

1 研究背景
在传统的实证研究中, 因素分析可以将众多观测变量降维, 提取出少量的因素来解释观测变量, 让研究者对题项的分类有更清楚的认识, 也可以运用更简洁的因素得分进行进一步研究.后来, 当研究者们希望使用同一测量工具进行跨群体比较时, 发现因素分析降维所得到的维度对组成总样本的不同子样本来说含义可能有所不同, 将因素均值和因素得分直接进行比较可能存在问题.所以, 检验维度的可比较性(comparability)成为越来越受关注的问题.一些跨国研究探究了测量工具的跨群体间的可比较性, 获得了许多有价值的发现.Billiet对欧洲各国男女性的宗教信仰进行了研究, 发现相比其他欧洲国家的女性, 土耳其女性是唯一回答参与宗教服务的频率比男性低的群组, 有些研究者可能会下“土耳其是欧洲唯一的男性比女性更信教的国家”的结论.但当及时了解到在土耳其这样的伊斯兰国家, 即使女性信教, 一般也不允许女性参与宗教服务, 作者判断这一题项对土耳其回答者的含义要不同于其他欧洲国家的回答者, 题项仅在其他欧洲国家间具备可比较性.正是发现了特殊的国情差异, 作者没有因为这一题项的异常而低估土耳其女性的信教程度(Billiet, 2013).Piurko等人研究了东欧和西欧国家公民的“左”和“右”的政治态度, 发现对“左”和“右”的理解可能在欧洲的自由主义国家(如瑞典),传统主义国家(如希腊),后共产主义国家(如捷克)间是不一样的(Piurko et al., 2011), 所以根据“左”和“右”的政治倾向把国家归类, 比较不同国家公民之间的回答可能并不合理.总之, 检验所研究维度在不同群体之间的可比较性十分重要.如果不具备可比较性, 因素分析所得出的因素得分或是因素均值就不能直接进行跨群组比较.
目前, 比较常用的一种检验维度可比较性的方法是多群组验证性因素分析(多群组CFA, multiple-group confirmatory factor analysis).研究者可以运用多群组CFA检验所得模型的测量恒定性(measurement invariance, Davidov et al., 2014; Millsap, 2011)来得出量表维度是否具备跨群体可比较性的结论.检验测量恒定性包括检验构置恒定(configural invariance或pattern invariance),因素载荷恒定(metric invariance或weak measurement invariance),截距恒定(scalar invariance或strong measurement invariance),残差恒定(uniqueness invariance或strict measurement invariance),因素方差-协方差恒定(factor variance-covariance invariance),因素均值恒定(factor mean invariance)等.构置恒定1(1国内有研究者使用“形态恒定”这一中文翻译(王孟成, 2014).但形态恒定的英文原文为pattern invariance, 与configural invariance有所不同.对于configural invariance, 国内许多研究者译为“结构恒定”, 笔者认为这一译法并不妥当.一方面, “结构的”对应的英文为structural, 将其和configural等同似乎并不恰当; 另一方面, 如上文所述, configural invariance代表各群组因素结构,数目相同, 还代表各因素设为定值和设为自由估计的因素载荷相同, 所以configural不仅有因素结构一致的含义, 还有因素载荷配置情况一致的含义.综上所述, configural invariance的中文译文不应当是“结构恒定”, 笔者认为应当是“构置恒定”.)表示对于不同的群组, 量表所包含的因素数目和各因素设为定值和设为自由估计的因素载荷是相同的(Marsh et al., 2017; Millsap, 2011; Vandenberg & Lance, 2000; Wang & Wang, 2012; Widaman & Reise, 1997), 检验该假设需要设定模型中不同群组有相同的因素数目, 相同估计模式的因素载荷; 因素载荷恒定表示对于不同的群组, 因素上每一单位的变化使观测变量产生的变化是相同的, 检验该假设需要在设定相同因素数目和因素载荷估计模式的基础上进一步设定模型中不同群组有相等的因素载荷; 截距恒定表示对于不同的群组, 观测变量的初始参照值是相同的, 检验该假设需要在设定相同因素结构,相同的因素载荷的基础上进一步设定模型中不同群组有相等的截距; 残差恒定等以此类推.由于这些依次限定参数恒定的模型具有嵌套关系, 所以检验这些测量恒定性假设需要计算所研究模型两两间的卡方变化值和自由度变化值, 进而计算出显著性, 得出是否拒绝原假设.通常情况下, 只要不同群组的构置,因素载荷和截距都满足测量恒定, 就说明不同群组对研究维度的理解相同, 进而可以对不同群组的因素均值进行直接比较, 探究不同群组在所得维度上的表现差异.
大多数的实证研究都希望通过多群组CFA探究不同群组在潜在因素上的表现差异, 也就是进行因素均值比较.但多群组CFA最大的不足是依赖严苛的截距恒定假设才能进行群组间因素均值比较, 而截距恒定假设在许多情况下无法满足.在这些情况下, 多数研究者会试图借助于修正指数(modification index)释放一些参数限定来改善模型拟合, 可能会得到部分截距恒定模型, 继续进行均值比较.但Asparouhov和Muthén在2014年指出, 通过修正指数进行模型修正需要人工手动选择, 存在主观性.另外, 通过修正指数进行模型修正可能导致得出并不正确的部分恒定模型, 因为截距恒定模型本来就和真实模型相差甚远(Asparouhov & Muthén, 2014).Marsh等人也在2017年指出, 虽然通过修正指数释放参数可以得到模型拟合度较好的部分截距恒定模型, 但这样做并不能保证得到没有偏差的因素均值(Marsh et al., 2017).因此, 当截距恒定被拒绝时, 如何继续进行组间比较一直以来都是难题.
Asparouhov和Muthén在2014年提出了一种“对齐” (Alignment)方法, 并不依赖截距恒定, 只需要模型中的大多数参数满足近似恒定就可以进行因素均值比较(Asparouhov & Muthén, 2014).对齐方法相比传统方法拥有众多优势, 但可能由于对传统方法的依赖,新方法理解有一定难度,新方法只能在Mplus软件上实现等原因, 对齐法目前只在少数国外实证研究中被使用.本文希望对新方法的原理和优势进行介绍, 并运用我国某省4个学校的本科生职业价值观研究实例来演示如何使用对齐法进行实证研究.
2 对齐方法的原理
从最一般的线性回归模型入手, 其一般形式如下式所示:
y = a + bx + ε (1)
其中y为因变量, 也可称为结果变量, 对应坐标轴y轴上的数值.x为自变量, 也可称为预测变量, 用来解释因变量, 对应坐标轴x轴上的数值.a为截距, 是直线与y轴的交点的数值, 此时x = 0, 截距值是y的初始参考值.b为斜率, 也就是回归系数, 直接反映了自变量x每变化一个单位因变量y所改变的值.ε为残差, 代表观测值与预测值的偏离, 服从正态分布.线性回归描述了自变量和因变量间最一般的线性关系.
如果把一般线性回归模型推广至因素分析, 那么假设多群组CFA模型为下式:
${{y}_{ipg~}}=~{{v}_{pg}}+\underset{m=1}{\overset{m}{\mathop \sum }}\,{{\lambda }_{pmg}}{{\eta }_{img}}+{{\varepsilon }_{ipg}}$ (2)
其中y为观测变量, 属于因变量; v为截距, 与一般线性回归类似, 代表观测变量初始参照值(蔡华俭, 林永佳, 伍秋萍, 严乐, 黄玄凤, 2008); λ为因素载荷, 相当于一般线性回归中的斜率, 代表因素η每变化一个单位在相应观测变量上的变动值; η为因素, 也就是问卷量表中各观测变量所包含的维度, 相当于一般线性回归中的自变量x; 残差仍然为ε.这些参数可以属于不同的群组,因素,观测变量,不同群组中的个案, 所以有了下标.其中p = 1, 2, et al., p,为观测变量序数; m = 1, 2, et al., m, 为因素序数; g = 1, 2, et al., g,为群组序数; i = 1, 2, et al., i,为群组g中的独立个案序数.假设εipg均值为0, 方差为θpg, 服从正态分布; 假设ηig均值为αg,方差为ψg,服从正态分布.
前文所提到的构置恒定模型就是要限制各群组η的数目和对应的设为定值和设为自由估计的λ相同, 因素载荷恒定就是要在构置恒定前提下继续限制各群组因素载荷λ相同, 截距恒定就是要在构置恒定和因素载荷恒定前提下继续限制各群组截距v相同.
如果多群组CFA测量恒定性检验满足了截距恒定, 就可以判定所得出的因素分析模型适用于所有群组, 维度具备可比较性, 可以直接对各群组的因素均值进行比较.但截距恒定假设所有群组的因素载荷和截距完全相等的条件过于苛刻, 在实际研究中很难得到满足, 尤其是当模型较为复杂, 群组数较多的时候.如果多群组CFA测量恒定性检验不满足截距恒定, 那么如上文所述, 研究者即使依靠部分截距恒定模型也很难得到正确的模型, 组间因素均值比较变得无从下手.
在多群组CFA构置恒定模型设定下, 因素均值和因素方差被设为定值, 无法被自由估计, 个案间的因素得分比较和群组间的因素均值比较都无法进行.只有分别限制了因素载荷恒定和截距恒定, 因素方差和因素均值才能被自由估计.与基于截距恒定模型进行组间因素均值比较的多群组CFA不同, 对齐法进行组间因素均值比较是基于构置恒定模型.
假设构置恒定模型为M0, 将其截距和因素载荷分别记为vpg0和λpg0.M0要求将因素转化为均值为0, 方差为1, 各群组需要做如下变换:
ηg0 = (ηg-αg) /\(\sqrt{{{\psi }_{g}}}\ \ \ (3)\)
同时, 为了让所有变量拥有相同的单位(metric), 方便不同观测变量进行比较, 对齐法也要求标准化所有观测变量.
观测变量的方差和均值如下式所示:
V (ypg) = λ2pgψg = λ2pg,0 (4)
E (ypg) = vpg+λpgαg = vpg,0 (5)
因此通过公式变换可以得到 :
λpg,0 =λpg\(\sqrt{{{\psi }_{g}}} \ \ (6)\)
vpg,0 = vpg+ \(\frac{{{\lambda }_{pg}}_{,0}}{\sqrt{{{\psi }_{g}}}}{{\alpha }_{g}}\ \ \ (7)\)
对于任意群组的αg和ψg, 总有对应的截距vpg和因素载荷λpg, 使得所得模型和M0具有相同的似然值, 并且由下式所得到:
λpg,1 =\(\frac{{{\lambda }_{pg}}_{,0}}{\sqrt{{{\psi }_{g}}}}{{}_{}}\ \ \ (8)\)
vpg,1 = vpg,0 - αg =\(\frac{{{\lambda }_{pg}}_{,0}}{\sqrt{{{\psi }_{g}}}}{{}_{}}\ \ \ (9)\)
通过赋予每个组别不同的因素均值αg和因素方差ψg, 利用待分析模型和最初构置恒定模型有相同模型拟合度的关系计算出对应的因素载荷λ和截距v, 如此不断重复,迭代, 直到以下总衰减函数(total loss function) F被最小化, 模型的参数不恒定性也被最小化, 此时就找到了最优测量恒定模型.
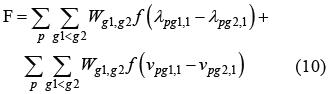
对于任意一对群组g1,g2, 截距和因素载荷的差异通过成分衰减函数(component loss function) ƒ的缩放被纳入进总衰减函数F进行计算.在Mplus中使用对齐法分析时所使用的成分衰减函数ƒ如下式所示:
$\left( x \right)=\sqrt{\sqrt{{{x}^{2}}+\varepsilon }} (11)$
此处ε为一个很小的正值, 保证了ƒ具有一阶连续导数.利用ƒ的一阶连续导数, 总衰减函数F的优化过程(optimization process)变得更容易, 方便了总衰减函数F的计算.成分衰减函数ƒ约等于\(\sqrt{|x|}\).总丢失函数F取得最小值解将是当模型中有少数较大的不恒定参数和大部分近似恒定的参数的时候.此时, 大部分参数近似恒定, 不同群组相应参数的差异x接近为0, ƒ(x)=\(\sqrt{|x|}\), 取得最小值; 对于少数较大的不恒定参数, 需要考虑两种情况:当x<1时, ƒ(x)>x, 参数不恒定性被放大, 较大的不恒定参数比较小的不恒定参数放大模型不恒定性的程度更小; 当x>1时, ƒ(x)<x, 参数不恒定性得到衰减, 较大的不恒定参数比较小的不恒定参数使模型不恒定性衰减的程度更大.所以, 根据ƒ的特点, x接近零本身取得最小值.如果必须有少量的x不接近零, 那么x应当尽量大.因为x越大, 函数衰减的越多, 模型的不恒定性衰减的越多.这和EFA中的旋转函数保留较大和较小载荷, 排除中等载荷的特点类似.
在公式(10)中, 总衰减函数F中的Wg1,g2是用来反映群组大小和特定群组参数估计的确定性.较大的群组比较小的群组对总丢失函数的贡献更大.具体计算如下式所示:
Wg1,g2 = $\sqrt{{{N}_{g1}}{{N}_{g2}}} (12)$
其中Ng1和Ng2为任意一对群组g1,g2的样本量.
当总衰减函数F被最小化后, 由于有一个群组被设为了方差为1的参照组(在Mplus中为第一组), 所以可以得到除了参照群组外的所有因素均值和因素方差和参照群组中的因素均值, 共计2g-1个参数.为了计算参照群组中的因素方差相对值, 需要利用以下参数限定, 令ψ1 = (ψ2×, et al.× ψg)-1:
ψ1×ψ2×, et al.×ψg = 1 (13)
在这里, 对齐法又可以分为固定优化和自由优化两种算法, 其区别是固定优化假设参照群组的均值α1为0, 自由优化则将α1自由估计.Asparouhov和Muthén所做的模拟研究显示, 当群组数目为2或是模型中没有不恒定参数时, 固定优化算法要优于自由优化算法; 在群组数目大于2并且模型不恒定时, 自由优化算法要优于固定优化算法(Asparouhov & Muthén, 2014).
3 案例应用
对齐法作为一种新方法, 在实证研究中的使用并不多.笔者根据研究经验, 针对在Mplus软件(2 Mplus 7.1以上的软件版本都提供了使用对齐法分析数据的功能.)中使用对齐法分析数据的步骤进行了一个总结.总得来说, 使用对齐法可以遵循以下四个步骤:
1)首先要运行EFA, 检验分析出的量表结构是否和设计时的结构相同, 如果不同, 则证明量表设计有问题.
2)其次进行多群组CFA分析, 检验各群组间的测量恒定性.如果模型满足截距恒定, 则该模型是较为简洁的模型, 已经可以进行群组间因素均值比较, 没有必要再使用对齐法; 如果模型拒绝截距恒定, 则可以考虑使用对齐法.
3)如果需要使用对齐法, 则根据所研究数据的实际情况选择固定优化算法或是自由优化算法进行分析.
4)根据研究需要进行蒙特卡洛模拟研究.此时进行模拟研究的目的可以是为了选择适当的优化算法, 可以是检验对齐法估计各个参数的有效性, 也可以是检验参数近似恒定性等.
同时, 笔者也提出一些使用对齐法分析的注意事项:当群组数较多, 模型较为复杂时, 准确的对齐法参数估计要求有较大的样本量(Asparouhov & Muthén, 2014).当模型中不恒定的参数比率达到25%时, 需要进一步使用模拟研究检验对齐法的有效性(Asparouhov & Muthén, 2014).如果需要进行模拟研究, 则需要注意在Mplus中使用svalues指令保存对齐法计算出的参数估计结果, 作为模拟研究的真实值.如果模型中的大多数参数不恒定性非常强, 无法满足近似恒定, 对齐法也不会有较好的分析效果.
接下来, 将运用某省4个学校的本科生职业价值观研究实例(3 本研究实例的数据和相关Mplus语法文件已经上传至OSF网站供读者参阅.项目链接为:https://osf.io/k34sg/)来演示当多群组CFA模型不满足截距恒定假设时, 应当如何使用对齐法检验模型参数的近似恒定性, 进而进行因素均值比较.参与本次调研的4个学校的本科生总样本共计4692名学生, 其中A学校2729名, B学校615名, C学校455名, D学校893名.4个学校各自的样本量较多, 可以满足对齐法分析的大样本量要求.研究共分为4个步骤, 供读者参考.
3.1 EFA分析
本研究使用的职业价值观量表是印第安纳大学问卷(Assessing Multinational Interest in STEM)的简化修改版(Maltese et al., 2014), 如表1所示.量表预设为个人兴趣,社会责任和经济动机三个维度, 使用4点量表(1.不重要,2.不太重要,3.比较重要,4.重要)的形式进行测量, 设问为“考虑到您自己的未来发展, 您认为下列因素的重要程度如何”.
表1 问卷中职业价值观量表的维度设计
| 维度设计 | 题号 | 题项内容 |
|---|---|---|
| 社会责任 | Q1 | 有助于可持续发展和环境保护 |
| Q5 | 帮助他人 | |
| Q9 | 做对社会发展有重要意义的事情 | |
| 个人兴趣 | Q2 | 自我发展 |
| Q3 | 做我感兴趣的事情 | |
| Q4 | 获得一份有保障的工作 | |
| Q6 | 发挥我的天赋和能力 | |
| 经济动机 | Q7 | 获得高薪的机会 |
| Q8 | 尽快开始赚钱 |
使用Mplus软件运行EFA后, 所得的表2所示的旋转后因素载荷矩阵结构和问卷的维度设计完全一致, 量表设计得到了数据样本的支撑.
表2 旋转后的因素载荷(N = 4692)
| 题项 | F1 | F2 | F3 |
|---|---|---|---|
| 1. 有助于可持续发展和环境保护 | 0.767 | ||
| 2. 自我发展 | 0.742 | ||
| 3. 做我感兴趣的事情 | 0.833 | ||
| 4. 获得一份有保障的工作 | 0.625 | ||
| 5. 帮助他人 | 0.828 | ||
| 6. 发挥我的天赋和能力 | 0.689 | ||
| 7. 获得高薪的机会 | 0.671 | ||
| 8. 尽快开始赚钱 | 0.705 | ||
| 9. 做对社会发展有重要意义的事情 | 0.717 |
注:*黑体数值在5%的置信区间上显著
3.2 多群组CFA分析
分别限制模型构置恒定,因素载荷恒定,截距恒定, 使用Mplus软件运行多群组CFA测量恒定性检验, 得到表3所示的模型拟合结果.构置恒定模型的卡方值最低, 表明拟合度最好.经过嵌套模型计算后, 卡方变化值与自由度变化值对应的p值在5%的置信区间上拒绝截距恒定和因素载荷恒定模型,构置恒定模型是最优模型.由于截距恒定模型被拒绝, 因此可以继续使用对齐法检验近似测量恒定性, 进而尝试进行因素均值比较.
表3 使用多群组CFA进行测量恒定性检验得到的模型拟合结果(N = 4692)
| 模型 | 参数数目 | 卡方值 | 自由度 | p值 |
|---|---|---|---|---|
| 构置恒定 | 120 | 1028.009 | 96 | <0.001 |
| 因素载荷恒定 | 102 | 1058.646 | 114 | <0.001 |
| 截距恒定 | 84 | 1120.288 | 132 | <0.001 |
| 载荷恒定对构置恒定 | - | 30.638 | 18 | 0.0317 |
| 截距恒定对构置恒定 | - | 92.279 | 36 | <0.001 |
| 截距恒定对载荷恒定 | - | 61.614 | 18 | <0.001 |
3.3 对齐法分析
分别使用固定优化算法和自由优化算法在Mplus软件中执行对齐法分析, 得到以下参数近似恒定结果和因素均值估计结果.(后文通过模拟研究证明固定优化算法得出的结果较为可靠, 此处仅展示部分固定优化算法得到的参数估计结果)从表4所示的参数近似恒定结果来看, 所有截距和因素载荷都近似恒定, 对齐法得到了理想的结果, 群组间因素均值比较切实可行.而在上一步使用多群组CFA时, 因素载荷恒定模型和截距恒定模型都被拒绝, 因素均值比较无法进行.从这一方面来看, 对齐法克服了群组间因素载荷和截距完全恒定的苛刻假设, 通过检验因素载荷和截距参数的近似恒定性使不同群组因素均值间的直接比较成为可能, 这是其相较多群组CFA的一大优势.从表5所示的个人兴趣因素均值比较来看, 群组4显著高于群组1,2,3; 从表6所示的经济因素均值比较来看, 群组2和群组3显著高于群组1,4.考虑到4所院校层次的排序为4>1>2≈3, 对齐法的研究结果与之前全国样本“985院校学生相比211院校和普通本科院校学生更注重个人兴趣; 普通本科院校学生相比985院校学生和211院校学生更注重经济因素”的研究结论相一致(温聪聪, 伍伟平, 蒋玉塔, 2016).
表4 参数近似恒定结果(N = 4692
| 参数类型 | 近似恒定组别 | 参数类型 | 近似恒定组别 |
|---|---|---|---|
| 截距 | 因素载荷 | ||
| Y1 | 1,2,3,4 | Y1 | 1,2,3,4 |
| Y2 | 1,2,3,4 | Y2 | 1,2,3,4 |
| Y3 | 1,2,3,4 | Y3 | 1,2,3,4 |
| Y4 | 1,2,3,4 | Y4 | 1,2,3,4 |
| Y5 | 1,2,3,4 | Y5 | 1,2,3,4 |
| Y6 | 1,2,3,4 | Y6 | 1,2,3,4 |
| Y7 | 1,2,3,4 | Y7 | 1,2,3,4 |
| Y8 | 1,2,3,4 | Y8 | 1,2,3,4 |
| Y9 | 1,2,3,4 | Y9 | 1,2,3,4 |
3.4 蒙特卡洛模拟研究
在第三步对齐法分析中并不清楚应该使用固定优化算法还是自由优化算法比较好, 所以在这一步中, 应当分别利用两种优化算法得到的参数估计结果进行蒙特卡洛模拟研究, 探究使用特定算法的对齐法能否较好分析参数间的恒定与不恒定性, 能否无偏估计各个参数.本研究中检验使用不同算法的对齐法是否无偏估计各个参数的标准有两个, 一是相应算法的因素均值真实值和估计值的比较, 体现因素均值出现了多少数值的偏差.二是相应算法因素均值的均方误差, 通过将该因素均值的方差和因素均值的期望偏差的平方加和得到, 体现参数估计的效果.均方误差越小越好, 且当等于所估计参数的方差的时候说明是无偏估计.模拟研究的条件基本模仿真实情况, 选择4个群组, 与真实数据相同的群组样本量(2729,615,455,893), 生成数据组数为500.使用第三步固定优化算法得到的参数估计结果进行固定优化对齐分析, 使用自由优化算法得到的参数估计结果进行自由优化对齐分析, 得到以下因素均值估计结果和因素均方误差计算结果.从表7所示的因素均值估计结果来看, 使用固定优化算法的对齐法能较好估计各群组的因素均值; 但使用自由优化算法的对齐法因素均值估计出现了较大偏差, 尤其是在经济因素, 偏差超过了1.3.从表8所示的因素均方误差计算结果来看, 两种算法在因素方差上的均方误差完全相同, 但自由优化算法在各因素均值上的均方误差都要大于固定优化算法.尤其是在经济因素, 自由优化算法估计因素均值的均方误差均值达到1.527, 而固定优化算法的这一数值仅为0.041.综上所述, 在本部分模拟研究所设定的研究条件下, 使用固定优化算法的对齐法可以几乎无偏估计因素均值, 均方误差较小, 效果明显优于使用自由优化算法的对齐法.回想第三步中所有因素载荷和截距都近似恒定, 这一结论和Asparouhov和Muthén所做模拟研究中“当模型中没有不恒定参数时, 固定优化算法要优于自由优化算法”的结论相一致(Asparouhov & Muthén, 2014).所以, 第三步仅列出了使用固定优化算法的对齐法计算出的参数估计结果.
表7 两种算法的因素均值估计结果(N=4692)
| 均值类别 | 固定优 化算法 真实值 | 估计值 | 自由优 化算法 真实值 | 估计值 |
|---|---|---|---|---|
| 群组1 | ||||
| 个人兴趣因素 | 0.000 | 0.000 | 0.314 | 0.221 |
| 社会责任因素 | 0.000 | 0.000 | -0.081 | -0.072 |
| 经济因素 | 0.000 | 0.000 | 1.848 | 0.520 |
| 群组2 | ||||
| 个人兴趣因素 | 0.038 | 0.040 | 0.351 | 0.261 |
| 社会责任因素 | 0.075 | 0.079 | -0.004 | 0.008 |
| 经济因素 | 0.163 | 0.164 | 2.009 | 0.682 |
| 群组3 | ||||
| 个人兴趣因素 | 0.028 | 0.033 | 0.339 | 0.252 |
| 社会责任因素 | 0.065 | 0.070 | -0.018 | -0.002 |
| 经济因素 | 0.127 | 0.129 | 1.975 | 0.648 |
| 群组4 | ||||
| 个人兴趣因素 | 0.162 | 0.163 | 0.472 | 0.381 |
| 社会责任因素 | -0.005 | -0.006 | -0.086 | -0.077 |
| 经济因素 | -0.014 | -0.021 | 1.810 | 0.484 |
表8 两种算法的因素均方误差计算结果(N = 4692
| 因素 | 固定优化算法 均方误差 | 自由优化算法 均方误差 | ||
|---|---|---|---|---|
| 均值 | 标准差 | 均值 | 标准差 | |
| 个人兴趣因素 | ||||
| 因素均值 | 0.036 | 0.016 | 0.224 | 0.179 |
| 因素方差 | 0.046 | 0.020 | 0.046 | 0.020 |
| 社会责任因素 | ||||
| 因素均值 | 0.038 | 0.017 | 0.184 | 0.141 |
| 因素方差 | 0.050 | 0.022 | 0.050 | 0.022 |
| 经济因素 | ||||
| 因素均值 | 0.041 | 0.018 | 1.527 | 1.139 |
| 因素方差 | 0.060 | 0.025 | 0.060 | 0.025 |
4 方法总结与展望
通过前文所述, 对齐法可以被认为是传统多群组CFA的有益补充, 其最大贡献是可以克服苛刻的截距恒定假设, 通过检验参数的近似恒定性而达到群组间的因素均值比较的目的.相比传统的多群组CFA, 对齐法可以有效拟合参数近似恒定的模型, 模型拟合度和拟合度较好的构置恒定模型完全相同, 还可以处理数目繁多的群组,较为复杂的量表结构, 可以为模型中因素载荷和截距的近似恒定性提供详细的诊断.通常情况下, 如果研究数据的样本量很大, 群组较多, 模型较复杂, 那么使用多群组CFA很难满足截距恒定假设.此时, 使用对齐法检验模型参数近似恒定性而进行因素均值比较可能是较好的选择.如果研究者希望了解模型中因素载荷和截距等参数的恒定性, 从而对模型进行诊断或是希望改进量表设计, 使用对齐法也是更好的选择, 因为传统的使用修正指数释放参数的方法受研究者主观判断的影响较大, 修正指数的多重共线性也会误导研究者的判断.
同时, 对齐法作为一种新方法, 也存在着一些局限性.首先, 对齐法是基于构置恒定模型, 潜在的前提是构置恒定模型拟合较好, 且要优于因素载荷恒定模型或是截距恒定模型.但有的时候会出现构置恒定模型本身拟合就很不好或是因素载荷恒定模型拟合更好, 此时使用对齐法就会有一定的问题.其次, 对于较多的群组和较为复杂的模型, 对齐法要求待分析的各个群组的样本量足够大, 而这一条件不一定总能满足.再次, 对齐法的提出者仅仅指出当模型中的不恒定参数比率小于等于25%时对齐法参数估计能取得较好效果(Asparouhov & Muthén, 2014), 但25%的依据并不充分, 今后的研究可以探究这一比率是否更小或更大.最后, 对齐法仍然是基于传统CFA, 只允许观测变量在一个因素上有因素载荷, 不允许因素拥有跨因素载荷(cross-loadings), 所以研究的CFA模型可能本身就不是正确的模型.
对齐法自2014年提出以来也在不断更新, 方法被应用于更多领域, 也有许多新进展.对齐法提出同年, Muthén和Asparouhov将对齐法应用于项目反应理论(item response theory)研究(Muthén & Asparouhov, 2014).他们介绍了在项目反应理论情境下对齐法的计算方法, 运用蒙特卡洛模拟研究检验了对齐法的适用性.2017年, Muthén和Asparouhov比较了对齐法和随机效应法(random effects method)两种研究多群组测量恒定性的方法, 详细叙述了在不同研究条件下选取对齐法或是随机效应法分析数据的准则, 比较了两种方法各自的优势与缺陷.随机效应法的引入进一步填补了测量恒定性研究领域的空白, 是对齐法的有益补充.2017年, Marsh等人基于标准对齐法提出了CFA对齐法(alignment within CFA), 将更倾向于探索性的对齐法变为了验证性的对齐法(Marsh et al., 2017).相比标准对齐法, CFA对齐法可以更广泛地应用于结构方程模型, 引入协变量进行多指标多因素(MIMIC)模型分析, 并且在Mplus软件中还可以得到标准对齐法无法提供的修正指数等指标.
随着研究者越来越深入了解对齐法的原理, 有越来越多的研究开始使用对齐法进行多群组分析, 研究群组间的可比较性.Munck等人使用对齐法研究了1999年教育成就评价国际委员会收集的欧洲22国公民教育研究数据和2009年该机构收集的欧洲24国国际公民与公民身份教育研究数据(Munck & Torney, 2017).研究者以国别和性别两个变量区分不同群组, 运用对齐法研究了92个研究组别的测量恒定性, 成功比较了样本中国别与性别的差异, 解决了没有满足截距恒定无法进行群组间因素均值比较的问题.Lomazzi使用对齐法研究了世界民众价值观调研收集的关于男女性承担角色的态度的全球59国数据样本 (Lomazzi, 2018), 比较了部分截距恒定模型和对齐法各自的特点和优势.
最后, 基于对齐法的局限性, 可能仍然有许多等待研究者挖掘的领域.例如, 不同情境下对齐法需要的群组样本量大小, 对齐法取得较好估计效果所能接受的不恒定参数率, 对齐法与探索性结构方程模型(ESEM)结合的可能性, 运用对齐法研究跨时序模型中参数近似恒定性的可能性, 对齐法和多水平随机效应法的适用性等等.
参考文献
网络测验和纸笔测验的测量不变性研究——以生活满意度量表为例.
以生活满意度量表为例,运用实证性因素分析,考察在中国文化下网络测验和传统纸笔测验之间的测量不变性。结果显示,网络测验和纸笔测验之间存在弱不变性,即网络测验和纸笔测验有着相同的测量单位;但网络测验和纸笔测验只存在部分的强不变性和部分的严格不变性,测验实施环境对结果的影响不可忽视。该研究表明,恰当设计的网络测验是可靠的,同时还提示,当一个测验在不同情境下运用时,检验测量不变性十分必要。
Multiple-group factor analysis alignment.
DOI:10.1080/10705511.2014.919210
URL
[本文引用: 7]

This article presents a new method for multiple-group confirmatory factor analysis (CFA), referred to as the alignment method. The alignment method can be used to estimate group-specific factor means and variances without requiring exact measurement invariance. A strength of the method is the ability to conveniently estimate models for many groups. The method is a valuable alternative to the currently used multiple-group CFA methods for studying measurement invariance that require multiple manual model adjustments guided by modification indexes. Multiple-group CFA is not practical with many groups due to poor model fit of the scalar model and too many large modification indexes. In contrast, the alignment method is based on the configural model and essentially automates and greatly simplifies measurement invariance analysis. The method also provides a detailed account of parameter invariance for every model parameter in every group.
Quantitative methods with survey data in comparative research.
DOI:10.1016/j.urology.2010.07.118
URL
[本文引用: 1]
Introduction and Objective To determine efficacy of bone anchored male sling (BAMS) versus transobturator male sling (TOMS) and identify pre-operative risk factors contributing to success and/or failure. Methods A retrospective chart review was performed from 2000-2010 of patients who underwent BAMS and TOMS. Patients with follow-up time < 1.5 months were excluded. Data examined included demographics, urodynamic parameters, pad usage, presence of detrusor overactivity (DO), and previous urethral disease. Failure was defined < 50% improvement. Pre-operative risk factors for failure were analyzed using Student t test, Wilcoxon test, Fisher's Exact test, and logistical regression. A p-value < 0.05 was considered statistically significant. Results Fifty-nine of 64 patients with a mean age of 69.4 years ± 9.3 were analyzed. Five were excluded for inadequate follow-up. Forty-one received BAMS and 18 received TOMS with median follow up of 9 months (1.5-96) and 7 months (1.5–14) respectively (p= 0.1). Table I, POD-1.06 Pre-operative Characteristics for Male Sling Total patients (n=59) BAMS (n=41) TOMS (n=18) P Value Pads/day (Median & IQR) 4.0(2.0-5.0) 3.0(2.0-5.3) ns LPP (Mean & SD) 70.3±45.8 83.8±34.5 ns MUP (Mean & SD) 53.6±40.2 86.7±30.2 0.0067 FL (Mean & SD) 3.1±1.4 3.5±1.0 ns DO 13(31.7%) 3(16.7%) ns UD 23(56.1%) 7(38.9%) ns (LPP)= Abdominal Leak Point-pressure, (MUP)= Maximal Urethral Pressure, (FL)= Functional Profile Length, (DO)= Detrusor Overactivity, (UD)= Urethral Disease, (SD)= Standard Deviation, (IQR)= Interquartile Range Peri-operative decrease in pad usage was statistically significant for the TOMS group (3 to 1.5, p < 0.004) compared to the BAMS group (4 to 3.5, p=0.3). Failure rate was 46.3% (19/41) in BAMS and 16.7% (3/18) in TOMS (p=0.03). Table II, POD-1.06 Pre-operative Risk Factors for Failed Sli ng Procedures Risk Factor P value LPP 0.0032 FL ns MUP 0.0246 DO ns UD 0.0118 (LPP)= Abdominal Leak Point-pressure, (FL)= Functional Profile Length, (MUP)= Maximal Urethral Pressure, (DO)= Detrusor Overactivity, (UD)= Urethral Disease Conclusion Males undergoing TOMS placement have lower failure rates. Males with pre-operative increased pad usage, low MUP, low LPP, and presence of UD may not be appropriate candidates for male sling.
Measurement equivalence in cross-national research.
DOI:10.1146/annurev-soc-071913-043137
URL
[本文引用: 1]
Determining whether people in certain countries score differently in measurements of interest or whether concepts relate differently to each other across nation
Using alignment optimization to test the measurement invariance of gender role attitudes in 59 countries.
Assessing multinational interest in STEM: Implementing a comparative survey research study in China.
What to do when scalar
invariance fails: The extended alignment method for multiple-group factor analysis comparison of latent means across many groups
.
Statistical approaches to measurement invariance. New York, NY, US: Routledge/Taylor &.
IRT studies of many groups: the alignment method.
DOI:10.3389/fpsyg.2014.00978
URL
PMID:4162377
[本文引用: 1]
Asparouhov and Muthen (forthcoming) presented a new method for multiple-group confirmatory factor analysis (CFA), referred to as the alignment method. The alignment method can be used to estimate group-specific factor means and variances without requiring exact measurement invariance. A strength of the method is the ability to conveniently estimate models for many groups, such as with comparisons of countries. This paper focuses on IRT applications of the alignment method. An empirical investigation is made of binary knowledge items administered in two separate surveys of a set of countries. A Monte Carlo study is presented that shows how the quality of the alignment can be assessed.
Recent methods for the study of measurement invariance with many groups: alignment and random effects.
Measurement invariance in comparing attitudes toward immigrants among youth across Europe in 1999 and 2009: The alignment method applied to IEA CIVED and ICCS.
Basic personal values and the meaning of left-right political orientations in 20 countries.
DOI:10.1111/j.1467-9221.2011.00828.x
URL
[本文引用: 1]
This study used basic personal values to elucidate the motivational meanings of "left" and "right" political orientations in 20 representative national samples from the European Social Survey (2002-2003). It also compared the importance of personal values and sociodemographic variables as determinants of political orientation. Hypotheses drew on the different histories, prevailing culture, and socioeconomic level of three sets of countries iberal, traditional, and postcommunist. As hypothesized, universalism and benevolence values explained a left orientation in both liberal and traditional countries and conformity and tradition values explained a right orientation; values had little explanatory power in postcommunist countries. Values predicted political orientation more strongly than sociodemographic variables in liberal countries, more weakly in postcommunist countries, and about equally in traditional countries.
A review and synthesis of the measurement invariance literature: Suggestions, practices, and recommendations for organizational research.
Structural equation modeling: Applications using Mplus. John Wiley &.
Exploring the measurement invariance of psychological instruments: Applications in the substance use domain. In K. J. Bryant, M. Windle, & S. G. West (Eds.), The science of prevention: Methodological advances from alcohol and substance abuse research (pp. 281-324)
.
DOI:10.1037/10222-009
URL
[本文引用: 1]
ABSTRACT Discusses several forms of invariance that may be distinguished and tested, reviews confirmatory factor analysis (CFA) approaches to addressing questions of this sort, presents analyses of empirical data to demonstrate how to perform and interpret such analyses, and outlines several problems that must be confronted in future research to provide a complete consideration of the invariance of psychological instruments. The chapter describes several concepts and advances contained within recent contributions to the measurement invariance literature. The chapter then describes the data set to be used in the authors' study and the types of analyses conducted, including how the results of these analyses should be interpreted. Measurement invariance is explored in relation to high school seniors' current attitudes and behaviors about smoking. (PsycINFO Database Record (c) 2012 APA, all rights reserved)
