

1 前言
人们常常根据外部反馈信息来矫正自己的错误行为。外部反馈既可以在短时间内帮助人们觉察错误, 及时补救, 又可以在较长时间内帮助人们区分奖惩, 强化适应性行为。因此, 研究者们一直关注人脑是如何评估外部反馈的。反馈评估(feedback evaluation), 或称为结果评价, 是行为监控(performance monitoring)过程的一部分, 主要通过比较预期与实际结果来判断结果的好坏、得失等(Ullsperger, Danielmeier, & Jocham, 2014)。反馈评估有助于人们优化自己的行为方式和策略, 以便更快适应环境(Holroyd & Coles, 2002)。反馈评估在行为上通常表现为简单选择反应任务中的错误后减慢(Wang et al., 2015), 或时间估计任务中, 错误后时间估计调整量的增大(向玲, 王宝玺, 张庆林, 2012)。反馈评估的脑电(ERP)研究发现, 反馈相关负波(feedback-related negativity, FRN)可以作为神经生理指标, 用以考察反馈评估的神经机制(李丹阳, 李鹏, 李红, 2018; Sambrook & Goslin, 2015; Walsh & Anderson, 2012)。
FRN是一个分布于前额中部的负向偏转脑电成分, 最初发现于正确反馈和错误反馈所引发脑电波的差异(Miltner, Braun, & Coles, 1997)。这一差异出现于反馈后200~400 ms, 而波峰出现于250 ms左右(Gehring & Willoughby, 2002)。相对于有利结果, 不利结果, 如错误反馈、金钱损失会诱发更负的FRN (效价效应), 这一现象被称为好/坏二元分类评估(good/bad binary evaluation) (Gehring & Willoughby, 2002; Hajcak, Moser, Holroyd, & Simons, 2006; Holroyd, Hajcak, & Larsen, 2006; Yeung & Sanfey, 2004)。FRN的效价效应符合强化学习理论(reinforcement learning theory) (Holroyd & Coles, 2002)。最近有研究者认为, 正、负反馈诱发的脑电波的差异是正反馈诱发的奖赏正波(reward positivity, RewP) (Proudfit, 2015)导致的, 而不是因为负反馈诱发的负脑电成分。奖赏正波通常是FRN差异波(即负反馈引发的脑电成分减去正反馈引发的脑电成分)或采用主成分分析技术得到的, 而由于正、负反馈之后, 通常都会出现负偏向成分, 根
据直观结果以及前人研究(Sambrook & Goslin, 2015; Walsh & Anderson, 2012), 本研究也把正负反馈诱发的脑电成分称作FRN。
反馈评估相关ERP研究中, 一个研究者们感兴趣的问题是人脑是如何判断好坏的呢?在不同实验背景下, 人脑对同一事件的价值评估是否相同呢?针对这些问题, 研究者们进行了相关研究。结果发现, 人在进行反馈评估时, 对同一事件的好坏界定是以该结果与同处一个背景下的其他结果相比较得出的相对价值(relative value)为判断标准, 因此FRN的好/坏二元评估是以背景依赖为基础实现的(Holroyd, Larsen, & Cohen, 2004; Kujawa, Smith, Luhmann, & Hajcak, 2013; Osinsky, Walter, & Hewig, 2014)。
Holroyd等人于2004年考察背景(context)对FRN波幅的影响, 首次探究反馈评估是遵循背景依赖还是背景独立这一问题。如果人在不同实验背景对某个反馈刺激的价值判断相同, 则其评估不受背景影响, 即背景独立; 如果人在不同实验背景, 对某个反馈刺激的价值评估是根据其在具体背景的相对价值来判断, 则其评估受到背景影响, 即背景依赖(Holroyd et al., 2004)。
Holroyd等人(2004)向被试呈现两个背景:“Win”背景, 被试可能获得一个大数额(+ +)、小数额(+)或者零金额(0)的金钱; “Lose”背景, 被试可能损失一个大数额(- -)、小数额(-)或者零金额(0)的金钱。“Win”背景和“Lose”背景采用组块间变化(block by block)的呈现方式。结果发现, 两种背景中相对更坏的结果引发的FRN都显著负于相对更好的结果。另外, 分析了被试对零金额的评估结果。零金额是“Win”背景中的最差结果, 也是“Lose”背景中的最好结果, 这是“0”的相对价值; 而其绝对价值都是“0”。结果发现“Win” 0比“Lose” 0引发更负的FRN。以上结果说明反馈评估是背景依赖的。Holroyd等人(2004)认为人判断行为表现好坏是根据期望水平, 而不是结果本身的客观价值(objective value)。Nieuwenhuis, Yeung, Holroyd, Schurger和Cohen (2004)也提出背景是通过影响人对结果的主观价值(subjective value)形成来影响FRN波幅的; Nieuwenhuis等人(2005)发现奖赏相关脑区, 如伏隔核、杏仁核也存在背景依赖效应。向玲、王宝玺、张庆林和袁弘(2008)发现FRN反映的是以赌注为基点的相对价值, 且比投注稍大或稍小的反馈无显著差异, 故研究者提出参照是以赌注为基点的区间而非一个点。
背景因素是如何影响结果评估过程的?Osinsky等人(2014)发现未选择选项结果是人们评估所选选项结果的重要背景因素。人们在评估所选选项结果时, 以未选选项结果为参照, 确定所选选项结果的相对价值, 相对更坏的结果引发了更负的FRN。而关于背景是如何发挥作用的, Osinsky等人认为人脑中存在一个内部参照系统, 通过不断结合分析反馈和环境信息, 对结果形成预期, 而早期评估通过期望来判断好坏。这一系统与Holroyd和Coles (2002)所提出的强化学习系统在概念上、功能上和结构上高度重叠, 都与对结果的预期高度相关。
Kujawa等人于2013年对背景依赖进行进一步探究, 提出FRN的背景依赖效应只能是整体(global)背景依赖, 还是可以发生在局部(local)背景水平这一问题。整体背景依赖指以同一组块(block)内所有可能结果为参照的背景依赖模式; 局部背景依赖是指以单个试次的所有可能结果为参照的背景依赖模式。以整体背景为参照, 参照标准不用时时变化, 相对固定和容易。而以单个试次的背景为参照, 需要在每个试次评估时提取本试次的背景, 参照标准时时变化, 更灵活但是难度也较大。
Holroyd等人(2004)研究中的“Win”和“Lose”背景为组块间变化, 因此该背景依赖效应可以认为是整体水平的。Kujawa等人(2013)采用添加线索的简单赌博任务, 线索为试次间变化(trial by trial)呈现。其中, 半绿半白色圆环线索表示被试处于获益试次, 50%可能获益(绿色上箭头), 50%可能不获益(“0”); 半红半白色圆环线索表示被试处于损失试次, 50%可能损失(红色下箭头), 50%可能不损失(“0”)。结果发现, 获益背景下, 零获益比获益反馈引发更负的FRN; 损失背景下, 零损失与损失反馈所引发的FRN无显著差异。跨线索比较发现, 零获益、零损失和损失反馈无显著差异, 零损失和损失反馈显著负于获益反馈。这一结果表明线索并未起作用, 人在进行结果评估时以整个组块所有可能结果为参照, 而非以现有线索背景下的本试次可能的结果为参照。因此该结果也支持背景依赖为整体水平, 而不是局部水平。然而, Angus等人(2017)同样采用添加线索和试次间变化的任务, 却发现无论获益背景或损失背景下, 该背景下相对坏比相对好的反馈引发更负的FRN。这表明线索是起作用的, 每种线索在本试次中形成相应背景, 人在评估结果时, 仅以所在试次的可能结果为参照, 该结果支持背景依赖为局部水平。因此, 局部水平的背景是否能影响结果评估, 结论还不统一。当人在进行结果评估时, 背景依赖效应是只能在整体水平上发挥作用, 还是可以延伸到局部水平即本研究所关注的问题。
为了探究该问题, 本研究改进了Kujawa等人(2013)的研究, 采用添加奖励线索的时间估计任务(估计1秒时间) (Mars, De Bruijn, Hulstijn, Miltner, & Coles, 2004; Miltner et al., 1997; 向玲 等, 2012)。首先由每个试次开始时的线索决定所在试次为获益或损失背景, 然后根据被试时间估计的准确与否给予正确反馈或错误反馈, 最后通过分析反馈呈现后FRN来检验FRN背景依赖效应出现于整体水平还是出现于局部水平。数据处理参照Kujawa等人(2013)的研究。相对于Kujawa等人(2013)的研究, 本研究有两个改进:第一个是采用主动任务且反馈为真实反馈。Kujawa等人(2013)的研究中采用的简单赌博任务, 反馈为伪随机反馈。主动任务和真实反馈, 有利于提高被试的动机, 可以促进针对每个试次的精细加工; 第二个是增加试次数, 每个实验条件设置80试次。Kujawa等人(2013)的研究中每个条件20个试次。试次太少可能造成被试没有完全掌握线索的意义。通过增加试次, 可以促进被试对线索的加工, 改善对局部背景的使用。
如图1所示, 如果为局部背景依赖, 则每个试次中相对坏的结果比相对好的结果会引发更负的FRN, 也就是说, 获益背景中零反馈比获益反馈引发更负的FRN, 而损失背景中损失反馈比零反馈引发更负的FRN, 并且获益-零反馈比损失-零反馈引发更负的FRN (Angus et al., 2017)。如果为整体背景依赖, 则结果与Kujawa等人(2013)的结果类似, 以所有可能的结果为参照, 相对坏的结果(损失反馈和零反馈)比相对好的结果(获益反馈)引发更负的FRN, 无论所在试次线索如何(Kujawa et al., 2013)。
图1
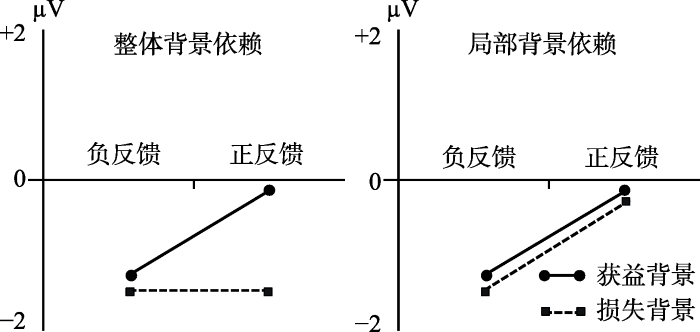
图1
背景依赖情况示意图。如果结果评估采取整体依赖模式, 结果如左图所示, 被试以所有可能的结果为参照, 相对坏的结果比相对好的结果引发更负的FRN, 不受所在试次的线索影响。如果结果评估采取局部依赖模式, 结果如右图所示, 被试以本试次的可能的结果为参照, 相对坏的结果比相对好的结果引发更负的FRN。
2 方法
2.1 被试
本研究中(本研究隶属于一个项目, 该项目研究大脑反馈评估的方式以及影响因素。该项目还设置了不同的控制条件和实验条件, 考察控制条件对实验条件的影响; 设置了不同类型的线索呈现方式, 考察线索提取难度对反馈评估的影响。而本研究通过获益和损失线索所在试次的结果评估, 研究背景依赖效应是否在局部水平下依然存在。), 25名成年人(17名女性, 平均年龄21.96岁)参与时间估计任务(2 结合前人研究, 使用G*Power 3.1推算样本量。其中, 最大效应值设置为f = 0.4 (Meadows, Gable, Lohse, & Miller, 2016), α = 0.05, 重复测量间相关系数为r = 0.5。最终推算出样本量为19。结合本研究对标研究(Kujawa et al., 2013)的有效样本量为22人, 本研究最终将被试量定为25。)。采用Oldfield (1971)的方法确定所有被试均为右利手, 视力或矫正视力正常, 无神经系统和心理疾病病史。所有被试在实验进行前阅读知情同意书并签字。本研究已通过山东师范大学伦理委员会审查。
2.2 实验程序
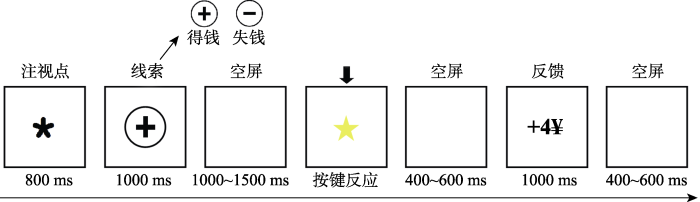
被试坐在安静的实验室中, 距离电脑屏幕1 m。实验流程如图2所示, 首先在屏幕中央呈现一个注视点(800 ms)。在进行时间估计之前, 会先呈现一个线索表明当前试次所处的特定背景, 线索呈现1000 ms。线索包含获益(圆圈中“+”)和损失(圆圈中“-”) (视角均为2.3° × 2.3°) (Angus et al., 2017; Pfabigan et al., 2015)。线索出现后的1000~1500 ms (随机间隔)中, 要求被试在心中默记所看到的线索, 同时准备做出反应。随后, 在金色五角星(目标刺激, 视角为2.3° × 2.3°)出现时, 被试开始估计1秒钟, 同时计算机开始计时; 当被试感觉1秒钟已经过去, 即目标刺激已经呈现了1秒钟时, 就用右手食指按“空格键”, 计算机停止计时, 目标刺激消失。在随机间隔400~600 ms后, 计算机根据被试的真实时间估计准确或不准确, 给予被试相应的反馈, 反馈呈现1000 ms。最后再经过400~600 ms随机间隔, 进入下一试次。
被试的初始奖金为30元。在获益背景下, 被试估计准确获得4元; 估计不准确则获得0元。而在损失背景中, 估计准确损失0元; 估计不准确则损失4元。主试通过指导语告诉被试规则, 并通过指导语阶段的记忆和练习阶段的重复练习确保其明白线索和反馈的意义。如果是局部背景依赖, 那么被试会利用线索进行评估, 实验结果将会得到这四种条件:获益-正(+ ¥4)、获益-负(¥0)、损失-正(¥0)、损失-负(- ¥4)。如果是整体背景依赖, 也就是说每个试次的线索不起作用, 那么被试会将反馈评估为三种类型:正(+ ¥4)、中(¥0)和负(- ¥4)。本研究参照Kujawa等人(2013)的实验设计, 根据具体结果, 验证背景依赖是否可以在局部水平实现。
图2
为了使整体和每种背景中的时间估计正确率保持在50%左右, 本研究采用了滑动时间窗口设置(Mars et al., 2004; Miltner et al., 1997)。最初的时间窗口为1000 ± 120 ms, 即要求被试在首个试次所估计的时间长度必须在880~1120 ms这个范围内, 才认为其时间估计准确, 给予正性反馈; 否则则认为估计不准确, 给予负性反馈。同时采用自适应机制, 使得时间窗口可以根据被试估计准确与否进行动态调整。若时间估计准确, 窗口两端各减小10 ms, 提高时间估计的难度, 以降低正确率; 若时间估计不准确, 则窗口两端各增加10 ms, 降低难度, 以提高正确率。
练习实验阶段, 被试进行练习试次。待被试熟悉实验程序后, 进入正式实验阶段, 获益情景、损失情景各占160个试次, 共320个试次, 两种线索随机呈现。实验过程中, 每40个试次有一次小间歇(大约5分钟), 每80个试次有一次大间歇(10~15分钟)。
2.3 EEG的记录和分析
实验程序使用E-Prime 2.0 (Psychology Software Tools, Inc., Sharpsburg, PA)编写。实验采用Brain Products系统(Brain Products GmbH, Munich, Germany), 以及符合标准10-20系统的配套电极帽收集EEG数据(滤波带通:0.0531~80 Hz; 采样频率:500 Hz)。以电极点FCz作为在线参考, 电极点AFz作为接地点进行记录。头皮与电极接触电阻小于10 kΩ。水平眼电(HEOG)由安置于右眼下方的电极记录, 垂直眼电(VEOG)由安置于左眼外侧1 cm处的电极记录。
实验数据采用Brain Vision Analyzer 2.0进行离线分析。首先, 重置参考为双侧乳突的平均波幅值, 并将FCz恢复为可分析电极点。然后, 滤波采用0.1~20 Hz带通及24 dB衰减模式。分段时程为反馈刺激出现的-200~800 ms, 其中-200~0 ms作为基线。采用ICA眼动矫正机制半自动矫正眼电伪迹。波幅超过+/- 80 µV被视为伪迹半自动剔除。最后, 对每种条件下EEG进行叠加平均。
因为反馈相关脑电成分(如:P2、FRN、P300)易受成分叠加的影响, 所以本研究依据前人经验, 选择峰峰值算法(Holroyd, Nieuwenhuis, Yeung, & Cohen, 2003; Osinsky, Mussel, & Hewig, 2012; Osinsky et al., 2014; Pfabigan, Alexopoulos, Bauer, & Sailer, 2011; 向玲 等, 2012)。FRN峰峰值(FRN - P2)是指反馈出现后200~300 ms内最负波(作为FRN波幅值)减去反馈呈现后150~250 ms内的最正波(作为P2波幅值)的差值; 若FRN峰峰值为非负数, 则FRN波幅值记为0 µV (Holroyd et al., 2003; 向玲等, 2012)。根据这一规则, 共有23个数据记为0 µV, 占7.67%。选取Fz、FCz、Cz三个点对FRN波幅进行取值。
脑电数据分析包括两部分。第一部分, 进行2 (线索:获益、损失) × 2 (反馈效价:正、负) × 3 (电极点:Fz、FCz、Cz)的三因素重复测量方差分析, 主要目的是验证局部水平的背景依赖效应; 第二部分是选取FRN波幅值最大的电极点的ERP数据, 采用配对样本t检验分别比较获益-正和获益-负、损失-正和损失-负、同为零反馈的获益-负和损失-正, 主要目的是验证整体水平的背景依赖效应, 尤其是通过比较两种零反馈(获益-负、损失-正), 验证大脑是根据其所处背景下的相对价值评估的, 还是根据其绝对价值评估的。
2.4 行为数据分析
为了检测滑动时间窗口是否有效, 本研究使用t检验对各条件下的准确与不准确的试次数进行比较。另外, 为了检验线索和反馈效价对行为适应的影响, 以本试次与前一试次被试所估计时间差值的绝对值(|trialn - trialn-1|)为因变量(向玲 等, 2012), 前一试次的线索和反馈效价为自变量, 进行2 (线索:获益、损失) × 2 (反馈效价:正、负)双因素重复测量方差分析。
本研究使用SPSS 17.0进行数据分析。如有需要, 采用Greenhouse-Geisser对数据进行校正。
3 结果
3.1 行为结果
首先, 对各条件下的准确与不准确试次数进行比较, 均未发现显著差异:获益背景(正:79.84 ± 6.58, CI95% = 77.12~82.56; 负:80.20 ± 6.58, CI95% = 77.48~82.92), t(19) = -0.14, p = 0.892; 损失背景(正:79.76 ± 5.79, CI95% = 77.37~82.15; 负:79.92 ± 5.79, CI95% = 77.53~82.31), t(19) = -0.07, p = 0.945。另外, 总的正确率为49.98%。以上结果表明实验中滑动时间窗口的设置有效, 正反馈与负反馈比率得到有效控制。
图3所示为时间估计的试次间调整量。方差分析发现, 反馈效价的主效应显著, F(1, 24) = 37.47, p < 0.001, ηp2 = 0.61, 负反馈(M = 135.46 ms, CI95% = 123.92~145.00 ms)引发的时间估计试次间变化显著大于正反馈(M = 168.47 ms, CI95% = 155.21 ~ 183.74 ms); 但是线索的主效应并不显著(获益:M = 151.95 ms, CI95% = 139.77~164.12 ms; 损失:M = 152.99 ms, CI95% = 139.06~166.91 ms), F(1, 24) = 0.13, p = 0.719。两者交互作用边缘显著, F(1, 24) = 4.03, p = 0.056, ηp2 = 0.14。行为结果表明, 被试能够利用线索, 并根据线索在特定的背景下, 对结果正负进行辨别。
图3

3.2 ERP结果
方差分析结果发现反馈效价主效应显著, F(1, 24) = 61.14, p < 0.001, ηp2 = 0.72, 负反馈(M = -6.97 μV, CI95% = -8.34~-5.60 μV)引发的FRN显著负于正反馈(M = -3.77 μV, CI95% = -5.12 ~ -2.42 μV); 电极点的主效应也显著, F(2, 48) = 13.31, p = 0.001, ηp2 = 0.36, 其中Fz点(M = -5.98 μV, CI95% = -7.41~-4.54 μV)和FCz点(M = -5.59 μV, CI95% = -6.94~-4.24 μV)的波幅值显著大于Cz点(M = -4.55 μV, CI95% = -5.75~-3.349 μV) (p = 0.001; p < 0.001), Fz点和FCz点无显著差异(p = 0.089); 而线索(获益: M = -5.68 μV, CI95% = -6.98~-4.37 μV; 损失: M = -5.06 μV, CI95% = -6.42~-3.71 μV)的主效应不显著, F(1, 24) = 3.84, p = 0.062。因为本研究主要关注线索与反馈效价对于结果反馈的影响, 所以仅报告线索×反馈效价交互作用。实验结果并未发现显著的线索×反馈效价交互作用, F(1, 24) = 0.02, p = 0.899 (详见图5、图6)。
以Fz点的ERP数据为因变量, 进一步对不同的试次类型进行配对样本t检验。结果发现无论处于获益背景还是损失背景, 相对于正反馈, 负反馈会引发一个显著更负的FRN (获益: t(24) = 4.19, p < 0.001, d = 0.84; 损失: t(24) = 3.31, p = 0.003, d = 0.66)。比较两背景中相对好的两种反馈和相对坏的两种反馈发现, 获益-正与损失-正反馈、获益-负与损失-负反馈并未发现显著差异(t(24) = 0.48, p = 0.634, d = 0.09; t(24) = -1.10, p = 0.284)。另外, 两种零反馈存在显著差异, 即获益-负反馈(相对坏的结果)引发的FRN波幅值显著大于损失-正反馈(t(24) = -6.86, p < 0.001, d = 1.37) (见图4)。
图4

综上, 当线索试次间变化时, 无论获益背景还是损失背景, 处于该背景下相对更坏的反馈总会比相对更好的反馈引发更负的FRN, 即FRN具有背景依赖效应, 而且是局部水平的背景依赖。这与Angus等人(2017)结果一致, 但与Kujawa等人(2013)并不一致。
因Kujawa等人(2013)研究中每个条件仅设置了20个试次, 而本研究每个条件设置了80试次。我们推测试次数过少可能会影响线索-结果联结的建立, 进而影响结果评估时大脑是否根据线索评估本试次的结果。为了排除这个可能性, 本研究截取每种实验条件的前20个试次重新进行叠加分析。
前20试次脑电数据的分析结果与所有试次的分析结果完全一致, 反馈出现后波幅变化模式也基本一致, 说明试次数并未对不同条件下的FRN波幅产生显著影响, 排除了试次数的影响。前20试次的分析结果与Kujawa等人(2013)的结果也不一致, 再次证明FRN的背景依赖可以延伸至局部水平。
图5

图6

4 讨论
为了探索大脑如何进行好坏评估, Holroyd等人(2004)提出并验证了FRN的背景依赖效应。随后, 研究者们开展了许多不同的背景依赖性相关研究。研究者们使用的背景包括不同结果出现的频率(Holroyd et al., 2003)、结果呈现次序(Osinsky et al., 2012)、某背景下可能的结果(Angus et al., 2017; Holroyd et al., 2004; Kujawa et al., 2013; Osinsky et al., 2014; Pfabigan et al., 2015)。本研究采用时间估计任务, 通过线索的试次间变化来构建每个试次上的特定背景, 并根据被试所估计时间是否在滑动时间窗口内, 给予其估计正确或错误的真实反馈, 从而探讨当人在进行结果评估时, 究竟是以整体所有结果为参照, 还是更进一步, 以局部背景下的可能结果为参照。
行为结果发现, 无论总体还是获益或损失背景, 其正确率均在50%左右, 说明实验过程中滑动时间窗口的设置有效(Mars et al., 2004; Miltner et al., 1997; 向玲 等, 2012)。对于所估计时间的试次间变化量, 获益和损失背景下, 负反馈所引发的变化量均显著大于正反馈的, 即人在接收到负反馈后, 会在下次行为做出相对于本次行为更大的调整。人可以从错误中汲取经验, 通过改变不适当的行为以便表现得更好以达到最终目的(Luft, 2014)。行为结果表明, 被试利用了线索信息, 针对具体背景来辨别相对的正负, 进行行为调整。
脑电结果发现, 总试次数与前20试次的ERP分析结果基本一致。首先, 反馈效价对FRN产生显著影响, 即相对于相对好的反馈, 相对坏的反馈引发更负的FRN, 这与诸多前人研究结果一致(Angus et al., 2017; Gehring & Willoughby, 2002; Hajcak, Holroyd, Moser, & Simons, 2005; Holroyd et al., 2004; Kujawa et al., 2013), 符合强化学习理论的好/坏二元分类评估推论(Holroyd & Coles, 2002)。更重要的是, 被试在评估时利用了线索信息, 被试对事件的好坏评估是根据具体背景而言的。在获益背景中, 相对坏的反馈(零获益)都比相对好的反馈(获益)引发更负的FRN; 在损失背景中, 相对坏的反馈(损失)都比相对好的反馈(零损失)引发更负的FRN。同样是零反馈, 获益-零(相对坏)反馈比损失-零(相对好)反馈引发更负FRN。这些结果与Angus等人(2017)结果一致, 根据本研究假设, 被试在反馈加工过程中, 是以某局部背景下的可能结果为参照的, 即FRN的背景依赖效应可以延伸到局部水平。但这一结果与结果不一致。同样为线索试次间变化, Kujawa等人(2013)发现结果评估是以所有结果为参照, 而非以当前试次特定背景下的结果为参照, 因此获益-零反馈和损失-零反馈所引发的FRN无显著差异, 零反馈与损失反馈也无显著差异, 但两者均比获益反馈引发了更负的FRN。
同样是试次间变化和通过线索构建背景的实验任务, 为何人在进行结果评估是有时以整体结果为参照(Kujawa et al., 2013), 有时则以局部结果为参照(Angus et al., 2017)?根据前人研究(Heydari & Holroyd, 2016; Mulligan & Hajcak, 2018; Soder & Potts, 2018)以及本研究与Kujawa等人(2013)的研究对比, 我们推测任务类型及反馈是否真实可能是关键因素。
反馈评估相关ERP研究中, 常用实验任务可大体分为被动任务(被试不做任何反应, 反馈也无虚假、真实之分) (Talmi, Atkinson, & Elderedy, 2013; Soder & Potts, 2018)、含虚假反馈的主动任务(被试做反应, 但反馈并非根据被试真实表现给出, 多为伪随机呈现) (Heydari & Holroyd, 2016; Kujawa et al., 2013; Mulligan & Hajcak, 2018)、含真实反馈的主动任务(被试做反应, 且得到根据其真实表现给出的真实反馈) (Angus et al., 2017)。
Talmi等人(2013)呈现给被试多个线索和反馈, 但并不需要被试做任何反应, Soder和Potts (2018)采用与之类似的被动(passive)任务, 均未发现FRN对效价的敏感性, 即正、负反馈引发的FRN无显著差异。Heydari和Holroyd (2016)针对这一点, 采用主动性和参与感更强的T迷宫任务, 被试需要在迷宫中选择行进方向(向左或向右), 随后获得奖励或非奖励的虚假反馈, 结果却发现结果评估遵循二元分类规则, 即负反馈比正反馈引发更负FRN。Mulligan和Hajcak (2018)采用同样需要被试主动做出选择的简单赌博任务, 结果与Heydari和Holroyd (2016)一致。Kujawa等人(2013)同样发现FRN的二元分类标准, 同时, 其结果表明FRN的产生依赖整体背景。本研究与Angus等人(2017)采用主动任务设计, 但是根据被试行为的正确与否给予真实反馈, 结果发现结果评估的情境依赖可以延伸至局部水平。
因此, 本研究认为任务类型及反馈真实性在结果评估是否遵循二元分类, 以及结果评估是依赖整体或局部背景这一点上起到重要影响。其内部机制可能是任务类型及反馈真实性会影响人们进行结果评估时的主观能动性和对结果的掌控感(sense of agency) (Sambrook & Goslin, 2015)。被动设计可能会减少被试对结果的知觉控制和相关主观能动性, 而有实验结果表明主观选择之后的反馈会最大化FRN波幅(Walsh & Anderson, 2012; Yeung & Sanfey, 2004), 所以, 被动任务范式中负反馈引发FRN波幅会减小(Heydari & Holroyd, 2016; Sambrook & Goslin, 2015), 而主动任务范式中则会相应增大。而相较于伪随机的虚假反馈, 能够反映被试表现的真实反馈可能使得被试具有更高的主观能动性和掌控感, 而这可能调动更多注意资源, 使每个试次开始时的线索起作用, 构建起该试次下的特定情境, 从而使得人在进行结果评估时, 是以所处局部背景中的可能结果为参照, 而非跨试次的整体背景中的全部结果为参照。
综上, 我们推测任务类型(主动/被动任务)和反馈的真实性(真实/虚假反馈)可能通过影响人的主观能动性和掌控感, 进而影响人的注意资源分配, 最终决定FRN对效价敏感与否和背景依赖效应归为整体或局部。主动任务范式中, 若给予虚假反馈, 人在进行结果评估时, 则以整体全部结果为参照; 若给予真实反馈, 则以所处背景下局部部分结果为参照。
本研究在数据挖掘方面还存在不足, 还需采用更加深入的分析方法, 如主成分分析和时频分析等, 从另一个角度对FRN的背景依赖效应进行检验。另外, 针对时间估计任务中行为与脑电活动的关系, 可以采用脑电信号的单试次分析, 以更好地探究反馈评估中行为适应的脑机制。
参考文献
Electrocortical components of anticipation and consumption in a monetary incentive delay task
The medial frontal cortex and the rapid processing of monetary gains and losses
Brain potentials associated with expected and unexpected good and bad outcomes
The feedback-related negativity reflects the binary evaluation of good versus bad outcomes
Reward positivity: Reward prediction error or salience prediction error?
The neural basis of human error processing: Reinforcement learning, dopamine, and the error-related negativity
The good, the bad and the neutral: Electrophysiological responses to feedback stimuli
Context dependence of the event-related brain potential associated with reward and punishment
Errors in reward prediction are reflected in the event-related brain potential
The feedback negativity reflects favorable compared to nonfavorable outcomes based on global, not local, alternatives
The updated theories of feedback-related negativity in the last decade
Learning from feedback: The neural mechanisms of feedback processing facilitating better performance
What if I told you: ‘you were wrong’? Brain potentials and behavioral adjustments elicited by feedback in a time-estimation task. M. Ullsperger, M. Falkenstein (Eds.), Errors, Conflicts, and the Brain
The effects of reward magnitude on reward processing: An averaged and single trial event-related potential study
Event-related brain potentials following incorrect feedback in a time-estimation task: Evidence for a “generic” neural system for error detection
The electrocortical response to rewarding and aversive feedback: The reward positivity does not reflect salience in simple gambling tasks
Activity in human reward-sensitive brain areas is strongly context dependent
Sensitivity of electrophysiological activity from medial frontal cortex to utilitarian and performance feedback
The assessment and analysis of handedness: The Edinburgh inventory
Feedback-related potentials are sensitive to sequential order of decision outcomes in a gambling task
What is and what could have been: An ERP study on counterfactual comparisons
Manipulation of feedback expectancy and valence induces negative and positive reward prediction error signals manifest in event-related brain potentials
Context-sensitivity of the feedback-related negativity for zero-value feedback outcomes
The reward positivity: From basic research on reward to a biomarker for depression
A neural reward prediction error revealed by a meta-analysis of ERPs using great grand averages
Medial frontal cortex response to unexpected motivationally salient outcomes
The feedback-related negativity signals salience prediction errors, not reward prediction errors
.
Neurophysiology of performance monitoring and adaptive behavior
Learning from experience: Event-related potential correlates of reward processing, neural adaptation, and behavioral choice
Disentangling the impacts of outcome valence and outcome frequency on the post-error slowing
Performance monitoring and behavioral adjustments in a time- estimation task: Evidence from ERP study
The effect of reference point of the feedback-related ERPs
Independent coding of reward magnitude and valence in the human brain

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}