ± 0.06 | 0.16 ± 0.08 | 296 | 8.36 | 0.000 | 0.97 | [0.05, 0.08] |
| Contempt | 0.06 ± 0.07 | 0.07 ± 0.06 | 296 | 0.77 | 0.504 | 0.09 | [?0.01, 0.02] |
| Contentment | 0.04 ± 0.06 | 0.05 ± 0.06 | 296 | 1.60 | 0.176 | 0.19 | [0.00, 0.03] |
| Desire | 0.02 ± 0.02 | 0.05 ± 0.05 | 296 | 7.05 | 0.000 | 0.82 | [0.02, 0.04] |
| Disappointment | 0.08 ± 0.10 | 0.07 ± 0.06 | 296 | ?0.77 | 0.504 | ?0.09 | [?0.03, 0.01] |
| Doubt | 0.07 ± 0.05 | 0.12 ± 0.07 | 296 | 7.38 | 0.000 | 0.85 | [0.04, 0.07] |
| Elation | 0.03 ± 0.05 | 0.02 ± 0.04 | 296 | ?2.63 | 0.020 | ?0.31 | [?0.02, 0.00] |
| Interest | 0.09 ± 0.08 | 0.07 ± 0.07 | 296 | ?1.47 | 0.192 | ?0.17 | [?0.03, 0.00] |
| Pain | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | ?0.06 | 0.953 | ?0.01 | [?0.01, 0.01] |
| Triumph | 0.02 ± 0.03 | 0.01 ± 0.02 | 296 | ?1.75 | 0.143 | ?0.20 | [?0.01, 0.00] |
Table S8 Results of independent samples t-test between GPT-4-turbo zero-shot and human participant emotion prediction
| Emotion labels | Participant M ± SD | GPT-4-turbo M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.04 ± 0.05 | 296 | ?3.88 | 0.000 | ?0.45 | [?0.04, ?0.01] |
| Anger | 0.09 ± 0.13 | 0.07 ± 0.09 | 296 | ?1.48 | 0.192 | ?0.17 | [?0.04, 0.01] |
| Sadness | 0.05 ± 0.07 | 0.05 ± 0.05 | 296 | ?0.72 | 0.504 | ?0.08 | [?0.02, 0.01] |
| Surprise | 0.13 ± 0.10 | 0.06 ± 0.06 | 296 | ?7.88 | 0.000 | ?0.91 | [?0.09, ?0.06] |
| Awe | 0.02 ± 0.03 | 0.04 ± 0.04 | 296 | 3.83 | 0.000 | 0.44 | [0.01, 0.02] |
| Concentration | 0.10 ± 0.09 | 0.08 ± 0.08 | 296 | ?2.37 | 0.037 | ?0.27 | [?0.04, 0.00] |
| Confusion | 0.09 ± 0.06 | 0.16 ± 0.08 | 296 | 8.36 | 0.000 | 0.97 | [0.05, 0.08] |
| Contempt | 0.06 ± 0.07 | 0.07 ± 0.06 | 296 | 0.77 | 0.504 | 0.09 | [?0.01, 0.02] |
| Contentment | 0.04 ± 0.06 | 0.05 ± 0.06 | 296 | 1.60 | 0.176 | 0.19 | [0.00, 0.03] |
| Desire | 0.02 ± 0.02 | 0.05 ± 0.05 | 296 | 7.05 | 0.000 | 0.82 | [0.02, 0.04] |
| Disappointment | 0.08 ± 0.10 | 0.07 ± 0.06 | 296 | ?0.77 | 0.504 | ?0.09 | [?0.03, 0.01] |
| Doubt | 0.07 ± 0.05 | 0.12 ± 0.07 | 296 | 7.38 | 0.000 | 0.85 | [0.04, 0.07] |
| Elation | 0.03 ± 0.05 | 0.02 ± 0.04 | 296 | ?2.63 | 0.020 | ?0.31 | [?0.02, 0.00] |
| Interest | 0.09 ± 0.08 | 0.07 ± 0.07 | 296 | ?1.47 | 0.192 | ?0.17 | [?0.03, 0.00] |
| Pain | 0.04 ± 0.06 | 0.04 ± 0.05 | 296 | ?0.06 | 0.953 | ?0.01 | [?0.01, 0.01] |
| Triumph | 0.02 ± 0.03 | 0.01 ± 0.02 | 296 | ?1.75 | 0.143 | ?0.20 | [?0.01, 0.00] |
| Emotion labels | Participant M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.13 ± 0.15 | 296 | 3.74 | 0.000 | 0.43 | [0.03, 0.08] |
| Anger | 0.11 ± 0.17 | 0.16 ± 0.17 | 296 | 2.42 | 0.023 | 0.28 | [0.01, 0.09] |
| Sadness | 0.05 ± 0.07 | 0.01 ± 0.03 | 296 | ?5.69 | 0.000 | ?0.66 | [?0.05, ?0.02] |
| Surprise | 0.05 ± 0.09 | 0.00 ± 0.02 | 296 | ?6.09 | 0.000 | ?0.71 | [?0.06, ?0.03] |
| Awe | 0.01 ± 0.02 | 0.06 ± 0.07 | 296 | 8.01 | 0.000 | 0.93 | [0.04, 0.06] |
| Concentration | 0.12 ± 0.12 | 0.13 ± 0.12 | 296 | 1.29 | 0.227 | 0.15 | [?0.01, 0.04] |
| Confusion | 0.09 ± 0.11 | 0.19 ± 0.12 | 296 | 7.90 | 0.000 | 0.92 | [0.08, 0.14] |
| Contempt | 0.09 ± 0.11 | 0.04 ± 0.07 | 296 | ?4.24 | 0.000 | ?0.49 | [?0.07, ?0.02] |
| Contentment | 0.03 ± 0.05 | 0.04 ± 0.07 | 296 | 0.69 | 0.526 | 0.08 | [?0.01, 0.02] |
| Desire | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | ?1.79 | 0.092 | ?0.21 | [?0.03, 0.00] |
| Disappointment | 0.07 ± 0.08 | 0.09 ± 0.11 | 296 | 2.35 | 0.026 | 0.27 | [0.00, 0.05] |
| Doubt | 0.06 ± 0.07 | 0.06 ± 0.08 | 296 | 0.24 | 0.814 | 0.03 | [?0.02, 0.02] |
| Elation | 0.05 ± 0.10 | 0.00 ± 0.01 | 296 | ?6.20 | 0.000 | ?0.72 | [?0.07, ?0.03] |
| Interest | 0.08 ± 0.08 | 0.01 ± 0.03 | 296 | ?9.54 | 0.000 | ?1.11 | [?0.09, ?0.06] |
| Pain | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | ?4.77 | 0.000 | ?0.55 | [?0.04, ?0.02] |
| Triumph | 0.04 ± 0.06 | 0.00 ± 0.00 | 296 | ?7.32 | 0.000 | ?0.85 | [?0.05, ?0.03] |
Table S9 Results of independent samples t-test between Claude-3-haiku zero-shot and human participant emotion recognition
| Emotion labels | Participant M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.08 | 0.13 ± 0.15 | 296 | 3.74 | 0.000 | 0.43 | [0.03, 0.08] |
| Anger | 0.11 ± 0.17 | 0.16 ± 0.17 | 296 | 2.42 | 0.023 | 0.28 | [0.01, 0.09] |
| Sadness | 0.05 ± 0.07 | 0.01 ± 0.03 | 296 | ?5.69 | 0.000 | ?0.66 | [?0.05, ?0.02] |
| Surprise | 0.05 ± 0.09 | 0.00 ± 0.02 | 296 | ?6.09 | 0.000 | ?0.71 | [?0.06, ?0.03] |
| Awe | 0.01 ± 0.02 | 0.06 ± 0.07 | 296 | 8.01 | 0.000 | 0.93 | [0.04, 0.06] |
| Concentration | 0.12 ± 0.12 | 0.13 ± 0.12 | 296 | 1.29 | 0.227 | 0.15 | [?0.01, 0.04] |
| Confusion | 0.09 ± 0.11 | 0.19 ± 0.12 | 296 | 7.90 | 0.000 | 0.92 | [0.08, 0.14] |
| Contempt | 0.09 ± 0.11 | 0.04 ± 0.07 | 296 | ?4.24 | 0.000 | ?0.49 | [?0.07, ?0.02] |
| Contentment | 0.03 ± 0.05 | 0.04 ± 0.07 | 296 | 0.69 | 0.526 | 0.08 | [?0.01, 0.02] |
| Desire | 0.05 ± 0.08 | 0.04 ± 0.06 | 296 | ?1.79 | 0.092 | ?0.21 | [?0.03, 0.00] |
| Disappointment | 0.07 ± 0.08 | 0.09 ± 0.11 | 296 | 2.35 | 0.026 | 0.27 | [0.00, 0.05] |
| Doubt | 0.06 ± 0.07 | 0.06 ± 0.08 | 296 | 0.24 | 0.814 | 0.03 | [?0.02, 0.02] |
| Elation | 0.05 ± 0.10 | 0.00 ± 0.01 | 296 | ?6.20 | 0.000 | ?0.72 | [?0.07, ?0.03] |
| Interest | 0.08 ± 0.08 | 0.01 ± 0.03 | 296 | ?9.54 | 0.000 | ?1.11 | [?0.09, ?0.06] |
| Pain | 0.04 ± 0.06 | 0.01 ± 0.03 | 296 | ?4.77 | 0.000 | ?0.55 | [?0.04, ?0.02] |
| Triumph | 0.04 ± 0.06 | 0.00 ± 0.00 | 296 | ?7.32 | 0.000 | ?0.85 | [?0.05, ?0.03] |
| Emotion labels | Participant M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.10 ± 0.13 | 296 | 2.75 | 0.009 | 0.32 | [0.01, 0.06] |
| Anger | 0.09 ± 0.13 | 0.17 ± 0.15 | 296 | 5.09 | 0.000 | 0.59 | [0.05, 0.11] |
| Sadness | 0.05 ± 0.07 | 0.02 ± 0.04 | 296 | ?5.15 | 0.000 | ?0.60 | [?0.05, ?0.02] |
| Surprise | 0.13 ± 0.10 | 0.01 ± 0.03 | 296 | ?14.07 | 0.000 | ?1.63 | [?0.14, ?0.11] |
| Awe | 0.02 ± 0.03 | 0.05 ± 0.06 | 296 | 4.83 | 0.000 | 0.56 | [0.02, 0.04] |
| Concentration | 0.10 ± 0.09 | 0.13 ± 0.11 | 296 | 1.93 | 0.063 | 0.22 | [0.00, 0.04] |
| Confusion | 0.09 ± 0.06 | 0.20 ± 0.11 | 296 | 11.28 | 0.000 | 1.31 | [0.09, 0.13] |
| Contempt | 0.06 ± 0.07 | 0.05 ± 0.05 | 296 | ?2.71 | 0.009 | ?0.31 | [?0.03, ?0.01] |
| Contentment | 0.04 ± 0.06 | 0.03 ± 0.06 | 296 | ?2.16 | 0.039 | ?0.25 | [?0.03, 0.00] |
| Desire | 0.02 ± 0.02 | 0.04 ± 0.06 | 296 | 4.34 | 0.000 | 0.50 | [0.01, 0.03] |
| Disappointment | 0.08 ± 0.10 | 0.10 ± 0.10 | 296 | 1.62 | 0.113 | 0.19 | [0.00, 0.04] |
| Doubt | 0.07 ± 0.05 | 0.06 ± 0.07 | 296 | ?0.68 | 0.499 | ?0.08 | [?0.02, 0.01] |
| Elation | 0.03 ± 0.05 | 0.00 ± 0.01 | 296 | ?7.15 | 0.000 | ?0.83 | [?0.04, ?0.02] |
| Interest | 0.09 ± 0.08 | 0.01 ± 0.02 | 296 | ?12.03 | 0.000 | ?1.39 | [?0.09, ?0.07] |
| Pain | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | ?4.08 | 0.000 | ?0.47 | [?0.04, ?0.01] |
| Triumph | 0.02 ± 0.03 | 0.00 ± 0.00 | 296 | ?7.17 | 0.000 | ?0.83 | [?0.02, ?0.01] |
Table S10 Results of independent samples t-test between Claude-3-haiku zero-shot and human participant emotion prediction
| Emotion labels | Participant M ± SD | Claude-3-haiku M ± SD | df | t | p | Cohen’s d | 95% CI |
|---|---|---|---|---|---|---|---|
| Amusement | 0.07 ± 0.07 | 0.10 ± 0.13 | 296 | 2.75 | 0.009 | 0.32 | [0.01, 0.06] |
| Anger | 0.09 ± 0.13 | 0.17 ± 0.15 | 296 | 5.09 | 0.000 | 0.59 | [0.05, 0.11] |
| Sadness | 0.05 ± 0.07 | 0.02 ± 0.04 | 296 | ?5.15 | 0.000 | ?0.60 | [?0.05, ?0.02] |
| Surprise | 0.13 ± 0.10 | 0.01 ± 0.03 | 296 | ?14.07 | 0.000 | ?1.63 | [?0.14, ?0.11] |
| Awe | 0.02 ± 0.03 | 0.05 ± 0.06 | 296 | 4.83 | 0.000 | 0.56 | [0.02, 0.04] |
| Concentration | 0.10 ± 0.09 | 0.13 ± 0.11 | 296 | 1.93 | 0.063 | 0.22 | [0.00, 0.04] |
| Confusion | 0.09 ± 0.06 | 0.20 ± 0.11 | 296 | 11.28 | 0.000 | 1.31 | [0.09, 0.13] |
| Contempt | 0.06 ± 0.07 | 0.05 ± 0.05 | 296 | ?2.71 | 0.009 | ?0.31 | [?0.03, ?0.01] |
| Contentment | 0.04 ± 0.06 | 0.03 ± 0.06 | 296 | ?2.16 | 0.039 | ?0.25 | [?0.03, 0.00] |
| Desire | 0.02 ± 0.02 | 0.04 ± 0.06 | 296 | 4.34 | 0.000 | 0.50 | [0.01, 0.03] |
| Disappointment | 0.08 ± 0.10 | 0.10 ± 0.10 | 296 | 1.62 | 0.113 | 0.19 | [0.00, 0.04] |
| Doubt | 0.07 ± 0.05 | 0.06 ± 0.07 | 296 | ?0.68 | 0.499 | ?0.08 | [?0.02, 0.01] |
| Elation | 0.03 ± 0.05 | 0.00 ± 0.01 | 296 | ?7.15 | 0.000 | ?0.83 | [?0.04, ?0.02] |
| Interest | 0.09 ± 0.08 | 0.01 ± 0.02 | 296 | ?12.03 | 0.000 | ?1.39 | [?0.09, ?0.07] |
| Pain | 0.04 ± 0.06 | 0.02 ± 0.05 | 296 | ?4.08 | 0.000 | ?0.47 | [?0.04, ?0.01] |
| Triumph | 0.02 ± 0.03 | 0.00 ± 0.00 | 296 | ?7.17 | 0.000 | ?0.83 | [?0.02, ?0.01] |

Figure S1. Example prompt for zero-shot emotion recognition evaluation of multimodal large language models.

Figure S2. Example prompt for zero-shot emotion prediction evaluation of multimodal large language models.

Figure S3. Example prompt for repeated-measures emotion recognition evaluation of multimodal large language models.

Figure S4. Example prompt for repeated-measures emotion prediction evaluation of multimodal large language models.
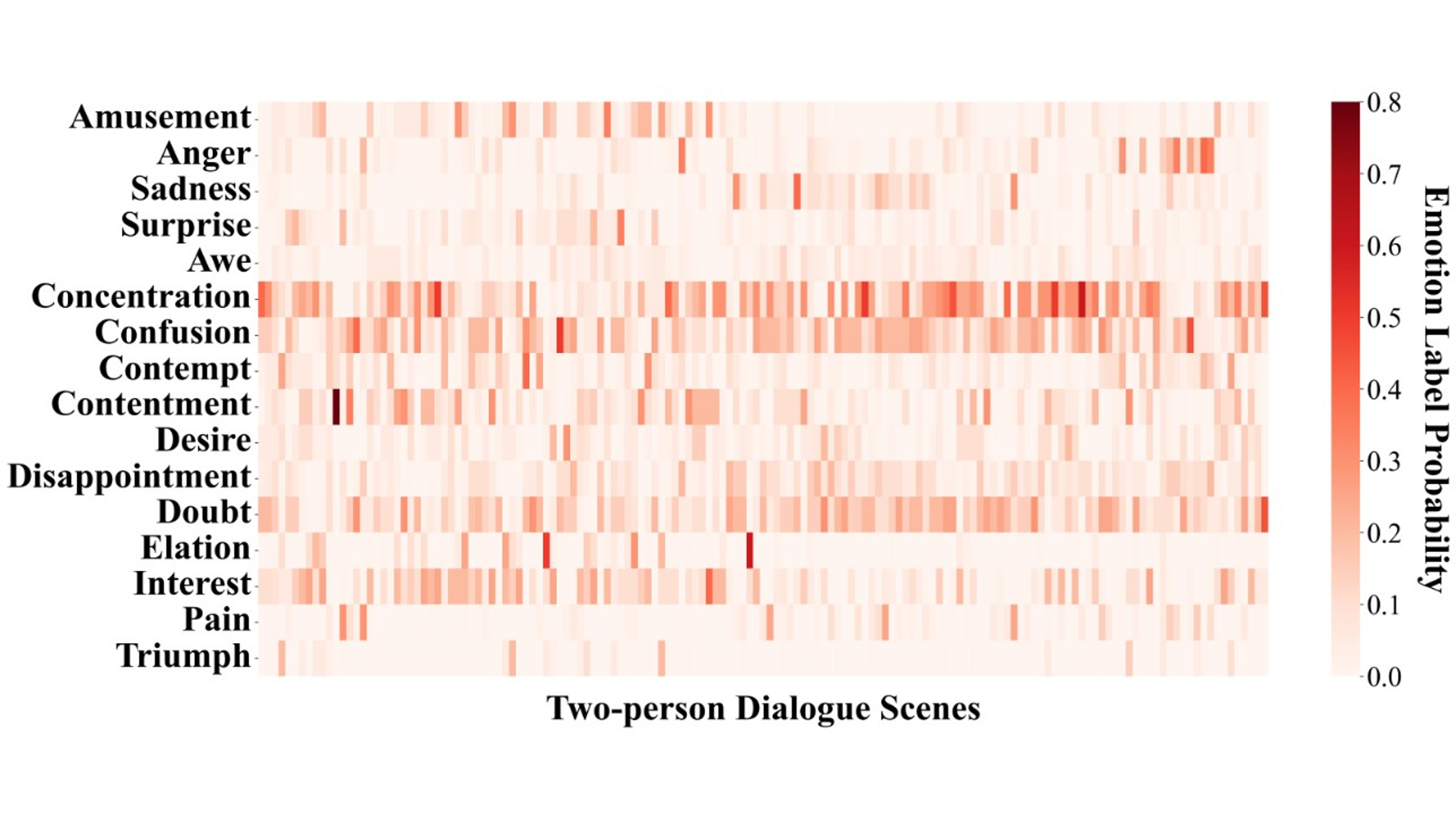
Figure S5. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-vision-image zero-shot emotion recognition.
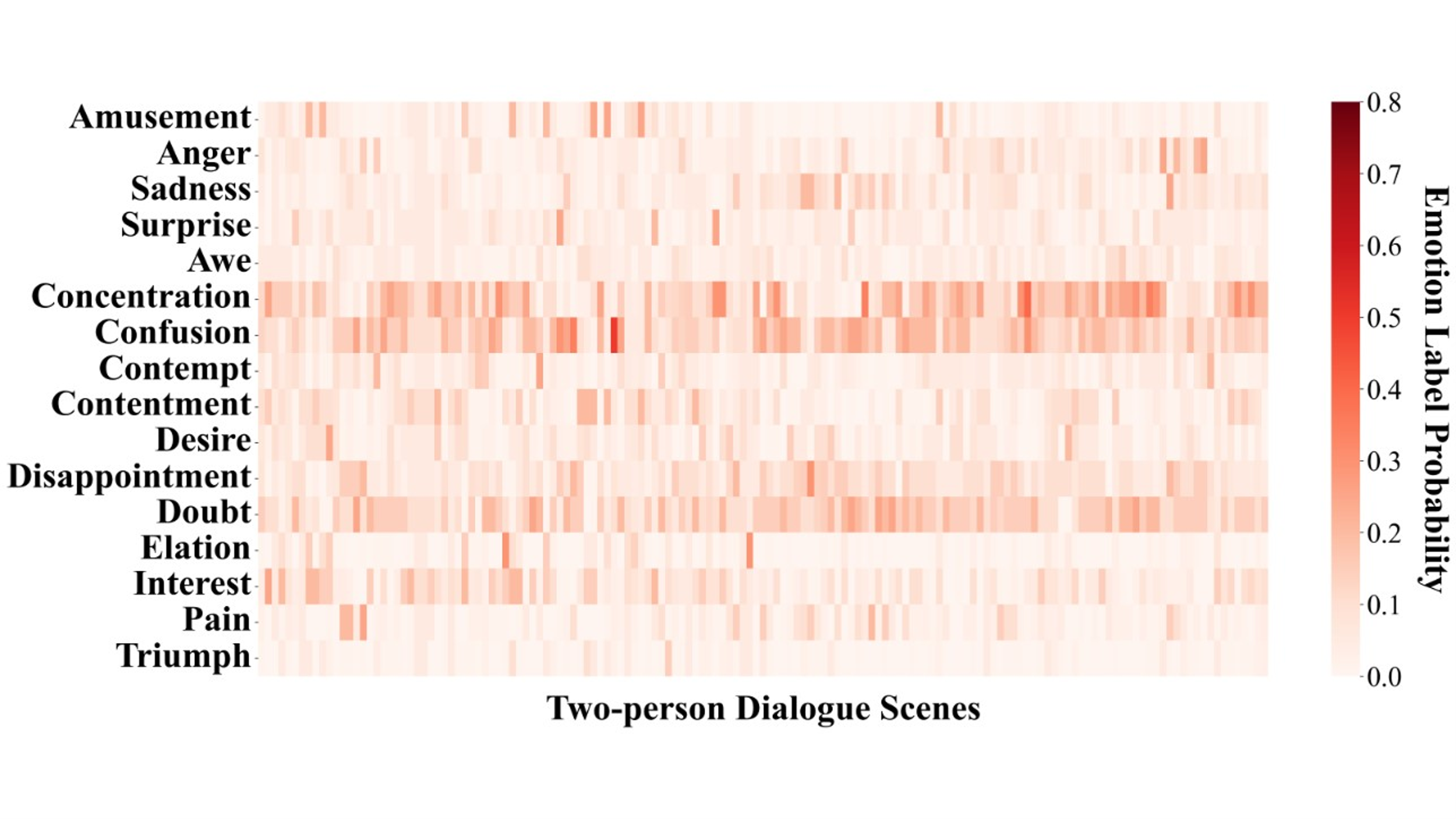
Figure S6. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-vision-image zero-shot emotion prediction.
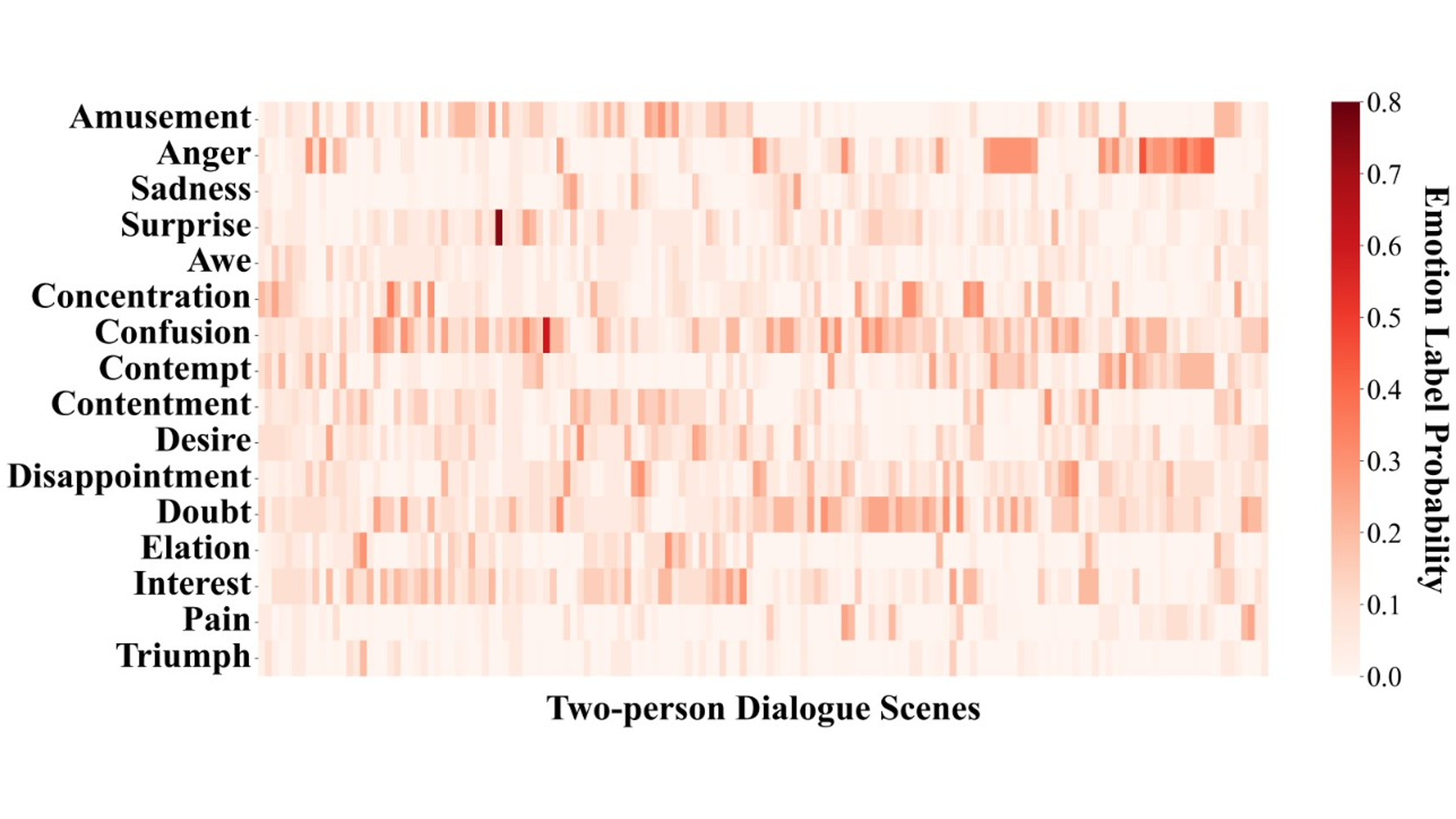
Figure S7. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-vision-text zero-shot emotion recognition.
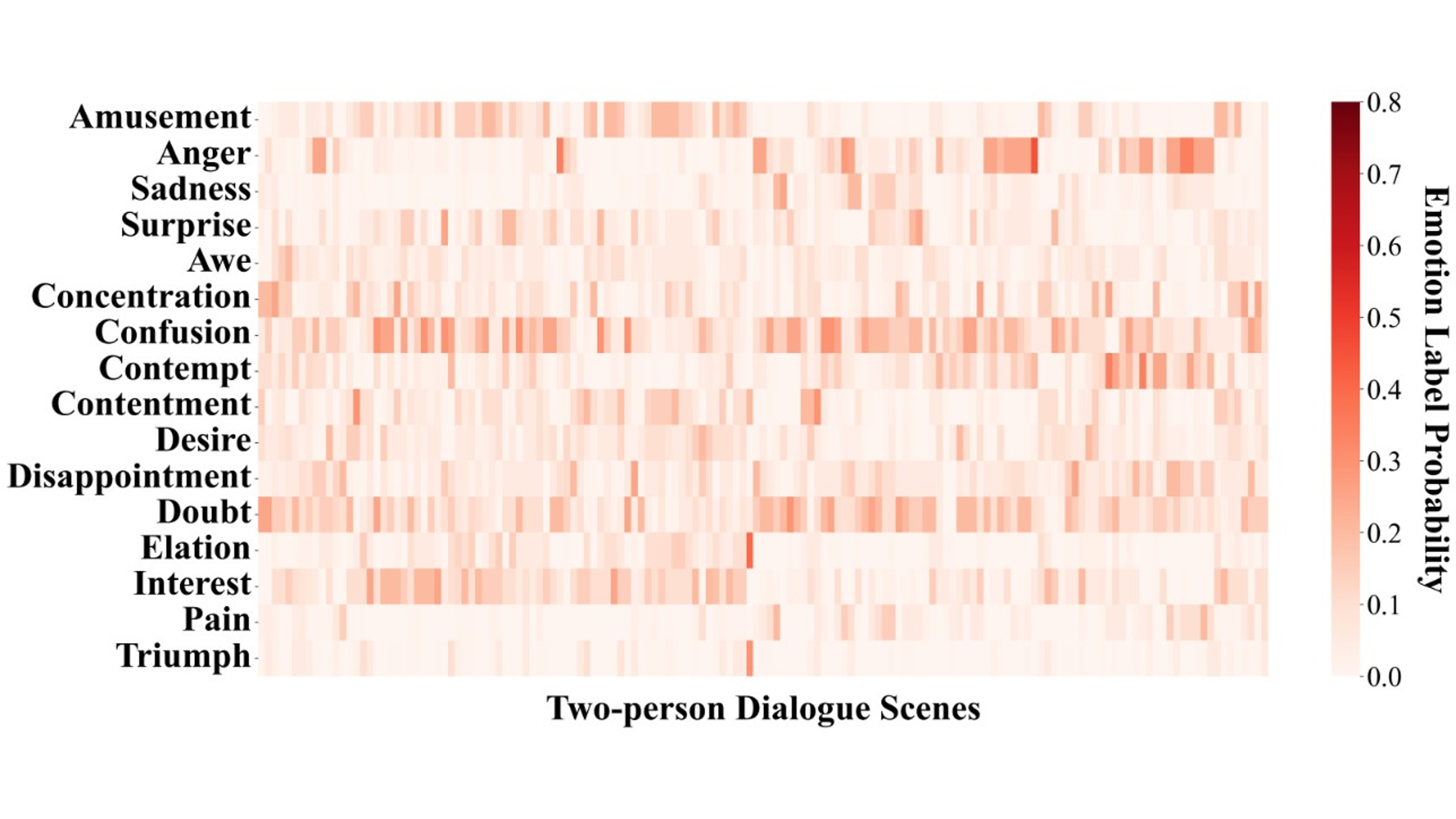
Figure S8. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-vision-text zero-shot emotion prediction.

Figure S9. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-vision zero-shot emotion recognition.
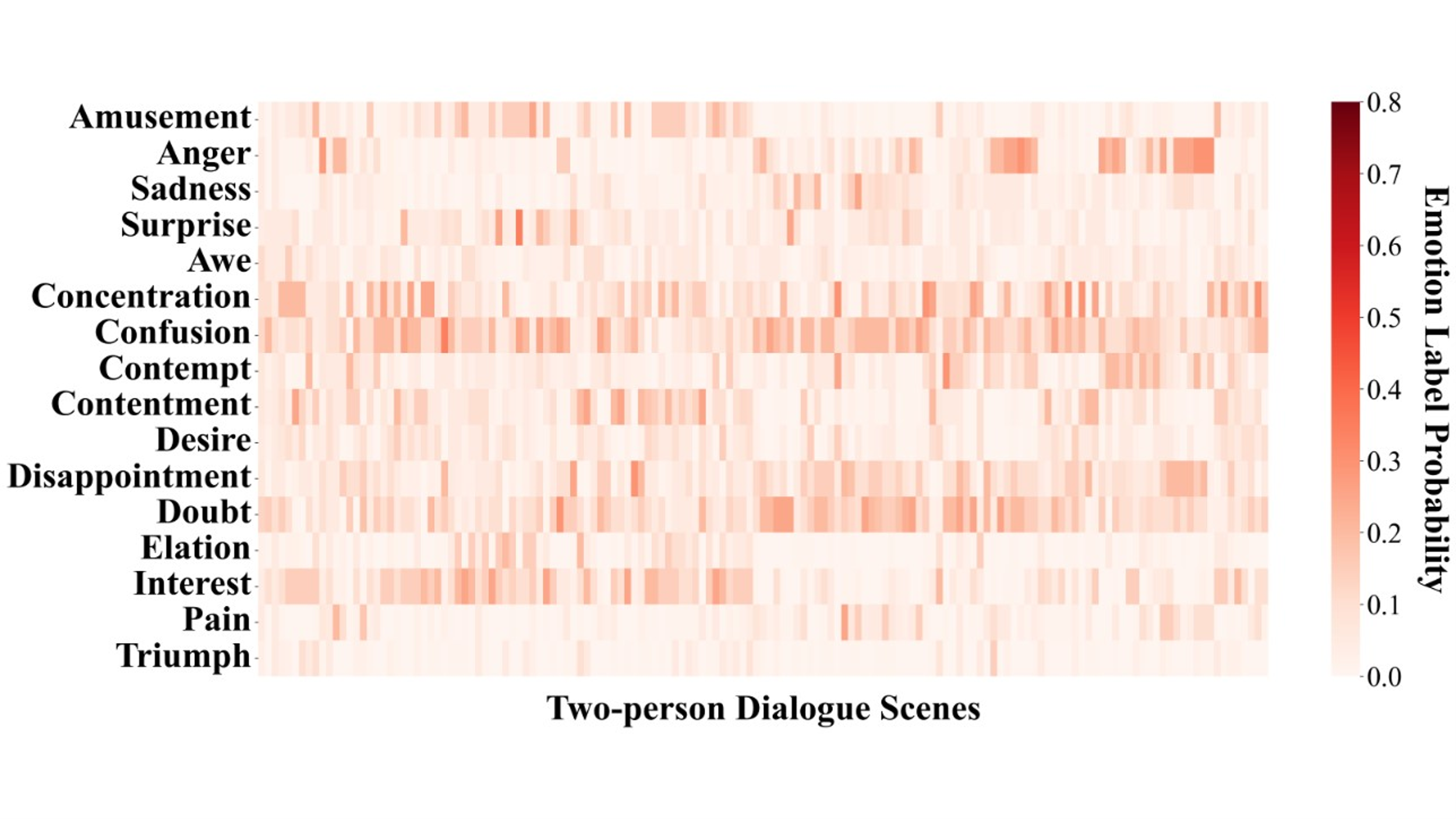
Figure S10. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-vision zero-shot emotion prediction.

Figure S11. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-turbo zero-shot emotion recognition.

Figure S12. Probability distribution matrix of emotion labels in two-person dialogue scenes for GPT-4-turbo zero-shot emotion prediction.
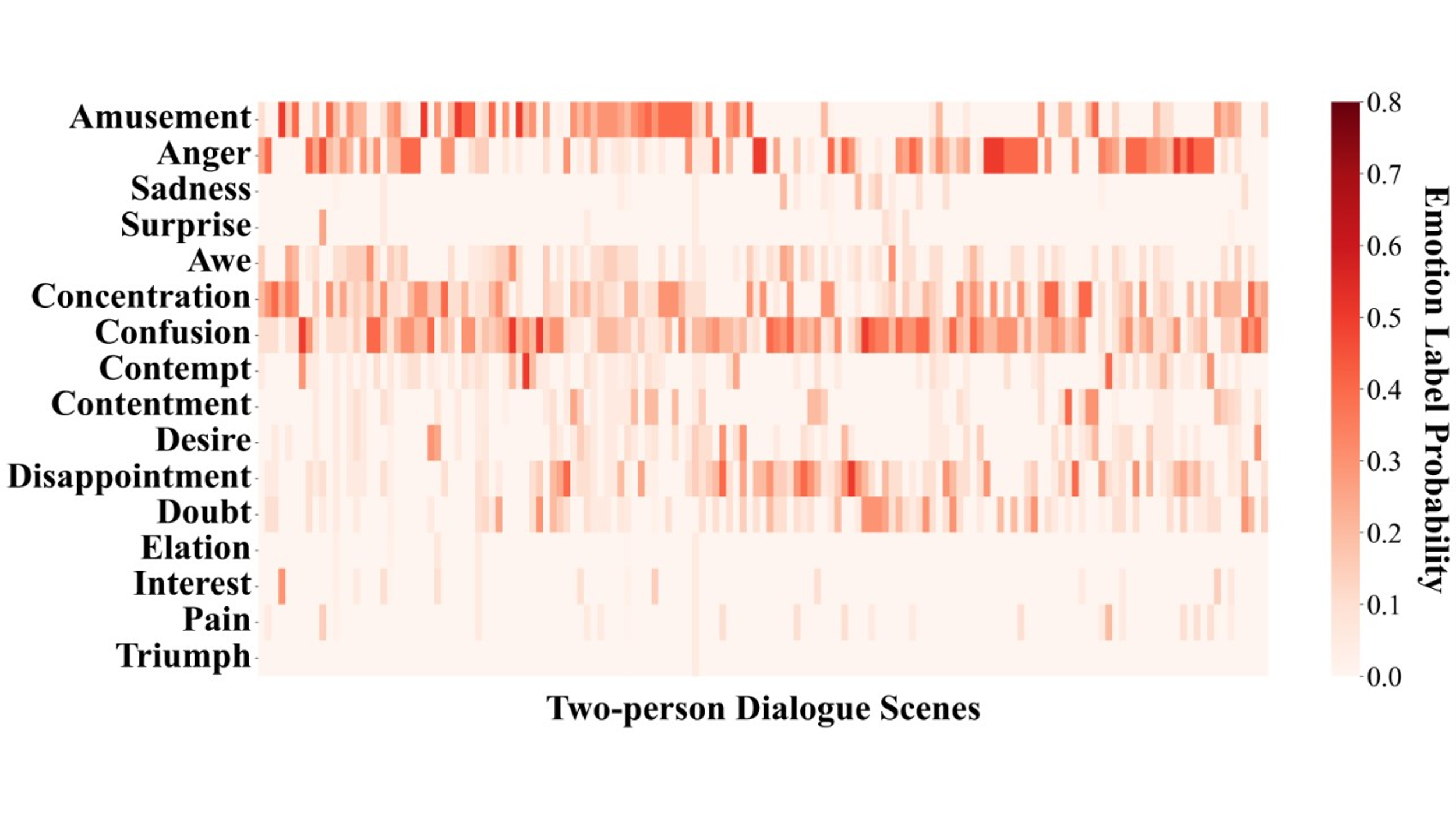
Figure S13. Probability distribution matrix of emotion labels in two-person dialogue scenes for Claude-3-haiku zero-shot emotion recognition.

Figure S14. Probability distribution matrix of emotion labels in two-person dialogue scenes for Claude-3-haiku zero-shot emotion prediction.
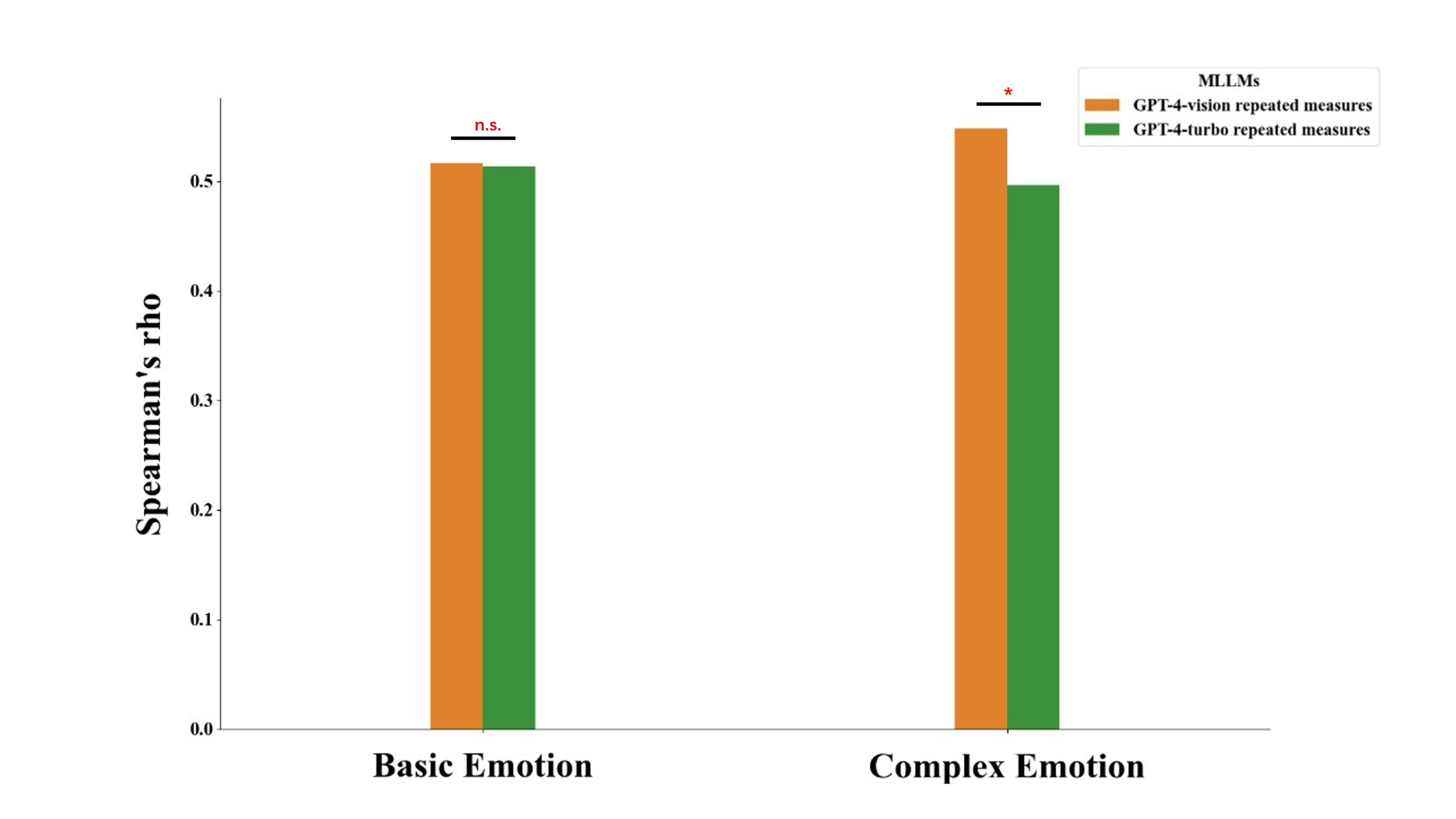
Figure S15. Spearman correlation analysis and comparison of multimodal large language models in repeated-measures emotion recognition.
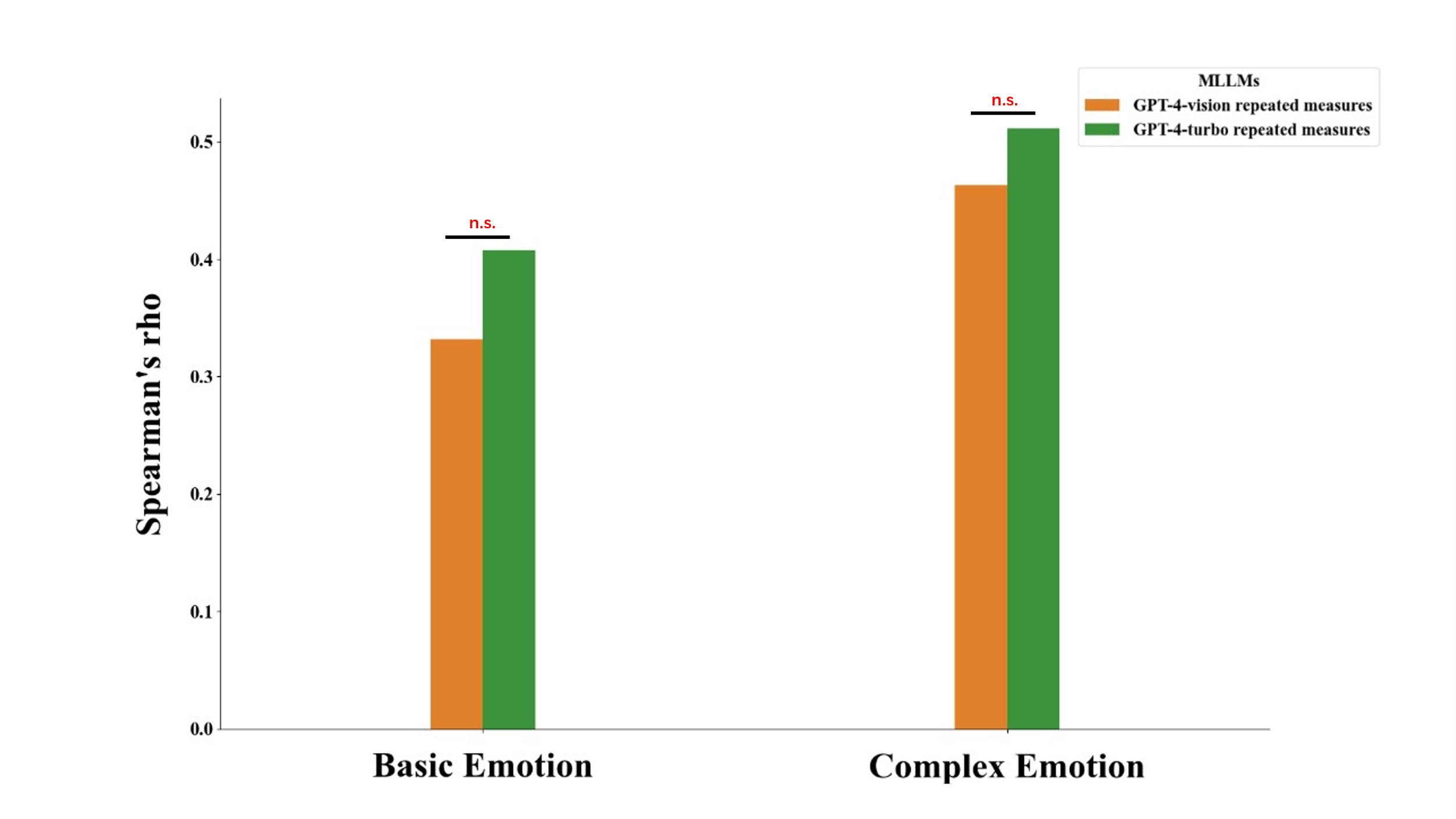
Figure S16. Spearman correlation analysis and comparison of multimodal large language models in repeated-measures emotion prediction.
| [1] |
Barrett, L. F. (2006). Are emotions natural kinds? Perspectives on Psychological Science, 1(1), 28-58.
doi: 10.1111/j.1745-6916.2006.00003.x pmid: 26151184 |
| [2] | Barrett, L. F., Mesquita, B., & Gendron, M. (2011). Context in emotion perception. Current Directions in Psychological Science, 20(5), 286-290. |
| [3] | Buck, R. (1985). Prime theory: An integrated view of motivation and emotion. Psychological Review, 92(3), 389-413. |
| [4] | Busso, C., Bulut, M., Lee, C. C., Kazemzadeh, A., Mower, E., Kim, S.,... Narayanan, S. S. (2008). IEMOCAP: Interactive emotional dyadic motion capture database. Language Resources and Evaluation, 42, 335-359. |
| [5] | Clark, H. H., & Schaefer, E. F. (1989). Contributing to discourse. Cognitive Science, 13(2), 259-294. |
| [6] |
Cordaro, D. T., Sun, R., Kamble, S., Hodder, N., Monroy, M., Cowen, A.,... Keltner, D. (2020). The recognition of 18 facial-bodily expressions across nine cultures. Emotion, 20(7), 1292-1300.
doi: 10.1037/emo0000576 pmid: 31180692 |
| [7] |
Cordaro, D. T., Sun, R., Keltner, D., Kamble, S., Huddar, N., & McNeil, G. (2018). Universals and cultural variations in 22 emotional expressions across five cultures. Emotion, 18(1), 75-93.
doi: 10.1037/emo0000302 pmid: 28604039 |
| [8] |
Cowen, A. S., & Keltner, D. (2020). What the face displays: Mapping 28 emotions conveyed by naturalistic expression. American Psychologist, 75(3), 349-364.
doi: 10.1037/amp0000488 pmid: 31204816 |
| [9] | Cowen, A. S., Keltner, D., Schroff, F., Jou, B., Adam, H., & Prasad, G. (2021). Sixteen facial expressions occur in similar contexts worldwide. Nature, 589(7841), 251-257. |
| [10] |
Cowen, A. S., Laukka, P., Elfenbein, H. A., Liu, R., & Keltner, D. (2019). The primacy of categories in the recognition of 12 emotions in speech prosody across two cultures. Nature Human Behaviour, 3(4), 369-382.
doi: 10.1038/s41562-019-0533-6 pmid: 30971794 |
| [11] | De Gelder, B., & Vroomen, J. (2000). The perception of emotions by ear and by eye. Cognition & Emotion, 14(3), 289-311. |
| [12] | Ekman, P. (1992). An argument for basic emotions. Cognition & Emotion, 6(3-4), 169-200. |
| [13] |
Ekman, P. (1993). Facial expression and emotion. American Psychologist, 48(4), 384-392.
pmid: 8512154 |
| [14] | Ekman, P., & Friesen, W. V. (1978). Facial Action Coding System (FACS) [Database record]. APA PsycTests. |
| [15] | Ekman, P., & Friesen, W. V. (2003). Unmasking the face: A guide to recognizing emotions from facial clues(Vol. 10). Ishk. |
| [16] | Fayek, H. M., Lech, M., & Cavedon, L. (2016). Modeling subjectiveness in emotion recognition with deep neural networks: Ensembles vs soft labels. In 2016 International Joint Conference on Neural Networks (IJCNN) (pp. 566-570). IEEE. |
| [17] | Ghosal, D., Majumder, N., Poria, S., Chhaya, N., & Gelbukh, A. (2019). Dialoguegcn: A graph convolutional neural network for emotion recognition in conversation. arXiv preprint arXiv:1908.11540. |
| [18] | Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press. |
| [19] | Gross, J. J. (2015). Emotion regulation: Current status and future prospects. Psychological Inquiry, 26(1), 1-26. |
| [20] | Kosti, R., Alvarez, J. M., Recasens, A., & Lapedriza, A. (2017). Emotion recognition in context. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1667-1675). IEEE. 1667-1675). IEEE. |
| [21] | Lazarus, R. S. (1991). Emotion and adaptation. Oxford University Press. |
| [22] | Li, S., & Deng, W. (2020). Deep facial expression recognition: A survey. IEEE Transactions on Affective Computing, 13(3), 1195-1215. |
| [23] |
Lindquist, K. A., Barrett, L. F., Bliss-Moreau, E., & Russell, J. A. (2006). Language and the perception of emotion. Emotion, 6(1), 125-138.
pmid: 16637756 |
| [24] |
Matsumoto, D., Yoo, S. H., & Nakagawa, S. (2008). Culture, emotion regulation, and adjustment. Journal of Personality and Social Psychology, 94(6), 925-937.
doi: 10.1037/0022-3514.94.6.925 pmid: 18505309 |
| [25] | McGurk, H., & MacDonald, J. (1976). Hearing lips and seeing voices. Nature, 264(5588), 746-748. |
| [26] | Mehrabian, A. (2017). Nonverbal communication. New York: Routledge. |
| [27] | Plutchik, R. (1980). A general psychoevolutionary theory of emotion. Theories of emotion, 3-33. |
| [28] | Pollmann, M. M., & Finkenauer, C. (2009). Empathic forecasting: How do we predict other people's feelings? Cognition and Emotion, 23(5), 978-1001. |
| [29] | Poria, S., Cambria, E., Bajpai, R., & Hussain, A. (2017). A review of affective computing: From unimodal analysis to multimodal fusion. Information Fusion, 37, 98-125. |
| [30] |
Russell, J. A. (2003). Core affect and the psychological construction of emotion. Psychological Review, 110(1), 145-172.
doi: 10.1037/0033-295x.110.1.145 pmid: 12529060 |
| [31] |
Schilbach, L., Timmermans, B., Reddy, V., Costall, A., Bente, G., Schlicht, T., & Vogeley, K. (2013). Toward a second-person neuroscience. Behavioral and Brain Sciences, 36(4), 393-414.
doi: 10.1017/S0140525X12000660 pmid: 23883742 |
| [32] | Sridhar, K., Lin, W. C., & Busso, C. (2021). Generative approach using soft-labels to learn uncertainty in predicting emotional attributes. In 2021 9th International Conference on Affective Computing and Intelligent Interaction (ACII) (pp. 1-8). IEEE. |
| [33] |
Strack, F., & Deutsch, R. (2004). Reflective and impulsive determinants of social behavior. Personality and Social Psychology Review, 8(3), 220-247.
doi: 10.1207/s15327957pspr0803_1 pmid: 15454347 |
| [34] | Su, P. H., Gasic, M., Mrksic, N., Rojas-Barahona, L., Ultes, S., Vandyke, D.,... Young, S.(2016). On-line active reward learning for policy optimisation in spoken dialogue systems. arXiv preprint arXiv:1605.07669. |
| [35] | Van Kleef, G. A., & Côté, S. (2022). The social effects of emotions. Annual Review of Psychology, 73, 629-658. |
| [36] | Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N.,... Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 6000-6010. |
| [37] | Vinciarelli, A., Pantic, M., & Bourlard, H. (2009). Social signal processing: Survey of an emerging domain. Image and Vision Computing, 27(12), 1743-1759. |
| [38] | Wang, W., Zheng, V. W., Yu, H., & Miao, C. (2019). A survey of zero-shot learning: Settings, methods, and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2), 1-37. |
| [39] | Zhang, D., Yu, Y., Dong, J., Li, C., Su, D., Chu, C., & Yu, D. (2024). Mm-llms: Recent advances in multimodal large language models. arXiv preprint arXiv:2401.13601. |
| [40] | Zhao, S., Yao, X., Yang, J., Jia, G., Ding, G., & Chua, T. S. (2021). Affective image content analysis: Two decades review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10), 6729-6751. |
| [1] | WANG Weihan, CAO Feizhen, YU Linwei, ZENG Ke, YANG Xinchao, XU Qiang. Influence of group information on facial expression recognition [J]. Acta Psychologica Sinica, 2024, 56(3): 268-280. |
| [2] | YAN Chi, GAO Yunfei, HU Saisai, SONG Fangxing, WANG Yonghui, ZHAO Jingjing. The impact and mechanism of gaze cues on object-based attention [J]. Acta Psychologica Sinica, 2022, 54(7): 748-760. |
| [3] | YANG Jimei, CHAI Jieyu, QIU Tianlong, QUAN Xiaoshan, ZHENG Maoping. Relationship between empathy and emotion recognition in Chinese national music: An event-related potential study evidence [J]. Acta Psychologica Sinica, 2022, 54(10): 1181-1192. |
| [4] | JIN Xinyi, ZHOU Bingxin, MENG Fei. Level 2 visual perspective-taking at age 3 and the corresponding effect of cooperation [J]. Acta Psychologica Sinica, 2019, 51(9): 1028-1039. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||