

1 前言
长久以来, 科学家们致力于自我面孔对自我认识特殊性的研究。无论是在人类还是黑猩猩身上, 都发现了较强的自我面孔识别能力, 自我面孔识别也被当作个体拥有自我意识的标志(Gallup, 1970; Parker, Mitchell & Boccia, 1994; Keenan, Mccutcheon, Freund, Gallup, & Pascual-Leone, 1999)。虽然自我面孔识别的研究历程悠久且方法较为成熟, 但是某些因疾病所导致的自我面孔识别能力受损仍旧是心理学研究的要点。例如, 在自闭症、阿兹海默症等神经或发育障碍的个体中, 自我面孔识别的损伤已被证实(Uddin et al., 2008; Adduri & Marotta, 2009)。不过, 精神分裂症作为一种病因较为复杂的精神类疾病, 在自我面孔识别的研究上仍存在争议。
精神分裂症患者在自我感知方面的缺陷已经被证实(Sass & Parnas, 2003; Moe & Docherty, 2014), 但是对患者是否拥有自我面孔识别能力的意见却不一致。有些研究发现, 精神分裂症在识别自我面孔方面存在一定的缺陷(Seiferth, Baar, & Schwabe, 2007; Hur, Kwon, Lee, & Park, 2014)。也有学者认为, 精神分裂症患者自我面孔识别的能力未受损, 并且相比于正常人, 加工过程反而增强了(Lee, Kwon, Shin, Lee, & Park, 2007)。近年对精神分裂症自我面孔研究的结果似乎更支持患者自我面孔识别出现障碍的原因并非是自我加工受损, 而是面孔的熟悉性加工出现问题(Zhang, Zhu, Xu, Jia, & Liu, 2012; Bortolon, Capdevielle, Salesse, & Stéphane, 2016; Catherine, Delphine, Salesse, & Raffard, 2016)。从现有研究来看, 精神分裂症的自我面孔研究大多集中在视觉通道的识别上, 即使方法各不相同, 但都并未脱离单通道研究的束缚。若能从其他较为成熟的研究领域出发(如多感觉整合), 采用多通道的研究手段, 或许能为精神分裂症自我面孔识别的研究带来新的证据。
多感觉整合理论(multisensory integration, MSI)提出, 相比于单通道, 多个通道同时呈现刺激时个体的反应更快更准确(Mishler & Neider, 2016)。但是在多个通道同时接受到刺激时, 会出现某个通道的主导效应, 促进或者抑制对另一个通道信息的反应(彭姓, 常若松, 任桂琴, 王爱君, 唐晓雨, 2018)。在视听整合中有视觉的主导效应(von Kriegstein et al., 2008), 例如McGurk效应, 表现为面孔和面部动作(如唇语)对声音识别的影响(McGurk & MacDonald, 1976)。这可能是由于听觉输入滞后于视觉输入(一般为150 ms)导致视觉内容对语音的可预测性(Arnal, Morillon, Kell, & Giraud, 2009)。Arnal等人(2009)认为视听整合是由两条不同的皮质通路完成的, 较快的直接皮质通路将视觉信息传递给听觉皮层, 较慢的反馈通路将视觉的预测信息与听觉输入之间的误差传递给听觉皮层, 这种视听不一致引起的神经失匹配经由颞上沟(superior temporal sulcus)反馈给听觉皮层, 当视听信息一致时, 视觉的预测性会促进语音的识别, 个体对信息的识别会加快, 当视听不一致时, 视听的误差会影响识别的速度。
精神分裂症患者的视听整合研究大多在于整合过程是否受损。有研究发现, 精神分裂症患者相比于正常人更少的产生McGurk错觉, 是由于交叉模态匹配的视听整合功能受损所致(Pearl et al., 2009; White et al., 2014), 但也有研究报告精神分裂症患者存在多感觉整合的现象, 并且视听整合功能并未受损(de Vroomen, Annen, Masthof, & Hodiamont, 2003; Martin, Giersch, Huron, & van Wassenhove, 2013)。功能磁共振成像(fMRI)显示, 视听整合过程主要涉及上丘(superior colliculi), 另外颞上沟皮层(cortex within the superior temporal sulcus)、顶内沟(intraparietal sulcus)和脑岛(insula)等脑区与这种交叉模态有关(Calvert, Hansen, Iversen, & Brammer, 2001)。有研究发现, 视觉通道的面孔加工区梭状面孔区(fusiform face area, FFA)和听觉通道声音敏感区(superior temporal sulcus, STS)有结构上的连接(Blank, Anwander, & Kriegstein, 2011), 这可能为单通道区之间的信息交流提供了桥梁(Maguinness & Kriegstein, 2017)。因此, 视听通道的身份识别可能直接通过这种连接共享信息, 并且gamma频段(30~50 Hz)神经震荡(neural oscillation)活动地同步可能是单通道区域相连的证据(Joassin, Maurage, & Campanella, 2011)。Stoned等人(Stoned, Coffman, Bustillo, Aine, & Stephen, 2014)通过脑磁图扫描(magnetoencephalography)发现, 在视听整合任务中, 精神分裂症患者gamma频段的震荡发生变化, 表明其在多感觉整合过程中发挥作用, 精神分裂症患者面孔和声音的视听整合过程可能直接通过FFA和STS的连接执行。
自我声音和自我面孔一样都包含自我身份信息, 这种自我感知与其它刺激相比是特殊的(Graux, Gomot, Roux, Bonnet-Brilhault, & Bruneau, 2015)。已有研究发现, 即使受到传导方式的影响, 个体依旧能够区分自我和陌生人的声音, 自我声音的检测与早期反应的一个成分(‘pre-MMN’, 即早期的失匹配负波, 表明了大脑对听觉信息的自动化检测, 是研究声音辨别力的指标)有关, 主要存在于左侧前额叶(Graux et al., 2013)。而性别信息作为一种固有的社会身份信息, 在面孔识别和声音识别上也被确认了认知过程的特殊性(Fellowes, Remez, & Rubin, 1997)。视听整合中, 正常人在视听性别信息不匹配的条件下(男性的面孔匹配女生的声音), 视觉的性别信息会影响被试对听觉信息的识别(PeynircioǧLu, Brent, Tatz, & Wyatt, 2017)。考察精神分裂患者在视听整合任务中自我面孔对声音识别影响的特点, 可能会为精神分裂症患者自我面孔识别的研究提供一些新的思路。
综上, 探索精神分裂症患者在视听整合中自我面孔的作用及其特点, 就成为一个重要的问题。本研究选取一批健康被试作为对照组, 采用自我面孔和他人面孔(同性和异性)同自我声音和他人声音(同性和异性)的匹配范式来进行研究, 提出的问题假设:精神分裂症患者能够在单通道任务中进行自我面孔和自我声音的识别, 并在视听整合任务中出现视觉通道的面孔主导效应, 该效应会影响到听觉通道的自我身份(自我声音)识别, 并对他人(同性和异性)声音的识别产生影响。
2 实验1:精神分裂症患者的面孔识别
2.1 实验目的
通过比较精神分裂症患者和健康被试在自我面孔、同性他人面孔和异性他人面孔识别任务中的差异, 分析精神分裂症患者面孔识别的能力。
2.2 实验方法
2.2.1 被试
选取甘肃省天水市第三人民医院34名(男17名)住院精神分裂症患者作为患者组。排除药物滥用、精神发育迟缓以及其他器质性疾病的患者。经由两名精神科主治医生诊断, 所有患者均符合DSM-5的诊断标准。其中3名患者为偏执型精神分裂症, 31名为未分化型。患者的平均病史为(3.50 ± 4.7)年。在实验阶段, 所有患者服用利哌酮、喹硫平、氯氮平等非典型抗精神病药物。招募了26名健康被试(男12名)作为健康组, 健康组的被试在年龄和受教育水平上与患者组匹配, 被试身体健康, 无精神病史及其他脑器质性损伤。采用G-power软件计算在效应量为0.4和统计检验力为0.8时所需要的被试总人数为25人, 实验达到了该水平。
所有被试均为右利手, 视力或矫正视力正常, 面部无明显疤痕及突出特征(例如胡须)。表1显示了具体的人口学变量信息。本研究得到西北师范大学和甘肃省天水市第三人民医院伦理委员会的批准。所有被试及其家属都同意参加实验, 并签署了书面的知情同意书。
表1 被试基本信息表(M ± SD)
| 变量 | 患者组(n = 34) | 健康组(n =26) |
|---|---|---|
| 年龄 | 33.50 ± 9.57 | 34.38 ± 11.8 |
| 受教育水平(年) | 10.76 ± 3.24 | 12.72 ± 4.51 |
| 性别(男/女) | 17/17 | 12/14 |
| SAPS | 34.97 ± 30.13 | |
| SANS | 35 ± 30.32 | |
| 药物剂量(氯丙嗪等效) | 335.35 ± 187.43 |
注:SAPS: 阳性症状量表; SANS: 阴性症状量表*。(* Crow和Andreason分别于1980年和1982年提出了Ⅰ型(阳性为主)和Ⅱ型(阴性为主)精神分裂症, 以及阳性(Scale for the Assessment of Positive Symptoms, SAPS)和阴性(Scale for the Assessment of Negative Symptoms, SANS)症状量表。经我国专家修正评定, 证明了其适用性。这两个量表也被广泛地应用于精神分裂症患者的症状评定。)
2.2.2 实验材料
利用Nikon-D7200单反相机以60帧/秒(1280×720像素分辨率)分别为每位被试进行视频拍摄, 要求被试目视镜头, 在听到研究人员说“开始”后, 被试在有嘴唇运动的条件下发“a”, 直到研究人员说“结束”后停止, 要求被试有完整的唇部发音过程, 该过程尽量保持在在1.5 s。
采用Adobe premiere视频处理软件将所有视频消音并处理为黑白色, 并对视频画面进行裁剪, 统一留出被试面孔的650×480像素。根据实验要求, 除了被试自己的面孔, 再为每位被试加入了3位陌生同性面孔和3位陌生异性面孔, 共7个面孔视频。
2.2.3 实验程序
视觉通道的自我身份识别通过对自我和他人的动态面孔进行识别, 自我面孔和他人面孔(同性和异性)分别都有30个试次(trial), 加上6个练习试次(trial), 共有96个试次, 练习结束后随机呈现。
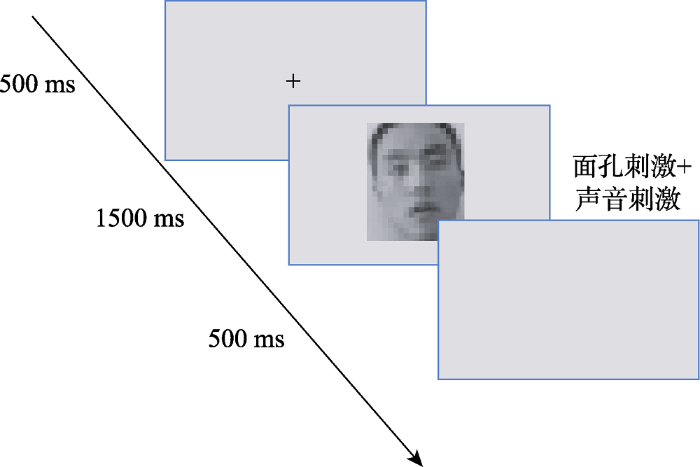
实验程序采用E-prime 2.0软件在15.6寸的电脑液晶屏上呈现所有的视频刺激, 像素为1600像素×900像素, 60 Hz刷新率。要求被试双眼始终注视屏幕中央, 眼睛离屏幕60 cm左右。每个试次开始时都是在屏幕中央呈现500 ms的黑色十字, 之后呈现1.5 s的无声动态面孔。刺激呈现后, 被试要对面孔进行识别, 如果是自己的面孔就按“F”键, 不是就按“J”键, 直到被试按键之后进入500 ms的空屏, 再到下一个试次, 按键之间进行了平衡, 实验流程见图1。
图1
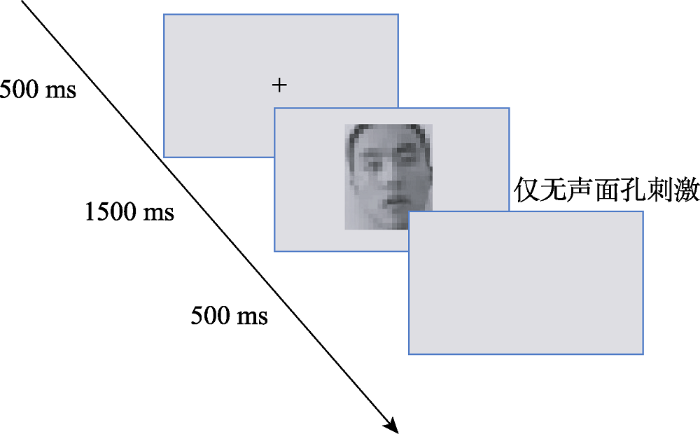
图1
实验1单一试次流程图
注:实验开始屏幕中央呈现字号为36磅的黑色十字, 500 ms之后出现无声的动态面孔刺激, 被试按键反应之后进入实验缓冲的空屏。
2.3 结果与分析
实验中练习试次被排除。对反应时的数据进行处理, 剔除了所有的错误试次。剔除了反应时超过3个标准差的反应试次(占总试次数的2.9%), 1名被试(该患者平均反应时超过3000 ms)数据被剔除。
采用信号检测理论中的辨别力(d¢ = Z击中 - Z虚报)指标来分析被试对自我面孔的辨别能力。
采用SPSS 23.0分别对被试的正确率和反应时进行了2 (被试类型:患者组, 健康组) × 3 (面孔身份:自我, 同性他人, 异性他人)的重复测量方差分析, 对被试自我面孔识别的辨别力d¢进行了独立样本t检验分析。
2.3.1 面孔识别的正确率
单通道面孔识别任务正确率的分析结果显示, 面孔识别的主效应不显著, F(2, 57) = 1.34, p = 0.27, 表明所有被试在面孔识别方面正确率没有显著差异; 组别的主效应不显著, F(1, 59) = 0.73, p = 0.40, 表明患者组和健康组被试面孔识别的正确率没有显著差异; 组别与面孔身份识别之间没有显著的交互作用, F(2, 57) = 0.94, p = 0.40, 具体见图2(a)。
图2
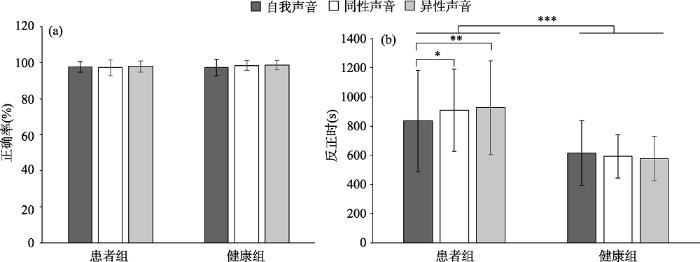
图2
不同类型被试单通道面孔识别任务结果
注:图(a)中正确率的结果为平均数, 竖线代表正确率的标准差;图(b)中反应时的结果为平均数, 竖线代表反应时的标准差。
*p < 0.05, **p < 0.01, ***p < 0.001。
2.3.2 面孔识别的反应时
单通道面孔识别任务反应时的分析结果为, 面孔身份识别的主效应不显著, F(2, 56) = 0.92, p = 0.40。组别的主效应显著, F(1, 57) = 21.78, p < 0.001, partial η2 = 0.28, 表现为健康组被试识别面孔的反应时(M =595.94, 95% CI [501.57, 690.30])总体低于患者组(M = 889.99, 95% CI [806.23, 973.75])。组别与面孔身份识别之间存在显著的交互作用, F(2, 56) = 4.80, p = 0.01, partial η2 = 0.15; 简单效应分析发现, 患者组的自我面孔识别的反应时(M = 834.47, 95% CI [730.37, 938.57])小于同性他人(M = 909.66, 95% CI [828.83, 990.49])和异性他人(M = 925.85, 95% CI [835.21, 1016.48]), 具体见图2(b)。
2.3.3 自我面孔识别的辨别力
自我面孔辨别力的分析结果为, 患者自我面孔识别的辨别力与健康被试无显著差异, t(58) = -0.71, p = 0.48。
2.4 讨论
从精神分裂症患者和健康被试的视觉面孔识别的结果发现, 患者能够和正常人一样辨别自己的面孔, 并且对自我面孔有更快的反应, 与之前的某些研究结果一致(Bortolon et al., 2016; Catherine et al., 2016; Bortolon et al., 2017), 验证了研究的假设, 精神分裂症患者有自我面孔识别的能力。但这并不能否定前人对精神分裂症患者自我面孔识别受损的说法, 由于对面孔识别的研究方法不同(有的研究采用morphing任务, 有的则采用视觉搜索范式), 所探究的角度不同, 结论大不相同。不过, 本研究可以说明, 至少在动态自我面孔识别的能力上, 精神分裂症患者与正常人一样。精神分裂症患者对面孔识别任务的反应时总体要大于正常被试, 这也存在于听觉任务和视听整合任务实验中。精神分裂症患者的反应变慢是一个病理上的普遍特征, 用精神分裂症患者和健康被试进行比较并不能只采用这个指标(Schatz, 1998)。
3 实验2:精神分裂症患者的声音识别
3.1 实验目的
通过比较精神分裂症患者和健康被试在自我声音、同性他人声音和异性他人声音识别任务中的差异, 分析精神分裂症患者声音识别的能力。
3.2 实验方法
3.2.1 被试
实验2被试来自实验1。
3.2.2 实验材料
被试声音的采集采用aigo-R8611录音笔, 采样频率为44.1 kHz, 音频信号为16-bit。要求被试在看到研究人员开始手势后面对录音笔用中性平缓的语调发“a”的音, 直到看到结束的手势后停止, 该过程尽量保持在在1.5 s以上。
采用Pro Tool软件将所有音频材料剪辑成1.5 s, 采用Praat软件将所有音频的响度标准化为70 dB, 除了被试自己的声音, 再为每位被试加入了3位陌生同性声音和3位陌生异性声音, 共7个音频。
3.2.3 实验程序
听觉通道的自我身份识别共有他人声音和自我声音。自我声音和他人声音(同性和异性)分别都有30个试次, 加上6个练习试次, 共有96个试次, 练习结束后随机呈现。
实验程序采用E-prime2.0软件在15.6寸的电脑液晶屏上呈现所有的音频刺激, 每个试次开始时都是在屏幕中央呈现500 ms的黑色十字, 之后耳机中播放1.5 s的声音刺激, 同时屏幕保持白色空屏, 要求被试眼睛不能离开电脑屏幕。刺激呈现后, 被试要对声音进行识别, 如果是自己的声音就按“F”键, 不是就按“J”键, 直到被试按键之后进入500 ms的空屏, 再到下一个试次, 按键之间进行了平衡, 实验流程见图3。
图3
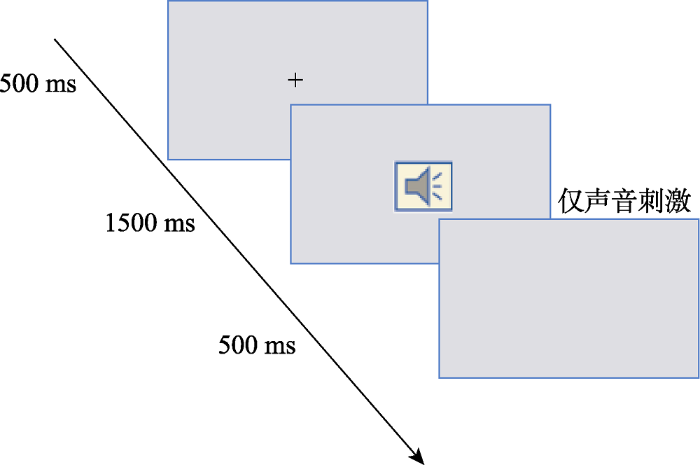
图3
实验2单一试次流程图
注:实验开始屏幕中央呈现字号为36磅的黑色十字, 500 ms之后出现空屏, 耳机中出现声音刺激, 要求被试注视屏幕, 被试按键反应之后进入实验缓冲的空屏。
3.3 结果与分析
研究中练习试次被排除。对反应时的数据进行处理, 剔除了所有的错误试次。剔除了反应时超过3个标准差的反应试次(占总试次数的1.8%), 1名被试(该患者平均反应时超过3000 ms)被剔除。
采用信号检测理论中的辨别力(d¢ = Z击中 - Z虚报)指标来分析被试对自我声音的辨别能力。
对被试的正确率和反应时进行了2 (组别:患者组, 健康组) × 3 (声音身份:自我, 同性他人, 异性他人)的重复测量方差分析, 对被试自我声音识别的辨别力d¢进行了独立样本t检验的分析。
3.3.1 声音识别的正确率
单通道听觉识别任务正确率的分析结果显示, 声音身份识别的主效应显著, F(2, 57) = 23.71, p < 0.001, partial η2 = 0.45, 所有被试对异性声音识别(M = 0.97, 95% CI [0.95, 0.99])的正确率显著高于自我(M = 0.89, 95% CI [0.86, 0.93])和同性的他人声音(M = 0.85, 95% CI [0.80, 0.90]); 自我声音和同性声音识别之间没有显著差异。组别的主效应不显著, F(1, 58) = 0.66, p = 0.42。组别与声音身份识别之间没有显著的交互作用, F(2, 57) = 2.86, p = 0.07, 具体见图4(a)。
图4
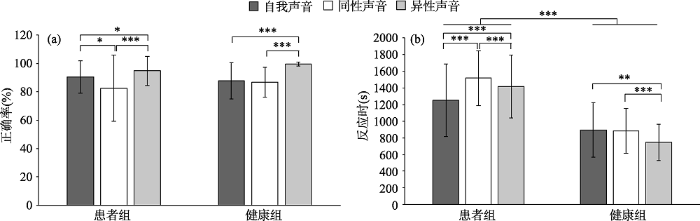
图4
不同类型被试单通道声音识别任务的结果
注:图(a)中正确率的结果为平均数, 竖线代表正确率的标准差; 图(b)中反应时的结果为平均数, 竖线代表反应时的标准差, *p < 0.05, **p < 0.01, ***p < 0.001。
3.3.2 声音识别的反应时
单通道听觉识别任务反应时的分析结果显示, 声音身份识别的主效应显著(F(2, 56) = 20.95, p < 0.001, partial η2 = 0.43), 具体为被试对自我声音识别的反应时(M = 1071.93, 95% CI [969.27, 1174.58])和异性他人声音识别的反应时(M = 1080.06, 95% CI [996.23, 1163.89])显著低于对同性他人声音识别的反应时(M = 1198.53, 95% CI [1119.04, 1278.01]), 自我声音识别的反应时与异性他人声音无显著差异; 组别的主效应显著(F(1, 57) = 43.54, p < 0.001, partial η2 = 0.43), 患者组对声音身份识别的反应时(M = 1393.64, 95% CI [1282.12, 1505.16])显著高于健康组(M = 840.03, 95% CI [714.39, 965.67]); 组别与声音身份识别之间存在显著的交互作用(F(2, 56) =15.13 p < 0.001, partial η2 = 0.35), 简单效应分析发现, 患者组的自我声音识别的反应时(M = 1250.42, 95% CI [1114.13, 1386.72])小于同性他人(M = 1515.55, 95% CI [1410.23, 1621.08])和异性他人(M = 1414.94, 95% CI [1303.65, 1526.24]), 健康组对异性他人声音识别的反应时(M = 745.17, 95% CI [619.78, 870.55])小于自我声音(M = 893.42, 95% CI [739.88, 1046.97])和同性他人声音(M = 881.50, 95% CI [762.61, 1000.39]), 具体见图4(b)。
3.3.3 自我声音识别的辨别力
自我声音辨别力的分析结果为, 患者自我声音识别的辨别力与健康被试无显著差异, t(58) = 0.5, p = 0.62。
3.4 讨论
听觉通道的声音识别任务的结果表明, 精神分裂症患者自我声音的识别能力与健康被试没有区别, 这与之前的自我和他人声音识别的研究结果一致(Mingdi, Fumitaka, Ryu-Ichiro, & Hiroko, 2013; Conde, Gonçalves, Óscar, & Pinheiro, 2018), 且患者在反应时结果上表现出对自我声音有更快的反应。已有的研究表明, 声音的音色就能反映个人的性别身份, 而不需要依赖音高或语义(Fellowes et al., 1997), 符合被试对异性声音的识别好且快于同性声音, 并且从结果看出, 所有被试都在异性他人声音识别上有较好的表现, 说明精神分裂症患者具有分辨异性声音的能力。患者声音身份识别的反应时均差于健康组, 这支持了以往对精神分裂症患者自我-他人声音加工异常的研究(Anouk, Prikken, & van Haren, 2015)。结合正确率、反应时和辨别力的结果, 认为精神分裂症患者在单通道听觉任务中具有自我声音识别的能力, 并且能够区分自我声音和异性声音。而健康被试的自我声音和同性声音识别的反应时慢于异性声音识别的反应时可能是受到速度—准确性权衡的影响。
4 实验3:视听条件下的面孔对声音识别的影响
从单通道的视觉和听觉的自我识别任务结果可以看出, 精神分裂症患者在单通道听觉和视觉的自我身份识别上与健康被试无异。那么在双通道的视听任务中, 精神分裂症自我面孔是否会影响到听觉通道这一结果, 可进一步验证精神分裂症患者有自我面孔识别能力的假设。
4.1 实验目的
在视听整合任务中, 通过比较精神分裂症患者和健康被试在不同面孔条件下对自我声音、同性他人声音和异性他人声音识别任务中的差异, 分析精神分裂症患者自我面孔对声音识别的影响, 以证明患者自我面孔识别的能力。
4.2 实验方法
4.2.1 被试
实验3被试来自实验1。
4.2.2 实验材料
用Adobe premiere 视频处理软件将实验1的视频材料匹配上实验2的音频材料。在自我面孔、同性面孔(2位)和异性面孔(2位)条件下, 分别匹配了2位陌生同性声音和2位陌生异性声音和自我声音, 每位被试共17个视频。
4.2.3 实验程序
视听条件下声音识别共有9种条件, 分别为自我面孔下的自我声音、同性他人声音和异性他人声音, 同性面孔下的自我声音、同性他人声音和异性他人声音, 异性面孔下的自我声音、同性他人声音和异性他人声音, 每种条件为20个试次, 加上6个练习试次, 共有186个试次, 练习结束后随机呈现。
实验过程同实验1和实验2, 被试需要在看到视频刺激之后判断耳机中听到声音身份, 实验流程图见图5。
图5
4.3 结果与分析
研究中练习实验试次被排除。剔除了反应时超过3个标准差的反应试次(占总试次数的1.06%), 5名被试(3名患者正确率低于50%, 1名患者的反应时超过3000 ms, 1名健康被试正确率低于50%)的数据被剔除。
采用信号检测理论中的辨别力(d¢ = Z击中 - Z虚报)指标来分析被试对不同面孔下自我声音的辨别能力。
对被试的正确率和反应时进行了2 (组别:患者组, 健康组) × 3 (面孔身份:自我, 同性他人, 异性他人) × 3(声音身份:自我, 同性他人, 异性他人)的重复测量方差分析。
对不同面孔下被试自我声音的辨别力进行了2 (组别:患者组, 健康组) × 3 (面孔身份:自我, 同性他人, 异性他人)的重复测量方差分析。
为验证自我面孔对精神分裂症患者自我声音识别的促进和对他人声音的识别的抑制作用, 进一步对实验2和实验3的统计结果进行跨实验的比较, 由于实验3为双通道任务, 其反应时和单通道实验结果相比意义不大, 因此跨实验的比较只对自我面孔条件下2 (组别:患者组, 健康组) × 2 (通道:听觉通道, 视听双通道) × 3(声音身份:自我, 同性他人, 异性他人)正确率进行重复测量方差分析。
4.3.1 视听整合任务中声音识别的正确率
视听整合任务正确率分析结果显示, 声音身份识别的主效应显著(F(2, 57) = 22.74, p < 0.001, partial η2 = 0.44), 被试对自我声音识别的正确率(M = 0.8, 95% CI [0.75, 0.85])低于同性他人(M = 0.89, 95% CI [0.85, 0.92])和异性他人(M = 0.95, 95% CI [0.93, 0.98]); 组别的主效应显著(F(1, 58) = 5.42, p = 0.023, partial η2 = 0.09), 患者组对声音身份识别的正确率(M = 0.85, 95% CI [0.81, 0.89])低于健康组(M = 0.92, 95% CI [0.87, 0.96]); 不同面孔条件下声音识别的主效应不显著, F(2, 57) = 2.29, p = 0.11。组别与面孔之间无显著的交互作用, F(2, 57) = 0.92, p = 0.40。组别与声音身份识别之间无显著的交互作用, F(2, 57) = 1.51, p = 0.23。面孔身份与声音身份识别之间存在显著的交互作用(F(4, 55) = 8.15, p < 0.001, partial η2 = 0.37), 被试在自我面孔条件下自我声音(M = 0.94, 95% CI [0.92, 0.96])和异性声音识别的正确率(M = 0.84, 95% CI [0.89, 0.99])高于同性声音识别的正确率(M = 0.78, 95% CI [0.70, 0.87]), 同性他人面孔条件下同性声音(M = 0.96, 95% CI [0.91, 0.98])和异性声音识别的正确率(M = 0.96, 95% CI [0.93, 0.99])高于自我声音识别的正确率(M = 0.68, 95% CI [0.60, 0.76]), 异性他人面孔条件下同性声音(M = 0.94, 95% CI [0.91, 0.98])和异性声音识别的正确率(M = 0.97, 95% CI [0.95, 0.98])高于自我声音识别的正确率(M = 0.78, 95% CI [0.70, 0.85]), 组别、面孔身份和声音身份之间的交互作用边缘显著(F(4, 55) = 2.51, p = 0.052, partial η2 = 0.15), 具体见图6。
图6
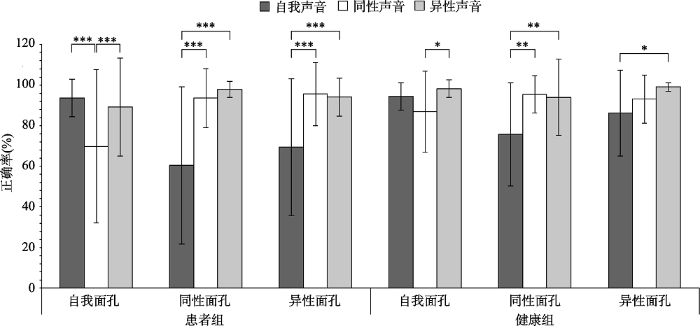
图6
不同面孔条件下声音识别任务的正确率
注:图中正确率的结果为平均数, 竖线代表正确率的标准差, *p < 0.05, **p < 0.01, ***p < 0.001。
4.3.2 视听整合任务中声音识别的反应时
视听整合任务反应时分析结果显示, 声音身份识别反应时的主效应显著(F(2, 52) = 22.49, p < 0.001, partial η2 = 0.46), 被试对自我声音识别的反应时(M = 1020.92, 95% CI [928.13, 1113.63])低于同性他人(M = 1088.70, 95% CI [1007.58, 1169.82]), 对异性他人声音识别的反应时(M = 926.88, 95% CI [895.81, 1029.95])低于自我声音; 组别的主效应显著(F(1, 53) = 36.94, p < 0.001, partial η2 = 0.41), 患者组对声音身份识别的反应时(M =1254.22, 95%CI [1151.85, 1356.59])大于健康组(M = 794.11, 95% CI [681.97, 906.26]); 不同面孔条件下声音识别的主效应不显著, F(2, 57) = 2.67, p = 0.078。组别与不同面孔条件下的声音识别之间无显著的交互作用(F(2, 52) = 2.13, p = 0.12), 组别与声音身份识别之间有显著的交互作用(F(2, 52) = 4.20, p = 0.02, partial η2 = 0.14), 进一步分析得出, 患者在对同性声音识别的反应时(M =1313.18, 95% CI [1203.80, 1422.56])大于自我声音(M = 1219.28, 95% CI [1094.29, 1344.27])和异性声音(M = 1230.20, 95% CI [1139.77, 1320.63]); 面孔身份与声音身份识别之间存在显著的交互作用(F(4, 50) = 7.61, p < 0.001, partial η2 = 0.38), 被试在同性他人面孔条件下对异性声音识别的反应时(M = 975.41, 95% CI [902.40, 1048.41)小于自我声音(M = 1096.64, 95% CI [990.8, 1203.21])和同性声音(M = 1077.12, 95% CI [991.28, 1162.95]), 异性他人面孔条件下同性声音识别的反应时(M = 1128.27, 95% CI [1058.20, 1198.35])大于自我声音(M = 987.56, 95% CI [901.18, 1073.96])和异性声音识别的反应时(M = 911.92, 95% CI [833.21, 0.63]), 组别、面孔身份和声音身份之间没有显著的交互作用, F(4, 50) = 0.95, p = 0.44, 具体见图7。
图7

图7
不同面孔条件下声音识别任务的反应时
注:图中反应时的结果为平均数, 竖线代表反应时的标准差, *p < 0.05, **p < 0.01, ***p < 0.001。
4.3.3 视听整合任务中声音识别的辨别力
不同面孔条件下自我声音辨别力的结果显示, 不同面孔条件下自我声音的辨别力有显著的主效应(F(2, 57) = 8.70, p = 0.001, partial η2 = 0.23), 自我面孔(M = 3.13, 95% CI [2.81, 3.45])和异性面孔条件下自我声音的辨别力(M = 2.96, 95% CI [2.60, 3.32])好于同性面孔条件下(M = 2.52, 95% CI [2.15, 2.90]); 组别的主效应显著(F(1, 58) = 5.43, p = 0.023, partial η2 = 0.09), 健康组对自我声音的辨别力(M = 3.22, 95% CI [2.77, 3.66])好于患者组(M = 2.53, 95% CI [2.13, 2.90]); 组别和面孔身份之间没有显著的交互作用, F(2, 57) = 0.13, p = 0.87。
4.3.4 听觉和视听整合的比较
跨实验正确率比较的结果显示, 自我面孔条件下, 声音识别有显著的主效应(F(2, 57) = 15.53, p < 0.001, partial η2 = 0.35), 被试对自我声音识别(M = 0.92, 95% CI [0.89, 0.94])的正确率高于同性他人声音(M = 0.82, 95% CI [0.76, 0.87]), 但低于异性他人声音(M = 0.96, 95% CI [0.93, 0.99]); 不同通道声音识别无显著的主效应, F(1, 58) = 1.19, p = 0.28; 组别无显著主效应, F(1, 58) = 1.19, p = 0.28; 组别和面孔身份之间无显著的交互作用, F(1, 58) = 3.62, p = 0.62。声音身份和组别之间有显著的交互作用(F(2, 57) = 4.06, p = 0.02, partial η2 = 0.13), 进一步分析得出患者对自我声音(M = 0.92, 95% CI [0.89, 0.95])和异性声音(M = 0.92, 95% CI [0.88, 0.96])识别的正确率高于同性声音(M = 0.76, 95% CI [0.69, 0.84]); 通道和声音身份之间有显著的交互作用(F(2, 57) = 4.35, p = 0.02, partial η2 = 0.13), 进一步分析得出视听条件下的自我声音识别正确率(M = 0.94, 95% CI [0.92, 0.96])要高于听觉单通道下的自我声音识别(M = 0.89, 95% CI [0.86, 0.93]), 组别、通道和声音身份之间没有显著的交互作用, F(2, 57) = 0.86 p = 0.43, 具体见图8。
图8
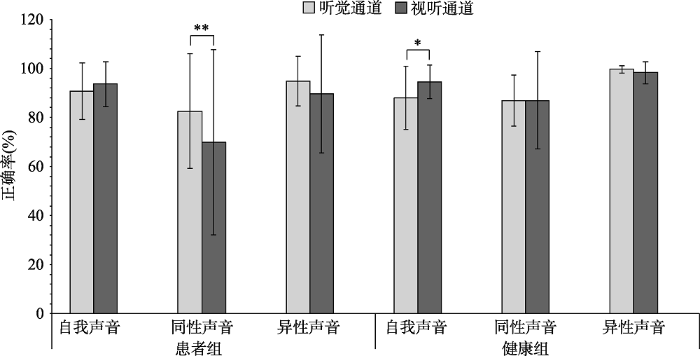
图8
单通道和双通道(自我面孔)条件下声音识别任务的正确率
注:图中正确率的结果为平均数, 竖线代表正确率的标准差, *p < 0.05, **p < 0.01, ***p < 0.001。
4.3 讨论
视听整合任务中, 被试在三种面孔条件下进行了声音识别任务, 自我面孔条件下, 患者在同性他人声音识别准确度上明显差于自我声音识别和异性他人声音识别, 自我声音和异性声音之间没有差别, 但在单通道听觉识别任务中, 患者对异性声音识别的能力好于对自我声音识别, 结合跨实验的比较结果可以看出, 精神分裂症患者在自我面孔条件下对自我声音识别有一定的提升, 而对于同性他人和异性他人的声音识别都变差了, 可能是患者在视听整合中视觉通道的自我面孔影响了听觉身份识别, 健康组被试在自我面孔条件下相比于单通道自我声音识别能力提升, 这与之前的研究结果一致(Candini et al., 2014), 自我面孔促进了自我声音的识别。在同性面孔和异性面孔条件下所有被试的自我声音识别都受到了影响, 并且对异性声音的识别和同性声音识别之间没有了差异, 这证明了视听整合中面孔对声音识别的影响(PeynircioǧLu et al., 2017), 这一点从自我声音辨别力上也可看出, 面孔的确会影响自我声音的辨别。在异性面孔条件下, 精神分裂症患者自我声音识别的能力差于健康被试, 这可能是患者受到异性面孔的干扰, 错误的拒绝了自我声音。
5 总讨论
自我面孔是自我意识最独特的标志。通过对精神分裂症患者自我面孔识别的研究, 能够帮助人们更好地了解该疾病所导致患者自我意识的变化。本研究通过对精神分裂症患者在不同通道下自我身份识别能力地探索, 共采用了单通道面孔识别任务、单通道声音识别任务和不同面孔(自我、同性他人和异性他人)条件下声音识别视听整合任务验证精神分裂症有自我面孔识别的能力。实验1探究精神分裂症患者在动态面孔识别任务中自我面孔识别能力与健康被试的差异; 实验2探究精神分裂症患者在声音识别任务中自我声音识别能力与健康被试的差异; 实验3在发现精神分裂症患者有自我面孔识别能力的基础上, 进一步通过自我面孔、同性他人面孔和异性他人面孔条件下进行声音识别的视听整合任务来证明精神分裂症患者自我面孔的识别能力。结果发现, 精神分裂症患者在视觉动态自我面孔识别的能力上与健康被试没有区别, 在单通道声音识别中表现出对自我声音和异性声音的加工优势, 在视听整合声音识别任务中受到面孔的影响, 自我面孔促进自我声音的识别, 抑制同性声音和异性声音的识别。他人面孔(同性+异性)抑制自我声音的识别。
5.1 精神分裂症的自我面孔识别特点
精神分裂症自我面孔识别研究是对患者自我意识研究的重要组成。本研究发现了精神分裂症自我面孔识别的能力与正常人一致, 支持了精神分裂症患者能进行自我面孔识别的研究结果(Bortolon et al., 2016; Catherine et al., 2016)。Catherine (2016)等人对精神分裂症患者面孔识别的过程进行了眼动追踪, 精神分裂症患者在对自我面孔加工过程中注视时间相对正常被试更长, 但是面部检测的模式与正常人没有区别, 证明了精神分裂症患者有自我面孔识别的能力。尽管之前的一部分研究认为精神分裂症患者可能会在识别自我和他人面孔时存在一定的困难, 但是最近的研究将这种面孔识别的困难解释为认知缺陷, 可能是精神分裂症患者的注意力和处理速度的缺陷而导致面孔识别异常(Hayley, Peterman, Sohee, Suresh, & Olivia, 2013; Bortolon et al., 2015)。精神分裂症患者在进行面孔识别的过程中, 除了本身疾病导致的反应速度变慢以外, Bortolon等人(2015)认为患者面孔识别过程的时间较长可能是因为他们需要以此来对面部的细节进行加工, 从而形成准确的判断。
本研究的自我面孔识别任务还发现了精神分裂症患者在识别自我面孔的反应时间要快于同性他人和异性他人面孔。而以往的研究发现精神分裂症患者识别性别面孔的能力和正常人没有区别(Delerue, Vincent, Verfaillie, & Boucart, 2010), 那么, 在精神分裂症患者能够识别性别面孔的能力正常的基础上, 对自我面孔加工的结果证明了精神分裂症患者的自我面孔的加工优势。
总的来看, 在视觉通道的动态面孔识别条件下, 精神分裂症患者能够区别自我面孔和他人面孔, 并且和正常人一样, 对自我面孔有更快地反应。这种动态面孔似乎能从基础上了解患者面孔识别的特点, 更具有生态效度, 也为精神分裂症患者具有自我意识提供了一个方面的证据。
5.2 精神分裂症的自我声音识别特点
声音识别的研究一直以来都是一项较为复杂的工作, 这是由于声音的传导分为骨传导和空气传导, 传导方式的多样使得个体发出的声音和听到自己的录音有一定的差异, 这也是很多人觉得录制自己的声音不像自己的原因(Maurer & Landis, 1990)。而精神分裂症患者声音识别的难度除了传导方式导致的识别的困难外还有患者本身可能出现的较为常见的病理特征——幻听的影响。实验2的研究发现精神分裂症患者同正常人一样, 能够区别自我声音和异性声音, 这与之前的某些研究结果不同(Stephane, Kuskowski, McClannahan, Surerus, & Nelson, 2010; Pinheiro, Rezaii, Rauber, & Niznikiewicz, 2016), 可能的原因是这些研究是在有幻听症状的精神分裂症患者和健康被试的比较中发现了自我-他人声音加工异常, 并且有研究还在中性声音的基础上加入了情绪性的声音或是情绪性的语义。Pinheiro等人(2017)所研究的语义效价对精神分裂症患者辨别自我-他人声音影响的结果发现, 虽然精神分裂症患者在对自我和非我声音处理的ERP结果上有差异, 患者在辨别消极词汇的自我或非我声音上对显著(情绪或自我相关)刺激增强的LPP (late positive potential)的振幅都要小于健康被试, 但是患者对无论是自我还是非我声音识别的准确性上同健康被试一样高, 都达到了90%以上。本研究选取的被试是在住院治疗后较为稳定的精神分裂症患者, 幻听经历患者的症状有所减缓。不过, 患者识别自我声音的能力虽然同健康被试没有区别, 但是辨别的时间仍旧要长于健康被试, 并且患者拒绝同性他人声音的能力较差, 这很可能受到之前幻听经验的影响。
此外, 精神分裂症患者对于异性声音识别的准确率和反应结果验证了患者对声音生物属性的识别同健康被试无异。患者分辨异性声音的正确程度甚至高出自我声音, 正如前言中所提到的性别作为社会身份信息, 患者能够又快又好的分辨, 也许能够证明精神分裂症患者在性别识别方面的社会功能并未受到疾病的影响。
本研究中, 对声音材料的选取只是简单的一个单音节字母, 这是考虑到有些患者只会方言而无法用普通话表达语音材料。根据Conde (2018)等人研究, 当声音是单词而不是简单的发音时, 被试能更好的区别自我声音, 精神分裂症患者是否会在文本声音材料中表现更好, 还需进一步的验证。
5.3 精神分裂症面孔识别对声音识别的影响
精神分裂症患者的某些症状被认为与声音处理的异常有关(Woodruff et al., 1997), 但有对视听整合的fMRI研究发现被试即使在面对不发声而只有唇动的情况下, 大脑中处理听觉性言语的颞上回仍旧被激活(MacSweeney et al., 2000), 证实了视觉信息对于听觉认知的影响, 并且在对精神分裂症患者视听整合的研究中也发现, 患者对模糊视觉的辨别也是通过激活多感官结构来实现的(Surguladze et al., 2001)。本研究对精神分裂症患者不同面孔条件下声音识别的探索发现, 自我面孔条件下患者对同性他人声音辨别的能力相比于健康被试较差, 与单通道声音识别任务比较, 患者在自我面孔下对自我声音识别的准确程度有所提高, 对同性他人声音识别的准确性有明显的降低, 对异性声音识别的能力也有降低, 虽然对于自我声音识别准确性的提高并不明显, 但这有可能是在单通道声音识别任务中患者自我声音识别的能力已经同健康被试没有差异且略高于健康被试, 不过患者在自我面孔条件下对自我声音识别的速度仍旧快于对异性声音的识别。异性声音和同性声音识别的速度没有差异, 而单通道声音识别条件下异性声音识别的速度快于同性声音识别, 表明异性声音识别可能也受到了面孔的影响。精神分裂症患者在视听任务中自我面孔促进了其自我声音的识别, 影响了他人声音(同性+异性)的识别, 可能从另一方面佐证了精神分裂症患者自我面孔识别能力的完好。
当面孔的条件变为同性面孔和异性面孔时, 可以看出患者对自我声音识别的能力差于健康被试, 虽然健康被试在对自我声音进行辨别的时候反应的时间增加了, 但是他们仍旧能够做出正确的选择, 精神分裂症患者却无法做到, 他们看见屏幕中的面孔为他人时, 即使耳机中播放了自己的声音, 他们也会选择这不是自己的声音。精神分裂症患者这种表现的原因除了其视听整合可能的缺陷之外, 还有可能是精神分裂症患者基于贝叶斯的推理过程出现问题所致, Jardri和Denève (2013)提出精神分裂症患者的分层神经网络中兴奋与抑制之间的失衡会导致一种病理性因果推断, 称为循环信念传播(circular belief propagation), 患者自上而下和自下而上的信息被不断地回弹, 会产生之前的信念被误认作直接的感官输入。因此, 精神分裂症患者可能会在视听任务中根据所看到的面孔信息预测听觉信息, 将这种预测作为自己真实听到的声音身份, 当对这种自上而下的信息选择过度自信时, 患者看到他人面孔刺激, 会十分肯定听到的声音不属于自己。精神分裂症患者很难根据先验的反馈来调整之后的选择, 他们对于因果学习的结果似乎是不可动摇的(Jardri & Denève, 2013)。
研究中精神分裂症患者在所有任务上的反应时都长于健康被试, 这也是精神分裂症患者的一种常见病理特征, 患者们由于长期服用神经阻滞剂类药物, 产生了许多方面的副作用, 其中就有如急性肌张力不全等对神经系统方面的影响(Schatz, 1998), 致使患者反应变慢, 这是精神分裂症患者研究中常见的一种额外变量。
6 结论
本研究发现在视觉通道条件下, 精神分裂症患者有自我面孔识别的能力; 在听觉通道条件下, 精神分裂症患者有自我声音识别的能力; 在视听双通道条件下, 视觉通道自我面孔的主导效应超过正常人, 即自我面孔促进了自我声音识别, 抑制了对他人声音的识别, 乃至会更多地将他人声音虚报为自我声音, 验证了精神分裂症患者有自我面孔识别的能力。此外, 在视听双通道条件下, 同性面孔和异性面孔都抑制了自我声音的识别。
致谢:
本文的英文摘要部分得到了西北师范大学Nicole L. Ross老师的支持, 特此鸣谢。
参考文献
Mental rotation of faces in healthy aging and Alzheimer's disease
Self-other integration and distinction in schizophrenia: A theoretical analysis and a review of the evidence
Dual neural routing of visual facilitation in speech processing
Direct structural connections between voice- and face-recognition areas
Face recognition in schizophrenia disorder: A comprehensive review of behavioral, neuroimaging and neurophysiological studies
Mirror self-face perception in individuals with schizophrenia: Feelings of strangeness associated with one's own image
Further insight into self-face recognition in schizophrenia patients: Why ambiguity matters
Detection of audio-visual integration sites in humans by application of electrophysiological criteria to the bold effect
Who is speaking? Implicit and explicit self and other voice recognition
Self-face recognition in schizophrenia: An eye-tracking study
Stimulus complexity matters when you hear your own voice: Attention effects on self-generated voice processing
Audio-visual integration in schizophrenia
Gaze control during face exploration in schizophrenia
Perceiving the sex and identity of a talker without natural vocal timbre
Is my voice just a familiar voice? An electrophysiological study
My voice or yours? An electrophysiological study
Are patients with schizophrenia impaired in processing non-emotional features of human faces?
The crisis of minimal self-awareness in schizophrenia: A meta- analytic review
Circular inferences in schizophrenia
The neural network sustaining the cross-modal processing of human gender from faces and voices: An fMRI study
Left hand advantage in a self-face recognition task
Visual self-recognition in patients with schizophrenia
Silent speechreading in the absence of scanner noise: An event-related fMRI study
Cross-modal processing of voices and faces in developmental prosopagnosia and developmental phonagnosia
Temporal event structure and timing in schizophrenia: Preserved binding in a longer “now”
Role of bone conduction in the self-perception of speech
Hearing lips and seeing voices
Acoustic cues for the recognition of self-voice and other-voice
Evidence for the redundant signals effect in detection of categorical targets
Schizophrenia and the sense of self
Differences in audiovisual integration, as measured by mcgurk phenomenon, among adult and adolescent patients with schizophrenia and age-matched healthy control groups
The interaction between exogenous attention and multisensory integration
外源性注意与多感觉整合的交互关系
Mcgurk effect in gender identification: Vision trumps audition in voice judgments
Is this my voice or yours? the role of emotion and acoustic quality in self-other voice discrimination in schizophrenia
Emotional self-other voice processing in schizophrenia and its relationship with hallucinations: ERP evidence
Schizophrenia, consciousness, and the self
Cognitive processing efficiency in schizophrenia: Generalized vs domain specific deficits
Self-face recognition in schizophrenia
Evaluation of speech misattribution bias in schizophrenia
Multisensory stimuli elicit altered oscillatory brain responses at gamma frequencies in patients with schizophrenia
Audio-visual speech perception in schizophrenia: An fMRI study
Neural basis of self and other representation in autism: An fMRI study of self-face recognition
Simulation of talking faces in the human brain improves auditory speech recognition
Eluding the illusion? Schizophrenia, dopamine and the mcgurk effect
Auditory hallucinations and the temporal cortical response to speech in schizophrenia: A functional magnetic resonance imaging study
Selective impairment in recognizing the familiarity of self faces in schizophrenia

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}